 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Steadily Learn to Drive with Virtual Memory
Feb 16, 2021
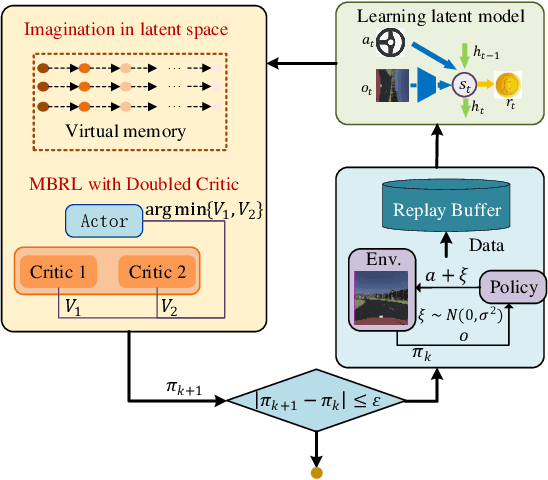
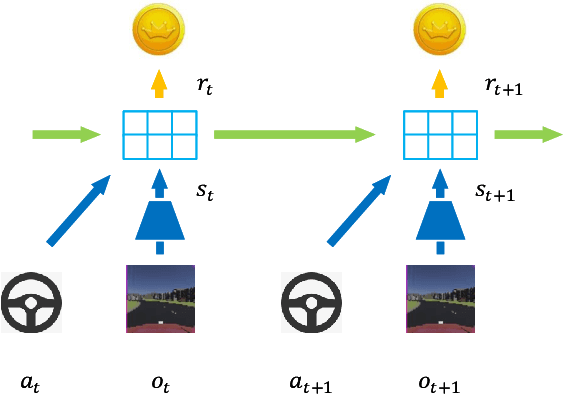
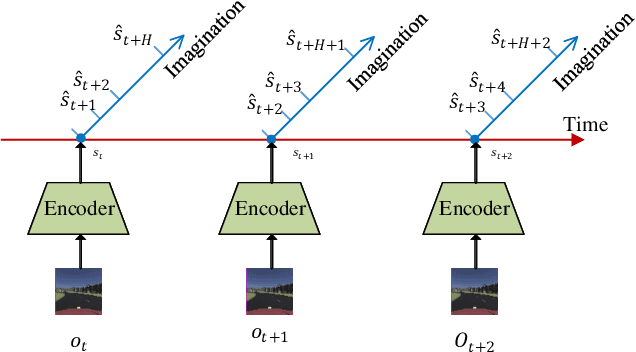

Reinforcement learning has shown great potential in developing high-level autonomous driving. However, for high-dimensional tasks, current RL methods suffer from low data efficiency and oscillation in the training process. This paper proposes an algorithm called Learn to drive with Virtual Memory (LVM) to overcome these problems. LVM compresses the high-dimensional information into compact latent states and learns a latent dynamic model to summarize the agent's experience. Various imagined latent trajectories are generated as virtual memory by the latent dynamic model. The policy is learned by propagating gradient through the learned latent model with the imagined latent trajectories and thus leads to high data efficiency. Furthermore, a double critic structure is designed to reduce the oscillation during the training process. The effectiveness of LVM is demonstrated by an image-input autonomous driving task, in which LVM outperforms the existing method in terms of data efficiency, learning stability, and control performance.
