 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
Apr 22, 2019
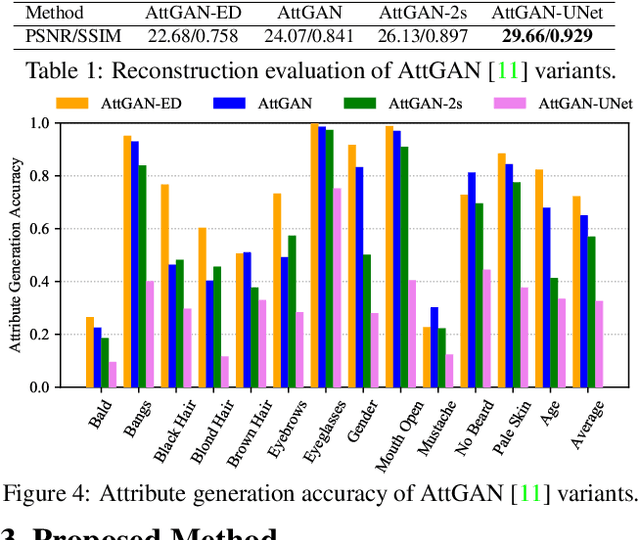



Arbitrary attribute editing generally can be tackled by incorporating encoder-decoder and generative adversarial networks. However, the bottleneck layer in encoder-decoder usually gives rise to blurry and low quality editing result. And adding skip connections improves image quality at the cost of weakened attribute manipulation ability. Moreover, existing methods exploit target attribute vector to guide the flexible translation to desired target domain. In this work, we suggest to address these issues from selective transfer perspective. Considering that specific editing task is certainly only related to the changed attributes instead of all target attributes, our model selectively takes the difference between target and source attribute vectors as input. Furthermore, selective transfer units are incorporated with encoder-decoder to adaptively select and modify encoder feature for enhanced attribute editing. Experiments show that our method (i.e., STGAN) simultaneously improves attribute manipulation accuracy as well as perception quality, and performs favorably against state-of-the-arts in arbitrary facial attribute editing and season translation.
Searching for Alignment in Face Recognition
Feb 10, 2021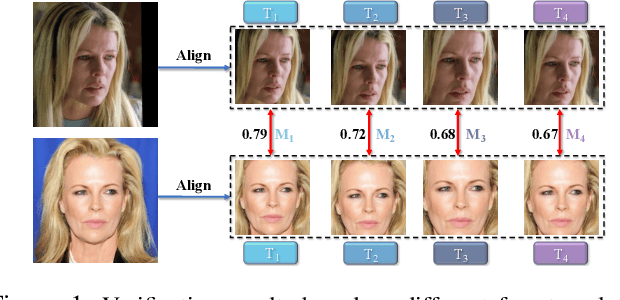
