 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiple Convolutional Features in Siamese Networks for Object Tracking
Mar 01, 2021
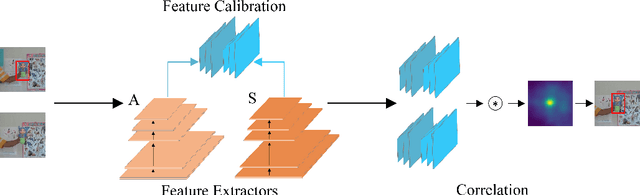
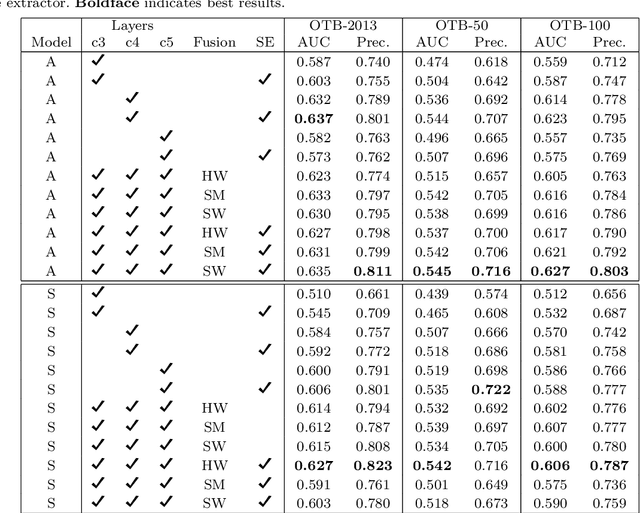
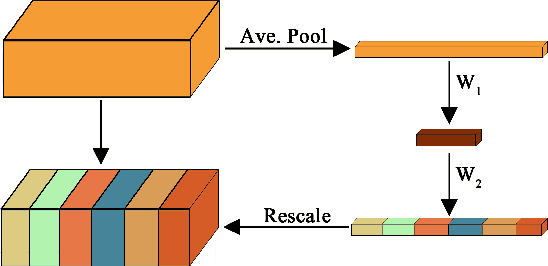
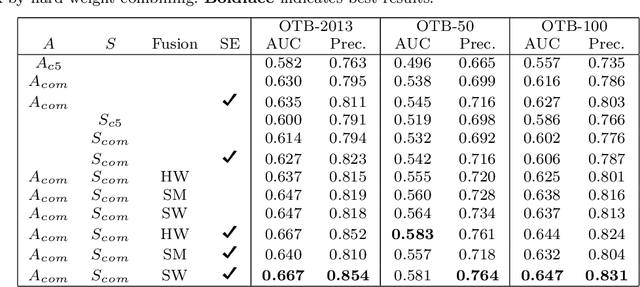
Siamese trackers demonstrated high performance in object tracking due to their balance between accuracy and speed. Unlike classification-based CNNs, deep similarity networks are specifically designed to address the image similarity problem, and thus are inherently more appropriate for the tracking task. However, Siamese trackers mainly use the last convolutional layers for similarity analysis and target search, which restricts their performance. In this paper, we argue that using a single convolutional layer as feature representation is not an optimal choice in a deep similarity framework. We present a Multiple Features-Siamese Tracker (MFST), a novel tracking algorithm exploiting several hierarchical feature maps for robust tracking. Since convolutional layers provide several abstraction levels in characterizing an object, fusing hierarchical features allows to obtain a richer and more efficient representation of the target. Moreover, we handle the target appearance variations by calibrating the deep features extracted from two different CNN models. Based on this advanced feature representation, our method achieves high tracking accuracy, while outperforming the standard siamese tracker on object tracking benchmarks. The source code and trained models are available at https://github.com/zhenxili96/MFST.
