 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Vehicle Re-Identification via Self-supervised Metric Learning using Feature Dictionary
Mar 03, 2021
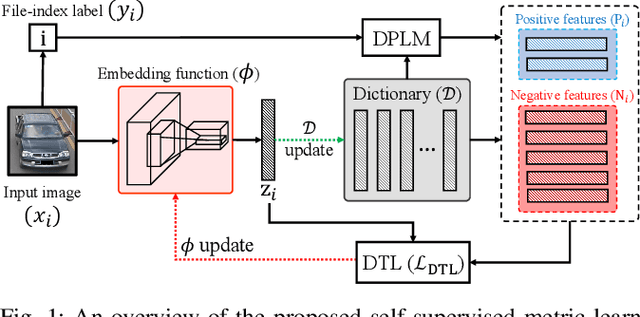
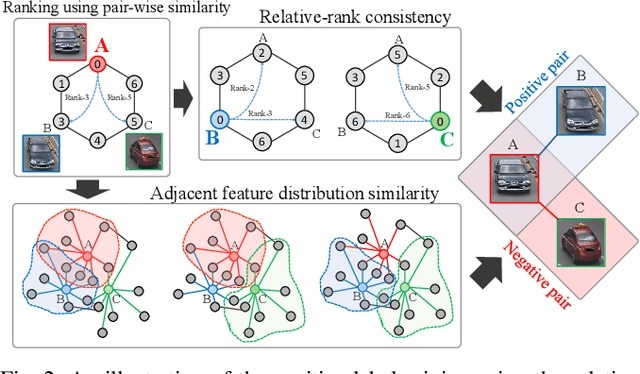
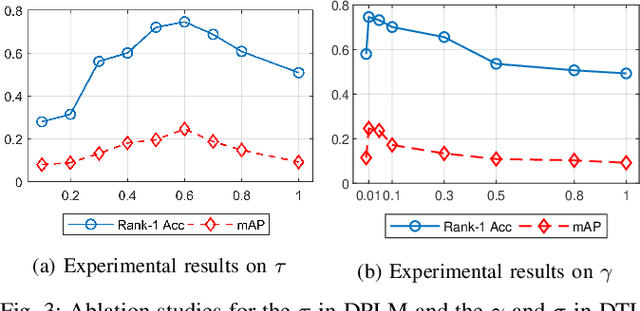
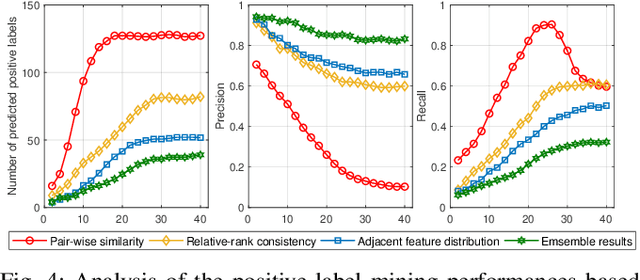
The key challenge of unsupervised vehicle re-identification (Re-ID) is learning discriminative features from unlabelled vehicle images. Numerous methods using domain adaptation have achieved outstanding performance, but those methods still need a labelled dataset as a source domain. This paper addresses an unsupervised vehicle Re-ID method, which no need any types of a labelled dataset, through a Self-supervised Metric Learning (SSML) based on a feature dictionary. Our method initially extracts features from vehicle images and stores them in a dictionary. Thereafter, based on the dictionary, the proposed method conducts dictionary-based positive label mining (DPLM) to search for positive labels. Pair-wise similarity, relative-rank consistency, and adjacent feature distribution similarity are jointly considered to find images that may belong to the same vehicle of a given probe image. The results of DPLM are applied to dictionary-based triplet loss (DTL) to improve the discriminativeness of learnt features and to refine the quality of the results of DPLM progressively. The iterative process with DPLM and DTL boosts the performance of unsupervised vehicle Re-ID. Experimental results demonstrate the effectiveness of the proposed method by producing promising vehicle Re-ID performance without a pre-labelled dataset. The source code for this paper is publicly available on `https://github.com/andreYoo/VeRI_SSML_FD.git'.
