 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Framework for Multi-class Breast Cancer Histology Image Classification
Feb 03, 2018
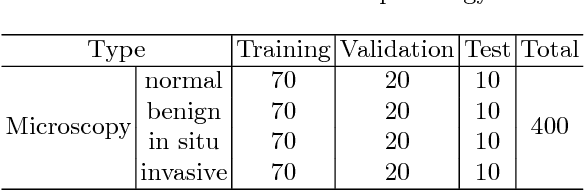

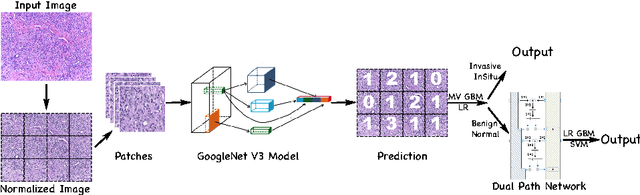
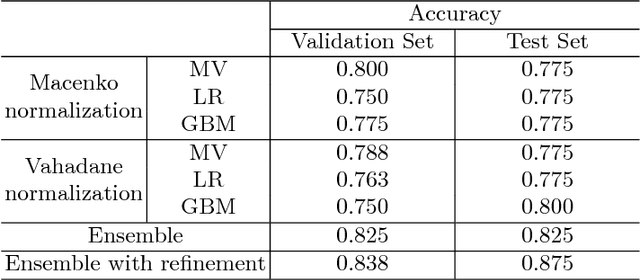
In this work, we present a deep learning framework for multi-class breast cancer image classification as our submission to the International Conference on Image Analysis and Recognition (ICIAR) 2018 Grand Challenge on BreAst Cancer Histology images (BACH). As these histology images are too large to fit into GPU memory, we first propose using Inception V3 to perform patch level classification. The patch level predictions are then passed through an ensemble fusion framework involving majority voting, gradient boosting machine (GBM), and logistic regression to obtain the image level prediction. We improve the sensitivity of the Normal and Benign predicted classes by designing a Dual Path Network (DPN) to be used as a feature extractor where these extracted features are further sent to a second layer of ensemble prediction fusion using GBM, logistic regression, and support vector machine (SVM) to refine predictions. Experimental results demonstrate our framework shows a 12.5$\%$ improvement over the state-of-the-art model.
Chest X-Rays Image Inpainting with Context Encoders
Dec 03, 2018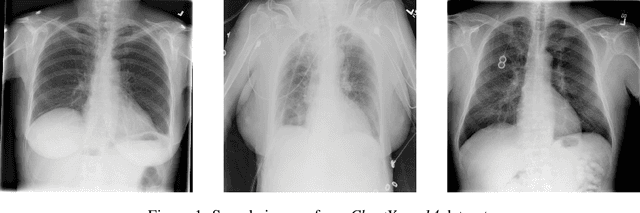

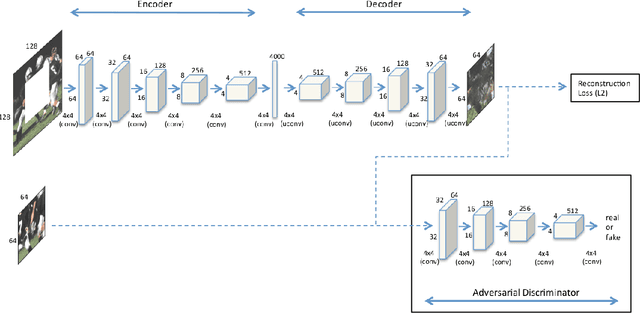
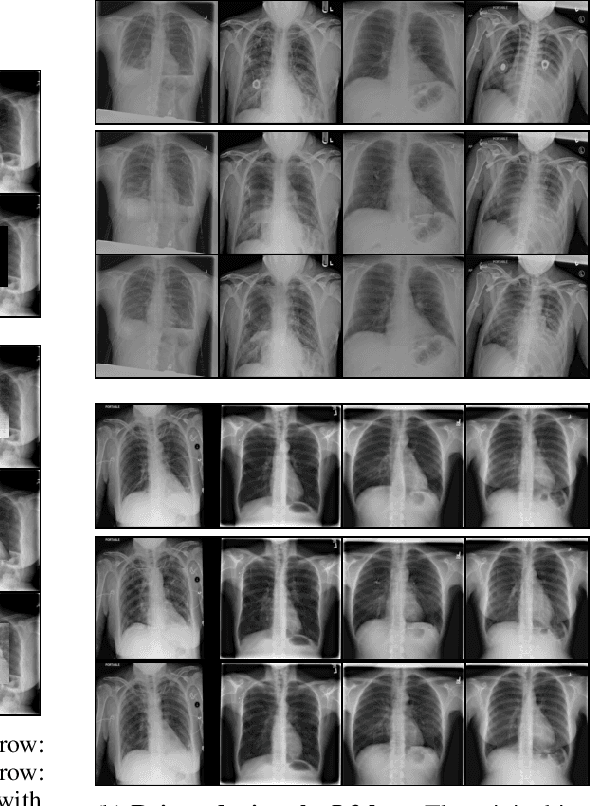
Chest X-rays are one of the most commonly used technologies for medical diagnosis. Many deep learning models have been proposed to improve and automate the abnormality detection task on this type of data. In this paper, we propose a different approach based on image inpainting under adversarial training first introduced by Goodfellow et al. We configure the context encoder model for this task and train it over 1.1M 128x128 images from healthy X-rays. The goal of our model is to reconstruct the missing central 64x64 patch. Once the model has learned how to inpaint healthy tissue, we