 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TräumerAI: Dreaming Music with StyleGAN
Feb 09, 2021
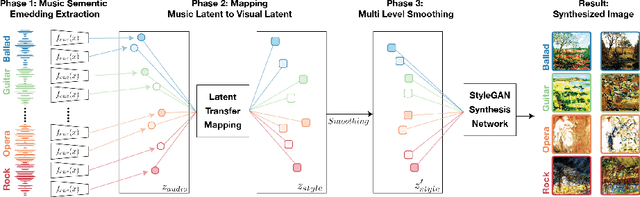


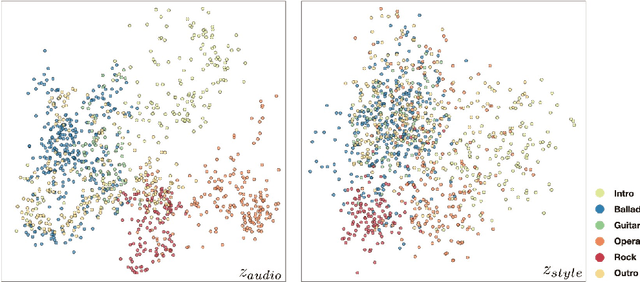
The goal of this paper to generate a visually appealing video that responds to music with a neural network so that each frame of the video reflects the musical characteristics of the corresponding audio clip. To achieve the goal, we propose a neural music visualizer directly mapping deep music embeddings to style embeddings of StyleGAN, named Tr\"aumerAI, which consists of a music auto-tagging model using short-chunk CNN and StyleGAN2 pre-trained on WikiArt dataset. Rather than establishing an objective metric between musical and visual semantics, we manually labeled the pairs in a subjective manner. An annotator listened to 100 music clips of 10 seconds long and selected an image that suits the music among the 200 StyleGAN-generated examples. Based on the collected data, we trained a simple transfer function that converts an audio embedding to a style embedding. The generated examples show that the mapping between audio and video makes a certain level of intra-segment similarity and inter-segment dissimilarity.
Webly Supervised Image Classification with Metadata: Automatic Noisy Label Correction via Visual-Semantic Graph
Oct 12, 2020
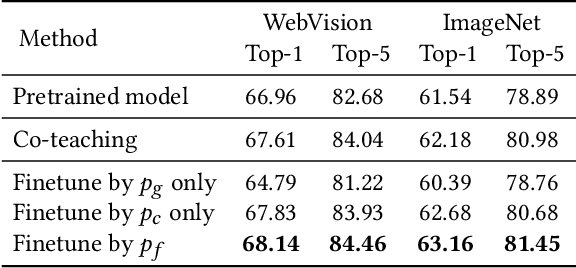
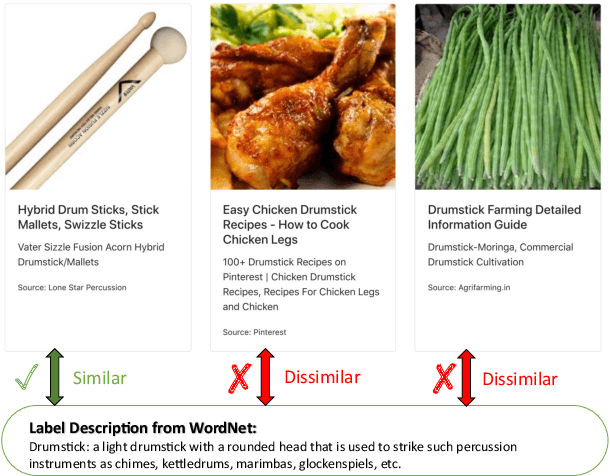
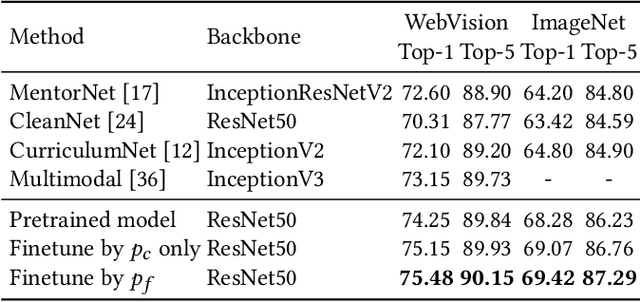
Webly supervised learning becomes attractive recently for its efficiency in data expansion without expensive human labeling. However, adopting search queries or hashtags as web labels of images for training brings massive noise that degrades the performance of DNNs. Especially, due to the semantic confusion of query words, the images retrieved by one query may contain tremendous images belonging to other concepts. For example, searching `tiger cat' on Flickr will return a dominating number of tiger images rather than the cat images. These realistic noisy samples usually have clear visual semantic clusters in the visual space that mislead DNNs from learning accurate semantic labels. To correct real-world noisy labels, expensive human annotations seem indispensable. Fortunately, we find that metadata can provide extra knowledge to discover clean web labels in a labor-free fashion, making it feasible to automatically provide correct semantic guidance among the massive label-noisy web data. In this paper, we propose an automatic label corrector VSGraph-LC based on the visual-semantic graph. VSGraph-LC starts from anchor selection referring to the semantic similarity between metadata and correct label concepts, and then propagates correct labels from anchors on a visual graph using graph neural network (GNN). Experiments on realistic webly supervised learning datasets Webvision-1000 and NUS-81-Web show the effectiveness and robustness of VSGraph-LC. Moreover, VSGraph-LC reveals its advantage on the open-set validation set.
