 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FACEGAN: Facial Attribute Controllable rEenactment GAN
Nov 09, 2020

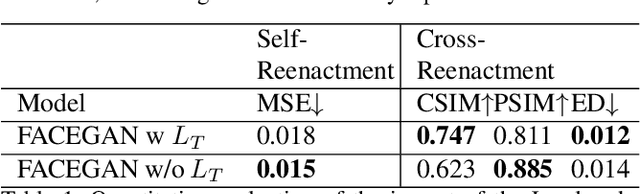
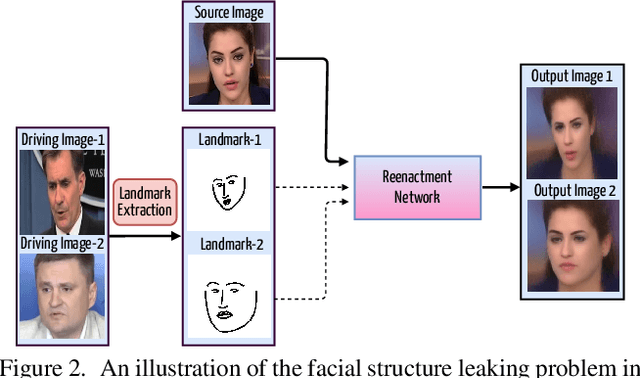
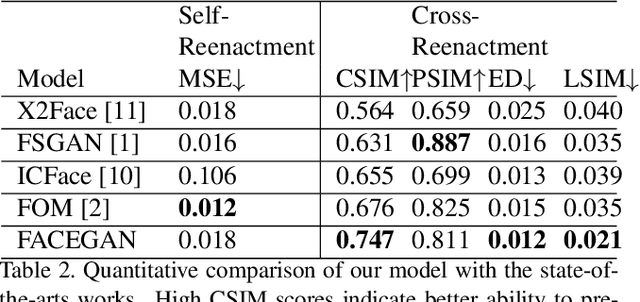
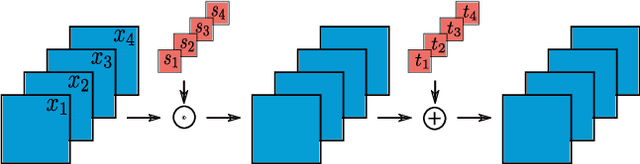
The face reenactment is a popular facial animation method where the person's identity is taken from the source image and the facial motion from the driving image. Recent works have demonstrated high quality results by combining the facial landmark based motion representations with the generative adversarial networks. These models perform best if the source and driving images depict the same person or if the facial structures are otherwise very similar. However, if the identity differs, the driving facial structures leak to the output distorting the reenactment result. We propose a novel Facial Attribute Controllable rEenactment GAN (FACEGAN), which transfers the facial motion from the driving face via the Action Unit (AU) representation. Unlike facial landmarks, the AUs are independent of the facial structure preventing the identity leak. Moreover, AUs provide a human interpretable way to control the reenactment. FACEGAN processes background and face regions separately for optimized output quality. The extensive quantitative and qualitative comparisons show a clear improvement over the state-of-the-art in a single source reenactment task. The results are best illustrated in the reenactment video provided in the supplementary material. The source code will be made available upon publication of the paper.
Learning to Read and Follow Music in Complete Score Sheet Images
Jul 21, 2020

This paper addresses the task of score following in sheet music given as unprocessed images. While existing work either relies on OMR software to obtain a computer-readable score representation, or crucially relies on prepared sheet image excerpts, we propose the first system that directly performs score following in full-page, completely unprocessed sheet images. Based on incoming audio and a given image of the score, our system directly predicts the most likely position within the page that matches the audio, outperforming current state-of-the-art image-based score followers in terms of alignment precision. We also compare our method to an OMR-based approach and empirically show that it can be a viable alternative to such a system.
