 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Translational Equivariance in Kernelizable Attention
Feb 15, 2021
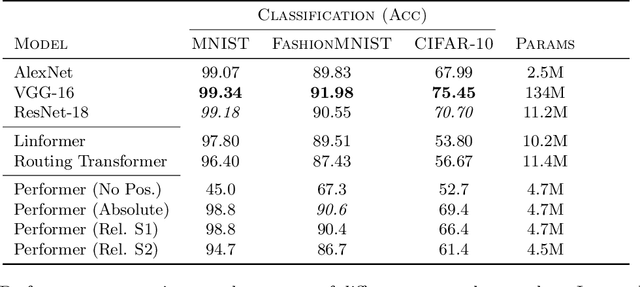
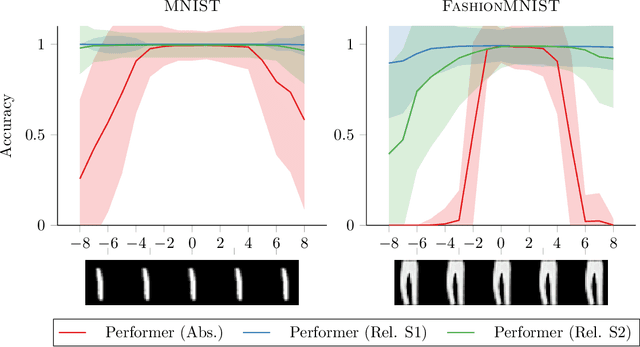
While Transformer architectures have show remarkable success, they are bound to the computation of all pairwise interactions of input element and thus suffer from limited scalability. Recent work has been successful by avoiding the computation of the complete attention matrix, yet leads to problems down the line. The absence of an explicit attention matrix makes the inclusion of inductive biases relying on relative interactions between elements more challenging. An extremely powerful inductive bias is translational equivariance, which has been conjectured to be responsible for much of the success of Convolutional Neural Networks on image recognition tasks. In this work we show how translational equivariance can be implemented in efficient Transformers based on kernelizable attention - Performers. Our experiments highlight that the devised approach significantly improves robustness of Performers to shifts of input images compared to their naive application. This represents an important step on the path of replacing Convolutional Neural Networks with more expressive Transformer architectures and will help to improve sample efficiency and robustness in this realm.
DmifNet:3D Shape Reconstruction Based on Dynamic Multi-Branch Information Fusion
Nov 21, 2020
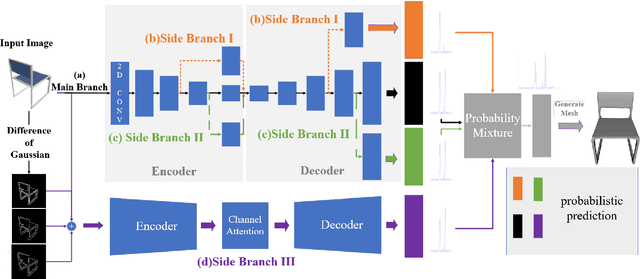
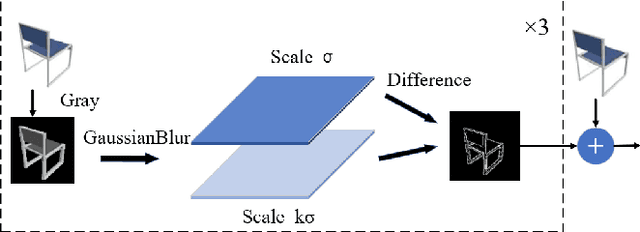
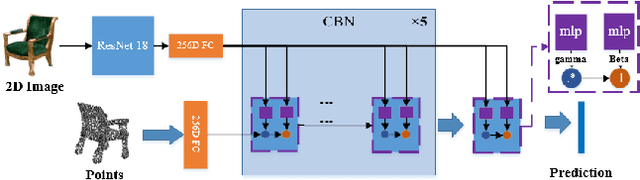
3D object reconstruction from a single-view image is a long-standing challenging problem. Previous work was difficult to accurately reconstruct 3D shapes with a complex topology which has rich details at the edges and corners. Moreover, previous works used synthetic data to train their network, but domain adaptation problems occurred when tested on real data. In this paper, we propose a Dynamic Multi-branch Information Fusion Network (DmifNet) which can recover a high-fidelity 3D shape of arbitrary topology from a 2D image. Specifically, we design several side branches from the intermediate layers to make the network produce more diverse representations to improve the generalization ability of network. In addition, we utilize DoG (Difference of Gaussians) to extract edge geometry and corners information from input images. Then, we use a separate side branch network to process the extracted data to better capture edge geometry and corners feature information. Finally, we dynamically fuse the information of all branches to gain final predicted probability. Extensive qualitative and quantitative experiments on a large-scale publicly available dataset demonstrate the validity and efficiency of our method. Code and models are publicly available at https://github.com/leilimaster/DmifNet.
