 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Densely Connected High Order Residual Network for Single Frame Image Super Resolution
Apr 16, 2018

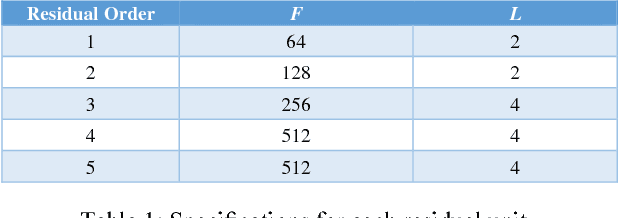


Deep convolutional neural networks (DCNN) have been widely adopted for research on super resolution recently, however previous work focused mainly on stacking as many layers as possible in their model, in this paper, we present a new perspective regarding to image restoration problems that we can construct the neural network model reflecting the physical significance of the image restoration process, that is, embedding the a priori knowledge of image restoration directly into the structure of our neural network model, we employed a symmetric non-linear colorspace, the sigmoidal transfer, to replace traditional transfers such as, sRGB, Rec.709, which are asymmetric non-linear colorspaces, we also propose a "reuse plus patch" method to deal with super resolution of different scaling factors, our proposed methods and model show generally superior performance over previous work even though our model was only roughly trained and could still be underfitting the training set.
RGB-D image-based Object Detection: from Traditional Methods to Deep Learning Techniques
Jul 22, 2019
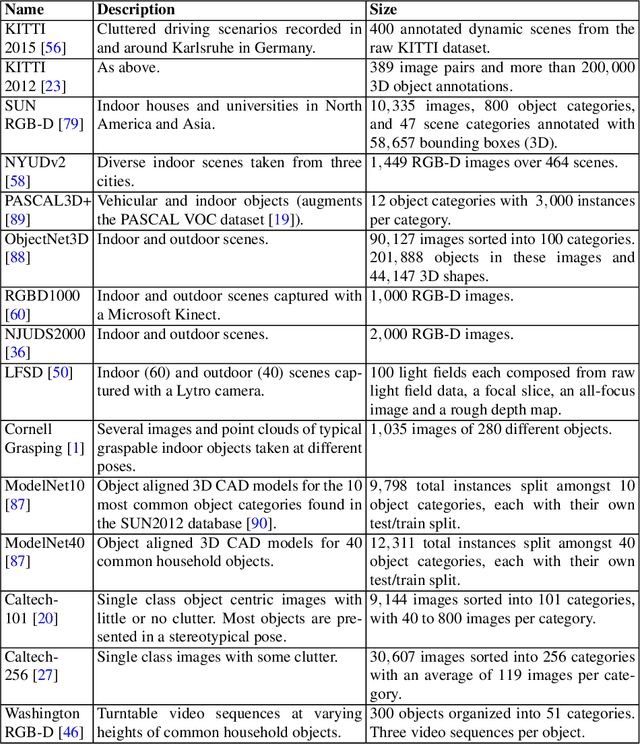

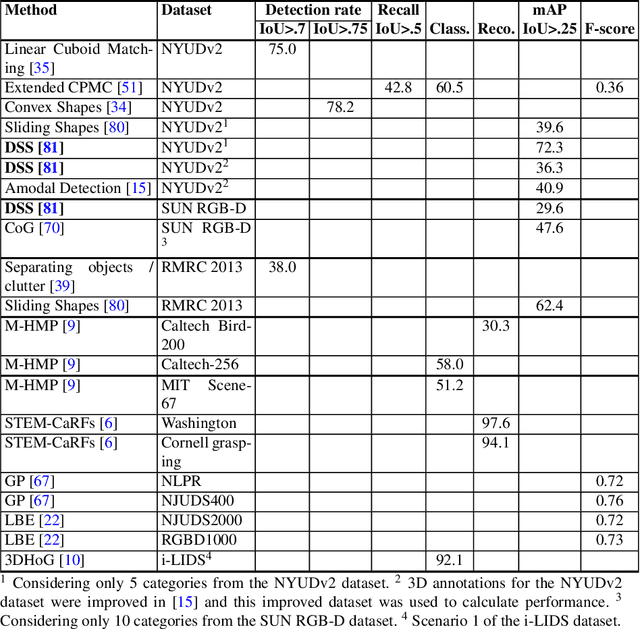
Object detection from RGB images is a long-standing problem in image processing and computer vision. It has applications in various domains including robotics, surveillance, human-computer interaction, and medical diagnosis. With the availability of low cost 3D scanners, a large number of RGB-D object detection approaches have been proposed in the past years. This chapter provides a comprehensive survey of the recent developments in this field. We structure the chapter into two parts; the focus of the first part is on techniques that are based on hand-crafted features combined with machine learning algorithms. The focus of the second part is on the more recent work, which is based on deep learning. Deep learning techniques, coupled with the availability of large training datasets, have now revolutionized the field of computer vision, including RGB-D object detection, achieving an unprecedented level of performance. We survey the key contributions, summarize the most commonly used pipelines, discuss their benefits and limitations, and highlight some important directions for future research.
