 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CT-GAN: Conditional Transformation Generative Adversarial Network for Image Attribute Modification
Aug 31, 2018
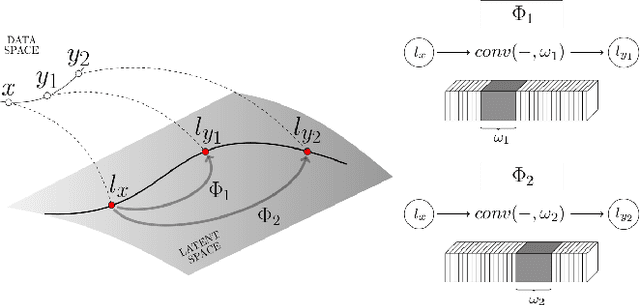

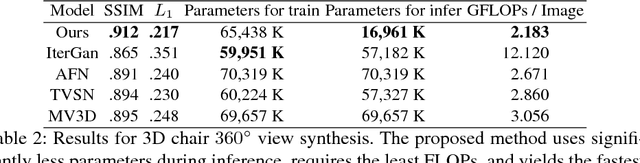
We propose a novel, fully-convolutional conditional generative model capable of learning image transformations using a light-weight network suited for real-time applications. We introduce the conditional transformation unit (CTU) designed to produce specified attribute modifications and an adaptive discriminator used to stabilize the learning procedure. We show that the network is capable of accurately modeling several discrete modifications simultaneously and can produce seamless continuous attribute modification via piece-wise interpolation. We also propose a task-divided decoder that incorporates a refinement map, designed to improve the network's coarse pixel estimation, along with RGB color balance parameters. We exceed state-of-the-art results on synthetic face and chair datasets and demonstrate the model's robustness using real hand pose datasets. Moreover, the proposed fully-convolutional model requires significantly fewer weights than conventional alternatives and is shown to provide an effective framework for producing a diverse range of real-time image attribute modifications.
A Multisite, Report-Based, Centralized Infrastructure for Feedback and Monitoring of Radiology AI/ML Development and Clinical Deployment
Aug 31, 2020
