 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Decoder: Concise Image Representations from Untrained Non-convolutional Networks
Oct 02, 2018
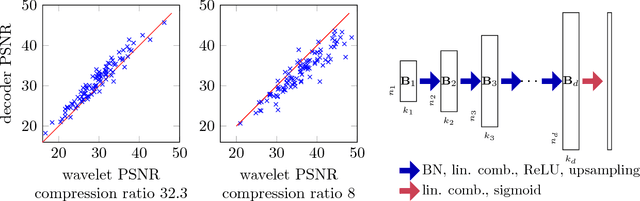
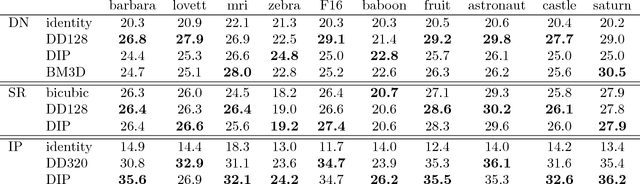

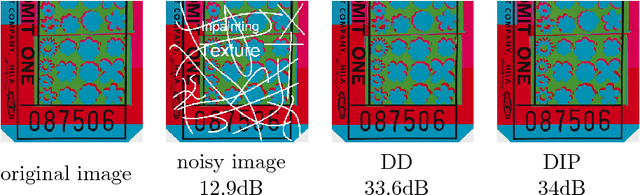
Deep neural networks, in particular convolutional neural networks, have become highly effective tools for compressing images and solving inverse problems including denoising, inpainting, and reconstruction from few and noisy measurements. This success can be attributed in part to their ability to represent and generate natural images well. Contrary to classical tools such as wavelets, image-generating deep neural networks have a large number of parameters---typically a multiple of their output dimension---and need to be trained on large datasets. In this paper, we propose an untrained simple image model, called the deep decoder, which is a deep neural network that can generate natural images from very few weight parameters. The deep decoder has a simple architecture with no convolutions and fewer weight parameters than the output dimensionality. This underparameterization enables the deep decoder to compress images into a concise set of network weights, which we show is on par with wavelet-based thresholding. Further, underparameterization provides a barrier to overfitting, allowing the deep decoder to have state-of-the-art performance for denoising. The deep decoder is simple in the sense that each layer has an identical structure that consists of only one upsampling unit, pixel-wise linear combination of channels, ReLU activation, and channelwise normalization. This simplicity makes the network amenable to theoretical analysis, and it sheds light on the aspects of neural networks that enable them to form effective signal representations.
Quantitative Error Prediction of Medical Image Registration using Regression Forests
May 18, 2019
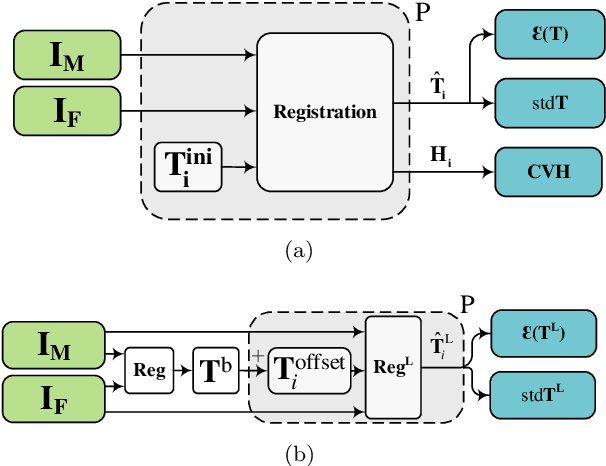
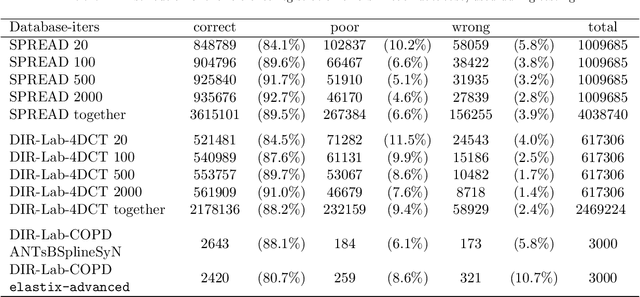
Predicting registration error can be useful for evaluation of registration procedures, which is important for the adoption of registration techniques in the clinic. In addition, quantitative error prediction can be helpful in improving the registration quality. The task of predicting registration error is demanding due to the lack of a ground truth in medical images. This paper proposes a new automatic method to predict the registration error in a quantitative manner, and is applied to chest CT scans. A random regression forest is utilized to predict the registration error locally. The forest is built with features related to the transformation model and features related to the dissimilarity after registration. The forest is trained and tested using manually annotated corresponding points between pairs of chest CT scans in two experiments: SPREAD (trained and tested on SPREAD) and inter-database (including three databases SPREAD, DIR-Lab-4DCT and DIR-Lab-COPDgene). The results show that the mean absolute errors of regression are 1.07 $\pm$ 1.86 and 1.76 $\pm$ 2.59 mm for the SPREAD and inter-database experiment, respectively. The overall accuracy of classification in three classes (correct, poor and wrong registration) is 90.7% and 75.4%, for SPREAD and inter-database respectively. The good performance of the proposed method enables important applications such as automatic quality control in large-scale image analysis.
