 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
COMBO: Conservative Offline Model-Based Policy Optimization
Feb 16, 2021
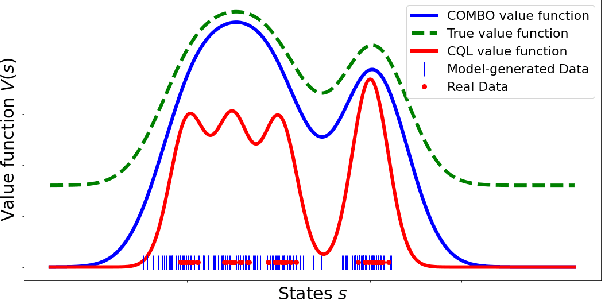
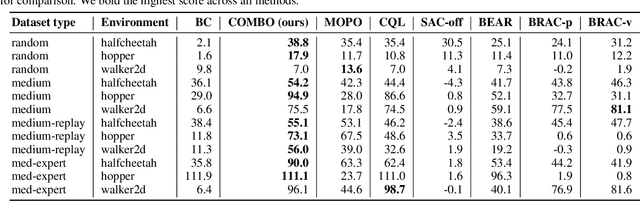
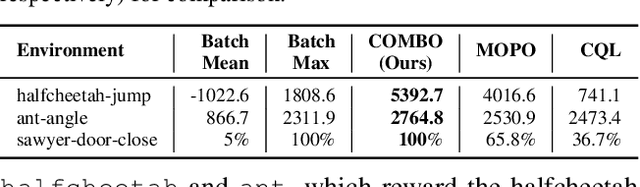

Model-based algorithms, which learn a dynamics model from logged experience and perform some sort of pessimistic planning under the learned model, have emerged as a promising paradigm for offline reinforcement learning (offline RL). However, practical variants of such model-based algorithms rely on explicit uncertainty quantification for incorporating pessimism. Uncertainty estimation with complex models, such as deep neural networks, can be difficult and unreliable. We overcome this limitation by developing a new model-based offline RL algorithm, COMBO, that regularizes the value function on out-of-support state-action tuples generated via rollouts under the learned model. This results in a conservative estimate of the value function for out-of-support state-action tuples, without requiring explicit uncertainty estimation. We theoretically show that our method optimizes a lower bound on the true policy value, that this bound is tighter than that of prior methods, and our approach satisfies a policy improvement guarantee in the offline setting. Through experiments, we find that COMBO consistently performs as well or better as compared to prior offline model-free and model-based methods on widely studied offline RL benchmarks, including image-based tasks.
Body models in humans, animals, and robots
Oct 19, 2020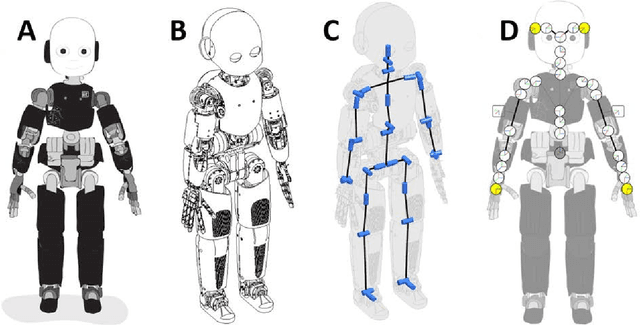

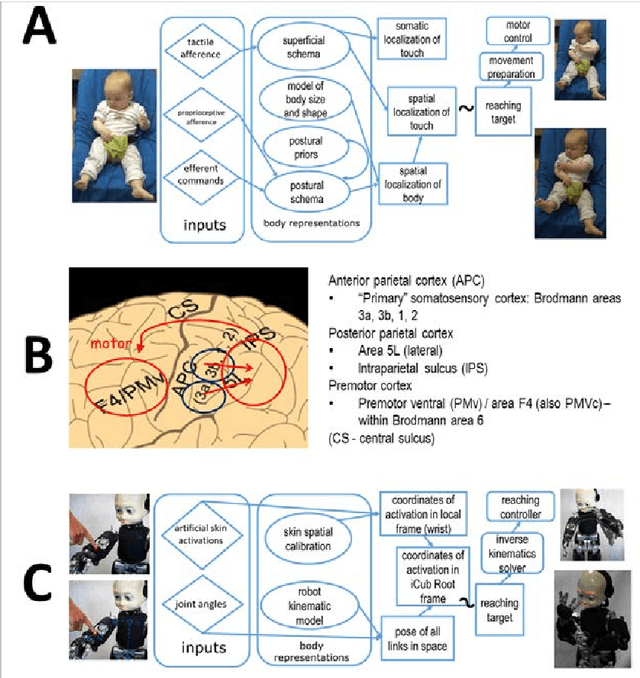
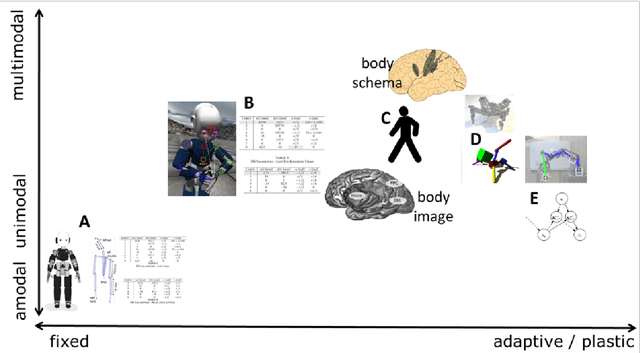
Humans and animals excel in combining information from multiple sensory modalities, controlling their complex bodies, adapting to growth, failures, or using tools. These capabilities are also highly desirable in robots. They are displayed by machines to some extent - yet, as is so often the case, the artificial creatures are lagging behind. The key foundation is an internal representation of the body that the agent - human, animal, or robot - has developed. In the biological realm, evidence has been accumulated by diverse disciplines giving rise to the concepts of body image, body schema, and others. In robotics, a model of the robot is an indispensable component that enables to control the machine. In this article I compare the character of body representations in biology with their robotic counterparts and relate that to the differences in performance that we observe. I put forth a number of axes regarding the nature of such body models: fixed