 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiple-Identity Image Attacks Against Face-based Identity Verification
Jun 20, 2019


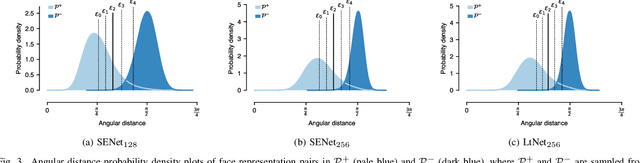
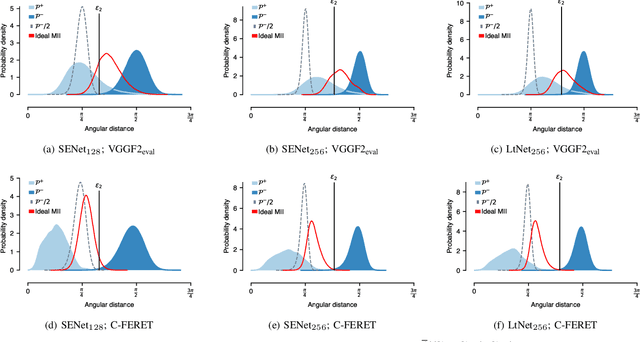
Facial verification systems are vulnerable to poisoning attacks that make use of multiple-identity images (MIIs)---face images stored in a database that resemble multiple persons, such that novel images of any of the constituent persons are verified as matching the identity of the MII. Research on this mode of attack has focused on defence by detection, with no explanation as to why the vulnerability exists. New quantitative results are presented that support an explanation in terms of the geometry of the representations spaces used by the verification systems. In the spherical geometry of those spaces, the angular distance distributions of matching and non-matching pairs of face representations are only modestly separated, approximately centred at 90 and 40-60 degrees, respectively. This is sufficient for open-set verification on normal data but provides an opportunity for MII attacks. Our analysis considers ideal MII algorithms, demonstrating that, if realisable, they would deliver faces roughly 45 degrees from their constituent faces, thus classed as matching them. We study the performance of three methods for MII generation---gallery search, image space morphing, and representation space inversion---and show that the latter two realise the ideal well enough to produce effective attacks, while the former could succeed but only with an implausibly large gallery to search. Gallery search and inversion MIIs depend on having access to a facial comparator, for optimisation, but our results show that these attacks can still be effective when attacking disparate comparators, thus securing a deployed comparator is an insufficient defence.
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
Mar 13, 2021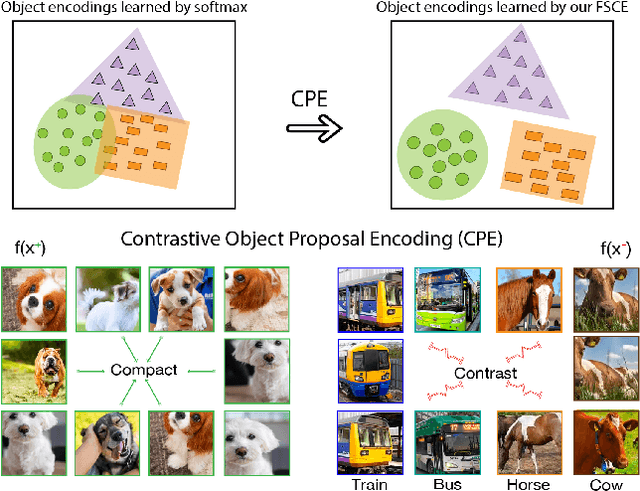



Emerging interests have been brought to recognize previously unseen objects given very few training examples, known as few-shot object detection (FSOD). Recent researches demonstrate that good feature embedding is the key to reach favorable few-shot learning performance. We observe object proposals with different Intersection-of-Union (IoU) scores are analogous to the intra-image augmentation used in contrastive approaches. And we exploit this analogy and incorporate supervised contrastive learning to achieve more robust objects representations in FSOD. We present Few-Shot