 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Dec 15, 2020
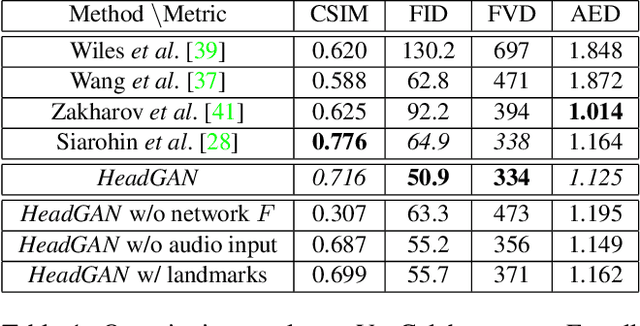
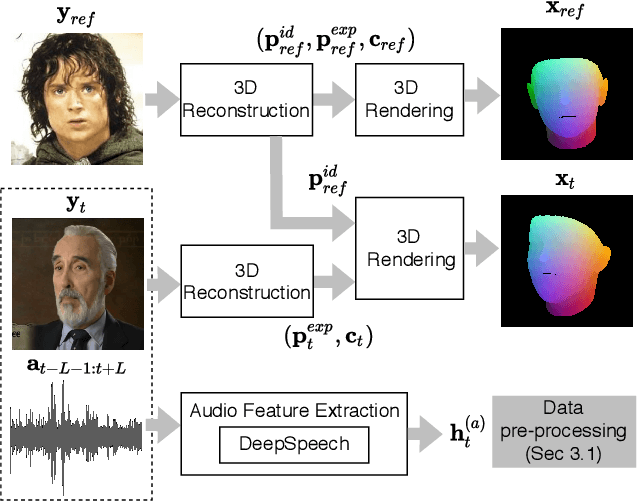
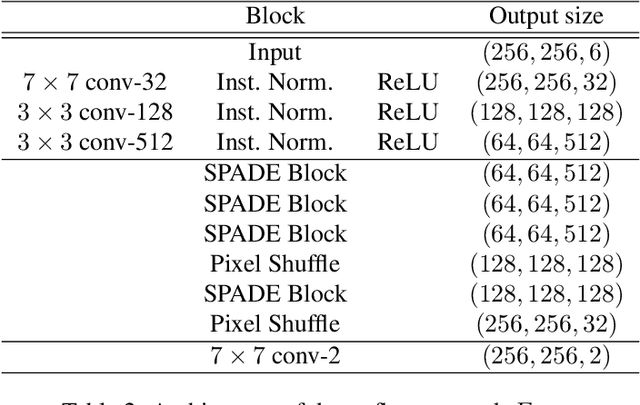
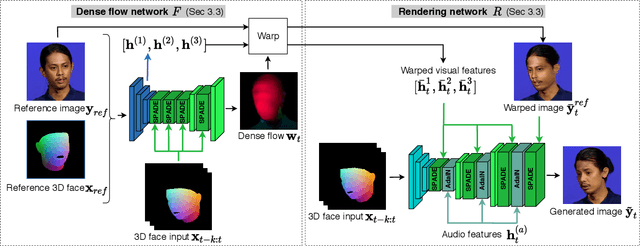
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.