Deferred Neural Rendering: Image Synthesis using Neural Textures
Apr 28, 2019

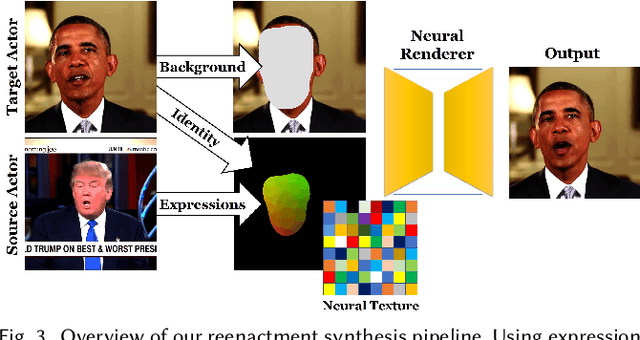
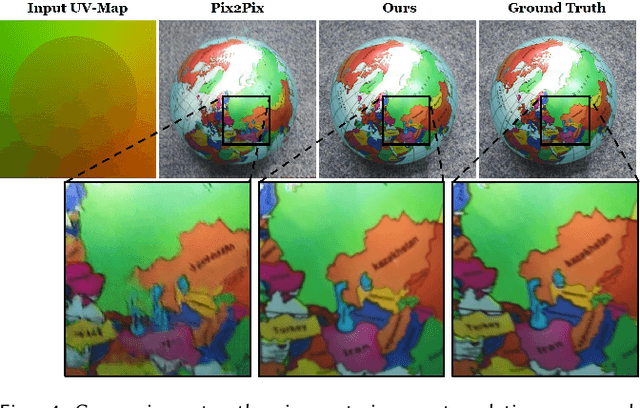
The modern computer graphics pipeline can synthesize images at remarkable visual quality; however, it requires well-defined, high-quality 3D content as input. In this work, we explore the use of imperfect 3D content, for instance, obtained from photo-metric reconstructions with noisy and incomplete surface geometry, while still aiming to produce photo-realistic (re-)renderings. To address this challenging problem, we introduce Deferred Neural Rendering, a new paradigm for image synthesis that combines the traditional graphics pipeline with learnable components. Specifically, we propose Neural Textures, which are learned feature maps that are trained as part of the scene capture process. Similar to traditional textures, neural textures are stored as maps on top of 3D mesh proxies; however, the high-dimensional feature maps contain significantly more information, which can be interpreted by our new deferred neural rendering pipeline. Both neural textures and deferred neural renderer are trained end-to-end, enabling us to synthesize photo-realistic images even when the original 3D content was imperfect. In contrast to traditional, black-box 2D generative neural networks, our 3D representation gives us explicit control over the generated output, and allows for a wide range of application domains. For instance, we can synthesize temporally-consistent video re-renderings of recorded 3D scenes as our representation is inherently embedded in 3D space. This way, neural textures can be utilized to coherently re-render or manipulate existing video content in both static and dynamic environments at real-time rates. We show the effectiveness of our approach in several experiments on novel view synthesis, scene editing, and facial reenactment, and compare to state-of-the-art approaches that leverage the standard graphics pipeline as well as conventional generative neural networks.
Autonomous Deep Learning: A Genetic DCNN Designer for Image Classification
Jul 01, 2018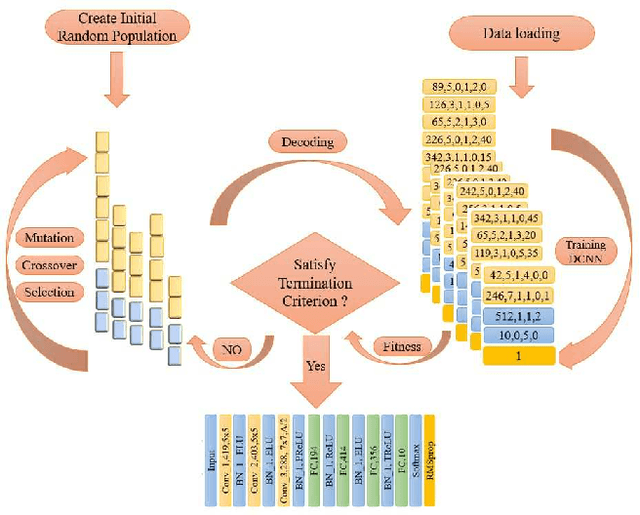
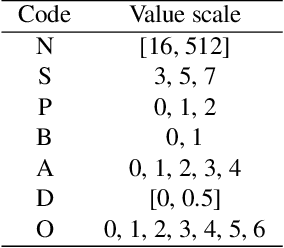
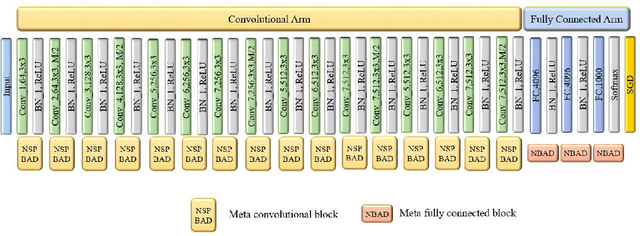
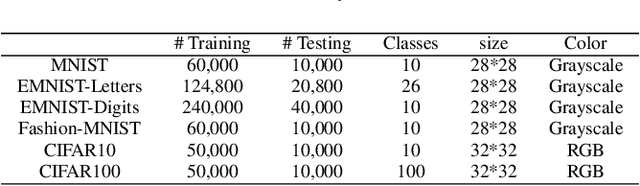
