 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 08, 2021
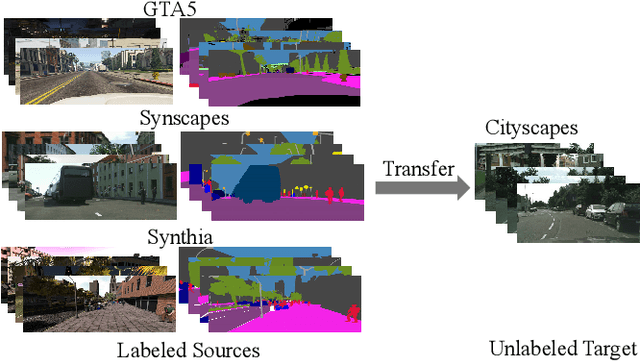
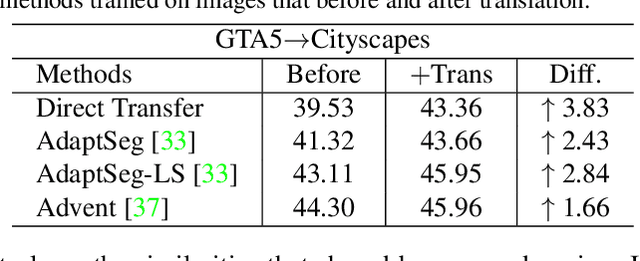
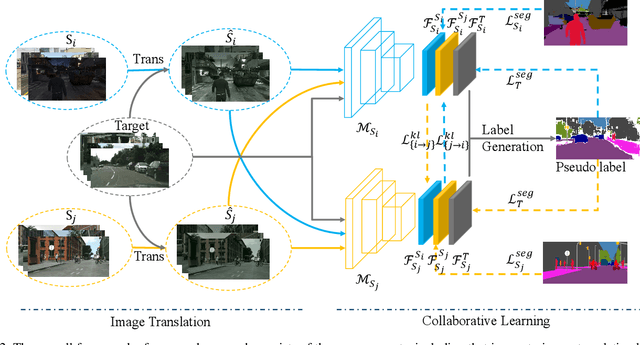
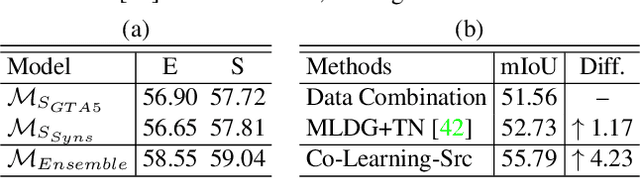
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.
Interpreting Super-Resolution Networks with Local Attribution Maps
Nov 22, 2020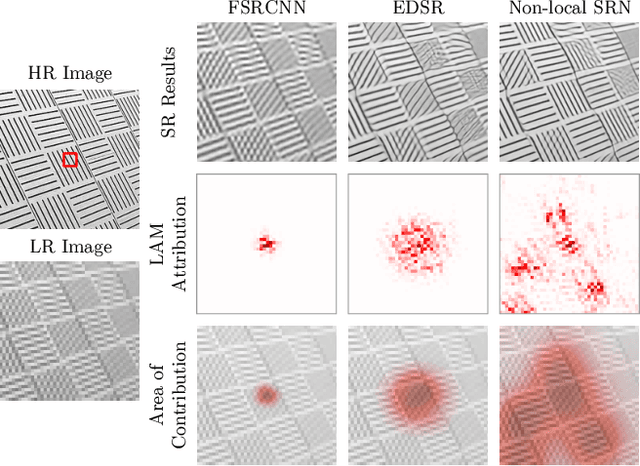
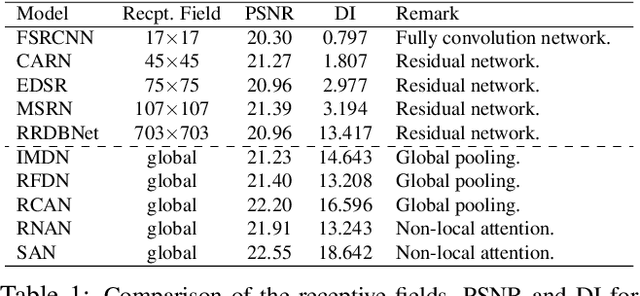
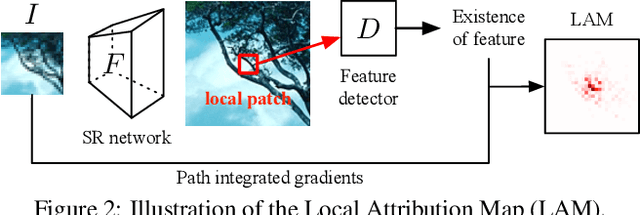
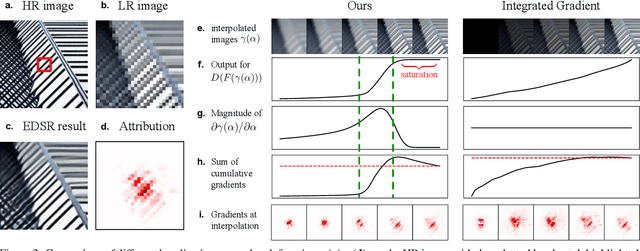
Image super-resolution (SR) techniques have been developing rapidly, benefiting from the invention of deep networks and its successive breakthroughs. However, it is acknowledged that deep learning and deep neural networks are difficult to interpret. SR networks inherit this mysterious nature and little works make attempt to understand them. In this paper, we perform attribution analysis of SR networks, which aims at finding the input pixels that strongly influence the SR results. We propose a novel attribution approach called local attribution map (LAM), which inherits the integral gradient method yet with two unique features. One is to use the blurred image as the baseline input, and the other is to adopt the progressive blurring function as the path function. Based on LAM, we show that: (1) SR networks with a wider range of involved input pixels could achieve better performance. (2) Attention networks and non-local networks extract features from a wider range of input pixels. (3) Comparing with the range that actually contributes, the receptive field is large enough for most deep networks. (4) For SR networks, textures with regular stripes or grids are more likely to be noticed, while complex semantics are difficult to utilize. Our work opens new directions for designing SR networks and interpreting low-level vision deep models.
