 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Context Decoupling Augmentation for Weakly Supervised Semantic Segmentation
Mar 02, 2021

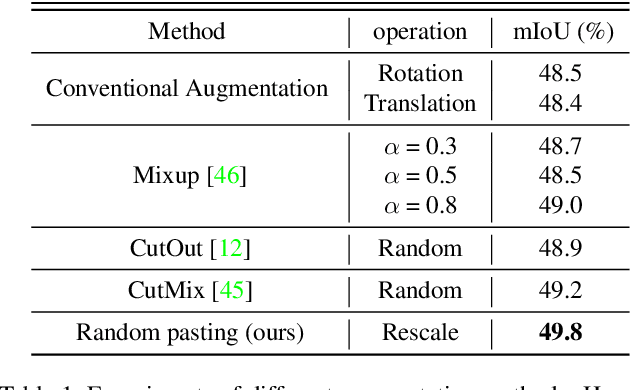
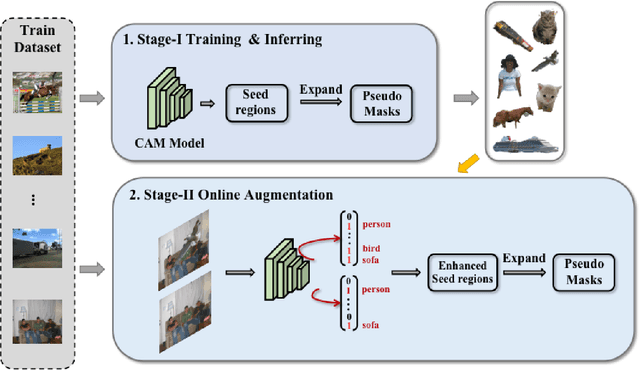
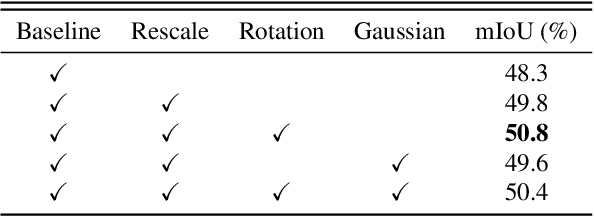
Data augmentation is vital for deep learning neural networks. By providing massive training samples, it helps to improve the generalization ability of the model. Weakly supervised semantic segmentation (WSSS) is a challenging problem that has been deeply studied in recent years, conventional data augmentation approaches for WSSS usually employ geometrical transformations, random cropping and color jittering. However, merely increasing the same contextual semantic data does not bring much gain to the networks to distinguish the objects, e.g., the correct image-level classification of "aeroplane" may be not only due to the recognition of the object itself, but also its co-occurrence context like "sky", which will cause the model to focus less on the object features. To this end, we present a Context Decoupling Augmentation (CDA) method, to change the inherent context in which the objects appear and thus drive the network to remove the dependence between object instances and contextual information. To validate the effectiveness of the proposed method, extensive experiments on PASCAL VOC 2012 dataset with several alternative network architectures demonstrate that CDA can boost various popular WSSS methods to the new state-of-the-art by a large margin.
