 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Appearance Learning for Image-based Motion Estimation in Tomography
Jun 18, 2020
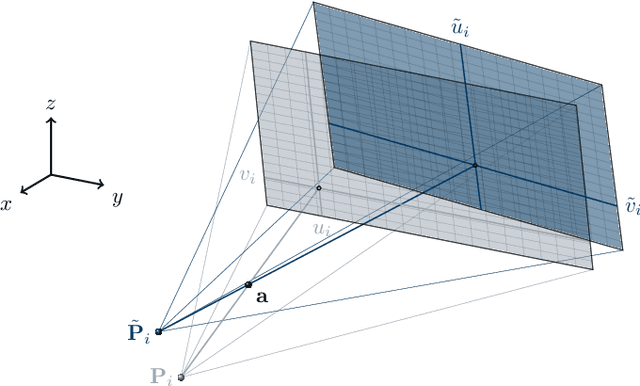
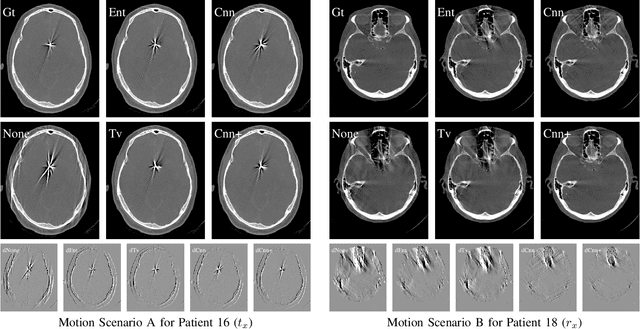
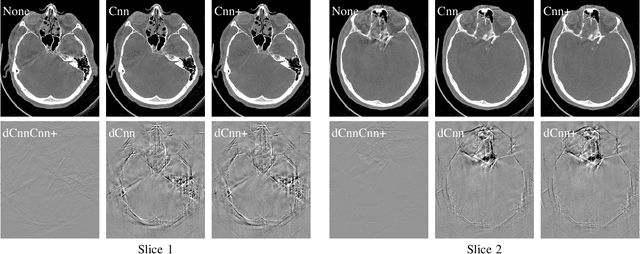
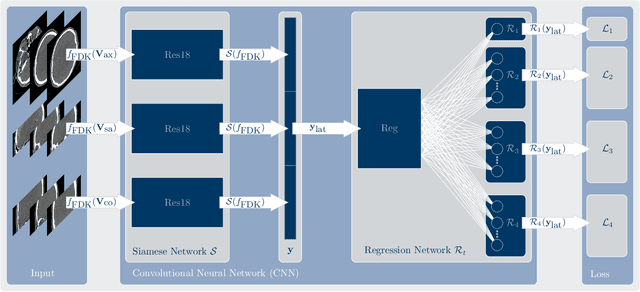
In tomographic imaging, anatomical structures are reconstructed by applying a pseudo-inverse forward model to acquired signals. Geometric information within this process is usually depending on the system setting only, i. e., the scanner position or readout direction. Patient motion therefore corrupts the geometry alignment in the reconstruction process resulting in motion artifacts. We propose an appearance learning approach recognizing the structures of rigid motion independently from the scanned object. To this end, we train a siamese triplet network to predict the reprojection error (RPE) for the complete acquisition as well as an approximate distribution of the RPE along the single views from the reconstructed volume in a multi-task learning approach. The RPE measures the motioninduced geometric deviations independent of the object based on virtual marker positions, which are available during training. We train our network using 27 patients and deploy a 21-4-2 split for training, validation and testing. In average, we achieve a residual mean RPE of 0.013mm with an inter-patient standard deviation of 0.022 mm. This is twice the accuracy compared to previously published results. In a motion estimation benchmark the proposed approach achieves superior results in comparison with two state-of-the-art measures in nine out of twelve experiments. The clinical applicability of the proposed method is demonstrated on a motion-affected clinical dataset.