Recent years have witnessed the breakthrough success of deep convolutional neural networks (DCNNs) in image classification and other vision applications. Although freeing users from the troublesome handcrafted feature extraction by providing a uniform feature extraction-classification framework, DCNNs still require a handcrafted design of their architectures. In this paper, we propose the genetic DCNN designer, an autonomous learning algorithm can generate a DCNN architecture automatically based on the data available for a specific image classification problem. We first partition a DCNN into multiple stacked meta convolutional blocks and fully connected blocks, each containing the operations of convolution, pooling, fully connection, batch normalization, activation and drop out, and thus convert the architecture into an integer vector. Then, we use refined evolutionary operations, including selection, mutation and crossover to evolve a population of DCNN architectures. Our results on the MNIST, Fashion-MNIST, EMNISTDigit, EMNIST-Letter, CIFAR10 and CIFAR100 datasets suggest that the proposed genetic DCNN designer is able to produce automatically DCNN architectures, whose performance is comparable to, if not better than, that of stateof- the-art DCNN models
Feature Sharing Cooperative Network for Semantic Segmentation
Jan 20, 2021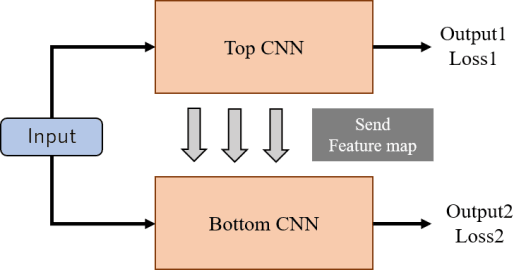
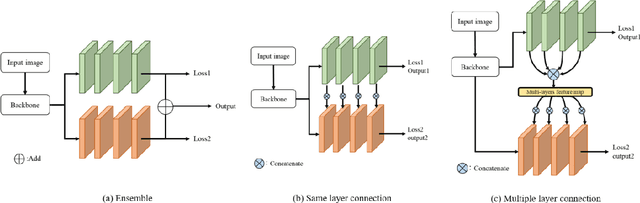
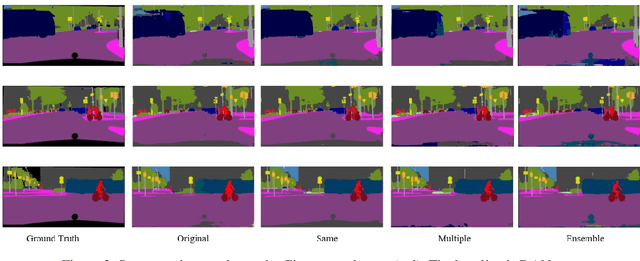
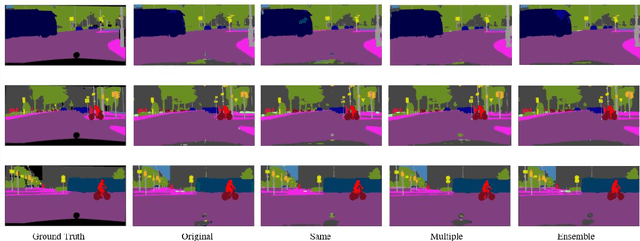
In recent years, deep neural networks have achieved high ac-curacy in the field of image recognition. By inspired from human learning method, we propose a semantic segmentation method using cooperative learning which shares the information resembling a group learning. We use two same networks and paths for sending feature maps between two networks. Two networks are trained simultaneously. By sharing feature maps, one of two networks can obtain the information that cannot be obtained by a single network. In addition, in order to enhance the degree of cooperation, we propose two kinds of methods that connect only the same layer and multiple layers. We evaluated our proposed idea on two kinds of networks. One is Dual Attention Network (DANet) and the other one is DeepLabv3+. The proposed method achieved better segmentation accuracy than the conventional single network and ensemble of networks.
