 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-focused Neurodegeneration Convolutional Neural Network for Modeling and Classification of Alzheimer's Disease
Jan 10, 2024
Alzheimer's disease (AD), the predominant form of dementia, poses a growing global challenge and underscores the urgency of accurate and early diagnosis. The clinical technique radiologists adopt for distinguishing between mild cognitive impairment (MCI) and AD using Machine Resonance Imaging (MRI) encounter hurdles because they are not consistent and reliable. Machine learning has been shown to offer promise for early AD diagnosis. However, existing models focused on focal fine-grain features without considerations to focal structural features that give off information on neurodegeneration of the brain cerebral cortex. Therefore, this paper proposes a machine learning (ML) framework that integrates Gamma correction, an image enhancement technique, and includes a structure-focused neurodegeneration convolutional neural network (CNN) architecture called SNeurodCNN for discriminating between AD and MCI. The ML framework leverages the mid-sagittal and para-sagittal brain image viewpoints of the structure-focused Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through experiments, our proposed machine learning framework shows exceptional performance. The parasagittal viewpoint set achieves 97.8% accuracy, with 97.0% specificity and 98.5% sensitivity. The midsagittal viewpoint is shown to present deeper insights into the structural brain changes given the increase in accuracy, specificity, and sensitivity, which are 98.1% 97.2%, and 99.0%, respectively. Using GradCAM technique, we show that our proposed model is capable of capturing the structural dynamics of MCI and AD which exist about the frontal lobe, occipital lobe, cerebellum, and parietal lobe. Therefore, our model itself as a potential brain structural change Digi-Biomarker for early diagnosis of AD.
Realism in Action: Anomaly-Aware Diagnosis of Brain Tumors from Medical Images Using YOLOv8 and DeiT
Jan 10, 2024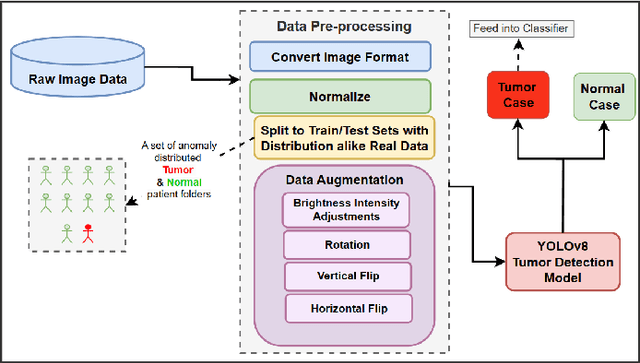
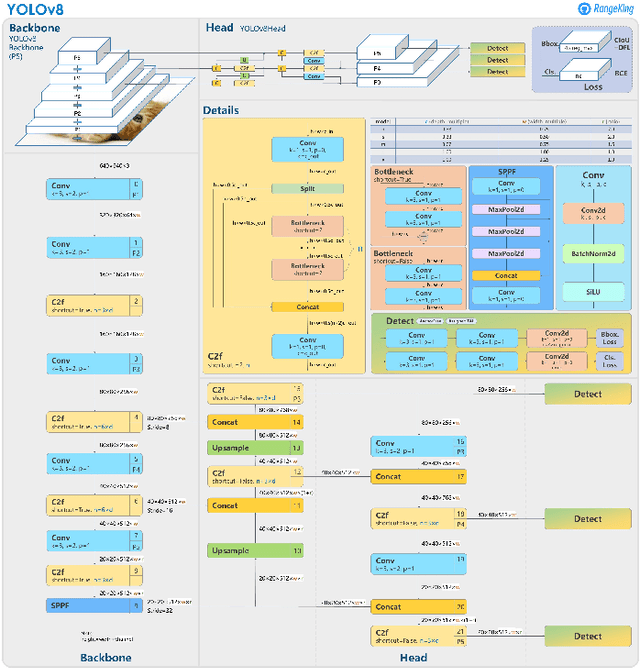
In the field of medical sciences, reliable detection and classification of brain tumors from images remains a formidable challenge due to the rarity of tumors within the population of patients. Therefore, the ability to detect tumors in anomaly scenarios is paramount for ensuring timely interventions and improved patient outcomes. This study addresses the issue by leveraging deep learning (DL) techniques to detect and classify brain tumors in challenging situations. The curated data set from the National Brain Mapping Lab (NBML) comprises 81 patients, including 30 Tumor cases and 51 Normal cases. The detection and classification pipelines are separated into two consecutive tasks. The detection phase involved comprehensive data analysis and pre-processing to modify the number of image samples and the number of patients of each class to anomaly distribution (9 Normal per 1 Tumor) to comply with real world scenarios. Next, in addition to common evaluation metrics for the testing, we employed a novel performance evaluation method called Patient to Patient (PTP), focusing on the realistic evaluation of the model. In the detection phase, we fine-tuned a YOLOv8n detection model to detect the tumor region. Subsequent testing and evaluation yielded competitive performance both in Common Evaluation Metrics and PTP metrics. Furthermore, using the Data Efficient Image Transformer (DeiT) module, we distilled a Vision Transformer (ViT) model from a fine-tuned ResNet152 as a teacher in the classification phase. This approach demonstrates promising strides in reliable tumor detection and classification, offering potential advancements in tumor diagnosis for real-world medical imaging scenarios.