Deep Convolutional Neural Network for Identifying Seam-Carving Forgery
Jul 07, 2020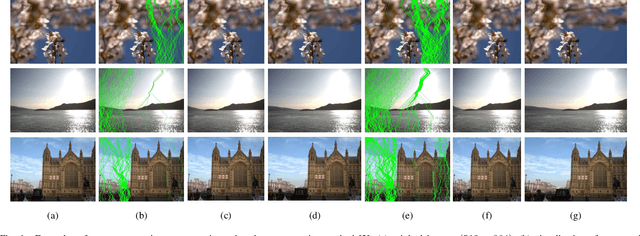
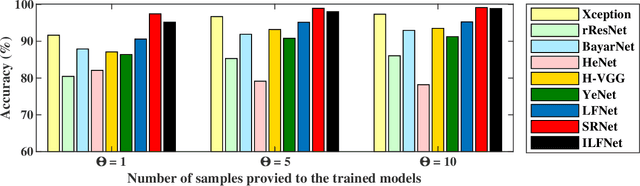

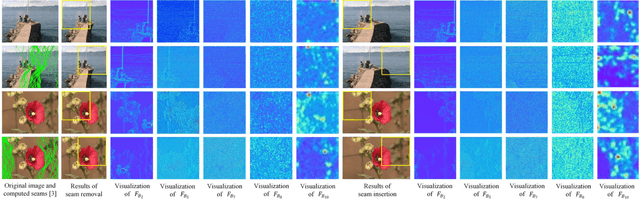
Seam carving is a representative content-aware image retargeting approach to adjust the size of an image while preserving its visually prominent content. To maintain visually important content, seam-carving algorithms first calculate the connected path of pixels, referred to as the seam, according to a defined cost function and then adjust the size of an image by removing and duplicating repeatedly calculated seams. Seam carving is actively exploited to overcome diversity in the resolution of images between applications and devices; hence, detecting the distortion caused by seam carving has become important in image forensics. In this paper, we propose a convolutional neural network (CNN)-based approach to classifying seam-carving-based image retargeting for reduction and expansion. To attain the ability to learn low-level features, we designed a CNN architecture comprising five types of network blocks specialized for capturing subtle signals. An ensemble module is further adopted to both enhance performance and comprehensively analyze the features in the local areas of the given image. To validate the effectiveness of our work, extensive experiments based on various CNN-based baselines were conducted. Compared to the baselines, our work exhibits state-of-the-art performance in terms of three-class classification (original, seam inserted, and seam removed). In addition, our model with the ensemble module is robust for various unseen cases. The experimental results also demonstrate that our method can be applied to localize both seam-removed and seam-inserted areas.
