 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Histogram Matching Augmentation for Domain Adaptation with Application to Multi-Centre, Multi-Vendor and Multi-Disease Cardiac Image Segmentation
Dec 27, 2020
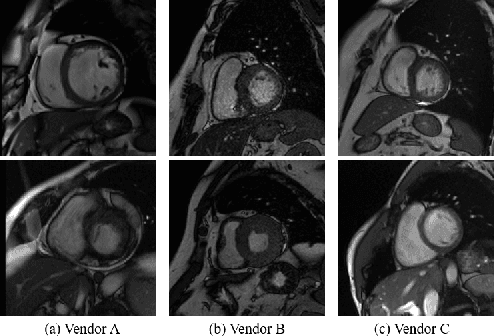
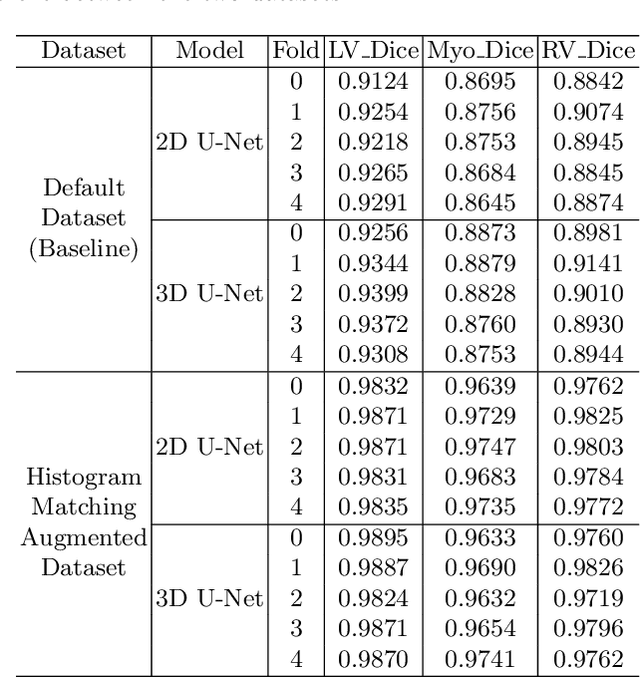
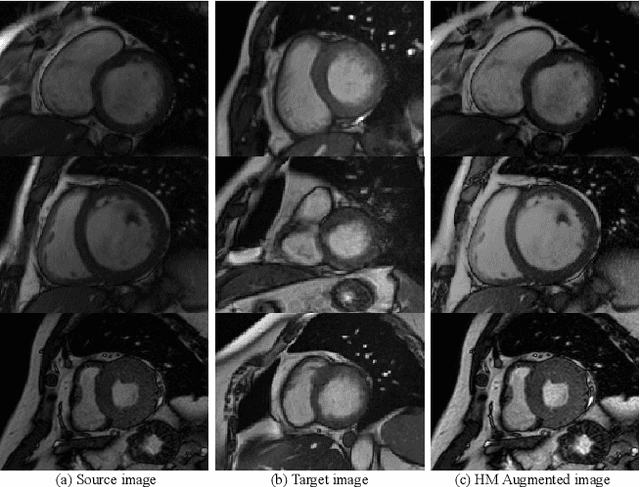
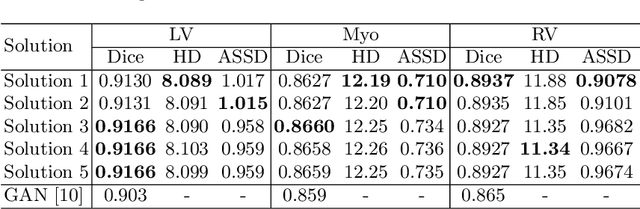
Convolutional Neural Networks (CNNs) have achieved high accuracy for cardiac structure segmentation if training cases and testing cases are from the same distribution. However, the performance would be degraded if the testing cases are from a distinct domain (e.g., new MRI scanners, clinical centers). In this paper, we propose a histogram matching (HM) data augmentation method to eliminate the domain gap. Specifically, our method generates new training cases by using HM to transfer the intensity distribution of testing cases to existing training cases. The proposed method is quite simple and can be used in a plug-and-play way in many segmentation tasks. The method is evaluated on MICCAI 2020 M\&Ms challenge, and achieves average Dice scores of 0.9051, 0.8405, and 0.8749, and Hausdorff Distances of 9.996, 12.49, and 12.68 for the left ventricular, myocardium, and right ventricular, respectively. Our results rank the third place in MICCAI 2020 M\&Ms challenge. The code and trained models are publicly available at \url{https://github.com/JunMa11/HM_DataAug}.
Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
Aug 29, 2020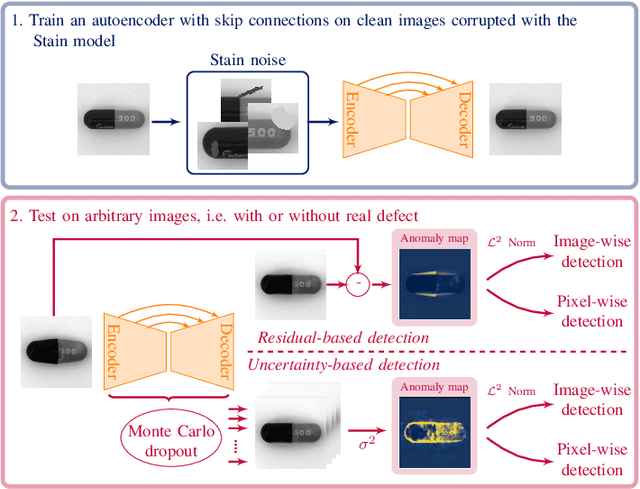
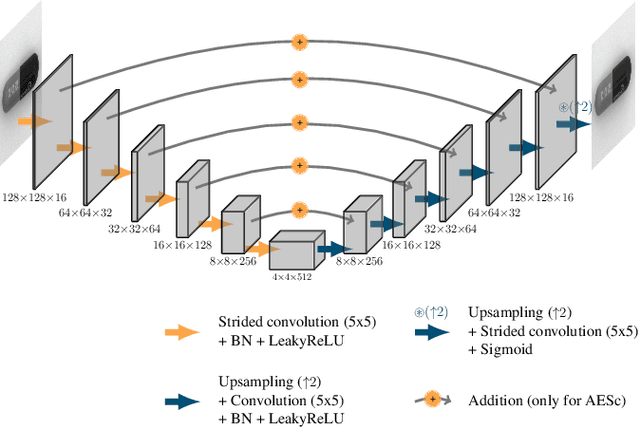

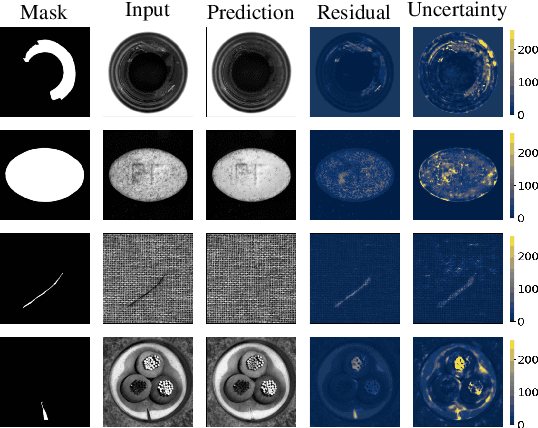
In industrial vision, the anomaly detection problem can be addressed with an autoencoder trained to map an arbitrary image, i.e. with or without any defect, to a clean image, i.e. without any defect. In this approach, anomaly detection relies conventionally on the reconstruction residual or, alternatively, on the reconstruction uncertainty. To improve the sharpness of the reconstruction, we consider an autoencoder architecture with skip connections. In the common scenario where only clean images are available for training, we propose to corrupt them with a synthetic noise model to prevent the convergence of the network towards the identity mapping, and introduce an original Stain noise model for that purpose. We show that this model favors the reconstruction of clean images from arbitrary real-world images, regardless of the actual defects appearance. In addition to demonstrating the relevance of our approach, our validation provides the first consistent assessment of reconstruction-based methods, by comparing their performance over the MVTec AD dataset, both for pixel- and image-wise anomaly detection.
The Case for High-Accuracy Classification: Think Small, Think Many!