Learning Adaptive Sampling and Reconstruction for Volume Visualization
Jul 20, 2020
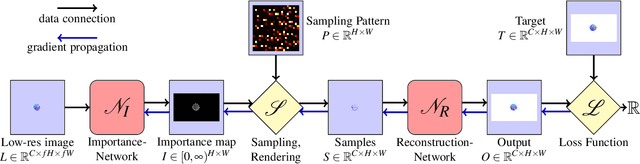
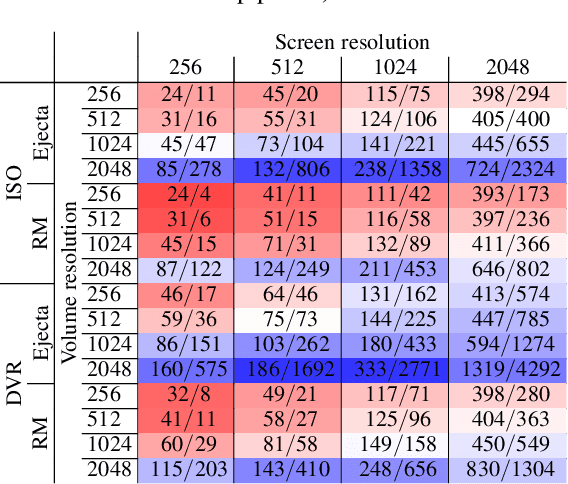
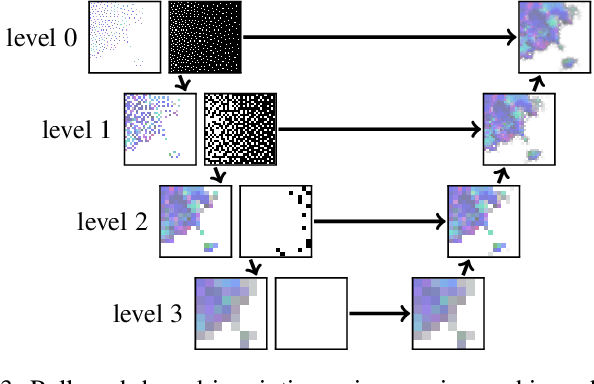
A central challenge in data visualization is to understand which data samples are required to generate an image of a data set in which the relevant information is encoded. In this work, we make a first step towards answering the question of whether an artificial neural network can predict where to sample the data with higher or lower density, by learning of correspondences between the data, the sampling patterns and the generated images. We introduce a novel neural rendering pipeline, which is trained end-to-end to generate a sparse adaptive sampling structure from a given low-resolution input image, and reconstructs a high-resolution image from the sparse set of samples. For the first time, to the best of our knowledge, we demonstrate that the selection of structures that are relevant for the final visual representation can be jointly learned together with the reconstruction of this representation from these structures. Therefore, we introduce differentiable sampling and reconstruction stages, which can leverage back-propagation based on supervised losses solely on the final image. We shed light on the adaptive sampling patterns generated by the network pipeline and analyze its use for volume visualization including isosurface and direct volume rendering.