test its performance on images with and without abnormalities. We discuss and motivate our results considering PSNR, MSE and SSIM scores as evaluation metrics. In addition, we conduct a 2AFC observer study showing that in half of the times an expert is unable to distinguish real images from the ones reconstructed using our model. By computing and visualizing the pixel-wise difference between source and reconstructed images, we can highlight abnormalities to simplify further detection and classification tasks.
Backtracking Spatial Pyramid Pooling (SPP)-based Image Classifier for Weakly Supervised Top-down Salient Object Detection
Aug 14, 2018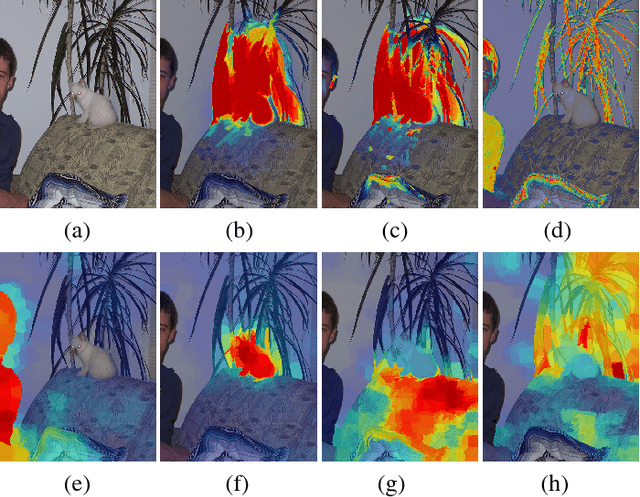
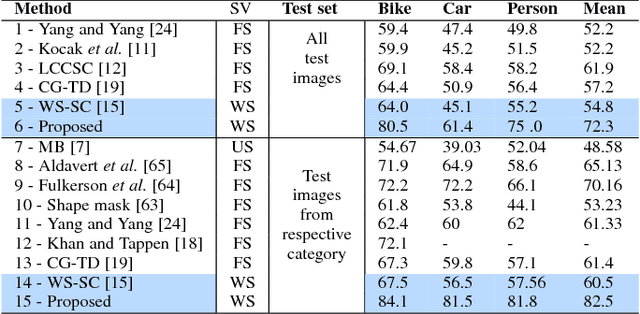


Top-down saliency models produce a probability map that peaks at target locations specified by a task/goal such as object detection. They are usually trained in a fully supervised setting involving pixel-level annotations of objects. We propose a weakly supervised top-down saliency framework using only binary labels that indicate the presence/absence of an object in an image. First, the probabilistic contribution of each image region to the confidence of a CNN-based image classifier is computed through a backtracking strategy to produce top-down saliency. From a set of saliency maps of an image produced by fast bottom-up saliency approaches, we select the best saliency map suitable for the top-down task. The selected bottom-up saliency map is combined with the top-down saliency map. Features having high combined saliency are used to train a linear SVM classifier to estimate feature saliency. This is integrated with combined saliency and further refined through a multi-scale superpixel-averaging of saliency map. We evaluate the performance of the proposed weakly supervised topdown saliency and achieve comparable performance with fully supervised approaches. Experiments are carried out on seven challenging datasets and quantitative results are compared with 40 closely related approaches across 4 different applications.