Riemannian-based Discriminant Analysis for Feature Extraction and Classification
Jan 20, 2021
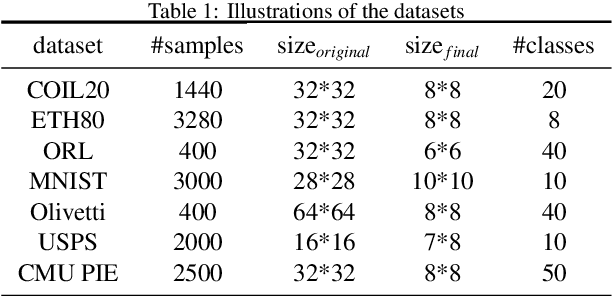
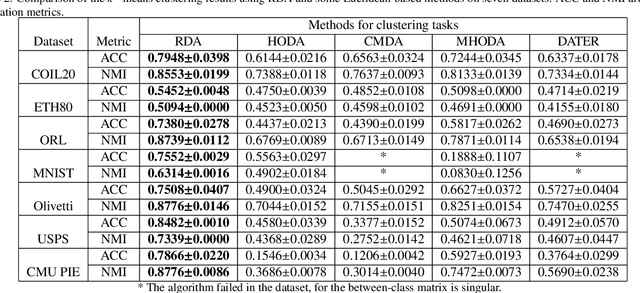
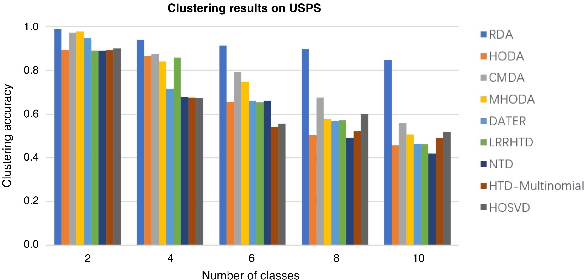
Discriminant analysis, as a widely used approach in machine learning to extract low-dimensional features from the high-dimensional data, applies the Fisher discriminant criterion to find the orthogonal discriminant projection subspace. But most of the Euclidean-based algorithms for discriminant analysis are easily convergent to a spurious local minima and hardly obtain an unique solution. To address such problem, in this study we propose a novel method named Riemannian-based Discriminant Analysis (RDA), which transforms the traditional Euclidean-based methods to the Riemannian manifold space. In RDA, the second-order geometry of trust-region methods is utilized to learn the discriminant bases. To validate the efficiency and effectiveness of RDA, we conduct a variety of experiments on image classification tasks. The numerical results suggest that RDA can extract statistically significant features and robustly outperform state-of-the-art algorithms in classification tasks.
Anonymization of labeled TOF-MRA images for brain vessel segmentation using generative adversarial networks
Sep 09, 2020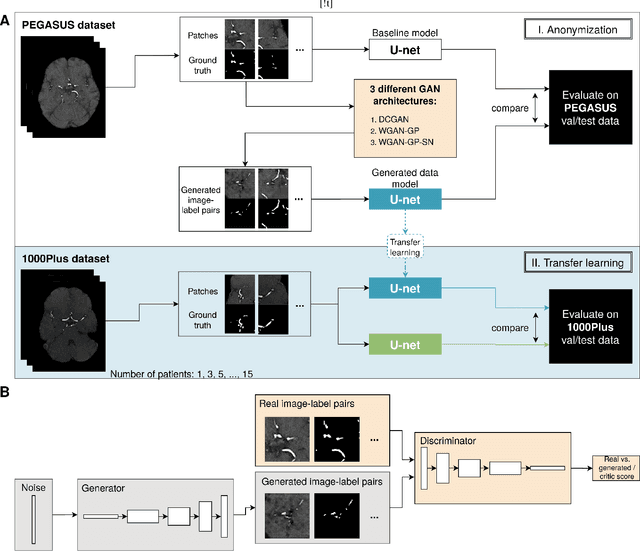
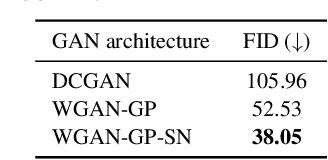

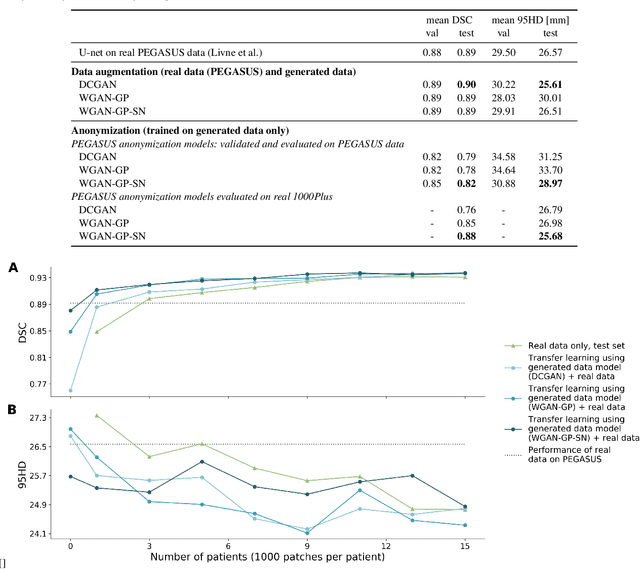
Anonymization and data sharing are crucial for privacy protection and acquisition of large datasets for medical image analysis. This is a big challenge, especially for neuroimaging. Here, the brain's unique structure allows for re-identification and thus requires non-conventional anonymization. Generative adversarial networks (GANs) have the potential to provide anonymous images while preserving predictive properties. Analyzing brain vessel segmentation as a use case, we trained 3 GANs on time-of-flight (TOF) magnetic resonance angiography (MRA) patches for image-label generation: 1) Deep convolutional GAN, 2) Wasserstein-GAN with gradient penalty (WGAN-GP) and 3) WGAN-GP with spectral normalization (WGAN-GP-SN). The generated image-labels