A Novel Nudity Detection Algorithm for Web and Mobile Application Development
Jun 28, 2020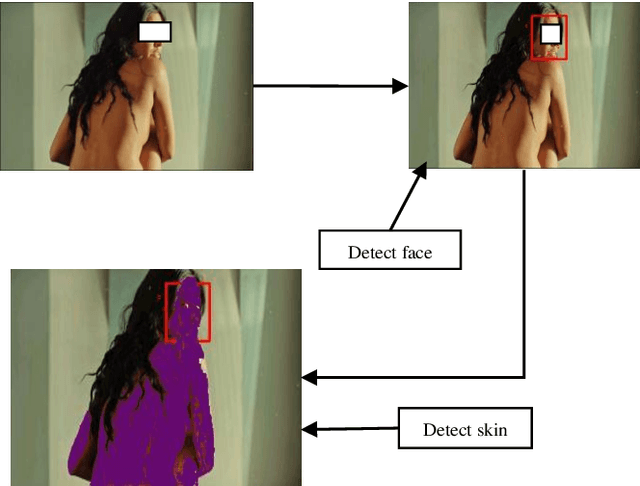



In our current web and mobile application development runtime nude image content detection is very important. This paper presents a runtime nudity detection method for web and mobile application development. We use two parameters to detect the nude content of an image. One is the number of skin pixels another is face region. A skin color model based on RGB, HSV color spaces are used to detect skin pixels in an image. Google vision api is used to detect the face region. By the percentage of skin regions and face regions an image is identified nude or not. The success of this algorithm exists in detecting skin regions and face regions. The skin detection algorithm can detect skin 95% accurately with a low false-positive rate and the google vision api for web and mobile applications can detect face 99% accurately with less than 1 second time. From the experimental analysis, we have seen that the proposed algorithm can detect 95% percent accurately the nudity of an image.
Depth extraction from a single compressive hologram
Feb 26, 2021

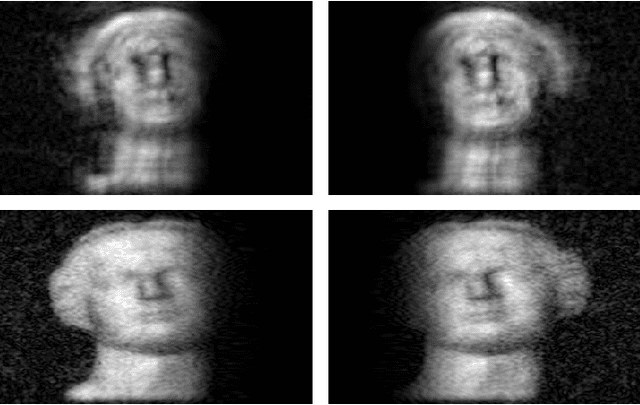

We propose a novel method that records a single compressive hologram in a short time and extracts the depth of a scene from that hologram using a stereo disparity technique. The method is verified with numerical simulations, but there is no restriction on adapting this into an optical experiment. In the simulations, a computer-generated hologram is first sampled with random binary patterns, and measurements are utilized in a recovery algorithm to form a compressive hologram. The compressive hologram is then divided into two parts (two apertures), and these parts are separately reconstructed to form a stereo image pair. The pair is eventually utilized in stereo disparity method for depth map extraction. The depth maps of the compressive holograms with the sampling rates of 2, 25, and 50 percent are compared with the depth map extracted from the original hologram, on which compressed sensing is not applied. It is demonstrated that the depth profiles obtained from the compressive holograms are in very good agreement with the depth profile obtained from the original hologram despite the data reduction.
