 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Real-time Counterfactual Explanations
Jul 11, 2020
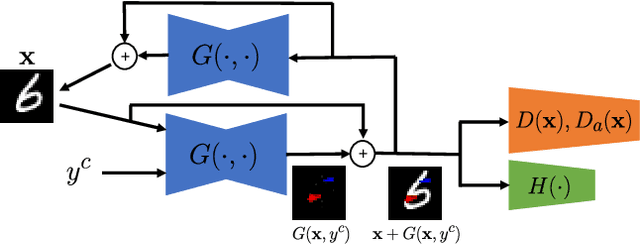
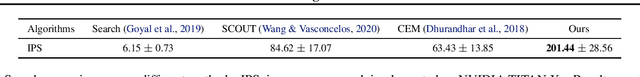

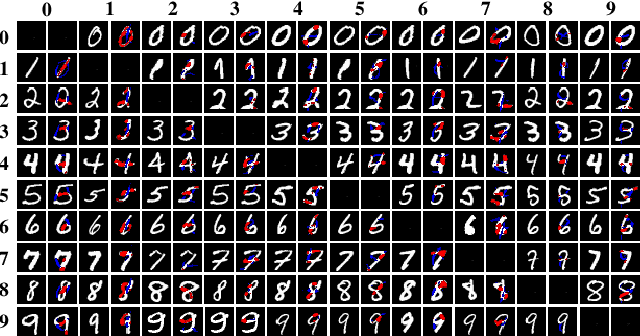
Counterfactual explanations are considered, which is to answer {\it why the prediction is class A but not B.} Different from previous optimization based methods, an optimization-free Fast ReAl-time Counterfactual Explanation (FRACE) algorithm is proposed benefiting from the development of multi-domain image to image translation algorithms. Built from starGAN, a transformer is trained as a residual generator conditional on a classifier constrained under a proposal perturbation loss which maintains the content information of the query image, but just the class-specific semantic information is changed. The transformer can transfer the query image to any counterfactual class, and during inference, our explanation can be generated by it only within a forward time. It is fast and can satisfy the real-time practical application. Because of the adversarial training of GAN, our explanation is also more realistic compared to other counterparts. The experimental results demonstrate that our proposal is better than the existing state of the art in terms of quality and speed.
FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding
Dec 05, 2020
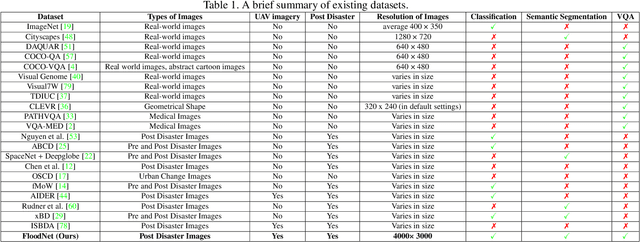
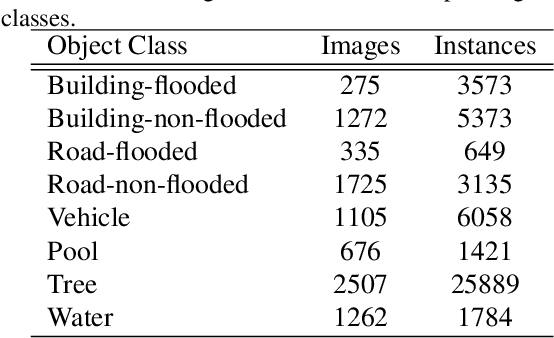
Visual scene understanding is the core task in making any crucial decision in any computer vision system. Although popular computer vision datasets like Cityscapes, MS-COCO, PASCAL provide good benchmarks for several tasks (e.g. image classification, segmentation, object detection), these datasets are hardly suitable for post disaster damage assessments. On the other hand, existing natural disaster datasets include mainly satellite imagery which have low spatial resolution and a high revisit period. Therefore, they do not have a scope to provide quick and efficient damage assessment tasks. Unmanned Aerial Vehicle(UAV) can effortlessly access difficult places during any disaster and collect high resolution imagery that is required for aforementioned tasks of computer vision. To address these issues we present a high resolution UAV imagery, FloodNet, captured after the hurricane Harvey. This dataset demonstrates the post flooded damages of the affected areas. The images are labeled pixel-wise for semantic segmentation task and questions are produced for the task of visual question answering. FloodNet poses several challenges including detection of flooded roads and buildings and distinguishing between natural water and flooded water. With the advancement of deep learning algorithms, we can analyze the impact of any disaster which can make a precise understanding of the affected areas. In this paper, we compare and contrast the performances of baseline methods for image classification, semantic segmentation, and visual question answering on our dataset.