Determining ellipses from low resolution images with a comprehensive image formation model
Jul 18, 2018
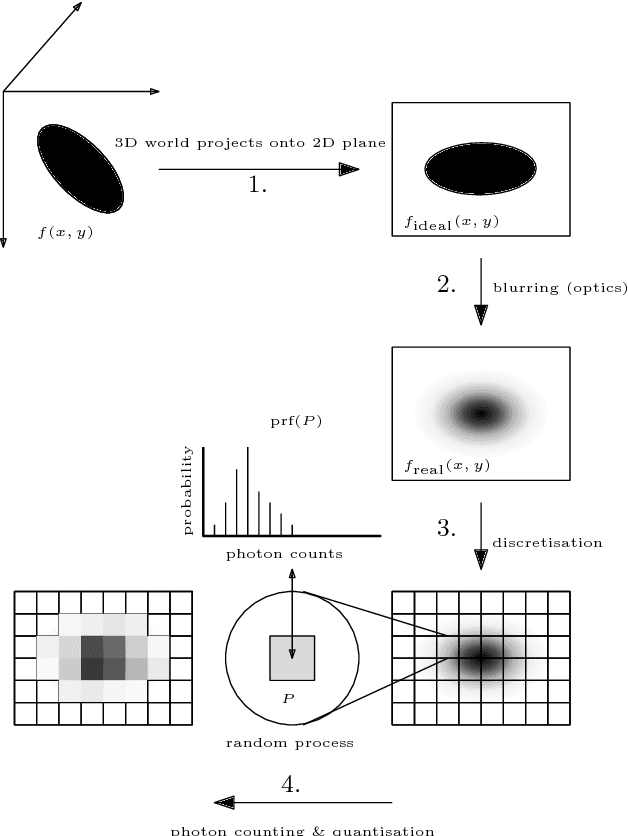
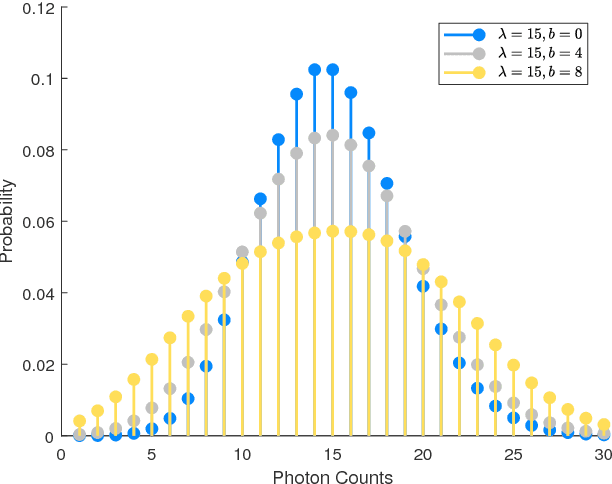
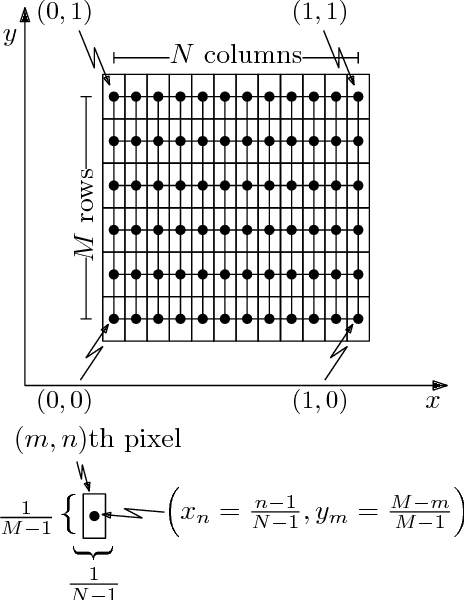
When determining the parameters of a parametric planar shape based on a single low-resolution image, common estimation paradigms lead to inaccurate parameter estimates. The reason behind poor estimation results is that standard estimation frameworks fail to model the image formation process at a sufficiently detailed level of analysis. We propose a new method for estimating the parameters of a planar elliptic shape based on a single photon-limited, low-resolution image. Our technique incorporates the effects of several elements - the point-spread function, the discretisation step, the quantisation step and photon noise - into a single cohesive and manageable statistical model. While we concentrate on the particular task of estimating the parameters of elliptic shapes, our ideas and methods have a much broader scope and can be used to address the problem of estimating the parameters of an arbitrary parametrically representable planar shape. Comprehensive experimental results on simulated and real imagery demonstrate that our approach yields parameter estimates with unprecedented accuracy. Furthermore, our method supplies a parameter covariance matrix as a measure of uncertainty for the estimated parameters, as well as a planar confidence region as a means for visualising the parameter uncertainty. The mathematical model developed in this paper may prove useful in a variety of disciplines which operate with imagery at the limits of resolution.