Branched Generative Adversarial Networks for Multi-Scale Image Manifold Learning
Mar 22, 2018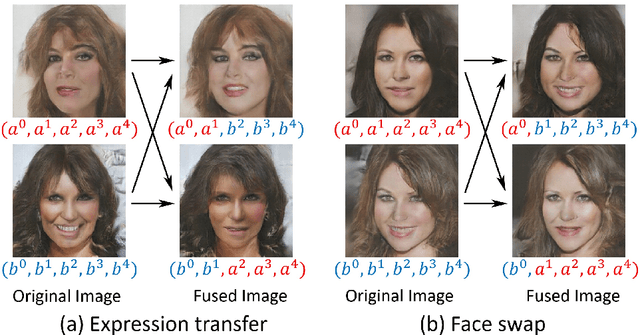
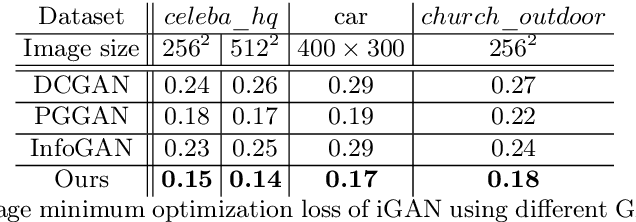
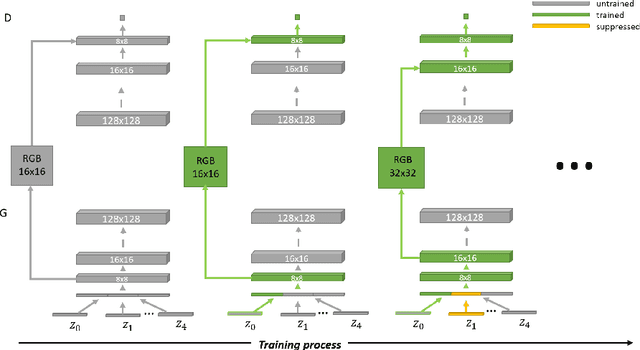
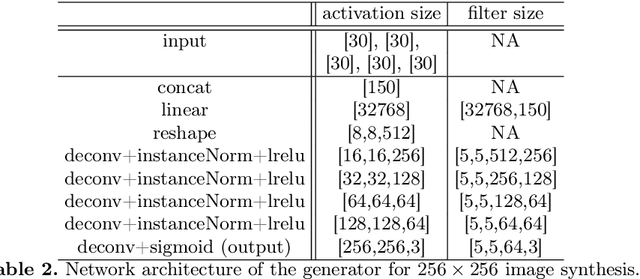
We introduce BranchGAN, a novel training method that enables unconditioned generative adversarial networks (GANs) to learn image manifolds at multiple scales. What is unique about BranchGAN is that it is trained in multiple branches, progressively covering both the breadth and depth of the network, as resolutions of the training images increase to reveal finer-scale features. Specifically, each noise vector, as input to the generator network, is explicitly split into several sub-vectors, each corresponding to and trained to learn image representations at a particular scale. During training, we progressively "de-freeze" the sub-vectors, one at a time, as a new set of higher-resolution images is employed for training and more network layers are added. A consequence of such an explicit sub-vector designation is that we can directly manipulate and even combine latent (sub-vector) codes that are associated with specific feature scales. Experiments demonstrate the effectiveness of our training method in multi-scale, disentangled learning of image manifolds and synthesis, without any extra labels and without compromising quality of the synthesized high-resolution images. We further demonstrate two new applications enabled by BranchGAN.
A Benchmark of Ocular Disease Intelligent Recognition: One Shot for Multi-disease Detection
Feb 16, 2021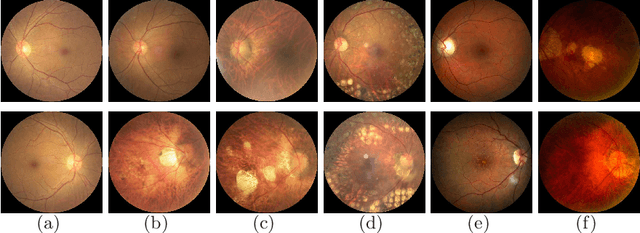
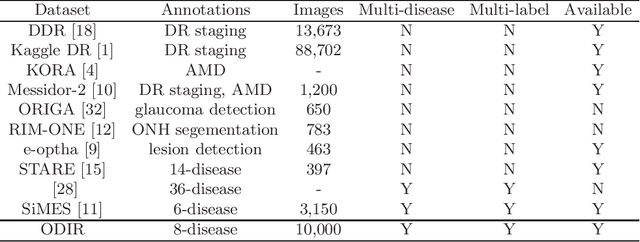
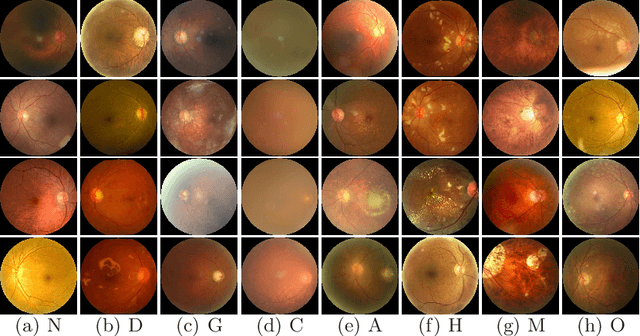
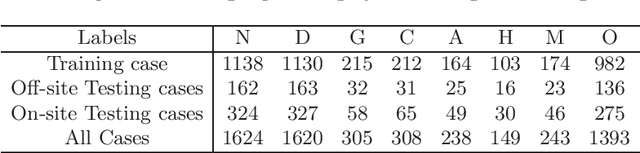