Bootstrapping Your Own Positive Sample: Contrastive Learning With Electronic Health Record Data
Apr 07, 2021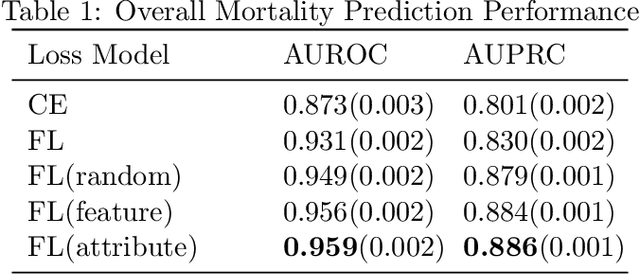
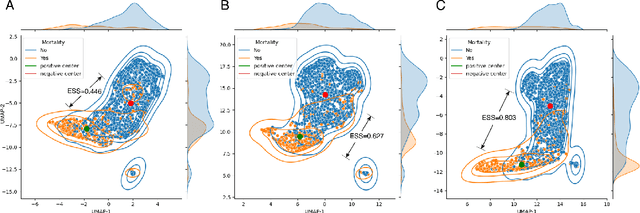
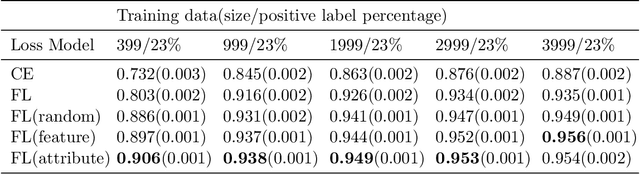
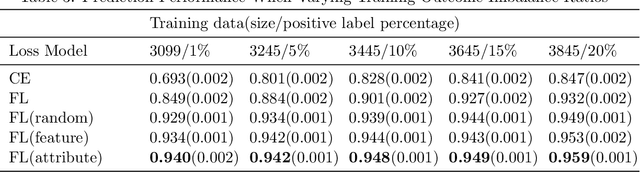
Electronic Health Record (EHR) data has been of tremendous utility in Artificial Intelligence (AI) for healthcare such as predicting future clinical events. These tasks, however, often come with many challenges when using classical machine learning models due to a myriad of factors including class imbalance and data heterogeneity (i.e., the complex intra-class variances). To address some of these research gaps, this paper leverages the exciting contrastive learning framework and proposes a novel contrastive regularized clinical classification model. The contrastive loss is found to substantially augment EHR-based prediction: it effectively characterizes the similar/dissimilar patterns (by its "push-and-pull" form), meanwhile mitigating the highly skewed class distribution by learning more balanced feature spaces (as also echoed by recent findings). In particular, when naively exporting the contrastive learning to the EHR data, one hurdle is in generating positive samples, since EHR data is not as amendable to data augmentation as image data. To this end, we have introduced two unique positive sampling strategies specifically tailored for EHR data: a feature-based positive sampling that exploits the feature space neighborhood structure to reinforce the feature learning; and an attribute-based positive sampling that incorporates pre-generated patient similarity metrics to define the sample proximity. Both sampling approaches are designed with an awareness of unique high intra-class variance in EHR data. Our overall framework yields highly competitive experimental results in predicting the