 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LambdaNetworks: Modeling Long-Range Interactions Without Attention
Feb 17, 2021

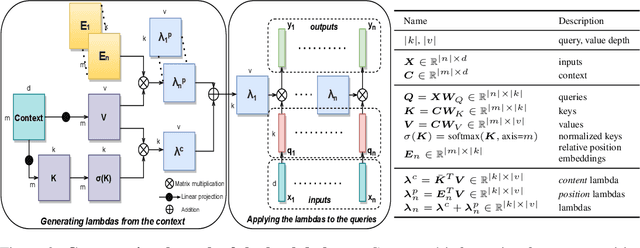


We present lambda layers -- an alternative framework to self-attention -- for capturing long-range interactions between an input and structured contextual information (e.g. a pixel surrounded by other pixels). Lambda layers capture such interactions by transforming available contexts into linear functions, termed lambdas, and applying these linear functions to each input separately. Similar to linear attention, lambda layers bypass expensive attention maps, but in contrast, they model both content and position-based interactions which enables their application to large structured inputs such as images. The resulting neural network architectures, LambdaNetworks, significantly outperform their convolutional and attentional counterparts on ImageNet classification, COCO object detection and COCO instance segmentation, while being more computationally efficient. Additionally, we design LambdaResNets, a family of hybrid architectures across different scales, that considerably improves the speed-accuracy tradeoff of image classification models. LambdaResNets reach excellent accuracies on ImageNet while being 3.2 - 4.4x faster than the popular EfficientNets on modern machine learning accelerators. When training with an additional 130M pseudo-labeled images, LambdaResNets achieve up to a 9.5x speed-up over the corresponding EfficientNet checkpoints.
Light Field Reconstruction Using Convolutional Network on EPI and Extended Applications
Mar 24, 2021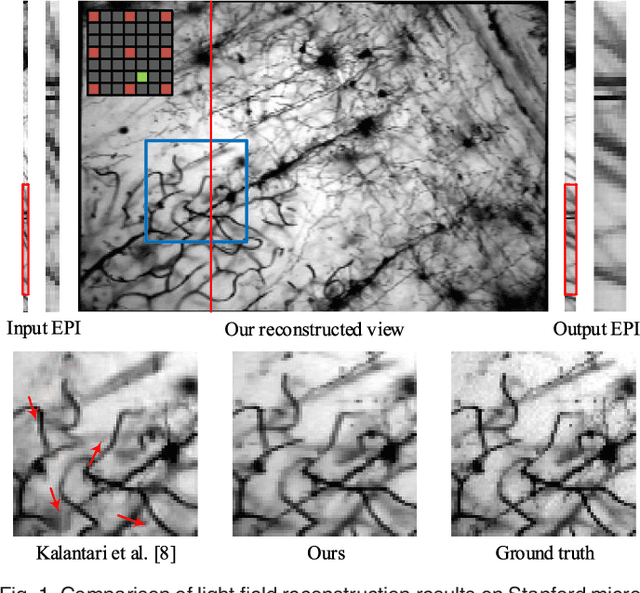
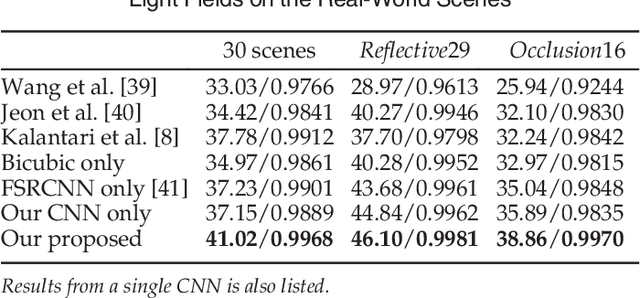


In this paper, a novel convolutional neural network (CNN)-based framework is developed for light field reconstruction from a sparse set of views. We indicate that the reconstruction can be efficiently modeled as angular restoration on an epipolar plane image (EPI). The main problem in direct reconstruction on the EPI involves an information asymmetry between the spatial and angular dimensions, where the detailed portion in the angular dimensions is damaged by undersampling. Directly upsampling or super-resolving the light field in the angular dimensions causes ghosting effects. To suppress these ghosting effects, we contribute a novel "blur-restoration-deblur" framework. First, the "blur" step is applied to extract the low-frequency components of the light field in the spatial dimensions by convolving each EPI slice with a selected blur kernel. Then, the "restoration" step is implemented by a CNN, which is trained to restore the angular details of the EPI. Finally, we use a non-blind "deblur" operation to recover the spatial high frequencies suppressed by the EPI blur. We evaluate our approach on several datasets, including synthetic scenes, real-world scenes and challenging microscope light field data. We demonstrate the high performance and robustness of the proposed framework compared with state-of-the-art algorithms. We further show extended applications, including depth enhancement and interpolation for unstructured input. More importantly, a novel rendering approach is presented by combining the proposed framework and depth information to handle large disparities.