Learning Discriminative Representations for Fine-Grained Diabetic Retinopathy Grading
Nov 04, 2020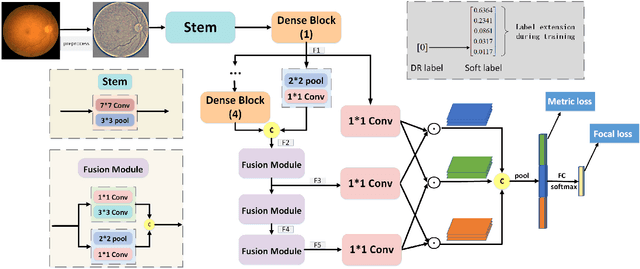
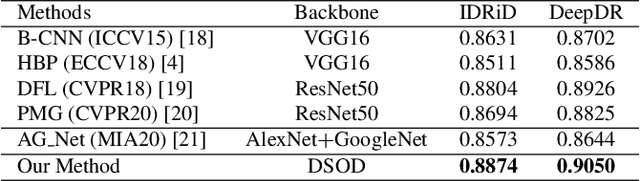
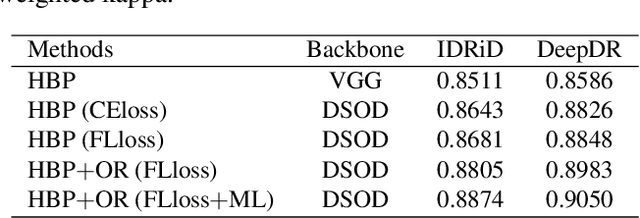
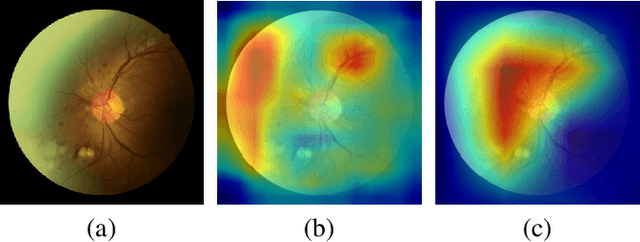
Diabetic retinopathy (DR) is one of the leading causes of blindness. However, no specific symptoms of early DR lead to a delayed diagnosis, which results in disease progression in patients. To determine the disease severity levels, ophthalmologists need to focus on the discriminative parts of the fundus images. In recent years, deep learning has achieved great success in medical image analysis. However, most works directly employ algorithms based on convolutional neural networks (CNNs), which ignore the fact that the difference among classes is subtle and gradual. Hence, we consider automatic image grading of DR as a fine-grained classification task, and construct a bilinear model to identify the pathologically discriminative areas. In order to leverage the ordinal information among classes, we use an ordinal regression method to obtain the soft labels. In addition, other than only using a categorical loss to train our network, we also introduce the metric loss to learn a more discriminative feature space. Experimental results demonstrate the superior performance of the proposed method on two public IDRiD and DeepDR datasets.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 02, 2021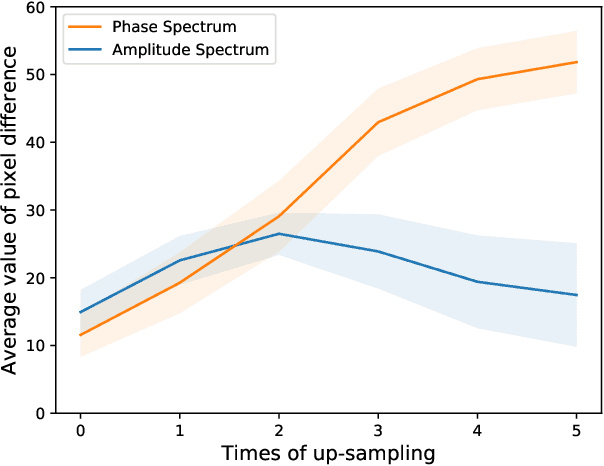