mortality risk on real-world COVID-19 EHR data with a total of 5,712 patients admitted to a large, urban health system. Specifically, our method reaches a high AUROC prediction score of 0.959, which outperforms other baselines and alternatives: cross-entropy(0.873) and focal loss(0.931).
Student Mixture Model Based Visual Servoing
Jun 19, 2020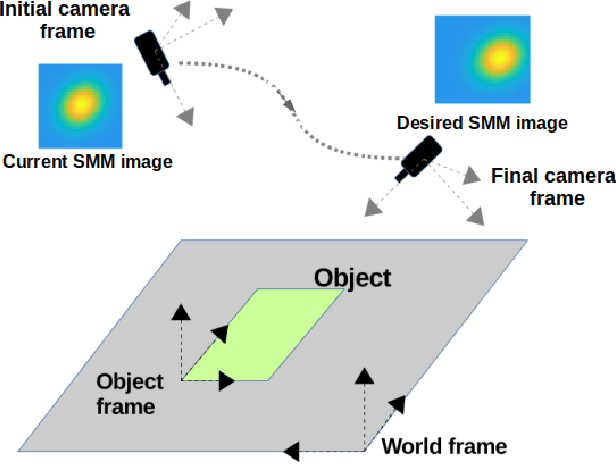
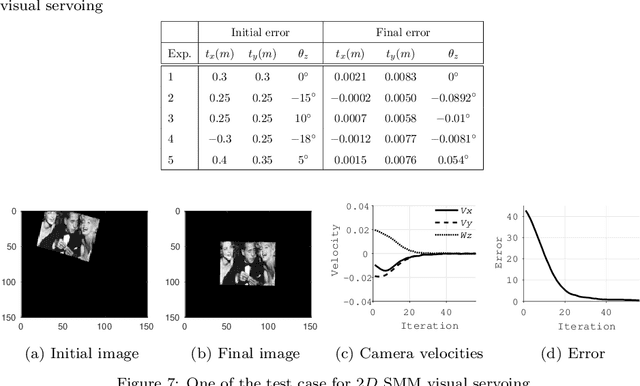
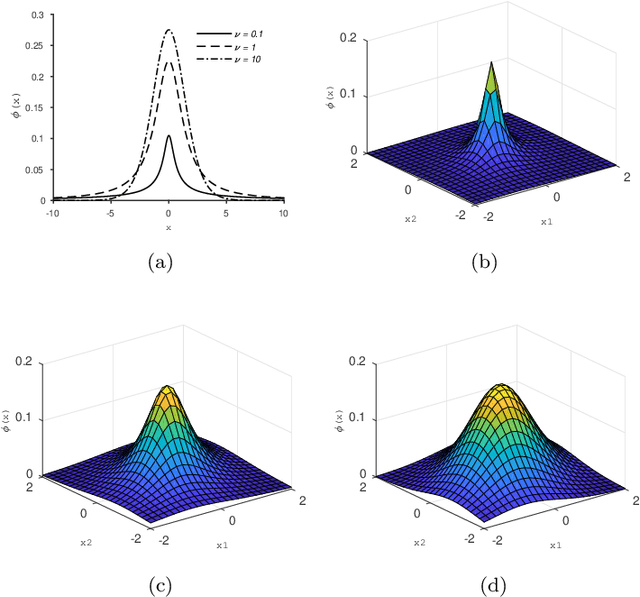
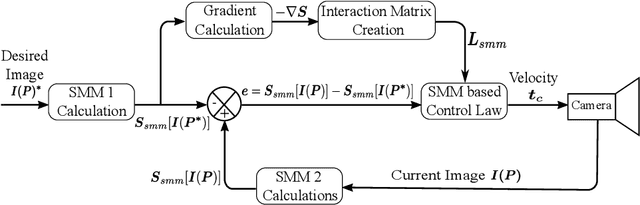
Classical Image-Based Visual Servoing (IBVS) makes use of geometric image features like point, straight line and image moments to control a robotic system. Robust extraction and real-time tracking of these features are crucial to the performance of the IBVS. Moreover, such features can be unsuitable for real world applications where it might not be easy to distinguish a target from the rest of the environment. Alternatively, an approach based on complete photometric data can avoid the requirement of feature extraction, tracking and object detection. In this work, we propose one such probabilistic model based approach which uses entire photometric data for the purpose of visual servoing. A novel image modelling method has been proposed using Student Mixture Model (SMM), which is based on Multivariate Student's t-Distribution. Consequently, a vision-based control law is formulated as a least squares minimisation problem. Efficacy of the proposed framework is demonstrated for 2D and 3D positioning tasks showing favourable error convergence and acceptable camera trajectories. Numerical experiments are also carried out to show robustness to distinct image scenes and partial occlusion.
Anonymization of labeled TOF-MRA images for brain vessel segmentation using generative adversarial networks
Sep 16, 2020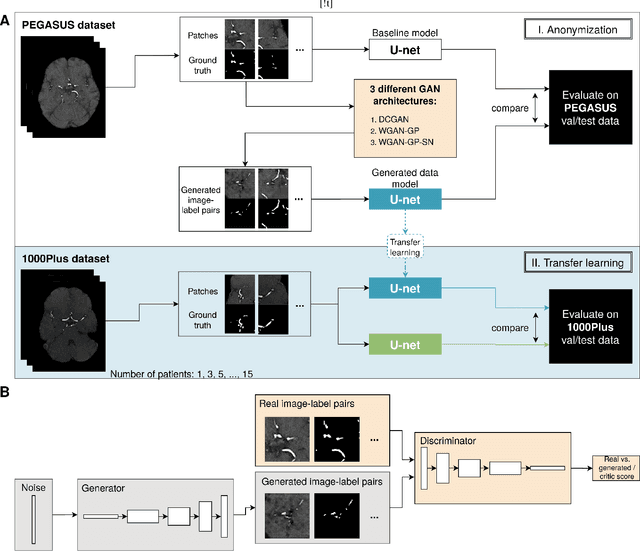
