 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-Consistent Weakly Supervised Salient Object Detection with Local Saliency Coherence
Dec 09, 2020
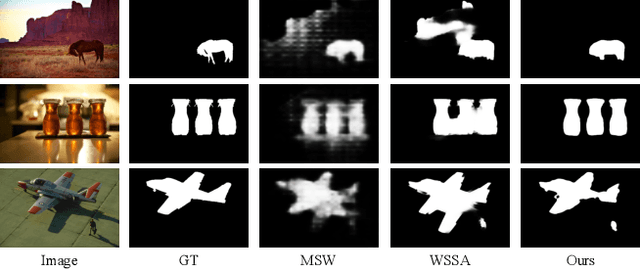
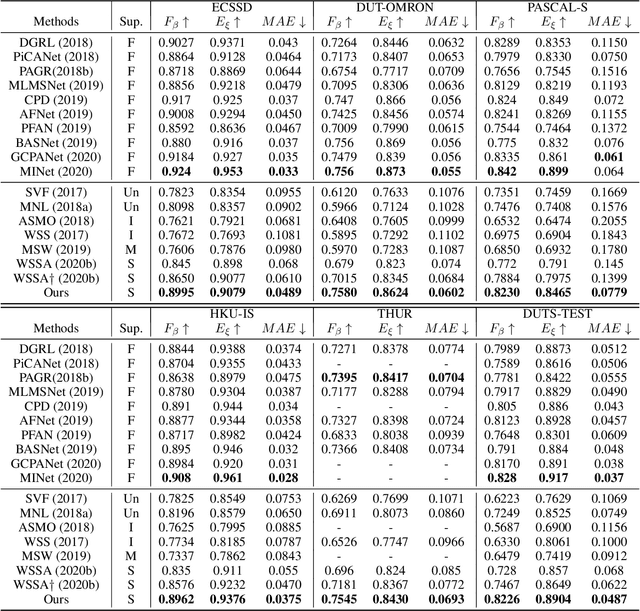
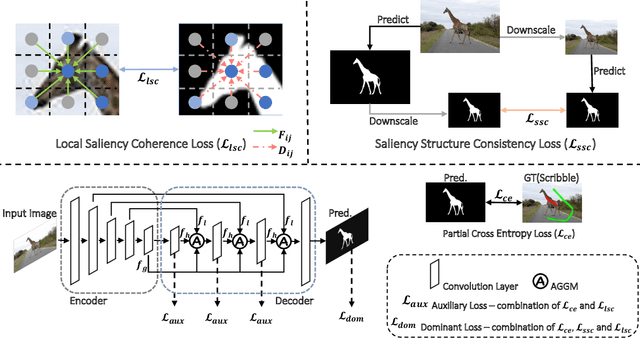
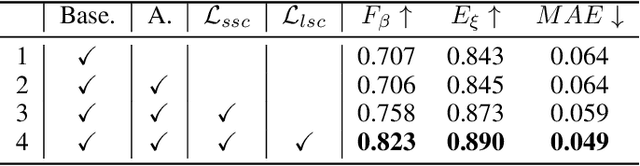
Sparse labels have been attracting much attention in recent years. However, the performance gap between weakly supervised and fully supervised salient object detection methods is huge, and most previous weakly supervised works adopt complex training methods with many bells and whistles. In this work, we propose a one-round end-to-end training approach for weakly supervised salient object detection via scribble annotations without pre/post-processing operations or extra supervision data. Since scribble labels fail to offer detailed salient regions, we propose a local coherence loss to propagate the labels to unlabeled regions based on image features and pixel distance, so as to predict integral salient regions with complete object structures. We design a saliency structure consistency loss as self-consistent mechanism to ensure consistent saliency maps are predicted with different scales of the same image as input, which could be viewed as a regularization technique to enhance the model generalization ability. Additionally, we design an aggregation module (AGGM) to better integrate high-level features, low-level features and global context information for the decoder to aggregate various information. Extensive experiments show that our method achieves a new state-of-the-art performance on six benchmarks (e.g. for the ECSSD dataset: F_\beta = 0.8995, E_\xi = 0.9079 and MAE = 0.0489$), with an average gain of 4.60\% for F-measure, 2.05\% for E-measure and 1.88\% for MAE over the previous best method on this task. Source code is available at http://github.com/siyueyu/SCWSSOD.