vs. plastic, amodal vs. modal, explicit vs. implicit, serial vs. parallel, modular vs. holistic, and centralized vs. distributed. An interesting trend emerges: on many of the axes, there is a sequence from robot body models, over body image, body schema, to the body representation in lower animals like the octopus. In some sense, robots have a lot in common with Ian Waterman - "the man who lost his body" - in that they rely on an explicit, veridical body model (body image taken to the extreme) and lack any implicit, multimodal representation (like the body schema) of their bodies. I will then detail how robots can inform the biological sciences dealing with body representations and finally, I will study which of the features of the "body in the brain" should be transferred to robots, giving rise to more adaptive and resilient, self-calibrating machines.
Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics
Apr 05, 2020
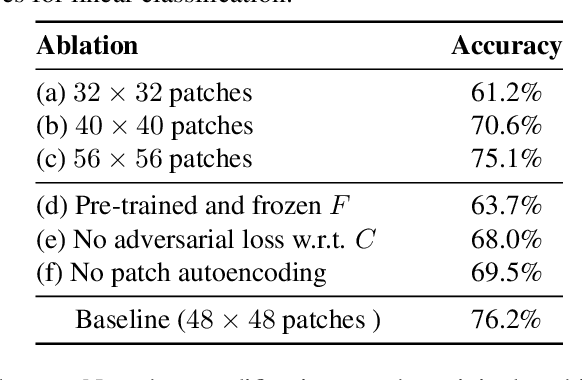

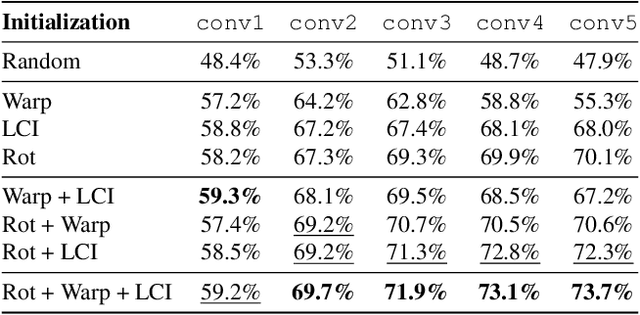
We introduce a novel principle for self-supervised feature learning based on the discrimination of specific transformations of an image. We argue that the generalization capability of learned features depends on what image neighborhood size is sufficient to discriminate different image transformations: The larger the required neighborhood size and the more global the image statistics that the feature can describe. An accurate description of global image statistics allows to better represent the shape and configuration of objects and their context, which ultimately generalizes better to new tasks such as object classification and detection. This suggests a criterion to choose and design image transformations. Based on this criterion, we introduce a novel image transformation that we call limited context inpainting (LCI). This transformation inpaints an image patch conditioned only on a small rectangular pixel boundary (the limited context). Because of the limited boundary information, the inpainter can learn to match local pixel statistics, but is unlikely to match the global statistics of the image. We claim that the same principle can be used to justify the performance of transformations such as image rotations and warping. Indeed, we demonstrate experimentally that learning to discriminate transformations such as LCI, image warping and rotations, yields features with state of the art generalization capabilities on several datasets such as Pascal VOC, STL-10, CelebA, and ImageNet. Remarkably, our trained features achieve a performance on Places on par with features trained through supervised learning with ImageNet labels.