When Face Recognition Meets Occlusion: A New Benchmark
Mar 04, 2021


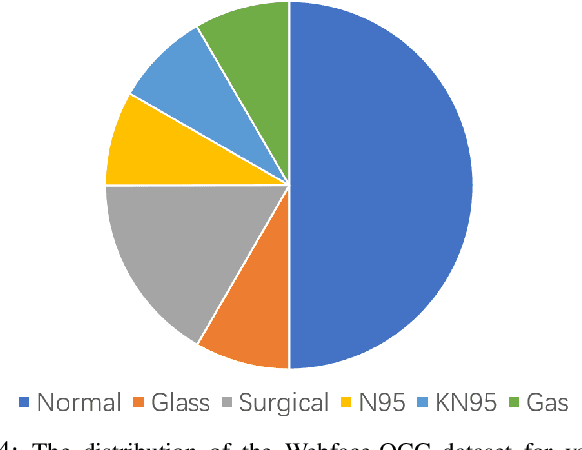
The existing face recognition datasets usually lack occlusion samples, which hinders the development of face recognition. Especially during the COVID-19 coronavirus epidemic, wearing a mask has become an effective means of preventing the virus spread. Traditional CNN-based face recognition models trained on existing datasets are almost ineffective for heavy occlusion. To this end, we pioneer a simulated occlusion face recognition dataset. In particular, we first collect a variety of glasses and masks as occlusion, and randomly combine the occlusion attributes (occlusion objects, textures,and colors) to achieve a large number of more realistic occlusion types. We then cover them in the proper position of the face image with the normal occlusion habit. Furthermore, we reasonably combine original normal face images and occluded face images to form our final dataset, termed as Webface-OCC. It covers 804,704 face images of 10,575 subjects, with diverse occlusion types to ensure its diversity and stability. Extensive experiments on public datasets show that the ArcFace retrained by our dataset significantly outperforms the state-of-the-arts. Webface-OCC is available at https://github.com/Baojin-Huang/Webface-OCC.
An analysis of the transfer learning of convolutional neural networks for artistic images
Nov 05, 2020


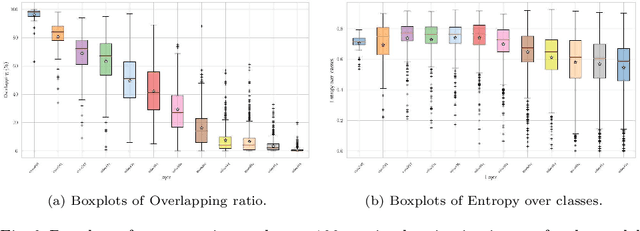
Transfer learning from huge natural image datasets, fine-tuning of deep neural networks and the use of the corresponding pre-trained networks have become de facto the core of art analysis applications. Nevertheless, the effects of transfer learning are still poorly understood. In this paper, we first use techniques for visualizing the network internal representations in order to provide clues to the understanding of what the network has learned on artistic images. Then, we provide a quantitative analysis of the changes introduced by the learning process thanks to metrics in both the feature and parameter spaces, as well as metrics computed on the set of maximal activation images. These analyses are performed on several variations of the transfer learning procedure. In particular, we observed that the network could specialize some pre-trained filters to the new image modality and also that higher layers tend to concentrate classes. Finally, we have shown that a double fine-tuning involving a medium-size artistic dataset can improve the classification on smaller datasets, even when the task changes.