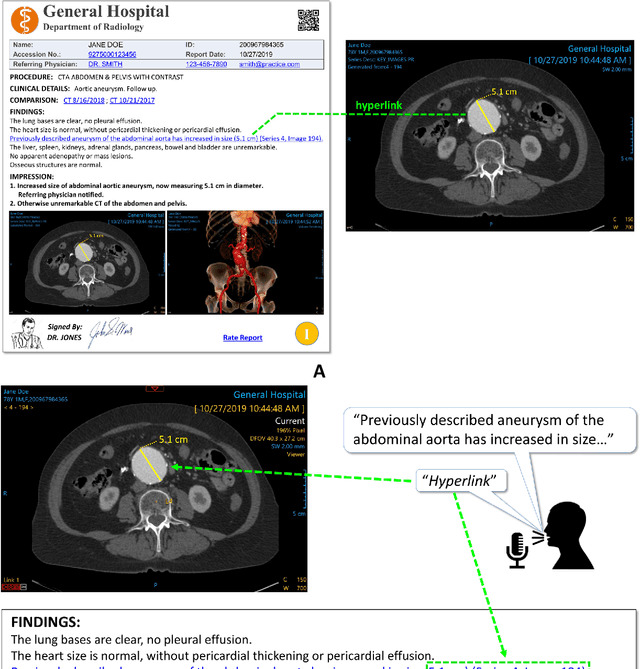
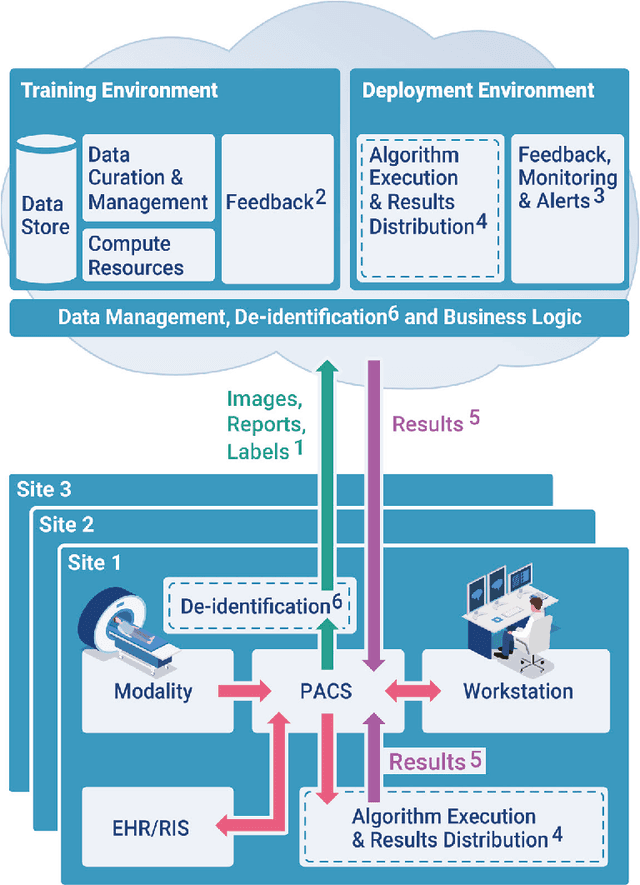
An infrastructure for multisite, geographically-distributed creation and collection of diverse, high-quality, curated and labeled radiology image data is crucial for the successful automated development, deployment, monitoring and continuous improvement of Artificial Intelligence (AI)/Machine Learning (ML) solutions in the real world. An interactive radiology reporting approach that integrates image viewing, dictation, natural language processing (NLP) and creation of hyperlinks between image findings and the report, provides localized labels during routine interpretation. These images and labels can be captured and centralized in a cloud-based system. This method provides a practical and efficient mechanism with which to monitor algorithm performance. It also supplies feedback for iterative development and quality improvement of new and existing algorithmic models. Both feedback and monitoring are achieved without burdening the radiologist. The method addresses proposed regulatory requirements for post-marketing surveillance and external data. Comprehensive multi-site data collection assists in reducing bias. Resource requirements are greatly reduced compared to dedicated retrospective expert labeling.
Aggregative Self-Supervised Feature Learning
Dec 14, 2020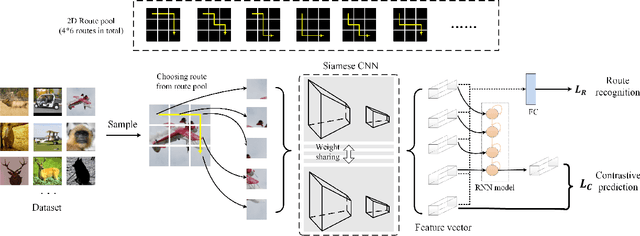
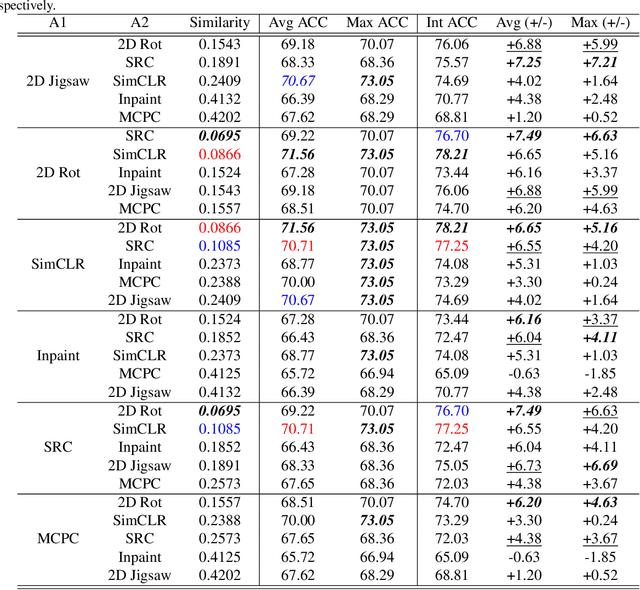
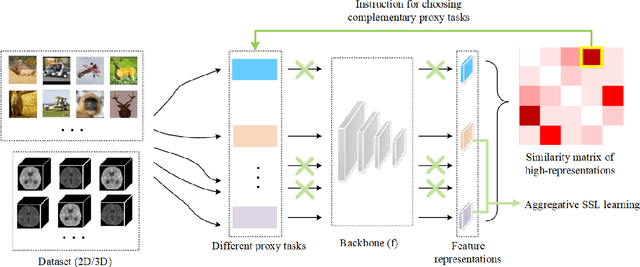