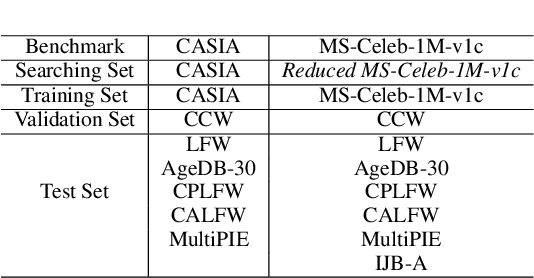
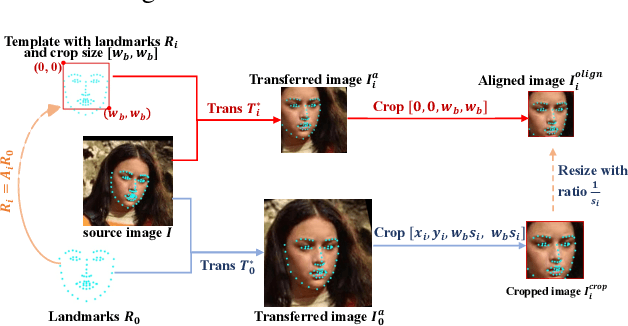
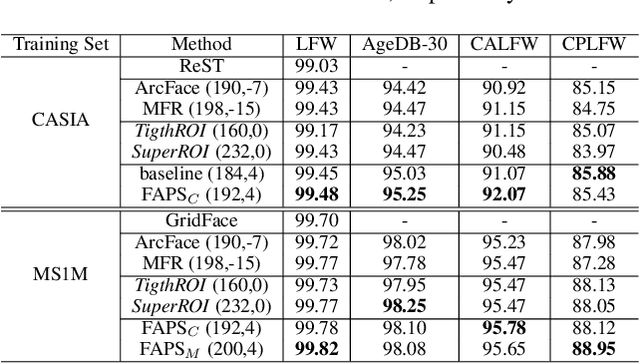
A standard pipeline of current face recognition frameworks consists of four individual steps: locating a face with a rough bounding box and several fiducial landmarks, aligning the face image using a pre-defined template, extracting representations and comparing. Among them, face detection, landmark detection and representation learning have long been studied and a lot of works have been proposed. As an essential step with a significant impact on recognition performance, the alignment step has attracted little attention. In this paper, we first explore and highlight the effects of different alignment templates on face recognition. Then, for the first time, we try to search for the optimal template automatically. We construct a well-defined searching space by decomposing the template searching into the crop size and vertical shift, and propose an efficient method Face Alignment Policy Search (FAPS). Besides, a well-designed benchmark is proposed to evaluate the searched policy. Experiments on our proposed benchmark validate the effectiveness of our method to improve face recognition performance.
Dynamic Neural Networks: A Survey
Feb 10, 2021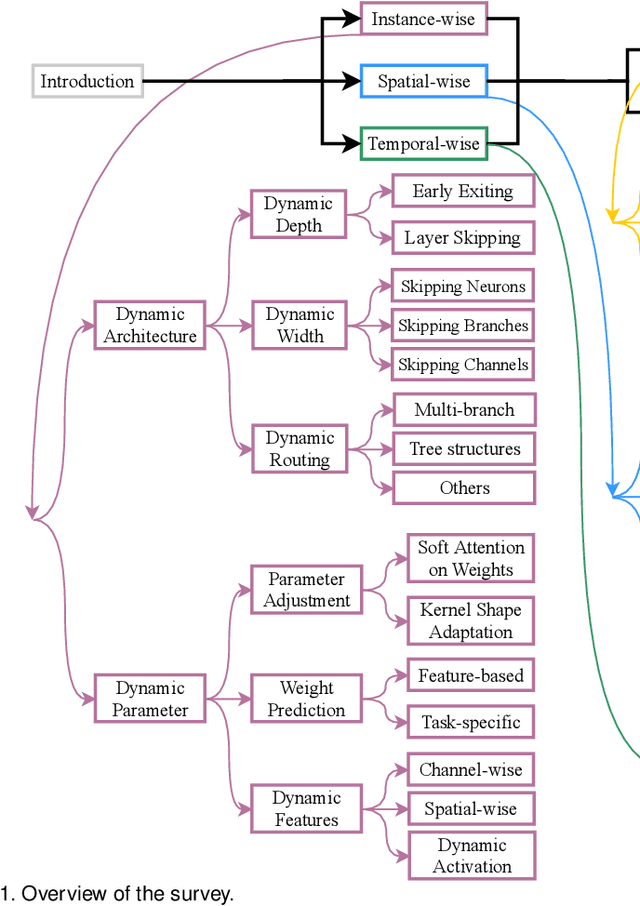
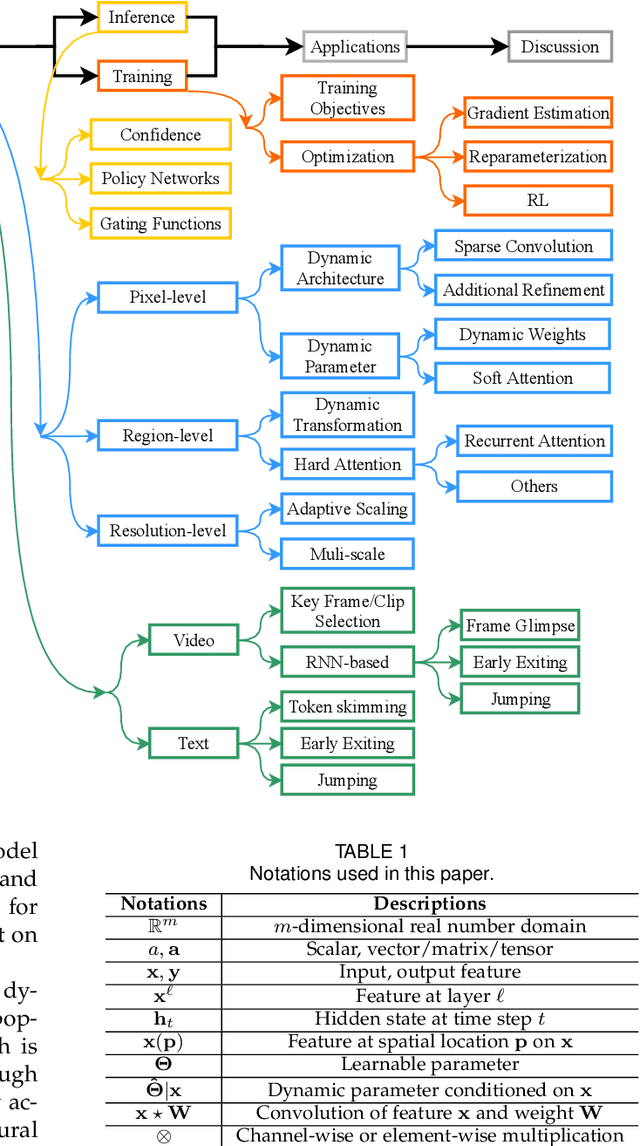