Iterative PET Image Reconstruction Using Convolutional Neural Network Representation
Oct 09, 2017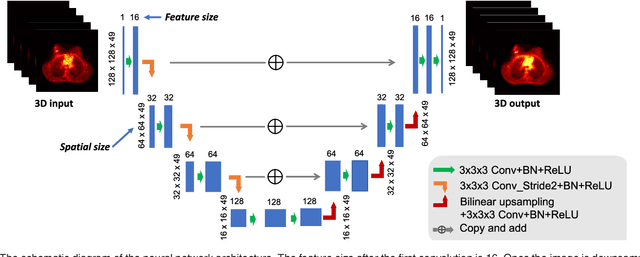
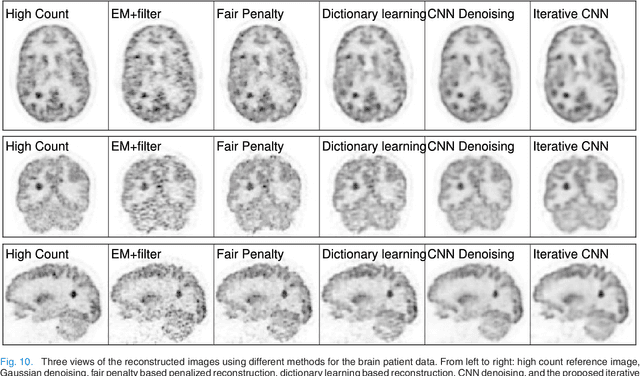
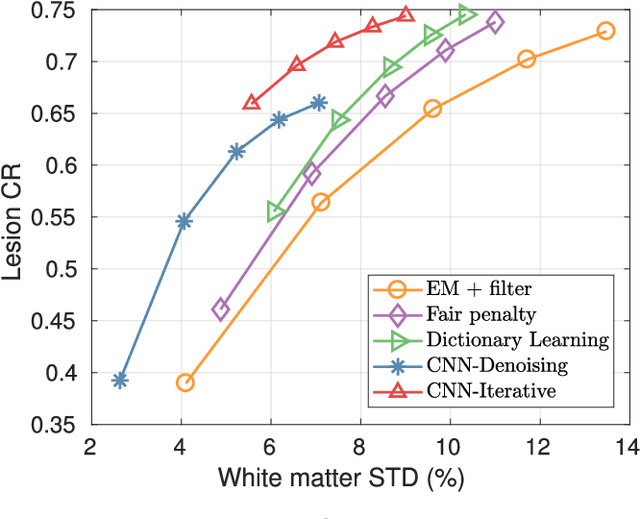
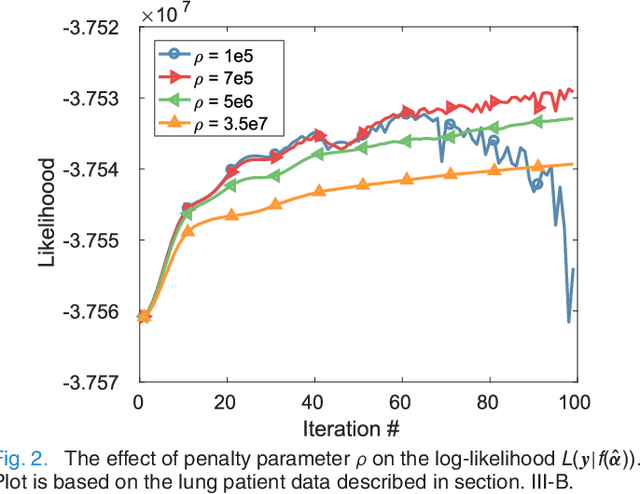
PET image reconstruction is challenging due to the ill-poseness of the inverse problem and limited number of detected photons. Recently deep neural networks have been widely and successfully used in computer vision tasks and attracted growing interests in medical imaging. In this work, we trained a deep residual convolutional neural network to improve PET image quality by using the existing inter-patient information. An innovative feature of the proposed method is that we embed the neural network in the iterative reconstruction framework for image representation, rather than using it as a post-processing tool. We formulate the objective function as a constraint optimization problem and solve it using the alternating direction method of multipliers (ADMM) algorithm. Both simulation data and hybrid real data are used to evaluate the proposed method. Quantification results show that our proposed iterative neural network method can outperform the neural network denoising and conventional penalized maximum likelihood methods.