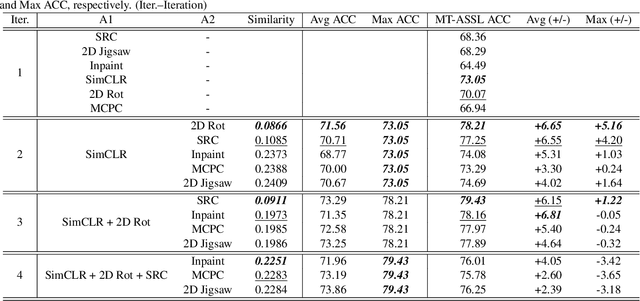
Self-supervised learning (SSL) is an efficient approach that addresses the issue of annotation shortage. The key part in SSL is its proxy task that defines the supervisory signals and drives the learning toward effective feature representations. However, most SSL approaches usually focus on a single proxy task, which greatly limits the expressive power of the learned features and therefore deteriorates the network generalization capacity. In this regard, we hereby propose three strategies of aggregation in terms of complementarity of various forms to boost the robustness of self-supervised learned features. In spatial context aggregative SSL, we contribute a heuristic SSL method that integrates two ad-hoc proxy tasks with spatial context complementarity, modeling global and local contextual features, respectively. We then propose a principled framework of multi-task aggregative self-supervised learning to form a unified representation, with an intent of exploiting feature complementarity among different tasks. Finally, in self-aggregative SSL, we propose to self-complement an existing proxy task with an auxiliary loss function based on a linear centered kernel alignment metric, which explicitly promotes the exploring of where are uncovered by the features learned from a proxy task at hand to further boost the modeling capability. Our extensive experiments on 2D natural image and 3D medical image classification tasks under limited annotation scenarios confirm that the proposed aggregation strategies successfully boost the classification accuracy.