Image Generation for Efficient Neural Network Training in Autonomous Drone Racing
Aug 06, 2020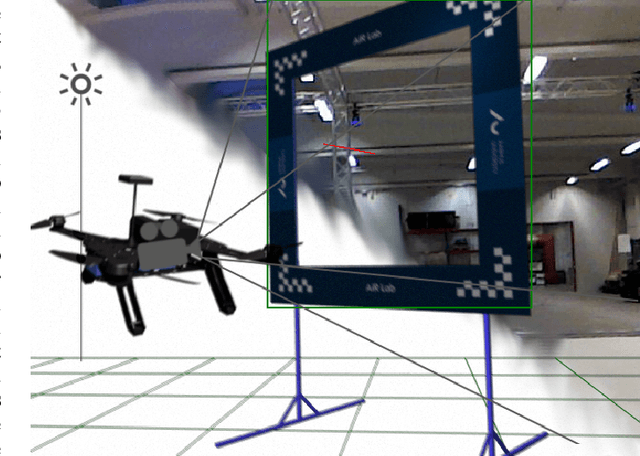
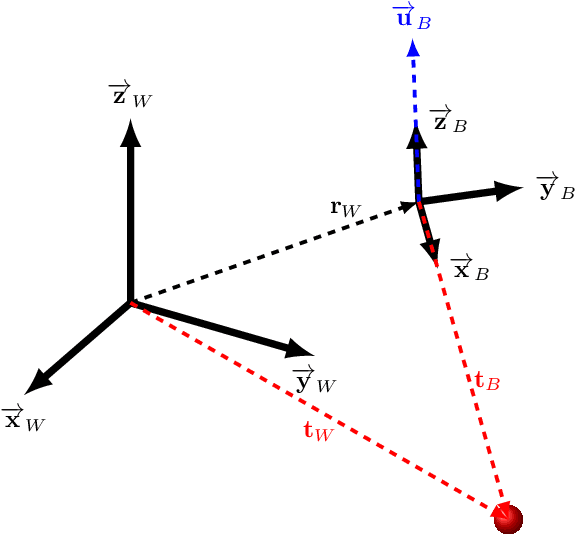
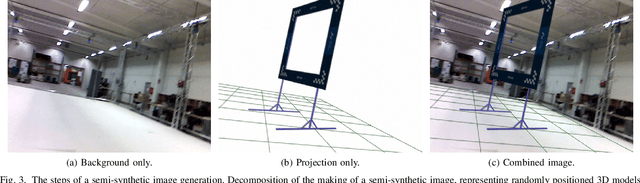

Drone racing is a recreational sport in which the goal is to pass through a sequence of gates in a minimum amount of time while avoiding collisions. In autonomous drone racing, one must accomplish this task by flying fully autonomously in an unknown environment by relying only on computer vision methods for detecting the target gates. Due to the challenges such as background objects and varying lighting conditions, traditional object detection algorithms based on colour or geometry tend to fail. Convolutional neural networks offer impressive advances in computer vision but require an immense amount of data to learn. Collecting this data is a tedious process because the drone has to be flown manually, and the data collected can suffer from sensor failures. In this work, a semi-synthetic dataset generation method is proposed, using a combination of real background images and randomised 3D renders of the gates, to provide a limitless amount of training samples that do not suffer from those drawbacks. Using the detection results, a line-of-sight guidance algorithm is used to cross the gates. In several experimental real-time tests, the proposed framework successfully demonstrates fast and reliable detection and navigation.
DeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021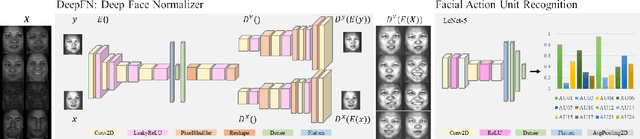
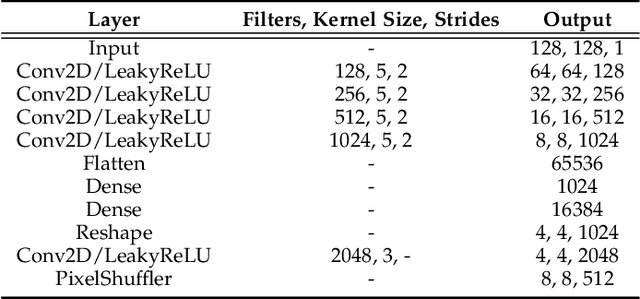
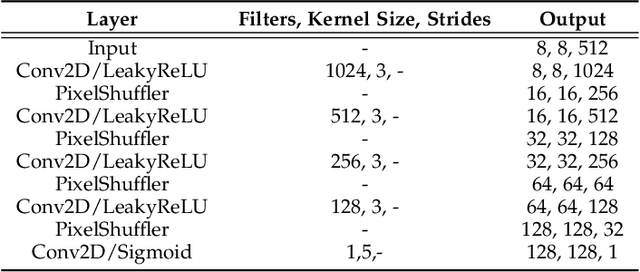
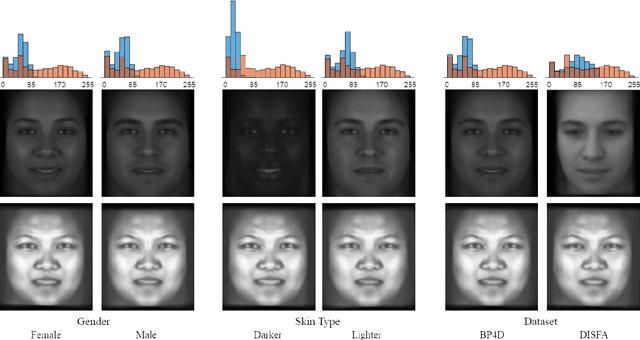
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
Enhancing Object Detection for Autonomous Driving by Optimizing Anchor Generation and Addressing Class Imbalance
Apr 08, 2021
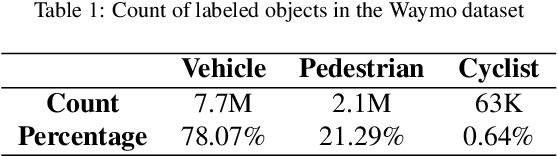

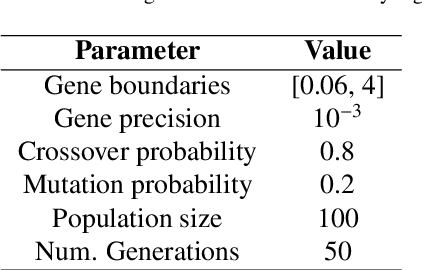
Object detection has been one of the most active topics in computer vision for the past years. Recent works have mainly focused on pushing the state-of-the-art in the general-purpose COCO benchmark. However, the use of such detection frameworks in specific applications such as autonomous driving is yet an area to be addressed. This study presents an enhanced 2D object detector based on Faster R-CNN that is better suited for the context of autonomous vehicles. Two main aspects are improved: the anchor generation procedure and the performance drop in minority classes. The default uniform anchor configuration is not suitable in this scenario due to the perspective projection of the vehicle cameras. Therefore, we propose a perspective-aware methodology that divides the image into key regions via clustering and uses evolutionary algorithms to optimize the base anchors for each of them. Furthermore, we add a module that enhances the precision of the second-stage header network by including the spatial information of the candidate regions proposed in the first stage. We also explore different re-weighting strategies to address the foreground-foreground class imbalance, showing that the use of a reduced version of focal loss can significantly improve the detection of difficult and underrepresented objects in two-stage detectors. Finally, we design an ensemble model to combine the strengths of the different learning strategies. Our proposal is evaluated with the Waymo Open Dataset, which is the most extensive and diverse up to date. The results demonstrate an average accuracy improvement of 6.13% mAP when using the best single model, and of 9.69% mAP with the ensemble. The proposed modifications over the Faster R-CNN do not increase computational cost and can easily be extended to optimize other anchor-based detection frameworks.