object detection via Contrastive proposals Encoding (FSCE), a simple yet effective approach to learning contrastive-aware object proposal encodings that facilitate the classification of detected objects. We notice the degradation of average precision (AP) for rare objects mainly comes from misclassifying novel instances as confusable classes. And we ease the misclassification issues by promoting instance level intra-class compactness and inter-class variance via our contrastive proposal encoding loss (CPE loss). Our design outperforms current state-of-the-art works in any shot and all data splits, with up to +8.8% on standard benchmark PASCAL VOC and +2.7% on challenging COCO benchmark. Code is available at: https: //github.com/MegviiDetection/FSCE
Metrics for Exposing the Biases of Content-Style Disentanglement
Aug 31, 2020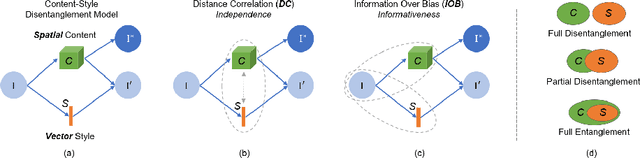
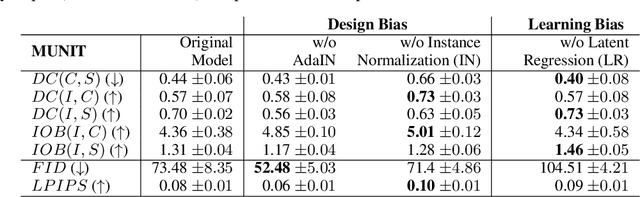
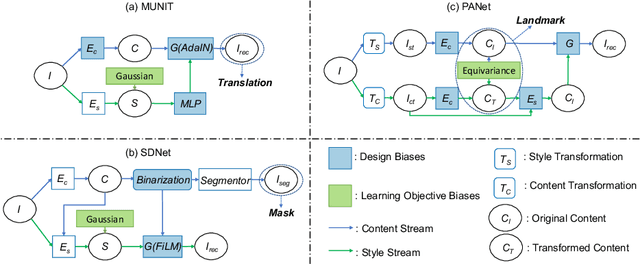
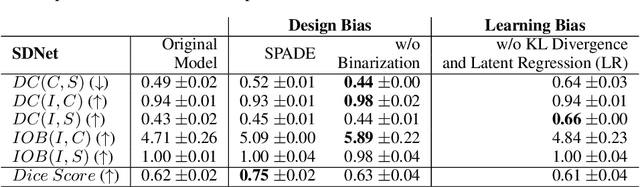
Recent state-of-the-art semi- and un-supervised solutions for challenging computer vision tasks have used the idea of encoding image content into a spatial tensor and image appearance or "style" into a vector. These decomposed representations take advantage of equivariant properties of network design and improve performance in equivariant tasks, such as image-to-image translation. Most of these methods use the term "disentangled" for their representations and employ model design, learning objectives, and data biases to achieve good model performance. While considerable effort has been made to measure disentanglement in vector representations, currently, metrics that can characterize the degree of disentanglement between content (spatial) and style (vector) representations and the relation to task performance are lacking. In this paper, we propose metrics to measure how (un)correlated, biased, and informative the content and style representations are. In particular, we first identify key design choices and learning constraints on three popular models that employ content-style disentanglement and derive ablated versions. Then, we use our metrics to ascertain the role of each bias. Our experiments reveal a "sweet-spot" between disentanglement, task performance and latent space interpretability. The proposed metrics enable the design of better models and the selection of models that achieve the desired performance and disentanglement. Our metrics library is available at https://github.com/TsaftarisCollaboratory/CSDisentanglement_Metrics_Library.