Mar 18, 2021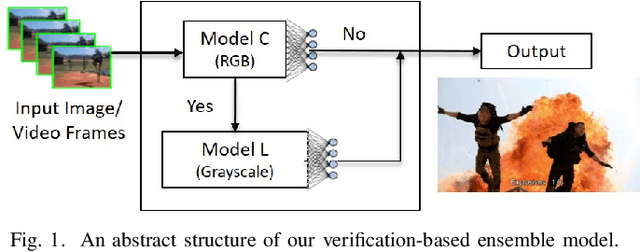

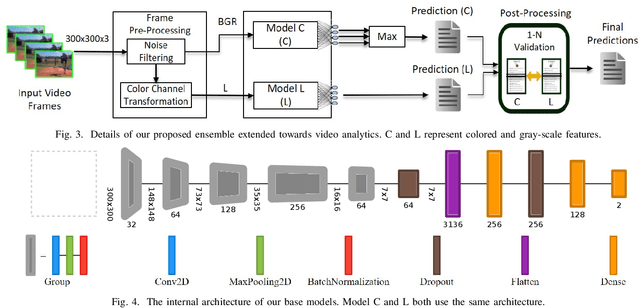
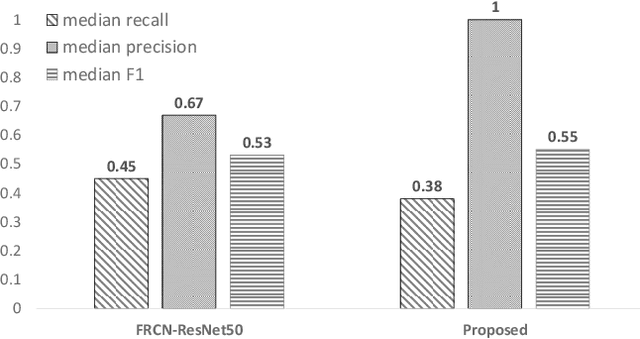
To facilitate implementation of high-accuracy deep neural networks especially on resource-constrained devices, maintaining low computation requirements is crucial. Using very deep models for classification purposes not only decreases the neural network training speed and increases the inference time, but also need more data for higher prediction accuracy and to mitigate false positives. In this paper, we propose an efficient and lightweight deep classification ensemble structure based on a combination of simple color features, which is particularly designed for "high-accuracy" image classifications with low false positives. We designed, implemented, and evaluated our approach for explosion detection use-case applied to images and videos. Our evaluation results based on a large test test show considerable improvements on the prediction accuracy compared to the popular ResNet-50 model, while benefiting from 7.64x faster inference and lower computation cost. While we applied our approach to explosion detection, our approach is general and can be applied to other similar classification use cases as well. Given the insight gained from our experiments, we hence propose a "think small, think many" philosophy in classification scenarios: that transforming a single, large, monolithic deep model into a verification-based step model ensemble of multiple small, simple, lightweight models with narrowed-down color spaces can possibly lead to predictions with higher accuracy.
Probabilistic Image Colorization
May 11, 2017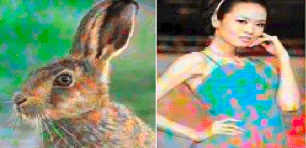
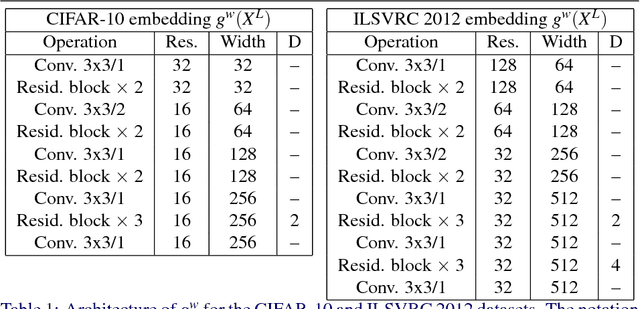
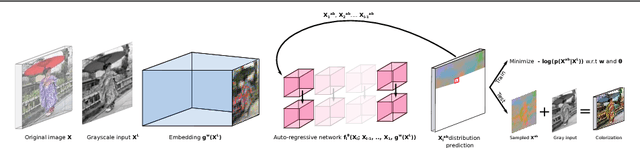

We develop a probabilistic technique for colorizing grayscale natural images. In light of the intrinsic uncertainty of this task, the proposed probabilistic framework has numerous desirable properties. In particular, our model is able to produce multiple plausible and vivid colorizations for a given grayscale image and is one of the first colorization models to provide a proper stochastic sampling scheme. Moreover, our training procedure is supported by a rigorous theoretical framework that does not require any ad hoc heuristics and allows for efficient modeling and learning of the joint pixel color distribution. We demonstrate strong quantitative and qualitative experimental results on the CIFAR-10 dataset and the challenging ILSVRC 2012 dataset.