* 14 pages, 7 figures
Benchmarking Perturbation-based Saliency Maps for Explaining Deep Reinforcement Learning Agents
Jan 18, 2021
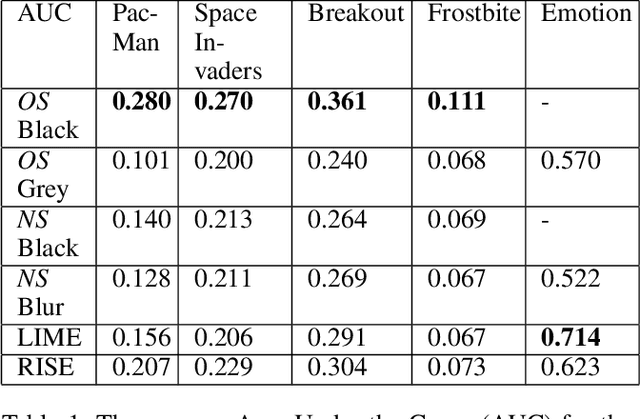

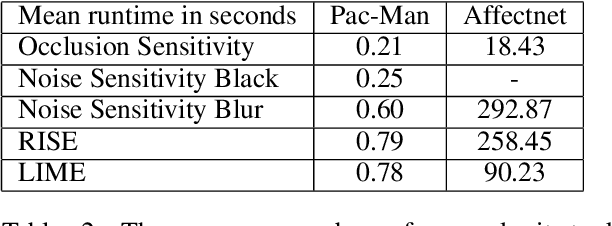
Recent years saw a plethora of work on explaining complex intelligent agents. One example is the development of several algorithms that generate saliency maps which show how much each pixel attributed to the agents' decision. However, most evaluations of such saliency maps focus on image classification tasks. As far as we know, there is no work which thoroughly compares different saliency maps for Deep Reinforcement Learning agents. This paper compares four perturbation-based approaches to create saliency maps for Deep Reinforcement Learning agents trained on four different Atari 2600 games. All four approaches work by perturbing parts of the input and measuring how much this affects the agent's output. The approaches are compared using three computational metrics: dependence on the learned parameters of the agent (sanity checks), faithfulness to the agent's reasoning (input degradation), and run-time.