Unsupervised Contrastive Photo-to-Caricature Translation based on Auto-distortion
Nov 10, 2020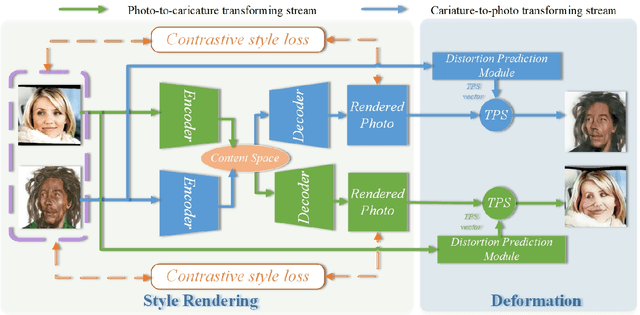
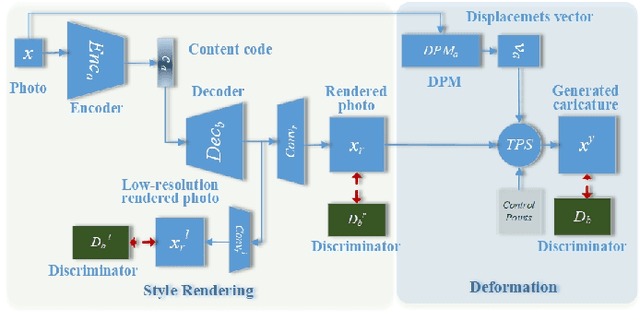
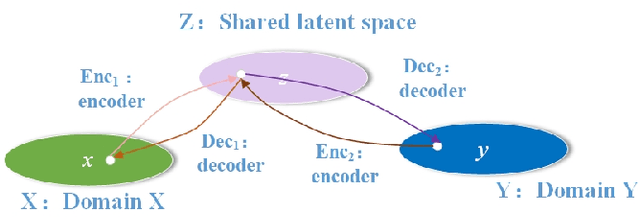

Photo-to-caricature translation aims to synthesize the caricature as a rendered image exaggerating the features through sketching, pencil strokes, or other artistic drawings. Style rendering and geometry deformation are the most important aspects in photo-to-caricature translation task. To take both into consideration, we propose an unsupervised contrastive photo-to-caricature translation architecture. Considering the intuitive artifacts in the existing methods, we propose a contrastive style loss for style rendering to enforce the similarity between the style of rendered photo and the caricature, and simultaneously enhance its discrepancy to the photos. To obtain an exaggerating deformation in an unpaired/unsupervised fashion, we propose a Distortion Prediction Module (DPM) to predict a set of displacements vectors for each input image while fixing some controlling points, followed by the thin plate spline interpolation for warping. The model is trained on unpaired photo and caricature while can offer bidirectional synthesizing via inputting either a photo or a caricature. Extensive experiments demonstrate that the proposed model is effective to generate hand-drawn like caricatures compared with existing competitors.
VisQA: X-raying Vision and Language Reasoning in Transformers
Apr 02, 2021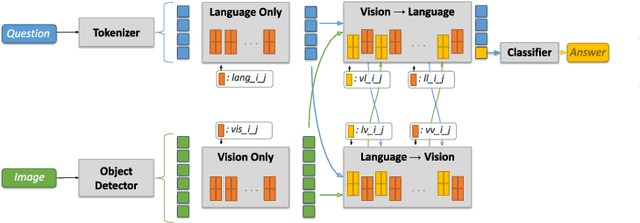
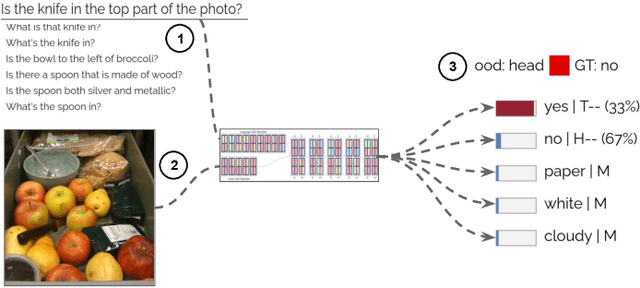