Branched Generative Adversarial Networks for Multi-Scale Image Manifold Learning
Mar 22, 2018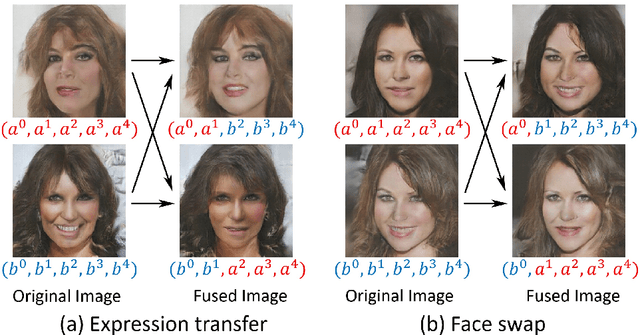
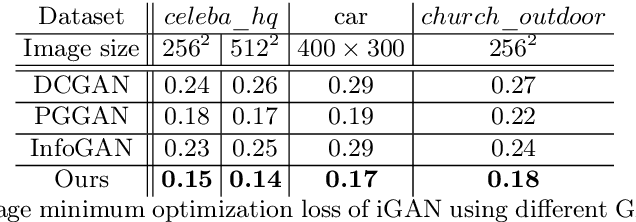
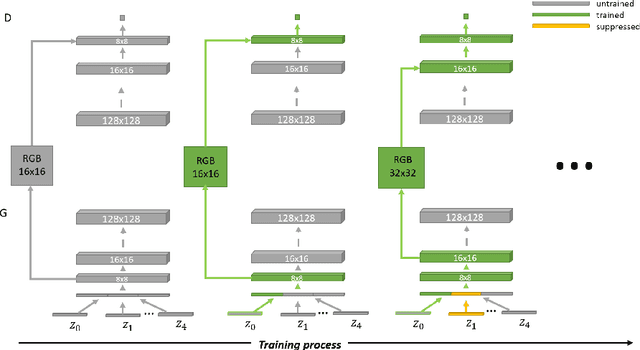
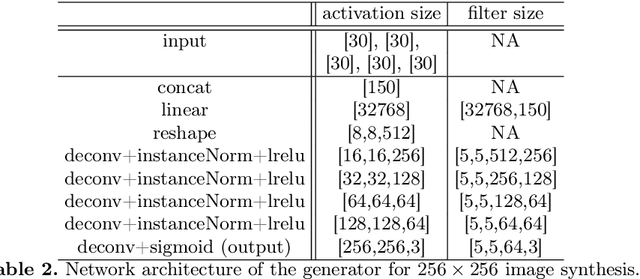
We introduce BranchGAN, a novel training method that enables unconditioned generative adversarial networks (GANs) to learn image manifolds at multiple scales. What is unique about BranchGAN is that it is trained in multiple branches, progressively covering both the breadth and depth of the network, as resolutions of the training images increase to reveal finer-scale features. Specifically, each noise vector, as input to the generator network, is explicitly split into several sub-vectors, each corresponding to and trained to learn image representations at a particular scale. During training, we progressively "de-freeze" the sub-vectors, one at a time, as a new set of higher-resolution images is employed for training and more network layers are added. A consequence of such an explicit sub-vector designation is that we can directly manipulate and even combine latent (sub-vector) codes that are associated with specific feature scales. Experiments demonstrate the effectiveness of our training method in multi-scale, disentangled learning of image manifolds and synthesis, without any extra labels and without compromising quality of the synthesized high-resolution images. We further demonstrate two new applications enabled by BranchGAN.