More Reliable AI Solution: Breast Ultrasound Diagnosis Using Multi-AI Combination
Jan 07, 2021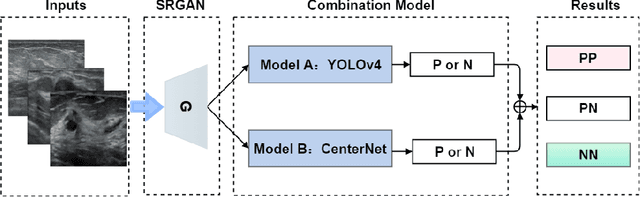
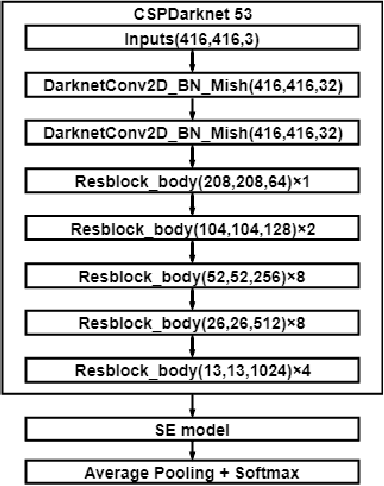

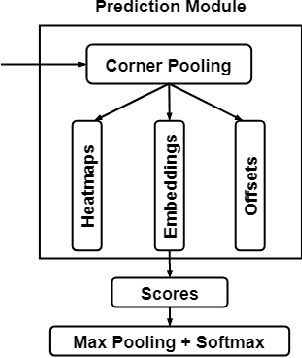
Objective: Breast cancer screening is of great significance in contemporary women's health prevention. The existing machines embedded in the AI system do not reach the accuracy that clinicians hope. How to make intelligent systems more reliable is a common problem. Methods: 1) Ultrasound image super-resolution: the SRGAN super-resolution network reduces the unclearness of ultrasound images caused by the device itself and improves the accuracy and generalization of the detection model. 2) In response to the needs of medical images, we have improved the YOLOv4 and the CenterNet models. 3) Multi-AI model: based on the respective advantages of different AI models, we employ two AI models to determine clinical resuls cross validation. And we accept the same results and refuses others. Results: 1) With the help of the super-resolution model, the YOLOv4 model and the CenterNet model both increased the mAP score by 9.6% and 13.8%. 2) Two methods for transforming the target model into a classification model are proposed. And the unified output is in a specified format to facilitate the call of the molti-AI model. 3) In the classification evaluation experiment, concatenated by the YOLOv4 model (sensitivity 57.73%, specificity 90.08%) and the CenterNet model (sensitivity 62.64%, specificity 92.54%), the multi-AI model will refuse to make judgments on 23.55% of the input data. Correspondingly, the performance has been greatly improved to 95.91% for the sensitivity and 96.02% for the specificity. Conclusion: Our work makes the AI model more reliable in medical image diagnosis. Significance: 1) The proposed method makes the target detection model more suitable for diagnosing breast ultrasound images. 2) It provides a new idea for artificial intelligence in medical diagnosis, which can more conveniently introduce target detection models from other fields to serve medical lesion screening.
Noise2Inpaint: Learning Referenceless Denoising by Inpainting Unrolling
Jun 16, 2020
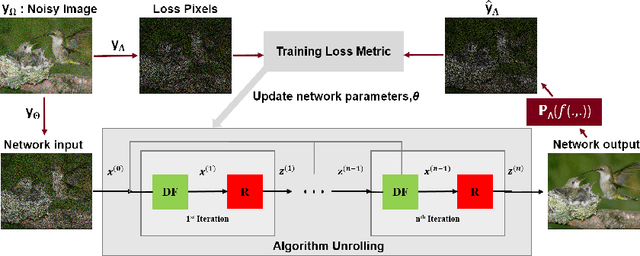


Deep learning based image denoising methods have been recently popular due to their improved performance. Traditionally, these methods are trained in a supervised manner, requiring a set of noisy input and clean target image pairs. More recently, self-supervised approaches have been proposed to learn denoising from noisy images only, without requiring clean ground truth during training. Succinctly, these methods assume that an image pixel is correlated with its neighboring pixels, while the noise is independent. In this work, building on these approaches and recent methods from image reconstruction, we introduce Noise2Inpaint (N2I), a training approach that recasts the denoising problem into a regularized image inpainting framework. This allows us to use an objective function, which can incorporate different statistical properties of the noise as needed. We use algorithm unrolling to unroll an iterative optimization for solving this objective function and train the unrolled network end-to-end. The training is self-supervised without requiring clean target images, where pixels in the noisy image are split into two disjoint sets. One of these is used to impose data fidelity in the unrolled network, while the other one defines the loss. We demonstrate that N2I performs successful denoising on real-world datasets, while preserving better details compared to its self-supervised counterpart Noise2Void.