Deep learning denoising for EOG artifacts removal from EEG signals
Sep 12, 2020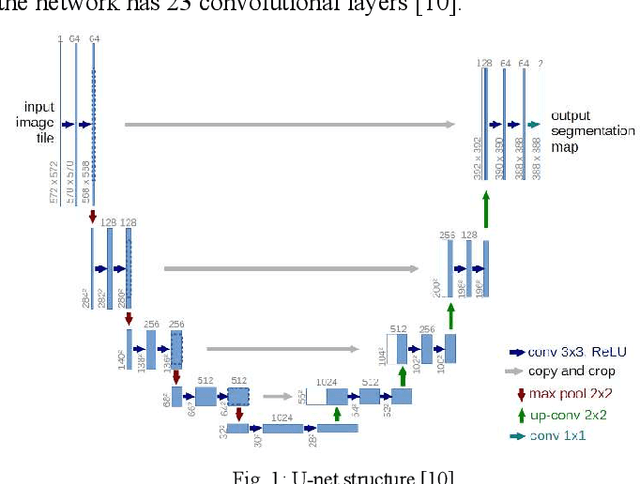
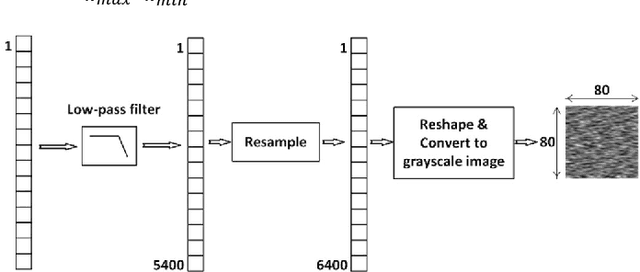

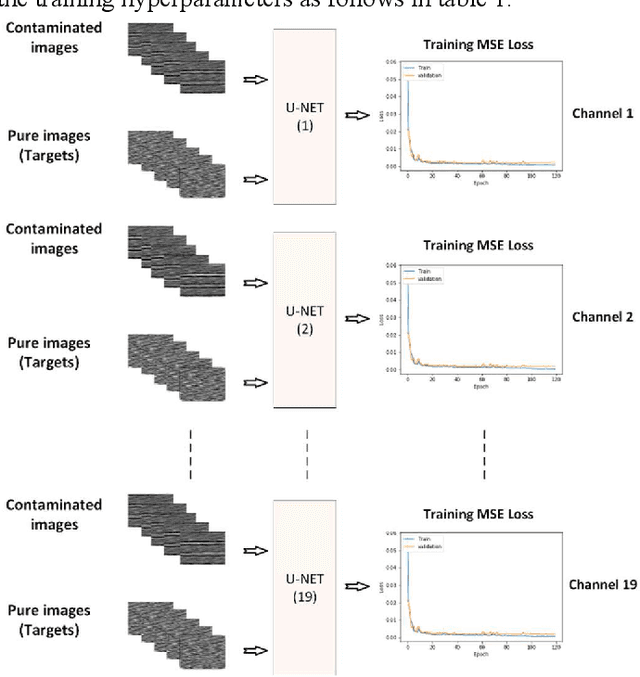
There are many sources of interference encountered in the electroencephalogram (EEG) recordings, specifically ocular, muscular, and cardiac artifacts. Rejection of EEG artifacts is an essential process in EEG analysis since such artifacts cause many problems in EEG signals analysis. One of the most challenging issues in EEG denoising processes is removing the ocular artifacts where Electrooculographic (EOG), and EEG signals have an overlap in both frequency and time domains. In this paper, we build and train a deep learning model to deal with this challenge and remove the ocular artifacts effectively. In the proposed scheme, we convert each EEG signal to an image to be fed to a U-NET model, which is a deep learning model usually used in image segmentation tasks. We proposed three different schemes and made our U-NET based models learn to purify contaminated EEG signals similar to the process used in the image segmentation process. The results confirm that one of our schemes can achieve a reliable and promising accuracy to reduce the Mean square error between the target signal (Pure EEGs) and the predicted signal (Purified EEGs).