MFST: Multi-Features Siamese Tracker
Mar 01, 2021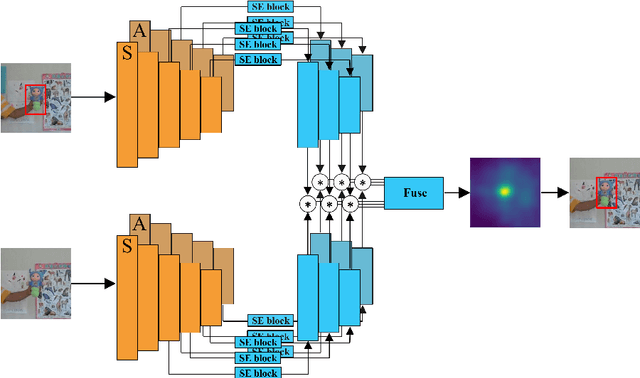
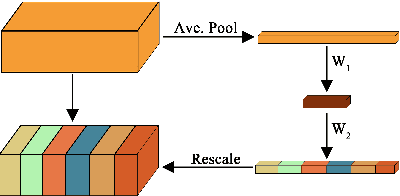
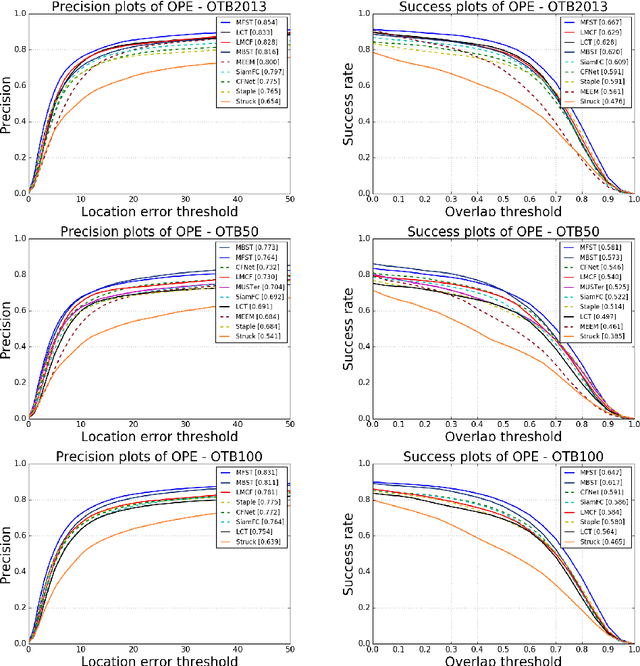
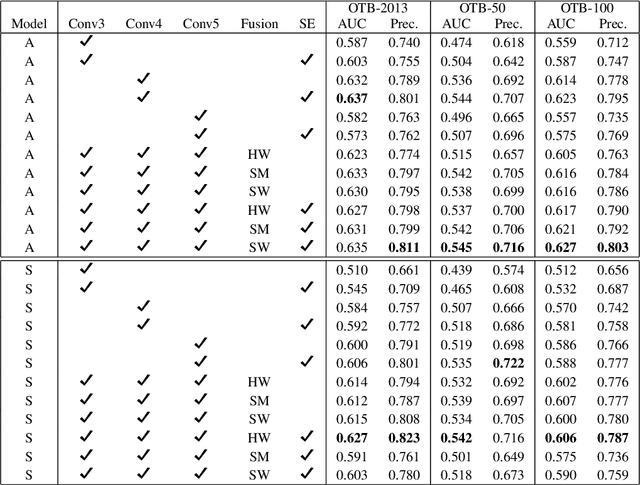
Siamese trackers have recently achieved interesting results due to their balance between accuracy and speed. This success is mainly due to the fact that deep similarity networks were specifically designed to address the image similarity problem. Therefore, they are inherently more appropriate than classical CNNs for the tracking task. However, Siamese trackers rely on the last convolutional layers for similarity analysis and target search, which restricts their performance. In this paper, we argue that using a single convolutional layer as feature representation is not the optimal choice within the deep similarity framework, as multiple convolutional layers provide several abstraction levels in characterizing an object. Starting from this motivation, we present the Multi-Features Siamese Tracker (MFST), a novel tracking algorithm exploiting several hierarchical feature maps for robust deep similarity tracking. MFST proceeds by fusing hierarchical features to ensure a richer and more efficient representation. Moreover, we handle appearance variation by calibrating deep features extracted from two different CNN models. Based on this advanced feature representation, our algorithm achieves high tracking accuracy, while outperforming several state-of-the-art trackers, including standard Siamese trackers. The code and trained models are available at https://github.com/zhenxili96/MFST.
