 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Detailed Face Reconstruction from a Single Image
Apr 06, 2017
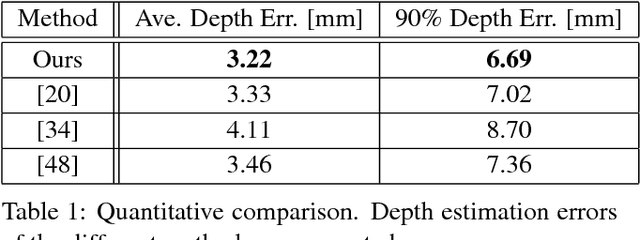


Reconstructing the detailed geometric structure of a face from a given image is a key to many computer vision and graphics applications, such as motion capture and reenactment. The reconstruction task is challenging as human faces vary extensively when considering expressions, poses, textures, and intrinsic geometries. While many approaches tackle this complexity by using additional data to reconstruct the face of a single subject, extracting facial surface from a single image remains a difficult problem. As a result, single-image based methods can usually provide only a rough estimate of the facial geometry. In contrast, we propose to leverage the power of convolutional neural networks to produce a highly detailed face reconstruction from a single image. For this purpose, we introduce an end-to-end CNN framework which derives the shape in a coarse-to-fine fashion. The proposed architecture is composed of two main blocks, a network that recovers the coarse facial geometry (CoarseNet), followed by a CNN that refines the facial features of that geometry (FineNet). The proposed networks are connected by a novel layer which renders a depth image given a mesh in 3D. Unlike object recognition and detection problems, there are no suitable datasets for training CNNs to perform face geometry reconstruction. Therefore, our training regime begins with a supervised phase, based on synthetic images, followed by an unsupervised phase that uses only unconstrained facial images. The accuracy and robustness of the proposed model is demonstrated by both qualitative and quantitative evaluation tests.
Polarimetric Monocular Dense Mapping Using Relative Deep Depth Prior
Feb 10, 2021
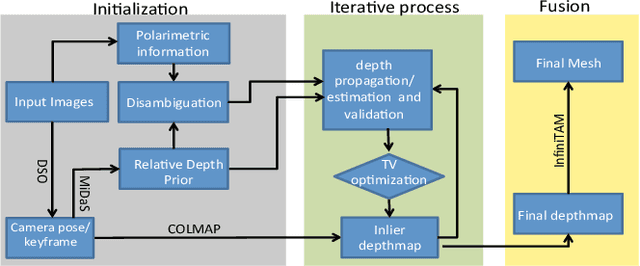


This paper is concerned with polarimetric dense map reconstruction based on a polarization camera with the help of relative depth information as a prior. In general, polarization imaging is able to reveal information about surface normal such as azimuth and zenith angles, which can support the development of solutions to the problem of dense reconstruction, especially in texture-poor regions. However, polarimetric shape cues are ambiguous due to two types of polarized reflection (specular/diffuse). Although methods have been proposed to address this issue, they either are offline and therefore not practical in robotics applications, or use incomplete polarimetric cues, leading to sub-optimal performance. In this paper, we propose an online reconstruction method that uses full polarimetric cues available from the polarization camera. With our online method, we can propagate sparse depth values both along and perpendicular to iso-depth contours. Through comprehensive experiments on challenging image sequences, we demonstrate that our method is able to significantly improve the accuracy of the depthmap as well as increase its density, specially in regions of poor texture.