Learning Product Codebooks using Vector Quantized Autoencoders for Image Retrieval
Jul 19, 2018
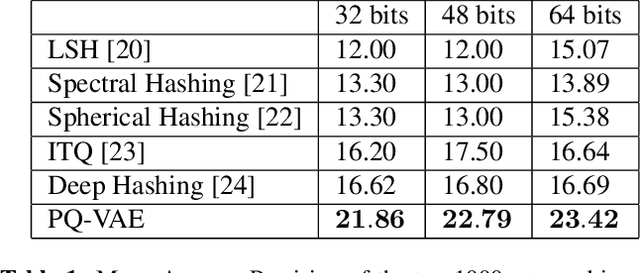
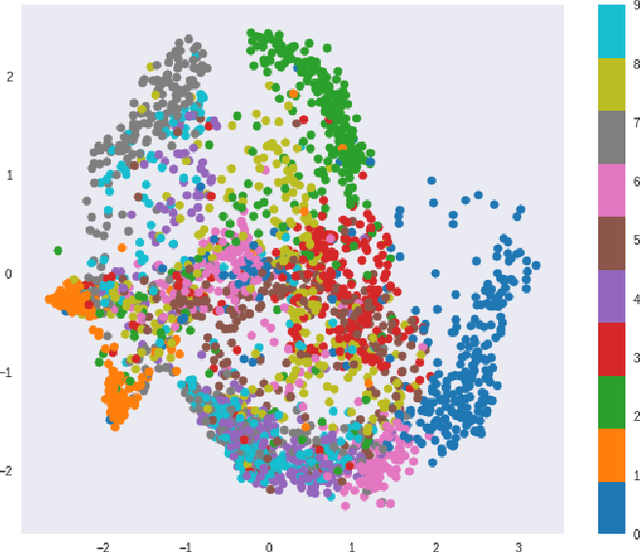
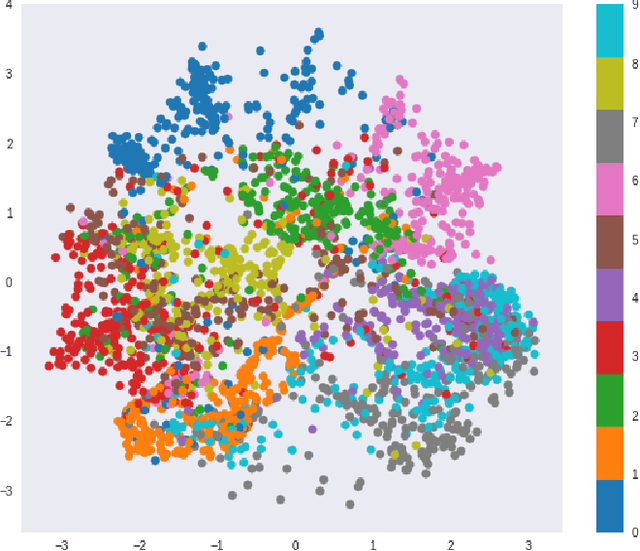
The Vector Quantized-Variational Autoencoder (VQ-VAE) [1] provides an unsupervised model for learning discrete representations by combining vector quantization and autoencoders. The VQ-VAE can avoid the issue of "posterior collapse" so that its learned discrete representation is meaningful. In this paper, we incorporate the product quantization into the bottleneck stage of VQ-VAE and propose an end-to-end unsupervised learning model for the image retrieval tasks. Compared to the classic vector quantization, product quantization has the advantage of generating large size codebook and fast retrieval can be achieved by using the lookup tables that store the distance between every two sub-codewords. In our proposed model, the product codebook is jointly learned with the encoders and decoders of the autoencoders. The encodings of query and database images can be generated by feeding the images into the trained encoder and learned product codebook. The experiment shows that our proposed model outperforms other state-of-the-art hashing and quantization methods for the image retrieval task.