Uncertainty-Aware Unsupervised Domain Adaptation in Object Detection
Feb 27, 2021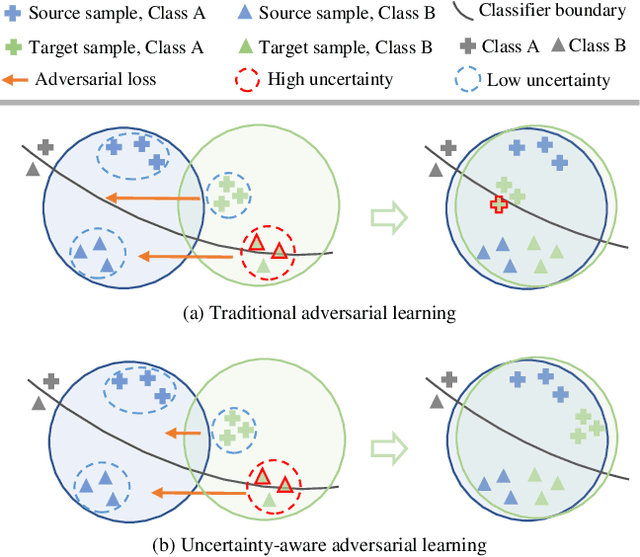
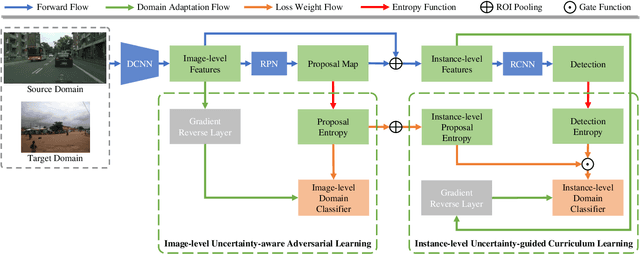

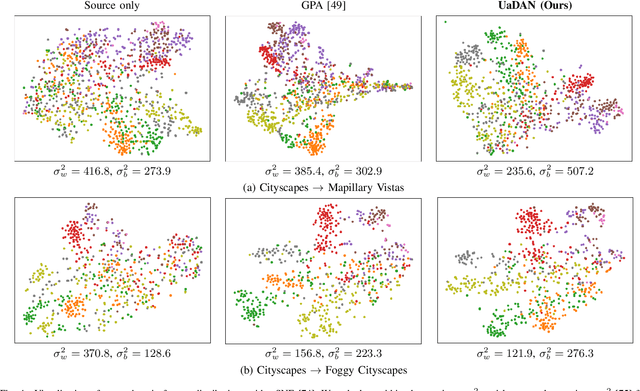
Unsupervised domain adaptive object detection aims to adapt detectors from a labelled source domain to an unlabelled target domain. Most existing works take a two-stage strategy that first generates region proposals and then detects objects of interest, where adversarial learning is widely adopted to mitigate the inter-domain discrepancy in both stages. However, adversarial learning may impair the alignment of well-aligned samples as it merely aligns the global distributions across domains. To address this issue, we design an uncertainty-aware domain adaptation network (UaDAN) that introduces conditional adversarial learning to align well-aligned and poorly-aligned samples separately in different manners. Specifically, we design an uncertainty metric that assesses the alignment of each sample and adjusts the strength of adversarial learning for well-aligned and poorly-aligned samples adaptively. In addition, we exploit the uncertainty metric to achieve curriculum learning that first performs easier image-level alignment and then more difficult instance-level alignment progressively. Extensive experiments over four challenging domain adaptive object detection datasets show that UaDAN achieves superior performance as compared with state-of-the-art methods.