Nonlinear Projection Based Gradient Estimation for Query Efficient Blackbox Attacks
Feb 25, 2021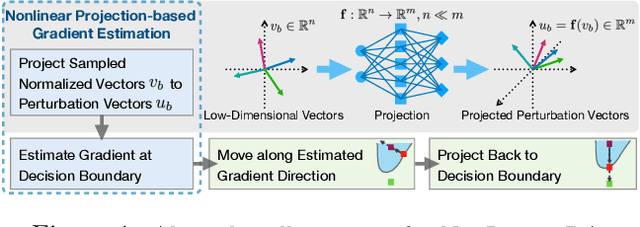

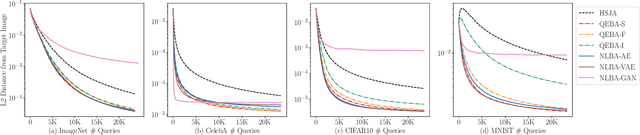
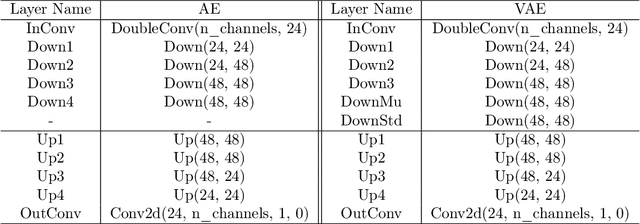
Gradient estimation and vector space projection have been studied as two distinct topics. We aim to bridge the gap between the two by investigating how to efficiently estimate gradient based on a projected low-dimensional space. We first provide lower and upper bounds for gradient estimation under both linear and nonlinear projections, and outline checkable sufficient conditions under which one is better than the other. Moreover, we analyze the query complexity for the projection-based gradient estimation and present a sufficient condition for query-efficient estimators. Built upon our theoretic analysis, we propose a novel query-efficient Nonlinear Gradient Projection-based Boundary Blackbox Attack (NonLinear-BA). We conduct extensive experiments on four image datasets: ImageNet, CelebA, CIFAR-10, and MNIST, and show the superiority of the proposed methods compared with the state-of-the-art baselines. In particular, we show that the projection-based boundary blackbox attacks are able to achieve much smaller magnitude of perturbations with 100% attack success rate based on efficient queries. Both linear and nonlinear projections demonstrate their advantages under different conditions. We also evaluate NonLinear-BA against the commercial online API MEGVII Face++, and demonstrate the high blackbox attack performance both quantitatively and qualitatively. The code is publicly available at https://github.com/AI-secure/NonLinear-BA.
