 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition
Apr 23, 2017
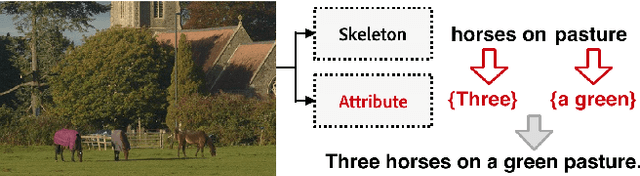

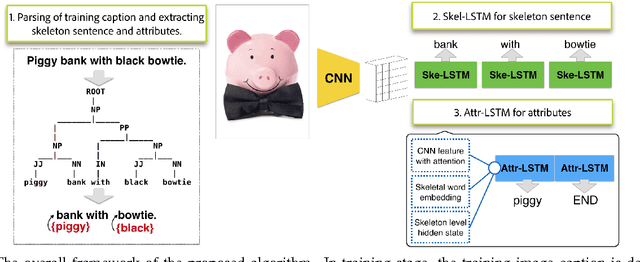
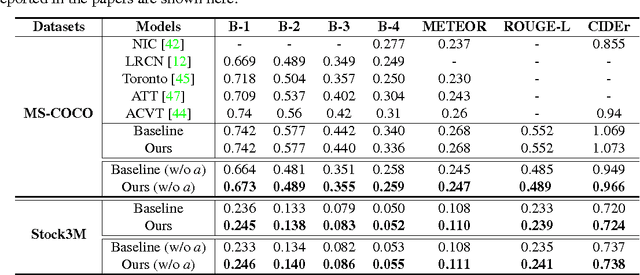
Recently, there has been a lot of interest in automatically generating descriptions for an image. Most existing language-model based approaches for this task learn to generate an image description word by word in its original word order. However, for humans, it is more natural to locate the objects and their relationships first, and then elaborate on each object, describing notable attributes. We present a coarse-to-fine method that decomposes the original image description into a skeleton sentence and its attributes, and generates the skeleton sentence and attribute phrases separately. By this decomposition, our method can generate more accurate and novel descriptions than the previous state-of-the-art. Experimental results on the MS-COCO and a larger scale Stock3M datasets show that our algorithm yields consistent improvements across different evaluation metrics, especially on the SPICE metric, which has much higher correlation with human ratings than the conventional metrics. Furthermore, our algorithm can generate descriptions with varied length, benefiting from the separate control of the skeleton and attributes. This enables image description generation that better accommodates user preferences.
MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network
Jul 08, 2017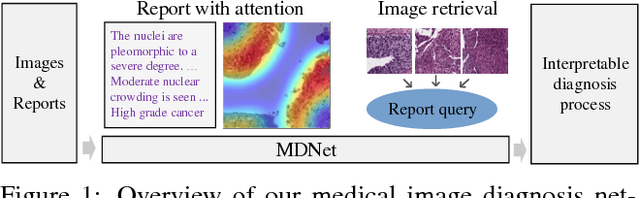
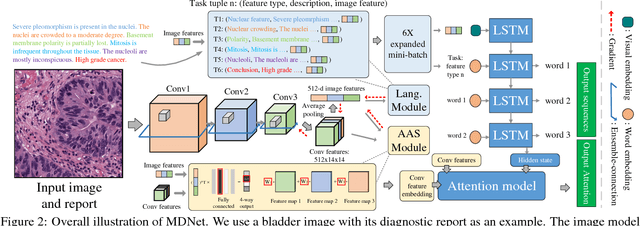
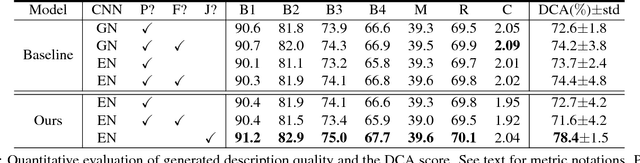
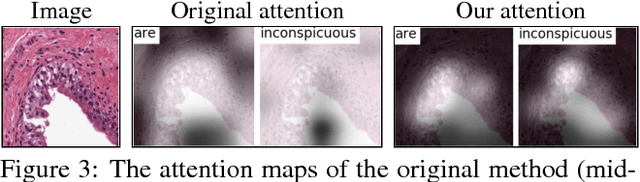
The inability to interpret the model prediction in semantically and visually meaningful ways is a well-known shortcoming of most existing computer-aided diagnosis methods. In this paper, we propose MDNet to establish a direct multimodal mapping between medical images and diagnostic reports that can read images, generate diagnostic reports, retrieve images by symptom descriptions, and visualize attention, to provide justifications of the network diagnosis process. MDNet includes an image model and a language model. The image model is proposed to enhance multi-scale feature ensembles and utilization efficiency. The language model, integrated with our improved attention mechanism, aims to read and explore discriminative image feature descriptions from reports to learn a direct mapping from sentence words to image pixels. The overall network is trained end-to-end by using our developed optimization strategy. Based on a pathology bladder cancer images and its diagnostic reports (BCIDR) dataset, we conduct sufficient experiments to demonstrate that MDNet outperforms comparative baselines. The proposed image model obtains state-of-the-art performance on two CIFAR datasets as well.