Source-Relaxed Domain Adaptation for Image Segmentation
May 07, 2020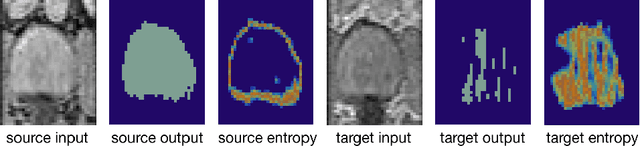

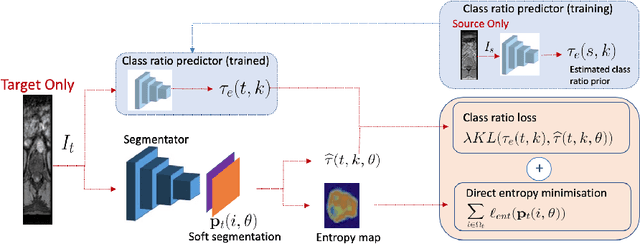
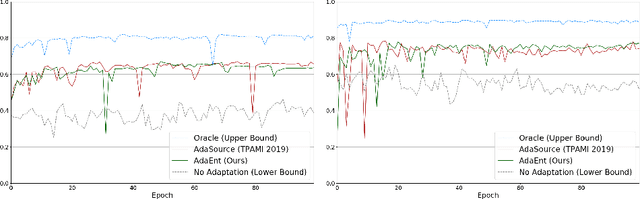
Domain adaptation (DA) has drawn high interests for its capacity to adapt a model trained on labeled source data to perform well on unlabeled or weakly labeled target data from a different domain. Most common DA techniques require the concurrent access to the input images of both the source and target domains. However, in practice, it is common that the source images are not available in the adaptation phase. This is a very frequent DA scenario in medical imaging, for instance, when the source and target images come from different clinical sites. We propose a novel formulation for adapting segmentation networks, which relaxes such a constraint. Our formulation is based on minimizing a label-free entropy loss defined over target-domain data, which we further guide with a domain invariant prior on the segmentation regions. Many priors can be used, derived from anatomical information. Here, a class-ratio prior is learned via an auxiliary network and integrated in the form of a Kullback-Leibler (KL) divergence in our overall loss function. We show the effectiveness of our prior-aware entropy minimization in adapting spine segmentation across different MRI modalities. Our method yields comparable results to