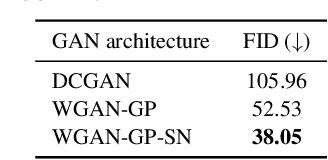

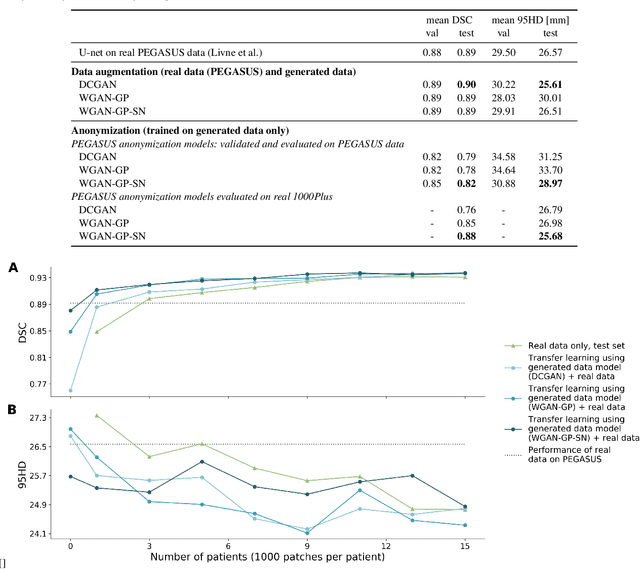
Anonymization and data sharing are crucial for privacy protection and acquisition of large datasets for medical image analysis. This is a big challenge, especially for neuroimaging. Here, the brain's unique structure allows for re-identification and thus requires non-conventional anonymization. Generative adversarial networks (GANs) have the potential to provide anonymous images while preserving predictive properties. Analyzing brain vessel segmentation as a use case, we trained 3 GANs on time-of-flight (TOF) magnetic resonance angiography (MRA) patches for image-label generation: 1) Deep convolutional GAN, 2) Wasserstein-GAN with gradient penalty (WGAN-GP) and 3) WGAN-GP with spectral normalization (WGAN-GP-SN). The generated image-labels from each GAN were used to train a U-net for segmentation and tested on real data. Moreover, we applied our synthetic patches using transfer learning on a second dataset. For an increasing number of up to 15 patients we evaluated the model performance on real data with and without pre-training. The performance for all models was assessed by the Dice Similarity Coefficient (DSC) and the 95th percentile of the Hausdorff Distance (95HD). Comparing the 3 GANs, the U-net trained on synthetic data generated by the WGAN-GP-SN showed the highest performance to predict vessels (DSC/95HD 0.82/28.97) benchmarked by the U-net trained on real data (0.89/26.61). The transfer learning approach showed superior performance for the same GAN compared to no pre-training, especially for one patient only (0.91/25.68 vs. 0.85/27.36). In this work, synthetic image-label pairs retained generalizable information and showed good performance for vessel segmentation. Besides, we showed that synthetic patches can be used in a transfer learning approach with independent data. This paves the way to overcome the challenges of scarce data and anonymization in medical imaging.