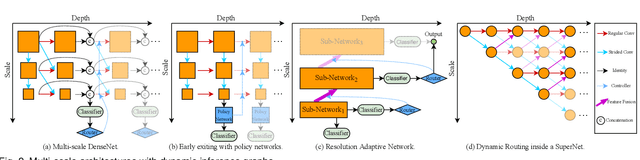

Dynamic neural network is an emerging research topic in deep learning. Compared to static models which have fixed computational graphs and parameters at the inference stage, dynamic networks can adapt their structures or parameters to different inputs, leading to notable advantages in terms of accuracy, computational efficiency, adaptiveness, etc. In this survey, we comprehensively review this rapidly developing area by dividing dynamic networks into three main categories: 1) instance-wise dynamic models that process each instance with data-dependent architectures or parameters; 2) spatial-wise dynamic networks that conduct adaptive computation with respect to different spatial locations of image data and 3) temporal-wise dynamic models that perform adaptive inference along the temporal dimension for sequential data such as videos and texts. The important research problems of dynamic networks, e.g., architecture design, decision making scheme, optimization technique and applications, are reviewed systematically. Finally, we discuss the open problems in this field together with interesting future research directions.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021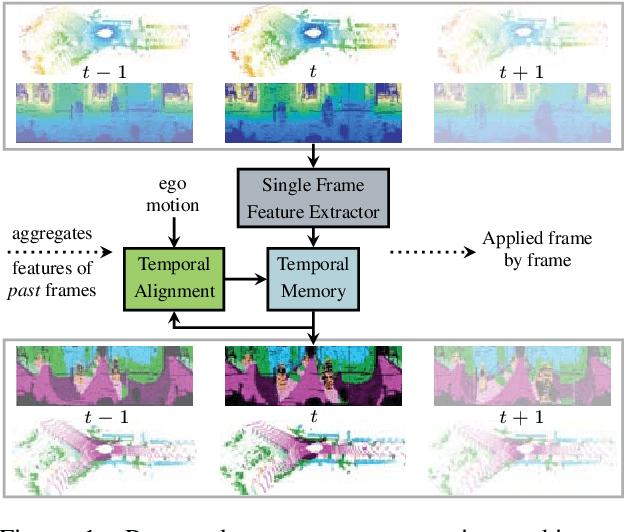
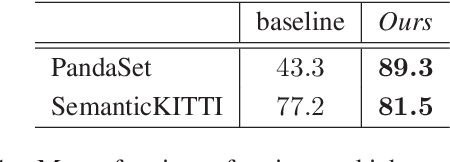
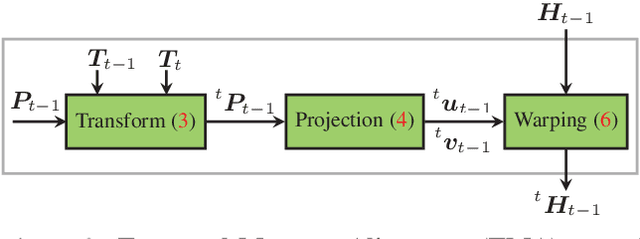