several state-of-the-art adaptation techniques, even though is has access to less information, the source images being absent in the adaptation phase. Our straight-forward adaptation strategy only uses one network, contrary to popular adversarial techniques, which cannot perform without the presence of the source images. Our framework can be readily used with various priors and segmentation problems.
Measuring Visual Generalization in Continuous Control from Pixels
Oct 13, 2020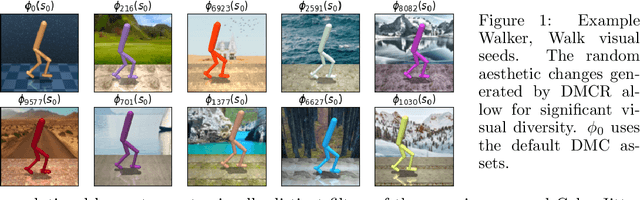
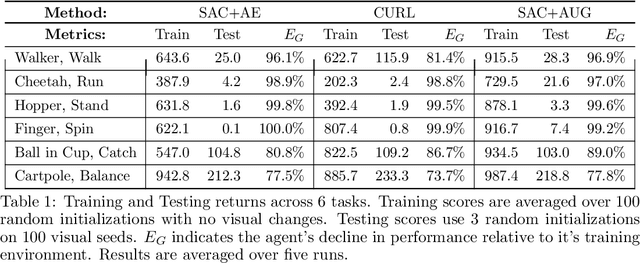
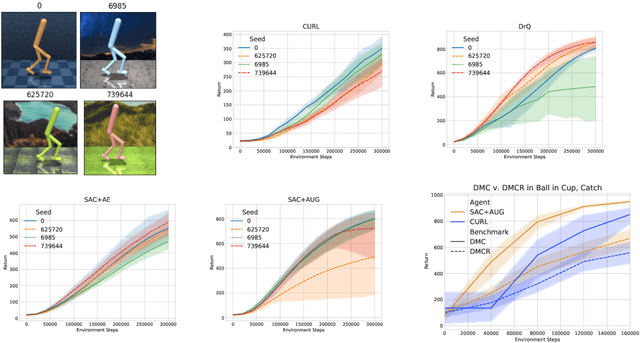
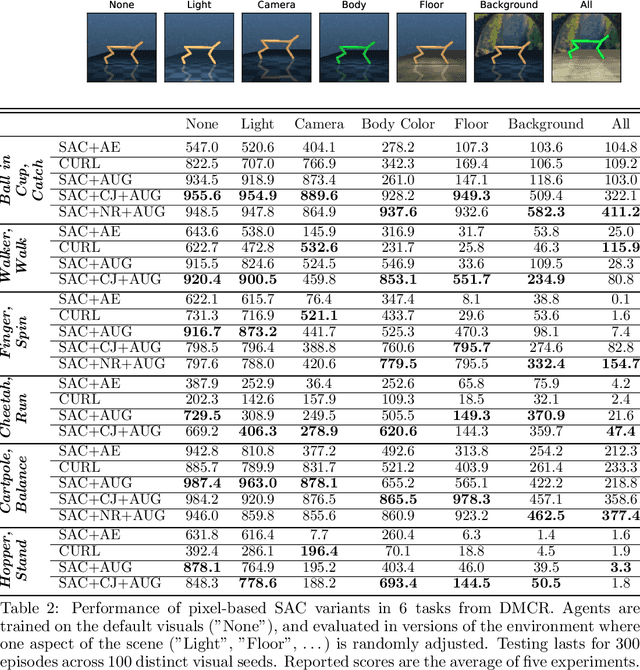
Self-supervised learning and data augmentation have significantly reduced the performance gap between state and image-based reinforcement learning agents in continuous control tasks. However, it is still unclear whether current techniques can face a variety of visual conditions required by real-world environments. We propose a challenging benchmark that tests agents' visual generalization by adding graphical variety to existing continuous control domains. Our empirical analysis shows that current methods struggle to generalize across a diverse set of visual changes, and we examine the specific factors of variation that make these tasks difficult. We find that data augmentation techniques outperform self-supervised learning approaches and that more significant image transformations provide better visual generalization \footnote{The benchmark and our augmented actor-critic implementation are open-sourced @ https://github.com/jakegrigsby/dmc_remastered)