In ophthalmology, early fundus screening is an economic and effective way to prevent blindness caused by ophthalmic diseases. Clinically, due to the lack of medical resources, manual diagnosis is time-consuming and may delay the condition. With the development of deep learning, some researches on ophthalmic diseases have achieved good results, however, most of them are just based on one disease. During fundus screening, ophthalmologists usually give diagnoses of multi-disease on binocular fundus image, so we release a dataset with 8 diseases to meet the real medical scene, which contains 10,000 fundus images from both eyes of 5,000 patients. We did some benchmark experiments on it through some state-of-the-art deep neural networks. We found simply increasing the scale of network cannot bring good results for multi-disease classification, and a well-structured feature fusion method combines characteristics of multi-disease is needed. Through this work, we hope to advance the research of related fields.
Probabilistic Image Colorization
May 11, 2017
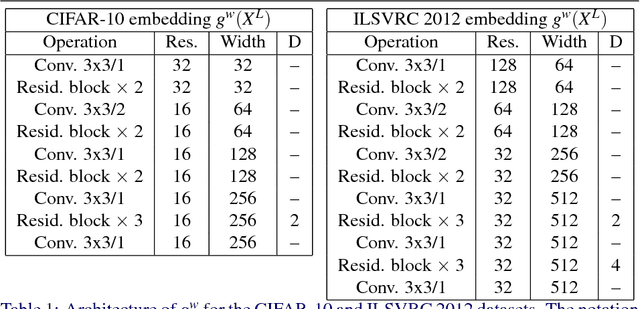
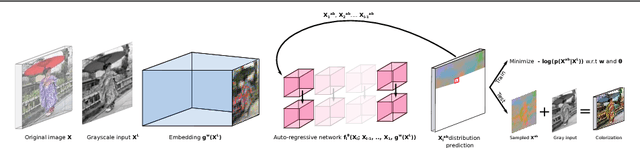

We develop a probabilistic technique for colorizing grayscale natural images. In light of the intrinsic uncertainty of this task, the proposed probabilistic framework has numerous desirable properties. In particular, our model is able to produce multiple plausible and vivid colorizations for a given grayscale image and is one of the first colorization models to provide a proper stochastic sampling scheme. Moreover, our training procedure is supported by a rigorous theoretical framework that does not require any ad hoc heuristics and allows for efficient modeling and learning of the joint pixel color distribution. We demonstrate strong quantitative and qualitative experimental results on the CIFAR-10 dataset and the challenging ILSVRC 2012 dataset.