Information Ranking Using Optimum-Path Forest
Feb 16, 2021

The task of learning to rank has been widely studied by the machine learning community, mainly due to its use and great importance in information retrieval, data mining, and natural language processing. Therefore, ranking accurately and learning to rank are crucial tasks. Context-Based Information Retrieval systems have been of great importance to reduce the effort of finding relevant data. Such systems have evolved by using machine learning techniques to improve their results, but they are mainly dependent on user feedback. Although information retrieval has been addressed in different works along with classifiers based on Optimum-Path Forest (OPF), these have so far not been applied to the learning to rank task. Therefore, the main contribution of this work is to evaluate classifiers based on Optimum-Path Forest, in such a context. Experiments were performed considering the image retrieval and ranking scenarios, and the performance of OPF-based approaches was compared to the well-known SVM-Rank pairwise technique and a baseline based on distance calculation. The experiments showed competitive results concerning precision and outperformed traditional techniques in terms of computational load.
Image-based reconstruction for strong-nonlinear transient problems by using an enhanced ReConNN
May 10, 2019
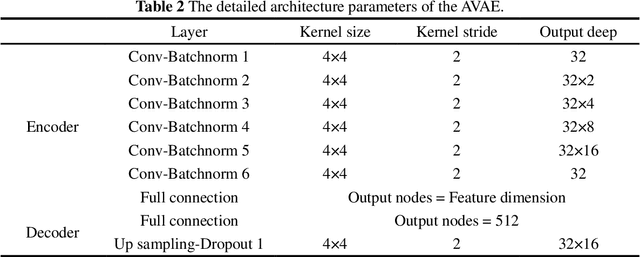


With the improvement of pattern recognition and feature extraction of Deep Neural Networks (DNNs), more and more problems are attempted to solve from the view of images. Recently, a Reconstructive Neural Network (ReConNN) was proposed to obtain an image-based model from an analysis-based model, which can help us to solve many high frequency problems with difficult sampling, e.g. sonic wave and collision. However, due to the slight difference between simulated images, the low-accuracy of the Convolutional Neural Network (CNN) and poor-diversity of the Generative Adversarial Network (GAN) make the reconstruction process low-accuracy, poor-efficiency, expensive-computation and high-manpower. In this study, an improved ReConNN model is proposed to address the mentioned weaknesses. Through experiments, comparisons and analyses, the improved one is demonstrated to outperform in accuracy, efficiency and cost.
Disguised-Nets: Image Disguising for Privacy-preserving Deep Learning
Feb 05, 2019
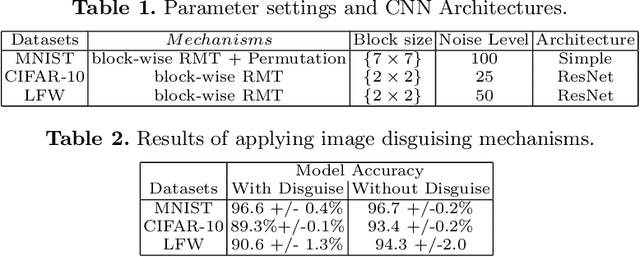

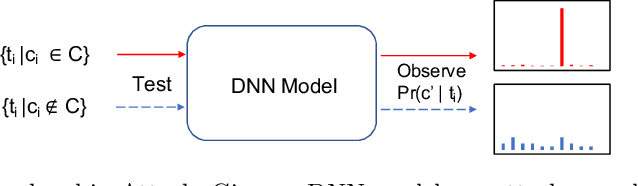
Due to the high training costs of deep learning, model developers often rent cloud GPU servers to achieve better efficiency. However, this practice raises privacy concerns. An adversarial party may be interested in 1) personal identifiable information encoded in the training data and the learned models, 2) misusing the sensitive models for its own benefits, or 3) launching model inversion (MIA) and generative adversarial network (GAN) attacks to reconstruct replicas of training data (e.g., sensitive images). Learning from encrypted data seems impractical due to the large training data and expensive learning algorithms, while differential-privacy based approaches have to make significant trade-offs between privacy and model quality. We investigate the use of image disguising techniques to protect both data and model privacy. Our preliminary results show that with block-wise permutation and transformations, surprisingly, disguised images still give reasonably well performing deep neural networks (DNN). The disguised images are also resilient to the deep-learning enhanced visual discrimination attack and provide an extra layer of protection from MIA and GAN attacks.