Generative Collaborative Networks for Single Image Super-Resolution
Mar 12, 2019
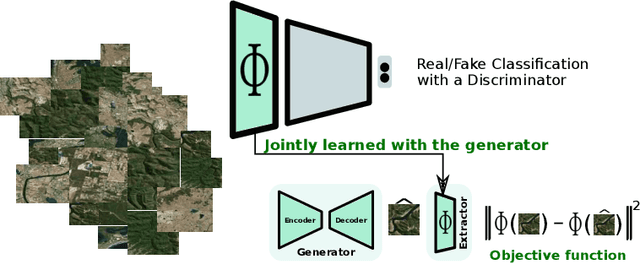
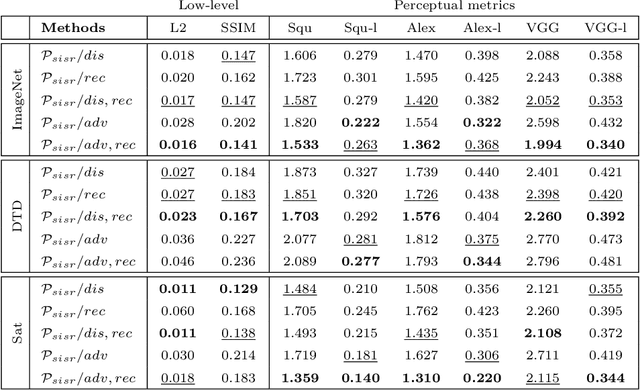
A common issue of deep neural networks-based methods for the problem of Single Image Super-Resolution (SISR), is the recovery of finer texture details when super-resolving at large upscaling factors. This issue is particularly related to the choice of the objective loss function. In particular, recent works proposed the use of a VGG loss which consists in minimizing the error between the generated high resolution images and ground-truth in the feature space of a Convolutional Neural Network (VGG19), pre-trained on the very "large" ImageNet dataset. When considering the problem of super-resolving images with a distribution "far" from the ImageNet images distribution (\textit{e.g.,} satellite images), their proposed \textit{fixed} VGG loss is no longer relevant. In this paper, we present a general framework named \textit{Generative Collaborative Networks} (GCN), where the idea consists in optimizing the \textit{generator} (the mapping of interest) in the feature space of a \textit{features extractor} network. The two networks (generator and extractor) are \textit{collaborative} in the sense that the latter "helps" the former, by constructing discriminative and relevant features (not necessarily \textit{fixed} and possibly learned \textit{mutually} with the generator). We evaluate the GCN framework in the context of SISR, and we show that it results in a method that is adapted to super-resolution domains that are "far" from the ImageNet domain.