Acceleration of Actor-Critic Deep Reinforcement Learning for Visual Grasping in Clutter by State Representation Learning Based on Disentanglement of a Raw Input Image
Feb 27, 2020
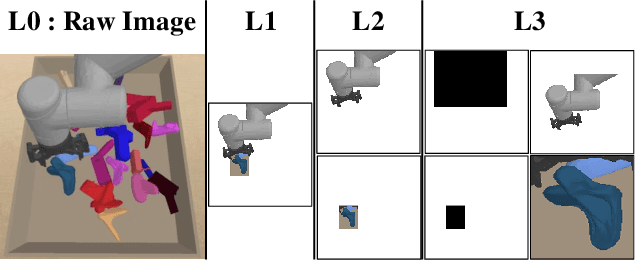
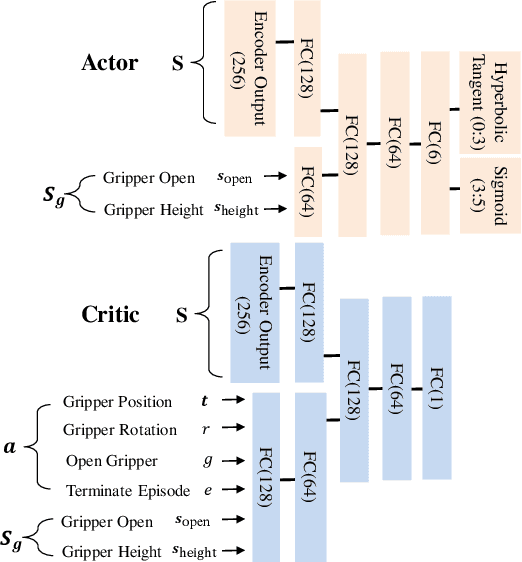
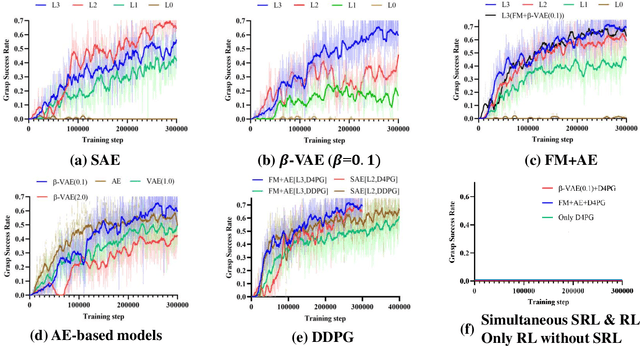
For a robotic grasping task in which diverse unseen target objects exist in a cluttered environment, some deep learning-based methods have achieved state-of-the-art results using visual input directly. In contrast, actor-critic deep reinforcement learning (RL) methods typically perform very poorly when grasping diverse objects, especially when learning from raw images and sparse rewards. To make these RL techniques feasible for vision-based grasping tasks, we employ state representation learning (SRL), where we encode essential information first for subsequent use in RL. However, typical representation learning procedures are unsuitable for extracting pertinent information for learning the grasping skill, because the visual inputs for representation learning, where a robot attempts to grasp a target object in clutter, are extremely complex. We found that preprocessing based on the disentanglement of a raw input image is the key to effectively capturing a compact representation. This enables deep RL to learn robotic grasping skills from highly varied and diverse visual inputs. We demonstrate the effectiveness of this approach with varying levels of disentanglement in a realistic simulated environment.
Multi-Scale Dense Networks for Resource Efficient Image Classification
Jun 07, 2018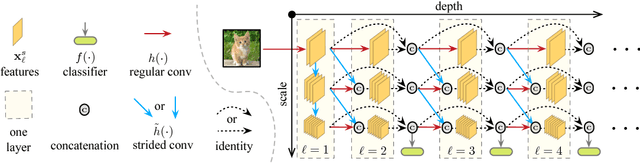
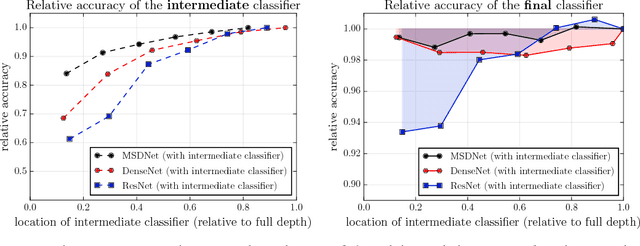

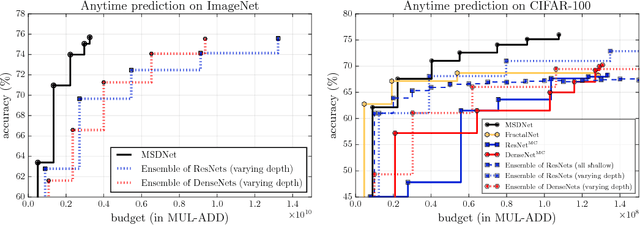
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network's prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across "easier" and "harder" inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.