CapWAP: Captioning with a Purpose
Nov 09, 2020

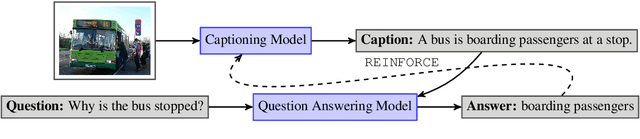

The traditional image captioning task uses generic reference captions to provide textual information about images. Different user populations, however, will care about different visual aspects of images. In this paper, we propose a new task, Captioning with a Purpose (CapWAP). Our goal is to develop systems that can be tailored to be useful for the information needs of an intended population, rather than merely provide generic information about an image. In this task, we use question-answer (QA) pairs---a natural expression of information need---from users, instead of reference captions, for both training and post-inference evaluation. We show that it is possible to use reinforcement learning to directly optimize for the intended information need, by rewarding outputs that allow a question answering model to provide correct answers to sampled user questions. We convert several visual question answering datasets into CapWAP datasets, and demonstrate that under a variety of scenarios our purposeful captioning system learns to anticipate and fulfill specific information needs better than its generic counterparts, as measured by QA performance on user questions from unseen images, when using the caption alone as context.
ReLGAN: Generalization of Consistency for GAN with Disjoint Constraints and Relative Learning of Generative Processes for Multiple Transformation Learning
Jun 14, 2020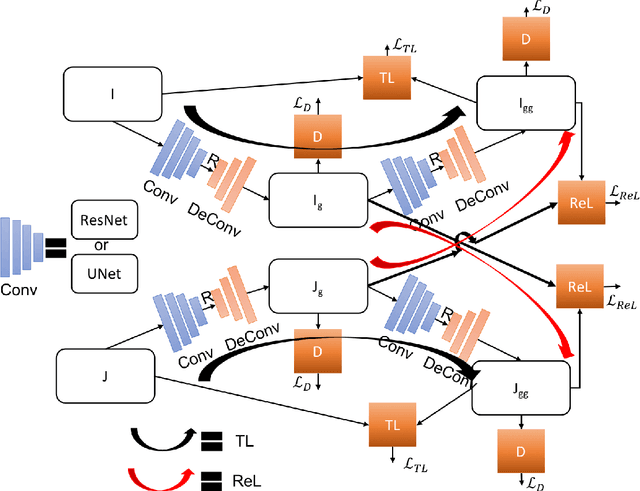
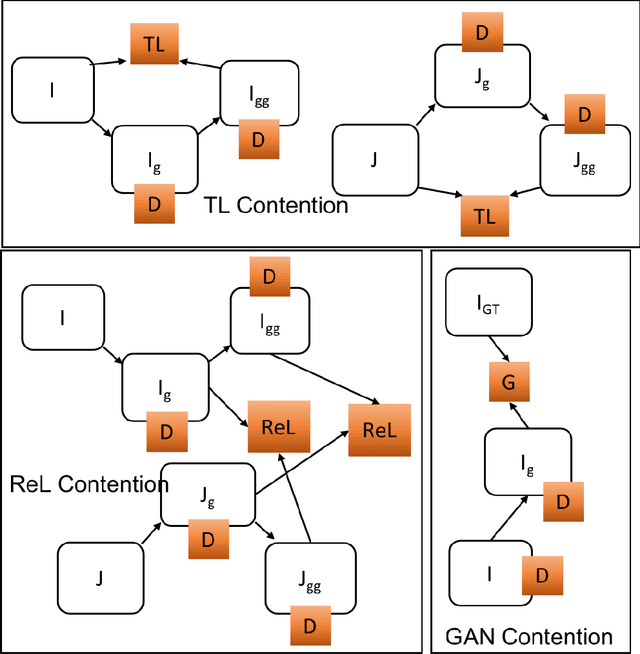

Image to image transformation has gained popularity from different research communities due to its enormous impact on different applications, including medical. In this work, we have introduced a generalized scheme for consistency for GAN architectures with two new concepts of Transformation Learning (TL) and Relative Learning (ReL) for enhanced learning image transformations. Consistency for GAN architectures suffered from inadequate constraints and failed to learn multiple and multi-modal transformations, which is inevitable for many medical applications. The main drawback is that it focused on creating an intermediate and workable hybrid, which is not permissible for the medical applications which focus on minute details. Another drawback is the weak interrelation between the two learning phases and TL and ReL have introduced improved coordination among them. We have demonstrated the capability of the novel network framework on public datasets. We emphasized that our novel architecture produced an improved neural image transformation version for the image, which is more acceptable to the medical community. Experiments and results demonstrated the effectiveness of our framework with enhancement compared to the previous works.