from each GAN were used to train a U-net for segmentation and tested on real data. Moreover, we applied our synthetic patches using transfer learning on a second dataset. For an increasing number of up to 15 patients we evaluated the model performance on real data with and without pre-training. The performance for all models was assessed by the Dice Similarity Coefficient (DSC) and the 95th percentile of the Hausdorff Distance (95HD). Comparing the 3 GANs, the U-net trained on synthetic data generated by the WGAN-GP-SN showed the highest performance to predict vessels (DSC/95HD 0.82/28.97) benchmarked by the U-net trained on real data (0.89/26.61). The transfer learning approach showed superior performance for the same GAN compared to no pre-training, especially for one patient only (0.91/25.68 vs. 0.85/27.36). In this work, synthetic image-label pairs retained generalizable information and showed good performance for vessel segmentation. Besides, we showed that synthetic patches can be used in a transfer learning approach with independent data. This paves the way to overcome the challenges of scarce data and anonymization in medical imaging.
Deep Label Fusion: A 3D End-to-End Hybrid Multi-Atlas Segmentation and Deep Learning Pipeline
Mar 19, 2021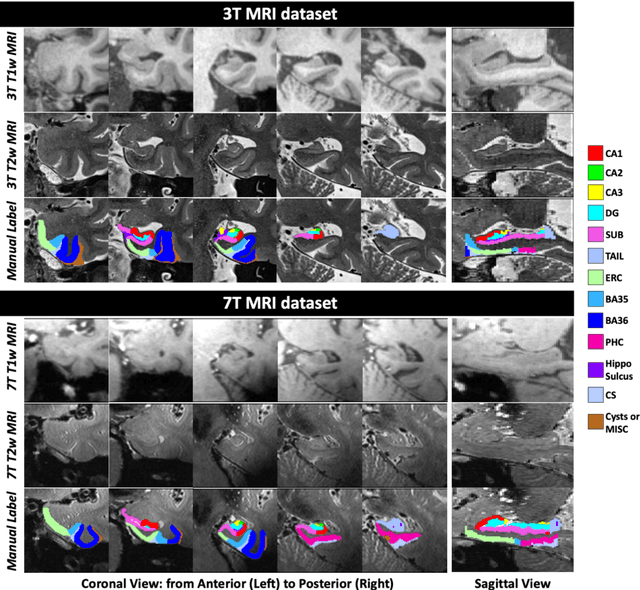
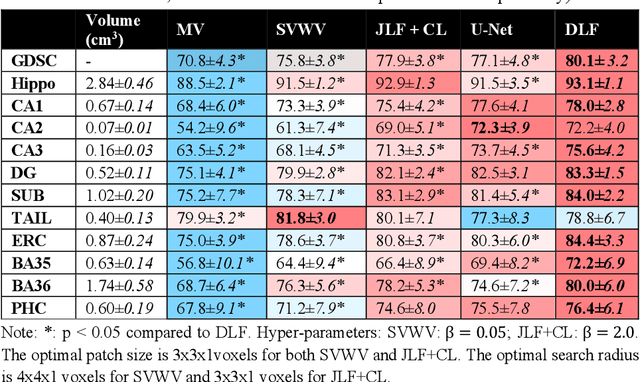
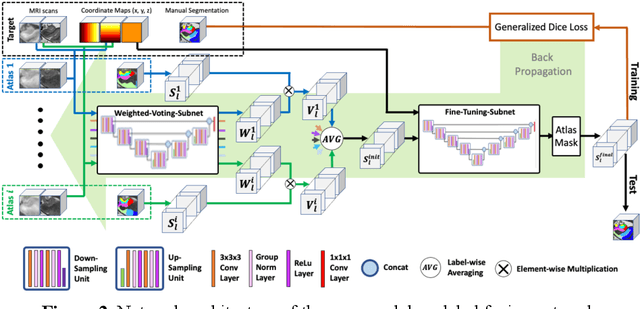
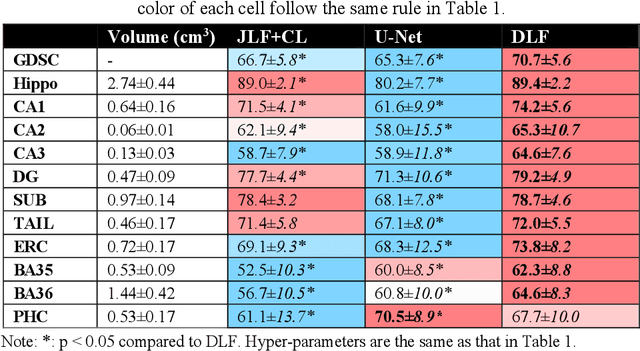
Deep learning (DL) is the state-of-the-art methodology in various medical image segmentation tasks. However, it requires relatively large amounts of manually labeled training data, which may be infeasible to generate in some applications. In addition, DL methods have relatively poor generalizability to out-of-sample data. Multi-atlas segmentation (MAS), on the other hand, has promising performance using limited amounts of training data and good generalizability. A hybrid method that integrates the high accuracy of DL and good generalizability of MAS is highly desired and could play an important role in segmentation problems where manually labeled data is hard to generate. Most of the prior work focuses on improving single components of MAS using