DDR-Net: Learning Multi-Stage Multi-View Stereo With Dynamic Depth Range
Mar 26, 2021
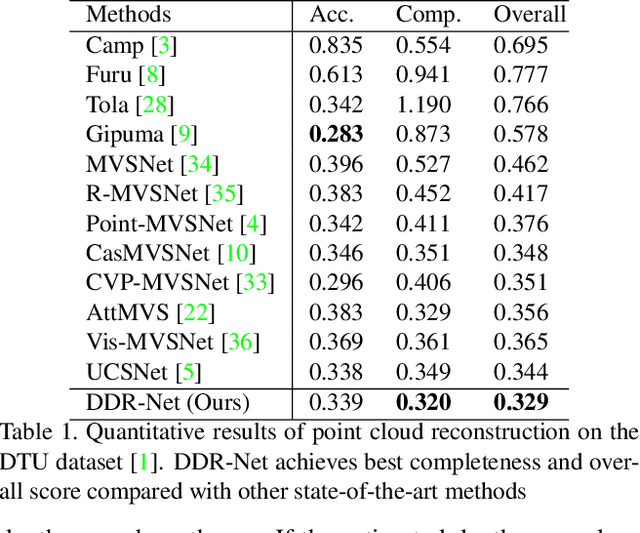
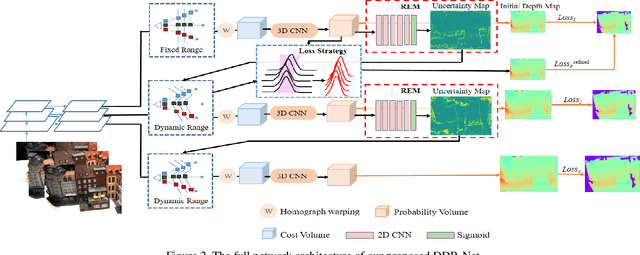

To obtain high-resolution depth maps, some previous learning-based multi-view stereo methods build a cost volume pyramid in a coarse-to-fine manner. These approaches leverage fixed depth range hypotheses to construct cascaded plane sweep volumes. However, it is inappropriate to set identical range hypotheses for each pixel since the uncertainties of previous per-pixel depth predictions are spatially varying. Distinct from these approaches, we propose a Dynamic Depth Range Network (DDR-Net) to determine the depth range hypotheses dynamically by applying a range estimation module (REM) to learn the uncertainties of range hypotheses in the former stages. Specifically, in our DDR-Net, we first build an initial depth map at the coarsest resolution of an image across the entire depth range. Then the range estimation module (REM) leverages the probability distribution information of the initial depth to estimate the depth range hypotheses dynamically for the following stages. Moreover, we develop a novel loss strategy, which utilizes learned dynamic depth ranges to generate refined depth maps, to keep the ground truth value of each pixel covered in the range hypotheses of the next stage. Extensive experimental results show that our method achieves superior performance over other state-of-the-art methods on the DTU benchmark and obtains comparable results on the Tanks and Temples benchmark. The code is available at https://github.com/Tangshengku/DDR-Net.