* Published in IEEE TPAMI, 2019
SemI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data
Feb 14, 2020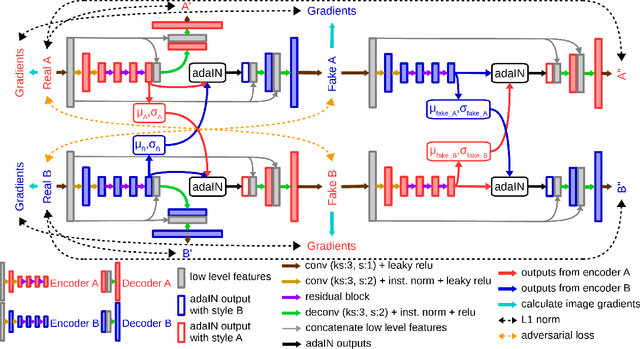
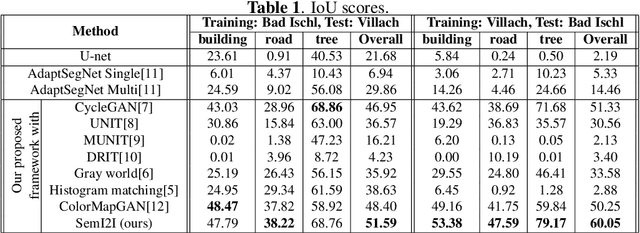

Although convolutional neural networks have been proven to be an effective tool to generate high quality maps from remote sensing images, their performance significantly deteriorates when there exists a large domain shift between training and test data. To address this issue, we propose a new data augmentation approach that transfers the style of test data to training data using generative adversarial networks. Our semantic segmentation framework consists in first training a U-net from the real training data and then fine-tuning it on the test stylized fake training data generated by the proposed approach. Our experimental results prove that our framework outperforms the existing domain adaptation methods.