Low Bit-Rate Wideband Speech Coding: A Deep Generative Model based Approach
Feb 04, 2021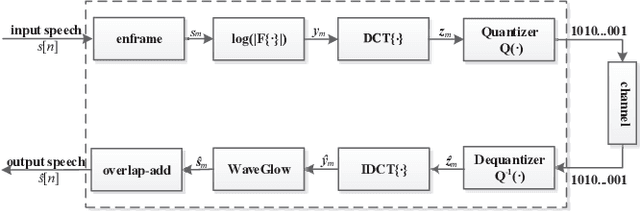



Traditional low bit-rate speech coding approach only handles narrowband speech at 8kHz, which limits further improvements in speech quality. Motivated by recent successful exploration of deep learning methods for image and speech compression, this paper presents a new approach through vector quantization (VQ) of mel-frequency cepstral coefficients (MFCCs) and using a deep generative model called WaveGlow to provide efficient and high-quality speech coding. The coding feature is sorely an 80-dimension MFCCs vector for 16kHz wideband speech, then speech coding at the bit-rate throughout 1000-2000 bit/s could be scalably implemented by applying different VQ schemes for MFCCs vector. This new deep generative network based codec works fast as the WaveGlow model abandons the sample-by-sample autoregressive mechanism. We evaluated this new approach over the multi-speaker TIMIT corpus, and experimental results demonstrate that it provides better speech quality compared with the state-of-the-art classic MELPe codec at lower bit-rate.
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020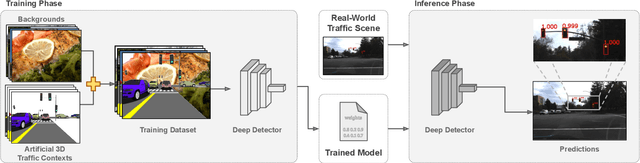
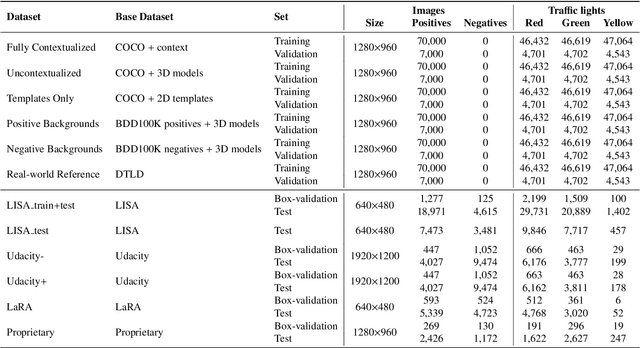
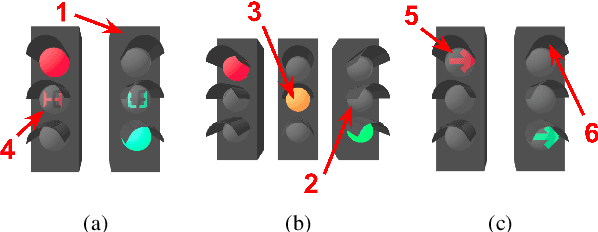
Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
Label-driven weakly-supervised learning for multimodal deformable image registration
Dec 24, 2017Spatially aligning medical images from different modalities remains a challenging task, especially for intraoperative applications that require fast and robust algorithms. We propose a weakly-supervised, label-driven formulation for learning 3D voxel correspondence from higher-level label correspondence, thereby bypassing classical intensity-based image similarity measures. During training, a convolutional neural network is optimised by outputting a dense displacement field (DDF) that warps a set of available anatomical labels from the moving image to match their corresponding counterparts in the fixed image. These label pairs, including solid organs, ducts, vessels, point landmarks and other ad hoc structures, are only required at training time and can be spatially aligned by minimising a cross-entropy function of the warped moving label and the fixed label. During inference, the trained network takes a new image pair to predict an optimal DDF, resulting in a fully-automatic, label-free, real-time and deformable registration. For interventional applications where large global transformation prevails, we also propose a neural network architecture to jointly optimise the global- and local displacements. Experiment results are presented based on cross-validating registrations of 111 pairs of T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients with a total of over 4000 anatomical labels, yielding a median target registration error of 4.2 mm on landmark centroids and a median Dice of 0.88 on prostate glands.