AI-driven Bayesian inference of statistical microstructure descriptors from finite-frequency waves
Apr 16, 2021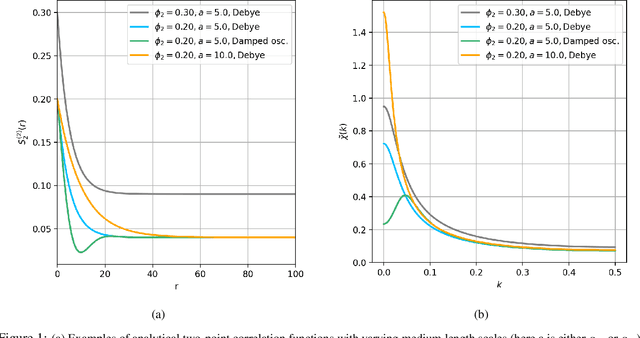
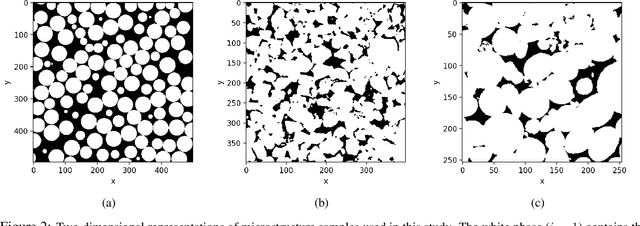
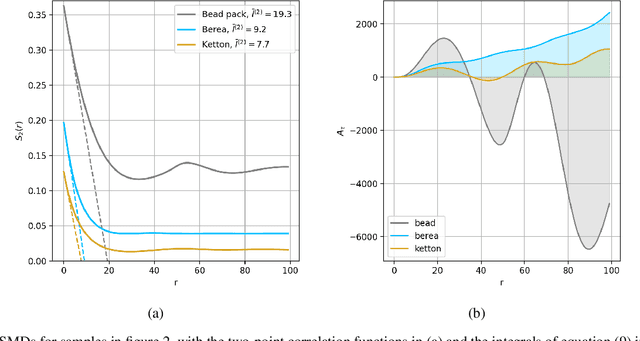
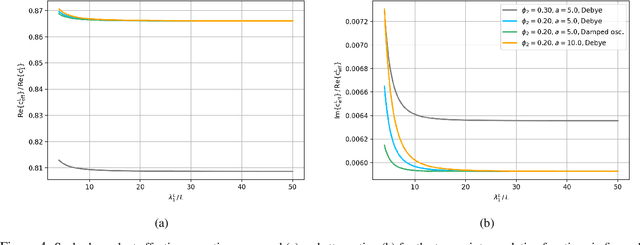
The ability to image materials at the microscale from long-wavelength wave data is a major challenge to the geophysical, engineering and medical fields. Here, we present a framework to constrain microstructure geometry and properties from long-scale waves. To realistically quantify microstructures we use two-point statistics, from which we derive scale-dependent effective wave properties - wavespeed and attenuation - using strong-contrast expansions (SCE) for (visco)elastic wavefields. By evaluating various two-point correlation functions we observe that both effective wavespeeds and attenuation of long-scale waves predominantly depend on volume fraction and phase properties, and that especially attenuation at small scales is highly sensitive to the geometry of microstructure heterogeneity (e.g. geometric hyperuniformity) due to incoherent inference of sub-wavelength multiple scattering. Our goal is to infer microstructure properties from observed effective wave parameters. To this end, we use the supervised machine learning method of Random Forests (RF) to construct a Bayesian inference approach. We can accurately resolve two-point correlation functions sampled from various microstructural configurations, including: a bead pack, Berea sandstone and Ketton limestone samples. Importantly, we show that inversion of small scale-induced effective elastic waves yields the best results, particularly compared to single-wave-mode (e.g., acoustic only) information. Additionally, we show that the retrieval of microscale medium contrasts is more difficult - as it is highly ill-posed - and can only be achieved with specific a priori knowledge. Our results are promising for many applications, such as earthquake hazard monitoring,non-destructive testing, imaging fluid flow in porous media, quantifying tissue properties in medical ultrasound, or designing materials with tailor-made wave properties.