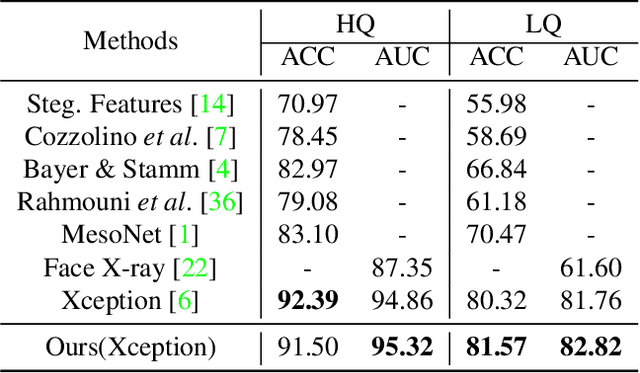
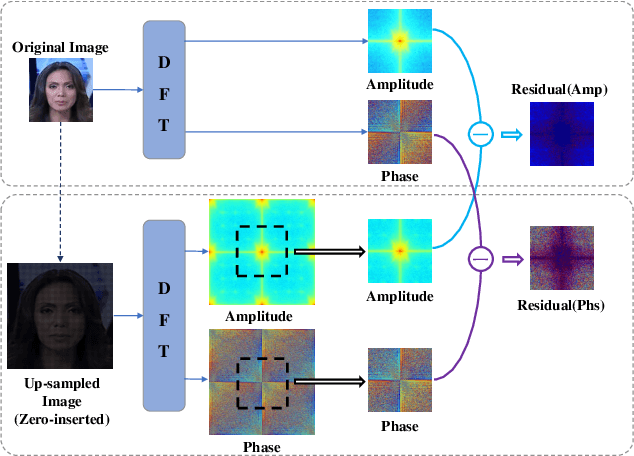
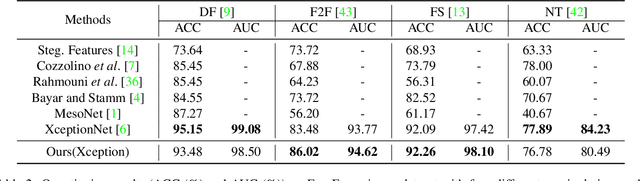
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
Efficient Near-Field Imaging Using Cylindrical MIMO Arrays
Jan 22, 2021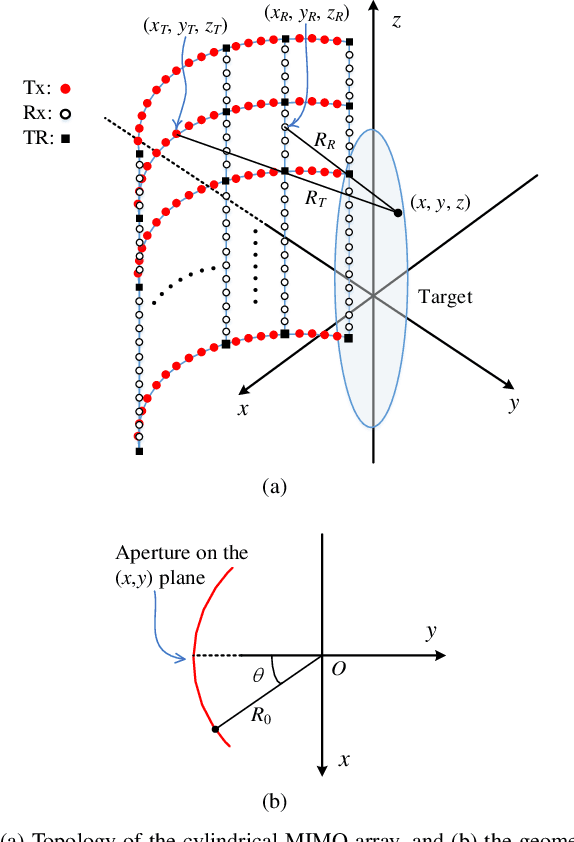
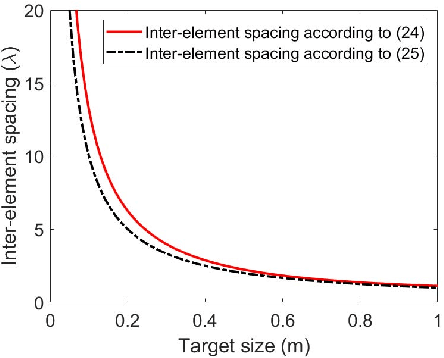
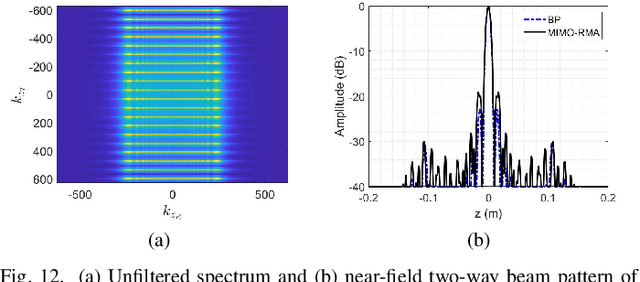
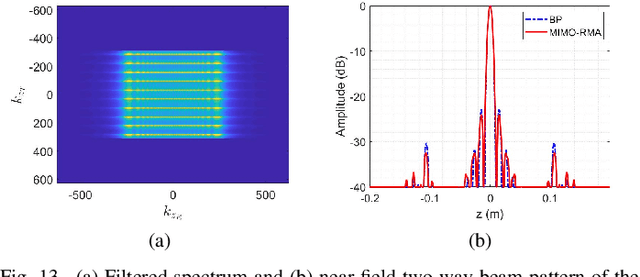
Multiple-input multiple-output (MIMO) array based millimeter-wave (MMW) imaging has a tangible prospect in applications of concealed weapons detection. A near-field imaging algorithm based on wavenumber domain processing is proposed for a cylindrical MIMO array scheme with uniformly spaced transmit and receive antennas over both the vertical and horizontal-arc directions. The spectrum aliasing associated with the proposed MIMO array is analyzed through a zero-filling discrete-time Fourier transform. The analysis shows that an undersampled array can be used in recovering the MMW image by a wavenumber domain algorithm. The requirements for the antenna inter-element spacing of the MIMO array are delineated. Numerical simulations as well as comparisons with the backprojection (BP) algorithm are provided to demonstrate the effectiveness of the proposed method.
Context Decoupling Augmentation for Weakly Supervised Semantic Segmentation
