 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Smooth-AP: Smoothing the Path Towards Large-Scale Image Retrieval
Jul 23, 2020
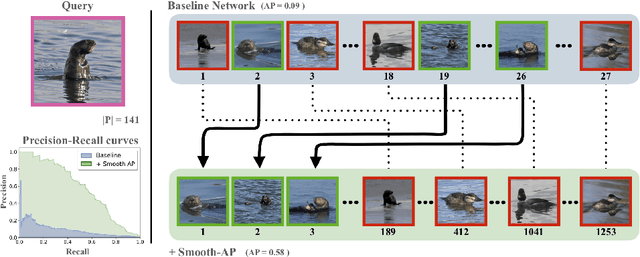
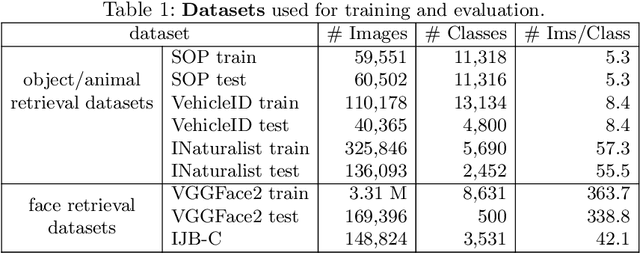

Optimising a ranking-based metric, such as Average Precision (AP), is notoriously challenging due to the fact that it is non-differentiable, and hence cannot be optimised directly using gradient-descent methods. To this end, we introduce an objective that optimises instead a smoothed approximation of AP, coined Smooth-AP. Smooth-AP is a plug-and-play objective function that allows for end-to-end training of deep networks with a simple and elegant implementation. We also present an analysis for why directly optimising the ranking based metric of AP offers benefits over other deep metric learning losses. We apply Smooth-AP to standard retrieval benchmarks: Stanford Online products and VehicleID, and also evaluate on larger-scale datasets: INaturalist for fine-grained category retrieval, and VGGFace2 and IJB-C for face retrieval. In all cases, we improve the performance over the state-of-the-art, especially for larger-scale datasets, thus demonstrating the effectiveness and scalability of Smooth-AP to real-world scenarios.
HarDNet-MSEG: A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS
Jan 20, 2021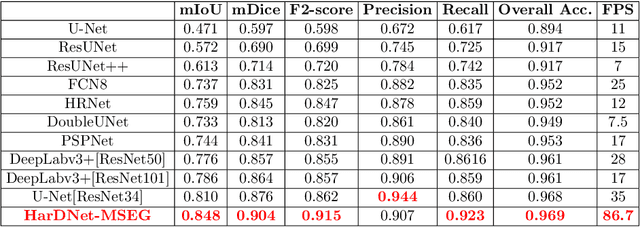
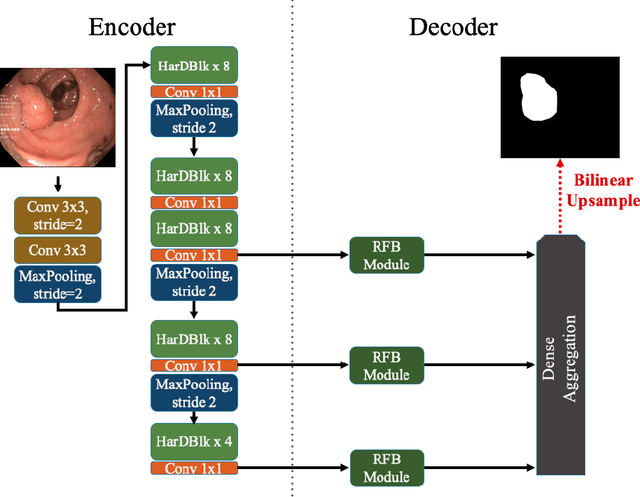
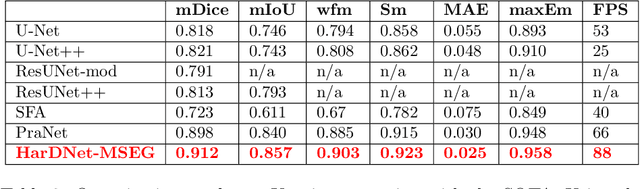
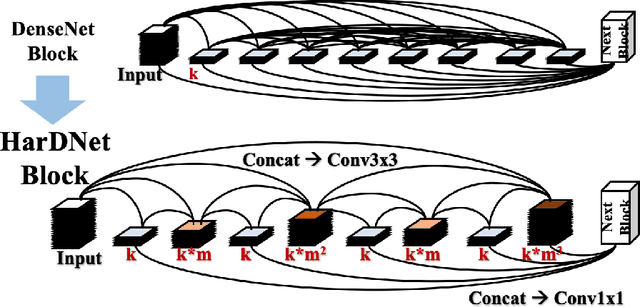