Image Generation for Efficient Neural Network Training in Autonomous Drone Racing
Aug 06, 2020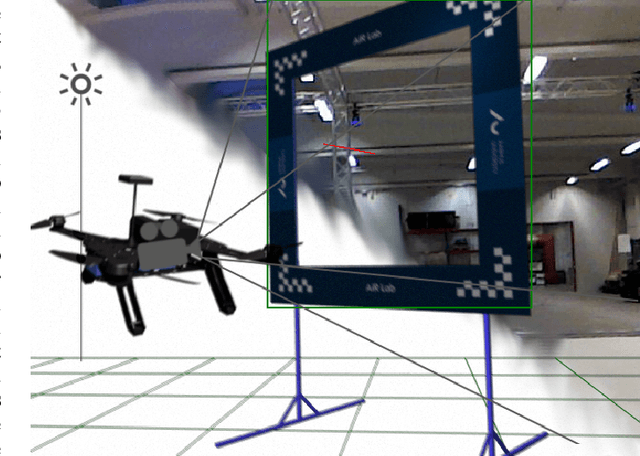
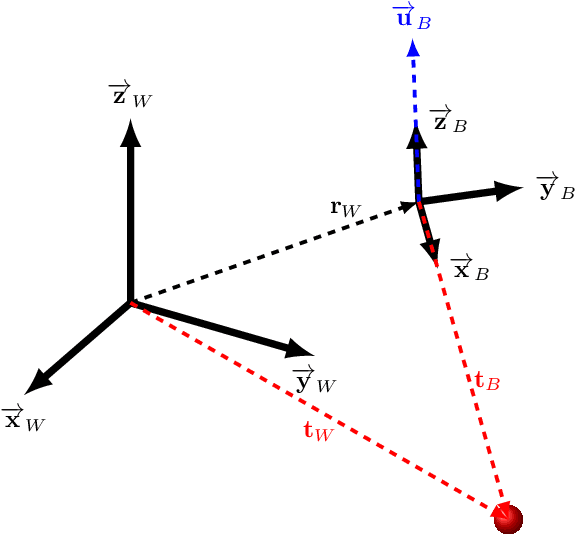
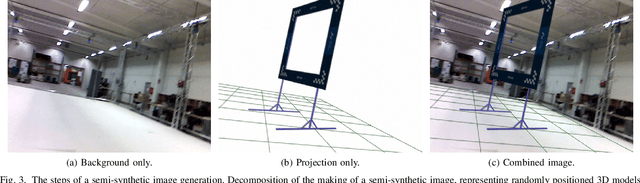

Drone racing is a recreational sport in which the goal is to pass through a sequence of gates in a minimum amount of time while avoiding collisions. In autonomous drone racing, one must accomplish this task by flying fully autonomously in an unknown environment by relying only on computer vision methods for detecting the target gates. Due to the challenges such as background objects and varying lighting conditions, traditional object detection algorithms based on colour or geometry tend to fail. Convolutional neural networks offer impressive advances in computer vision but require an immense amount of data to learn. Collecting this data is a tedious process because the drone has to be flown manually, and the data collected can suffer from sensor failures. In this work, a semi-synthetic dataset generation method is proposed, using a combination of real background images and randomised 3D renders of the gates, to provide a limitless amount of training samples that do not suffer from those drawbacks. Using the detection results, a line-of-sight guidance algorithm is used to cross the gates. In several experimental real-time tests, the proposed framework successfully demonstrates fast and reliable detection and navigation.