Intrinsic Image Diffusion for Single-view Material Estimation
Dec 19, 2023We present Intrinsic Image Diffusion, a generative model for appearance decomposition of indoor scenes. Given a single input view, we sample multiple possible material explanations represented as albedo, roughness, and metallic maps. Appearance decomposition poses a considerable challenge in computer vision due to the inherent ambiguity between lighting and material properties and the lack of real datasets. To address this issue, we advocate for a probabilistic formulation, where instead of attempting to directly predict the true material properties, we employ a conditional generative model to sample from the solution space. Furthermore, we show that utilizing the strong learned prior of recent diffusion models trained on large-scale real-world images can be adapted to material estimation and highly improves the generalization to real images. Our method produces significantly sharper, more consistent, and more detailed materials, outperforming state-of-the-art methods by $1.5dB$ on PSNR and by $45\%$ better FID score on albedo prediction. We demonstrate the effectiveness of our approach through experiments on both synthetic and real-world datasets.
Uncertainty-aware Sampling for Long-tailed Semi-supervised Learning
Jan 09, 2024For semi-supervised learning with imbalance classes, the long-tailed distribution of data will increase the model prediction bias toward dominant classes, undermining performance on less frequent classes. Existing methods also face challenges in ensuring the selection of sufficiently reliable pseudo-labels for model training and there is a lack of mechanisms to adjust the selection of more reliable pseudo-labels based on different training stages. To mitigate this issue, we introduce uncertainty into the modeling process for pseudo-label sampling, taking into account that the model performance on the tailed classes varies over different training stages. For example, at the early stage of model training, the limited predictive accuracy of model results in a higher rate of uncertain pseudo-labels. To counter this, we propose an Uncertainty-Aware Dynamic Threshold Selection (UDTS) approach. This approach allows the model to perceive the uncertainty of pseudo-labels at different training stages, thereby adaptively adjusting the selection thresholds for different classes. Compared to other methods such as the baseline method FixMatch, UDTS achieves an increase in accuracy of at least approximately 5.26%, 1.75%, 9.96%, and 1.28% on the natural scene image datasets CIFAR10-LT, CIFAR100-LT, STL-10-LT, and the medical image dataset TissueMNIST, respectively. The source code of UDTS is publicly available at: https://github.com/yangk/UDTS.
SonicVisionLM: Playing Sound with Vision Language Models
Jan 09, 2024There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision language models. Instead of generating audio directly from video, we use the capabilities of powerful vision language models (VLMs). When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed temporally controlled audio adapters. Our approach surpasses current state-of-the-art methods for converting video to audio, resulting in enhanced synchronization with the visuals and improved alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/
PPIDSG: A Privacy-Preserving Image Distribution Sharing Scheme with GAN in Federated Learning
Dec 16, 2023Federated learning (FL) has attracted growing attention since it allows for privacy-preserving collaborative training on decentralized clients without explicitly uploading sensitive data to the central server. However, recent works have revealed that it still has the risk of exposing private data to adversaries. In this paper, we conduct reconstruction attacks and enhance inference attacks on various datasets to better understand that sharing trained classification model parameters to a central server is the main problem of privacy leakage in FL. To tackle this problem, a privacy-preserving image distribution sharing scheme with GAN (PPIDSG) is proposed, which consists of a block scrambling-based encryption algorithm, an image distribution sharing method, and local classification training. Specifically, our method can capture the distribution of a target image domain which is transformed by the block encryption algorithm, and upload generator parameters to avoid classifier sharing with negligible influence on model performance. Furthermore, we apply a feature extractor to motivate model utility and train it separately from the classifier. The extensive experimental results and security analyses demonstrate the superiority of our proposed scheme compared to other state-of-the-art defense methods. The code is available at https://github.com/ytingma/PPIDSG.