Visual Explanation using Attention Mechanism in Actor-Critic-based Deep Reinforcement Learning
Mar 06, 2021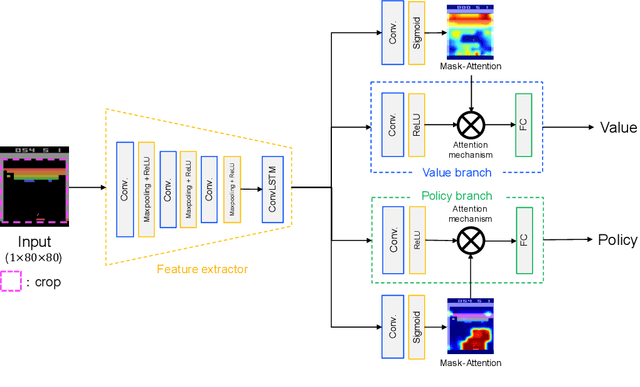
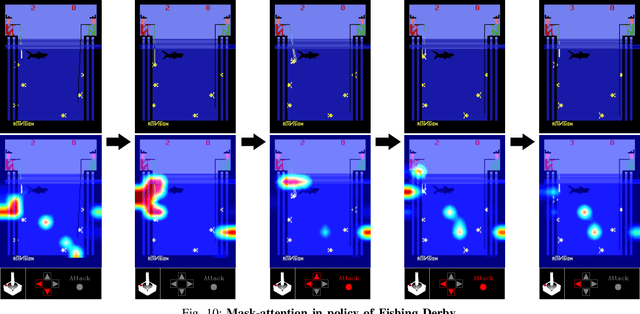
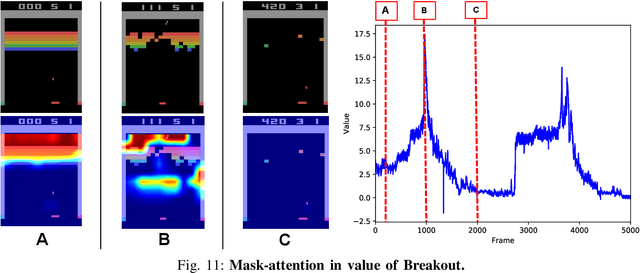
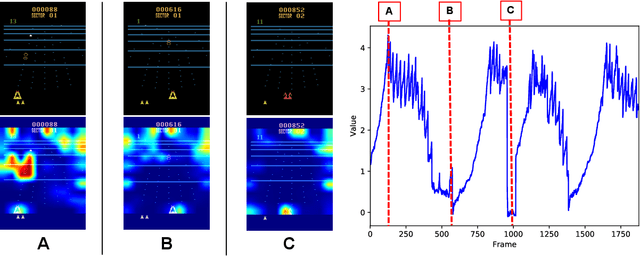
Deep reinforcement learning (DRL) has great potential for acquiring the optimal action in complex environments such as games and robot control. However, it is difficult to analyze the decision-making of the agent, i.e., the reasons it selects the action acquired by learning. In this work, we propose Mask-Attention A3C (Mask A3C), which introduces an attention mechanism into Asynchronous Advantage Actor-Critic (A3C), which is an actor-critic-based DRL method, and can analyze the decision-making of an agent in DRL. A3C consists of a feature extractor that extracts features from an image, a policy branch that outputs the policy, and a value branch that outputs the state value. In this method, we focus on the policy and value branches and introduce an attention mechanism into them. The attention mechanism applies a mask processing to the feature maps of each branch using mask-attention that expresses the judgment reason for the policy and state value with a heat map. We visualized mask-attention maps for games on the Atari 2600 and found we could easily analyze the reasons behind an agent's decision-making in various game tasks. Furthermore, experimental results showed that the agent could achieve a higher performance by introducing the attention mechanism.