Learning Vector Quantized Shape Code for Amodal Blastomere Instance Segmentation
Dec 02, 2020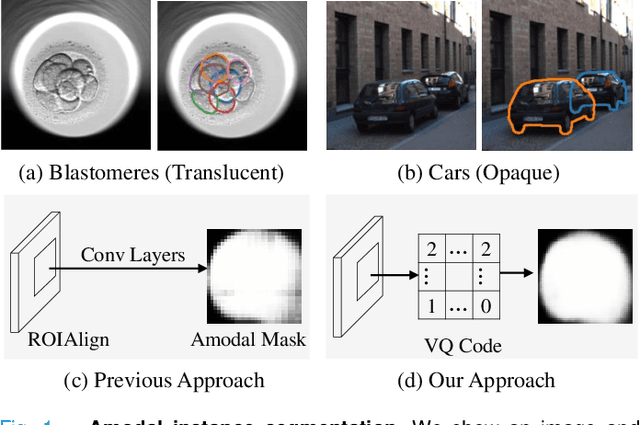
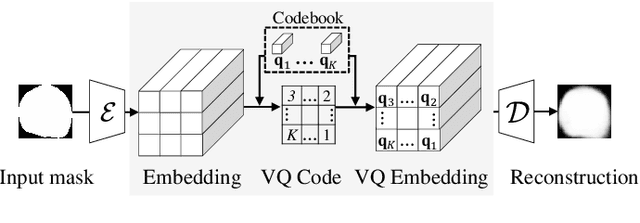
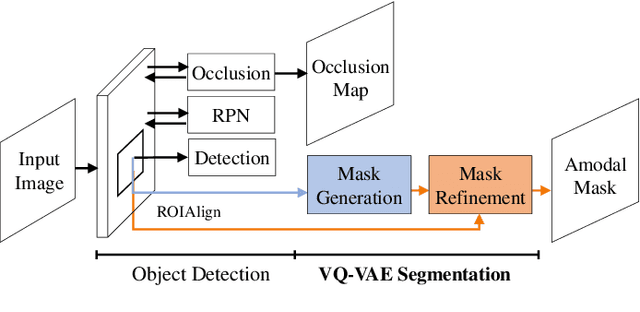
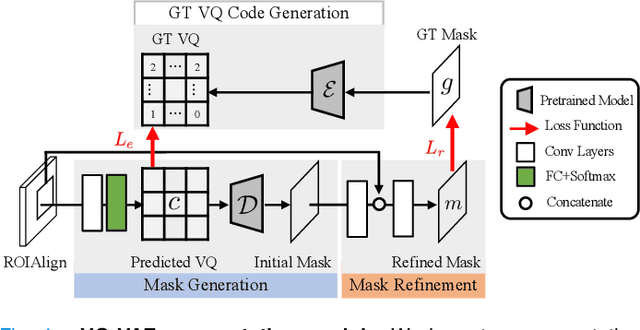
Blastomere instance segmentation is important for analyzing embryos' abnormality. To measure the accurate shapes and sizes of blastomeres, their amodal segmentation is necessary. Amodal instance segmentation aims to recover the complete silhouette of an object even when the object is not fully visible. For each detected object, previous methods directly regress the target mask from input features. However, images of an object under different amounts of occlusion should have the same amodal mask output, which makes it harder to train the regression model. To alleviate the problem, we propose to classify input features into intermediate shape codes and recover complete object shapes from them. First, we pre-train the Vector Quantized Variational Autoencoder (VQ-VAE) model to learn these discrete shape codes from ground truth amodal masks. Then, we incorporate the VQ-VAE model into the amodal instance segmentation pipeline with an additional refinement module. We also detect an occlusion map to integrate occlusion information with a backbone feature. As such, our network faithfully detects bounding boxes of amodal objects. On an internal embryo cell image benchmark, the proposed method outperforms previous state-of-the-art methods. To show generalizability, we show segmentation results on the public KINS natural image benchmark. To examine the learned shape codes and model design choices, we perform ablation studies on a synthetic dataset of simple overlaid shapes. Our method would enable accurate measurement of blastomeres in in vitro fertilization (IVF) clinics, which potentially can increase IVF success rate.
Vision-based Price Suggestion for Online Second-hand Items
Dec 10, 2020


Different from shopping in physical stores, where people have the opportunity to closely check a product (e.g., touching the surface of a T-shirt or smelling the scent of perfume) before making a purchase decision, online shoppers rely greatly on the uploaded product images to make any purchase decision. The decision-making is challenging when selling or purchasing second-hand items online since estimating the items' prices is not trivial. In this work, we present a vision-based price suggestion system for the online second-hand item shopping platform. The goal of vision-based price suggestion is to help sellers set effective prices for their second-hand listings with the images uploaded to the online platforms. First, we propose to better extract representative visual features from the images with the aid of some other image-based item information (e.g., category, brand). Then, we design a vision-based price suggestion module which takes the extracted visual features along with some statistical item features from the shopping platform as the inputs to determine whether an uploaded item image is qualified for price suggestion by a binary classification model, and provide price suggestions for items with qualified images by a regression model. According to two demands from the platform, two different objective functions are proposed to jointly optimize the classification model and the regression model. For better model training, we also propose a warm-up training strategy for the joint optimization. Extensive experiments on a large real-world dataset demonstrate the effectiveness of our vision-based price prediction system.
