 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-Image Depth Perception in the Wild
Jan 06, 2017
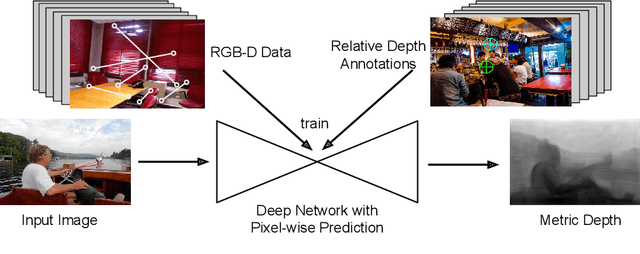
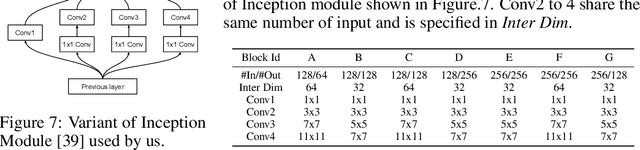

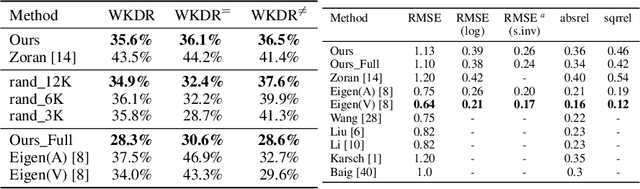
This paper studies single-image depth perception in the wild, i.e., recovering depth from a single image taken in unconstrained settings. We introduce a new dataset "Depth in the Wild" consisting of images in the wild annotated with relative depth between pairs of random points. We also propose a new algorithm that learns to estimate metric depth using annotations of relative depth. Compared to the state of the art, our algorithm is simpler and performs better. Experiments show that our algorithm, combined with existing RGB-D data and our new relative depth annotations, significantly improves single-image depth perception in the wild.
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 16, 2021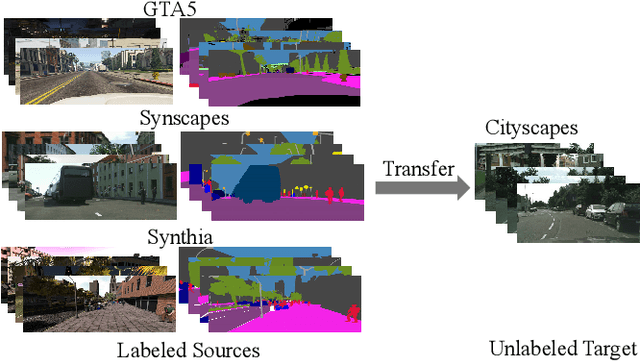
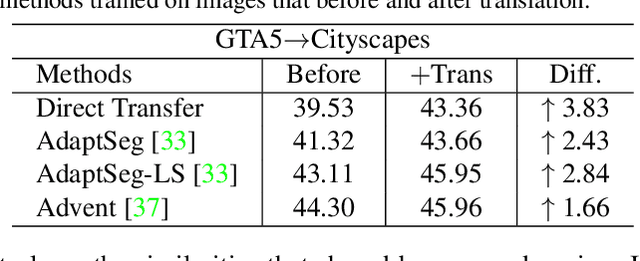
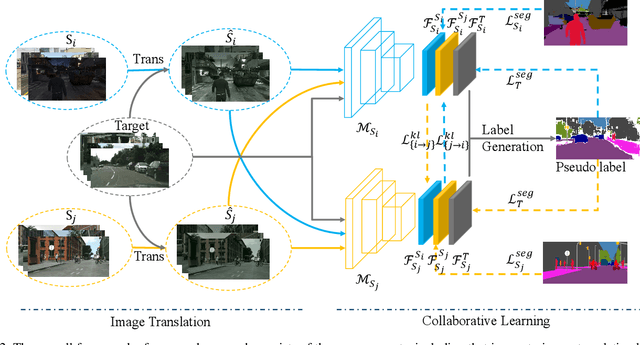
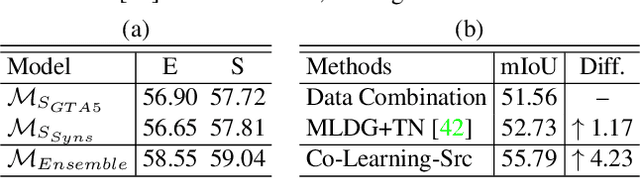
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.