Method for the generation of depth images for view-based shape retrieval of 3D CAD model from partial point cloud
Jun 30, 2020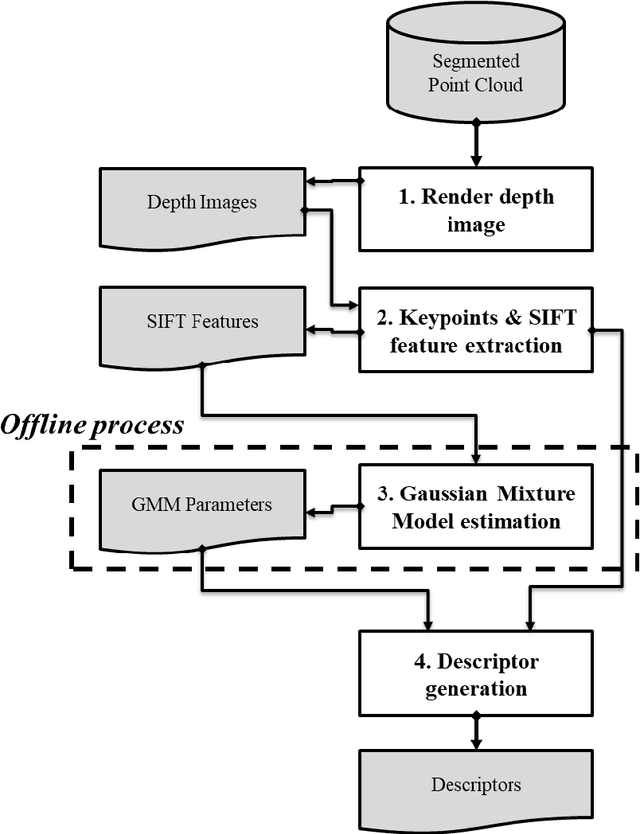



A laser scanner can easily acquire the geometric data of physical environments in the form of a point cloud. Recognizing objects from a point cloud is often required for industrial 3D reconstruction, which should include not only geometry information but also semantic information. However, recognition process is often a bottleneck in 3D reconstruction because it requires expertise on domain knowledge and intensive labor. To address this problem, various methods have been developed to recognize objects by retrieving the corresponding model in the database from an input geometry query. In recent years, the technique of converting geometric data into an image and applying view-based 3D shape retrieval has demonstrated high accuracy. Depth image which encodes depth value as intensity of pixel is frequently used for view-based 3D shape retrieval. However, geometric data collected from objects is often incomplete due to the occlusions and the limit of line of sight. Image generated by occluded point clouds lowers the performance of view-based 3D object retrieval due to loss of information. In this paper, we propose a method of viewpoint and image resolution estimation method for view-based 3D shape retrieval from point cloud query. Automatic selection of viewpoint and image resolution by calculating the data acquisition rate and density from the sampled viewpoints and image resolutions are proposed. The retrieval performance from the images generated by the proposed method is experimented and compared for various dataset. Additionally, view-based 3D shape retrieval performance with deep convolutional neural network has been experimented with the proposed method.