Image based cellular contractile force evaluation with small-world network inspired CNN: SW-UNet
Aug 23, 2019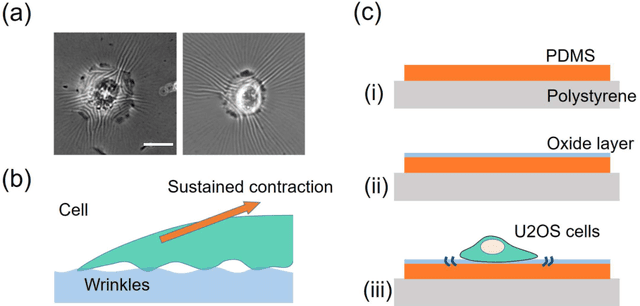
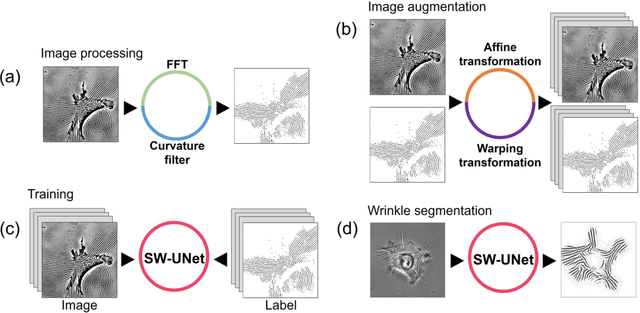
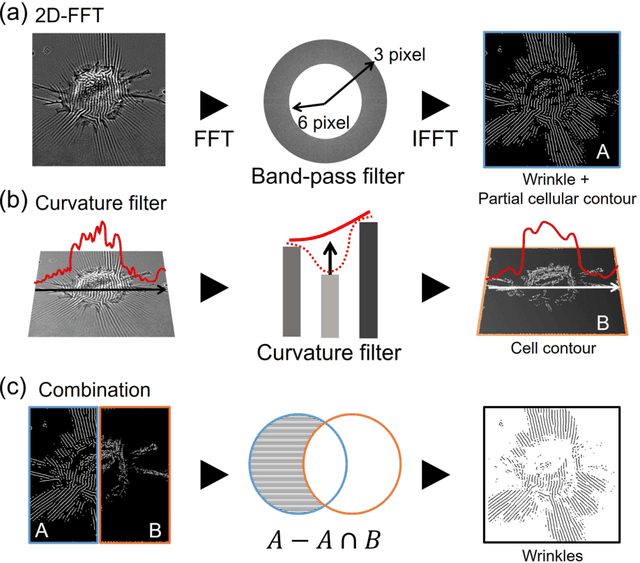
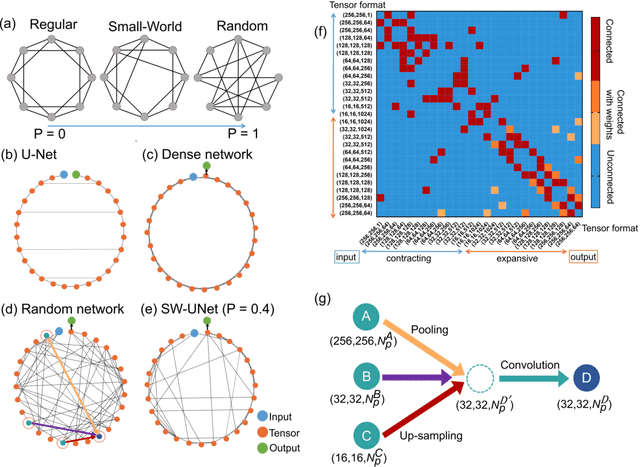
We propose an image-based cellular contractile force evaluation method using a machine learning technique. We use a special substrate that exhibits wrinkles when cells grab the substrate and contract, and the wrinkles can be used to visualize the force magnitude and direction. In order to extract wrinkles from the microscope images, we develop a new CNN (convolutional neural network) architecture SW-UNet (small-world U-Net), which is a CNN that reflects the concept of the small-world network. The SW-UNet shows better performance in wrinkle segmentation task compared to other methods: the error (Euclidean distance) of SW-UNet is 4.9 times smaller than 2D-FFT (fast Fourier transform) based segmentation approach, and is 2.9 times smaller than U-Net. As a demonstration, we compare the contractile force of U2OS (human osteosarcoma) cells and show that cells with a mutation in the KRAS oncogne show larger force compared to the wild-type cells. Our new machine learning based algorithm provides us an efficient, automated and accurate method to evaluate the cell contractile force.