Optical Braille Recognition Using Object Detection CNN
Dec 22, 2020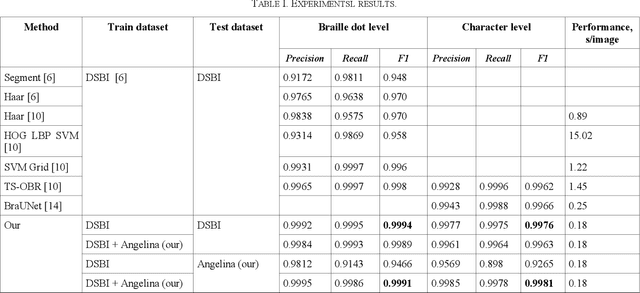
This paper proposes an optical Braille recognition method that uses an object detection convolutional neural network to detect whole Braille characters at once. The proposed algorithm is robust to the deformation of the page shown in the image and perspective distortions. It makes it usable for recognition of Braille texts being shoot on a smartphone camera, including bowed pages and perspective distorted images. The proposed algorithm shows high performance and accuracy compared to existing methods. We also introduce a new "Angelina Braille Images Dataset" containing 240 annotated photos of Braille texts. The proposed algorithm and dataset are available at GitHub.
PeR-ViS: Person Retrieval in Video Surveillance using Semantic Description
Dec 04, 2020
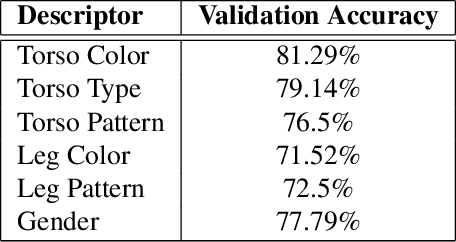
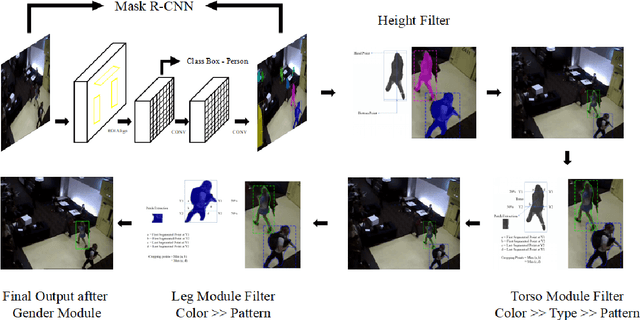
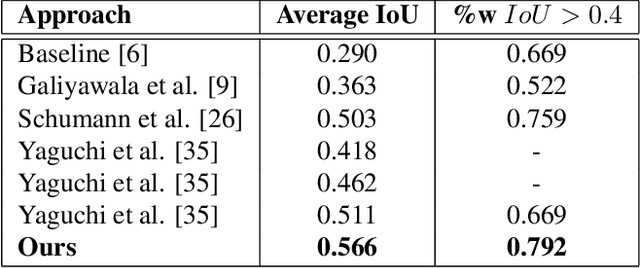
A person is usually characterized by descriptors like age, gender, height, cloth type, pattern, color, etc. Such descriptors are known as attributes and/or soft-biometrics. They link the semantic gap between a person's description and retrieval in video surveillance. Retrieving a specific person with the query of semantic description has an important application in video surveillance. Using computer vision to fully automate the person retrieval task has been gathering interest within the research community. However, the Current, trend mainly focuses on retrieving persons with image-based queries, which have major limitations for practical usage. Instead of using an image query, in this paper, we study the problem of person retrieval in video surveillance with a semantic description. To solve this problem, we develop a deep learning-based cascade filtering approach (PeR-ViS), which uses Mask R-CNN [14] (person detection and instance segmentation) and DenseNet-161 [16] (soft-biometric classification). On the standard person retrieval dataset of SoftBioSearch [6], we achieve 0.566 Average IoU and 0.792 %w $IoU > 0.4$, surpassing the current state-of-the-art by a large margin. We hope our simple, reproducible, and effective approach will help ease future research in the domain of person retrieval in video surveillance. The source code and pretrained weights available at https://parshwa1999.github.io/PeR-ViS/.