A Black-Box Attack Model for Visually-Aware Recommender Systems
Nov 05, 2020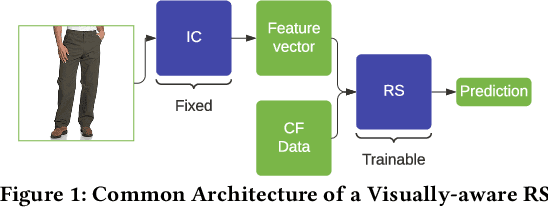
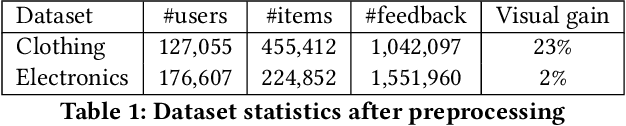
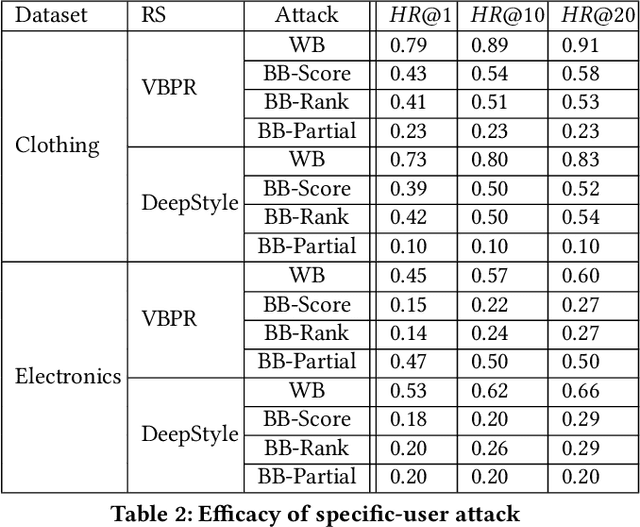
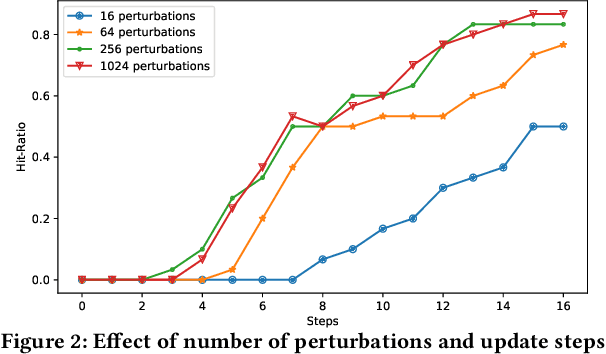
Due to the advances in deep learning, visually-aware recommender systems (RS) have recently attracted increased research interest. Such systems combine collaborative signals with images, usually represented as feature vectors outputted by pre-trained image models. Since item catalogs can be huge, recommendation service providers often rely on images that are supplied by the item providers. In this work, we show that relying on such external sources can make an RS vulnerable to attacks, where the goal of the attacker is to unfairly promote certain pushed items. Specifically, we demonstrate how a new visual attack model can effectively influence the item scores and rankings in a black-box approach, i.e., without knowing the parameters of the model. The main underlying idea is to systematically create small human-imperceptible perturbations of the pushed item image and to devise appropriate gradient approximation methods to incrementally raise the pushed item's score. Experimental evaluations on two datasets show that the novel attack model is effective even when the contribution of the visual features to the overall performance of the recommender system is modest.
