 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition
Jan 21, 2021

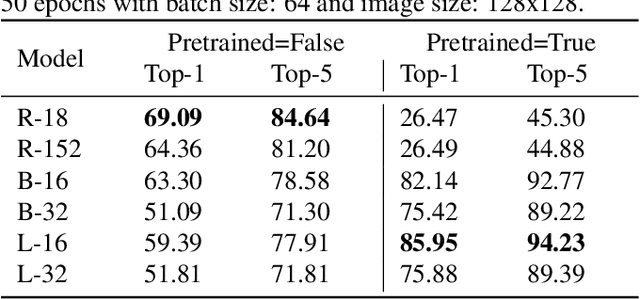
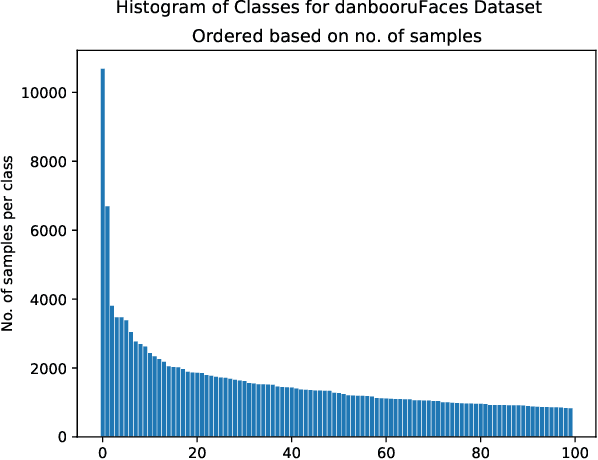
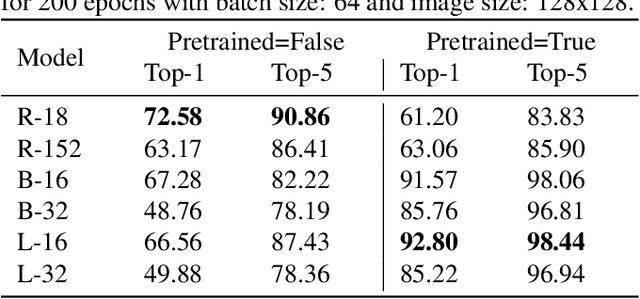
In this work we tackle the challenging problem of anime character recognition. Anime, referring to animation produced within Japan and work derived or inspired from it. For this purpose we present DAF:re (DanbooruAnimeFaces:revamped), a large-scale, crowd-sourced, long-tailed dataset with almost 500 K images spread across more than 3000 classes. Additionally, we conduct experiments on DAF:re and similar datasets using a variety of classification models, including CNN based ResNets and self-attention based Vision Transformer (ViT). Our results give new insights into the generalization and transfer learning properties of ViT models on substantially different domain datasets from those used for the upstream pre-training, including the influence of batch and image size in their training. Additionally, we share our dataset, source-code, pre-trained checkpoints and results, as Animesion, the first end-to-end framework for large-scale anime character recognition: https://github.com/arkel23/animesion
Regularization via deep generative models: an analysis point of view
Jan 21, 2021


This paper proposes a new way of regularizing an inverse problem in imaging (e.g., deblurring or inpainting) by means of a deep generative neural network. Compared to end-to-end models, such approaches seem particularly interesting since the same network can be used for many different problems and experimental conditions, as soon as the generative model is suited to the data. Previous works proposed to use a synthesis framework, where the estimation is performed on the latent vector, the solution being obtained afterwards via the decoder. Instead, we propose an analysis formulation where we directly optimize the image itself and penalize the latent vector. We illustrate the interest of such a formulation by running experiments of inpainting, deblurring and super-resolution. In many cases our technique achieves a clear improvement of the performance and seems to be more robust, in particular with respect to initialization.