We propose a new convolution neural network called HarDNet-MSEG for polyp segmentation. It achieves SOTA in both accuracy and inference speed on five popular datasets. For Kvasir-SEG, HarDNet-MSEG delivers 0.904 mean Dice running at 86.7 FPS on a GeForce RTX 2080 Ti GPU. It consists of a backbone and a decoder. The backbone is a low memory traffic CNN called HarDNet68, which has been successfully applied to various CV tasks including image classification, object detection, multi-object tracking and semantic segmentation, etc. The decoder part is inspired by the Cascaded Partial Decoder, known for fast and accurate salient object detection. We have evaluated HarDNet-MSEG using those five popular datasets. The code and all experiment details are available at Github. https://github.com/james128333/HarDNet-MSEG
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Aug 25, 2020
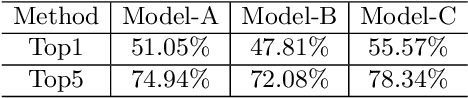
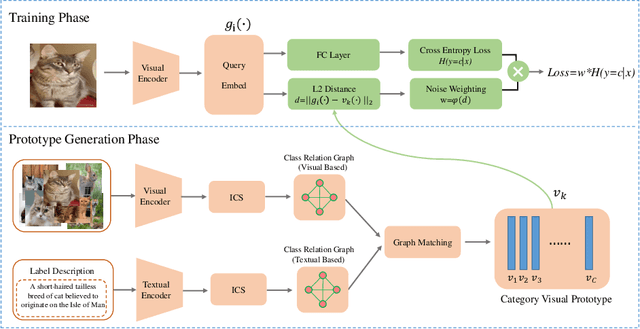

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.
Pixel-wise Distance Regression for Glacier Calving Front Detection and Segmentation
Mar 09, 2021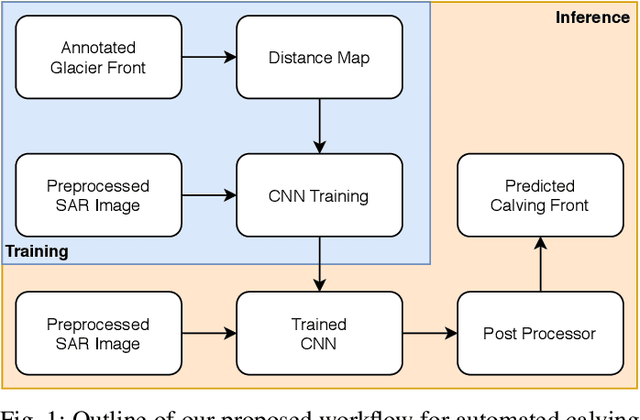


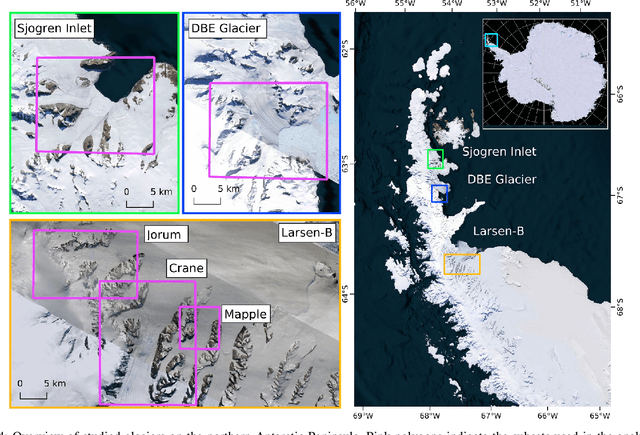
Glacier calving front position (CFP) is an important glaciological variable. Traditionally, delineating the CFPs has been carried out manually, which was subjective, tedious and expensive. Automating this process is crucial for continuously monitoring the evolution and status of glaciers. Recently, deep learning approaches have been investigated for this application. However, the current methods get challenged by a severe class-imbalance problem. In this work, we propose to mitigate the class-imbalance between