Who's a Good Boy? Reinforcing Canine Behavior in Real-Time using Machine Learning
Jan 11, 2021


In this paper we outline the development methodology for an automatic dog treat dispenser which combines machine learning and embedded hardware to identify and reward dog behaviors in real-time. Using machine learning techniques for training an image classification model we identify three behaviors of our canine companions: "sit", "stand", and "lie down" with up to 92% test accuracy and 39 frames per second. We evaluate a variety of neural network architectures, interpretability methods, model quantization and optimization techniques to develop a model specifically for an NVIDIA Jetson Nano. We detect the aforementioned behaviors in real-time and reinforce positive actions by making inference on the Jetson Nano and transmitting a signal to a servo motor to release rewards from a treat delivery apparatus.
Applications of Deep Learning in Fundus Images: A Review
Jan 25, 2021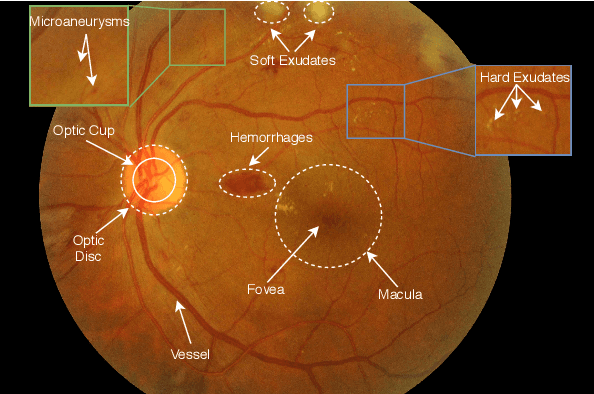
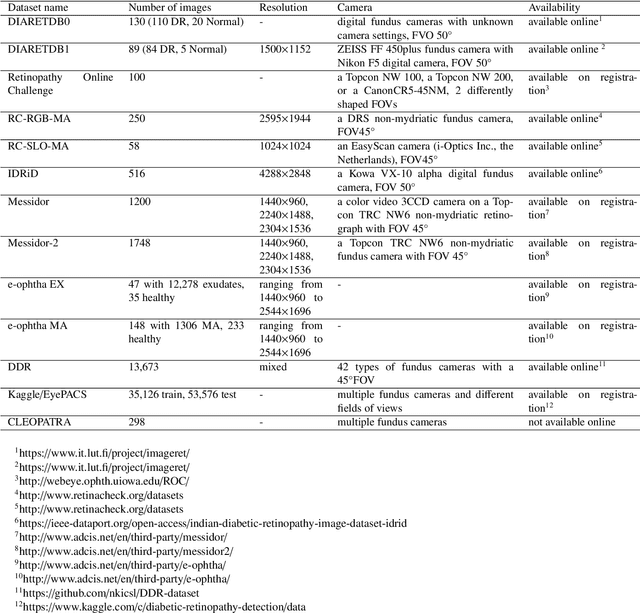
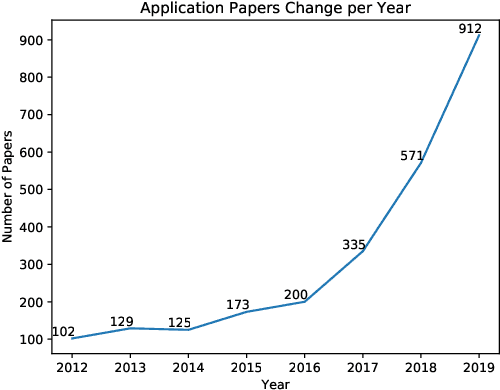
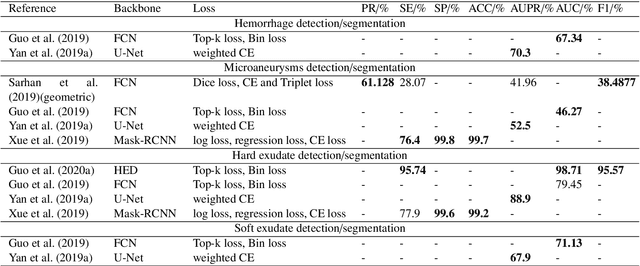
The use of fundus images for the early screening of eye diseases is of great clinical importance. Due to its powerful performance, deep learning is becoming more and more popular in related applications, such as lesion segmentation, biomarkers segmentation, disease diagnosis and image synthesis. Therefore, it is very necessary to summarize the recent developments in deep learning for fundus images with a review paper. In this review, we introduce 143 application papers with a carefully designed hierarchy. Moreover, 33 publicly available datasets are presented. Summaries and analyses are provided for each task. Finally, limitations common to all tasks are revealed and possible solutions are given. We will also release and regularly update the state-of-the-art results and newly-released datasets at https://github.com/nkicsl/Fundus Review to adapt to the rapid development of this field.