Audiovisual Highlight Detection in Videos
Feb 11, 2021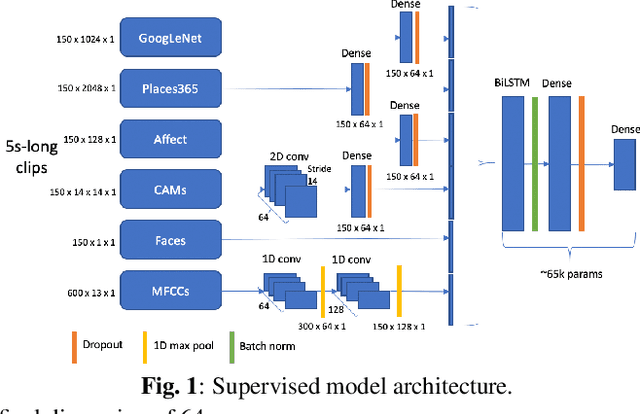
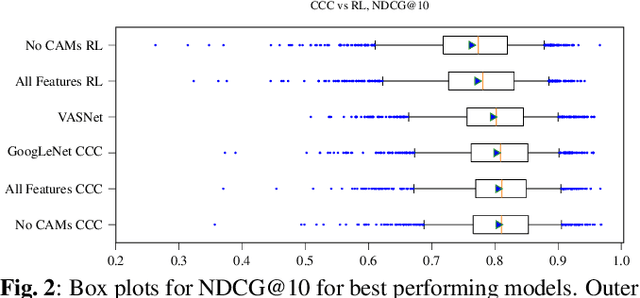
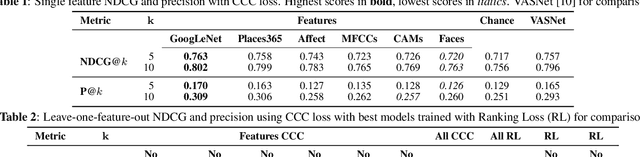
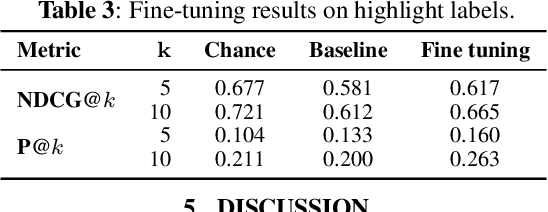
In this paper, we test the hypothesis that interesting events in unstructured videos are inherently audiovisual. We combine deep image representations for object recognition and scene understanding with representations from an audiovisual affect recognition model. To this set, we include content agnostic audio-visual synchrony representations and mel-frequency cepstral coefficients to capture other intrinsic properties of audio. These features are used in a modular supervised model. We present results from two experiments: efficacy study of single features on the task, and an ablation study where we leave one feature out at a time. For the video summarization task, our results indicate that the visual features carry most information, and including audiovisual features improves over visual-only information. To better study the task of highlight detection, we run a pilot experiment with highlights annotations for a small subset of video clips and fine-tune our best model on it. Results indicate that we can transfer knowledge from the video summarization task to a model trained specifically for the task of highlight detection.
C3VQG: Category Consistent Cyclic Visual Question Generation
May 27, 2020
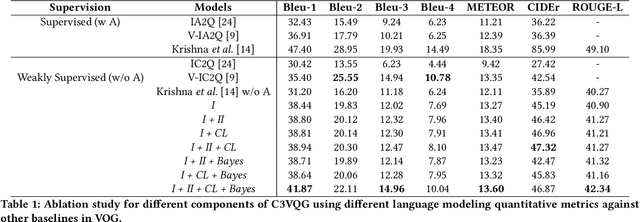