the calving front class and the non-calving front class by reformulating the segmentation problem into a pixel-wise regression task. A Convolutional Neural Network gets optimized to predict the distance values to the glacier front for each pixel in the image. The resulting distance map localizes the CFP and is further post-processed to extract the calving front line. We propose three post-processing methods, one method based on statistical thresholding, a second method based on conditional random fields (CRF), and finally the use of a second U-Net. The experimental results confirm that our approach significantly outperforms the state-of-the-art methods and produces accurate delineation. The Second U-Net obtains the best performance results, resulting in an average improvement of about 21% dice coefficient enhancement.
Improving the Classification of Rare Chords with Unlabeled Data
Dec 13, 2020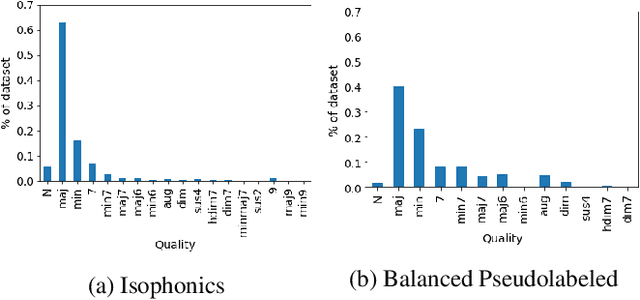

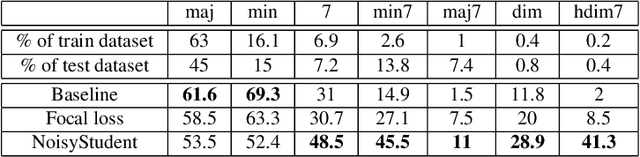
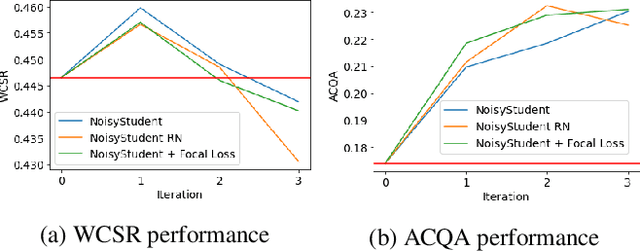
In this work, we explore techniques to improve performance for rare classes in the task of Automatic Chord Recognition (ACR). We first explored the use of the focal loss in the context of ACR, which was originally proposed to improve the classification of hard samples. In parallel, we adapted a self-learning technique originally designed for image recognition to the musical domain. Our experiments show that both approaches individually (and their combination) improve the recognition of rare chords, but using only self-learning with noise addition yields the best results.