Do Input Gradients Highlight Discriminative Features?
Feb 25, 2021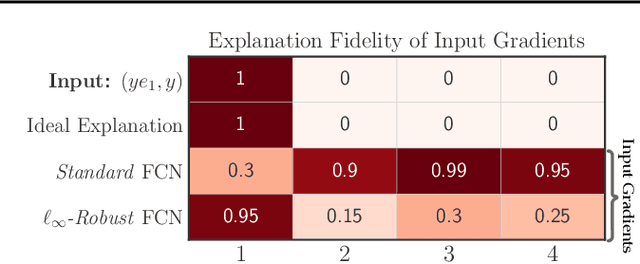

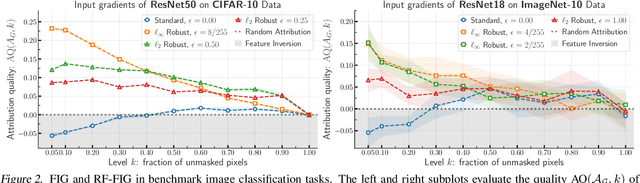
Interpretability methods that seek to explain instance-specific model predictions [Simonyan et al. 2014, Smilkov et al. 2017] are often based on the premise that the magnitude of input-gradient -- gradient of the loss with respect to input -- highlights discriminative features that are relevant for prediction over non-discriminative features that are irrelevant for prediction. In this work, we introduce an evaluation framework to study this hypothesis for benchmark image classification tasks, and make two surprising observations on CIFAR-10 and Imagenet-10 datasets: (a) contrary to conventional wisdom, input gradients of standard models (i.e., trained on the original data) actually highlight irrelevant features over relevant features; (b) however, input gradients of adversarially robust models (i.e., trained on adversarially perturbed data) starkly highlight relevant features over irrelevant features. To better understand input gradients, we introduce a synthetic testbed and theoretically justify our counter-intuitive empirical findings. Our observations motivate the need to formalize and verify common assumptions in interpretability, while our evaluation framework and synthetic dataset serve as a testbed to rigorously analyze instance-specific interpretability methods.
SPAN: Spatial Pyramid Attention Network forImage Manipulation Localization
Sep 01, 2020
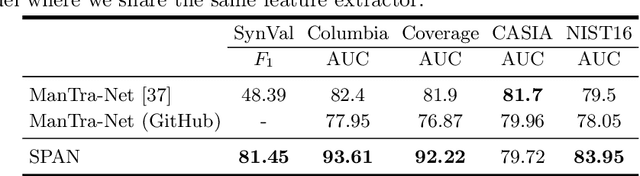
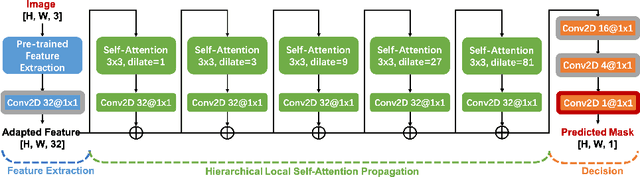
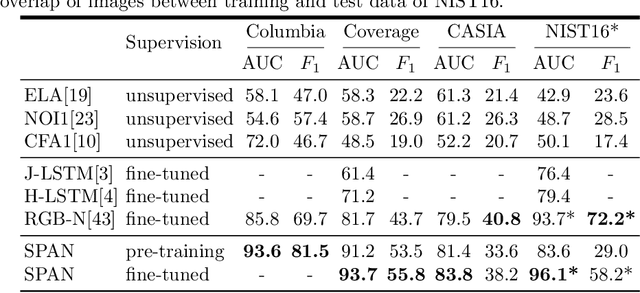
We present a novel framework, Spatial Pyramid Attention Network (SPAN) for detection and localization of multiple types of image manipulations. The proposed architecture efficiently and effectively models the relationship between image patches at multiple scales by constructing a pyramid of local self-attention blocks. The design includes a novel position projection to encode the spatial positions of the patches. SPAN is trained on a generic, synthetic dataset but can also be fine tuned for specific datasets; The proposed method shows significant gains in performance on standard datasets over previous state-of-the-art methods.