Q-matrix Unaware Double JPEG Detection using DCT-Domain Deep BiLSTM Network
Apr 10, 2021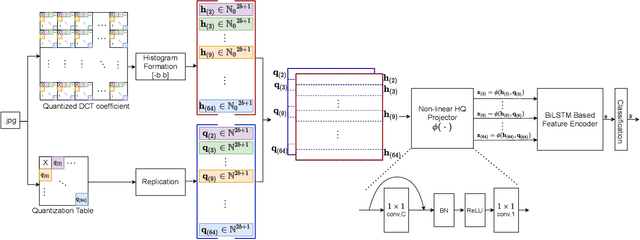
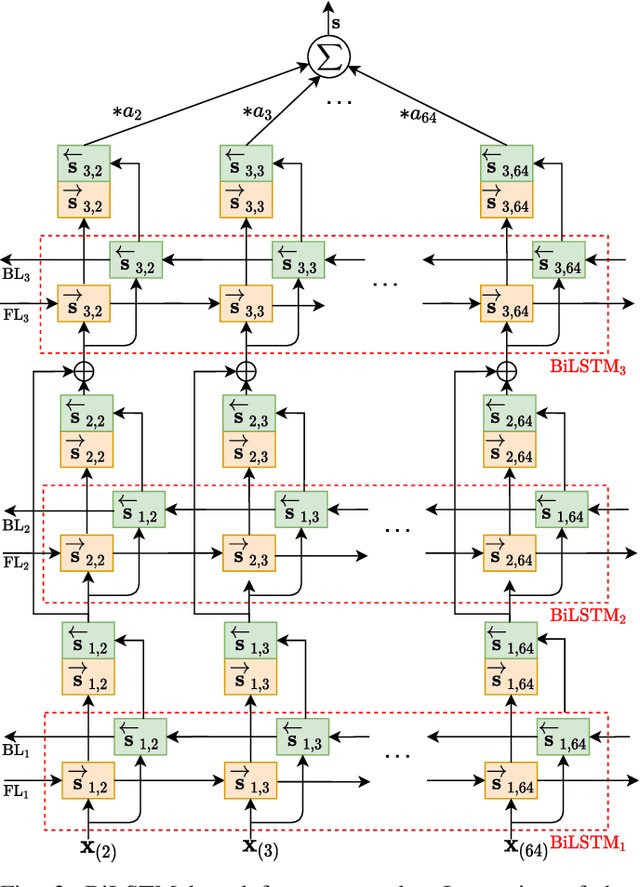

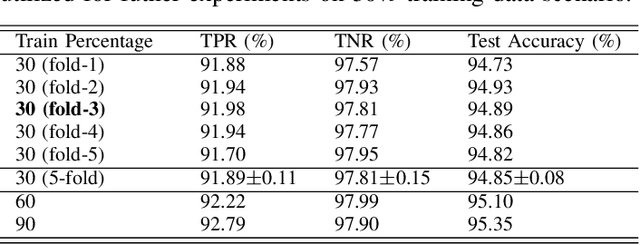
The double JPEG compression detection has received much attention in recent years due to its applicability as a forensic tool for the most widely used JPEG file format. Existing state-of-the-art CNN-based methods either use histograms of all the frequencies or rely on heuristics to select histograms of specific low frequencies to classify single and double compressed images. However, even amidst lower frequencies of double compressed images/patches, histograms of all the frequencies do not have distinguishable features to separate them from single compressed images. This paper directly extracts the quantized DCT coefficients from the JPEG images without decompressing them in the pixel domain, obtains all AC frequencies' histograms, uses a module based on $1\times 1$ depth-wise convolutions to learn the inherent relation between each histogram and corresponding q-factor, and utilizes a tailor-made BiLSTM network for selectively encoding these feature vector sequences. The proposed system outperforms several baseline methods on a relatively large and diverse publicly available dataset of single and double compressed patches. Another essential aspect of any single vs. double JPEG compression detection system is handling the scenario where test patches are compressed with entirely different quantization matrices (Q-matrices) than those used while training; different camera manufacturers and image processing software generally utilize their customized quantization matrices. A set of extensive experiments shows that the proposed system trained on a single dataset generalizes well on other datasets compressed with completely unseen quantization matrices and outperforms the state-of-the-art methods in both seen and unseen quantization matrices scenarios.