Real-Time Facial Expression Emoji Masking with Convolutional Neural Networks and Homography
Dec 24, 2020



Neural network based algorithms has shown success in many applications. In image processing, Convolutional Neural Networks (CNN) can be trained to categorize facial expressions of images of human faces. In this work, we create a system that masks a student's face with a emoji of the respective emotion. Our system consists of three building blocks: face detection using Histogram of Gradients (HoG) and Support Vector Machine (SVM), facial expression categorization using CNN trained on FER2013 dataset, and finally masking the respective emoji back onto the student's face via homography estimation. (Demo: https://youtu.be/GCjtXw1y8Pw) Our results show that this pipeline is deploy-able in real-time, and is usable in educational settings.
Re-evaluating Automatic Metrics for Image Captioning
Dec 22, 2016
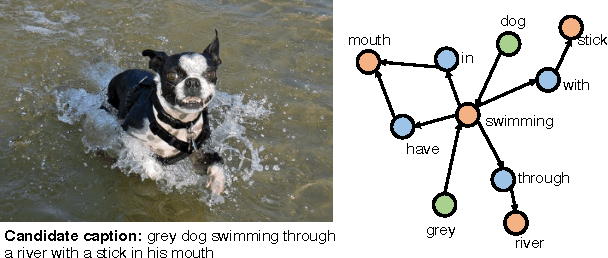
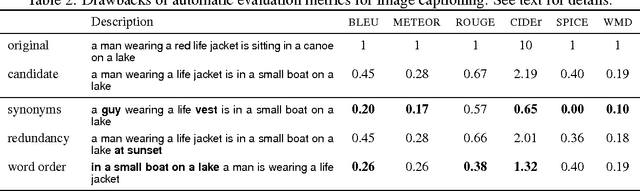
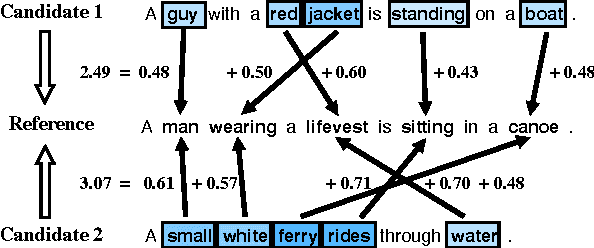
The task of generating natural language descriptions from images has received a lot of attention in recent years. Consequently, it is becoming increasingly important to evaluate such image captioning approaches in an automatic manner. In this paper, we provide an in-depth evaluation of the existing image captioning metrics through a series of carefully designed experiments. Moreover, we explore the utilization of the recently proposed Word Mover's Distance (WMD) document metric for the purpose of image captioning. Our findings outline the differences and/or similarities between metrics and their relative robustness by means of extensive correlation, accuracy and distraction based evaluations. Our results also demonstrate that WMD provides strong advantages over other metrics.
Synthetic Generation of Three-Dimensional Cancer Cell Models from Histopathological Images
Jan 26, 2021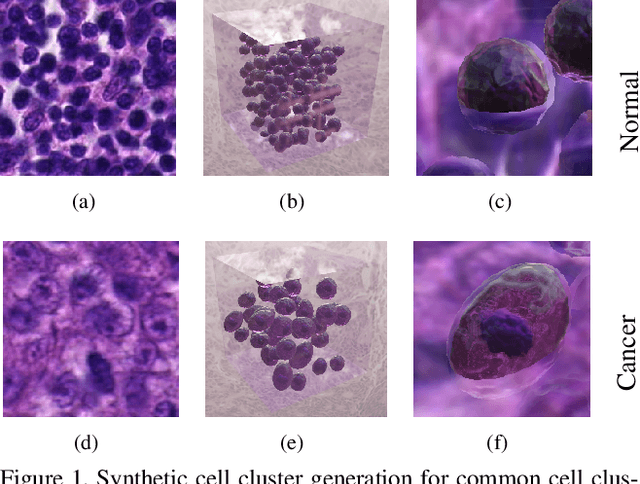
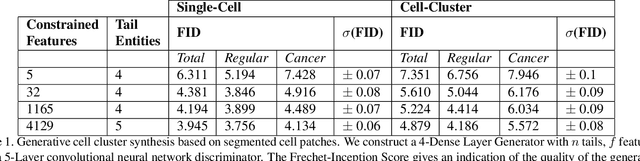
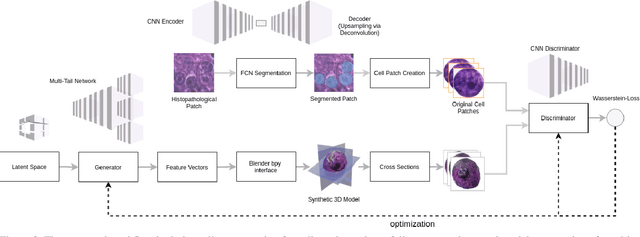
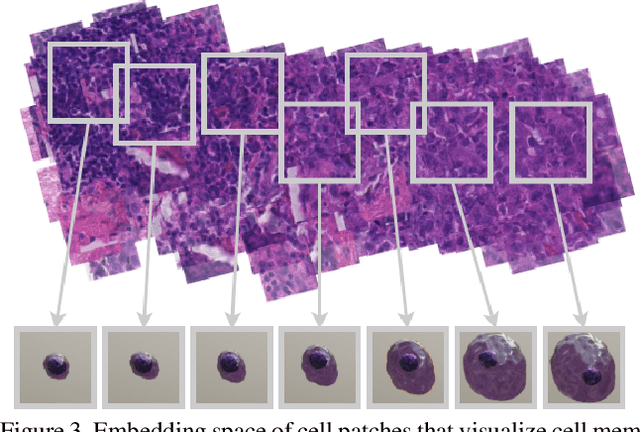