Assessing The Importance Of Colours For CNNs In Object Recognition
Dec 12, 2020
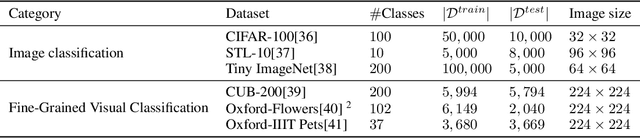
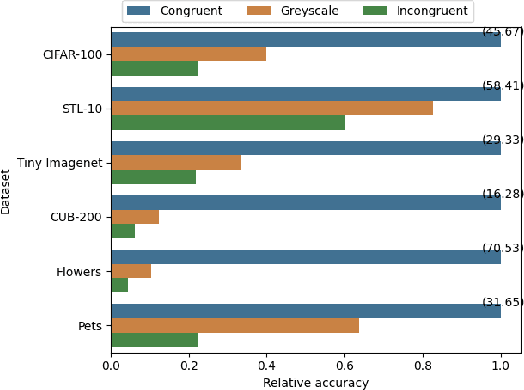

Humans rely heavily on shapes as a primary cue for object recognition. As secondary cues, colours and textures are also beneficial in this regard. Convolutional neural networks (CNNs), an imitation of biological neural networks, have been shown to exhibit conflicting properties. Some studies indicate that CNNs are biased towards textures whereas, another set of studies suggests shape bias for a classification task. However, they do not discuss the role of colours, implying its possible humble role in the task of object recognition. In this paper, we empirically investigate the importance of colours in object recognition for CNNs. We are able to demonstrate that CNNs often rely heavily on colour information while making a prediction. Our results show that the degree of dependency on colours tend to vary from one dataset to another. Moreover, networks tend to rely more on colours if trained from scratch. Pre-training can allow the model to be less colour dependent. To facilitate these findings, we follow the framework often deployed in understanding role of colours in object recognition for humans. We evaluate a model trained with congruent images (images in original colours eg. red strawberries) on congruent, greyscale, and incongruent images (images in unnatural colours eg. blue strawberries). We measure and analyse network's predictive performance (top-1 accuracy) under these different stylisations. We utilise standard datasets of supervised image classification and fine-grained image classification in our experiments.
Compositional GAN: Learning Conditional Image Composition
Aug 23, 2018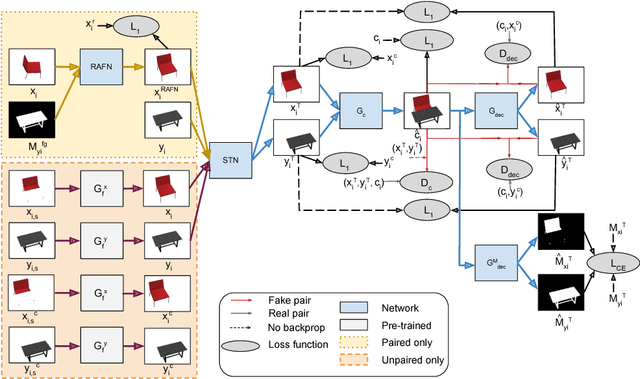

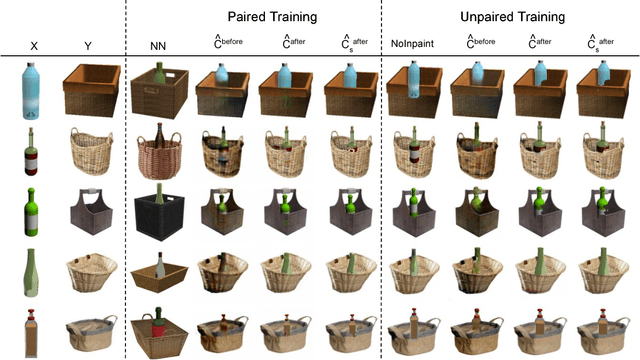
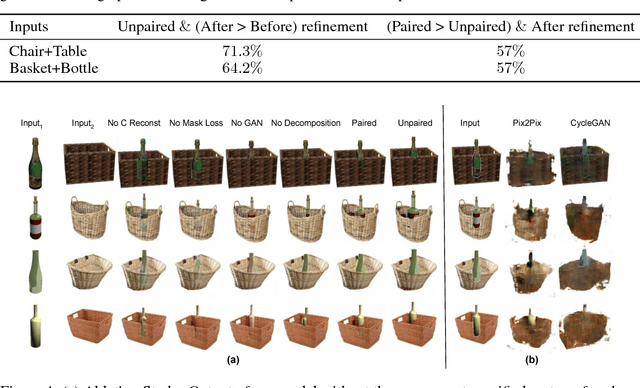
Generative Adversarial Networks (GANs) can produce images of surprising complexity and realism, but are generally modeled to sample from a single latent source ignoring the explicit spatial interaction between multiple entities that could be present in a scene. Capturing such complex interactions between different objects in the world, including their relative scaling, spatial layout, occlusion, or viewpoint transformation is a challenging problem. In this work, we propose to model object composition in a GAN framework as a self-consistent composition-decomposition network. Our model is conditioned on the object images from their marginal distributions to generate a realistic image from their joint distribution by explicitly learning the possible interactions. We evaluate our model through qualitative experiments and user evaluations in both the scenarios when either paired or unpaired examples for the individual object images and the joint scenes are given during training. Our results reveal that the learned model captures potential interactions between the two object domains given as input to output new instances of composed scene at test time in a reasonable fashion.