ReFusion: Learning Image Fusion from Reconstruction with Learnable Loss via Meta-Learning
Dec 13, 2023Image fusion aims to combine information from multiple source images into a single and more informative image. A major challenge for deep learning-based image fusion algorithms is the absence of a definitive ground truth and distance measurement. Thus, the manually specified loss functions aiming to steer the model learning, include hyperparameters that need to be manually thereby limiting the model's flexibility and generalizability to unseen tasks. To overcome the limitations of designing loss functions for specific fusion tasks, we propose a unified meta-learning based fusion framework named ReFusion, which learns optimal fusion loss from reconstructing source images. ReFusion consists of a fusion module, a loss proposal module, and a reconstruction module. Compared with the conventional methods with fixed loss functions, ReFusion employs a parameterized loss function, which is dynamically adapted by the loss proposal module based on the specific fusion scene and task. To ensure that the fusion network preserves maximal information from the source images, makes it possible to reconstruct the original images from the fusion image, a meta-learning strategy is used to make the reconstruction loss continually refine the parameters of the loss proposal module. Adaptive updating is achieved by alternating between inter update, outer update, and fusion update, where the training of the three components facilitates each other. Extensive experiments affirm that our method can successfully adapt to diverse fusion tasks, including infrared-visible, multi-focus, multi-exposure, and medical image fusion problems. The code will be released.
VQCNIR: Clearer Night Image Restoration with Vector-Quantized Codebook
Dec 16, 2023Night photography often struggles with challenges like low light and blurring, stemming from dark environments and prolonged exposures. Current methods either disregard priors and directly fitting end-to-end networks, leading to inconsistent illumination, or rely on unreliable handcrafted priors to constrain the network, thereby bringing the greater error to the final result. We believe in the strength of data-driven high-quality priors and strive to offer a reliable and consistent prior, circumventing the restrictions of manual priors. In this paper, we propose Clearer Night Image Restoration with Vector-Quantized Codebook (VQCNIR) to achieve remarkable and consistent restoration outcomes on real-world and synthetic benchmarks. To ensure the faithful restoration of details and illumination, we propose the incorporation of two essential modules: the Adaptive Illumination Enhancement Module (AIEM) and the Deformable Bi-directional Cross-Attention (DBCA) module. The AIEM leverages the inter-channel correlation of features to dynamically maintain illumination consistency between degraded features and high-quality codebook features. Meanwhile, the DBCA module effectively integrates texture and structural information through bi-directional cross-attention and deformable convolution, resulting in enhanced fine-grained detail and structural fidelity across parallel decoders. Extensive experiments validate the remarkable benefits of VQCNIR in enhancing image quality under low-light conditions, showcasing its state-of-the-art performance on both synthetic and real-world datasets. The code is available at https://github.com/AlexZou14/VQCNIR.
Concrete Surface Crack Detection with Convolutional-based Deep Learning Models
Jan 13, 2024Effective crack detection is pivotal for the structural health monitoring and inspection of buildings. This task presents a formidable challenge to computer vision techniques due to the inherently subtle nature of cracks, which often exhibit low-level features that can be easily confounded with background textures, foreign objects, or irregularities in construction. Furthermore, the presence of issues like non-uniform lighting and construction irregularities poses significant hurdles for autonomous crack detection during building inspection and monitoring. Convolutional neural networks (CNNs) have emerged as a promising framework for crack detection, offering high levels of accuracy and precision. Additionally, the ability to adapt pre-trained networks through transfer learning provides a valuable tool for users, eliminating the need for an in-depth understanding of algorithm intricacies. Nevertheless, it is imperative to acknowledge the limitations and considerations when deploying CNNs, particularly in contexts where the outcomes carry immense significance, such as crack detection in buildings. In this paper, our approach to surface crack detection involves the utilization of various deep-learning models. Specifically, we employ fine-tuning techniques on pre-trained deep learning architectures: VGG19, ResNet50, Inception V3, and EfficientNetV2. These models are chosen for their established performance and versatility in image analysis tasks. We compare deep learning models using precision, recall, and F1 scores.