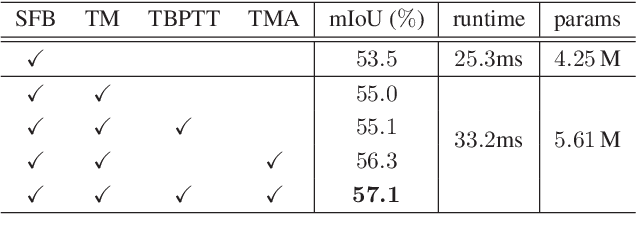
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
RGB-D image-based Object Detection: from Traditional Methods to Deep Learning Techniques
Jul 22, 2019
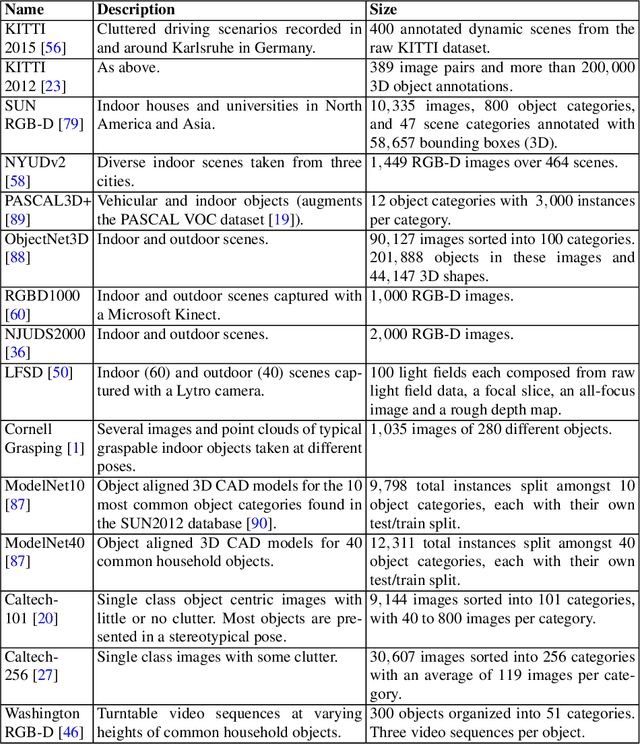

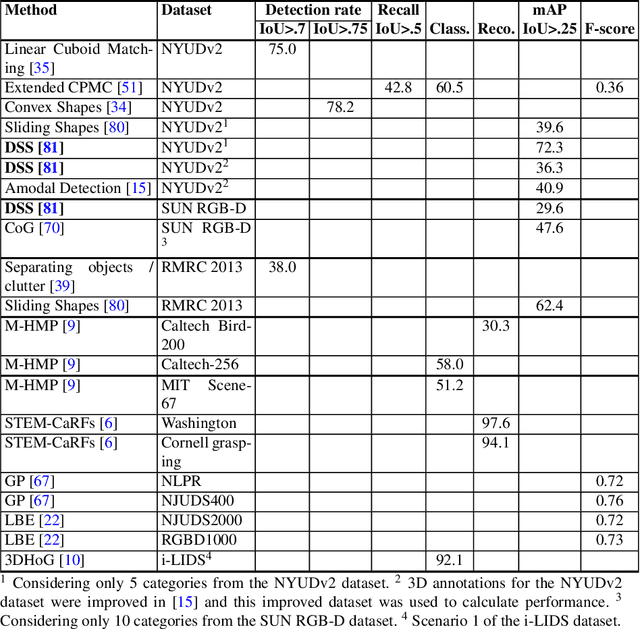
Object detection from RGB images is a long-standing problem in image processing and computer vision. It has applications in various domains including robotics, surveillance, human-computer interaction, and medical diagnosis. With the availability of low cost 3D scanners, a large number of RGB-D object detection approaches have been proposed in the past years. This chapter provides a comprehensive survey of the recent developments in this field. We structure the chapter into two parts; the focus of the first part is on techniques that are based on hand-crafted features combined with machine learning algorithms. The focus of the second part is on the more recent work, which is based on deep learning. Deep learning techniques, coupled with the availability of large training datasets, have now revolutionized the field of computer vision, including RGB-D object detection, achieving an unprecedented level of performance. We survey the key contributions, summarize the most commonly used pipelines, discuss their benefits and limitations, and highlight some important directions for future research.