Millimeter-Wave Circular Synthetic Aperture Radar Imaging
Dec 22, 2020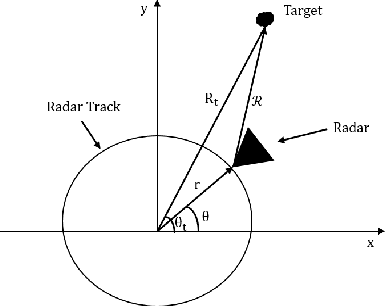
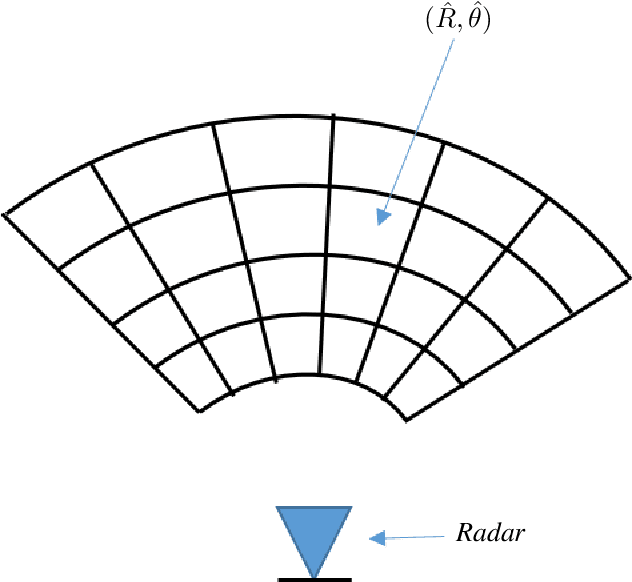

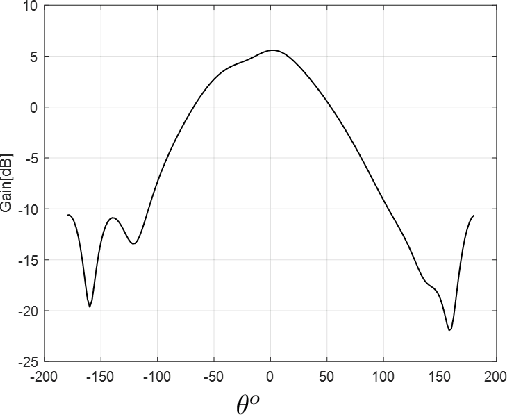
In this paper, we present a high resolution microwave imaging technique using a compact and low cost single channel Frequency Modulated Continuous Wave (FMCW) radar based on Circular Synthetic Aperture Radar (CSAR) technique. We develop an algorithm to reconstruct the image from the raw data and analyse different aspects of the system analytically. Furthermore, we discuss the differences between the proposed systems in the literature and the one presented in this work. Finally, we apply the proposed approach to the experimental data collected from a single channel FMCW radar operating at $\rm 79 \;GHz$ and present the results.