Mar 02, 2021
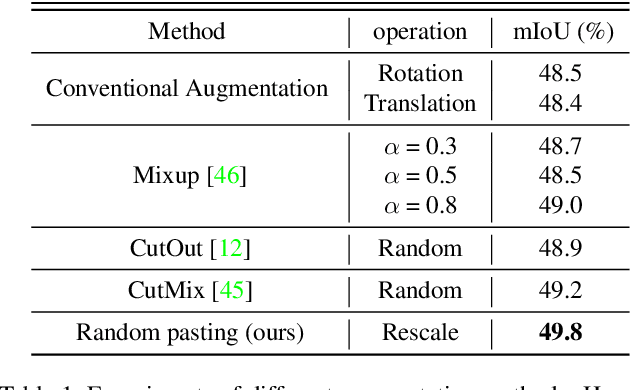
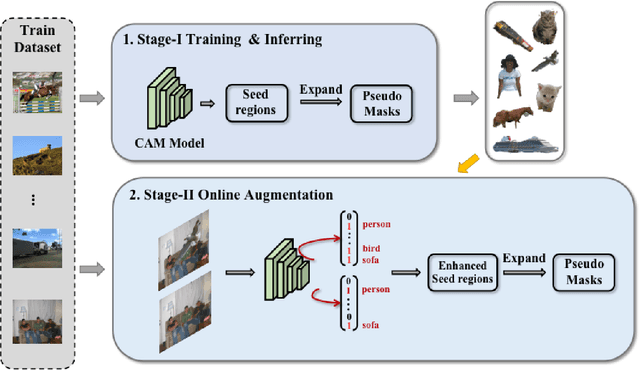
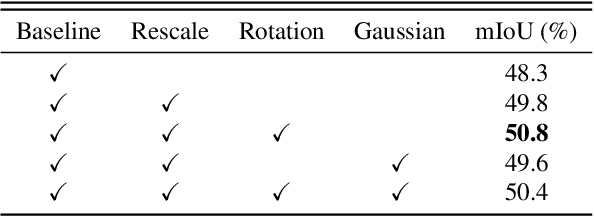
Data augmentation is vital for deep learning neural networks. By providing massive training samples, it helps to improve the generalization ability of the model. Weakly supervised semantic segmentation (WSSS) is a challenging problem that has been deeply studied in recent years, conventional data augmentation approaches for WSSS usually employ geometrical transformations, random cropping and color jittering. However, merely increasing the same contextual semantic data does not bring much gain to the networks to distinguish the objects, e.g., the correct image-level classification of "aeroplane" may be not only due to the recognition of the object itself, but also its co-occurrence context like "sky", which will cause the model to focus less on the object features. To this end, we present a Context Decoupling Augmentation (CDA) method, to change the inherent context in which the objects appear and thus drive the network to remove the dependence between object instances and contextual information. To validate the effectiveness of the proposed method, extensive experiments on PASCAL VOC 2012 dataset with several alternative network architectures demonstrate that CDA can boost various popular WSSS methods to the new state-of-the-art by a large margin.