Simulation of Vision-based Tactile Sensors using Physics based Rendering
Dec 24, 2020



Tactile sensing has seen rapid adoption with the advent of vision-based tactile sensors. Vision-based tactile sensors provide high resolution, compact and inexpensive data to perform precise in-hand manipulation and robot-human interaction. However, the simulation of tactile sensors is still a challenge. In this paper, we built the first fully general optical tactile simulation system for GelSight using physics-based rendering techniques. We propose physically accurate light models and show in-depth analysis of individual components of our simulation pipeline. Our system outperforms previous simulation techniques qualitatively and quantitative on image similarity metrics.
Automatic Detection of Cardiac Chambers Using an Attention-based YOLOv4 Framework from Four-chamber View of Fetal Echocardiography
Nov 26, 2020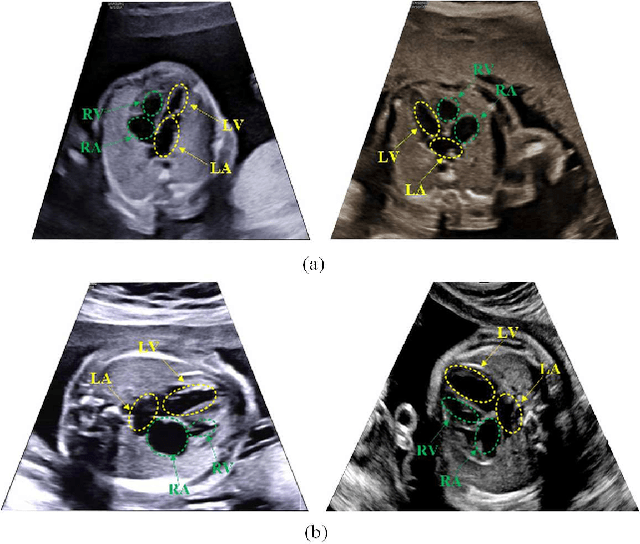
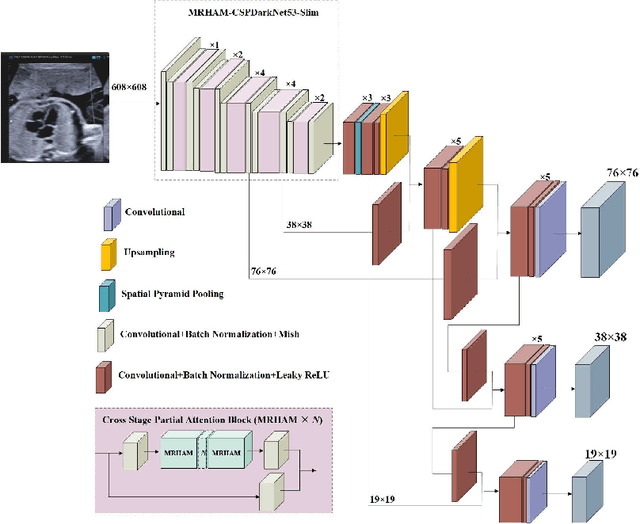
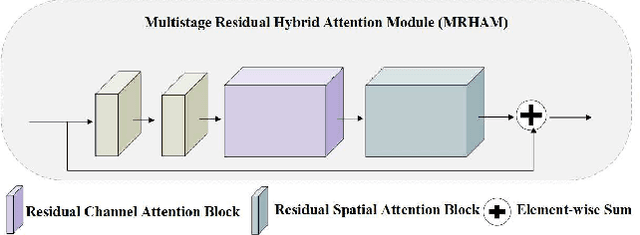
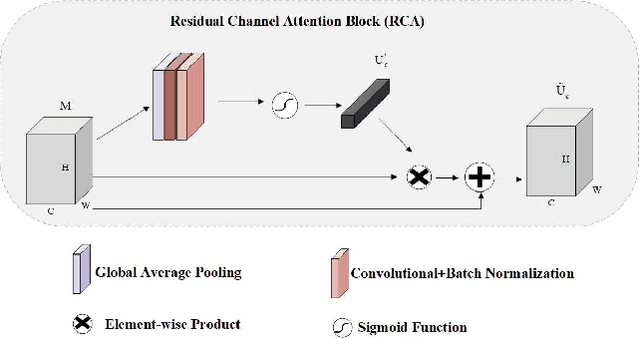
Echocardiography is a powerful prenatal examination tool for early diagnosis of fetal congenital heart diseases (CHDs). The four-chamber (FC) view is a crucial and easily accessible ultrasound (US) image among echocardiography images. Automatic analysis of FC views contributes significantly to the early diagnosis of CHDs. The first step to automatically analyze fetal FC views is locating the fetal four crucial chambers of heart in a US image. However, it is a greatly challenging task due to several key factors, such as numerous speckles in US images, the fetal cardiac chambers with small size and unfixed positions, and category indistinction caused by the similarity of cardiac