Deep Label Fusion: A 3D End-to-End Hybrid Multi-Atlas Segmentation and Deep Learning Pipeline
Mar 19, 2021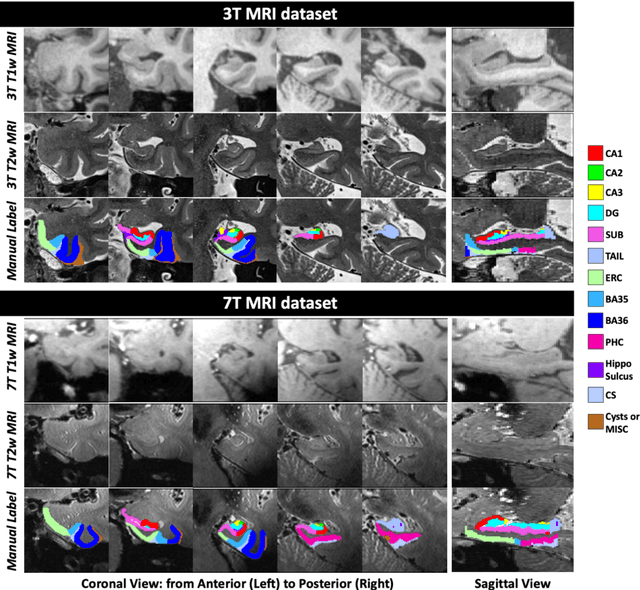
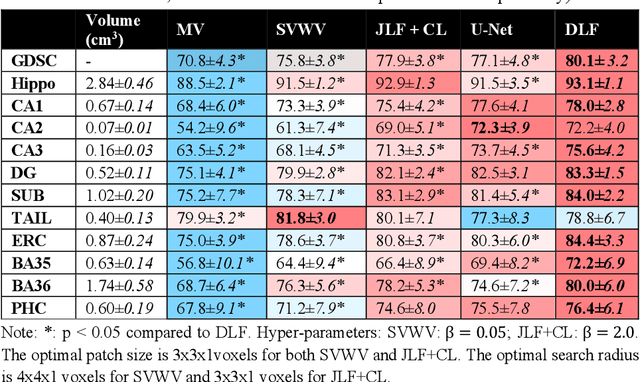
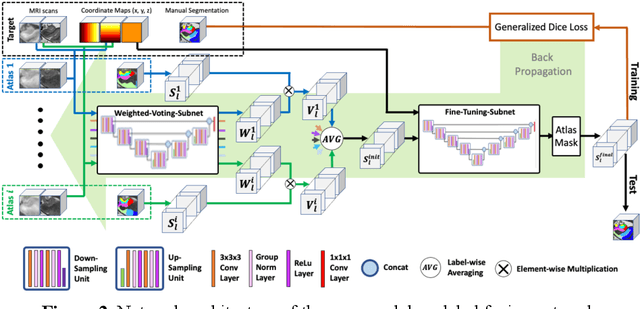
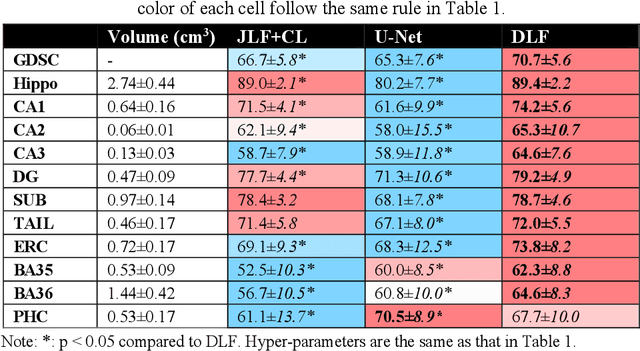
Deep learning (DL) is the state-of-the-art methodology in various medical image segmentation tasks. However, it requires relatively large amounts of manually labeled training data, which may be infeasible to generate in some applications. In addition, DL methods have relatively poor generalizability to out-of-sample data. Multi-atlas segmentation (MAS), on the other hand, has promising performance using limited amounts of training data and good generalizability. A hybrid method that integrates the high accuracy of DL and good generalizability of MAS is highly desired and could play an important role in segmentation problems where manually labeled data is hard to generate. Most of the prior work focuses on improving single components of MAS using DL rather than directly optimizing the final segmentation accuracy via an end-to-end pipeline. Only one study explored this idea in binary segmentation of 2D images, but it remains unknown whether it generalizes well to multi-class 3D segmentation problems. In this study, we propose a 3D end-to-end hybrid pipeline, named deep label fusion (DLF), that takes advantage of the strengths of MAS and DL. Experimental results demonstrate that DLF yields significant improvements over conventional label fusion methods and U-Net, a direct DL approach, in the context of segmenting medial temporal lobe subregions using 3T T1-weighted and T2-weighted MRI. Further, when applied to an unseen similar dataset acquired in 7T, DLF maintains its superior performance, which demonstrates its good generalizability.