MicroAnalyzer: A Python Tool for Automated Bacterial Analysis with Fluorescence Microscopy
Sep 26, 2020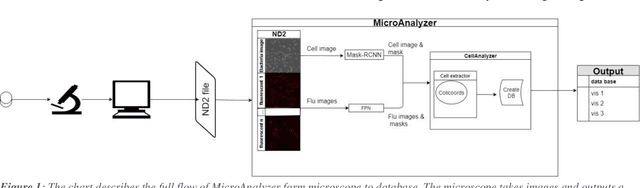
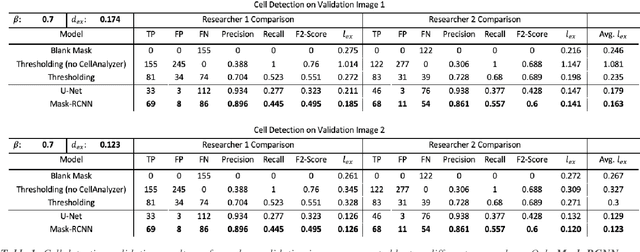
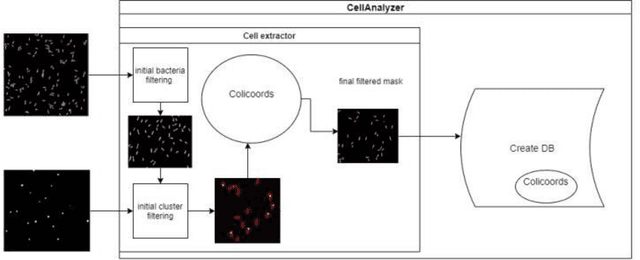
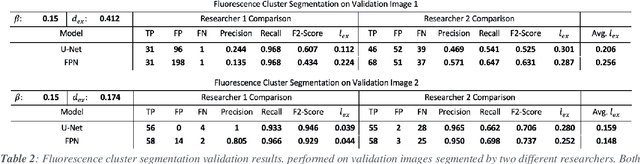
Fluorescence microscopy is a widely used method among cell biologists for studying the localization and co-localization of fluorescent protein. For microbial cell biologists, these studies often include tedious and time-consuming manual segmentation of bacteria and of the fluorescence clusters or working with multiple programs. Here, we present MicroAnalyzer - a tool that automates these tasks by providing an end-to-end platform for microscope image analysis. While such tools do exist, they are costly, black-boxed programs. Microanalyzer offers an open-source alternative to these tools, allowing flexibility and expandability by advanced users. MicroAnalyzer provides accurate cell and fluorescence cluster segmentation based on state-of-the-art deep-learning segmentation models, combined with ad-hoc post-processing and Colicoords - an open-source cell image analysis tool for calculating general cell and fluorescence measurements. Using these methods, it performs better than generic approaches since the dynamic nature of neural networks allows for a quick adaptation to experiment restrictions and assumptions. Other existing tools do not consider experiment assumptions, nor do they provide fluorescence cluster detection without the need for any specialized equipment. The key goal of MicroAnalyzer is to automate the entire process of cell and fluorescence image analysis "from microscope to database", meaning it does not require any further input from the researcher except for the initial deep-learning model training. In this fashion, it allows the researchers to concentrate on the bigger picture instead of granular, eye-straining labor