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
Jan 08, 2019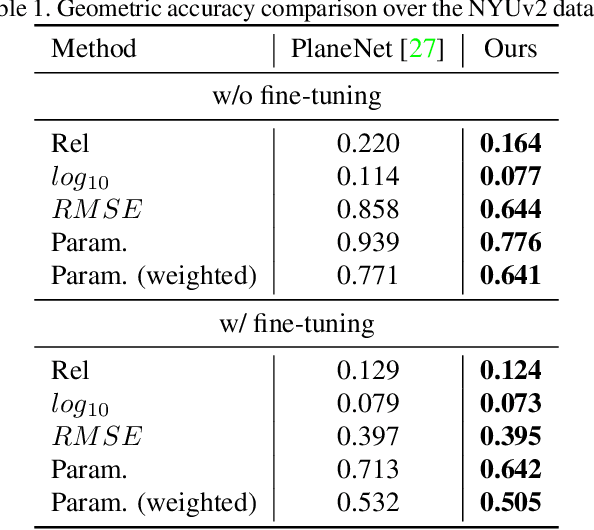
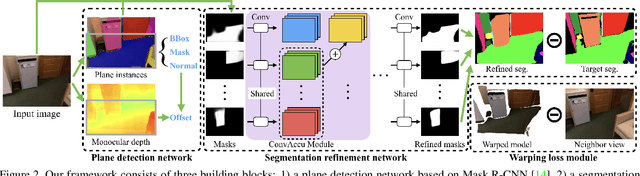
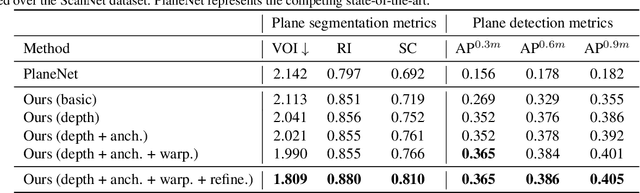

This paper proposes a deep neural architecture, PlaneRCNN, that detects and reconstructs piecewise planar surfaces from a single RGB image. PlaneRCNN employs a variant of Mask R-CNN to detect planes with their plane parameters and segmentation masks. PlaneRCNN then jointly refines all the segmentation masks with a novel loss enforcing the consistency with a nearby view during training. The paper also presents a new benchmark with more fine-grained plane segmentations in the ground-truth, in which, PlaneRCNN outperforms existing state-of-the-art methods with significant margins in the plane detection, segmentation, and reconstruction metrics. PlaneRCNN makes an important step towards robust plane extraction, which would have an immediate impact on a wide range of applications including Robotics, Augmented Reality, and Virtual Reality.
Finding Relevant Flood Images on Twitter using Content-based Filters
Nov 11, 2020
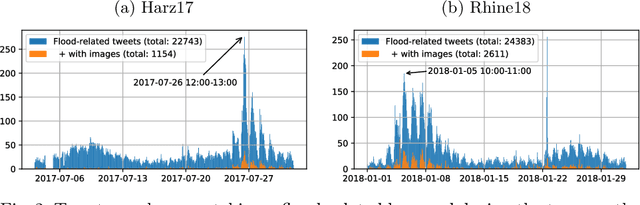
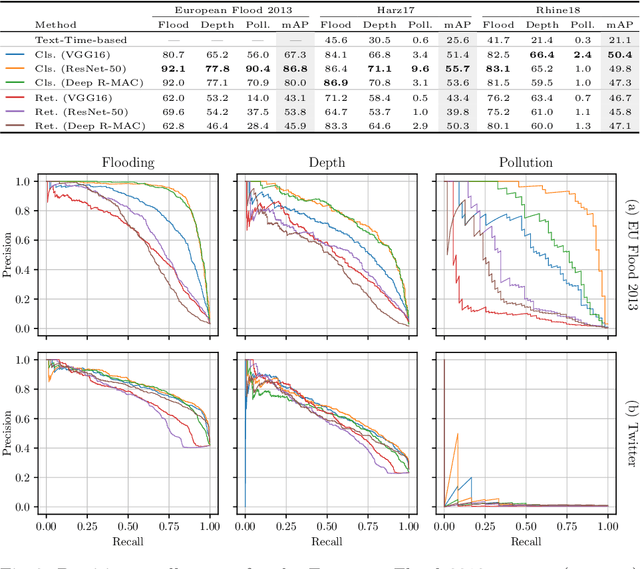
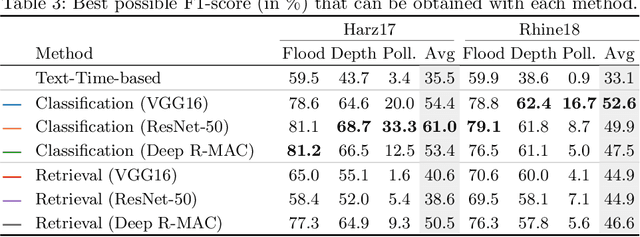
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to coarsely distributed sensors or sensor failures. At the same time, a plethora of information is buried in an abundance of images of the event posted on social media platforms such as Twitter. These images could be used to document and rapidly assess the situation and derive proxy-data not available from sensors, e.g., the degree of water pollution. However, not all images posted online are suitable or informative enough for this purpose. Therefore, we propose an automatic filtering approach using machine learning techniques for finding Twitter images that are relevant for one of the following information objectives: assessing the flooded area, the inundation depth, and the degree of water pollution. Instead of relying on textual information present in the tweet, the filter analyzes the image contents directly. We evaluate the performance of two different approaches and various features on a case-study of two major flooding events. Our image-based filter is able to enhance the quality of the results substantially compared with a keyword-based filter, improving the mean average precision from 23% to 53% on average.
Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders
Aug 12, 2020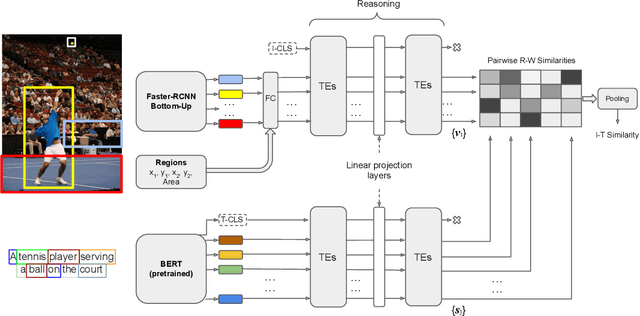
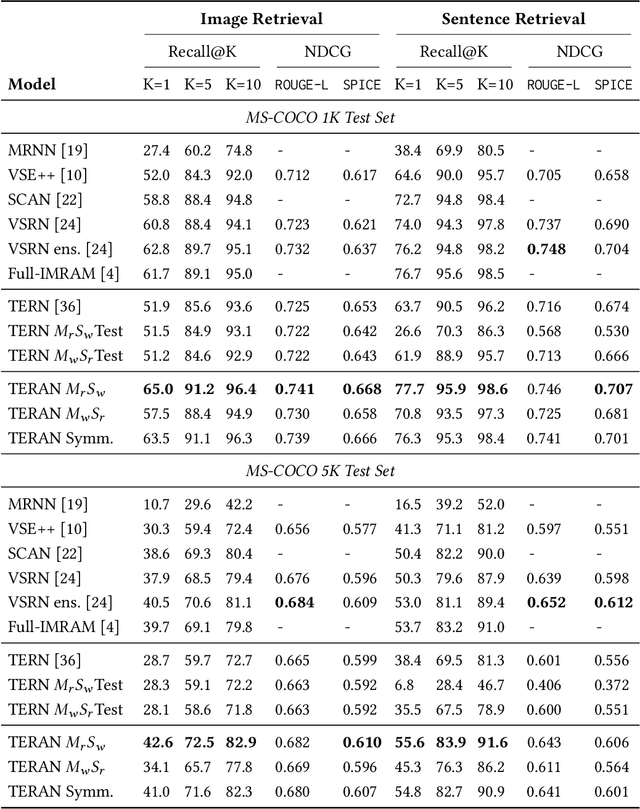
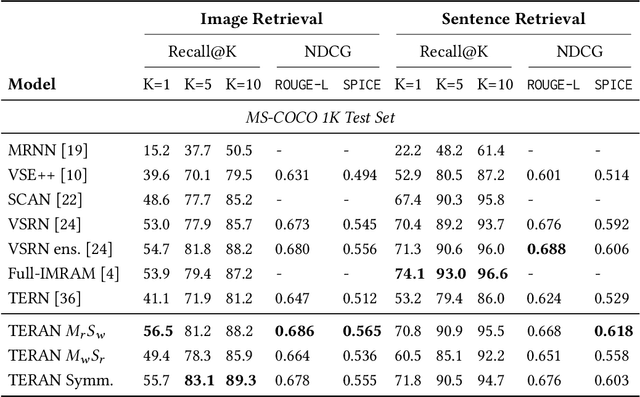

Despite the evolution of deep-learning-based visual-textual processing systems, precise multi-modal matching remains a challenging task. In this work, we tackle the problem of accurate cross-media retrieval through image-sentence matching based on word-region alignments using supervision only at the global image-sentence level. In particular, we present an approach called Transformer Encoder Reasoning and Alignment Network (TERAN). TERAN enforces a fine-grained match between the underlying components of images and sentences, i.e., image regions and words, respectively, in order to preserve the informative richness of both modalities. The proposed approach obtains state-of-the-art results on the image retrieval task on both MS-COCO and Flickr30k. Moreover, on MS-COCO, it defeats current approaches also on the sentence retrieval task. Given our long-term interest in scalable cross-modal information retrieval, TERAN is designed to keep the visual and textual data pipelines well separated. In fact, cross-attention links invalidate any chance to separately extract visual and textual features needed for the online search and the offline indexing steps in large-scale retrieval systems. In this respect, TERAN