Leveraging domain labels for object detection from UAVs
Jan 29, 2021
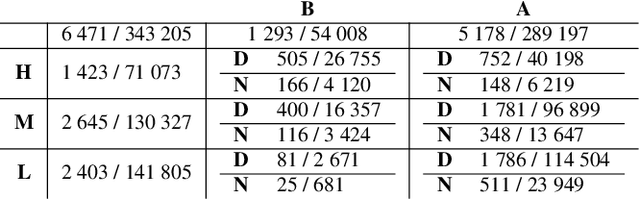
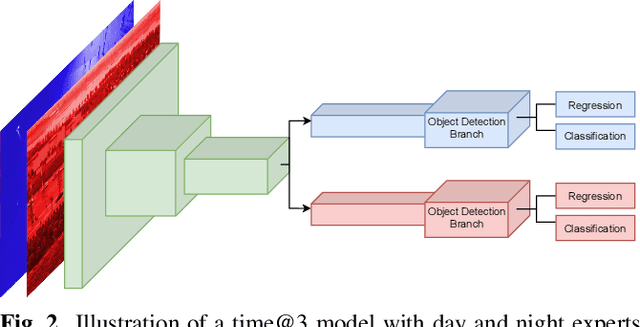
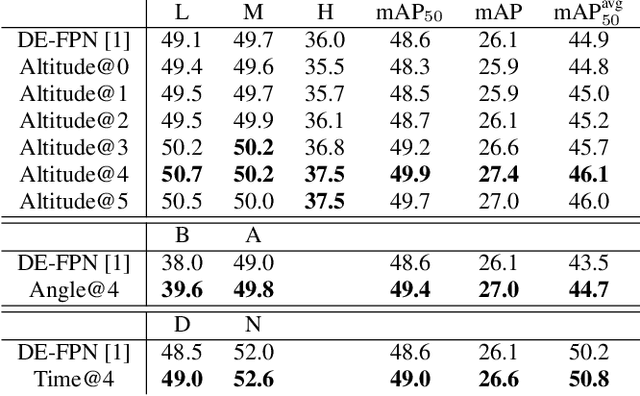
Object detection from Unmanned Aerial Vehicles (UAVs) is of great importance in many aerial vision-based applications. Despite the great success of generic object detection methods, a large performance drop is observed when applied to images captured by UAVs. This is due to large variations in imaging conditions, such as varying altitudes, dynamically changing viewing angles, and different capture times. We demonstrate that domain knowledge is a valuable source of information and thus propose domain-aware object detectors by using freely accessible sensor data. By splitting the model into cross-domain and domain-specific parts, substantial performance improvements are achieved on multiple datasets across multiple models and metrics. In particular, we achieve a new state-of-the-art performance on UAVDT for real-time detectors. Furthermore, we create a new airborne image dataset by annotating 13 713 objects in 2 900 images featuring precise altitude and viewing angle annotations.
Latent World Models For Intrinsically Motivated Exploration
Oct 05, 2020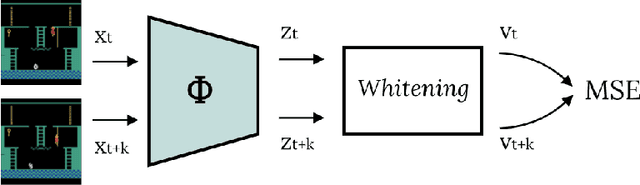
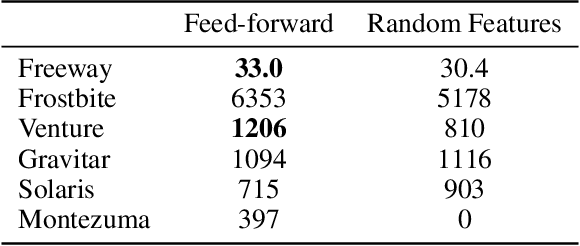
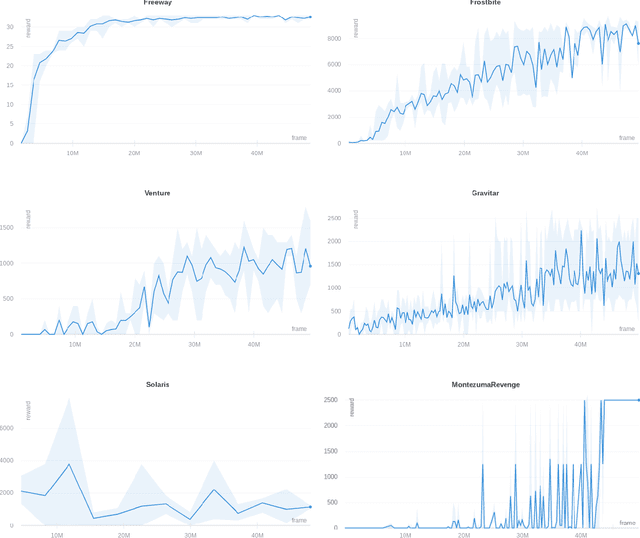
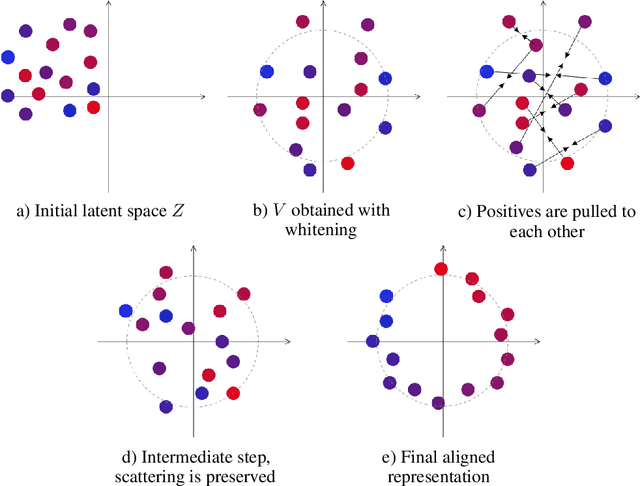
In this work we consider partially observable environments with sparse rewards. We present a self-supervised representation learning method for image-based observations, which arranges embeddings respecting temporal distance of observations. This representation is empirically robust to stochasticity and suitable for novelty detection from the error of a predictive forward model. We consider episodic and life-long uncertainties to guide the exploration. We propose to estimate the missing information about the environment with the world model, which operates in the learned latent space. As