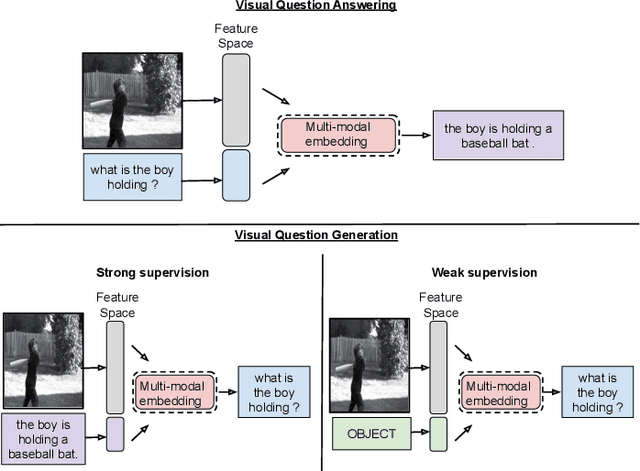
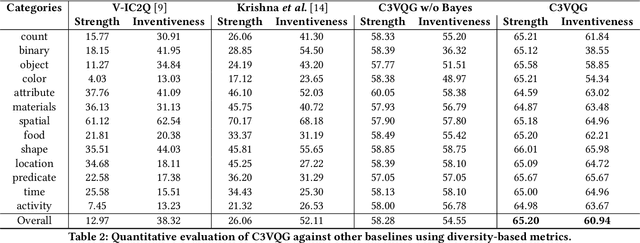
Visual Question Generation (VQG) is the task of generating natural questions based on an image. Popular methods in the past have explored image-to-sequence architectures trained with maximum likelihood which have demonstrated meaningful generated questions given an image and its associated ground-truth answer. VQG becomes more challenging if the image contains rich context information describing its different semantic categories. In this paper, we try to exploit the different visual cues and concepts in an image to generate questions using a variational autoencoder (VAE) without ground-truth answers. Our approach solves two major shortcomings of existing VQG systems: (i) minimize the level of supervision and (ii) replace generic questions with category relevant generations. Most importantly, through eliminating expensive answer annotations, the required supervision is weakened. Using different categories enables us to exploit different concepts as the inference requires only the image and category. Mutual information is maximized between the image, question, and answer category in the latent space of our VAE. A novel category consistent cyclic loss is proposed to enable the model to generate consistent predictions with respect to the answer category, reducing its redundancies and irregularities. Additionally, we also impose supplementary constraints on the latent space of our generative model