DL rather than directly optimizing the final segmentation accuracy via an end-to-end pipeline. Only one study explored this idea in binary segmentation of 2D images, but it remains unknown whether it generalizes well to multi-class 3D segmentation problems. In this study, we propose a 3D end-to-end hybrid pipeline, named deep label fusion (DLF), that takes advantage of the strengths of MAS and DL. Experimental results demonstrate that DLF yields significant improvements over conventional label fusion methods and U-Net, a direct DL approach, in the context of segmenting medial temporal lobe subregions using 3T T1-weighted and T2-weighted MRI. Further, when applied to an unseen similar dataset acquired in 7T, DLF maintains its superior performance, which demonstrates its good generalizability.
On the effectiveness of adversarial training against common corruptions
Mar 03, 2021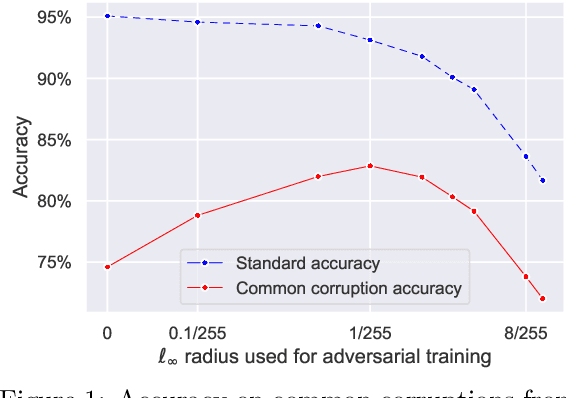

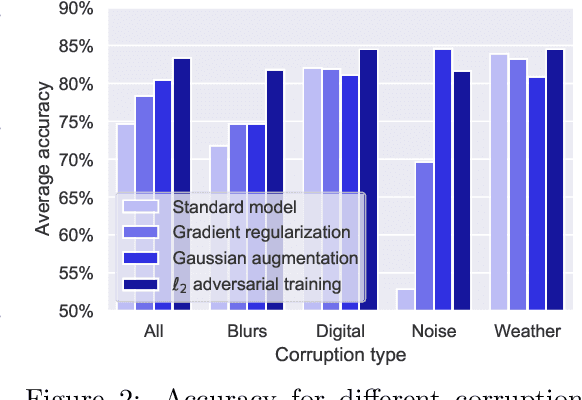

The literature on robustness towards common corruptions shows no consensus on whether adversarial training can improve the performance in this setting. First, we show that, when used with an appropriately selected perturbation radius, $\ell_p$ adversarial training can serve as a strong baseline against common corruptions. Then we explain why adversarial training performs better than data augmentation with simple Gaussian noise which has been observed to be a meaningful baseline on common corruptions. Related to this, we identify the $\sigma$-overfitting phenomenon when Gaussian augmentation overfits to a particular standard deviation used for training which has a significant detrimental effect on common corruption accuracy. We discuss how to alleviate this problem and then how to further enhance $\ell_p$ adversarial training by introducing an efficient relaxation of adversarial training with learned perceptual image patch similarity as the distance metric. Through experiments on CIFAR-10 and ImageNet-100, we show that our approach does not only improve the $\ell_p$ adversarial training baseline but also has cumulative gains with data augmentation methods such as AugMix, ANT, and SIN leading to state-of-the-art performance on common corruptions. The code of our experiments is publicly available at https://github.com/tml-epfl/adv-training-corruptions.