Hyperspectral Image Classification in the Presence of Noisy Labels
Sep 12, 2018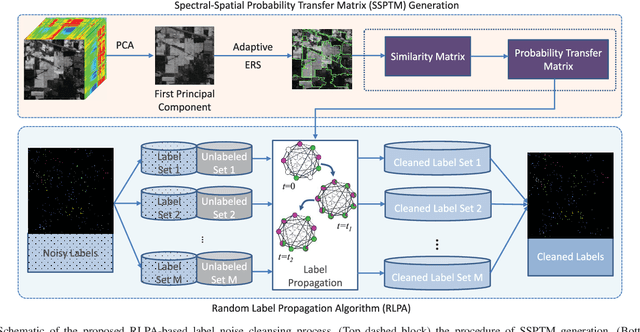

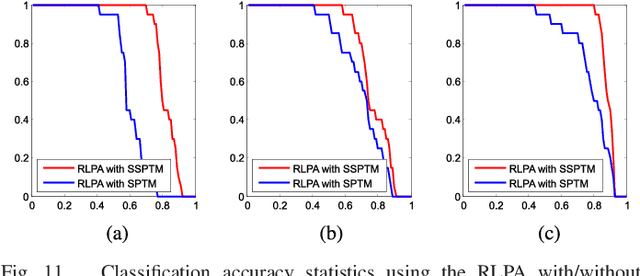

Label information plays an important role in supervised hyperspectral image classification problem. However, current classification methods all ignore an important and inevitable problem---labels may be corrupted and collecting clean labels for training samples is difficult, and often impractical. Therefore, how to learn from the database with noisy labels is a problem of great practical importance. In this paper, we study the influence of label noise on hyperspectral image classification, and develop a random label propagation algorithm (RLPA) to cleanse the label noise. The key idea of RLPA is to exploit knowledge (e.g., the superpixel based spectral-spatial constraints) from the observed hyperspectral images and apply it to the process of label propagation. Specifically, RLPA first constructs a spectral-spatial probability transfer matrix (SSPTM) that simultaneously considers the spectral similarity and superpixel based spatial information. It then randomly chooses some training samples as "clean" samples and sets the rest as unlabeled samples, and propagates the label information from the "clean" samples to the rest unlabeled samples with the SSPTM. By repeating the random assignment (of "clean" labeled samples and unlabeled samples) and propagation, we can obtain multiple labels for each training sample. Therefore, the final propagated label can be calculated by a majority vote algorithm. Experimental studies show that RLPA can reduce the level of noisy label and demonstrates the advantages of our proposed method over four major classifiers with a significant margin---the gains in terms of the average OA, AA, Kappa are impressive, e.g., 9.18%, 9.58%, and 0.1043. The Matlab source code is available at https://github.com/junjun-jiang/RLPA
Document Image Classification with Intra-Domain Transfer Learning and Stacked Generalization of Deep Convolutional Neural Networks
Aug 30, 2018
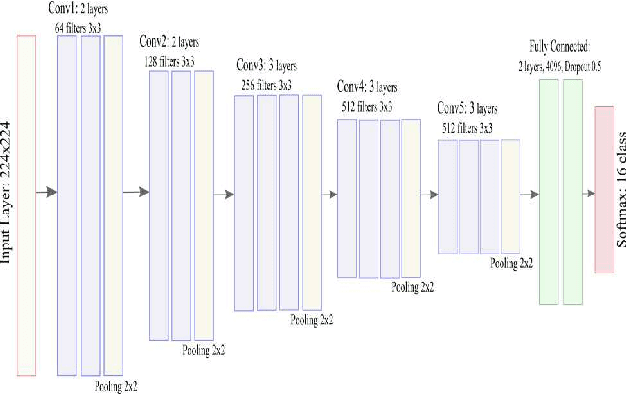

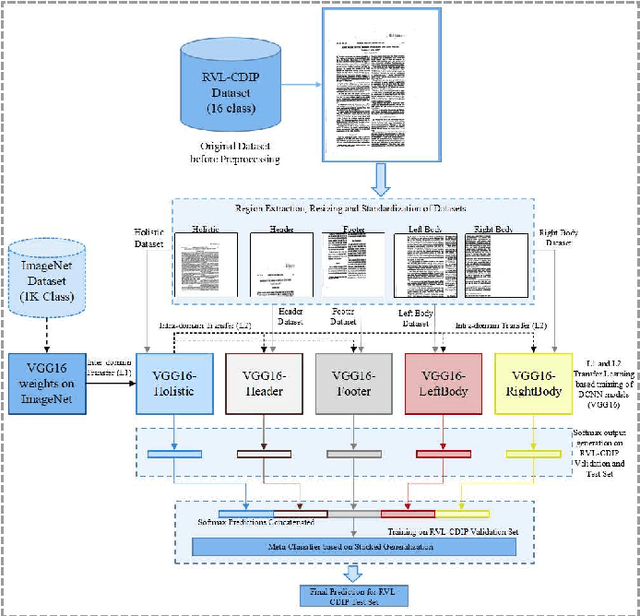