chambers. These factors hinder the process of capturing robust and discriminative features, hence destroying fetal cardiac anatomical chambers precise localization. Therefore, we first propose a multistage residual hybrid attention module (MRHAM) to improve the feature learning. Then, we present an improved YOLOv4 detection model, namely MRHAM-YOLOv4-Slim. Specially, the residual identity mapping is replaced with the MRHAM in the backbone of MRHAM-YOLOv4-Slim, accurately locating the four important chambers in fetal FC views. Extensive experiments demonstrate that our proposed method outperforms current state-of-the-art, including the precision of 0.890, the recall of 0.920, the F1 score of 0.907 and the mAP of 0.913.
Contrastive Self-supervised Neural Architecture Search
Feb 21, 2021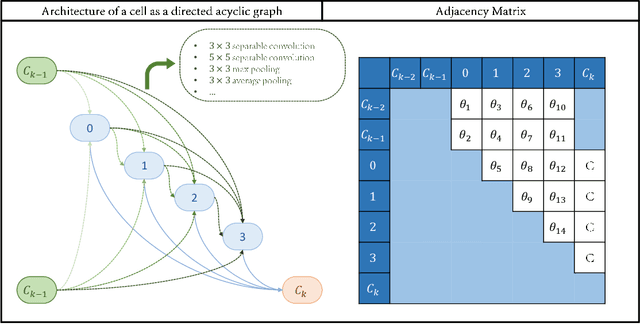
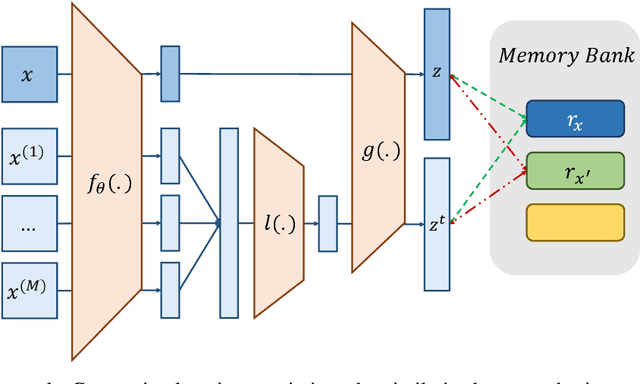
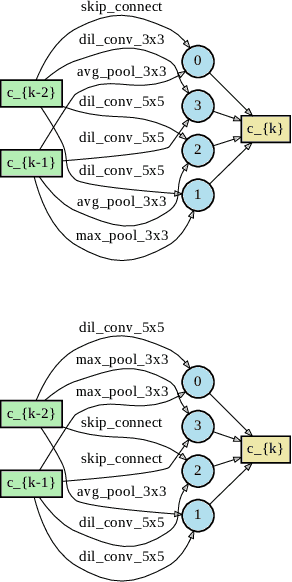
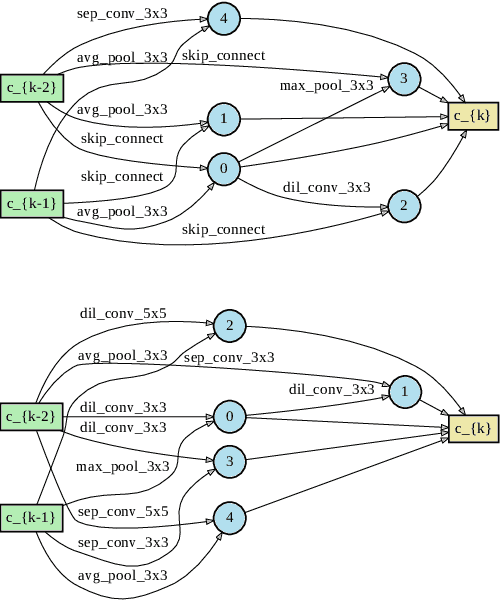
This paper proposes a novel cell-based neural architecture search algorithm (NAS), which completely alleviates the expensive costs of data labeling inherited from supervised learning. Our algorithm capitalizes on the effectiveness of self-supervised learning for image representations, which is an increasingly crucial topic of computer vision. First, using only a small amount of unlabeled train data under contrastive self-supervised learning allow us to search on a more extensive search space, discovering better neural architectures without surging the computational resources. Second, we entirely relieve the cost for labeled data (by contrastive loss) in the search stage without compromising architectures' final performance in the evaluation phase. Finally, we tackle the inherent discrete search space of