Light Field Reconstruction Using Convolutional Network on EPI and Extended Applications
Mar 24, 2021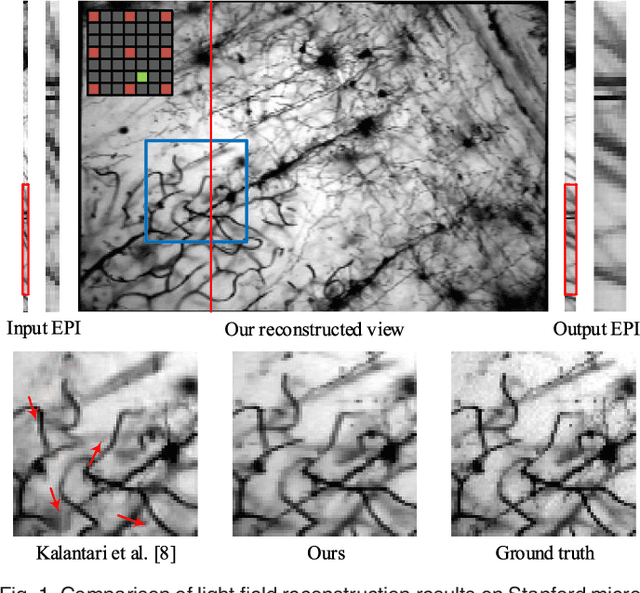
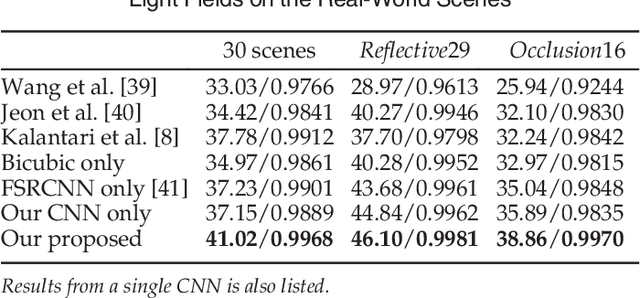


In this paper, a novel convolutional neural network (CNN)-based framework is developed for light field reconstruction from a sparse set of views. We indicate that the reconstruction can be efficiently modeled as angular restoration on an epipolar plane image (EPI). The main problem in direct reconstruction on the EPI involves an information asymmetry between the spatial and angular dimensions, where the detailed portion in the angular dimensions is damaged by undersampling. Directly upsampling or super-resolving the light field in the angular dimensions causes ghosting effects. To suppress these ghosting effects, we contribute a novel "blur-restoration-deblur" framework. First, the "blur" step is applied to extract the low-frequency components of the light field in the spatial dimensions by convolving each EPI slice with a selected blur kernel. Then, the "restoration" step is implemented by a CNN, which is trained to restore the angular details of the EPI. Finally, we use a non-blind "deblur" operation to recover the spatial high frequencies suppressed by the EPI blur. We evaluate our approach on several datasets, including synthetic scenes, real-world scenes and challenging microscope light field data. We demonstrate the high performance and robustness of the proposed framework compared with state-of-the-art algorithms. We further show extended applications, including depth enhancement and interpolation for unstructured input. More importantly, a novel rendering approach is presented by combining the proposed framework and depth information to handle large disparities.