Demonstrating the Evolution of GANs through t-SNE
Feb 25, 2021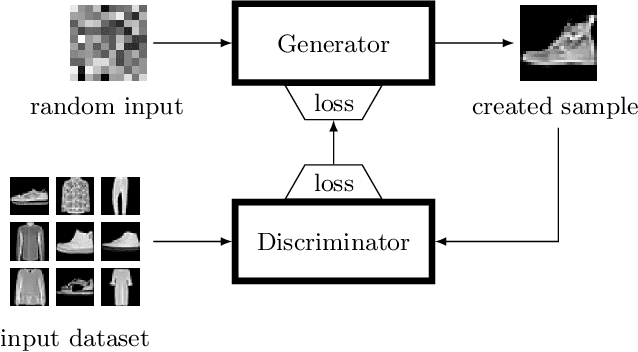
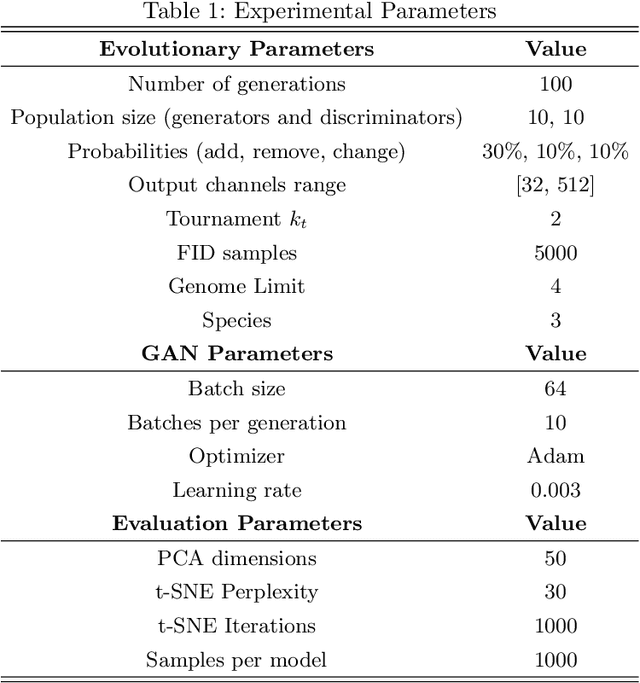
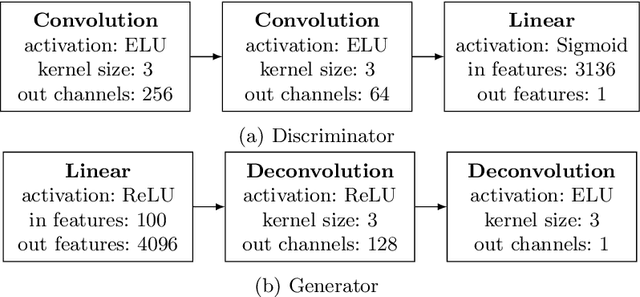
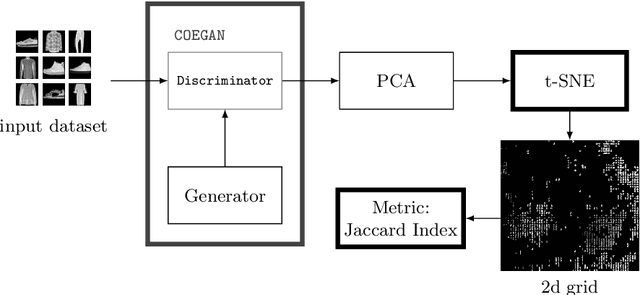
Generative Adversarial Networks (GANs) are powerful generative models that achieved strong results, mainly in the image domain. However, the training of GANs is not trivial, presenting some challenges tackled by different strategies. Evolutionary algorithms, such as COEGAN, were recently proposed as a solution to improve the GAN training, overcoming common problems that affect the model, such as vanishing gradient and mode collapse. In this work, we propose an evaluation method based on t-distributed Stochastic Neighbour Embedding (t-SNE) to assess the progress of GANs and visualize the distribution learned by generators in training. We propose the use of the feature space extracted from trained discriminators to evaluate samples produced by generators and from the input dataset. A metric based on the resulting t-SNE maps and the Jaccard index is proposed to represent the model quality. Experiments were conducted to assess the progress of GANs when trained using COEGAN. The results show both by visual inspection and metrics that the Evolutionary Algorithm gradually improves discriminators and generators through generations, avoiding problems such as mode collapse.