One Shot Learning for Deformable Medical Image Registration and Periodic Motion Tracking
Jul 11, 2019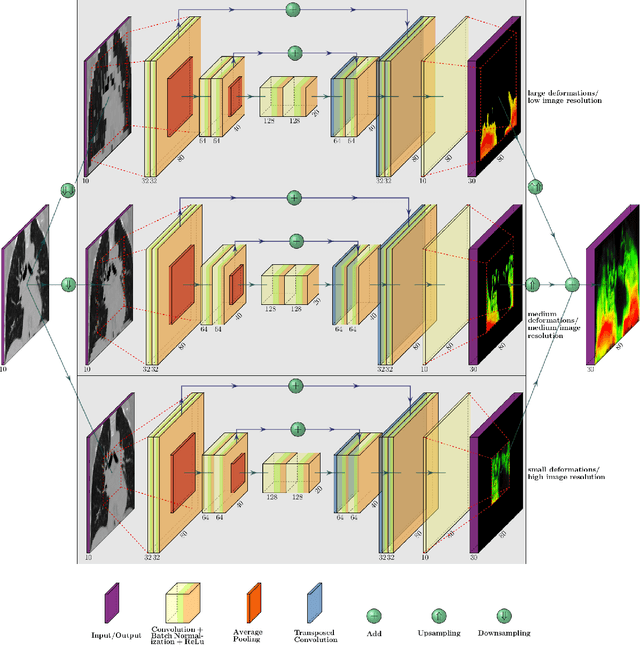
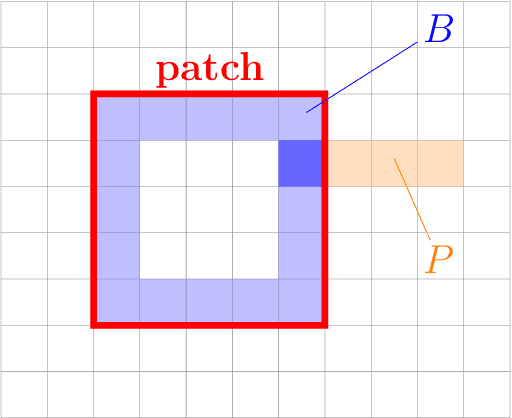
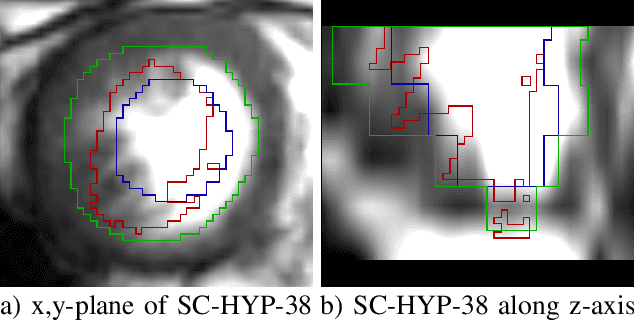
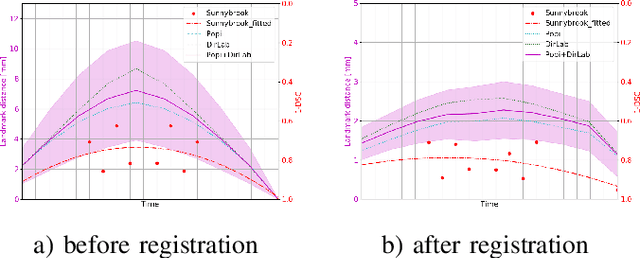
Deformable image registration is a very important field of research in medical imaging. Recently multiple deep learning approaches were published in this area showing promising results. However, drawbacks of deep learning methods are the need for a large amount of training datasets and their inability to register unseen images different from the training datasets. One shot learning comes without the need of large training datasets and has already been proven to be applicable to 3D data. In this work we present an one shot registration approach for periodic motion tracking in 3D and 4D datasets. When applied to 3D dataset the algorithm calculates the inverse of a registration vector field simultaneously. For registration we employed a U-Net combined with a coarse to fine approach and a differential spatial transformer module. The algorithm was thoroughly tested with multiple 4D and 3D datasets publicly available. The results show that the presented approach is able to track periodic motion and to yield a competitive registration accuracy. Possible applications are the use as a stand-alone algorithm for 3D and 4D motion tracking or in the beginning of studies until enough datasets for a separate training phase are available.