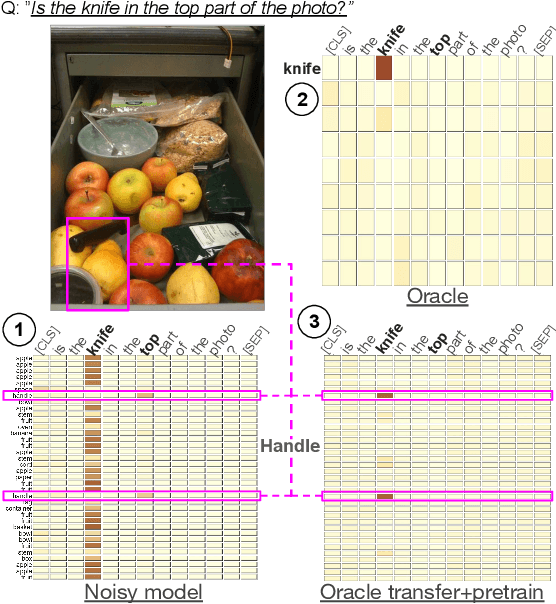
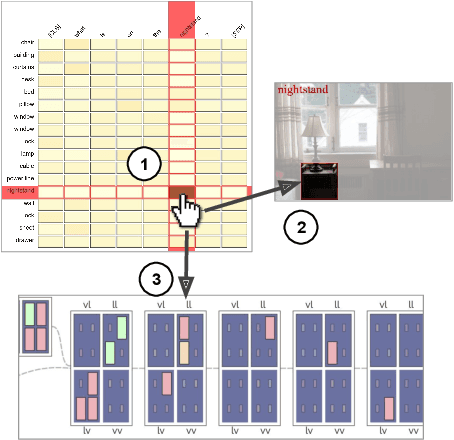
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.
Objective Diagnosis for Histopathological Images Based on Machine Learning Techniques: Classical Approaches and New Trends
Nov 10, 2020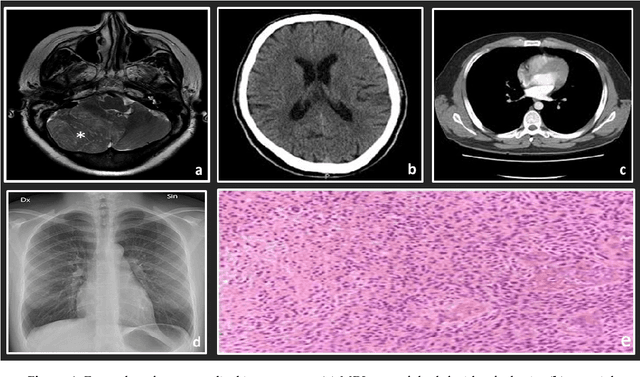
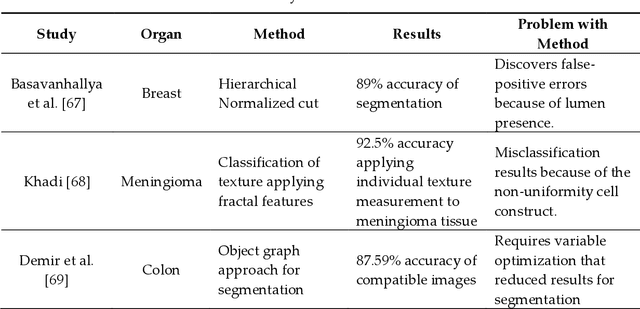
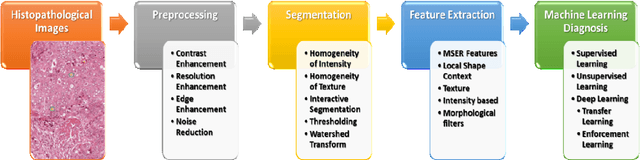
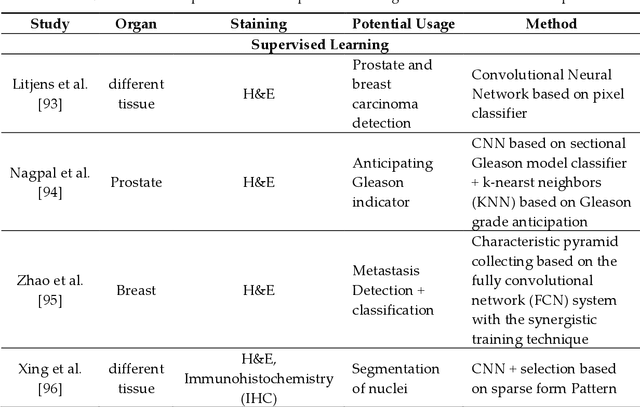
Histopathology refers to the examination by a pathologist of biopsy samples. Histopathology images are captured by a microscope to locate, examine, and classify many diseases, such as different cancer types. They provide a detailed view of different types of diseases and their tissue status. These images are an essential resource with which to define biological compositions or analyze cell and tissue structures. This imaging modality is very important for diagnostic applications. The analysis of histopathology images is a prolific and relevant research area supporting disease diagnosis. In this paper, the challenges of histopathology image analysis are evaluated. An extensive review of conventional and deep learning techniques which have been applied in histological image analyses is presented. This review summarizes many current datasets and highlights important challenges and constraints with recent deep learning techniques, alongside possible future research avenues. Despite the progress made in this research area so far, it is still a significant area of open research because of the variety of imaging techniques and disease-specific characteristics.