PC-HMR: Pose Calibration for 3D Human Mesh Recovery from 2D Images/Videos
Mar 18, 2021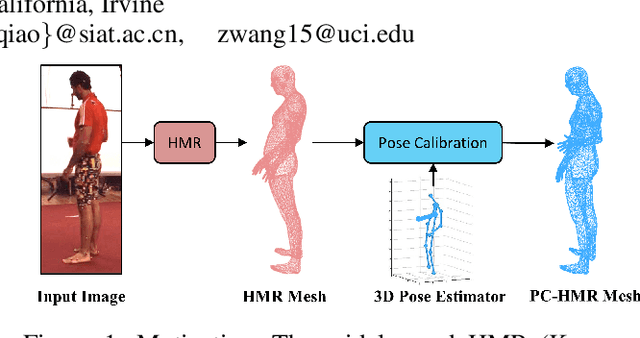
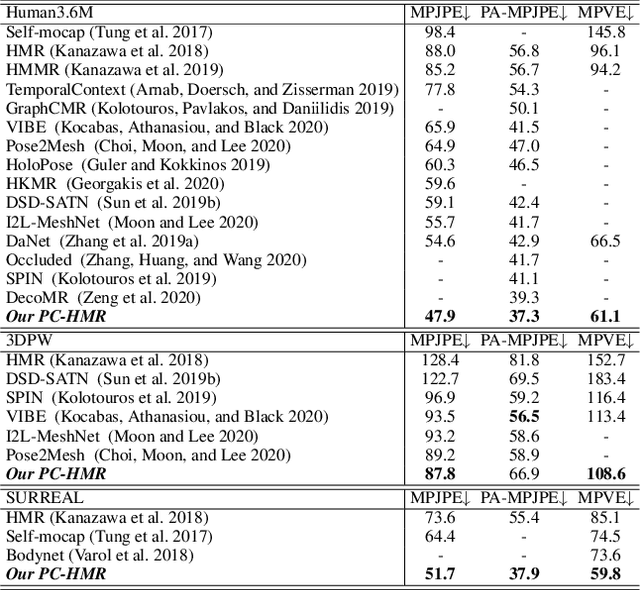
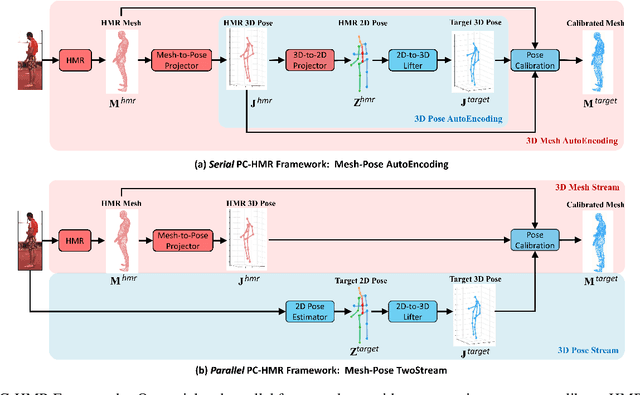
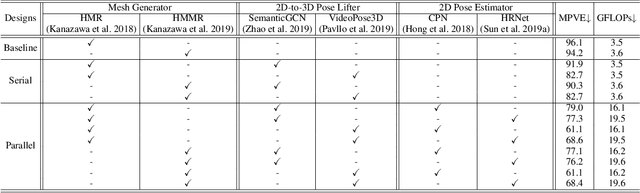
The end-to-end Human Mesh Recovery (HMR) approach has been successfully used for 3D body reconstruction. However, most HMR-based frameworks reconstruct human body by directly learning mesh parameters from images or videos, while lacking explicit guidance of 3D human pose in visual data. As a result, the generated mesh often exhibits incorrect pose for complex activities. To tackle this problem, we propose to exploit 3D pose to calibrate human mesh. Specifically, we develop two novel Pose Calibration frameworks, i.e., Serial PC-HMR and Parallel PC-HMR. By coupling advanced 3D pose estimators and HMR in a serial or parallel manner, these two frameworks can effectively correct human mesh with guidance of a concise pose calibration module. Furthermore, since the calibration module is designed via non-rigid pose transformation, our PC-HMR frameworks can flexibly tackle bone length variations to alleviate misplacement in the calibrated mesh. Finally, our frameworks are based on generic and complementary integration of data-driven learning and geometrical modeling. Via plug-and-play modules, they can be efficiently adapted for both image/video-based human mesh recovery. Additionally, they have no requirement of extra 3D pose annotations in the testing phase, which releases inference difficulties in practice. We perform extensive experiments on the popular bench-marks, i.e., Human3.6M, 3DPW and SURREAL, where our PC-HMR frameworks achieve the SOTA results.