to provide structure based on categories and enhance generalization by encapsulating decorrelated features within each dimension. Through extensive experiments, the proposed C3VQG outperforms the state-of-the-art visual question generation methods with weak supervision.
CLEVR Parser: A Graph Parser Library for Geometric Learning on Language Grounded Image Scenes
Oct 01, 2020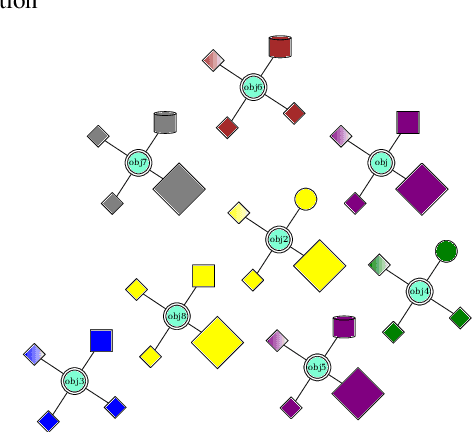

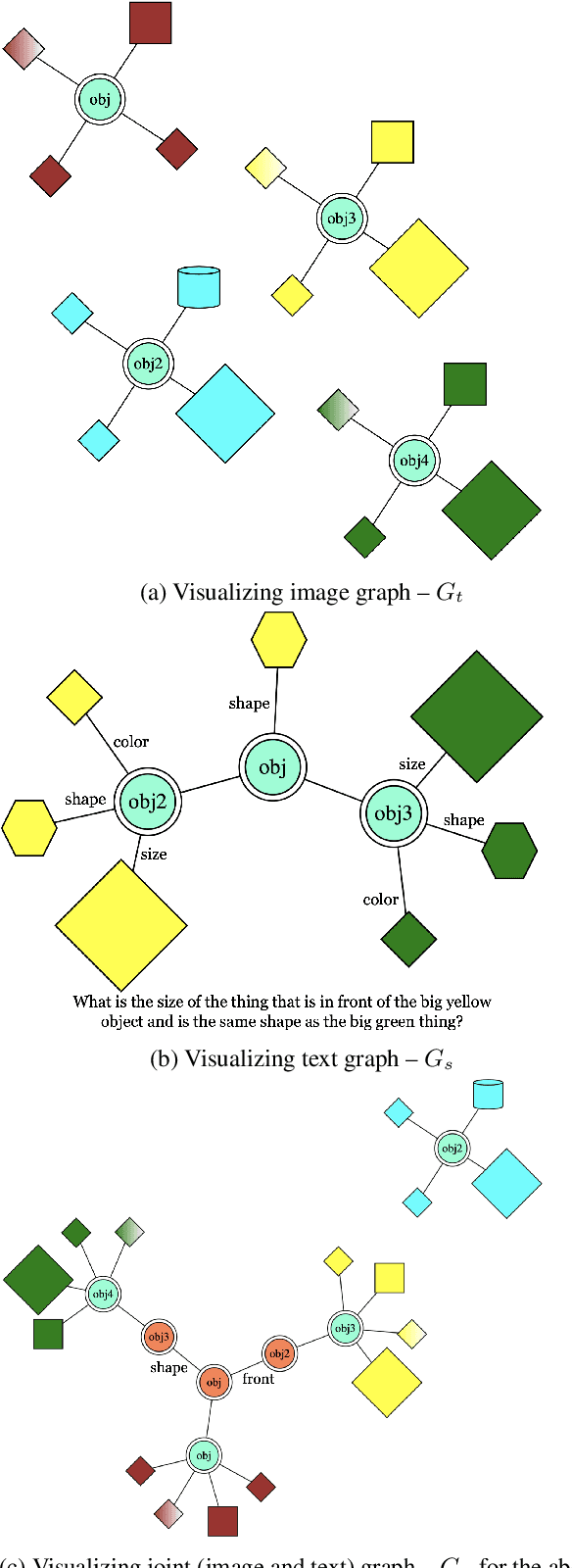
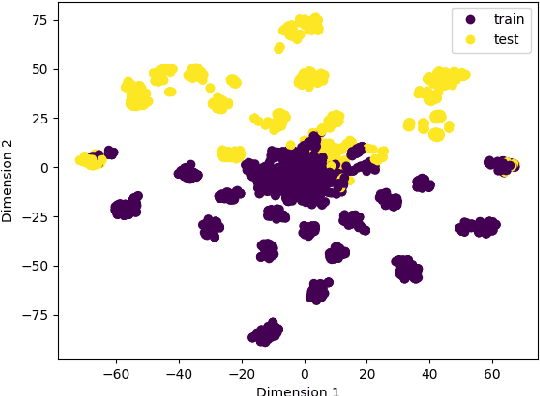
The CLEVR dataset has been used extensively in language grounded visual reasoning in Machine Learning (ML) and Natural Language Processing (NLP) domains. We present a graph parser library for CLEVR, that provides functionalities for object-centric attributes and relationships extraction, and construction of structural graph representations for dual modalities. Structural order-invariant representations enable geometric learning and can aid in downstream tasks like language grounding to vision, robotics, compositionality, interpretability, and computational grammar construction. We provide three extensible main components - parser, embedder, and visualizer that can be tailored to suit specific learning setups. We also provide out-of-the-box functionality for seamless integration with popular deep graph neural network (GNN) libraries. Additionally, we discuss downstream usage and applications of the library, and how it accelerates research for the NLP research community.