Quality-aware semi-supervised learning for CMR segmentation
Sep 01, 2020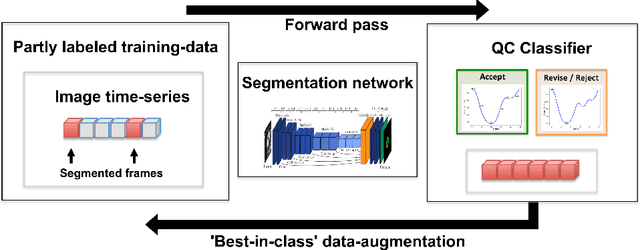
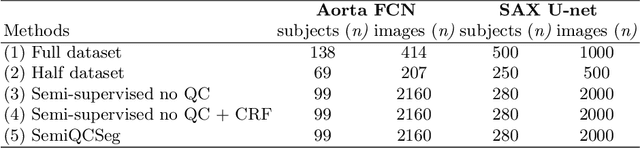
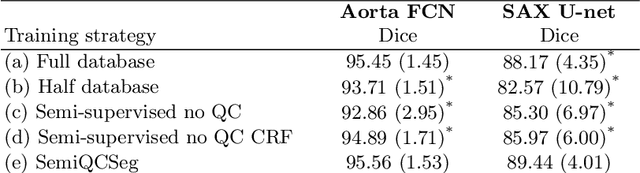
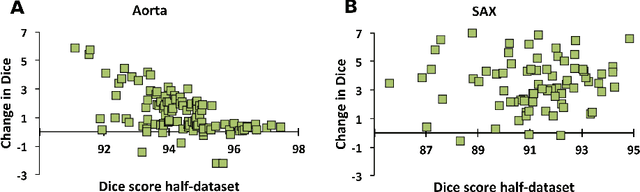
One of the challenges in developing deep learning algorithms for medical image segmentation is the scarcity of annotated training data. To overcome this limitation, data augmentation and semi-supervised learning (SSL) methods have been developed. However, these methods have limited effectiveness as they either exploit the existing data set only (data augmentation) or risk negative impact by adding poor training examples (SSL). Segmentations are rarely the final product of medical image analysis - they are typically used in downstream tasks to infer higher-order patterns to evaluate diseases. Clinicians take into account a wealth of prior knowledge on biophysics and physiology when evaluating image analysis results. We have used these clinical assessments in previous works to create robust quality-control (QC) classifiers for automated cardiac magnetic resonance (CMR) analysis. In this paper, we propose a novel scheme that uses QC of the downstream task to identify high quality outputs of CMR segmentation networks, that are subsequently utilised for further network training. In essence, this provides quality-aware augmentation of training data in a variant of SSL for segmentation networks (semiQCSeg). We evaluate our approach in two CMR segmentation tasks (aortic and short axis cardiac volume segmentation) using UK Biobank data and two commonly used network architectures (U-net and a Fully Convolutional Network) and compare against supervised and SSL strategies. We show that semiQCSeg improves training of the segmentation networks. It decreases the need for labelled data, while outperforming the other methods in terms of Dice and clinical metrics. SemiQCSeg can be an efficient approach for training segmentation networks for medical image data when labelled datasets are scarce.