GIMP-ML: Python Plugins for using Computer Vision Models in GIMP
Apr 27, 2020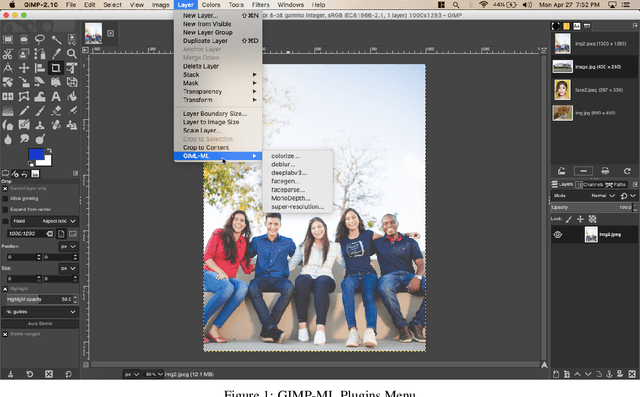
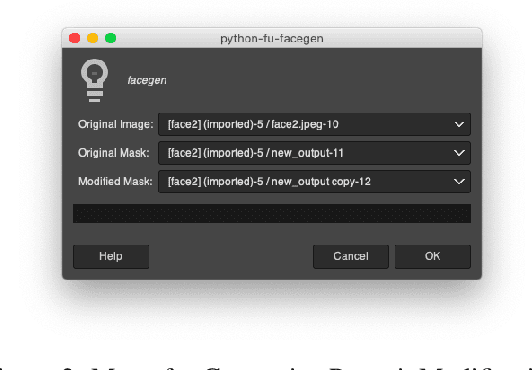
This paper introduces GIMP-ML, a set of Python plugins for the widely popular GNU Image Manipulation Program (GIMP). It enables the use of recent advances in computer vision to the conventional image editing pipeline in an open-source setting. Applications from deep learning such as monocular depth estimation, semantic segmentation, mask generative adversarial networks, image super-resolution, de-noising and coloring have been incorporated with GIMP through Python-based plugins. Additionally, operations on images such as edge detection and color clustering have also been added. GIMP-ML relies on standard Python packages such as numpy, scikit-image, pillow, pytorch, open-cv, scipy. Apart from these, several image manipulation techniques using these plugins have been compiled and demonstrated in the YouTube playlist (https://www.youtube.com/playlist?list=PLo9r5wFmpD5dLWTyo6NOiD6BJjhfEOM5t) with the objective of demonstrating the use-cases for machine learning based image modification. In addition, GIMP-ML also aims to bring the benefits of using deep learning networks used for computer vision tasks to routine image processing workflows. The code and installation procedure for configuring these plugins is available at https://github.com/kritiksoman/GIMP-ML.
ENSURE: Ensemble Stein's Unbiased Risk Estimator for Unsupervised Learning
Oct 20, 2020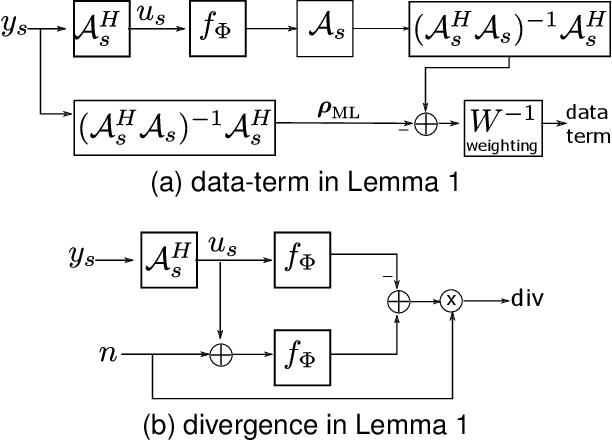
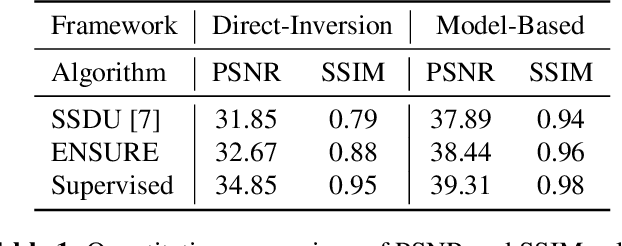
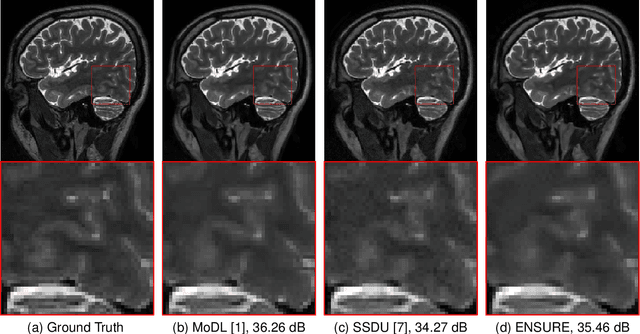
Deep learning accelerates the MR image reconstruction process after offline training of a deep neural network from a large volume of clean and fully sampled data. Unfortunately, fully sampled images may not be available or are difficult to acquire in several application areas such as high-resolution imaging. Previous studies have utilized Stein's Unbiased Risk Estimator (SURE) as a mean square error (MSE) estimate for the image denoising problem. Unrolled reconstruction algorithms, where the denoiser at each iteration is trained using SURE, has also been introduced. Unfortunately, the end-to-end training of a network using SURE remains challenging since the projected SURE loss is a poor approximation to the MSE, especially in the heavily undersampled setting. We propose an ENsemble SURE (ENSURE) approach to train a deep network only from undersampled measurements. In particular, we show that training a network using an ensemble of images, each acquired with a different sampling pattern, can closely approximate the MSE. Our preliminary experimental results show that the proposed ENSURE approach gives comparable reconstruction quality to supervised learning and a recent unsupervised learning method.