* Published in IEEE TPAMI, 2019
LambdaNetworks: Modeling Long-Range Interactions Without Attention
Feb 17, 2021
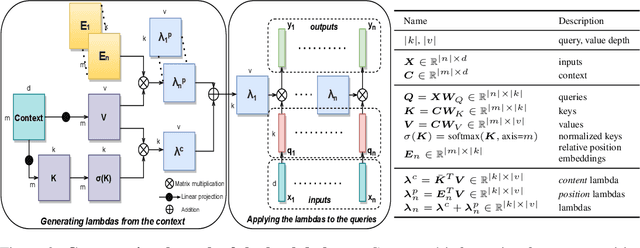


We present lambda layers -- an alternative framework to self-attention -- for capturing long-range interactions between an input and structured contextual information (e.g. a pixel surrounded by other pixels). Lambda layers capture such interactions by transforming available contexts into linear functions, termed lambdas, and applying these linear functions to each input separately. Similar to linear attention, lambda layers bypass expensive attention maps, but in contrast, they model both content and position-based interactions which enables their application to large structured inputs such as images. The resulting neural network architectures, LambdaNetworks, significantly outperform their convolutional and attentional counterparts on ImageNet classification, COCO object detection and COCO instance segmentation, while being more computationally efficient. Additionally, we design LambdaResNets, a family of hybrid architectures across different scales, that considerably improves the speed-accuracy tradeoff of image classification models. LambdaResNets reach excellent accuracies on ImageNet while being 3.2 - 4.4x faster than the popular EfficientNets on modern machine learning accelerators. When training with an additional 130M pseudo-labeled images, LambdaResNets achieve up to a 9.5x speed-up over the corresponding EfficientNet checkpoints.
Bicameral Structuring and Synthetic Imagery for Jointly Predicting Instance Boundaries and Nearby Occlusions from a Single Image
Jun 18, 2019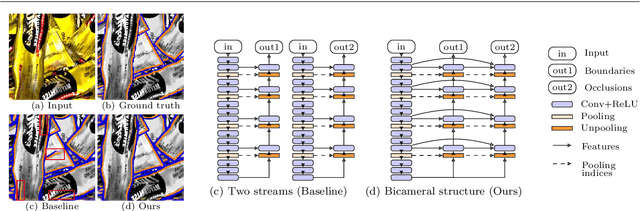



Oriented boundary detection is a challenging task aimed at both delineating category-agnostic object instances and inferring their spatial layout from a single RGB image. State-of-the-art deep convolutional networks for this task rely on two independent streams that predict boundaries and occlusions respectively, although both require similar local and global cues, and occlusions cause boundaries. We therefore propose a fully convolutional bicameral structuring, composed of two cascaded decoders sharing one deep encoder, linked altogether by skip connections to combine local and global features, for jointly predicting instance boundaries and their unoccluded side. Furthermore, state-of-the-art datasets contain real images with few instances and occlusions mostly due to objects occluding the background, thereby missing meaningful occlusions between instances. For evaluating the missing scenario of dense piles of objects as well, we introduce synthetic data (Mikado), which extensibly contains more instances and inter-instance occlusions per image than the PASCAL Instance Occlusion Dataset (PIOD), the COCO Amodal dataset (COCOA), and the Densely Segmented Supermarket Amodal dataset (D2SA). We show that the proposed network design outperforms the two-stream baseline and alternative archiectures for oriented boundary detection on both PIOD and Mikado, and the amodal segmentation approach on COCOA as well. Our experiments on D2SA also show that Mikado is plausible in the sense that it enables the learning of performance-enhancing representations transferable to real data, while drastically reducing the need of hand-made annotations for finetuning.