In this work, a region-based Deep Convolutional Neural Network framework is proposed for document structure learning. The contribution of this work involves efficient training of region based classifiers and effective ensembling for document image classification. A primary level of `inter-domain' transfer learning is used by exporting weights from a pre-trained VGG16 architecture on the ImageNet dataset to train a document classifier on whole document images. Exploiting the nature of region based influence modelling, a secondary level of `intra-domain' transfer learning is used for rapid training of deep learning models for image segments. Finally, stacked generalization based ensembling is utilized for combining the predictions of the base deep neural network models. The proposed method achieves state-of-the-art accuracy of 92.2% on the popular RVL-CDIP document image dataset, exceeding benchmarks set by existing algorithms.
MLMA-Net: multi-level multi-attentional learning for multi-label object detection in textile defect images
Jan 31, 2021

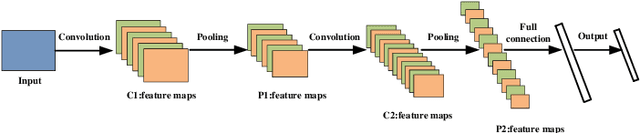
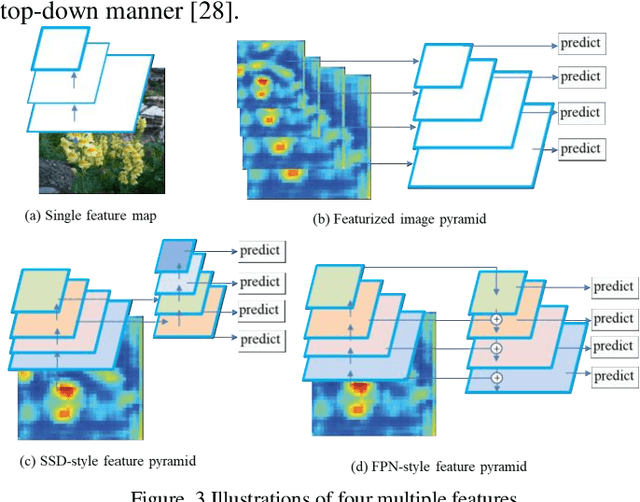
For the sake of recognizing and classifying textile defects, deep learning-based methods have been proposed and achieved remarkable success in single-label textile images. However, detecting multi-label defects in a textile image remains challenging due to the coexistence of multiple defects and small-size defects. To address these challenges, a multi-level, multi-attentional deep learning network (MLMA-Net) is proposed and built to 1) increase the feature representation ability to detect small-size defects; 2) generate a discriminative representation that maximizes the capability of attending the defect status, which leverages higher-resolution feature maps for multiple defects. Moreover, a multi-label object detection dataset (DHU-ML1000) in textile defect images is built to verify the performance of the proposed model. The results demonstrate that the network extracts more distinctive features and has better performance than the state-of-the-art approaches on the real-world industrial dataset.