* 26 Pages, 5 figures, 4 tables
Fast Multi-Level Foreground Estimation
Jun 26, 2020
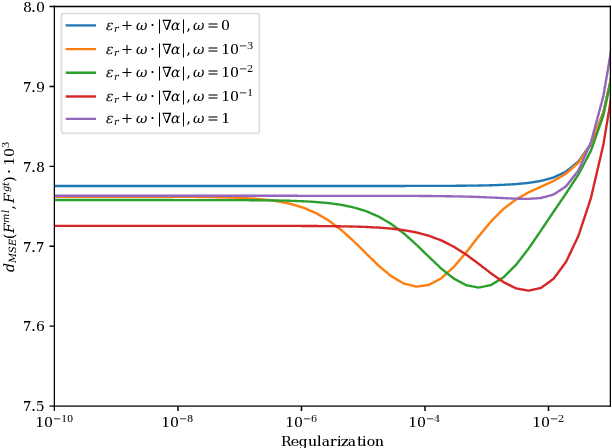
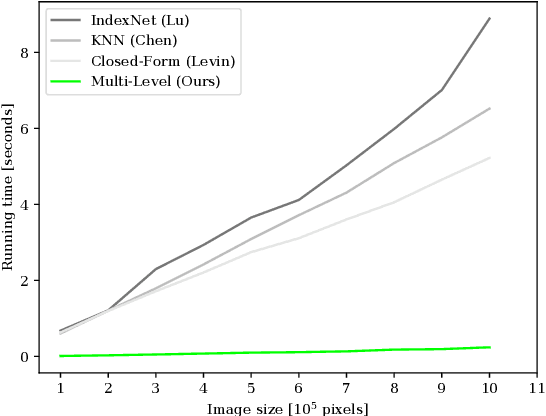
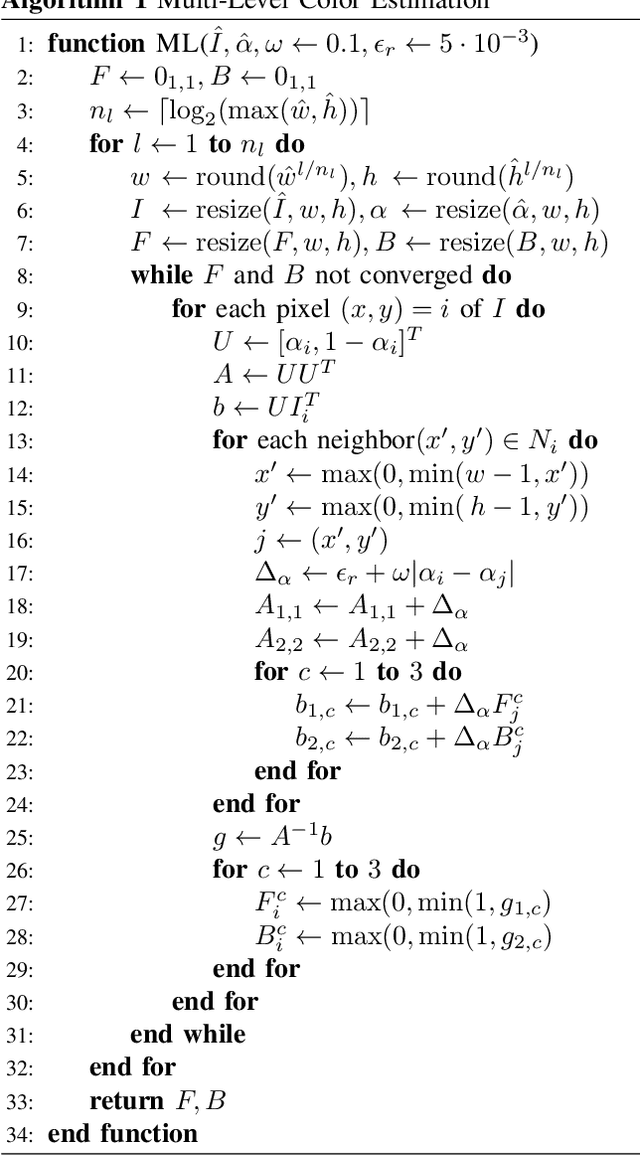
Alpha matting aims to estimate the translucency of an object in a given image. The resulting alpha matte describes pixel-wise to what amount foreground and background colors contribute to the color of the composite image. While most methods in literature focus on estimating the alpha matte, the process of estimating the foreground colors given the input image and its alpha matte is often neglected, although foreground estimation is an essential part of many image editing workflows. In this work, we propose a novel method for foreground estimation given the alpha matte. We demonstrate that our fast multi-level approach yields results that are comparable with the state-of-the-art while outperforming those methods in computational runtime and memory usage.
A New Cervical Cytology Dataset for Nucleus Detection and Image Classification (Cervix93) and Methods for Cervical Nucleus Detection