Joint super-resolution and synthesis of 1 mm isotropic MP-RAGE volumes from clinical MRI exams with scans of different orientation, resolution and contrast
Dec 24, 2020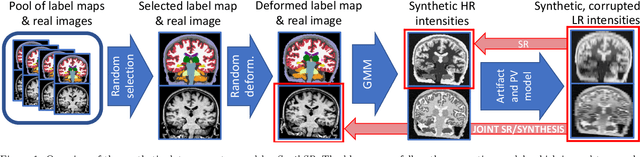

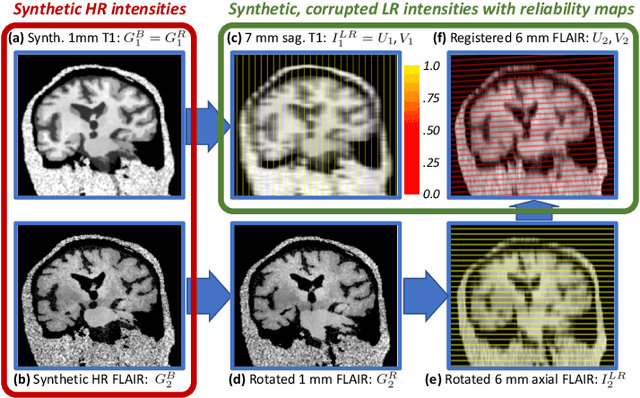
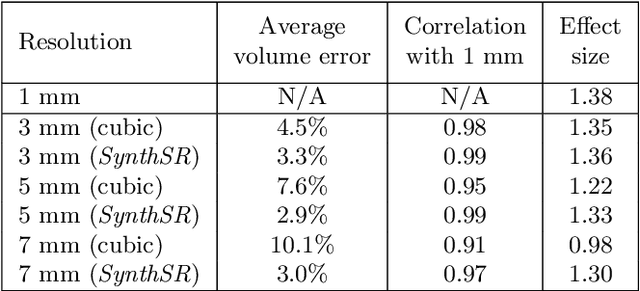
Most existing algorithms for automatic 3D morphometry of human brain MRI scans are designed for data with near-isotropic voxels at approximately 1 mm resolution, and frequently have contrast constraints as well - typically requiring T1 scans (e.g., MP-RAGE). This limitation prevents the analysis of millions of MRI scans acquired with large inter-slice spacing ("thick slice") in clinical settings every year. The inability to quantitatively analyze these scans hinders the adoption of quantitative neuroimaging in healthcare, and precludes research studies that could attain huge sample sizes and hence greatly improve our understanding of the human brain. Recent advances in CNNs are producing outstanding results in super-resolution and contrast synthesis of MRI. However, these approaches are very sensitive to the contrast, resolution and orientation of the input images, and thus do not generalize to diverse clinical acquisition protocols - even within sites. Here we present SynthSR, a method to train a CNN that receives one or more thick-slice scans with different contrast, resolution and orientation, and produces an isotropic scan of canonical contrast (typically a 1 mm MP-RAGE). The presented method does not require any preprocessing, e.g., skull stripping or bias field correction. Crucially, SynthSR trains on synthetic input images generated from 3D segmentations, and can thus be used to train CNNs for any combination of contrasts, resolutions and orientations without high-resolution training data. We test the images generated with SynthSR in an array of common downstream analyses, and show that they can be reliably used for subcortical segmentation and volumetry, image registration (e.g., for tensor-based morphometry), and, if some image quality requirements are met, even cortical thickness morphometry. The source code is publicly available at github.com/BBillot/SynthSR.