Synthetic generation of three-dimensional cell models from histopathological images enables an enhanced understanding of cell mutation, spatial context, and progression of cancer, necessary for clinical assessment and optimal treatment. Classical reconstruction algorithms based on image registration of consecutive slides of stained tissues are prone to errors and often not suitable for the training of three-dimensional segmentation algorithms. We propose a novel framework to generate synthetic three-dimensional histological models based on a generator-discriminator pattern optimizing constrained features that construct a 3D model via a blender interface exploiting smooth shape continuity typical for biological specimens. Simultaneously a discriminator is trained to distinguish between the original cell patches and projections of the three-dimensional model. To capture the spatial context of entire cell clusters we deploy a similar architecture expanded by style transfer capability. Models based on clusters of adjoined embedding points are generated to analyze the characteristic cell mutation process of breast cancer.
Learning a Dilated Residual Network for SAR Image Despeckling
Jan 24, 2018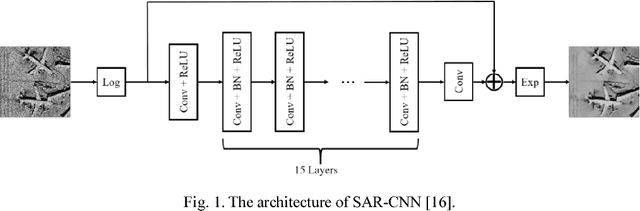
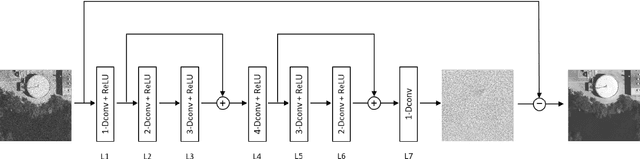
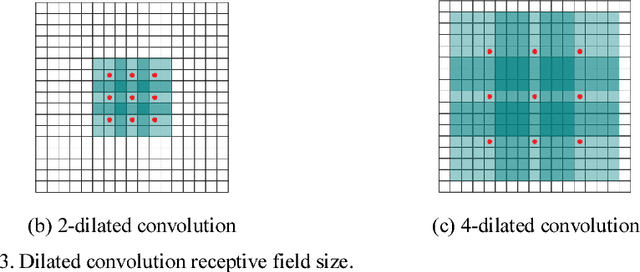
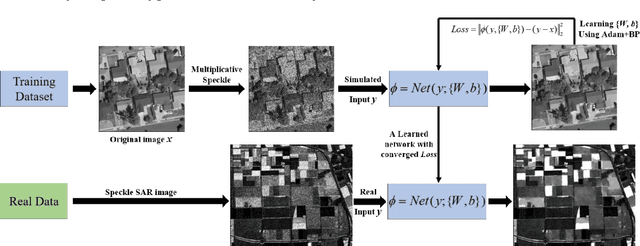
In this paper, to break the limit of the traditional linear models for synthetic aperture radar (SAR) image despeckling, we propose a novel deep learning approach by learning a non-linear end-to-end mapping between the noisy and clean SAR images with a dilated residual network (SAR-DRN). SAR-DRN is based on dilated convolutions, which can both enlarge the receptive field and maintain the filter size and layer depth with a lightweight structure. In addition, skip connections and residual learning strategy are added to the despeckling model to maintain the image details and reduce the vanishing gradient problem. Compared with the traditional despeckling methods, the proposed method shows superior performance over the state-of-the-art methods on both quantitative and visual assessments, especially for strong speckle noise.