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021
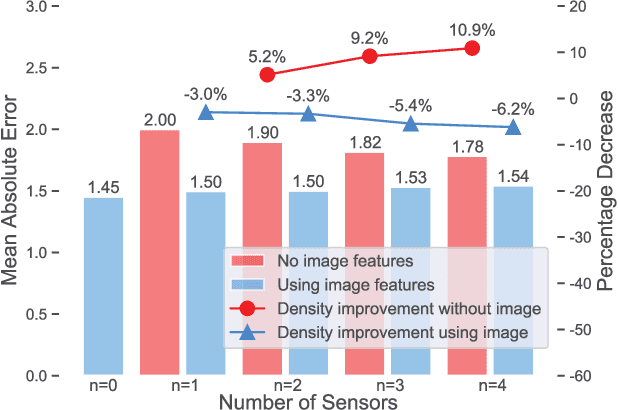
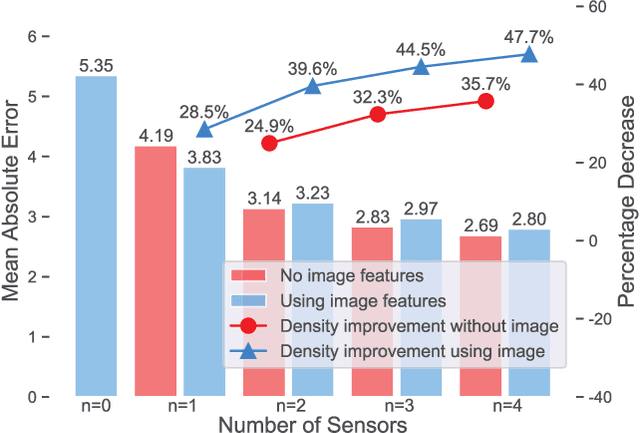
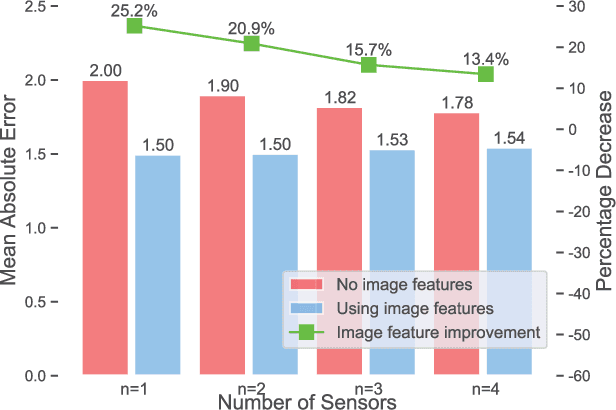
Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020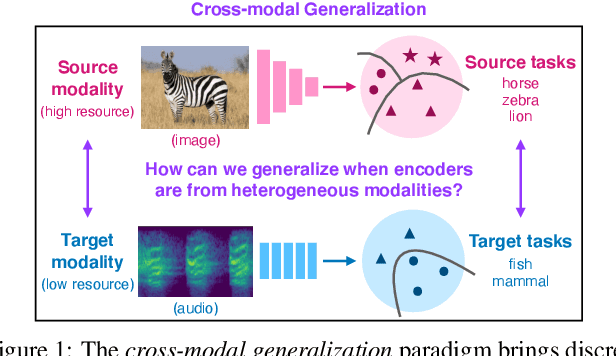
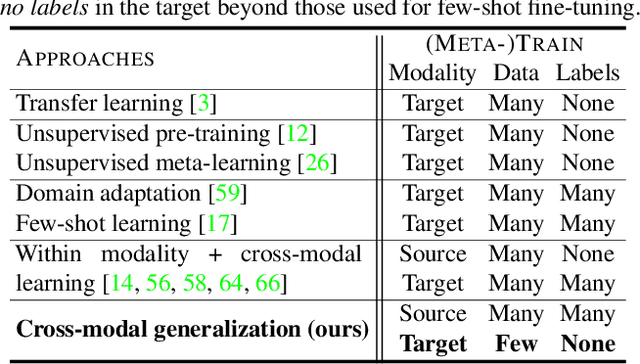
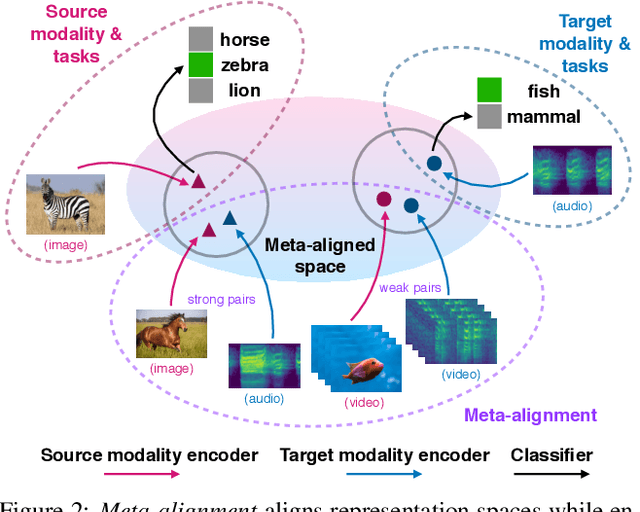
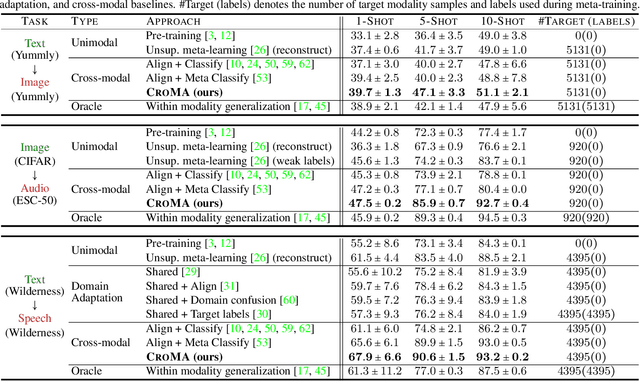
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
Variational Image Segmentation Model Coupled with Image Restoration Achievements
May 09, 2014


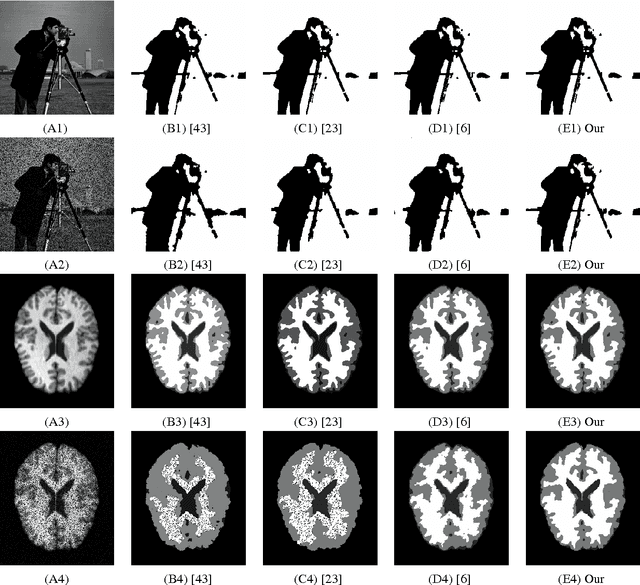
Image segmentation and image restoration are two important topics in image processing with great achievements. In this paper, we propose a new multiphase segmentation model by combining image restoration and image segmentation models. Utilizing image restoration aspects, the proposed segmentation model can effectively and robustly tackle high noisy images, blurry images, images with missing pixels, and vector-valued images. In particular, one of the most important segmentation models, the piecewise constant Mumford-Shah model, can be extended easily in this way to segment gray and vector-valued images corrupted for example by noise, blur or missing pixels after coupling a new data fidelity term which comes from image restoration topics. It can be solved efficiently using the alternating minimization