Conditional Image Generation with PixelCNN Decoders
Jun 18, 2016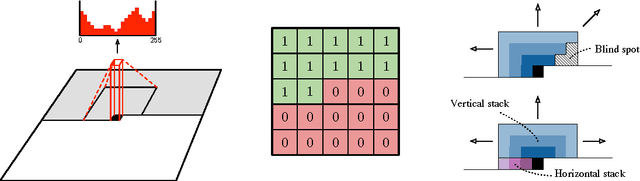
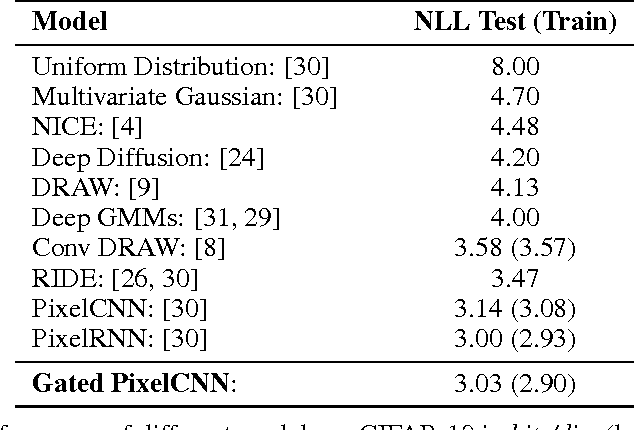
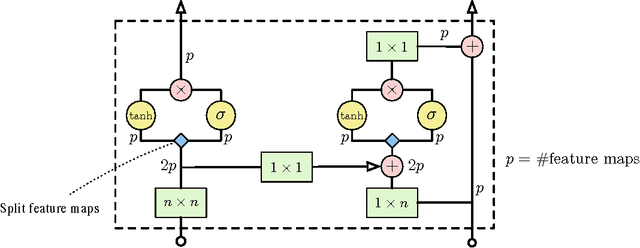
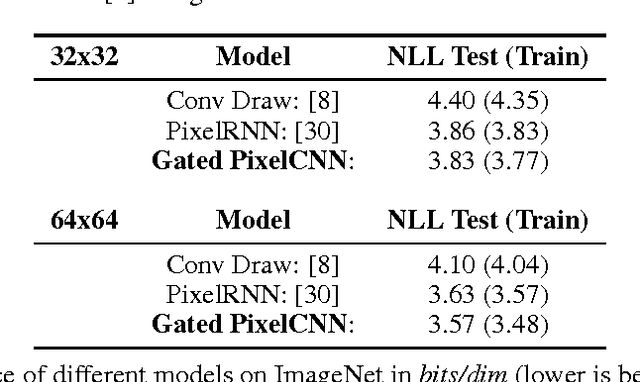
This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.
Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification
May 12, 2019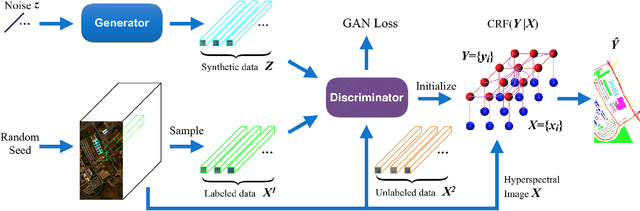
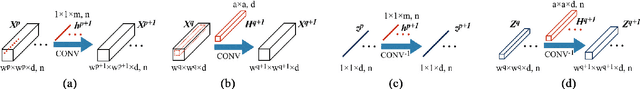
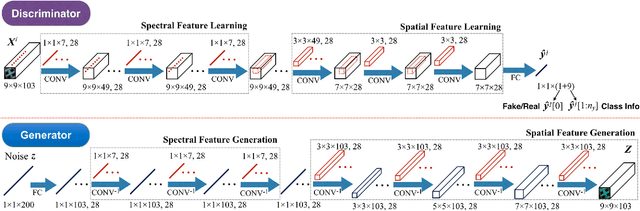
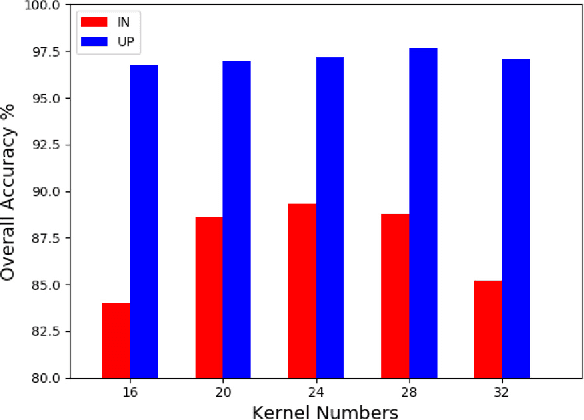
In this paper, we address the hyperspectral image (HSI) classification task with a generative adversarial network and conditional random field (GAN-CRF) -based framework, which integrates a semi-supervised deep learning and a probabilistic graphical model, and make three contributions. First, we design four types of convolutional and transposed convolutional layers that consider the characteristics of HSIs to help with extracting discriminative features from limited numbers of labeled HSI samples. Second, we construct semi-supervised GANs to alleviate the shortage of training samples by adding labels to them and implicitly reconstructing real HSI data distribution through adversarial training. Third, we build dense conditional random fields (CRFs) on top of the random variables that are initialized to the softmax predictions of the trained GANs and are conditioned on HSIs to refine classification maps. This semi-supervised framework leverages the merits of discriminative and generative models through a game-theoretical approach. Moreover, even though we used very small numbers of labeled training HSI samples from the two most challenging and extensively studied datasets, the experimental results demonstrated that spectral-spatial GAN-CRF (SS-GAN-CRF) models achieved top-ranking accuracy for semi-supervised HSI classification.