Efficient Near-Field Imaging Using Cylindrical MIMO Arrays
Jan 22, 2021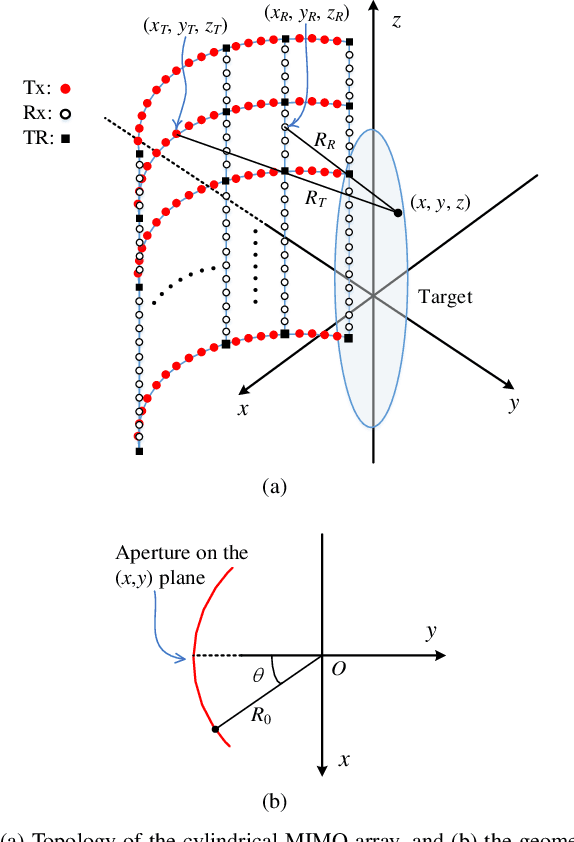
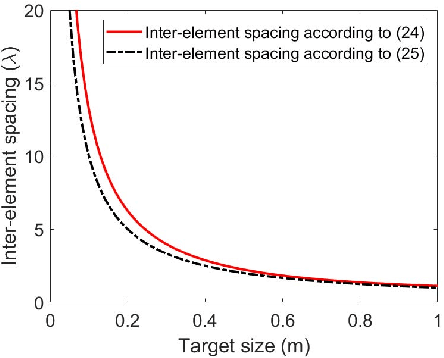
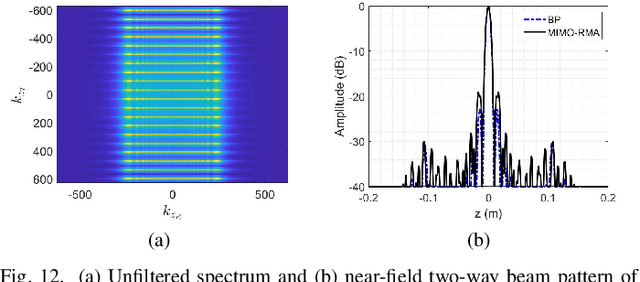
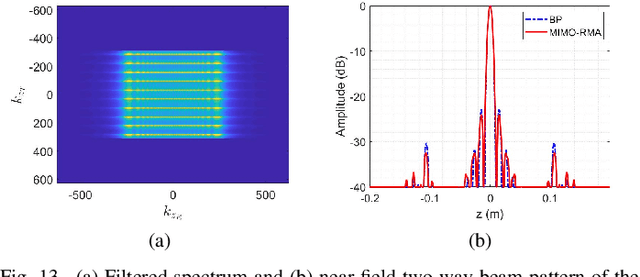
Multiple-input multiple-output (MIMO) array based millimeter-wave (MMW) imaging has a tangible prospect in applications of concealed weapons detection. A near-field imaging algorithm based on wavenumber domain processing is proposed for a cylindrical MIMO array scheme with uniformly spaced transmit and receive antennas over both the vertical and horizontal-arc directions. The spectrum aliasing associated with the proposed MIMO array is analyzed through a zero-filling discrete-time Fourier transform. The analysis shows that an undersampled array can be used in recovering the MMW image by a wavenumber domain algorithm. The requirements for the antenna inter-element spacing of the MIMO array are delineated. Numerical simulations as well as comparisons with the backprojection (BP) algorithm are provided to demonstrate the effectiveness of the proposed method.