Latent World Models For Intrinsically Motivated Exploration
Oct 05, 2020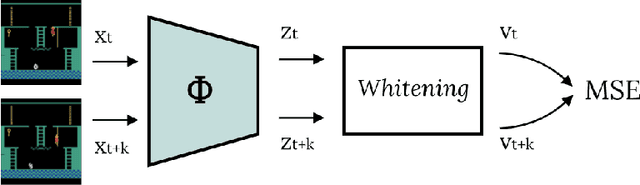
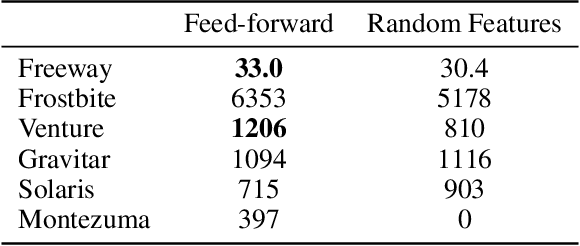
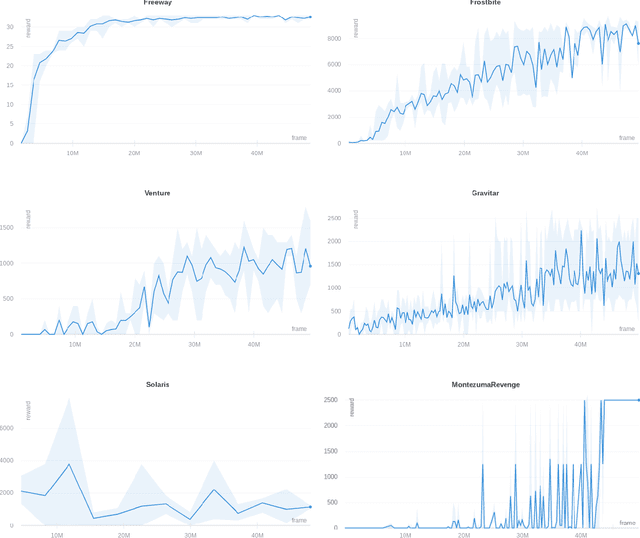
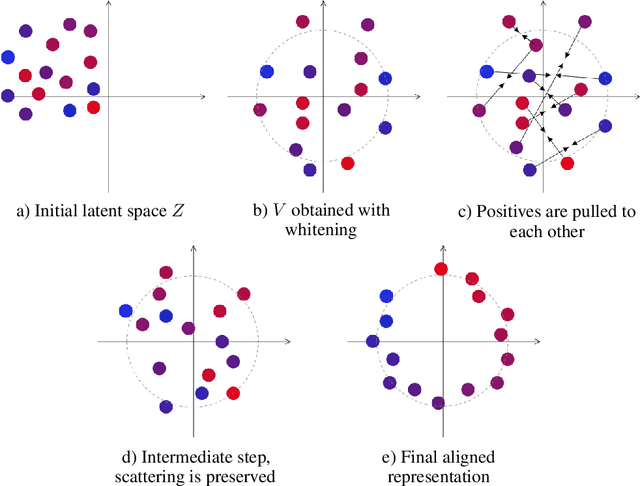
In this work we consider partially observable environments with sparse rewards. We present a self-supervised representation learning method for image-based observations, which arranges embeddings respecting temporal distance of observations. This representation is empirically robust to stochasticity and suitable for novelty detection from the error of a predictive forward model. We consider episodic and life-long uncertainties to guide the exploration. We propose to estimate the missing information about the environment with the world model, which operates in the learned latent space. As a motivation of the method, we analyse the exploration problem in a tabular Partially Observable Labyrinth. We demonstrate the method on image-based hard exploration environments from the Atari benchmark and report significant improvement with respect to prior work. The source code of the method and all the experiments is available at https://github.com/htdt/lwm.