A Neuro-Inspired Autoencoding Defense Against Adversarial Perturbations
Dec 21, 2020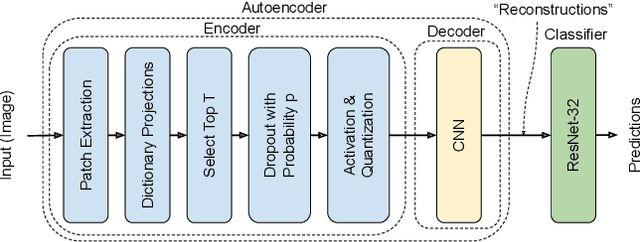

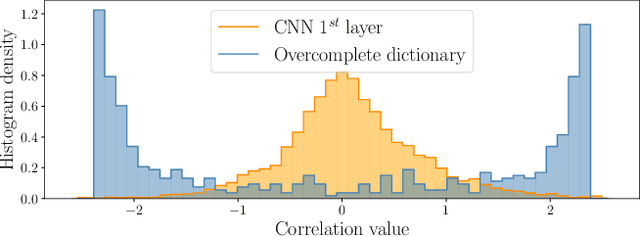
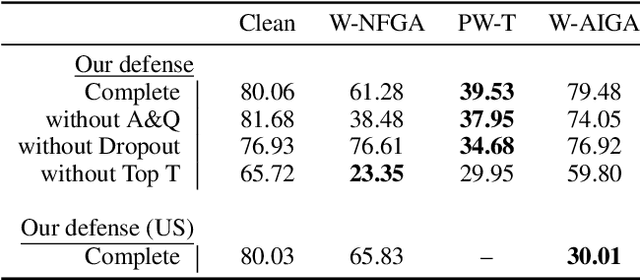
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks: carefully constructed perturbations to an image can seriously impair classification accuracy, while being imperceptible to humans. While there has been a significant amount of research on defending against such attacks, most defenses based on systematic design principles have been defeated by appropriately modified attacks. For a fixed set of data, the most effective current defense is to train the network using adversarially perturbed examples. In this paper, we investigate a radically different, neuro-inspired defense mechanism, starting from the observation that human vision is virtually unaffected by adversarial examples designed for machines. We aim to reject L^inf bounded adversarial perturbations before they reach a classifier DNN, using an encoder with characteristics commonly observed in biological vision: sparse overcomplete representations, randomness due to synaptic noise, and drastic nonlinearities. Encoder training is unsupervised, using standard dictionary learning. A CNN-based decoder restores the size of the encoder output to that of the original image, enabling the use of a standard CNN for classification. Our nominal design is to train the decoder and classifier together in standard supervised fashion, but we also consider unsupervised decoder training based on a regression objective (as in a conventional autoencoder) with separate supervised training of the classifier. Unlike adversarial training, all training is based on clean images. Our experiments on the CIFAR-10 show performance competitive with state-of-the-art defenses based on adversarial training, and point to the promise of neuro-inspired techniques for the design of robust neural networks. In addition, we provide results for a subset of the Imagenet dataset to verify that our approach scales to larger images.