Bridge the Vision Gap from Field to Command: A Deep Learning Network Enhancing Illumination and Details
Jan 20, 2021


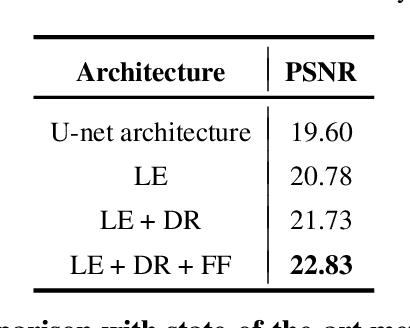
With the goal of tuning up the brightness, low-light image enhancement enjoys numerous applications, such as surveillance, remote sensing and computational photography. Images captured under low-light conditions often suffer from poor visibility and blur. Solely brightening the dark regions will inevitably amplify the blur, thus may lead to detail loss. In this paper, we propose a simple yet effective two-stream framework named NEID to tune up the brightness and enhance the details simultaneously without introducing many computational costs. Precisely, the proposed method consists of three parts: Light Enhancement (LE), Detail Refinement (DR) and Feature Fusing (FF) module, which can aggregate composite features oriented to multiple tasks based on channel attention mechanism. Extensive experiments conducted on several benchmark datasets demonstrate the efficacy of our method and its superiority over state-of-the-art methods.
Riemannian-based Discriminant Analysis for Feature Extraction and Classification
Jan 20, 2021
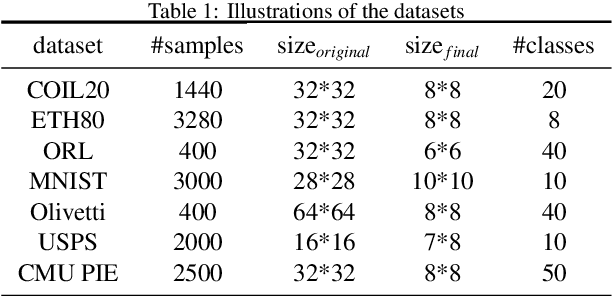
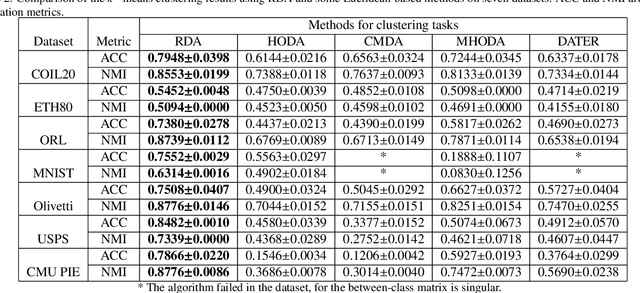
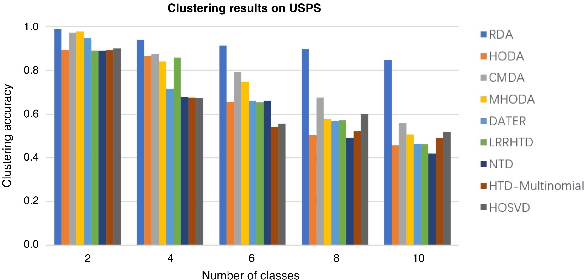
Discriminant analysis, as a widely used approach in machine learning to extract low-dimensional features from the high-dimensional data, applies the Fisher discriminant criterion to find the orthogonal discriminant projection subspace. But most of the Euclidean-based algorithms for discriminant analysis are easily convergent to a spurious local minima and hardly obtain an unique solution. To address such problem, in this study we propose a novel method named Riemannian-based Discriminant Analysis (RDA), which transforms the traditional Euclidean-based methods to the Riemannian manifold space. In RDA, the second-order geometry of trust-region methods is utilized to learn the discriminant bases. To validate the efficiency and effectiveness of RDA, we conduct a variety of experiments on image classification tasks. The numerical results suggest that RDA can extract statistically significant features and robustly outperform state-of-the-art algorithms in classification tasks.