* 11 pages, 3 figures, Journal paper
Investigating Semi-Supervised Learning Algorithms in Text Datasets
Jan 07, 2024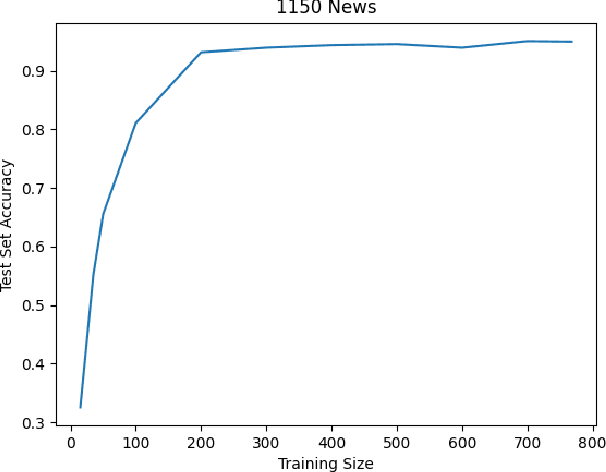
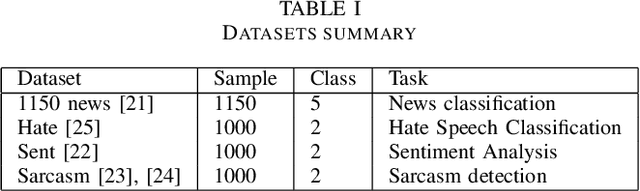
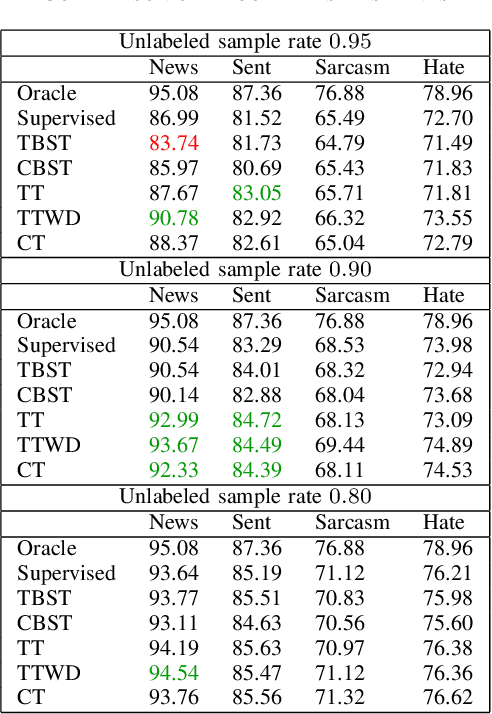
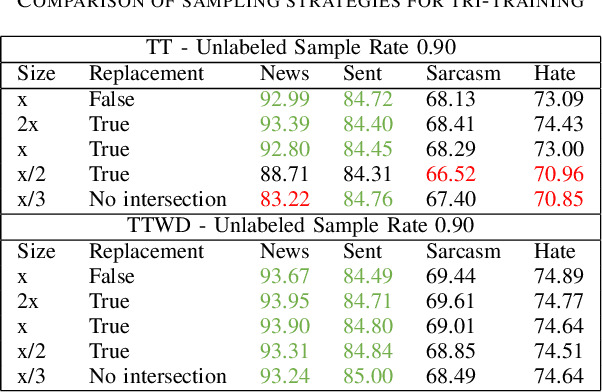
Using large training datasets enhances the generalization capabilities of neural networks. Semi-supervised learning (SSL) is useful when there are few labeled data and a lot of unlabeled data. SSL methods that use data augmentation are most successful for image datasets. In contrast, texts do not have consistent augmentation methods as images. Consequently, methods that use augmentation are not as effective in text data as they are in image data. In this study, we compared SSL algorithms that do not require augmentation; these are self-training, co-training, tri-training, and tri-training with disagreement. In the experiments, we used 4 different text datasets for different tasks. We examined the algorithms from a variety of perspectives by asking experiment questions and suggested several improvements. Among the algorithms, tri-training with disagreement showed the closest performance to the Oracle; however, performance gap shows that new semi-supervised algorithms or improvements in existing methods are needed.
* Innovations in Intelligent Systems and Applications Conference (ASYU)