a motivation of the method, we analyse the exploration problem in a tabular Partially Observable Labyrinth. We demonstrate the method on image-based hard exploration environments from the Atari benchmark and report significant improvement with respect to prior work. The source code of the method and all the experiments is available at https://github.com/htdt/lwm.
Shuffle and Learn: Minimizing Mutual Information for Unsupervised Hashing
Nov 20, 2020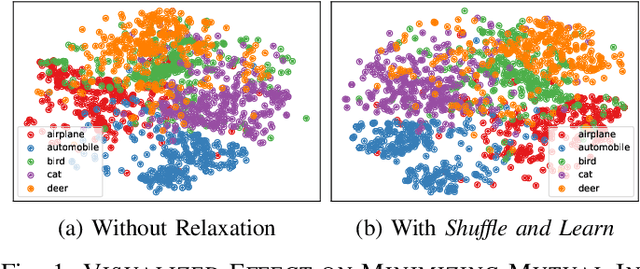
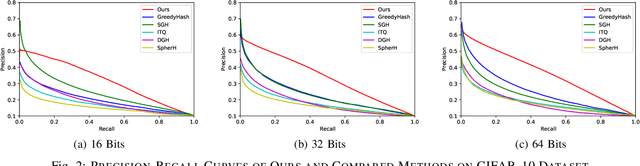

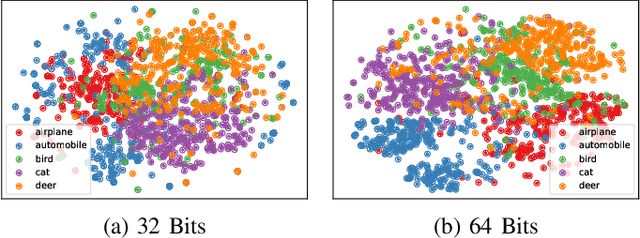
Unsupervised binary representation allows fast data retrieval without any annotations, enabling practical application like fast person re-identification and multimedia retrieval. It is argued that conflicts in binary space are one of the major barriers to high-performance unsupervised hashing as current methods failed to capture the precise code conflicts in the full domain. A novel relaxation method called Shuffle and Learn is proposed to tackle code conflicts in the unsupervised hash. Approximated derivatives for joint probability and the gradients for the binary layer are introduced to bridge the update from the hash to the input. Proof on $\epsilon$-Convergence of joint probability with approximated derivatives is provided to guarantee the preciseness on update applied on the mutual information. The proposed algorithm is carried out with iterative global updates to minimize mutual information, diverging the code before regular unsupervised optimization. Experiments suggest that the proposed method can relax the code optimization from local optimum and help to generate binary representations that are more discriminative and informative without any annotations. Performance benchmarks on image retrieval with the unsupervised binary code are conducted on three open datasets, and the model achieves state-of-the-art accuracy on image retrieval task for all those datasets. Datasets and reproducible code are provided.
EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis
Jul 30, 2017


Single image super-resolution is the task of inferring a high-resolution image from a single low-resolution input. Traditionally, the performance of algorithms for this task is measured using pixel-wise reconstruction measures such as peak signal-to-noise ratio (PSNR) which have been shown to correlate poorly with the human perception of image quality. As a result, algorithms minimizing these metrics tend to produce over-smoothed images that lack high-frequency textures and do not look natural despite yielding high PSNR values. We propose a novel application of automated texture synthesis in combination with a perceptual loss focusing on creating realistic textures rather than optimizing for a pixel-accurate reproduction of ground truth images during training. By using feed-forward fully convolutional neural networks in an adversarial training setting, we achieve a significant boost in image quality at high magnification ratios. Extensive experiments on a number of datasets show the effectiveness of our approach, yielding state-of-the-art results in both quantitative and qualitative benchmarks.
FaR-GAN for One-Shot Face Reenactment
May 13, 2020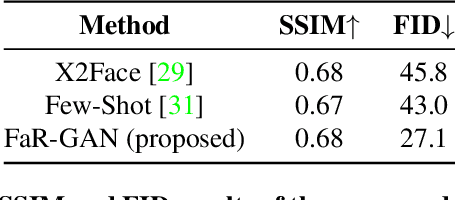
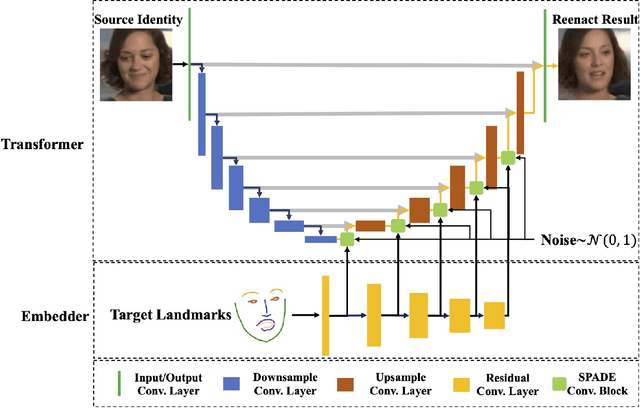
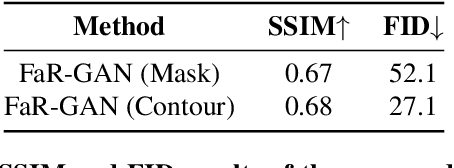
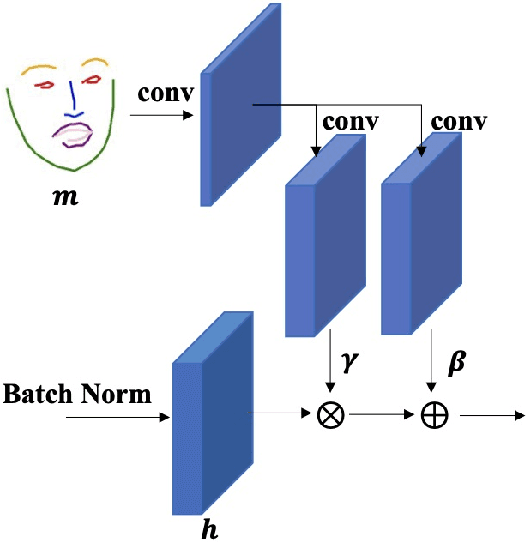
Animating a static face image with target facial expressions and movements is important in the area of image editing and movie production. This face reenactment process is challenging due to the complex geometry and movement of human faces. Previous work usually requires a large set of images from the same person to model the appearance. In this paper, we present a one-shot face reenactment model, FaR-GAN, that takes only one face image of any given source identity and a target expression as input, and then produces a face image of the same source identity but with the target expression. The proposed method makes no assumptions about the source identity, facial expression, head pose, or even image background. We evaluate our method on the VoxCeleb1 dataset and show that our method is able to generate a higher quality face image than the compared methods.