Counterfactual Explanation and Causal Inference in Service of Robustness in Robot Control
Sep 22, 2020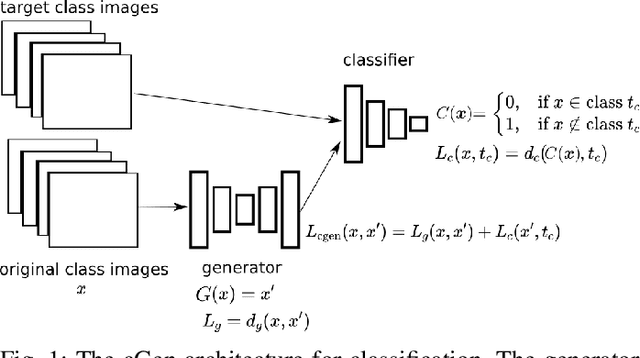


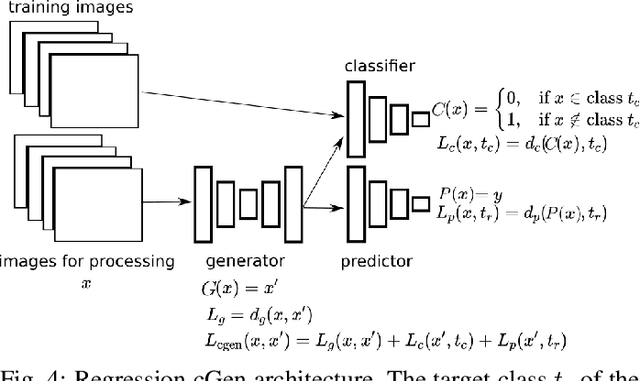
We propose an architecture for training generative models of counterfactual conditionals of the form, 'can we modify event A to cause B instead of C?', motivated by applications in robot control. Using an 'adversarial training' paradigm, an image-based deep neural network model is trained to produce small and realistic modifications to an original image in order to cause user-defined effects. These modifications can be used in the design process of image-based robust control - to determine the ability of the controller to return to a working regime by modifications in the input space, rather than by adaptation. In contrast to conventional control design approaches, where robustness is quantified in terms of the ability to reject noise, we explore the space of counterfactuals that might cause a certain requirement to be violated, thus proposing an alternative model that might be more expressive in certain robotics applications. So, we propose the generation of counterfactuals as an approach to explanation of black-box models and the envisioning of potential movement paths in autonomous robotic control. Firstly, we demonstrate this approach in a set of classification tasks, using the well known MNIST and CelebFaces Attributes datasets. Then, addressing multi-dimensional regression, we demonstrate our approach in a reaching task with a physical robot, and in a navigation task with a robot in a digital twin simulation.