Enhancing Object Detection for Autonomous Driving by Optimizing Anchor Generation and Addressing Class Imbalance
Apr 08, 2021
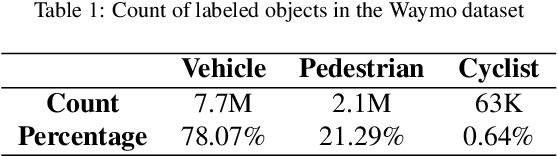

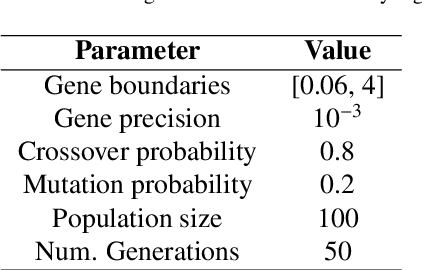
Object detection has been one of the most active topics in computer vision for the past years. Recent works have mainly focused on pushing the state-of-the-art in the general-purpose COCO benchmark. However, the use of such detection frameworks in specific applications such as autonomous driving is yet an area to be addressed. This study presents an enhanced 2D object detector based on Faster R-CNN that is better suited for the context of autonomous vehicles. Two main aspects are improved: the anchor generation procedure and the performance drop in minority classes. The default uniform anchor configuration is not suitable in this scenario due to the perspective projection of the vehicle cameras. Therefore, we propose a perspective-aware methodology that divides the image into key regions via clustering and uses evolutionary algorithms to optimize the base anchors for each of them. Furthermore, we add a module that enhances the precision of the second-stage header network by including the spatial information of the candidate regions proposed in the first stage. We also explore different re-weighting strategies to address the foreground-foreground class imbalance, showing that the use of a reduced version of focal loss can significantly improve the detection of difficult and underrepresented objects in two-stage detectors. Finally, we design an ensemble model to combine the strengths of the different learning strategies. Our proposal is evaluated with the Waymo Open Dataset, which is the most extensive and diverse up to date. The results demonstrate an average accuracy improvement of 6.13% mAP when using the best single model, and of 9.69% mAP with the ensemble. The proposed modifications over the Faster R-CNN do not increase computational cost and can easily be extended to optimize other anchor-based detection frameworks.
Learning Local Complex Features using Randomized Neural Networks for Texture Analysis
Jul 10, 2020
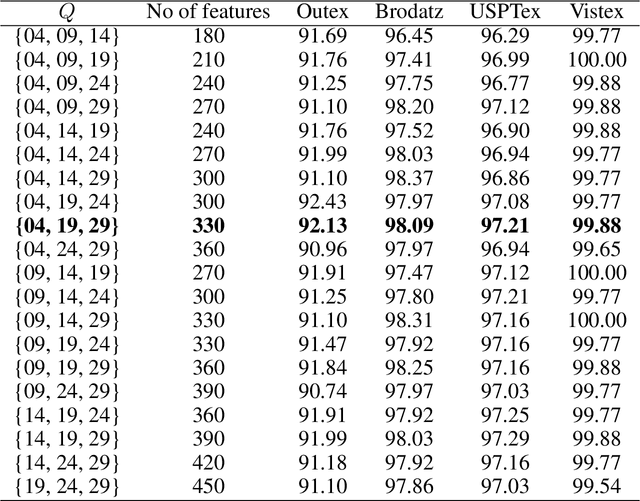
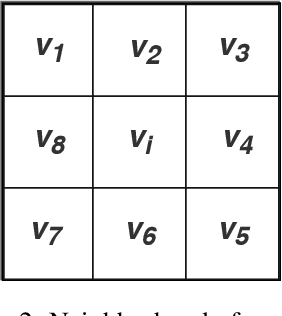
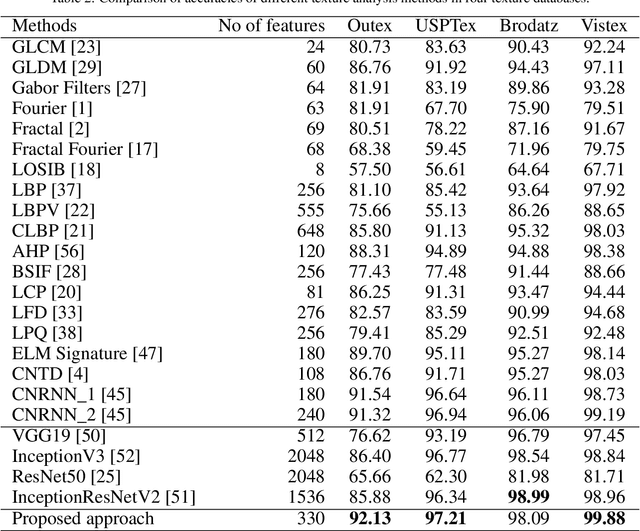
Texture is a visual attribute largely used in many problems of image analysis. Currently, many methods that use learning techniques have been proposed for texture discrimination, achieving improved performance over previous handcrafted methods. In this paper, we present a new approach that combines a learning technique and the Complex Network (CN) theory for texture analysis. This method takes advantage of the representation capacity of CN to model a texture image as a directed network and uses the topological information of vertices to train a randomized neural network. This neural network has a single hidden layer and uses a fast learning algorithm, which is able to learn local CN patterns for texture characterization. Thus, we use the weighs of the trained neural network to compose a feature vector. These feature vectors are evaluated in a classification experiment in four widely used image databases. Experimental results show a high classification performance of the proposed method when compared to other methods, indicating that our approach can be used in many image analysis problems.