A Neuro-Inspired Autoencoding Defense Against Adversarial Perturbations
Dec 21, 2020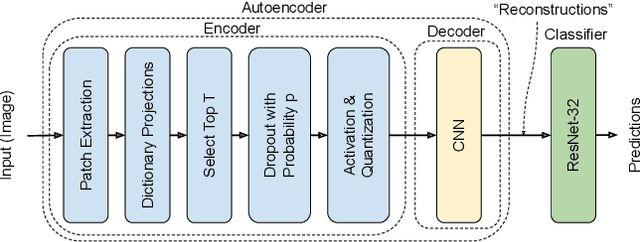

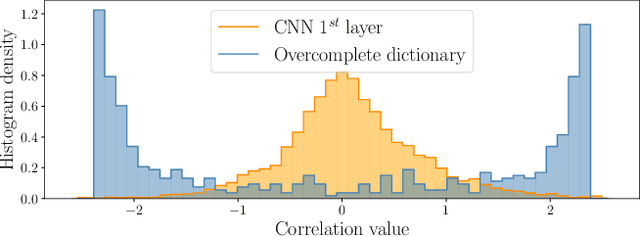
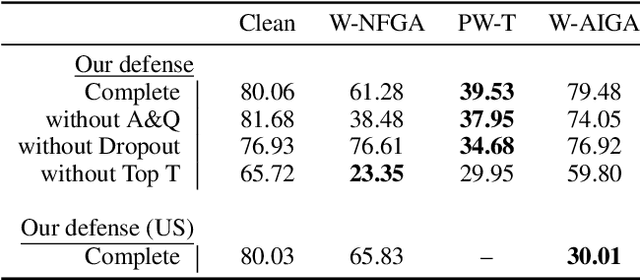
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks: carefully constructed perturbations to an image can seriously impair classification accuracy, while being imperceptible to humans. While there has been a significant amount of research on defending against such attacks, most defenses based on systematic design principles have been defeated by appropriately modified attacks. For a fixed set of data, the most effective current defense is to train the network using adversarially perturbed examples. In this paper, we investigate a radically different, neuro-inspired defense mechanism, starting from the observation that human vision is virtually unaffected by adversarial examples designed for machines. We aim to reject L^inf bounded adversarial perturbations before they reach a classifier DNN, using an encoder with characteristics commonly observed in biological vision: sparse overcomplete representations, randomness due to synaptic noise, and drastic nonlinearities. Encoder training is unsupervised, using standard dictionary learning. A CNN-based decoder restores the size of the encoder output to that of the original image, enabling the use of a standard CNN for classification. Our nominal design is to train the decoder and classifier together in standard supervised fashion, but we also consider unsupervised decoder training based on a regression objective (as in a conventional autoencoder) with separate supervised training of the classifier. Unlike adversarial training, all training is based on clean images. Our experiments on the CIFAR-10 show performance competitive with state-of-the-art defenses based on adversarial training, and point to the promise of neuro-inspired techniques for the design of robust neural networks. In addition, we provide results for a subset of the Imagenet dataset to verify that our approach scales to larger images.
ICAM-reg: Interpretable Classification and Regression with Feature Attribution for Mapping Neurological Phenotypes in Individual Scans
Mar 03, 2021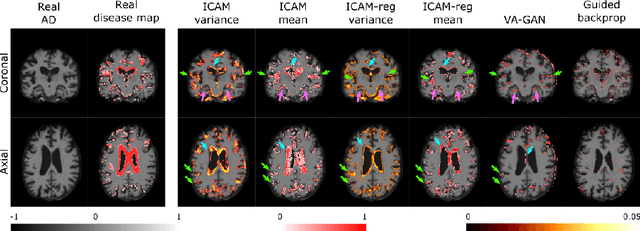
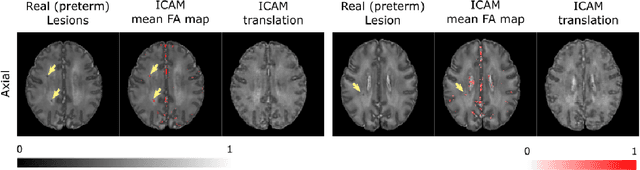
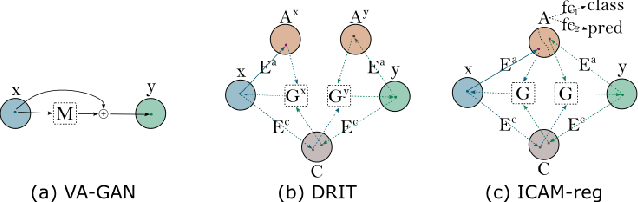
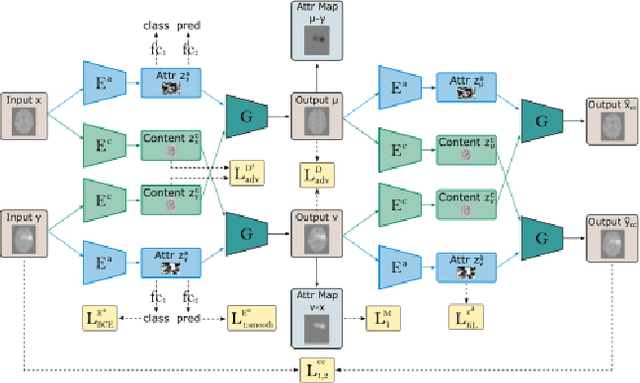