Transductive Zero-Shot Learning using Cross-Modal CycleGAN
Nov 13, 2020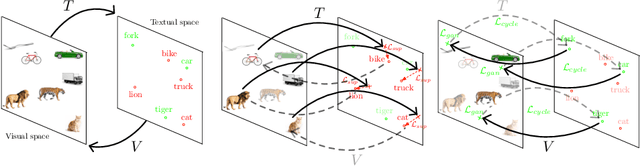
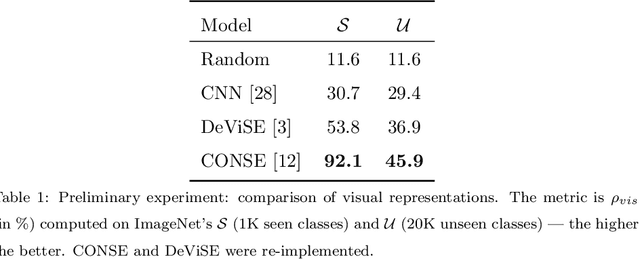
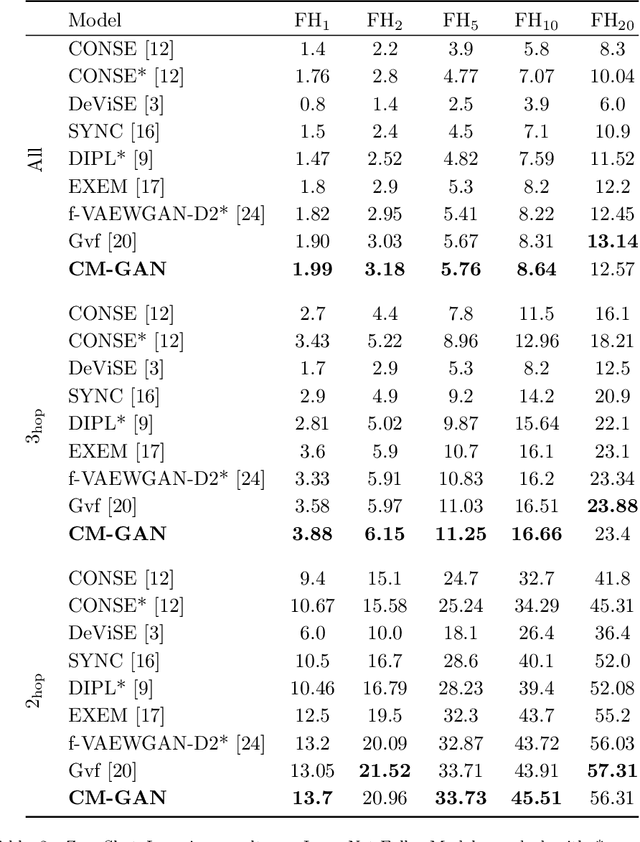
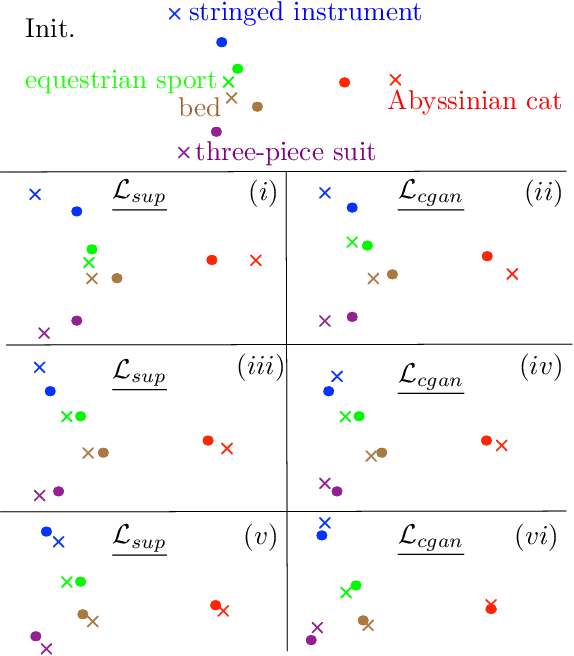
In Computer Vision, Zero-Shot Learning (ZSL) aims at classifying unseen classes -- classes for which no matching training image exists. Most of ZSL works learn a cross-modal mapping between images and class labels for seen classes. However, the data distribution of seen and unseen classes might differ, causing a domain shift problem. Following this observation, transductive ZSL (T-ZSL) assumes that unseen classes and their associated images are known during training, but not their correspondence. As current T-ZSL approaches do not scale efficiently when the number of seen classes is high, we tackle this problem with a new model for T-ZSL based upon CycleGAN. Our model jointly (i) projects images on their seen class labels with a supervised objective and (ii) aligns unseen class labels and visual exemplars with adversarial and cycle-consistency objectives. We show the efficiency of our Cross-Modal CycleGAN model (CM-GAN) on the ImageNet T-ZSL task where we obtain state-of-the-art results. We further validate CM-GAN on a language grounding task, and on a new task that we propose: zero-shot sentence-to-image matching on MS COCO.