Iterative Optimisation with an Innovation CNN for Pose Refinement
Jan 22, 2021
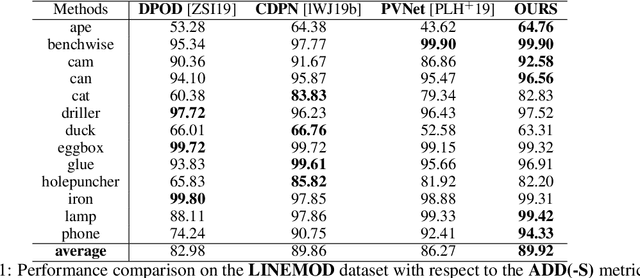
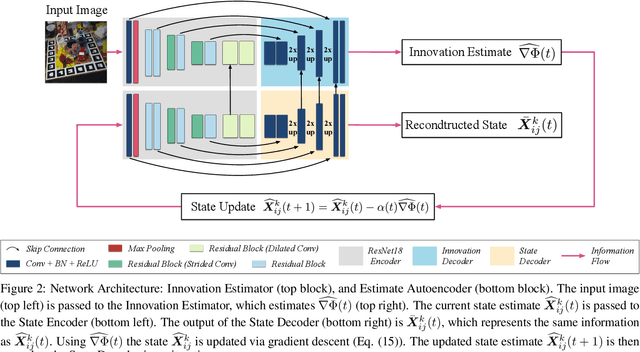
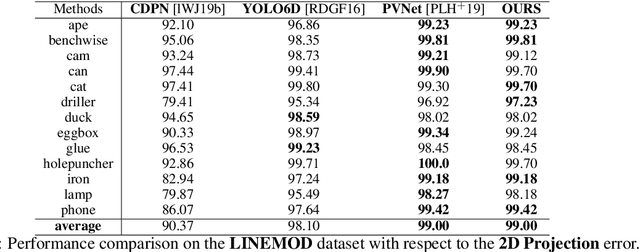
Object pose estimation from a single RGB image is a challenging problem due to variable lighting conditions and viewpoint changes. The most accurate pose estimation networks implement pose refinement via reprojection of a known, textured 3D model, however, such methods cannot be applied without high quality 3D models of the observed objects. In this work we propose an approach, namely an Innovation CNN, to object pose estimation refinement that overcomes the requirement for reprojecting a textured 3D model. Our approach improves initial pose estimation progressively by applying the Innovation CNN iteratively in a stochastic gradient descent (SGD) framework. We evaluate our method on the popular LINEMOD and Occlusion LINEMOD datasets and obtain state-of-the-art performance on both datasets.
AAA: Adaptive Aggregation of Arbitrary Online Trackers with Theoretical Performance Guarantee
Sep 19, 2020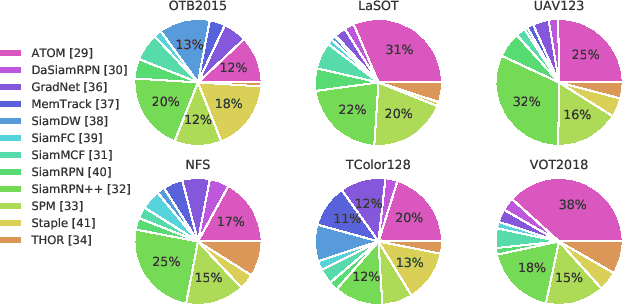
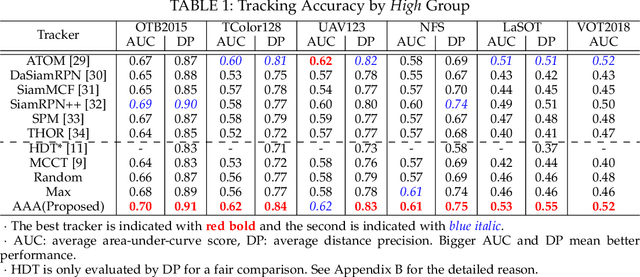

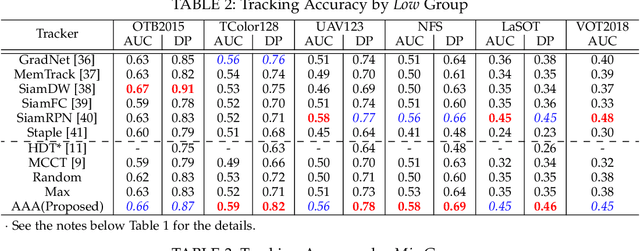
For visual object tracking, it is difficult to realize an almighty online tracker due to the huge variations of target appearance depending on an image sequence. This paper proposes an online tracking method that adaptively aggregates arbitrary multiple online trackers. The performance of the proposed method is theoretically guaranteed to be comparable to that of the best tracker for any image sequence, although the best expert is unknown during tracking. The experimental study on the large variations of benchmark datasets and aggregated trackers demonstrates that the proposed method can achieve state-of-the-art performance. The code is available at https://github.com/songheony/AAA-journal.