C3VQG: Category Consistent Cyclic Visual Question Generation
May 30, 2020
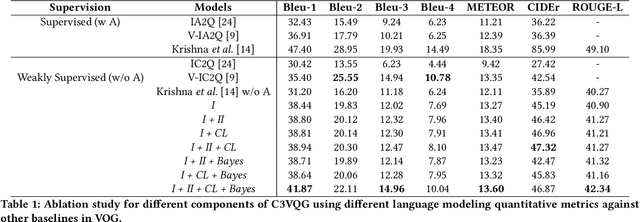
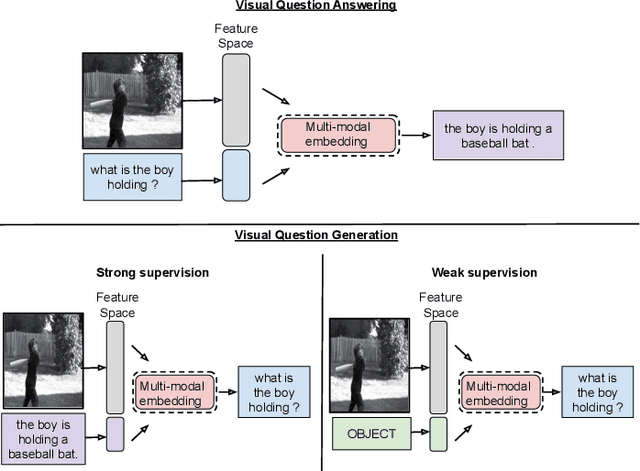
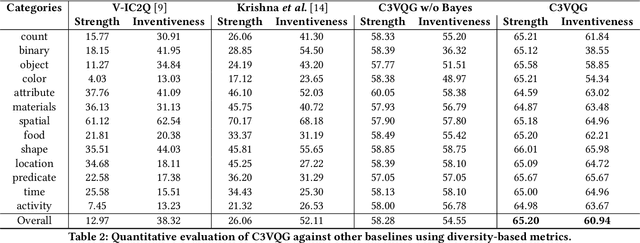
Visual Question Generation (VQG) is the task of generating natural questions based on an image. Popular methods in the past have explored image-to-sequence architectures trained with maximum likelihood which have demonstrated meaningful generated questions given an image and its associated ground-truth answer. VQG becomes more challenging if the image contains rich context information describing its different semantic categories. In this paper, we try to exploit the different visual cues and concepts in an image to generate questions using a variational autoencoder (VAE) without ground-truth answers. Our approach solves two major shortcomings of existing VQG systems: (i) minimize the level of supervision and (ii) replace generic questions with category relevant generations. Most importantly, through eliminating expensive answer annotations, the required supervision is weakened. Using different categories enables us to exploit different concepts as the inference requires only the image and category. Mutual information is maximized between the image, question, and answer category in the latent space of our VAE. A novel category consistent cyclic loss is proposed to enable the model to generate consistent predictions with respect to the answer category, reducing its redundancies and irregularities. Additionally, we also impose supplementary constraints on the latent space of our generative model to provide structure based on categories and enhance generalization by encapsulating decorrelated features within each dimension. Through extensive experiments, the proposed C3VQG outperforms the state-of-the-art visual question generation methods with weak supervision.
Probabilistic Vehicle Reconstruction Using a Multi-Task CNN
Feb 21, 2021
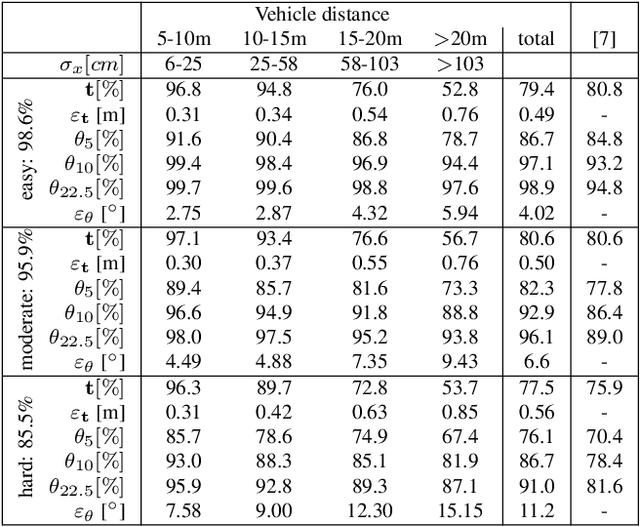
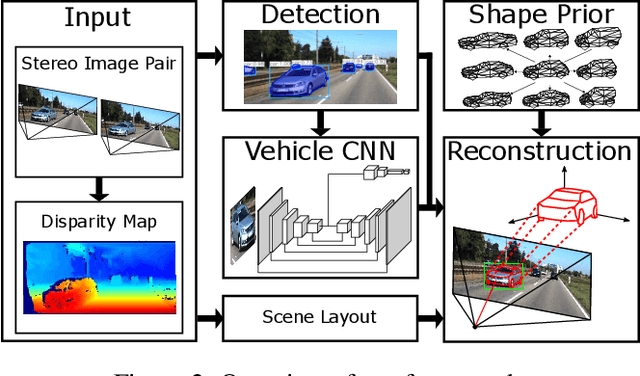

The retrieval of the 3D pose and shape of objects from images is an ill-posed problem. A common way to object reconstruction is to match entities such as keypoints, edges, or contours of a deformable 3D model, used as shape prior, to their corresponding entities inferred from the image. However, such approaches are highly sensitive to model initialisation, imprecise keypoint localisations and/or illumination conditions. In this paper, we present a probabilistic approach for shape-aware 3D vehicle reconstruction from stereo images that leverages the outputs of a novel multi-task CNN. Specifically, we train a CNN that outputs probability distributions for the vehicle's orientation and