An important goal of medical imaging is to be able to precisely detect patterns of disease specific to individual scans; however, this is challenged in brain imaging by the degree of heterogeneity of shape and appearance. Traditional methods, based on image registration to a global template, historically fail to detect variable features of disease, as they utilise population-based analyses, suited primarily to studying group-average effects. In this paper we therefore take advantage of recent developments in generative deep learning to develop a method for simultaneous classification, or regression, and feature attribution (FA). Specifically, we explore the use of a VAE-GAN translation network called ICAM, to explicitly disentangle class relevant features from background confounds for improved interpretability and regression of neurological phenotypes. We validate our method on the tasks of Mini-Mental State Examination (MMSE) cognitive test score prediction for the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, as well as brain age prediction, for both neurodevelopment and neurodegeneration, using the developing Human Connectome Project (dHCP) and UK Biobank datasets. We show that the generated FA maps can be used to explain outlier predictions and demonstrate that the inclusion of a regression module improves the disentanglement of the latent space. Our code is freely available on Github https://github.com/CherBass/ICAM.
Universal Joint Image Clustering and Registration using Partition Information
Nov 30, 2017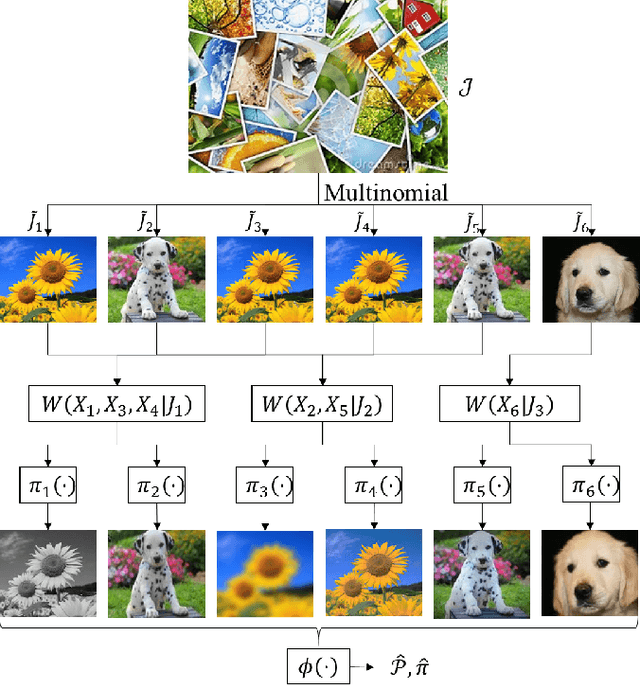
We consider the problem of universal joint clustering and registration of images and define algorithms using multivariate information functionals. We first study registering two images using maximum mutual information and prove its asymptotic optimality. We then show the shortcomings of pairwise registration in multi-image registration, and design an asymptotically optimal algorithm based on multiinformation. Further, we define a novel multivariate information functional to perform joint clustering and registration of images, and prove consistency of the algorithm. Finally, we consider registration and clustering of numerous limited-resolution images, defining algorithms that are order-optimal in scaling of number of pixels in each image with the number of images.