Spatial Attention Point Network for Deep-learning-based Robust Autonomous Robot Motion Generation
Mar 02, 2021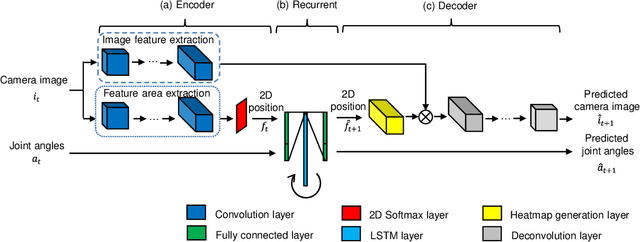
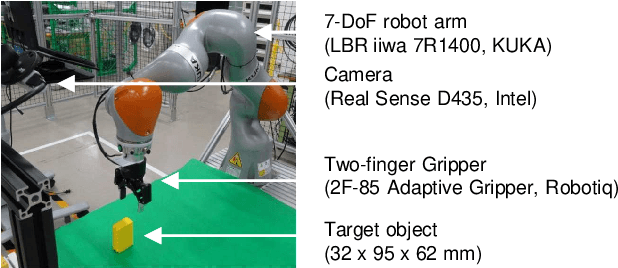
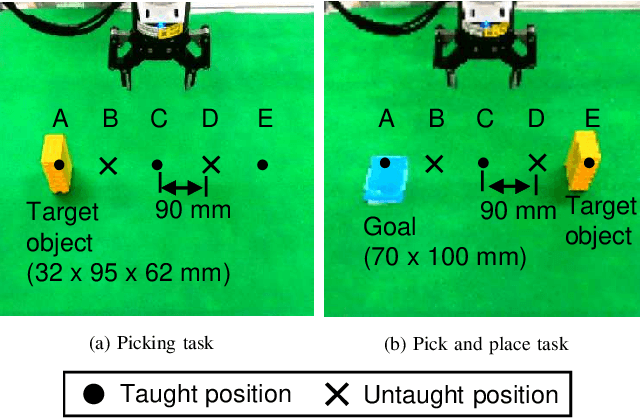

Deep learning provides a powerful framework for automated acquisition of complex robotic motions. However, despite a certain degree of generalization, the need for vast amounts of training data depending on the work-object position is an obstacle to industrial applications. Therefore, a robot motion-generation model that can respond to a variety of work-object positions with a small amount of training data is necessary. In this paper, we propose a method robust to changes in object position by automatically extracting spatial attention points in the image for the robot task and generating motions on the basis of their positions. We demonstrate our method with an LBR iiwa 7R1400 robot arm on a picking task and a pick-and-place task at various positions in various situations. In each task, the spatial attention points are obtained for the work objects that are important to the task. Our method is robust to changes in object position. Further, it is robust to changes in background, lighting, and obstacles that are not important to the task because it only focuses on positions that are important to the task.
An Objective Evaluation Metric for image fusion based on Del Operator
May 19, 2019
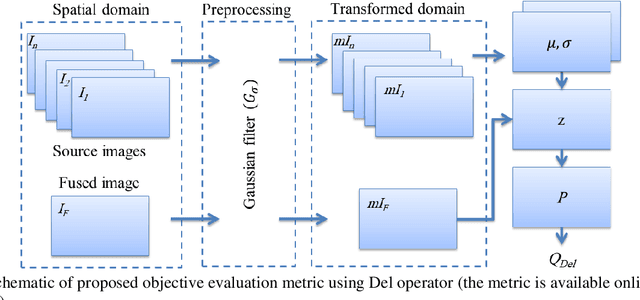
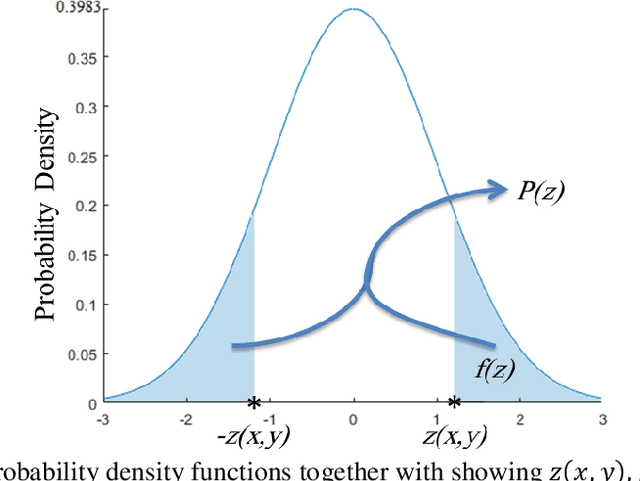
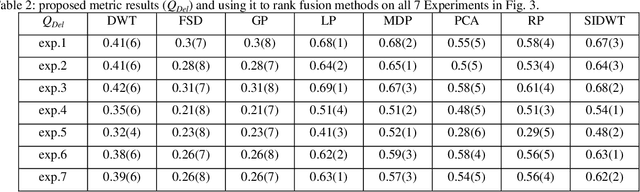
In this paper, a novel objective evaluation metric for image fusion is presented. Remarkable and attractive points of the proposed metric are that it has no parameter, the result is probability in the range of [0, 1] and it is free from illumination dependence. This metric is easy to implement and the result is computed in four steps: (1) Smoothing the images using Gaussian filter. (2) Transforming images to a vector field using Del operator. (3) Computing the normal distribution function ({\mu},{\sigma}) for each corresponding pixel, and converting to the standard normal distribution function. (4) Computing the probability of being well-behaved fusion method as the result. To judge the quality of the proposed metric, it is compared to thirteen well-known non-reference objective evaluation metrics, where eight fusion methods are employed on seven experiments of multimodal medical images. The experimental results and statistical comparisons show that in contrast to the previously objective evaluation metrics the proposed one performs better in terms of both agreeing with human visual perception and evaluating fusion methods that are not performed at the same level.