Learning of Art Style Using AI and Its Evaluation Based on Psychological Experiments
May 04, 2020
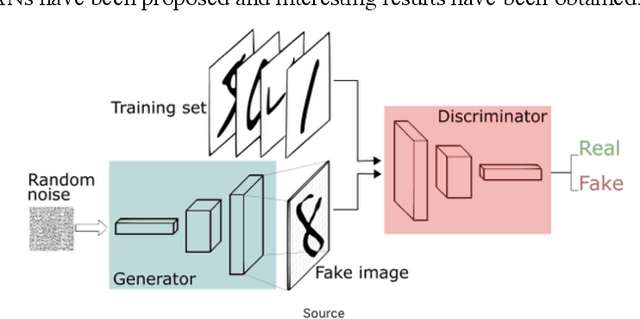
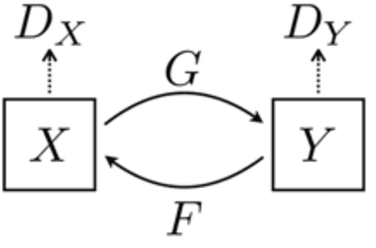

GANs (Generative adversarial networks) is a new AI technology that can perform deep learning with less training data and has the capability of achieving transformation between two image sets. Using GAN we have carried out a comparison between several art sets with different art style. We have prepared several image sets; a flower photo set (A), an art image set (B1) of Impressionism drawings, an art image set of abstract paintings (B2), an art image set of Chinese figurative paintings, (B3), and an art image set of abstract images (B4) created by Naoko Tosa, one of the authors. Transformation between set A to each of B was carried out using GAN and four image sets (B1, B2, B3, B4) was obtained. Using these four image sets we have carried out psychological experiment by asking subjects consisting of 23 students to fill in questionnaires. By analyzing the obtained questionnaires, we have found the followings. Abstract drawings and figurative drawings are clearly judged to be different. Figurative drawings in West and East were judged to be similar. Abstract images by Naoko Tosa were judged as similar to Western abstract images. These results show that AI could be used as an analysis tool to reveal differences between art genres.
Deep Reinforcement Learning with Mixed Convolutional Network
Oct 01, 2020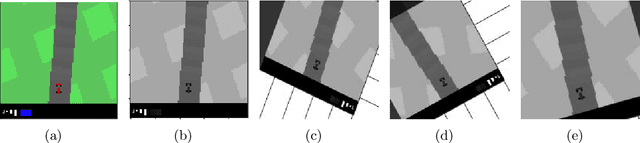
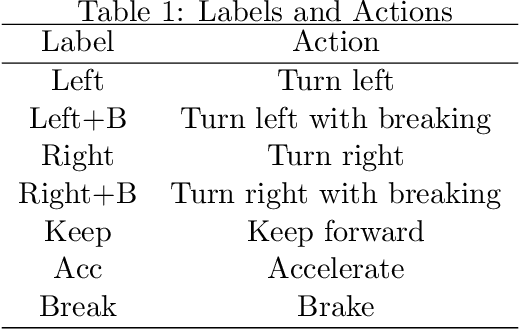
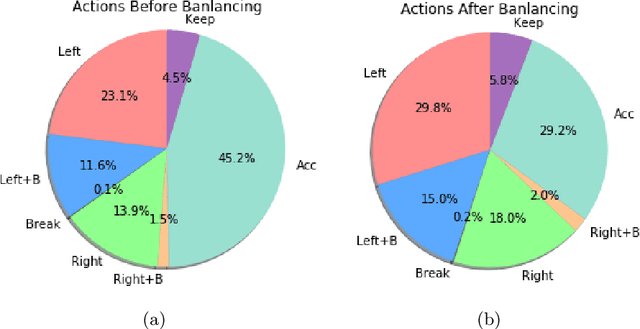
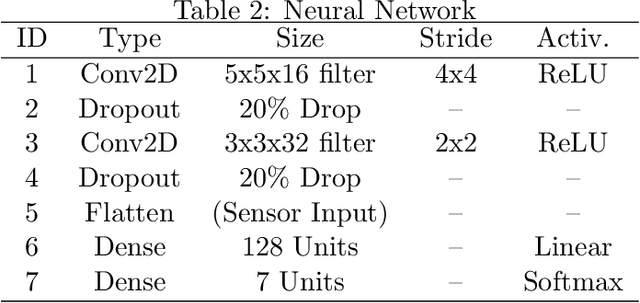
Recent research has shown that map raw pixels from a single front-facing camera directly to steering commands are surprisingly powerful. This paper presents a convolutional neural network (CNN) to playing the CarRacing-v0 using imitation learning in OpenAI Gym. The dataset is generated by playing the game manually in Gym and used a data augmentation method to expand the dataset to 4 times larger than before. Also, we read the true speed, four ABS sensors, steering wheel position, and gyroscope for each image and designed a mixed model by combining the sensor input and image input. After training, this model can automatically detect the boundaries of road features and drive the robot like a human. By comparing with AlexNet and VGG16 using the average reward in CarRacing-v0, our model wins the maximum overall system performance.