CAPTION: Correction by Analyses, POS-Tagging and Interpretation of Objects using only Nouns
Oct 02, 2020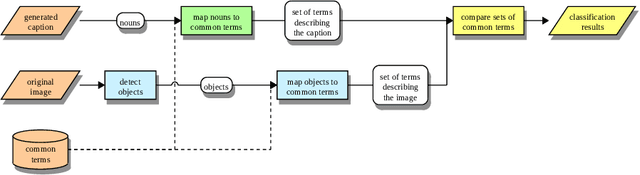
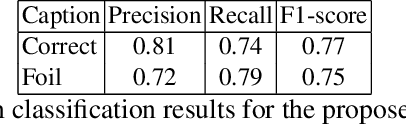

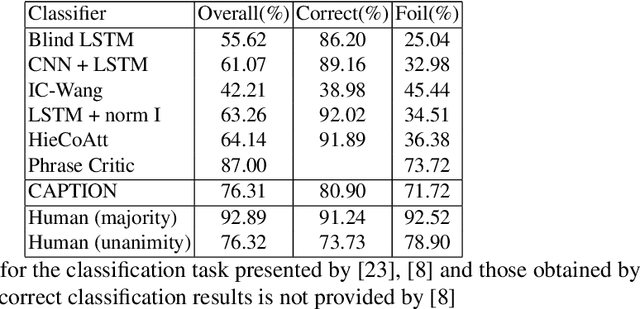
Recently, Deep Learning (DL) methods have shown an excellent performance in image captioning and visual question answering. However, despite their performance, DL methods do not learn the semantics of the words that are being used to describe a scene, making it difficult to spot incorrect words used in captions or to interchange words that have similar meanings. This work proposes a combination of DL methods for object detection and natural language processing to validate image's captions. We test our method in the FOIL-COCO data set, since it provides correct and incorrect captions for various images using only objects represented in the MS-COCO image data set. Results show that our method has a good overall performance, in some cases similar to the human performance.
GRAPPA-GANs for Parallel MRI Reconstruction
Jan 05, 2021
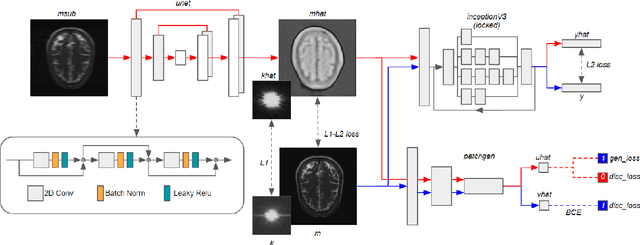
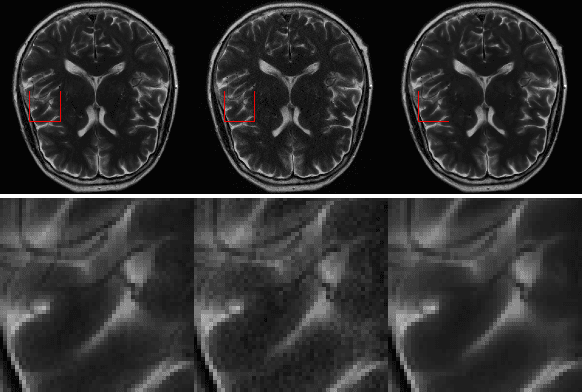
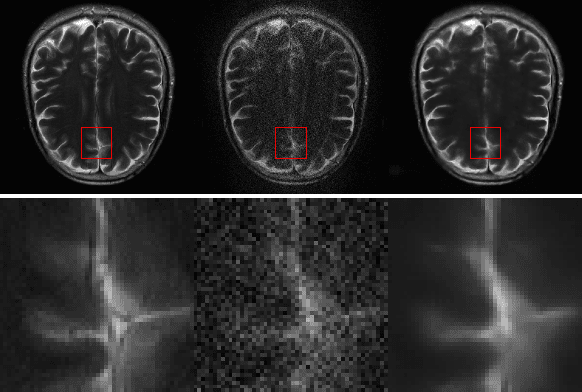
k-space undersampling is a standard technique to accelerate MR image acquisitions. Reconstruction techniques including GeneRalized Autocalibrating Partial Parallel Acquisition(GRAPPA) and its variants are utilized extensively in clinical and research settings. A reconstruction model combining GRAPPA with a conditional generative adversarial network (GAN) was developed and tested on multi-coil human brain images from the fastMRI dataset. For various acceleration rates, GAN and GRAPPA reconstructions were compared in terms of peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). For an acceleration rate of R=4, PSNR improved from 33.88 using regularized GRAPPA to 37.65 using GAN. GAN consistently outperformed GRAPPA for various acceleration rates.