algorithm, and we prove the convergence of this algorithm with three variables under mild condition. Experiments on many synthetic and real-world images demonstrate that our method gives better segmentation results in comparison to others state-of-the-art segmentation models especially for blurry images and images with missing pixels values.
The Unreasonable Effectiveness of Texture Transfer for Single Image Super-resolution
Jul 31, 2018
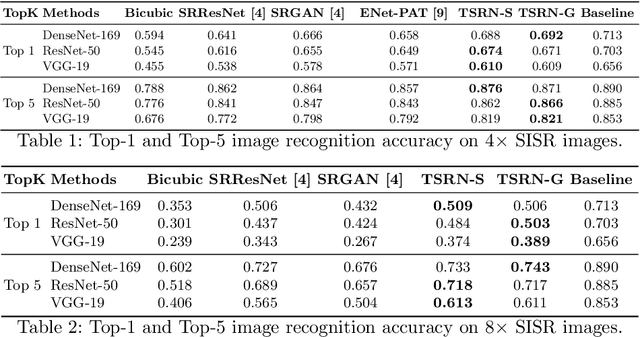

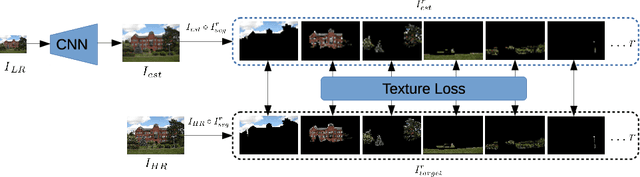
While implicit generative models such as GANs have shown impressive results in high quality image reconstruction and manipulation using a combination of various losses, we consider a simpler approach leading to surprisingly strong results. We show that texture loss alone allows the generation of perceptually high quality images. We provide a better understanding of texture constraining mechanism and develop a novel semantically guided texture constraining method for further improvement. Using a recently developed perceptual metric employing "deep features" and termed LPIPS, the method obtains state-of-the-art results. Moreover, we show that a texture representation of those deep features better capture the perceptual quality of an image than the original deep features. Using texture information, off-the-shelf deep classification networks (without training) perform as well as the best performing (tuned and calibrated) LPIPS metrics. The code is publicly available.