merges the information from the two domains only during the final alignment phase, immediately before the loss computation. We argue that the fine-grained alignments produced by TERAN pave the way towards the research for effective and efficient methods for large-scale cross-modal information retrieval. We compare the effectiveness of our approach against the best eight methods in this research area. On the MS-COCO 1K test set, we obtain an improvement of 3.5% and 1.2% respectively on the image and the sentence retrieval tasks on the Recall@1 metric. The code used for the experiments is publicly available on GitHub at https://github.com/mesnico/TERAN.
HarDNet-MSEG: A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS
Jan 18, 2021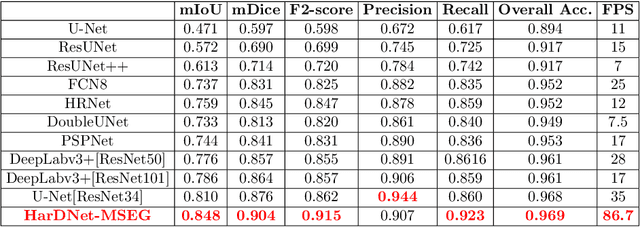
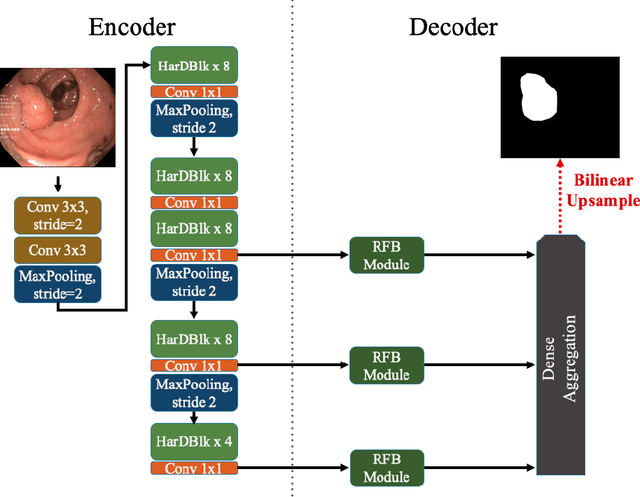
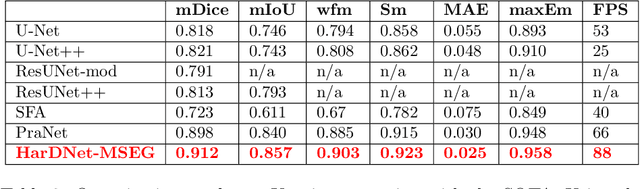
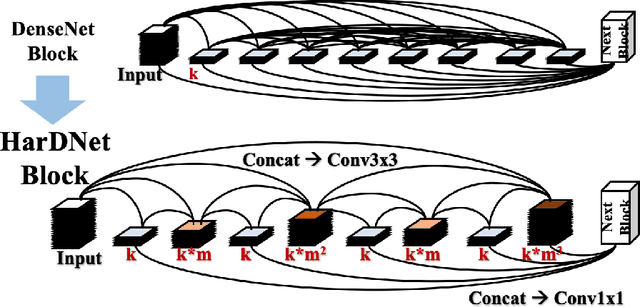
We propose a new convolution neural network called HarDNet-MSEG for polyp segmentation. It achieves SOTA in both accuracy and inference speed on five popular datasets. For Kvasir-SEG, HarDNet-MSEG delivers 0.904 mean Dice running at 86.7 FPS on a GeForce RTX 2080 Ti GPU. It consists of a backbone and a decoder. The backbone is a low memory traffic CNN called HarDNet68, which has been successfully applied to various CV tasks including image classification, object detection, multi-object tracking and semantic