One Model to Reconstruct Them All: A Novel Way to Use the Stochastic Noise in StyleGAN
Oct 21, 2020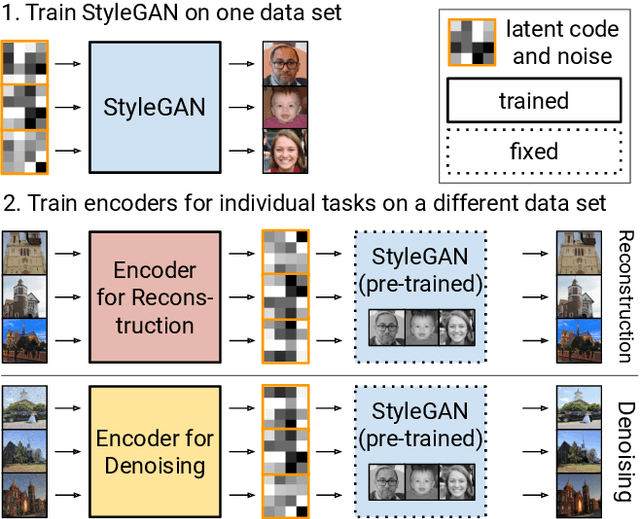
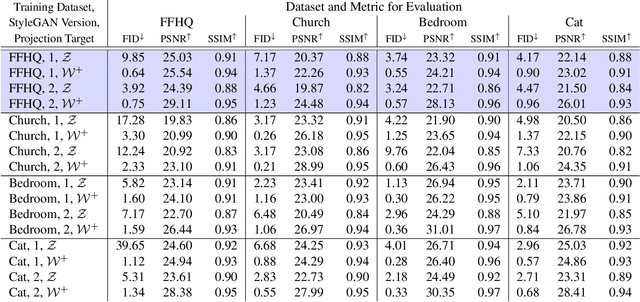
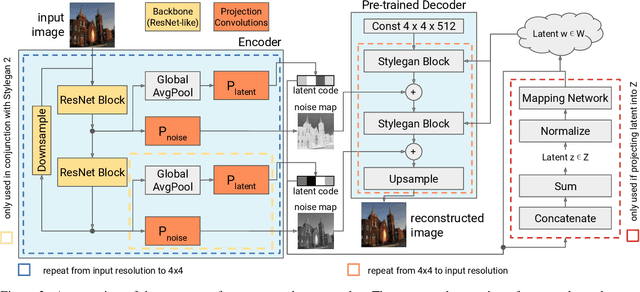
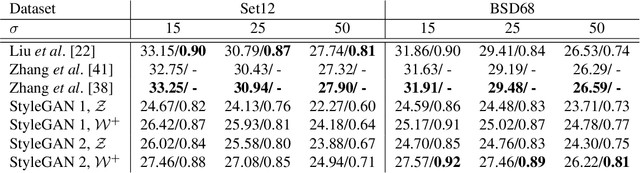
Generative Adversarial Networks (GANs) have achieved state-of-the-art performance for several image generation and manipulation tasks. Different works have improved the limited understanding of the latent space of GANs by embedding images into specific GAN architectures to reconstruct the original images. We present a novel StyleGAN-based autoencoder architecture, which can reconstruct images with very high quality across several data domains. We demonstrate a previously unknown grade of generalizablility by training the encoder and decoder independently and on different datasets. Furthermore, we provide new insights about the significance and capabilities of noise inputs of the well-known StyleGAN architecture. Our proposed architecture can handle up to 40 images per second on a single GPU, which is approximately 28x faster than previous approaches. Finally, our model also shows promising results, when compared to the state-of-the-art on the image denoising task, although it was not explicitly designed for this task.