Deep Depth Completion of a Single RGB-D Image
May 02, 2018

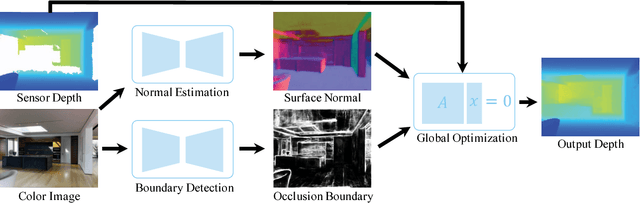
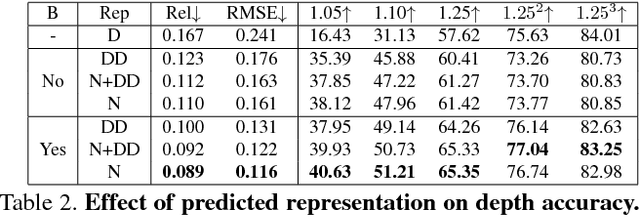
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions, optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.
Distributed Deep Learning Using Volunteer Computing-Like Paradigm
Mar 16, 2021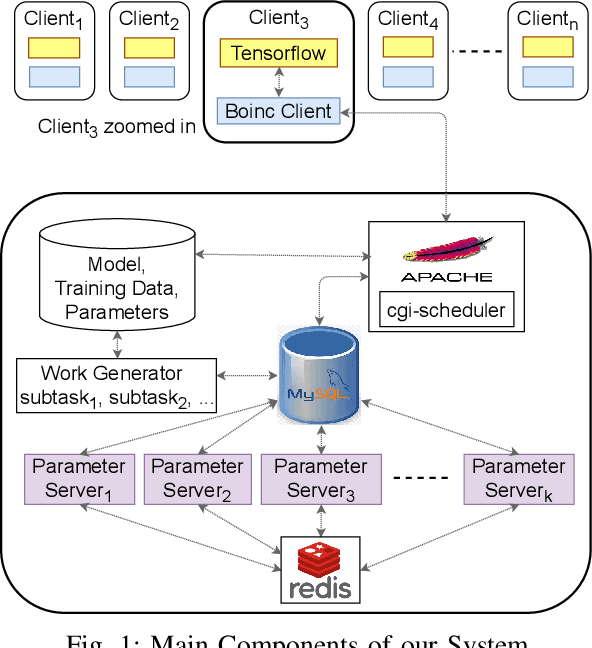
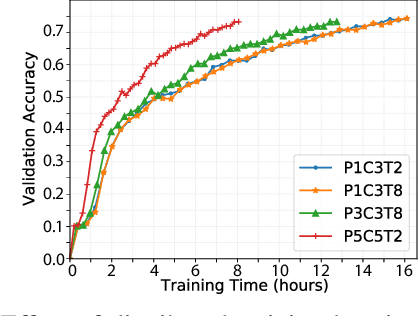
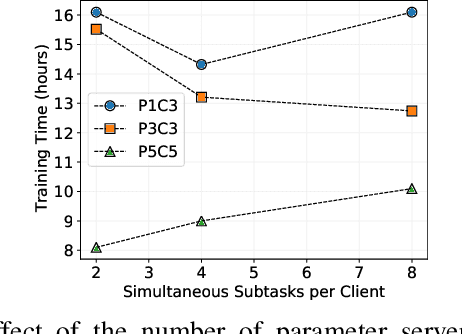
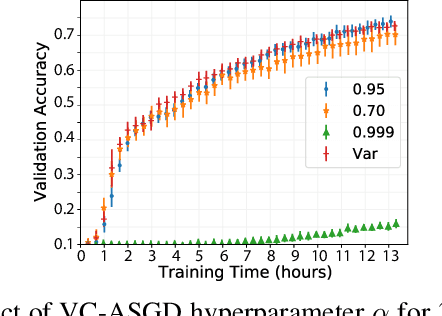
Use of Deep Learning (DL) in commercial applications such as image classification, sentiment analysis and speech recognition is increasing. When training DL models with large number of parameters and/or large datasets, cost and speed of training can become prohibitive. Distributed DL training solutions that split a training job into subtasks and execute them over multiple nodes can decrease training time. However, the cost of current solutions, built predominantly for cluster computing systems, can still be an issue. In contrast to cluster computing systems, Volunteer Computing (VC) systems can lower the cost of computing, but applications running on VC systems have to handle fault tolerance, variable network latency and heterogeneity of compute nodes, and the current solutions are not designed to do so. We design a distributed solution that can run DL training on a VC system by using a data parallel approach. We implement a novel asynchronous SGD scheme called VC-ASGD suited for VC systems. In contrast to