Efficient Sparse Coding using Hierarchical Riemannian Pursuit
Apr 21, 2021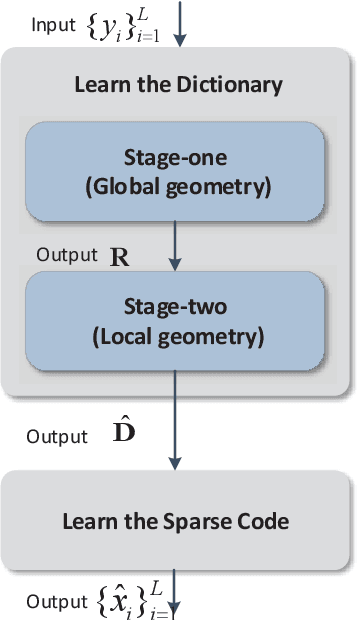
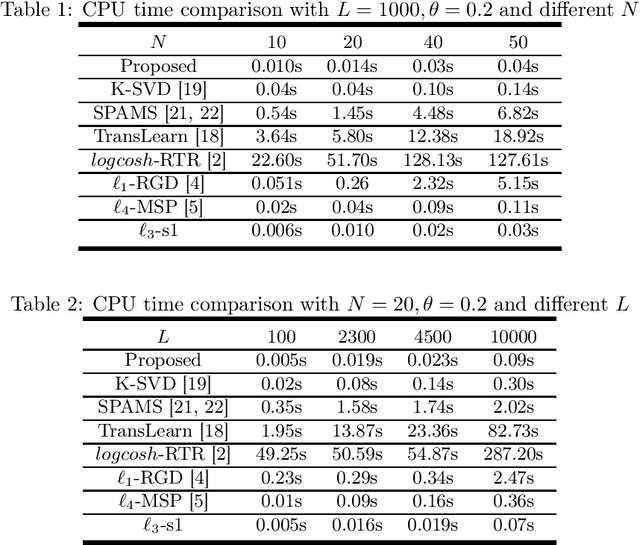
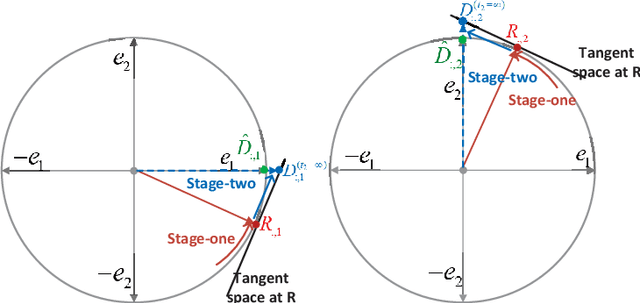
Sparse coding is a class of unsupervised methods for learning a sparse representation of the input data in the form of a linear combination of a dictionary and a sparse code. This learning framework has led to state-of-the-art results in various image and video processing tasks. However, classical methods learn the dictionary and the sparse code based on alternative optimizations, usually without theoretical guarantees for either optimality or convergence due to non-convexity of the problem. Recent works on sparse coding with a complete dictionary provide strong theoretical guarantees thanks to the development of the non-convex optimization. However, initial non-convex approaches learn the dictionary in the sparse coding problem sequentially in an atom-by-atom manner, which leads to a long execution time. More recent works seek to directly learn the entire dictionary at once, which substantially reduces the execution time. However, the associated recovery performance is degraded with a finite number of data samples. In this paper, we propose an efficient sparse coding scheme with a two-stage optimization. The proposed scheme leverages the global and local Riemannian geometry of the two-stage optimization problem and facilitates fast implementation for superb dictionary recovery performance by a finite number of samples without atom-by-atom calculation. We further prove that, with high probability, the proposed scheme can exactly recover any atom in the target dictionary with a finite number of samples if it is adopted to recover one atom of the dictionary. An application on wireless sensor data compression is also proposed. Experiments on both synthetic and real-world data verify the efficiency and effectiveness of the proposed scheme.