NeRF--: Neural Radiance Fields Without Known Camera Parameters
Feb 19, 2021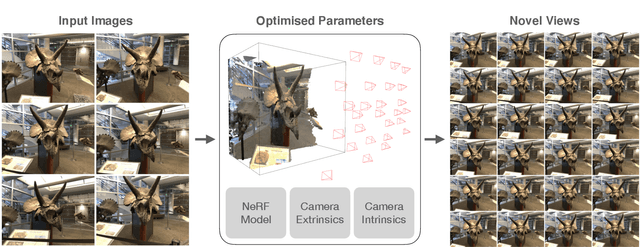
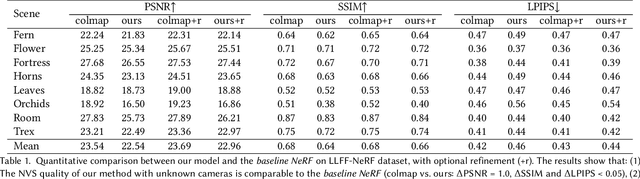
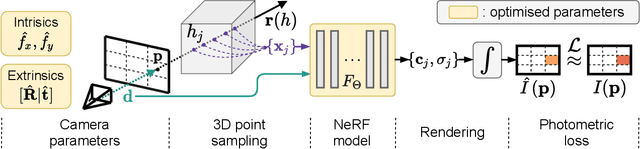
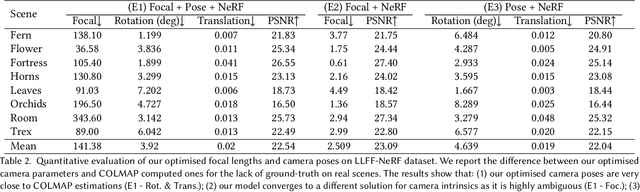
This paper tackles the problem of novel view synthesis (NVS) from 2D images without known camera poses and intrinsics. Among various NVS techniques, Neural Radiance Field (NeRF) has recently gained popularity due to its remarkable synthesis quality. Existing NeRF-based approaches assume that the camera parameters associated with each input image are either directly accessible at training, or can be accurately estimated with conventional techniques based on correspondences, such as Structure-from-Motion. In this work, we propose an end-to-end framework, termed NeRF--, for training NeRF models given only RGB images, without pre-computed camera parameters. Specifically, we show that the camera parameters, including both intrinsics and extrinsics, can be automatically discovered via joint optimisation during the training of the NeRF model. On the standard LLFF benchmark, our model achieves comparable novel view synthesis results compared to the baseline trained with COLMAP pre-computed camera parameters. We also conduct extensive analyses to understand the model behaviour under different camera trajectories, and show that in scenarios where COLMAP fails, our model still produces robust results.