MagGAN: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network
Oct 03, 2020
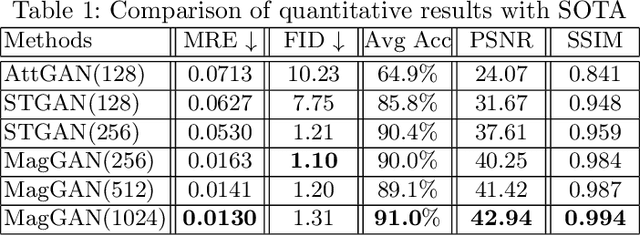

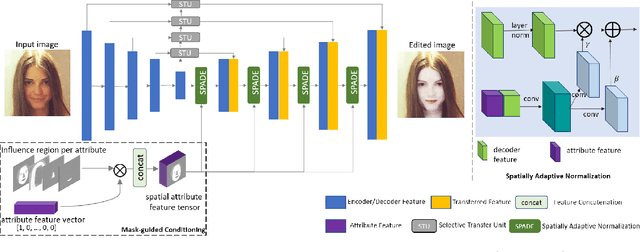
We present Mask-guided Generative Adversarial Network (MagGAN) for high-resolution face attribute editing, in which semantic facial masks from a pre-trained face parser are used to guide the fine-grained image editing process. With the introduction of a mask-guided reconstruction loss, MagGAN learns to only edit the facial parts that are relevant to the desired attribute changes, while preserving the attribute-irrelevant regions (e.g., hat, scarf for modification `To Bald'). Further, a novel mask-guided conditioning strategy is introduced to incorporate the influence region of each attribute change into the generator. In addition, a multi-level patch-wise discriminator structure is proposed to scale our model for high-resolution ($1024 \times 1024$) face editing. Experiments on the CelebA benchmark show that the proposed method significantly outperforms prior state-of-the-art approaches in terms of both image quality and editing performance.
Visual Place Recognition for Aerial Robotics: Exploring Accuracy-Computation Trade-off for Local Image Descriptors
Aug 01, 2019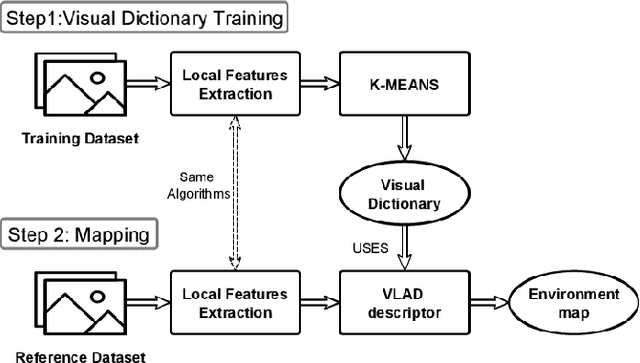
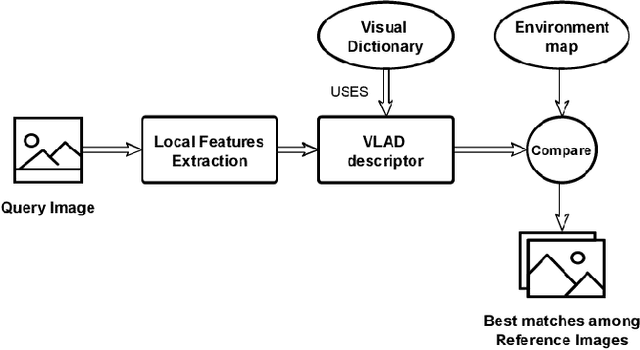


Visual Place Recognition (VPR) is a fundamental yet challenging task for small Unmanned Aerial Vehicle (UAV). The core reasons are the extreme viewpoint changes, and limited computational power onboard a UAV which restricts the applicability of robust but computation intensive state-of-the-art VPR methods. In this context, a viable approach is to use local image descriptors for performing VPR as these can be computed relatively efficiently without the need of any special hardware, such as a GPU. However, the choice of a local feature descriptor is not trivial and calls for a detailed investigation as there is a trade-off between VPR accuracy and the required computational effort. To fill this research gap, this paper examines the performance of several state-of-the-art local feature descriptors, both from accuracy and computational perspectives, specifically for VPR application utilizing standard aerial datasets. The presented results confirm that a trade-off between accuracy and computational effort is inevitable while executing VPR on resource-constrained hardware.