Look, Cast and Mold: Learning 3D Shape Manifold from Single-view Synthetic Data
Mar 18, 2021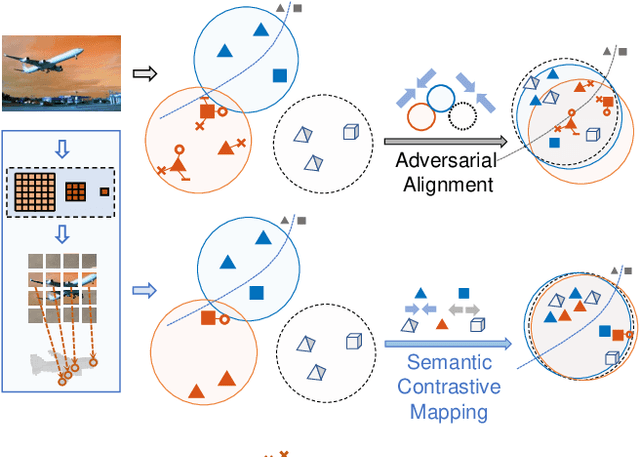
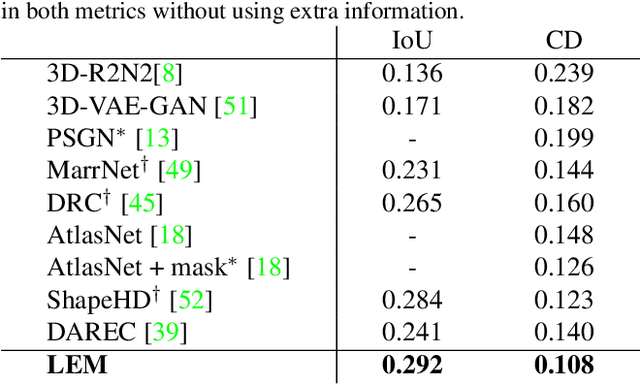
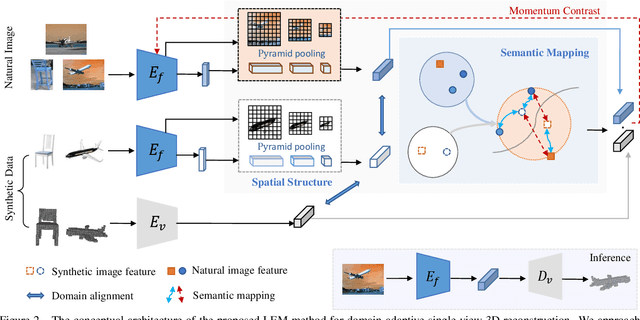
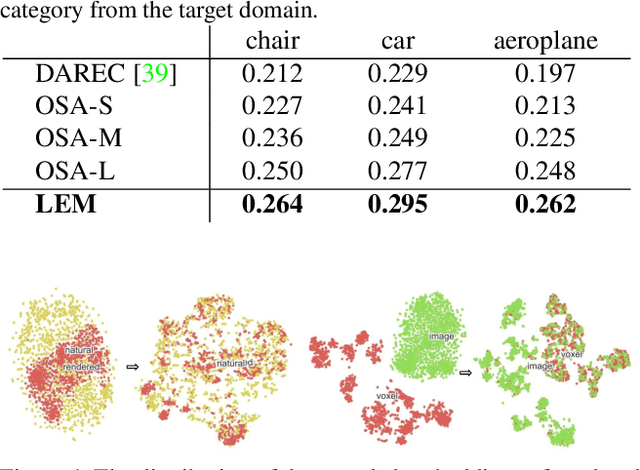
Inferring the stereo structure of objects in the real world is a challenging yet practical task. To equip deep models with this ability usually requires abundant 3D supervision which is hard to acquire. It is promising that we can simply benefit from synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gaps are nontrivial considering the variant texture, shape and context. To overcome these difficulties, we propose a Visio-Perceptual Adaptive Network for single-view 3D reconstruction, dubbed VPAN. To generalize the model towards a real scenario, we propose to fulfill several aspects: (1) Look: visually incorporate spatial structure from the single view to enhance the expressiveness of representation; (2) Cast: perceptually align the 2D image features to the 3D shape priors with cross-modal semantic contrastive mapping; (3) Mold: reconstruct stereo-shape of target by transforming embeddings into the desired manifold. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method in learning the 3D shape manifold from synthetic data via a single-view. The proposed method outperforms state-of-the-arts on Pix3D dataset with IoU 0.292 and CD 0.108, and reaches IoU 0.329 and CD 0.104 on Pascal 3D+.