Real-time Localized Photorealistic Video Style Transfer
Oct 20, 2020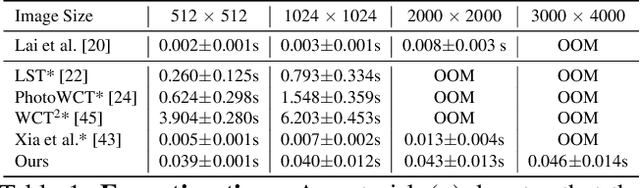
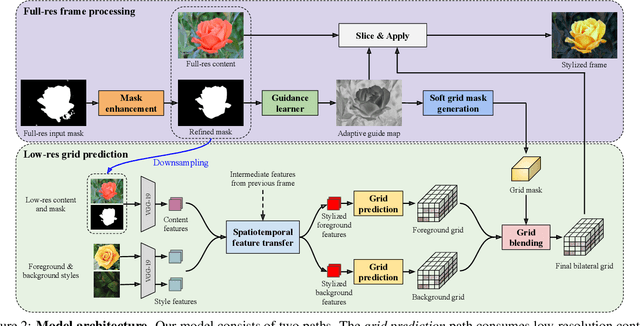

We present a novel algorithm for transferring artistic styles of semantically meaningful local regions of an image onto local regions of a target video while preserving its photorealism. Local regions may be selected either fully automatically from an image, through using video segmentation algorithms, or from casual user guidance such as scribbles. Our method, based on a deep neural network architecture inspired by recent work in photorealistic style transfer, is real-time and works on arbitrary inputs without runtime optimization once trained on a diverse dataset of artistic styles. By augmenting our video dataset with noisy semantic labels and jointly optimizing over style, content, mask, and temporal losses, our method can cope with a variety of imperfections in the input and produce temporally coherent videos without visual artifacts. We demonstrate our method on a variety of style images and target videos, including the ability to transfer different styles onto multiple objects simultaneously, and smoothly transition between styles in time.
Practical Issues of Action-conditioned Next Image Prediction
Feb 08, 2018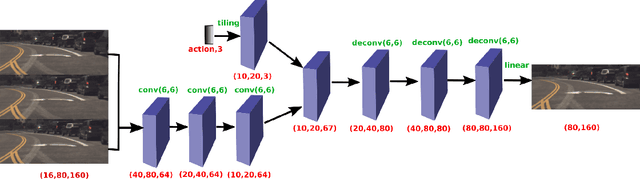
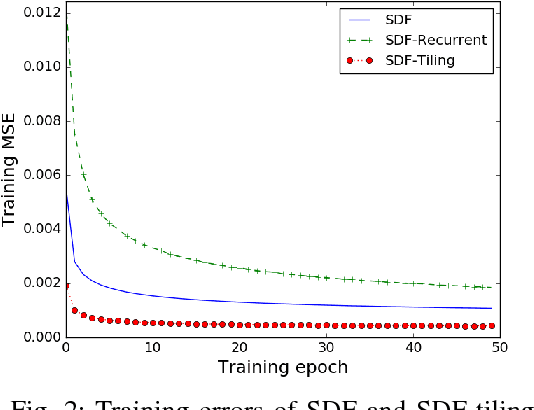


The problem of action-conditioned image prediction is to predict the expected next frame given the current camera frame the robot observes and an action selected by the robot. We provide the first comparison of two recent popular models, especially for image prediction on cars. Our major finding is that action tiling encoding is the most important factor leading to the remarkable performance of the CDNA model. We present a light-weight model by action tiling encoding which has a single-decoder feedforward architecture same as [action_video_prediction_honglak]. On a real driving dataset, the CDNA model achieves ${0.3986} \times 10^{-3}$ MSE and ${0.9846}$ Structure SIMilarity (SSIM) with a network size of about {\bfseries ${12.6}$ million} parameters. With a small network of fewer than {\bfseries ${1}$ million} parameters, our new model achieves a comparable performance to CDNA at ${0.3613} \times 10^{-3}$ MSE and ${0.9633}$ SSIM. Our model requires less memory, is more computationally efficient and is advantageous to be used inside self-driving vehicles.