Visual Place Recognition for Aerial Robotics: Exploring Accuracy-Computation Trade-off for Local Image Descriptors
Aug 01, 2019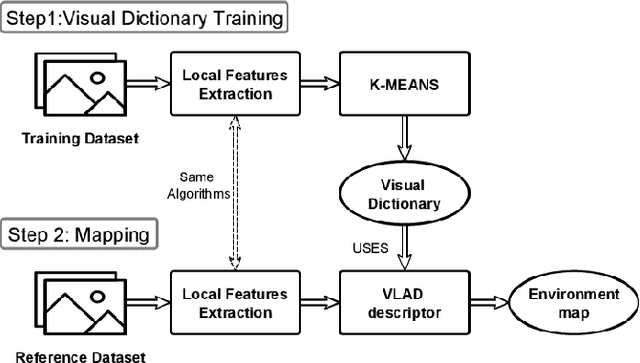
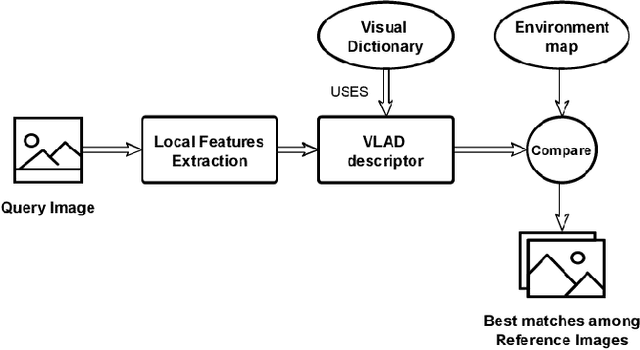


Visual Place Recognition (VPR) is a fundamental yet challenging task for small Unmanned Aerial Vehicle (UAV). The core reasons are the extreme viewpoint changes, and limited computational power onboard a UAV which restricts the applicability of robust but computation intensive state-of-the-art VPR methods. In this context, a viable approach is to use local image descriptors for performing VPR as these can be computed relatively efficiently without the need of any special hardware, such as a GPU. However, the choice of a local feature descriptor is not trivial and calls for a detailed investigation as there is a trade-off between VPR accuracy and the required computational effort. To fill this research gap, this paper examines the performance of several state-of-the-art local feature descriptors, both from accuracy and computational perspectives, specifically for VPR application utilizing standard aerial datasets. The presented results confirm that a trade-off between accuracy and computational effort is inevitable while executing VPR on resource-constrained hardware.
Edge-Labeling based Directed Gated Graph Network for Few-shot Learning
Jan 27, 2021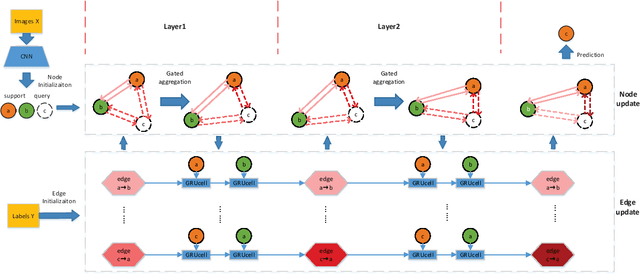
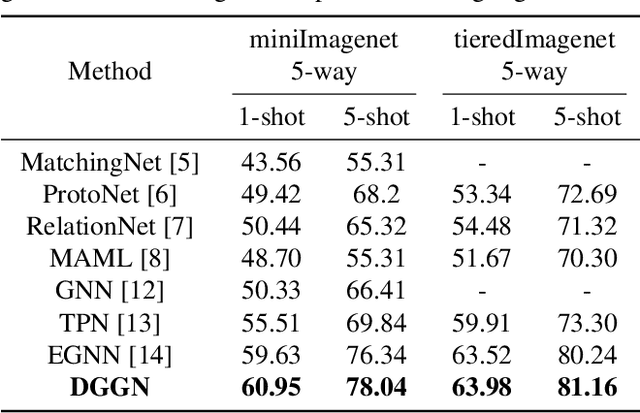
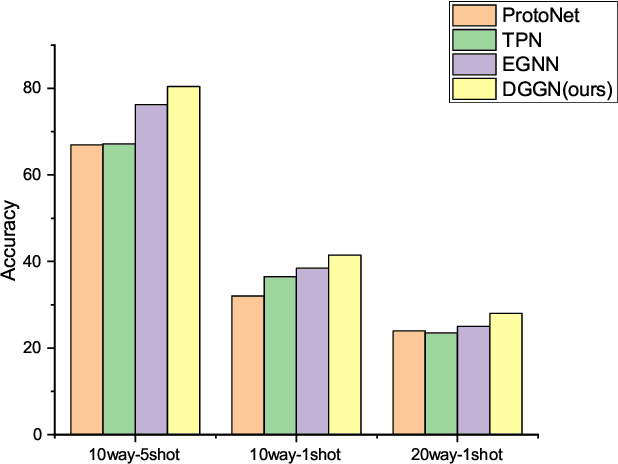
Existing graph-network-based few-shot learning methods obtain similarity between nodes through a convolution neural network (CNN). However, the CNN is designed for image data with spatial information rather than vector form node feature. In this paper, we proposed an edge-labeling-based directed gated graph network (DGGN) for few-shot learning, which utilizes gated recurrent units to implicitly update the similarity between nodes. DGGN is composed of a gated node aggregation module and