Exploiting Adam-like Optimization Algorithms to Improve the Performance of Convolutional Neural Networks
Mar 26, 2021
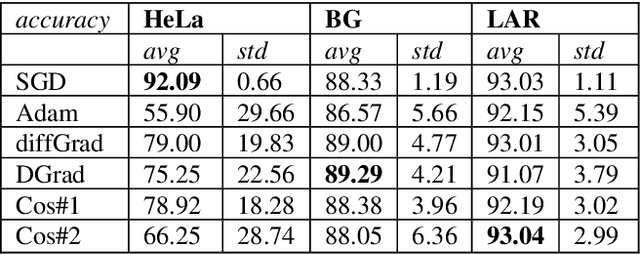
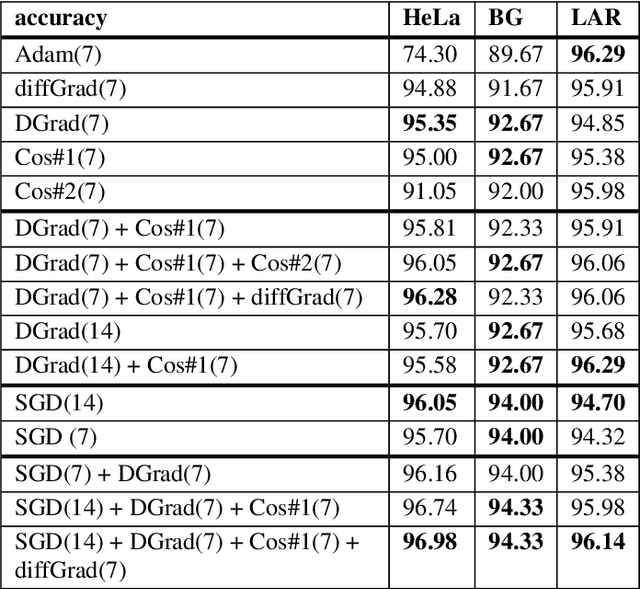
Stochastic gradient descent (SGD) is the main approach for training deep networks: it moves towards the optimum of the cost function by iteratively updating the parameters of a model in the direction of the gradient of the loss evaluated on a minibatch. Several variants of SGD have been proposed to make adaptive step sizes for each parameter (adaptive gradient) and take into account the previous updates (momentum). Among several alternative of SGD the most popular are AdaGrad, AdaDelta, RMSProp and Adam which scale coordinates of the gradient by square roots of some form of averaging of the squared coordinates in the past gradients and automatically adjust the learning rate on a parameter basis. In this work, we compare Adam based variants based on the difference between the present and the past gradients, the step size is adjusted for each parameter. We run several tests benchmarking proposed methods using medical image data. The experiments are performed using ResNet50 architecture neural network. Moreover, we have tested ensemble of networks and the fusion with ResNet50 trained with stochastic gradient descent. To combine the set of ResNet50 the simple sum rule has been applied. Proposed ensemble obtains very high performance, it obtains accuracy comparable or better than actual state of the art. To improve reproducibility and research efficiency the MATLAB source code used for this research is available at GitHub: https://github.com/LorisNanni.
Multi-Scale Dense Networks for Resource Efficient Image Classification
Jun 07, 2018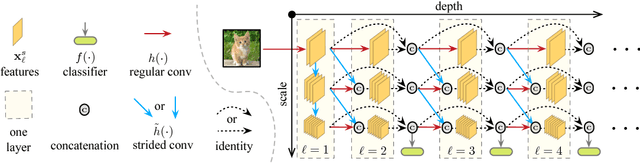
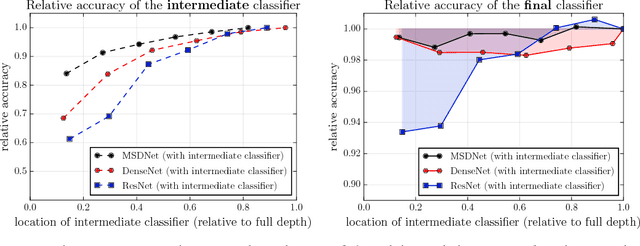

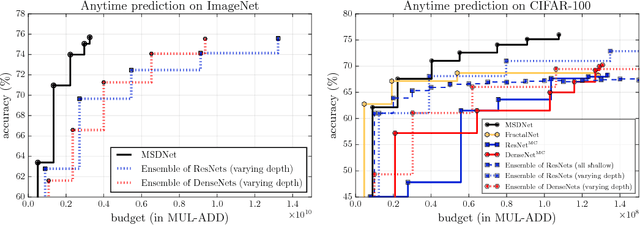
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network's prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across "easier" and "harder" inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.