Towards On-Device Face Recognition in Body-worn Cameras
Apr 07, 2021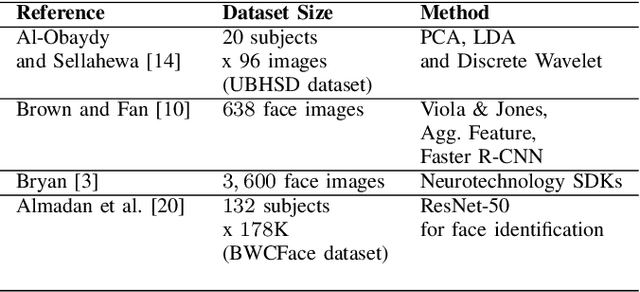
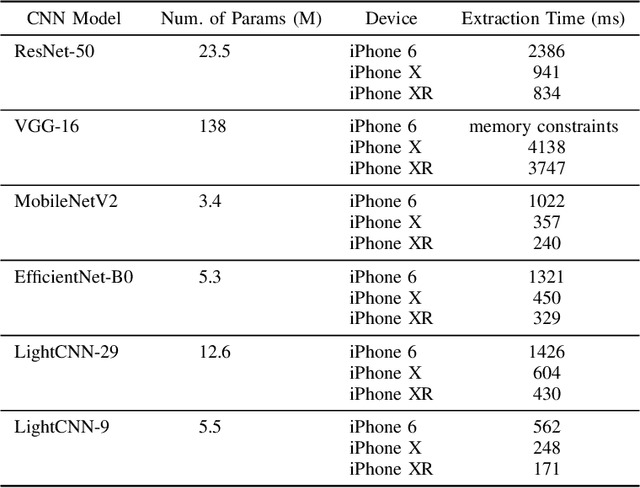
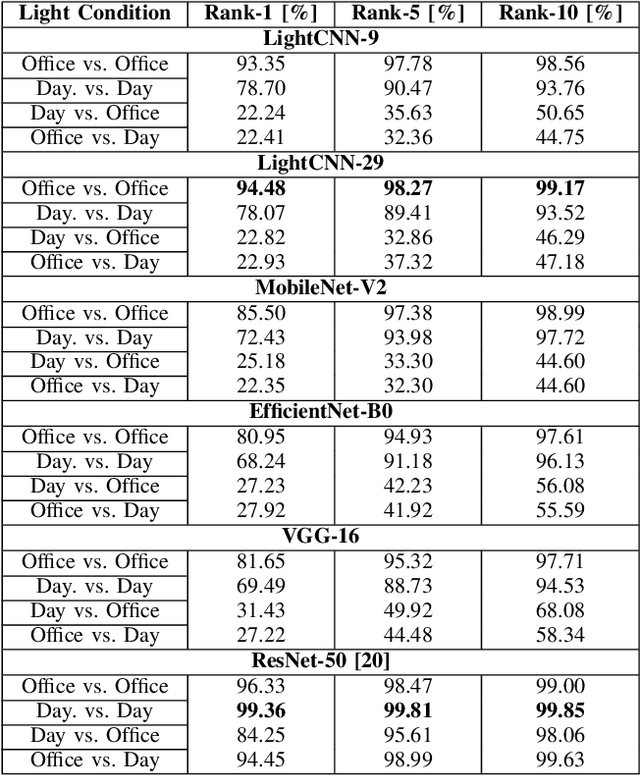
Face recognition technology related to recognizing identities is widely adopted in intelligence gathering, law enforcement, surveillance, and consumer applications. Recently, this technology has been ported to smartphones and body-worn cameras (BWC). Face recognition technology in body-worn cameras is used for surveillance, situational awareness, and keeping the officer safe. Only a handful of academic studies exist in face recognition using the body-worn camera. A recent study has assembled BWCFace facial image dataset acquired using a body-worn camera and evaluated the ResNet-50 model for face identification. However, for real-time inference in resource constraint body-worn cameras and privacy concerns involving facial images, on-device face recognition is required. To this end, this study evaluates lightweight MobileNet-V2, EfficientNet-B0, LightCNN-9 and LightCNN-29 models for face identification using body-worn camera. Experiments are performed on a publicly available BWCface dataset. The real-time inference is evaluated on three mobile devices. The comparative analysis is done with heavy-weight VGG-16 and ResNet-50 models along with six hand-crafted features to evaluate the trade-off between the performance and model size. Experimental results suggest the difference in maximum rank-1 accuracy of lightweight LightCNN-29 over best-performing ResNet-50 is \textbf{1.85\%} and the reduction in model parameters is \textbf{23.49M}. Most of the deep models obtained similar performances at rank-5 and rank-10. The inference time of LightCNNs is 2.1x faster than other models on mobile devices. The least performance difference of \textbf{14\%} is noted between LightCNN-29 and Local Phase Quantization (LPQ) descriptor at rank-1. In most of the experimental settings, lightweight LightCNN models offered the best trade-off between accuracy and the model size in comparison to most of the models.