Nov 23, 2018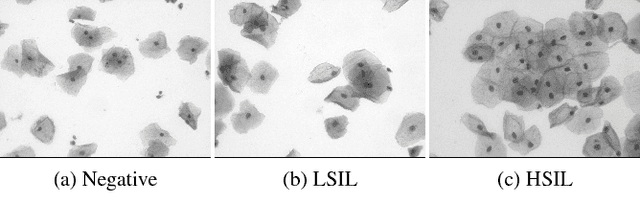
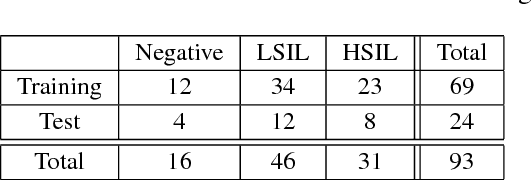
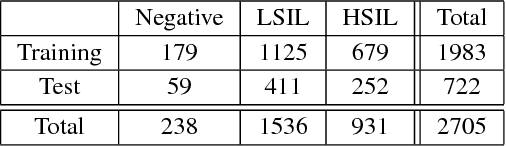

Analyzing Pap cytology slides is an important tasks in detecting and grading precancerous and cancerous cervical cancer stages. Processing cytology images usually involve segmenting nuclei and overlapping cells. We introduce a cervical cytology dataset that can be used to evaluate nucleus detection, as well as image classification methods in the cytology image processing area. This dataset contains 93 real image stacks with their grade labels and manually annotated nuclei within images. We also present two methods: a baseline method based on a previously proposed approach, and a deep learning method, and compare their results with other state-of-the-art methods. Both the baseline method and the deep learning method outperform other state-of-the-art methods by significant margins. Along with the dataset, we publicly make the evaluation code and the baseline method available to download for further benchmarking.