3D Human Mesh Regression with Dense Correspondence
Jun 10, 2020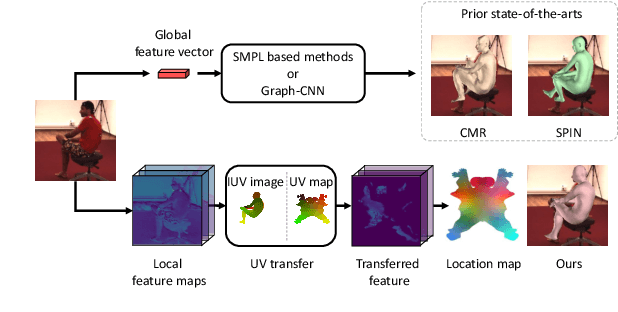

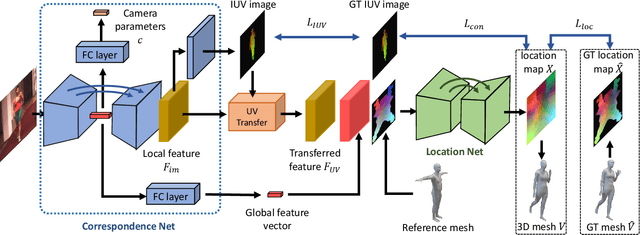
Estimating 3D mesh of the human body from a single 2D image is an important task with many applications such as augmented reality and Human-Robot interaction. However, prior works reconstructed 3D mesh from global image feature extracted by using convolutional neural network (CNN), where the dense correspondences between the mesh surface and the image pixels are missing, leading to suboptimal solution. This paper proposes a model-free 3D human mesh estimation framework, named DecoMR, which explicitly establishes the dense correspondence between the mesh and the local image features in the UV space (i.e. a 2D space used for texture mapping of 3D mesh). DecoMR first predicts pixel-to-surface dense correspondence map (i.e., IUV image), with which we transfer local features from the image space to the UV space. Then the transferred local image features are processed in the UV space to regress a location map, which is well aligned with transferred features. Finally we reconstruct 3D human mesh from the regressed location map with a predefined mapping function. We also observe that the existing discontinuous UV map are unfriendly to the learning of network. Therefore, we propose a novel UV map that maintains most of the neighboring relations on the original mesh surface. Experiments demonstrate that our proposed local feature alignment and continuous UV map outperforms existing 3D mesh based methods on multiple public benchmarks. Code will be made available at https://github.com/zengwang430521/DecoMR
Spatial Attention Point Network for Deep-learning-based Robust Autonomous Robot Motion Generation
Mar 02, 2021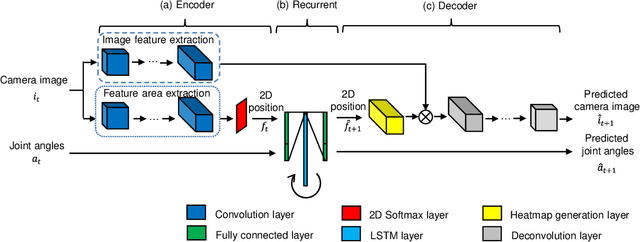
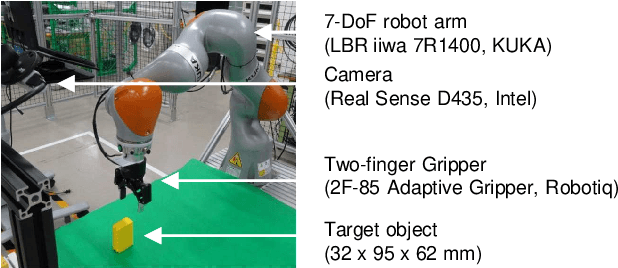
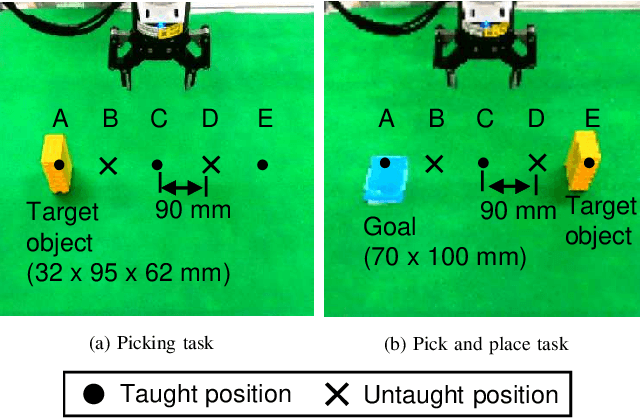