Interpretable Hyperspectral AI: When Non-Convex Modeling meets Hyperspectral Remote Sensing
Mar 02, 2021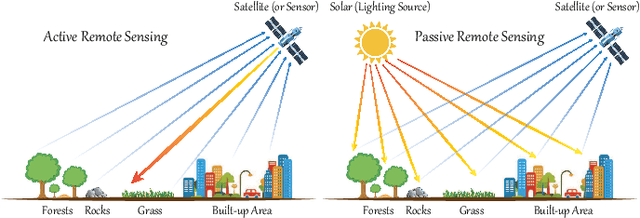

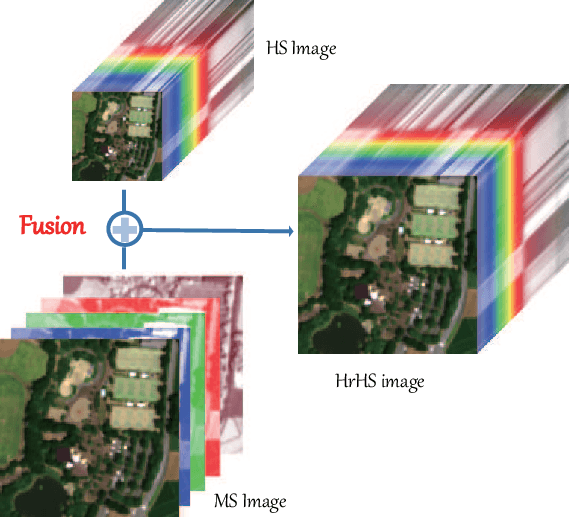

Hyperspectral imaging, also known as image spectrometry, is a landmark technique in geoscience and remote sensing (RS). In the past decade, enormous efforts have been made to process and analyze these hyperspectral (HS) products mainly by means of seasoned experts. However, with the ever-growing volume of data, the bulk of costs in manpower and material resources poses new challenges on reducing the burden of manual labor and improving efficiency. For this reason, it is, therefore, urgent to develop more intelligent and automatic approaches for various HS RS applications. Machine learning (ML) tools with convex optimization have successfully undertaken the tasks of numerous artificial intelligence (AI)-related applications. However, their ability in handling complex practical problems remains limited, particularly for HS data, due to the effects of various spectral variabilities in the process of HS imaging and the complexity and redundancy of higher dimensional HS signals. Compared to the convex models, non-convex modeling, which is capable of characterizing more complex real scenes and providing the model interpretability technically and theoretically, has been proven to be a feasible solution to reduce the gap between challenging HS vision tasks and currently advanced intelligent data processing models.
Block-Matching Convolutional Neural Network for Image Denoising
Apr 03, 2017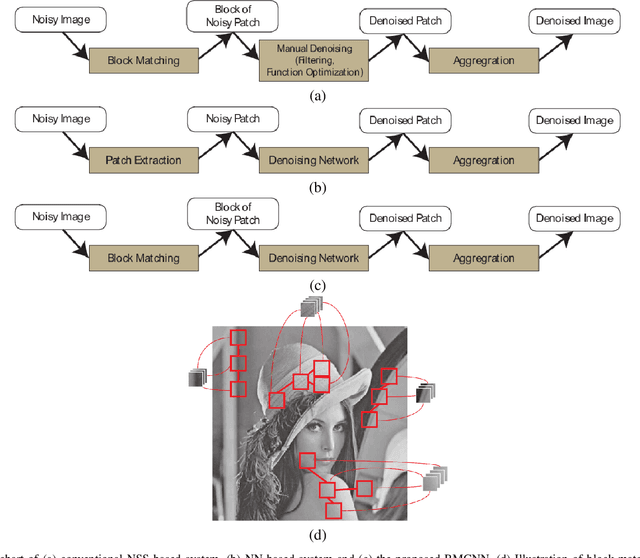
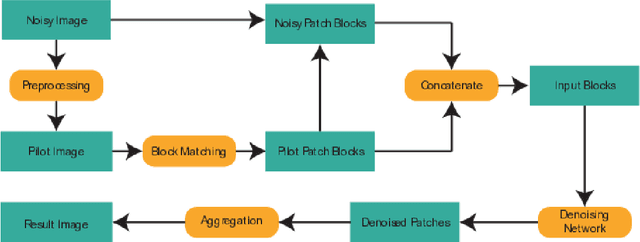
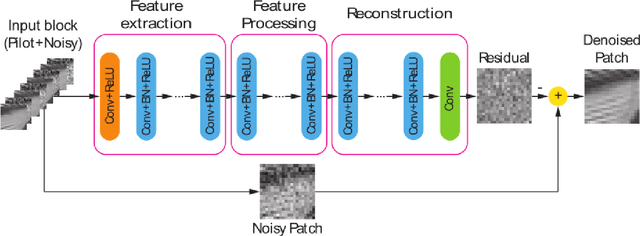

There are two main streams in up-to-date image denoising algorithms: non-local self similarity (NSS) prior based methods and convolutional neural network (CNN) based methods. The NSS based methods are favorable on images with regular and repetitive patterns while the CNN based methods perform better on irregular structures. In this paper, we propose a block-matching convolutional neural network (BMCNN) method that combines NSS prior and CNN. Initially, similar local patches in the input image are integrated into a 3D block. In order to prevent the noise from messing up the block matching, we first apply an existing denoising algorithm on the noisy image. The denoised image is employed as a pilot signal for the block matching, and then denoising function for the block is learned by a CNN structure. Experimental results show that the proposed BMCNN algorithm achieves state-of-the-art performance. In detail, BMCNN can restore both repetitive and irregular structures.
DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
Jan 28, 2021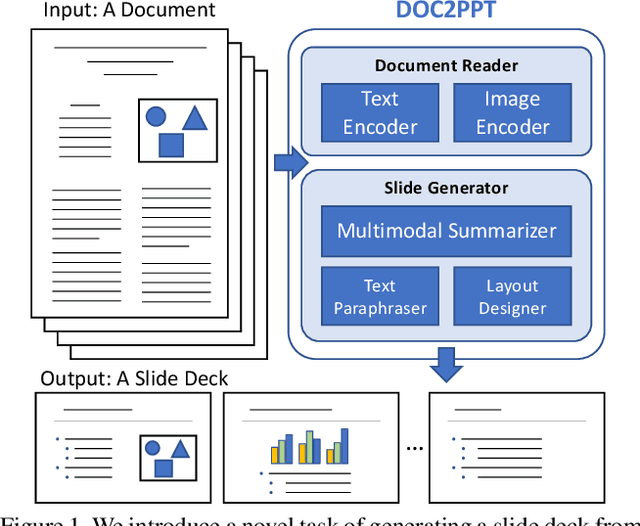

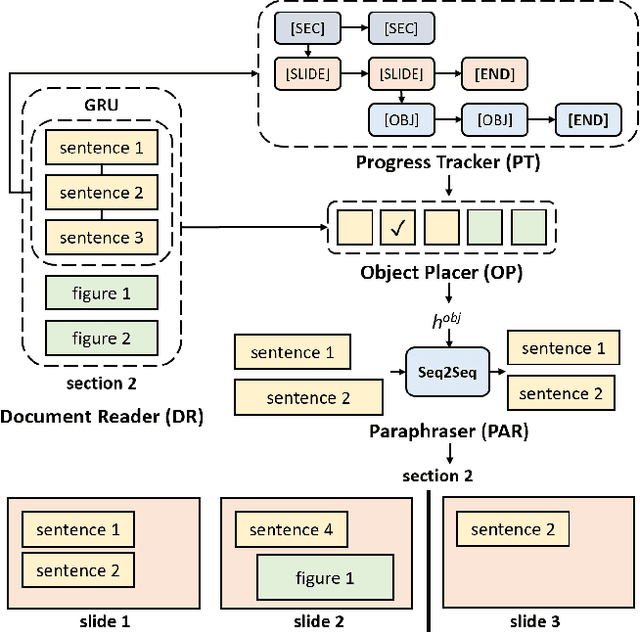
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, slide structure, and layout prediction to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
Student Mixture Model Based Visual Servoing
Jun 19, 2020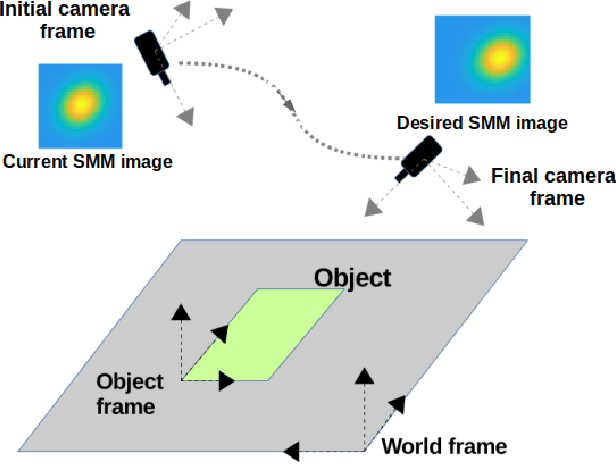
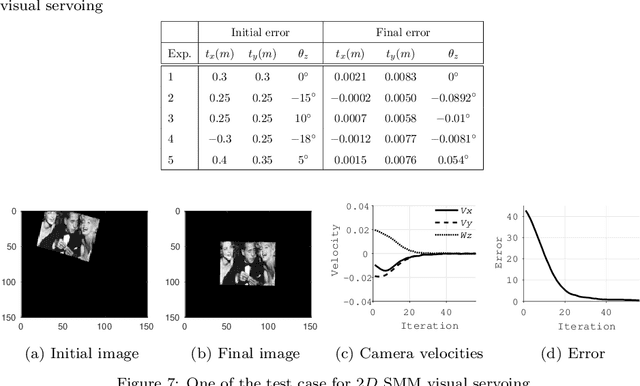
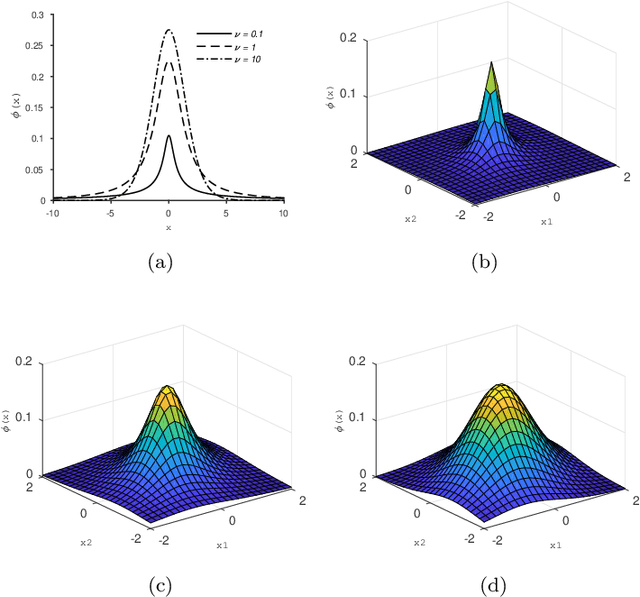
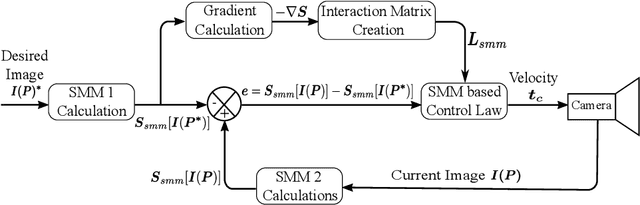
Classical Image-Based Visual Servoing (IBVS) makes use of geometric image features like point, straight line and image moments to control a robotic system. Robust extraction and real-time tracking of these features are crucial to the performance of the IBVS. Moreover, such features can be unsuitable for real world applications where it might not be easy to distinguish a target from the rest of the environment. Alternatively, an approach based on complete photometric data can avoid the requirement of feature extraction, tracking and object detection. In this work, we propose one such probabilistic model based approach which uses entire photometric data for the purpose of visual servoing. A novel image modelling method has been proposed using Student Mixture Model (SMM), which is based on Multivariate Student's t-Distribution. Consequently, a vision-based control law is formulated