Semi-Supervised Learning for Fetal Brain MRI Quality Assessment with ROI consistency
Jun 23, 2020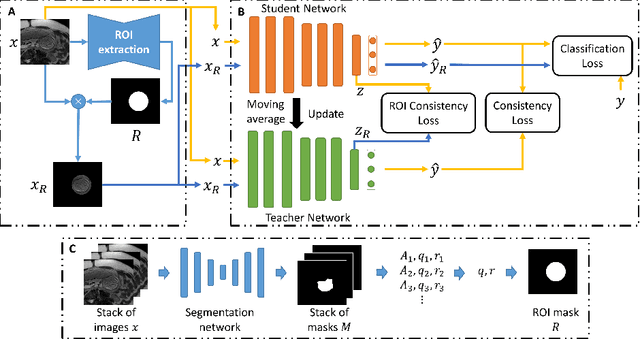
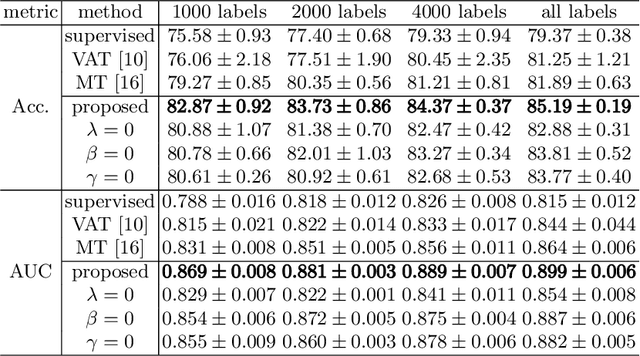
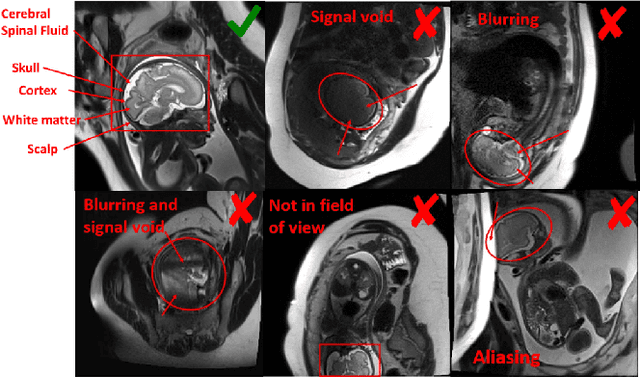
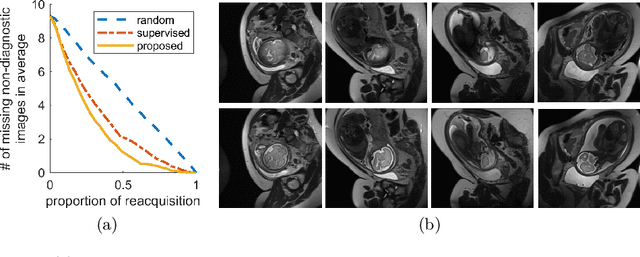
Fetal brain MRI is useful for diagnosing brain abnormalities but is challenged by fetal motion. The current protocol for T2-weighted fetal brain MRI is not robust to motion so image volumes are degraded by inter- and intra- slice motion artifacts. Besides, manual annotation for fetal MR image quality assessment are usually time-consuming. Therefore, in this work, a semi-supervised deep learning method that detects slices with artifacts during the brain volume scan is proposed. Our method is based on the mean teacher model, where we not only enforce consistency between student and teacher models on the whole image, but also adopt an ROI consistency loss to guide the network to focus on the brain region. The proposed method is evaluated on a fetal brain MR dataset with 11,223 labeled images and more than 200,000 unlabeled images. Results show that compared with supervised learning, the proposed method can improve model accuracy by about 6\% and outperform other state-of-the-art semi-supervised learning methods. The proposed method is also implemented and evaluated on an MR scanner, which demonstrates the feasibility of online image quality assessment and image reacquisition during fetal MR scans.