Dilated Convolutions with Lateral Inhibitions for Semantic Image Segmentation
Jun 16, 2020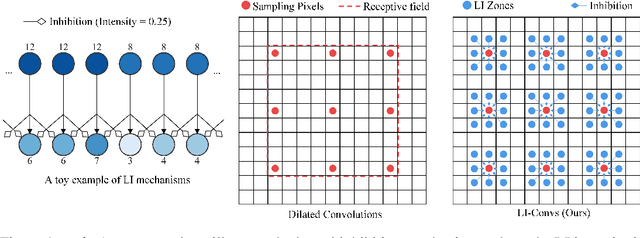
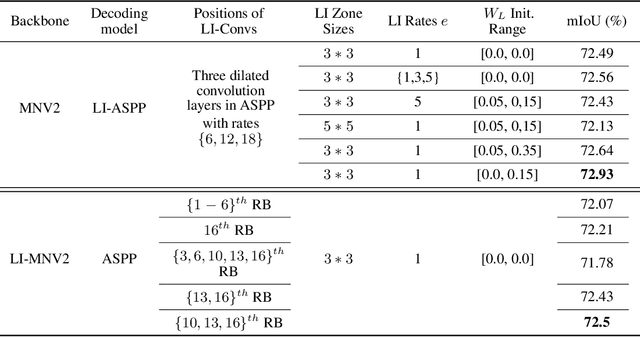

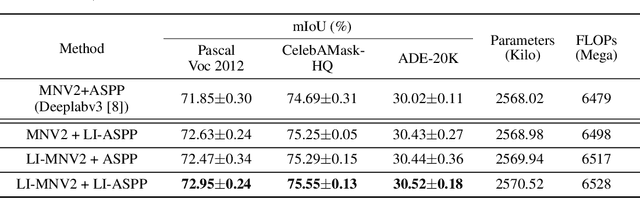
Dilated convolutions are widely used in deep semantic segmentation models as they can enlarge the filters' receptive field without adding additional weights nor sacrificing spatial resolution. However, as dilated convolutional filters do not possess positional knowledge about the pixels on semantically meaningful contours, they could lead to ambiguous predictions on object boundaries. In addition, although dilating the filter can expand its receptive field, the total number of sampled pixels remains unchanged, which usually comprises a small fraction of the receptive field's total area. Inspired by the Lateral Inhibition (LI) mechanisms in human visual systems, we propose the dilated convolution with lateral inhibitions (LI-Convs) to overcome these limitations. Introducing LI mechanisms improves the convolutional filter's sensitivity to semantic object boundaries. Moreover, since LI-Convs also implicitly take the pixels from the laterally inhibited zones into consideration, they can also extract features at a denser scale. By integrating LI-Convs into the Deeplabv3+ architecture, we propose the Lateral Inhibited Atrous Spatial Pyramid Pooling (LI-ASPP) and the Lateral Inhibited MobileNet-V2 (LI-MNV2). Experimental results on three benchmark datasets (PASCAL VOC 2012, CelebAMask-HQ and ADE20K) show that our LI-based segmentation models outperform the baseline on all of them, thus verify the effectiveness and generality of the proposed LI-Convs.
Generative networks as inverse problems with fractional wavelet scattering networks
Jul 28, 2020
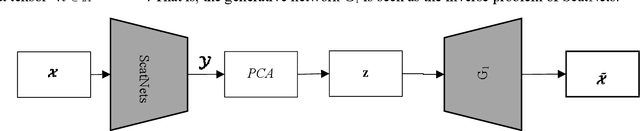
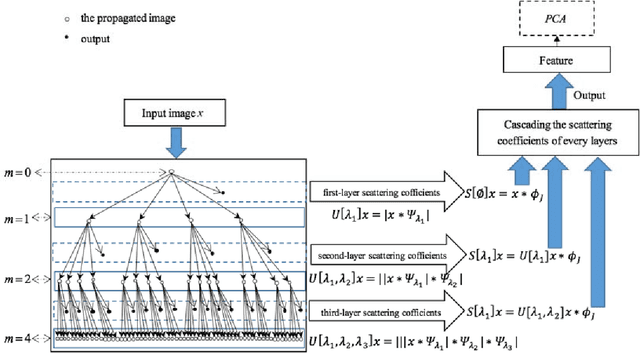
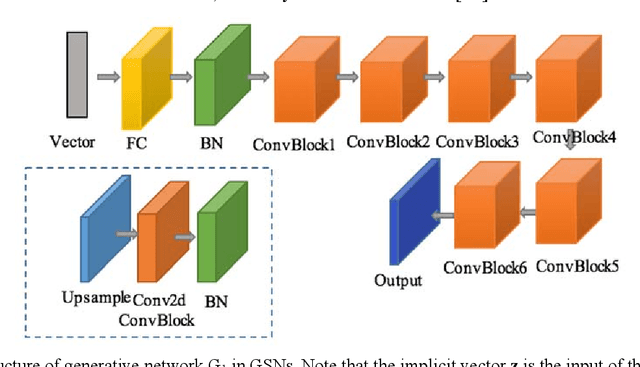
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.