Structure-preserving Guided Retinal Image Filtering and Its Application for Optic Disc Analysis
May 22, 2018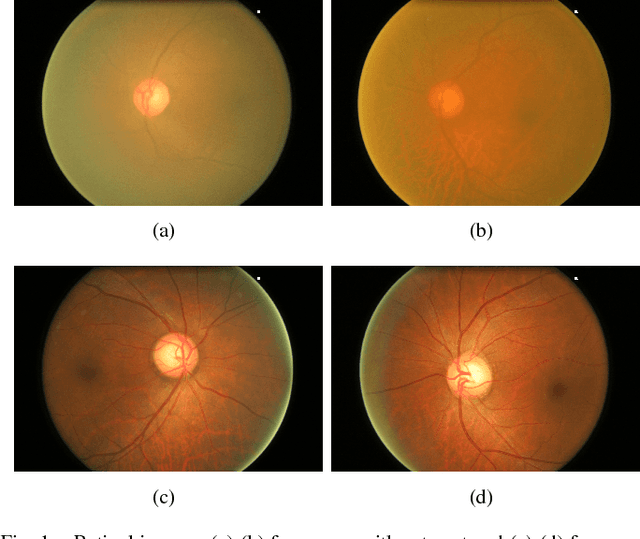
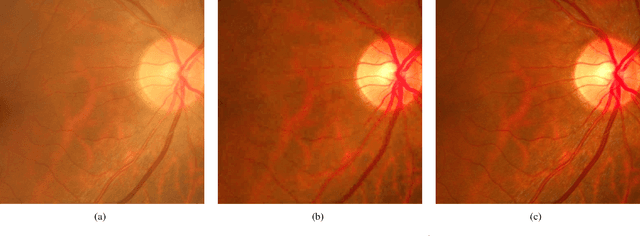

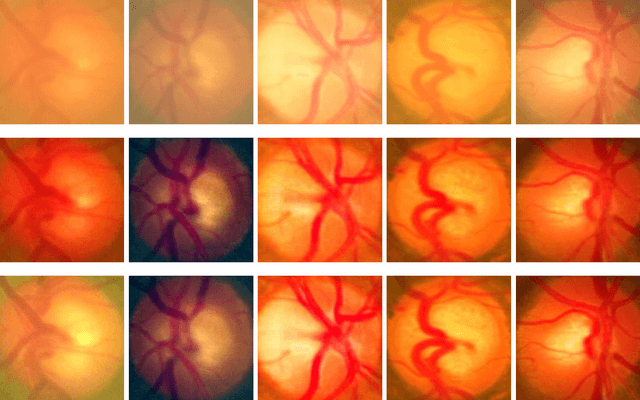
Retinal fundus photographs have been used in the diagnosis of many ocular diseases such as glaucoma, pathological myopia, age-related macular degeneration and diabetic retinopathy. With the development of computer science, computer aided diagnosis has been developed to process and analyse the retinal images automatically. One of the challenges in the analysis is that the quality of the retinal image is often degraded. For example, a cataract in human lens will attenuate the retinal image, just as a cloudy camera lens which reduces the quality of a photograph. It often obscures the details in the retinal images and posts challenges in retinal image processing and analysing tasks. In this paper, we approximate the degradation of the retinal images as a combination of human-lens attenuation and scattering. A novel structure-preserving guided retinal image filtering (SGRIF) is then proposed to restore images based on the attenuation and scattering model. The proposed SGRIF consists of a step of global structure transferring and a step of global edge-preserving smoothing. Our results show that the proposed SGRIF method is able to improve the contrast of retinal images, measured by histogram flatness measure, histogram spread and variability of local luminosity. In addition, we further explored the benefits of SGRIF for subsequent retinal image processing and analysing tasks. In the two applications of deep learning based optic cup segmentation and sparse learning based cup-to-disc ratio (CDR) computation, our results show that we are able to achieve more accurate optic cup segmentation and CDR measurements from images processed by SGRIF.
* Accepted for publication on IEEE Trans. on Medical Imaging