ParaNet: Deep Regular Representation for 3D Point Clouds
Dec 05, 2020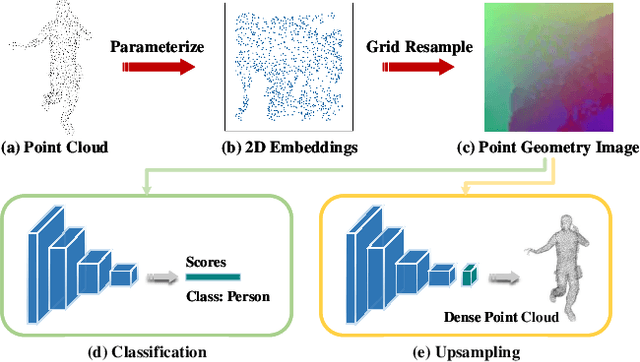
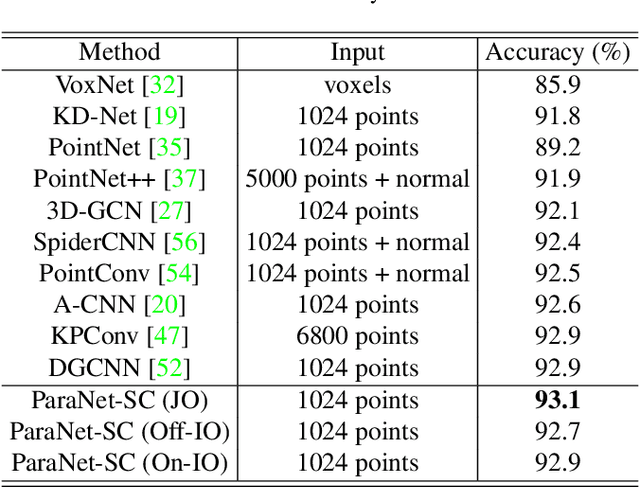
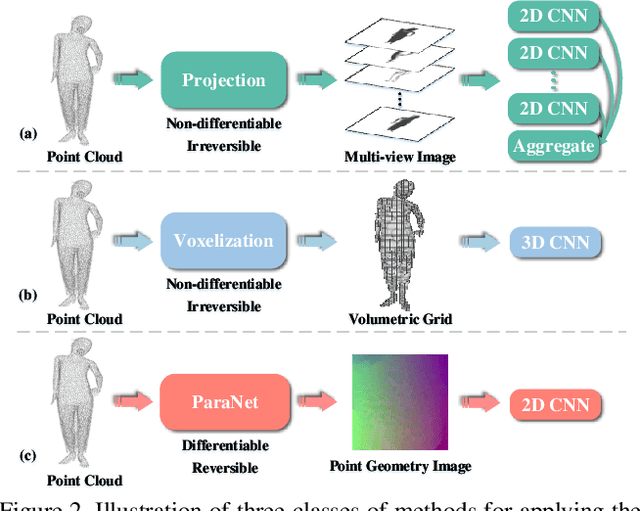

Although convolutional neural networks have achieved remarkable success in analyzing 2D images/videos, it is still non-trivial to apply the well-developed 2D techniques in regular domains to the irregular 3D point cloud data. To bridge this gap, we propose ParaNet, a novel end-to-end deep learning framework, for representing 3D point clouds in a completely regular and nearly lossless manner. To be specific, ParaNet converts an irregular 3D point cloud into a regular 2D color image, named point geometry image (PGI), where each pixel encodes the spatial coordinates of a point. In contrast to conventional regular representation modalities based on multi-view projection and voxelization, the proposed representation is differentiable and reversible. Technically, ParaNet is composed of a surface embedding module, which parameterizes 3D surface points onto a unit square, and a grid resampling module, which resamples the embedded 2D manifold over regular dense grids. Note that ParaNet is unsupervised, i.e., the training simply relies on reference-free geometry constraints. The PGIs can be seamlessly coupled with a task network established upon standard and mature techniques for 2D images/videos to realize a specific task for 3D point clouds. We evaluate ParaNet over shape classification and point cloud upsampling, in which our solutions perform favorably against the existing state-of-the-art methods. We believe such a paradigm will open up many possibilities to advance the progress of deep learning-based point cloud processing and understanding.