Image Inpainting using Block-wise Procedural Training with Annealed Adversarial Counterpart
Mar 28, 2018

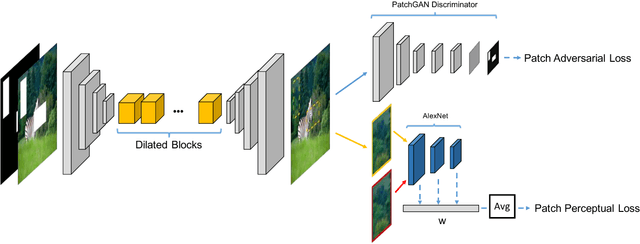
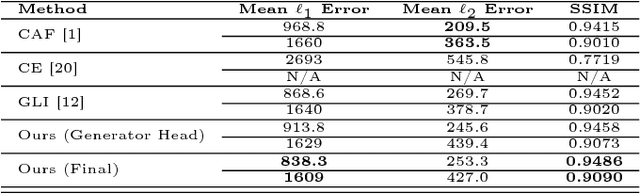
Recent advances in deep generative models have shown promising potential in image inpanting, which refers to the task of predicting missing pixel values of an incomplete image using the known context. However, existing methods can be slow or generate unsatisfying results with easily detectable flaws. In addition, there is often perceivable discontinuity near the holes and require further post-processing to blend the results. We present a new approach to address the difficulty of training a very deep generative model to synthesize high-quality photo-realistic inpainting. Our model uses conditional generative adversarial networks (conditional GANs) as the backbone, and we introduce a novel block-wise procedural training scheme to stabilize the training while we increase the network depth. We also propose a new strategy called adversarial loss annealing to reduce the artifacts. We further describe several losses specifically designed for inpainting and show their effectiveness. Extensive experiments and user-study show that our approach outperforms existing methods in several tasks such as inpainting, face completion and image harmonization. Finally, we show our framework can be easily used as a tool for interactive guided inpainting, demonstrating its practical value to solve common real-world challenges.
Towards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Jan 26, 2021
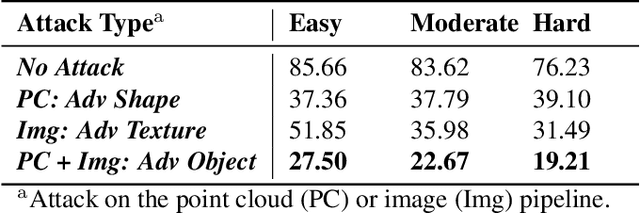
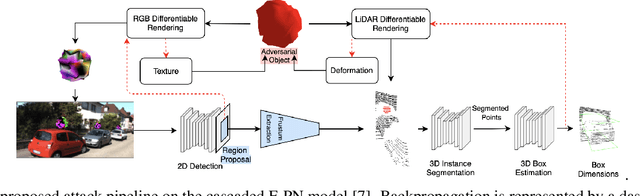
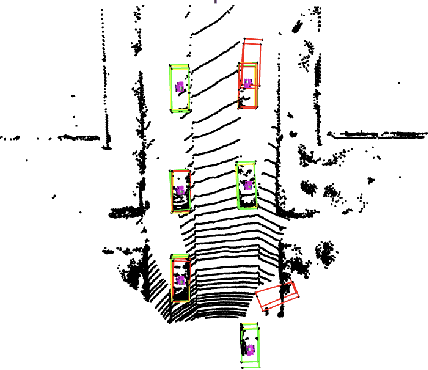
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.