traditional VC systems that lower cost by using untrustworthy volunteer devices, we lower cost by leveraging preemptible computing instances on commercial cloud platforms. By using preemptible instances that require applications to be fault tolerant, we lower cost by 70-90% and improve data security.
Efficient Scale-Permuted Backbone with Learned Resource Distribution
Oct 22, 2020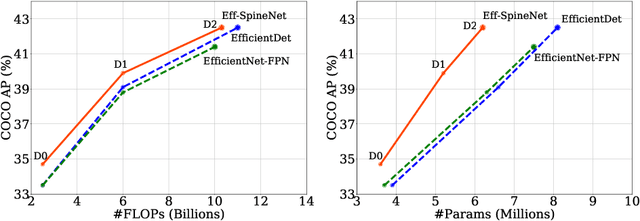
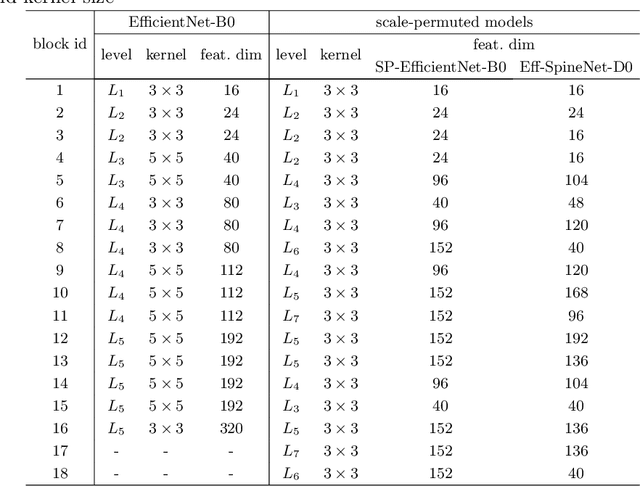
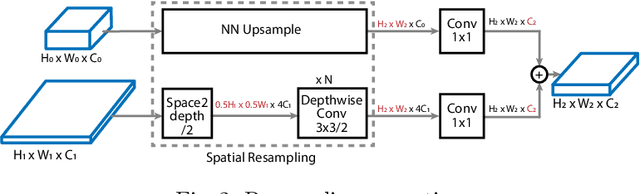

Recently, SpineNet has demonstrated promising results on object detection and image classification over ResNet model. However, it is unclear if the improvement adds up when combining scale-permuted backbone with advanced efficient operations and compound scaling. Furthermore, SpineNet is built with a uniform resource distribution over operations. While this strategy seems to be prevalent for scale-decreased models, it may not be an optimal design for scale-permuted models. In this work, we propose a simple technique to combine efficient operations and compound scaling with a previously learned scale-permuted architecture. We demonstrate the efficiency of scale-permuted model can be further improved by learning a resource distribution over the entire network. The resulting efficient scale-permuted models outperform state-of-the-art EfficientNet-based models on object detection and achieve competitive performance on image classification and semantic segmentation. Code and models will be open-sourced soon.