Face Morphing Attack Generation & Detection: A Comprehensive Survey
Nov 03, 2020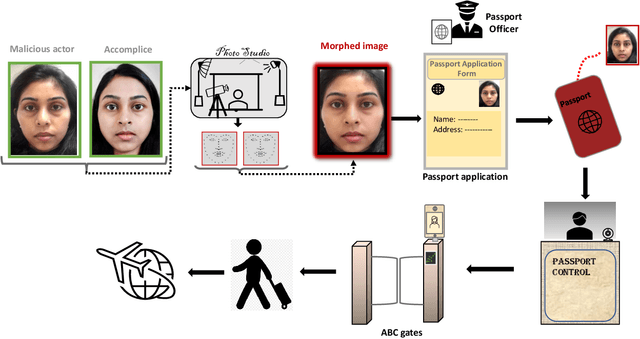

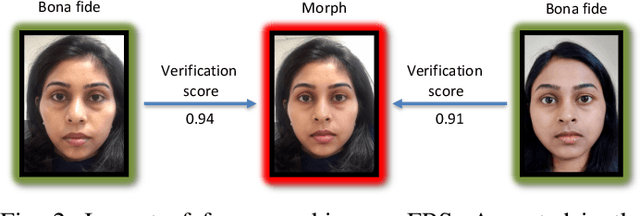
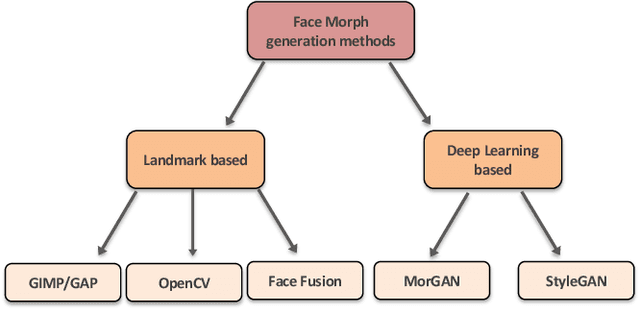
The vulnerability of Face Recognition System (FRS) to various kind of attacks (both direct and in-direct attacks) and face morphing attacks has received a great interest from the biometric community. The goal of a morphing attack is to subvert the FRS at Automatic Border Control (ABC) gates by presenting the Electronic Machine Readable Travel Document (eMRTD) or e-passport that is obtained based on the morphed face image. Since the application process for the e-passport in the majority countries requires a passport photo to be presented by the applicant, a malicious actor and the accomplice can generate the morphed face image and to obtain the e-passport. An e-passport with a morphed face images can be used by both the malicious actor and the accomplice to cross the border as the morphed face image can be verified against both of them. This can result in a significant threat as a malicious actor can cross the border without revealing the track of his/her criminal background while the details of accomplice are recorded in the log of the access control system. This survey aims to present a systematic overview of the progress made in the area of face morphing in terms of both morph generation and morph detection. In this paper, we describe and illustrate various aspects of face morphing attacks, including different techniques for generating morphed face images but also the state-of-the-art regarding Morph Attack Detection (MAD) algorithms based on a stringent taxonomy and finally the availability of public databases, which allow to benchmark new MAD algorithms in a reproducible manner. The outcomes of competitions/benchmarking, vulnerability assessments and performance evaluation metrics are also provided in a comprehensive manner. Furthermore, we discuss the open challenges and potential future works that need to be addressed in this evolving field of biometrics.
FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding
Dec 05, 2020
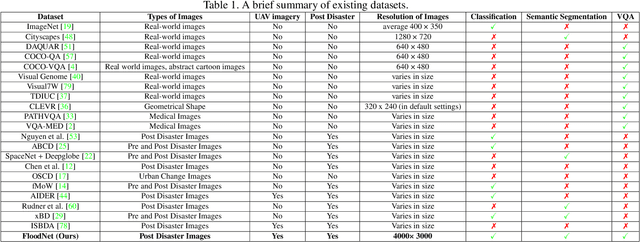
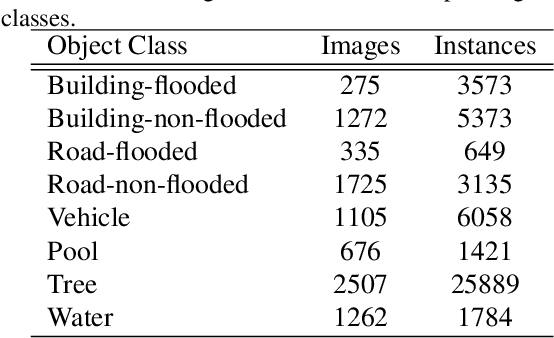
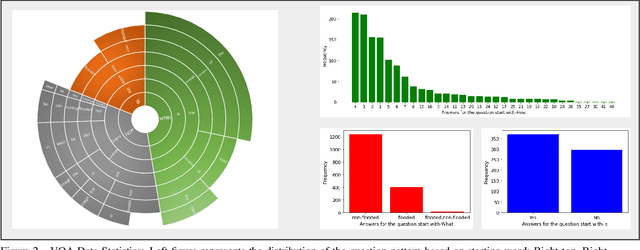
Visual scene understanding is the core task in making any crucial decision in any computer vision system. Although popular computer vision datasets like Cityscapes, MS-COCO, PASCAL provide good benchmarks for several tasks (e.g. image classification, segmentation, object detection), these datasets are hardly suitable for post disaster damage assessments. On the other hand, existing natural disaster datasets include mainly satellite imagery which have low spatial resolution and a high revisit period. Therefore, they do not have a scope to provide quick and efficient damage assessment tasks. Unmanned Aerial Vehicle(UAV) can effortlessly access difficult places during any disaster and collect high resolution imagery that is required for aforementioned tasks of computer vision. To address these issues we present a high resolution UAV imagery, FloodNet, captured after the hurricane Harvey. This dataset demonstrates the post flooded damages of the affected areas. The images are labeled pixel-wise for semantic segmentation task and questions are produced for the task of visual question answering. FloodNet poses several challenges including detection of flooded roads and buildings and distinguishing between natural water and flooded water. With the advancement of deep learning algorithms, we can analyze the impact of any disaster which can make a precise understanding of the affected areas. In this paper, we compare and contrast the performances of baseline methods for image classification, semantic segmentation, and visual question answering on our dataset.