Unsupervised Vehicle Re-Identification via Self-supervised Metric Learning using Feature Dictionary
Mar 03, 2021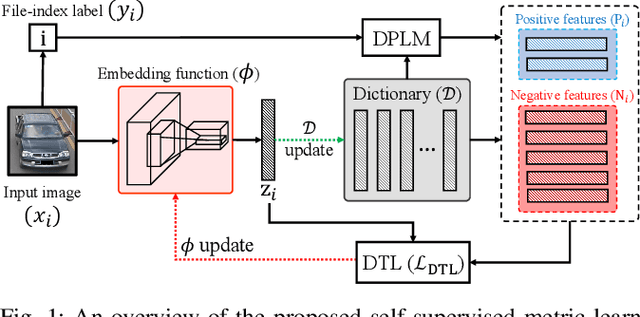
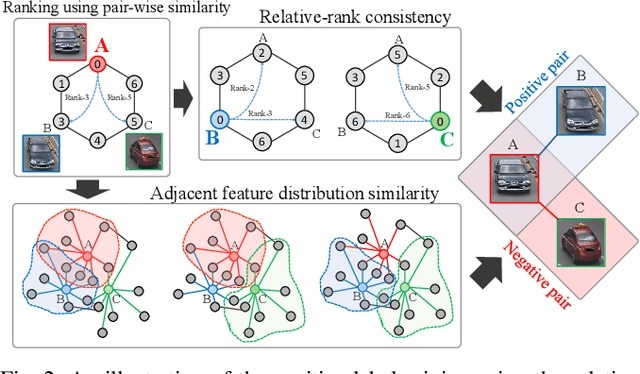
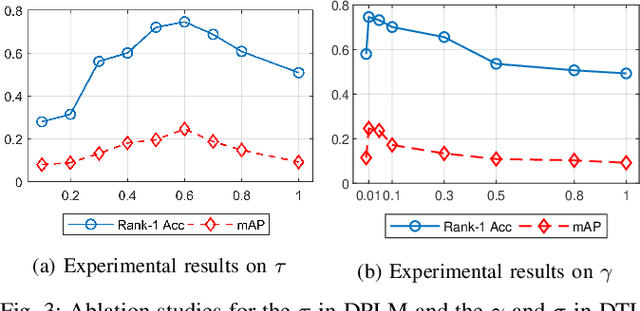
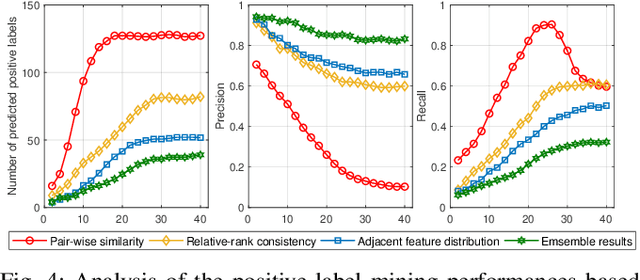
The key challenge of unsupervised vehicle re-identification (Re-ID) is learning discriminative features from unlabelled vehicle images. Numerous methods using domain adaptation have achieved outstanding performance, but those methods still need a labelled dataset as a source domain. This paper addresses an unsupervised vehicle Re-ID method, which no need any types of a labelled dataset, through a Self-supervised Metric Learning (SSML) based on a feature dictionary. Our method initially extracts features from vehicle images and stores them in a dictionary. Thereafter, based on the dictionary, the proposed method conducts dictionary-based positive label mining (DPLM) to search for positive labels. Pair-wise similarity, relative-rank consistency, and adjacent feature distribution similarity are jointly considered to find images that may belong to the same vehicle of a given probe image. The results of DPLM are applied to dictionary-based triplet loss (DTL) to improve the discriminativeness of learnt features and to refine the quality of the results of DPLM progressively. The iterative process with DPLM and DTL boosts the performance of unsupervised vehicle Re-ID. Experimental results demonstrate the effectiveness of the proposed method by producing promising vehicle Re-ID performance without a pre-labelled dataset. The source code for this paper is publicly available on `https://github.com/andreYoo/VeRI_SSML_FD.git'.