Iterative Residual Network for Deep Joint Image Demosaicking and Denoising
Sep 10, 2018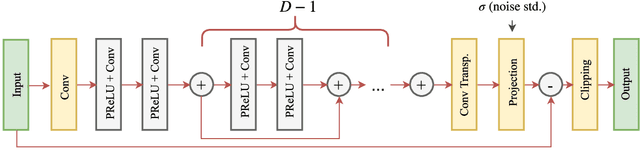
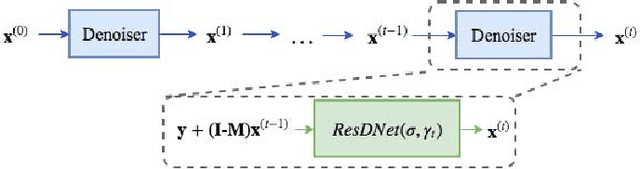
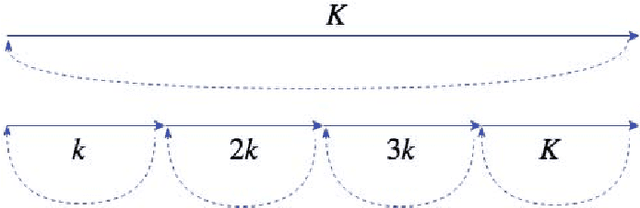
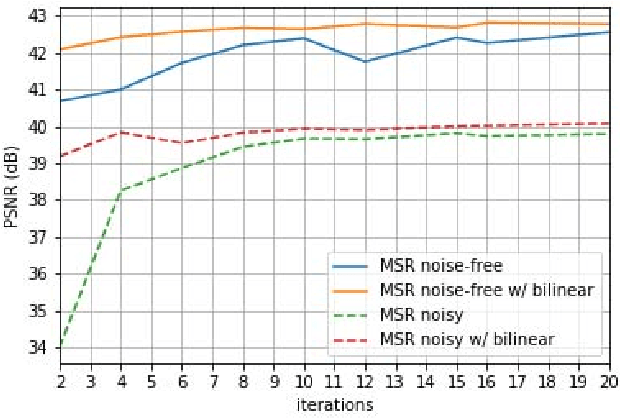
Modern digital cameras rely on sequential execution of separate image processing steps to produce realistic images. The first two steps are usually related to denoising and demosaicking where the former aims to reduce noise from the sensor and the latter converts a series of light intensity readings to color images. Modern approaches try to jointly solve these problems, i.e joint denoising-demosaicking which is an inherently ill-posed problem given that two-thirds of the intensity information are missing and the rest are perturbed by noise. While there are several machine learning systems that have been recently introduced to tackle this problem, in this work we propose a novel algorithm which is inspired by powerful classical image regularization methods, large-scale optimization and deep learning techniques. Consequently, our derived iterative neural network has a transparent and clear interpretation compared to other black-box data driven approaches. The extensive comparisons that we report demonstrate the superiority of our proposed network, which outperforms any previous approaches on both noisy and noise-free data across many different datasets using less training samples. This improvement in reconstruction quality is attributed to the principled way we design and train our network architecture, which as a result requires fewer trainable parameters than the current state-of-the-art solution.