the NAS problem by sequential model-based optimization via the tree-parzen estimator (SMBO-TPE), enabling us to reduce the computational expense response surface significantly. An extensive number of experiments empirically show that our search algorithm can achieve state-of-the-art results with better efficiency in data labeling cost, searching time, and accuracy in final validation.
Compositional GAN: Learning Conditional Image Composition
Aug 23, 2018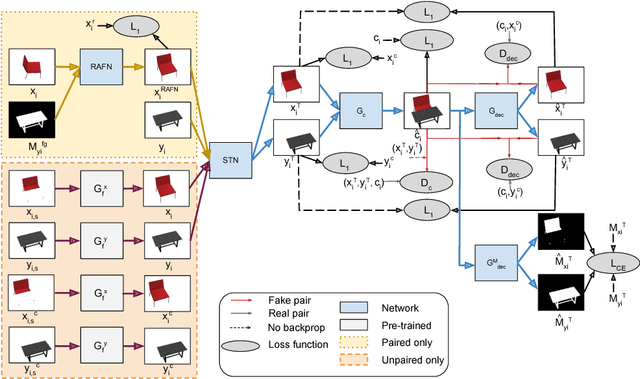

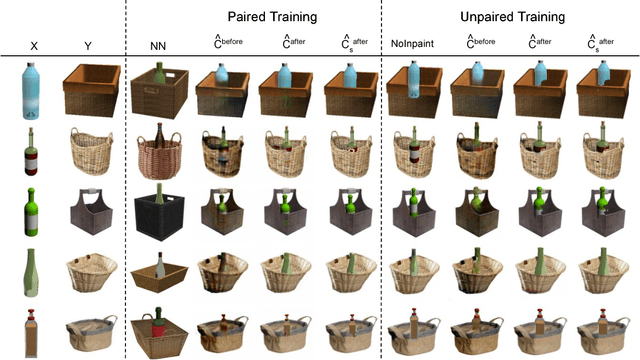
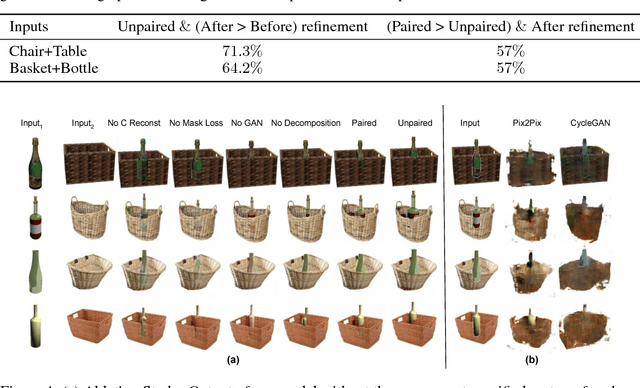
Generative Adversarial Networks (GANs) can produce images of surprising complexity and realism, but are generally modeled to sample from a single latent source ignoring the explicit spatial interaction between multiple entities that could be present in a scene. Capturing such complex interactions between different objects in the world, including their relative scaling, spatial layout, occlusion, or viewpoint transformation is a challenging problem. In this work, we propose to model object composition in a GAN framework as a self-consistent composition-decomposition network. Our model is conditioned on the object images from their marginal distributions to generate a realistic image from their joint distribution by explicitly learning the possible interactions. We evaluate our model through qualitative experiments and user evaluations in both the scenarios when either paired or unpaired examples for the individual object images and the joint scenes are given during training. Our results reveal that the learned model captures potential interactions between the two object domains given as input to output new instances of composed scene at test time in a reasonable fashion.