for both, vehicle keypoints and wireframe edges. Together with 3D stereo information we integrate the predicted distributions into a common probabilistic framework. We believe that the CNN-based detection of wireframe edges reduces the sensitivity to illumination conditions and object contrast and that using the raw probability maps instead of inferring keypoint positions reduces the sensitivity to keypoint localisation errors. We show that our method achieves state-of-the-art results, evaluating our method on the challenging KITTI benchmark and on our own new 'Stereo-Vehicle' dataset.
Fusion of Real Time Thermal Image and 1D/2D/3D Depth Laser Readings for Remote Thermal Sensing in Industrial Plants by Means of UAVs and/or Robots
Jun 04, 2020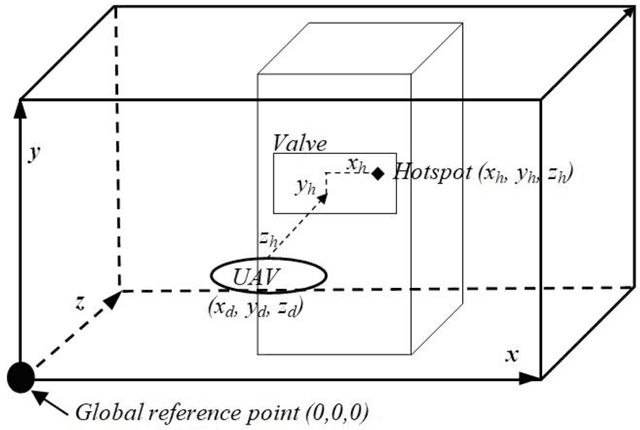


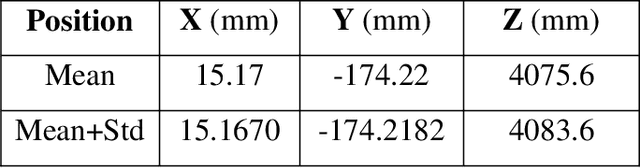
This paper presents fast procedures for thermal infrared remote sensing in dark, GPS-denied environments, such as those found in industrial plants such as in High-Voltage Direct Current (HVDC) converter stations. These procedures are based on the combination of the depth estimation obtained from either a 1-Dimensional LIDAR laser or a 2-Dimensional Hokuyo laser or a 3D MultiSense SLB laser sensor and the visible and thermal cameras from a FLIR Duo R dual-sensor thermal camera. The combination of these sensors/cameras is suitable to be mounted on Unmanned Aerial Vehicles (UAVs) and/or robots in order to provide reliable information about the potential malfunctions, which can be found within the hazardous environment. For example, the capabilities of the developed software and hardware system corresponding to the combination of the 1-D LIDAR sensor and the FLIR Duo R dual-sensor thermal camera is assessed from the point of the accuracy of results and the required computational times: the obtained computational times are under 10 ms, with a maximum localization error of 8 mm and an average standard deviation for the measured temperatures of 1.11 degree Celsius, which results are obtained for a number of test cases. The paper is structured as follows: the description of the system used for identification and localization of hotspots in industrial plants is presented in section II. In section III, the method for faults identification and localization in plants by using a 1-Dimensional LIDAR laser sensor and thermal images is described together with results. In section IV the real time thermal image processing is presented. Fusion of the 2-Dimensional depth laser Hokuyo and the thermal images is described in section V. In section VI the combination of the 3D MultiSense SLB laser and thermal images is described. In section VII a discussion and several conclusions are drawn.