On the effectiveness of adversarial training against common corruptions
Mar 03, 2021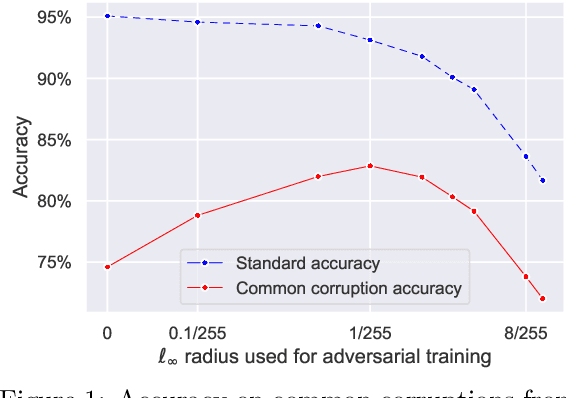

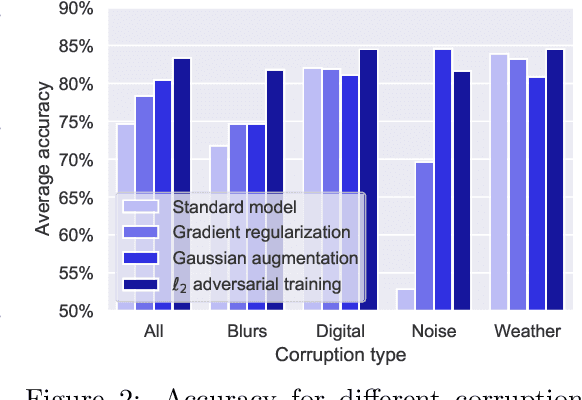

The literature on robustness towards common corruptions shows no consensus on whether adversarial training can improve the performance in this setting. First, we show that, when used with an appropriately selected perturbation radius, $\ell_p$ adversarial training can serve as a strong baseline against common corruptions. Then we explain why adversarial training performs better than data augmentation with simple Gaussian noise which has been observed to be a meaningful baseline on common corruptions. Related to this, we identify the $\sigma$-overfitting phenomenon when Gaussian augmentation overfits to a particular standard deviation used for training which has a significant detrimental effect on common corruption accuracy. We discuss how to alleviate this problem and then how to further enhance $\ell_p$ adversarial training by introducing an efficient relaxation of adversarial training with learned perceptual image patch similarity as the distance metric. Through experiments on CIFAR-10 and ImageNet-100, we show that our approach does not only improve the $\ell_p$ adversarial training baseline but also has cumulative gains with data augmentation methods such as AugMix, ANT, and SIN leading to state-of-the-art performance on common corruptions. The code of our experiments is publicly available at https://github.com/tml-epfl/adv-training-corruptions.