One Shot Learning for Deformable Medical Image Registration and Periodic Motion Tracking
Jul 11, 2019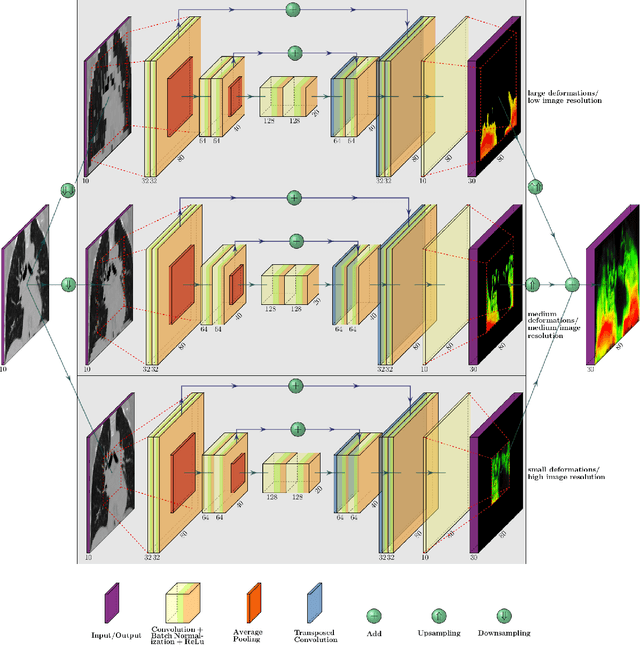
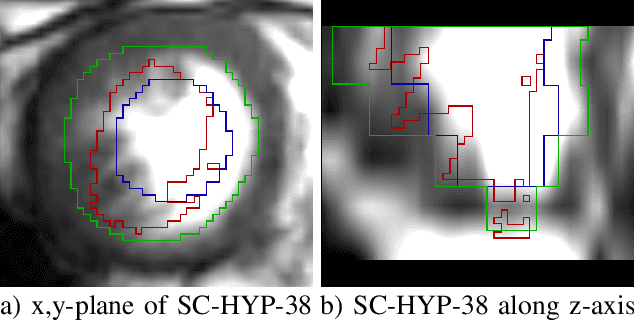
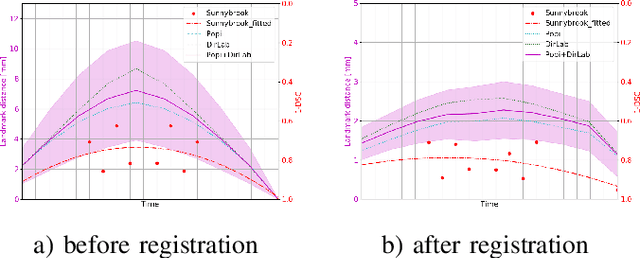
Deformable image registration is a very important field of research in medical imaging. Recently multiple deep learning approaches were published in this area showing promising results. However, drawbacks of deep learning methods are the need for a large amount of training datasets and their inability to register unseen images different from the training datasets. One shot learning comes without the need of large training datasets and has already been proven to be applicable to 3D data. In this work we present an one shot registration approach for periodic motion tracking in 3D and 4D datasets. When applied to 3D dataset the algorithm calculates the inverse of a registration vector field simultaneously. For registration we employed a U-Net combined with a coarse to fine approach and a differential spatial transformer module. The algorithm was thoroughly tested with multiple 4D and 3D datasets publicly available. The results show that the presented approach is able to track periodic motion and to yield a competitive registration accuracy. Possible applications are the use as a stand-alone algorithm for 3D and 4D motion tracking or in the beginning of studies until enough datasets for a separate training phase are available.