an improved gated recurrent unit (GRU) based edge update module. Specifically, the node update module adopts a gate mechanism using activation of edge feature, making a learnable node aggregation process. Besides, improved GRU cells are employed in the edge update procedure to compute the similarity between nodes. Further, this mechanism is beneficial to gradient backpropagation through the GRU sequence across layers. Experiment results conducted on two benchmark datasets show that our DGGN achieves a comparable performance to the-state-of-art methods.
SDF-SRN: Learning Signed Distance 3D Object Reconstruction from Static Images
Oct 20, 2020
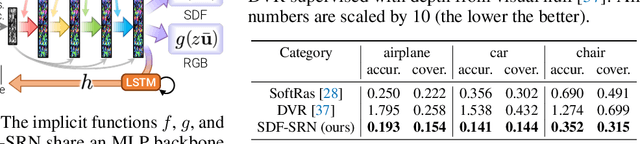
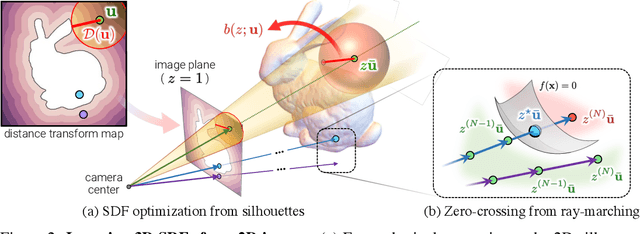
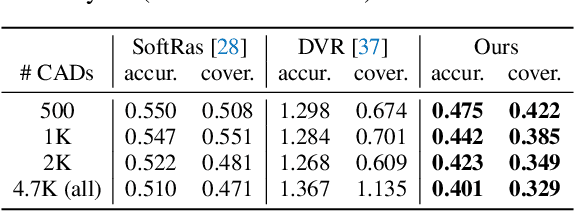
Dense 3D object reconstruction from a single image has recently witnessed remarkable advances, but supervising neural networks with ground-truth 3D shapes is impractical due to the laborious process of creating paired image-shape datasets. Recent efforts have turned to learning 3D reconstruction without 3D supervision from RGB images with annotated 2D silhouettes, dramatically reducing the cost and effort of annotation. These techniques, however, remain impractical as they still require multi-view annotations of the same object instance during training. As a result, most experimental efforts to date have been limited to synthetic datasets. In this paper, we address this issue and propose SDF-SRN, an approach that requires only a single view of objects at training time, offering greater utility for real-world scenarios. SDF-SRN learns implicit 3D shape representations to handle arbitrary shape topologies that may exist in the datasets. To this end, we derive a novel differentiable rendering formulation for learning signed distance functions (SDF) from 2D silhouettes. Our method outperforms the state of the art under challenging single-view supervision settings on both synthetic and real-world datasets.