* 6 pages
Prepare for the Worst: Generalizing across Domain Shifts with Adversarial Batch Normalization
Sep 21, 2020
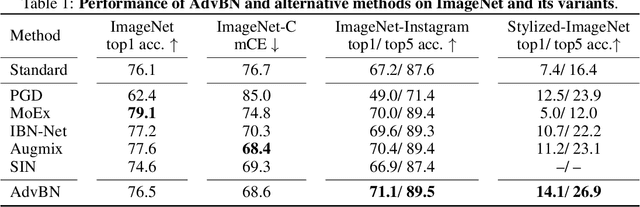

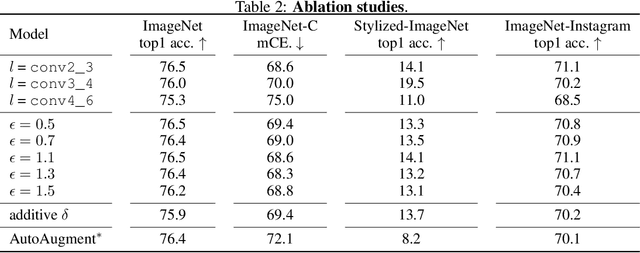
Adversarial training is the industry standard for producing models that are robust to small adversarial perturbations. However, machine learning practitioners need models that are robust to domain shifts that occur naturally, such as changes in the style or illumination of input images. Such changes in input distribution have been effectively modeled as shifts in the mean and variance of deep image features. We adapt adversarial training by adversarially perturbing these feature statistics, rather than image pixels, to produce models that are robust to domain shift. We also visualize images from adversarially crafted distributions. Our method, Adversarial Batch Normalization (AdvBN), significantly improves the performance of ResNet-50 on ImageNet-C (+8.1%), Stylized-ImageNet (+6.7%), and ImageNet-Instagram (+3.9%) over standard training practices. In addition, we demonstrate that AdvBN can also improve generalization on semantic segmentation.
RGB image-based data analysis via discrete Morse theory and persistent homology
Jan 09, 2018
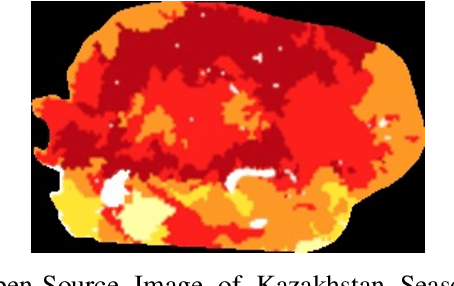

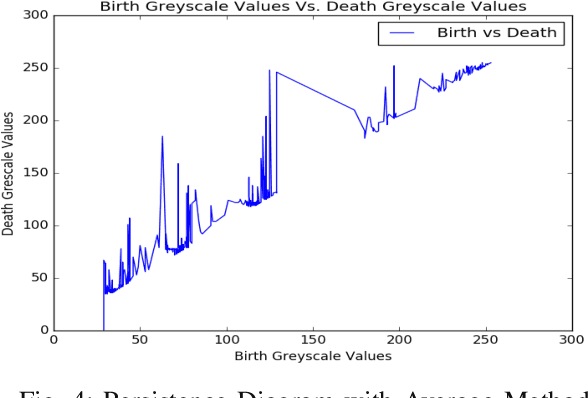
Understanding and comparing images for the purposes of data analysis is currently a very computationally demanding task. A group at Australian National University (ANU) recently developed open-source code that can detect fundamental topological features of a grayscale image in a computationally feasible manner. This is made possible by the fact that computers store grayscale images as cubical cellular complexes. These complexes can be studied using the techniques of discrete Morse theory. We expand the functionality of the ANU code by introducing methods and software for analyzing images encoded in red, green, and blue (RGB), because this image encoding is very popular for publicly available data. Our methods allow the extraction of key topological information from RGB images via informative persistence diagrams by introducing novel methods for transforming RGB-to-grayscale. This paradigm allows us to perform data analysis directly on RGB images representing water scarcity variability as well as crime variability. We introduce software enabling a a user to predict future image properties, towards the eventual aim of more rapid image-based data behavior prediction.