SimTriplet: Simple Triplet Representation Learning with a Single GPU
Mar 09, 2021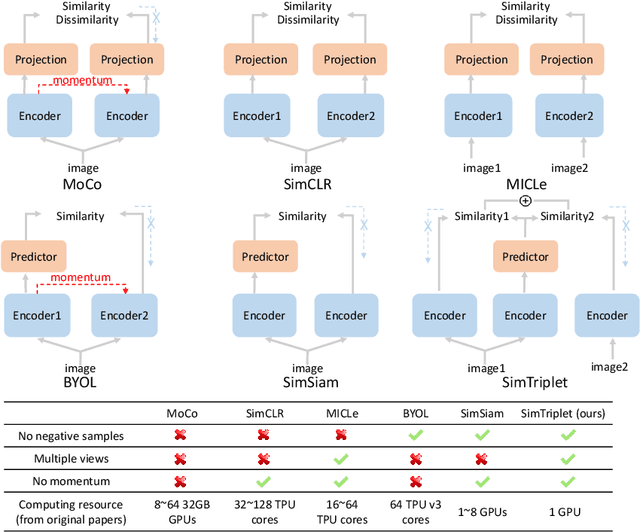
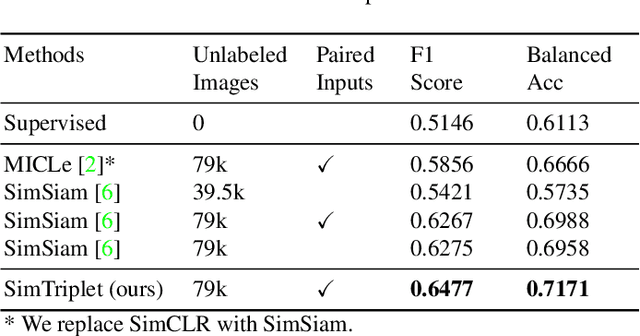
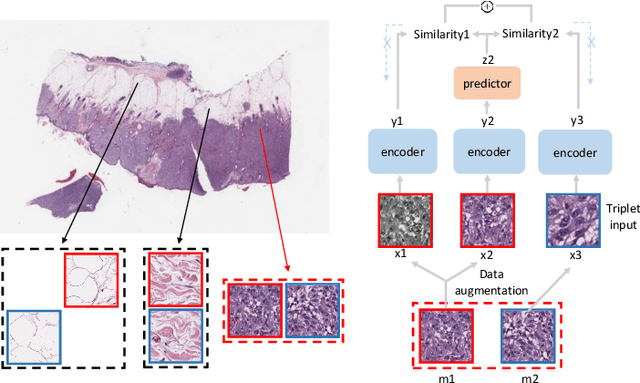
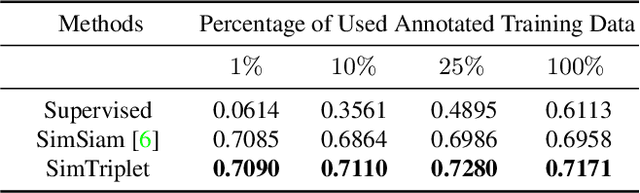
Contrastive learning is a key technique of modern self-supervised learning. The broader accessibility of earlier approaches is hindered by the need of heavy computational resources (e.g., at least 8 GPUs or 32 TPU cores), which accommodate for large-scale negative samples or momentum. The more recent SimSiam approach addresses such key limitations via stop-gradient without momentum encoders. In medical image analysis, multiple instances can be achieved from the same patient or tissue. Inspired by these advances, we propose a simple triplet representation learning (SimTriplet) approach on pathological images. The contribution of the paper is three-fold: (1) The proposed SimTriplet method takes advantage of the multi-view nature of medical images beyond self-augmentation; (2) The method maximizes both intra-sample and inter-sample similarities via triplets from positive pairs, without using negative samples; and (3) The recent mix precision training is employed to advance the training by only using a single GPU with 16GB memory. By learning from 79,000 unlabeled pathological patch images, SimTriplet achieved 10.58% better performance compared with supervised learning. It also achieved 2.13% better performance compared with SimSiam. Our proposed SimTriplet can achieve decent performance using only 1% labeled data. The code and data are available at https://github.com/hrlblab/SimTriple.