as a least squares minimisation problem. Efficacy of the proposed framework is demonstrated for 2D and 3D positioning tasks showing favourable error convergence and acceptable camera trajectories. Numerical experiments are also carried out to show robustness to distinct image scenes and partial occlusion.
Leveraging Visual Question Answering for Image-Caption Ranking
Aug 31, 2016
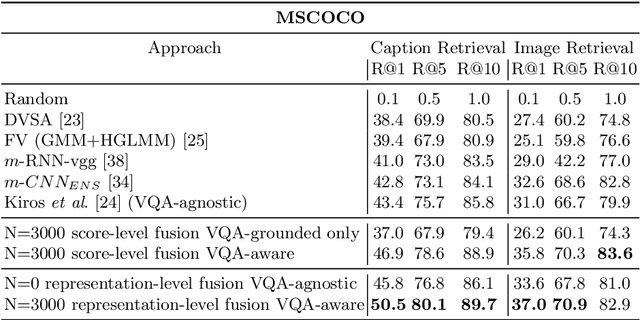


Visual Question Answering (VQA) is the task of taking as input an image and a free-form natural language question about the image, and producing an accurate answer. In this work we view VQA as a "feature extraction" module to extract image and caption representations. We employ these representations for the task of image-caption ranking. Each feature dimension captures (imagines) whether a fact (question-answer pair) could plausibly be true for the image and caption. This allows the model to interpret images and captions from a wide variety of perspectives. We propose score-level and representation-level fusion models to incorporate VQA knowledge in an existing state-of-the-art VQA-agnostic image-caption ranking model. We find that incorporating and reasoning about consistency between images and captions significantly improves performance. Concretely, our model improves state-of-the-art on caption retrieval by 7.1% and on image retrieval by 4.4% on the MSCOCO dataset.