Shuffler: A Large Scale Data Management Tool for ML in Computer Vision
Apr 11, 2021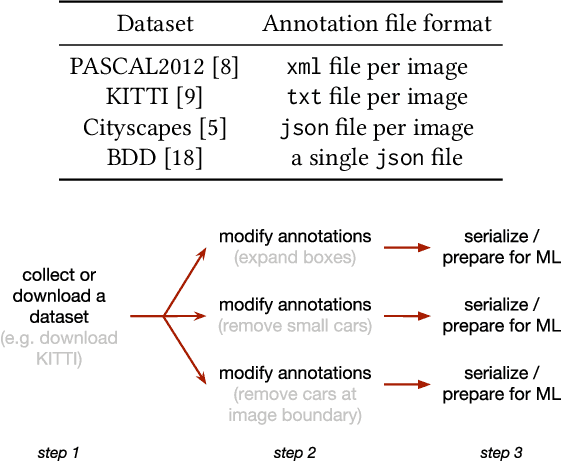

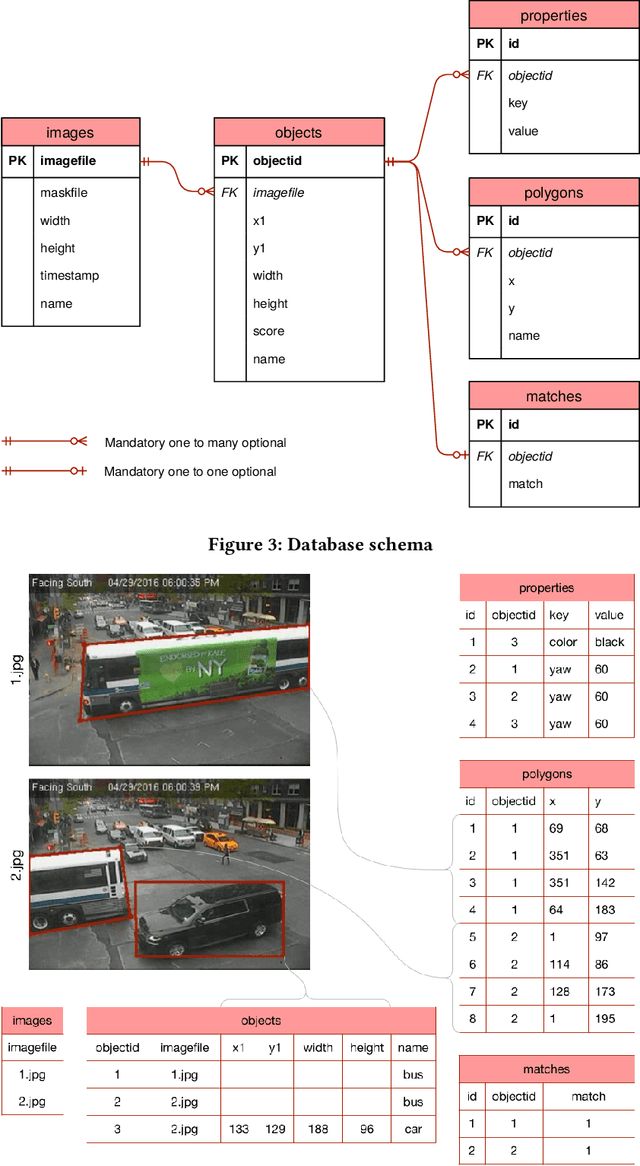
Datasets in the computer vision academic research community are primarily static. Once a dataset is accepted as a benchmark for a computer vision task, researchers working on this task will not alter it in order to make their results reproducible. At the same time, when exploring new tasks and new applications, datasets tend to be an ever changing entity. A practitioner may combine existing public datasets, filter images or objects in them, change annotations or add new ones to fit a task at hand, visualize sample images, or perhaps output statistics in the form of text or plots. In fact, datasets change as practitioners experiment with data as much as with algorithms, trying to make the most out of machine learning models. Given that ML and deep learning call for large volumes of data to produce satisfactory results, it is no surprise that the resulting data and software management associated to dealing with live datasets can be quite complex. As far as we know, there is no flexible, publicly available instrument to facilitate manipulating image data and their annotations throughout a ML pipeline. In this work, we present Shuffler, an open source tool that makes it easy to manage large computer vision datasets. It stores annotations in a relational, human-readable database. Shuffler defines over 40 data handling operations with annotations that are commonly useful in supervised learning applied to computer vision and supports some of the most well-known computer vision datasets. Finally, it is easily extensible, making the addition of new operations and datasets a task that is fast and easy to accomplish.
Super-Selfish: Self-Supervised Learning on Images with PyTorch
Dec 07, 2020Super-Selfish is an easy to use PyTorch framework for image-based self-supervised learning. Features can be learned with 13 algorithms that span from simple classification to more complex state of theart contrastive pretext tasks. The framework is easy to use and allows for pretraining any PyTorch neural network with only two lines of code. Simultaneously, full flexibility is maintained through modular design choices. The code can be found at https://github.com/MECLabTUDA/Super_Selfish and installed using pip install super-selfish.