segmentation, etc. The decoder part is inspired by the Cascaded Partial Decoder, known for fast and accurate salient object detection. We have evaluated HarDNet-MSEG using those five popular datasets. The code and all experiment details are available at Github. https://github.com/james128333/HarDNet-MSEG
Split Computing and Early Exiting for Deep Learning Applications: Survey and Research Challenges
Mar 08, 2021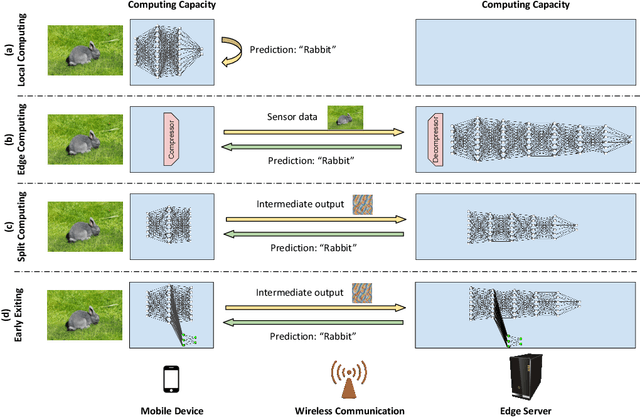
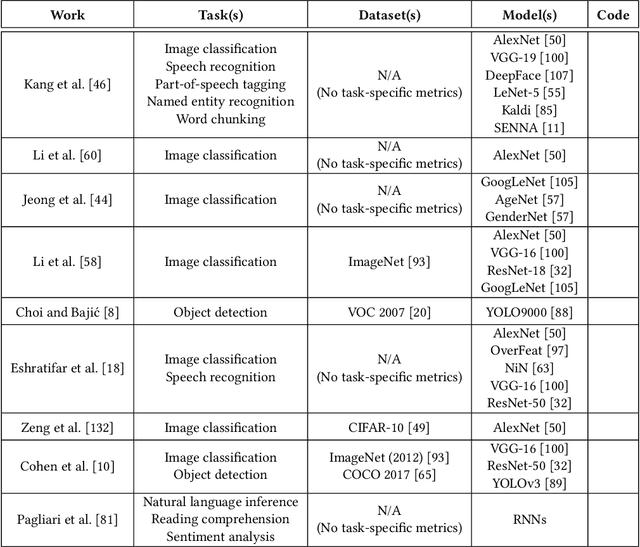
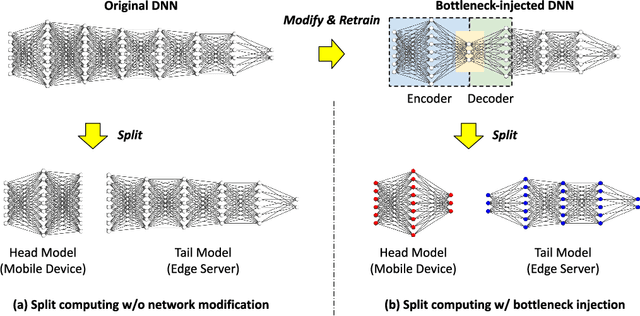
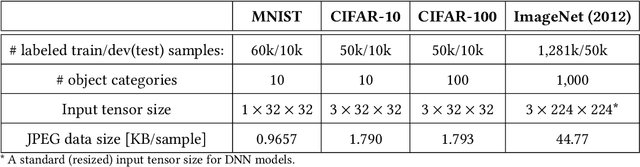
Mobile devices such as smartphones and autonomous vehicles increasingly rely on deep neural networks (DNNs) to execute complex inference tasks such as image classification and speech recognition, among others. However, continuously executing the entire DNN on the mobile device can quickly deplete its battery. Although task offloading to edge devices may decrease the mobile device's computational burden, erratic patterns in channel quality, network and edge server load can lead to a significant delay in task execution. Recently, approaches based on split computing (SC) have been proposed, where the DNN is split into a head and a tail model, executed respectively on the mobile device and on the edge device. Ultimately, this may reduce bandwidth usage as well as energy consumption. Another approach, called early exiting (EE), trains models to present multiple "exits" earlier in the architecture, each providing increasingly higher target accuracy. Therefore, the trade-off between accuracy and delay can be tuned according to the current conditions or application demands. In this paper, we provide a comprehensive survey of the state of the art in SC and EE strategies, by presenting a comparison of the most relevant approaches. We conclude the paper by providing a set of compelling research challenges.
Applications of Deep Learning in Fundus Images: A Review
Jan 25, 2021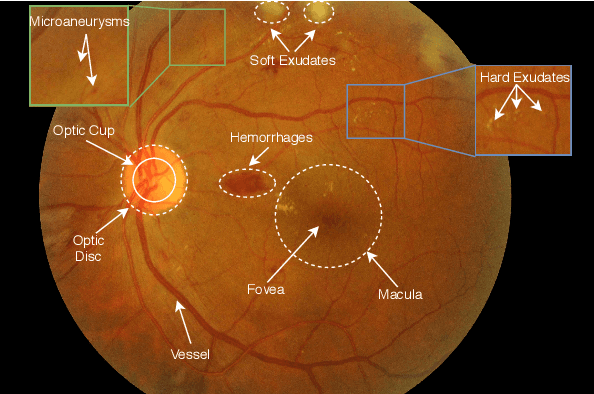
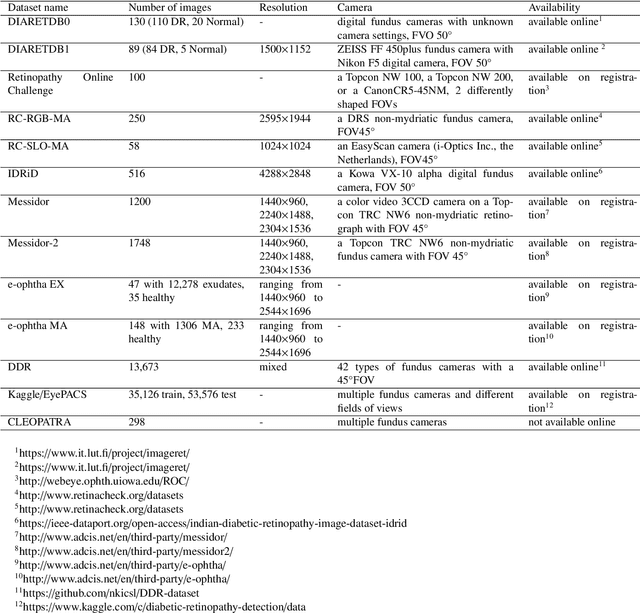
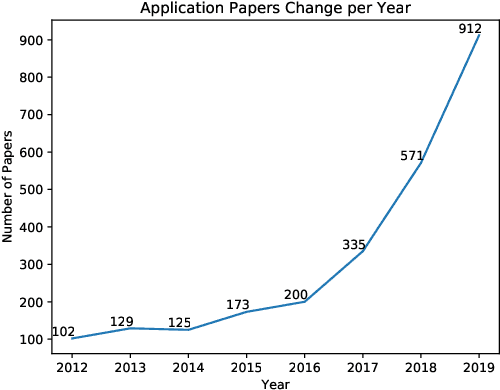
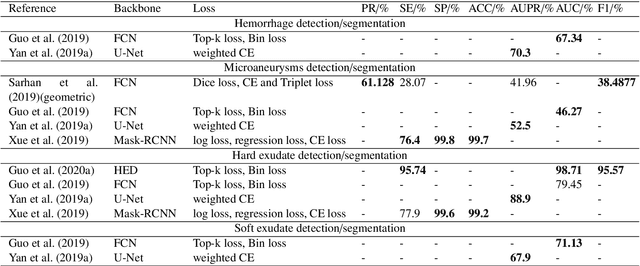
The use of fundus images for the early screening of eye diseases is of great clinical importance. Due to its powerful performance, deep learning is becoming more and more popular in related applications, such as lesion segmentation, biomarkers segmentation, disease diagnosis and image synthesis. Therefore, it is very necessary to summarize the recent developments in deep learning for fundus images with a review paper. In this review, we introduce 143 application papers with a carefully designed hierarchy. Moreover, 33 publicly available datasets are presented. Summaries and analyses are provided for each task. Finally, limitations common to all tasks are revealed and possible solutions are given. We will also release and regularly update the state-of-the-art results and newly-released datasets at https://github.com/nkicsl/Fundus Review to adapt to the rapid development of this field.