Attending Category Disentangled Global Context for Image Classification
Dec 17, 2018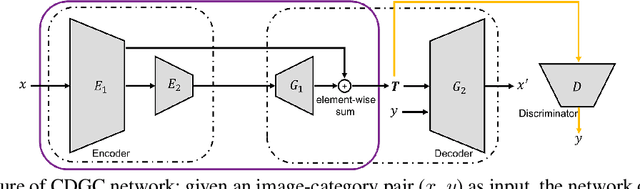
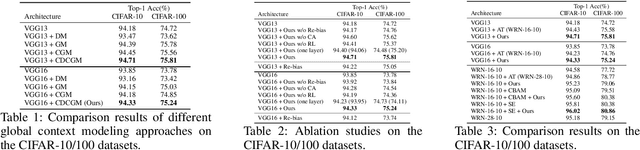
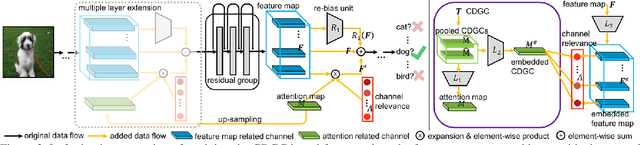
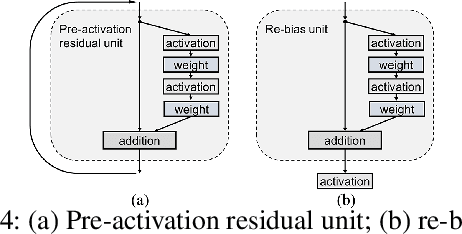
In this paper, we propose a general framework for image classification using the attention mechanism and global context, which could incorporate with various network architectures to improve their performance. To investigate the capability of the global context, we compare four mathematical models and observe the global context encoded in the category disentangled conditional generative model retains the richest complementary information to that in the baseline classification networks. Based on this observation, we define a novel Category Disentangled Global Context (CDGC) and devise a deep network to obtain it. By attending CDGC, the baseline networks could identify the objects of interest more accurately, thus improving the performance. We apply the framework to many different network architectures to demonstrate its effectiveness and versatility. Extensive results on four publicly available datasets validate our approach could generalize well and is superior to the state-of-the-art. In addition, the framework could be combined with various self-attention based methods to further promote the performance. Code and pretrained models will be made public upon paper acceptance.
nnU-Net: Breaking the Spell on Successful Medical Image Segmentation
Apr 17, 2019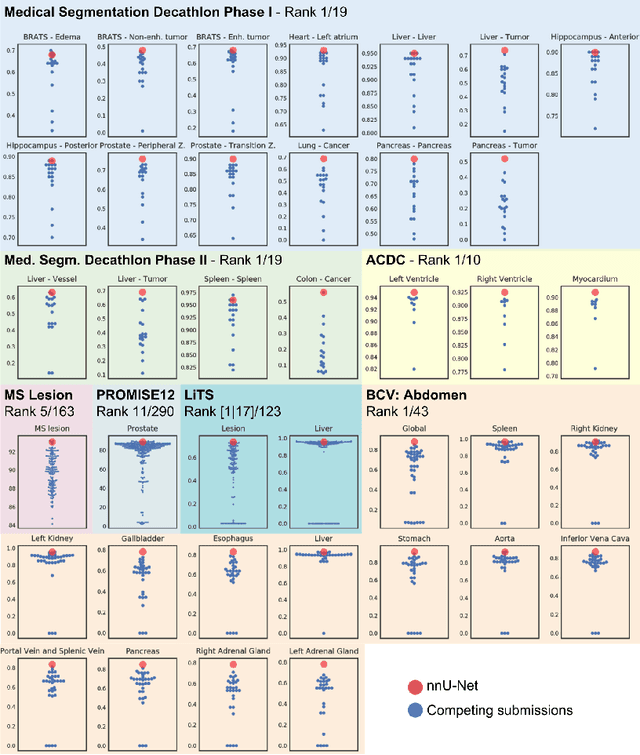

Fueled by the diversity of datasets, semantic segmentation is a popular subfield in medical image analysis with a vast number of new methods being proposed each year. This ever-growing jungle of methodologies, however, becomes increasingly impenetrable. At the same time, many proposed methods fail to generalize beyond the experiments they were demonstrated on, thus hampering the process of developing a segmentation algorithm on a new dataset. Here we present nnU-Net ('no-new-Net'), a framework that automatically adapts itself to any given new dataset. While this process was completely human-driven so far, we make a first attempt to automate necessary adaptations such as preprocessing, the exact patch size, batch size, and inference settings based on the properties of a given dataset. Remarkably, nnU-Net strips away the architectural bells and whistles that are typically proposed in the literature and relies on just a simple U-Net architecture embedded in a robust training scheme. Out of the box, nnU-Net achieves state of the art performance on six well-established segmentation challenges. Source code is available at https://github.com/MIC-DKFZ/nnunet.