Orthogonal Projection Loss
Mar 25, 2021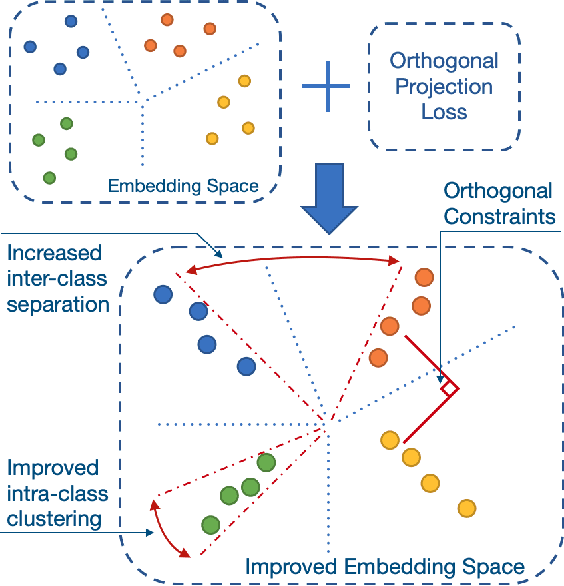
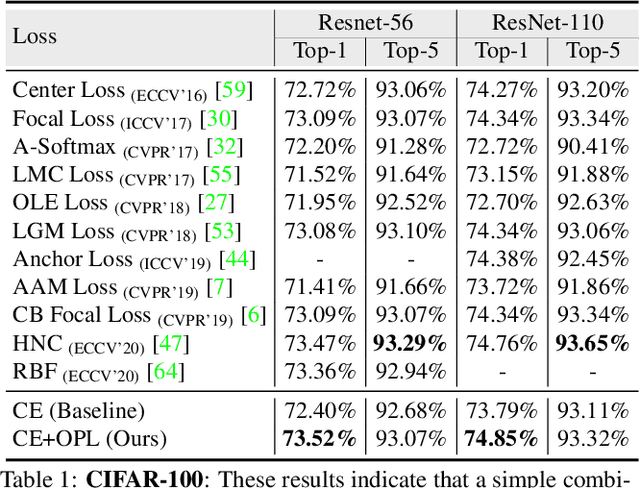
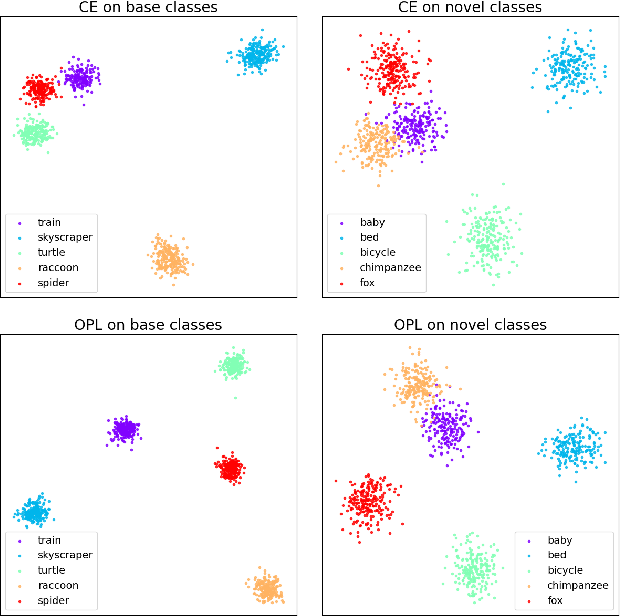
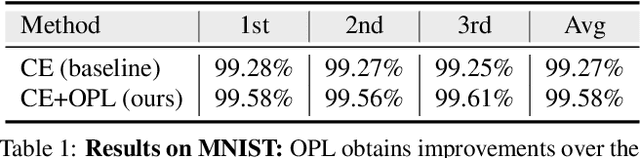
Deep neural networks have achieved remarkable performance on a range of classification tasks, with softmax cross-entropy (CE) loss emerging as the de-facto objective function. The CE loss encourages features of a class to have a higher projection score on the true class-vector compared to the negative classes. However, this is a relative constraint and does not explicitly force different class features to be well-separated. Motivated by the observation that ground-truth class representations in CE loss are orthogonal (one-hot encoded vectors), we develop a novel loss function termed `Orthogonal Projection Loss' (OPL) which imposes orthogonality in the feature space. OPL augments the properties of CE loss and directly enforces inter-class separation alongside intra-class clustering in the feature space through orthogonality constraints on the mini-batch level. As compared to other alternatives of CE, OPL offers unique advantages e.g., no additional learnable parameters, does not require careful negative mining and is not sensitive to the batch size. Given the plug-and-play nature of OPL, we evaluate it on a diverse range of tasks including image recognition (CIFAR-100), large-scale classification (ImageNet), domain generalization (PACS) and few-shot learning (miniImageNet, CIFAR-FS, tiered-ImageNet and Meta-dataset) and demonstrate its effectiveness across the board. Furthermore, OPL offers better robustness against practical nuisances such as adversarial attacks and label noise. Code is available at: https://github.com/kahnchana/opl.
Generalized Doubly Reparameterized Gradient Estimators
Jan 26, 2021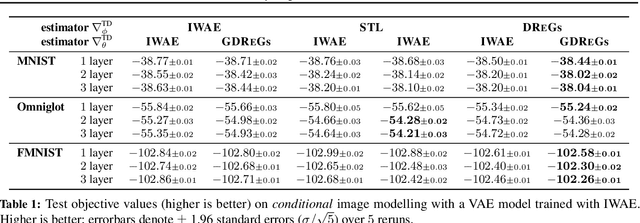

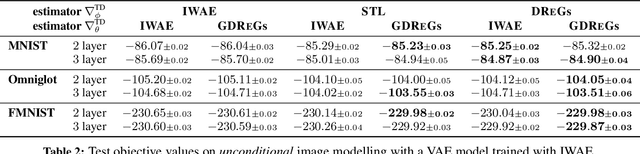

Efficient low-variance gradient estimation enabled by the reparameterization trick (RT) has been essential to the success of variational autoencoders. Doubly-reparameterized gradients (DReGs) improve on the RT for multi-sample variational bounds by applying reparameterization a second time for an additional reduction in variance. Here, we develop two generalizations of the DReGs estimator and show that they can be used to train conditional and hierarchical VAEs on image modelling tasks more effectively. We first extend the estimator to hierarchical models with several stochastic layers by showing how to treat additional score function terms due to the hierarchical variational posterior. We then generalize DReGs to score functions of arbitrary distributions instead of just those of the sampling distribution, which makes the estimator applicable to the parameters of the prior in addition to those of the posterior.