EPSR: Edge Profile Super resolution
Nov 09, 2020
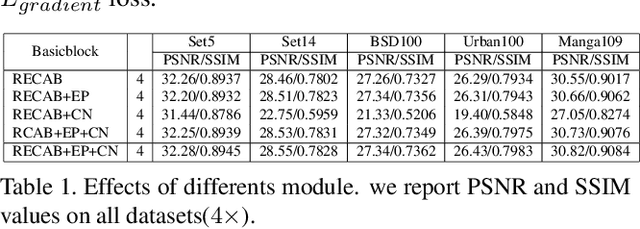
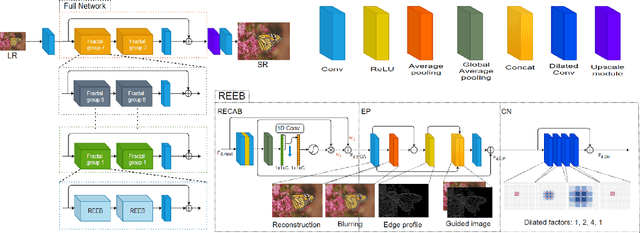
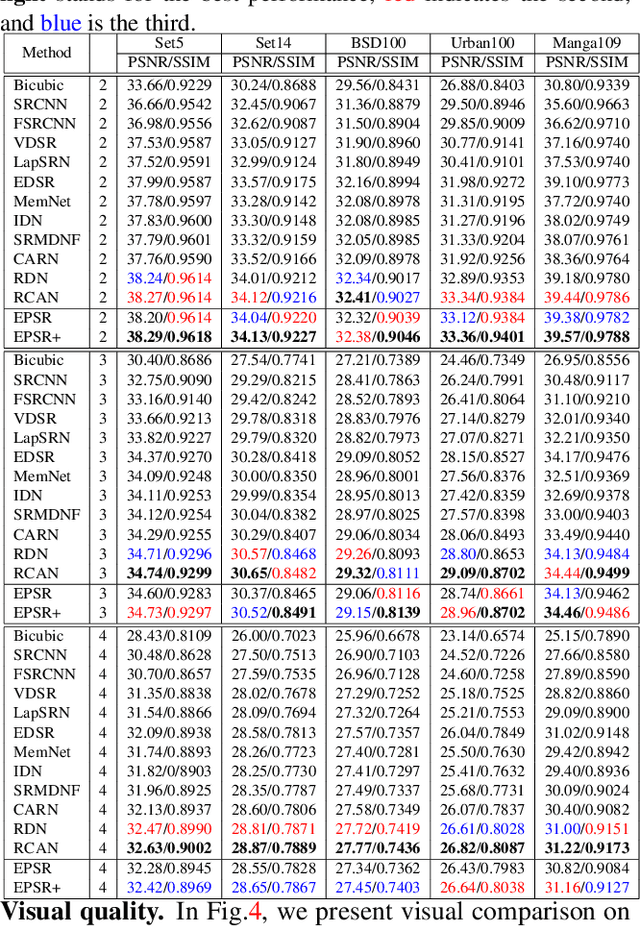
Recently numerous deep convolutional neural networks(CNNs) have been explored in single image super-resolution(SISR) and they achieved significant performance. However, most deep CNN-based SR mainly focuses on designing wider or deeper architecture and it is hard to find methods that utilize image properties in SISR. In this paper, by developing an edge-profile approach based on end-to-end CNN model to SISR problem, we propose an edge profile super resolution(EPSR). Specifically, we construct a residual edge enhance block(REEB), which consists of residual efficient channel attention block(RECAB), edge profile(EP) module, and context network(CN) module. RE-CAB extracts adaptively rescale channel-wise features by considering interdependencies among channels efficiently.From the features, EP module generates edge-guided features by extracting edge profile itself, and then CN module enhances details by exploiting contextual information of the features. To utilize various information from low to high frequency components, we design a fractal skip connection(FSC) structure. Since self-similarity of the architecture, FSC structure allows our EPSR to bypass abundant information into each REEB block. Experimental results present that our EPSR achieves competitive performance against state-of-the-art methods.