Centroid Transformers: Learning to Abstract with Attention
Feb 17, 2021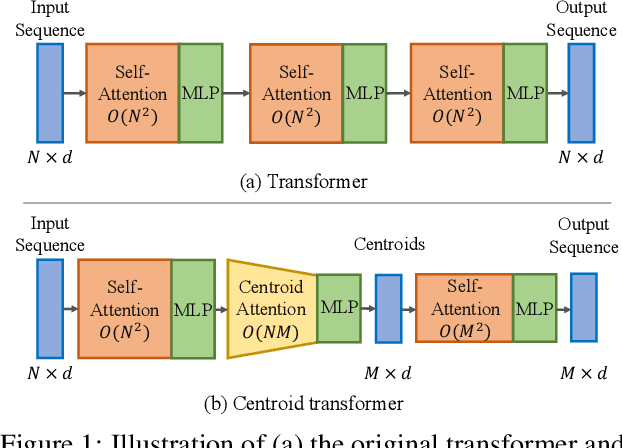

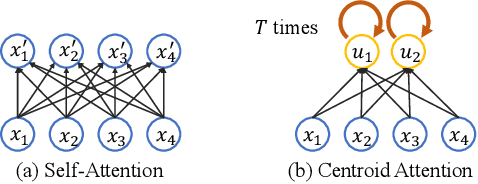
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic $O(N^2)$ memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs $(M\leq N)$, such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.
Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification
May 12, 2019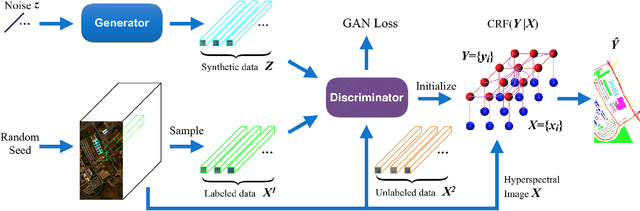
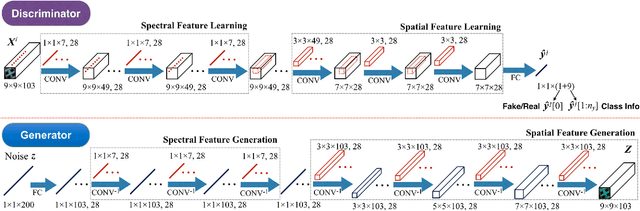
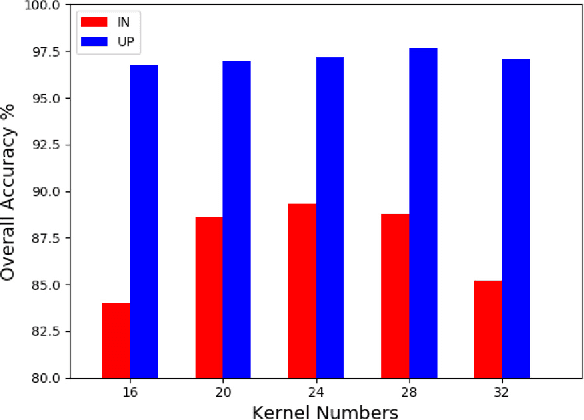
In this paper, we address the hyperspectral image (HSI) classification task with a generative adversarial network and conditional random field (GAN-CRF) -based framework, which integrates a semi-supervised deep learning and a probabilistic graphical model, and make three contributions. First, we design four types of convolutional and transposed convolutional layers that consider the characteristics of HSIs to help with extracting discriminative features from limited numbers of labeled HSI samples. Second, we construct semi-supervised GANs to alleviate the shortage of training samples by adding labels to them and implicitly reconstructing real HSI data distribution through adversarial training. Third, we build dense conditional random fields (CRFs) on top of the random variables that are initialized to the softmax predictions of the trained GANs and are conditioned on HSIs to refine classification maps. This semi-supervised framework leverages the merits of discriminative and generative models through a game-theoretical approach. Moreover, even though we used very small numbers of labeled training HSI samples from the two most challenging and extensively studied datasets, the experimental results demonstrated that spectral-spatial GAN-CRF (SS-GAN-CRF) models achieved top-ranking accuracy for semi-supervised HSI classification.