Deep learning provides a powerful framework for automated acquisition of complex robotic motions. However, despite a certain degree of generalization, the need for vast amounts of training data depending on the work-object position is an obstacle to industrial applications. Therefore, a robot motion-generation model that can respond to a variety of work-object positions with a small amount of training data is necessary. In this paper, we propose a method robust to changes in object position by automatically extracting spatial attention points in the image for the robot task and generating motions on the basis of their positions. We demonstrate our method with an LBR iiwa 7R1400 robot arm on a picking task and a pick-and-place task at various positions in various situations. In each task, the spatial attention points are obtained for the work objects that are important to the task. Our method is robust to changes in object position. Further, it is robust to changes in background, lighting, and obstacles that are not important to the task because it only focuses on positions that are important to the task.
Comprehensive Attention Self-Distillation for Weakly-Supervised Object Detection
Oct 22, 2020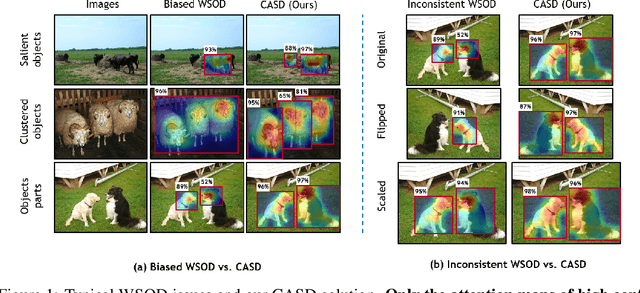

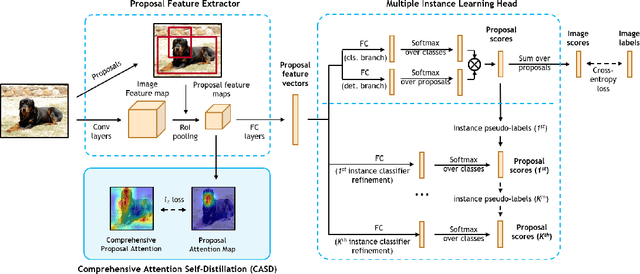

Weakly Supervised Object Detection (WSOD) has emerged as an effective tool to train object detectors using only the image-level category labels. However, without object-level labels, WSOD detectors are prone to detect bounding boxes on salient objects, clustered objects and discriminative object parts. Moreover, the image-level category labels do not enforce consistent object detection across different transformations of the same images. To address the above issues, we propose a Comprehensive Attention Self-Distillation (CASD) training approach for WSOD. To balance feature learning among all object instances, CASD computes the comprehensive attention aggregated from multiple transformations and feature layers of the same images. To enforce consistent spatial supervision on objects, CASD conducts self-distillation on the WSOD networks, such that the comprehensive attention is approximated simultaneously by multiple transformations and feature layers of the same images. CASD produces new state-of-the-art WSOD results on standard benchmarks such as PASCAL VOC 2007/2012 and MS-COCO.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
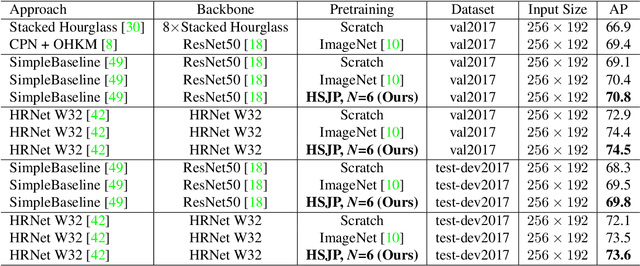

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.