Lensless-camera based machine learning for image classification
Sep 03, 2017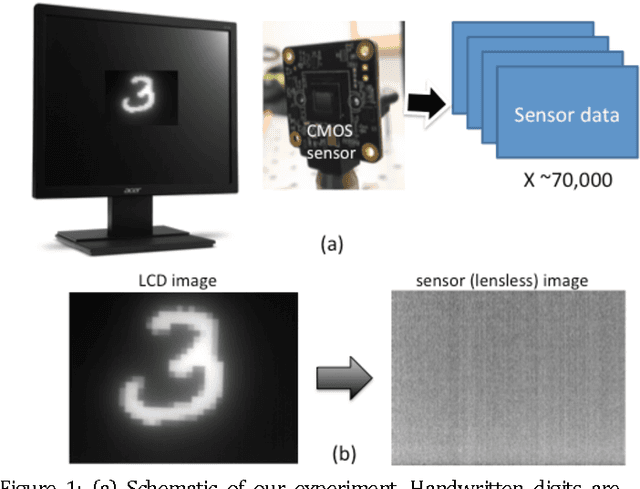
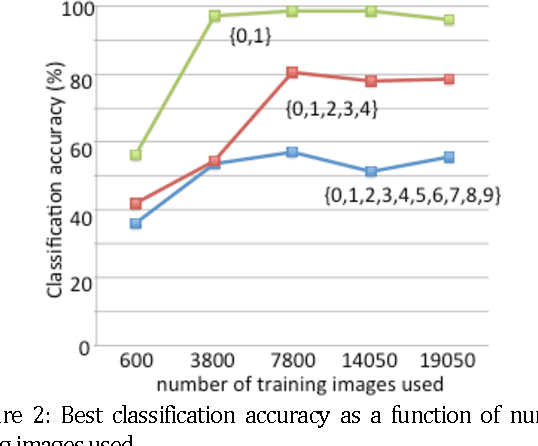
Machine learning (ML) has been widely applied to image classification. Here, we extend this application to data generated by a camera comprised of only a standard CMOS image sensor with no lens. We first created a database of lensless images of handwritten digits. Then, we trained a ML algorithm on this dataset. Finally, we demonstrated that the trained ML algorithm is able to classify the digits with accuracy as high as 99% for 2 digits. Our approach clearly demonstrates the potential for non-human cameras in machine-based decision-making scenarios.
Smooth-AP: Smoothing the Path Towards Large-Scale Image Retrieval
Jul 23, 2020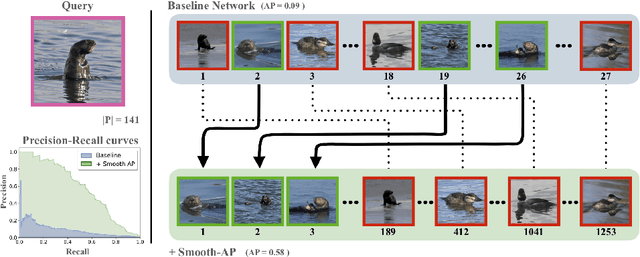
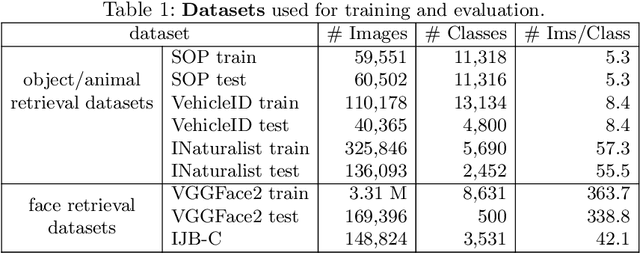

Optimising a ranking-based metric, such as Average Precision (AP), is notoriously challenging due to the fact that it is non-differentiable, and hence cannot be optimised directly using gradient-descent methods. To this end, we introduce an objective that optimises instead a smoothed approximation of AP, coined Smooth-AP. Smooth-AP is a plug-and-play objective function that allows for end-to-end training of deep networks with a simple and elegant implementation. We also present an analysis for why directly optimising the ranking based metric of AP offers benefits over other deep metric learning losses. We apply Smooth-AP to standard retrieval benchmarks: Stanford Online products and VehicleID, and also evaluate on larger-scale datasets: INaturalist for fine-grained category retrieval, and VGGFace2 and IJB-C for face retrieval. In all cases, we improve the performance over the state-of-the-art, especially for larger-scale datasets, thus demonstrating the effectiveness and scalability of Smooth-AP to real-world scenarios.
VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
Mar 10, 2021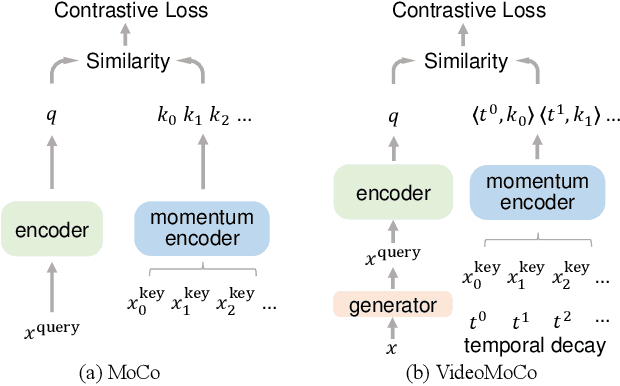
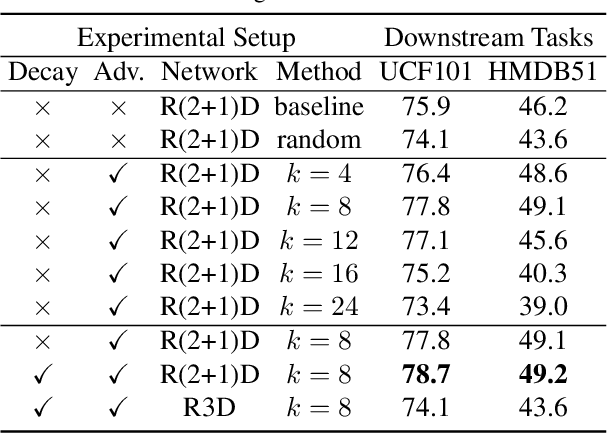
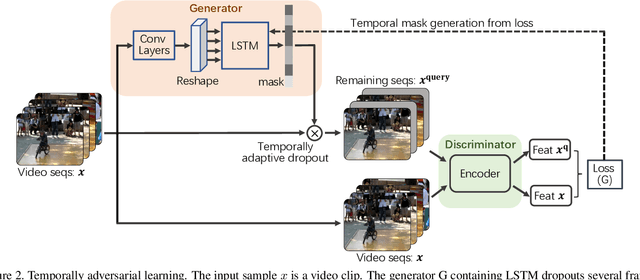
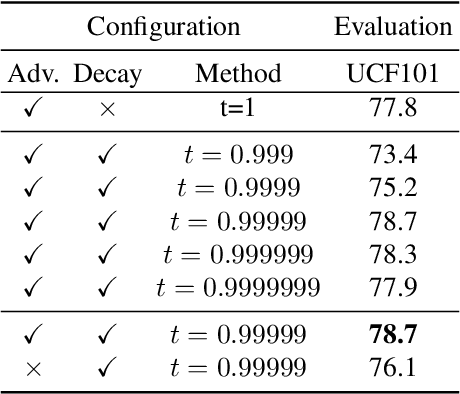
MoCo is effective for unsupervised image representation learning. In this paper, we propose VideoMoCo for unsupervised video representation learning. Given a video sequence as an input sample, we improve the temporal feature representations of MoCo from two perspectives. First, we introduce a generator to drop out several frames from this sample temporally. The discriminator is then learned to encode similar feature representations regardless of frame removals. By adaptively dropping out different frames during training iterations of adversarial learning, we augment this input sample to train a temporally robust encoder. Second, we use temporal decay to model key attenuation in the memory queue when computing the contrastive loss. As the momentum encoder updates after keys enqueue, the representation ability of these keys degrades when we use the current input sample for contrastive learning. This degradation is reflected via temporal decay to attend the input sample to recent keys in the queue. As a result, we adapt MoCo to learn video representations without empirically designing pretext tasks. By empowering the temporal robustness of the encoder and modeling the temporal decay of the keys, our VideoMoCo improves MoCo temporally based on contrastive learning. Experiments on benchmark datasets including UCF101 and HMDB51 show that VideoMoCo stands as a state-of-the-art video representation learning method.
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Aug 25, 2020
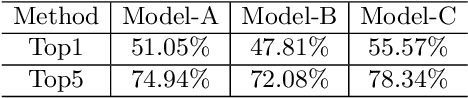
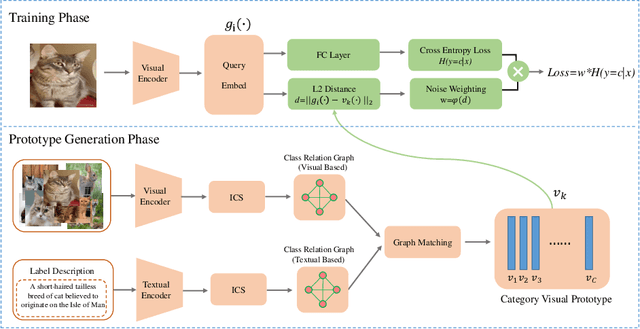

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.