Fast Image Classification by Boosting Fuzzy Classifiers
Oct 04, 2016
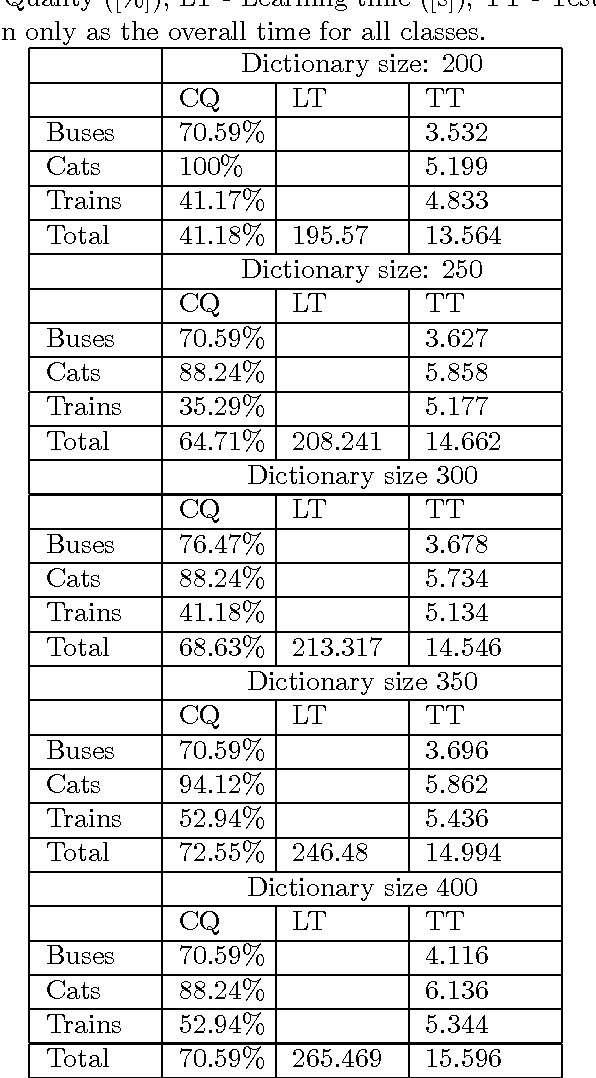
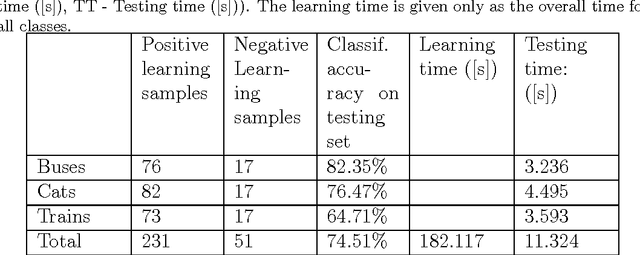
This paper presents a novel approach to visual objects classification based on generating simple fuzzy classifiers using local image features to distinguish between one known class and other classes. Boosting meta learning is used to find the most representative local features. The proposed approach is tested on a state-of-the-art image dataset and compared with the bag-of-features image representation model combined with the Support Vector Machine classification. The novel method gives better classification accuracy and the time of learning and testing process is more than 30% shorter.
* 1 figure