MLMA-Net: multi-level multi-attentional learning for multi-label object detection in textile defect images
Jan 31, 2021

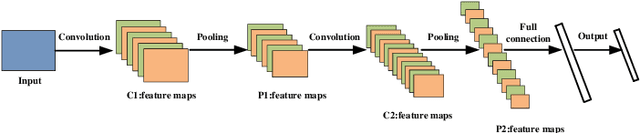
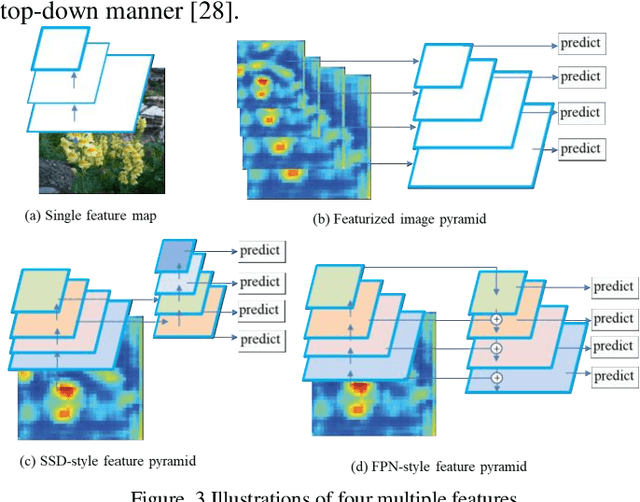
For the sake of recognizing and classifying textile defects, deep learning-based methods have been proposed and achieved remarkable success in single-label textile images. However, detecting multi-label defects in a textile image remains challenging due to the coexistence of multiple defects and small-size defects. To address these challenges, a multi-level, multi-attentional deep learning network (MLMA-Net) is proposed and built to 1) increase the feature representation ability to detect small-size defects; 2) generate a discriminative representation that maximizes the capability of attending the defect status, which leverages higher-resolution feature maps for multiple defects. Moreover, a multi-label object detection dataset (DHU-ML1000) in textile defect images is built to verify the performance of the proposed model. The results demonstrate that the network extracts more distinctive features and has better performance than the state-of-the-art approaches on the real-world industrial dataset.