Simultaneous Denoising and Motion Estimation for Low-dose Gated PET using a Siamese Adversarial Network with Gate-to-Gate Consistency Learning
Sep 14, 2020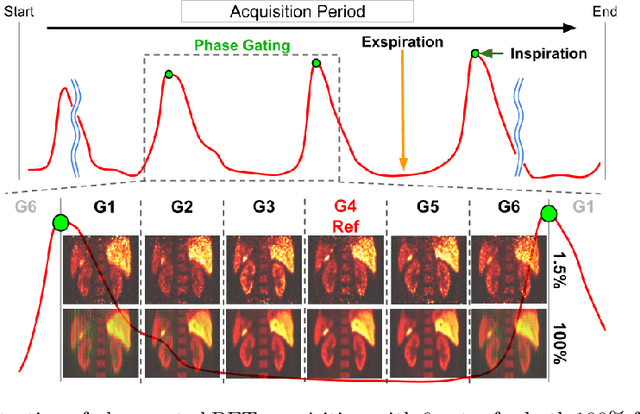
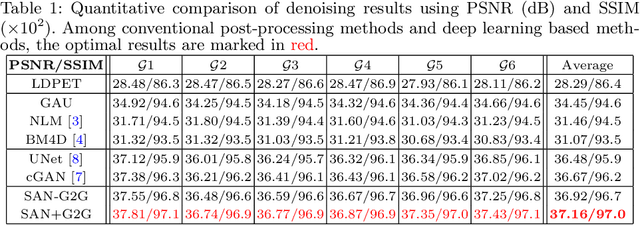
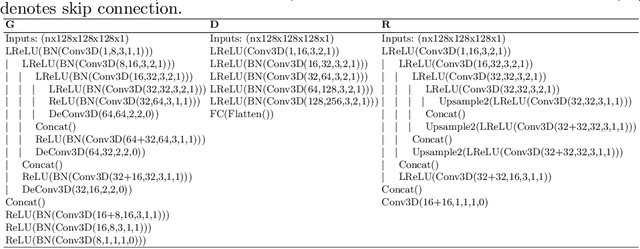
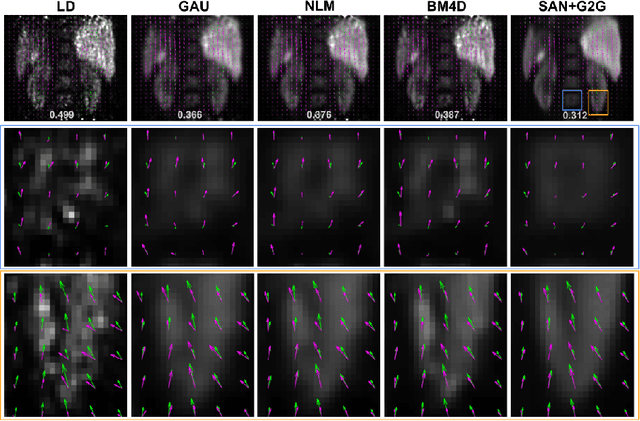
Gating is commonly used in PET imaging to reduce respiratory motion blurring and facilitate more sophisticated motion correction methods. In the applications of low dose PET, however, reducing injection dose causes increased noise and reduces signal-to-noise ratio (SNR), subsequently corrupting the motion estimation/correction steps, causing inferior image quality. To tackle these issues, we first propose a Siamese adversarial network (SAN) that can efficiently recover high dose gated image volume from low dose gated image volume. To ensure the appearance consistency between the recovered gated volumes, we then utilize a pre-trained motion estimation network incorporated into SAN that enables the constraint of gate-to-gate (G2G) consistency. With high-quality recovered gated volumes, gate-to-gate motion vectors can be simultaneously outputted from the motion estimation network. Comprehensive evaluations on a low dose gated PET dataset of 29 subjects demonstrate that our method can effectively recover the low dose gated PET volumes, with an average PSNR of 37.16 and SSIM of 0.97, and simultaneously generate robust motion estimation that could benefit subsequent motion corrections.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 20, 2021

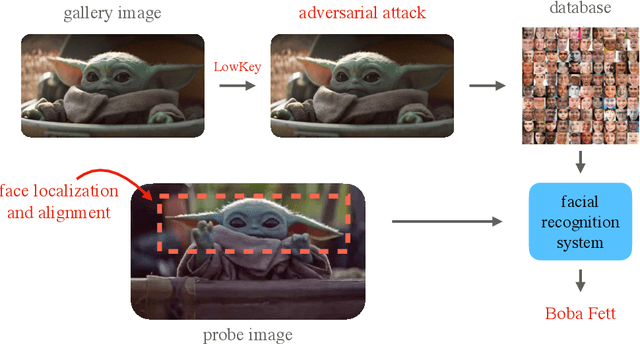
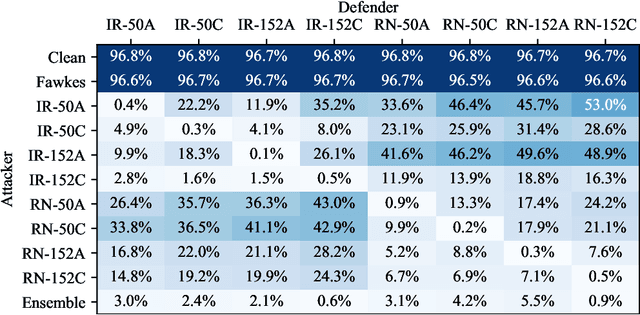
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%
Depth as Attention for Face Representation Learning
Jan 03, 2021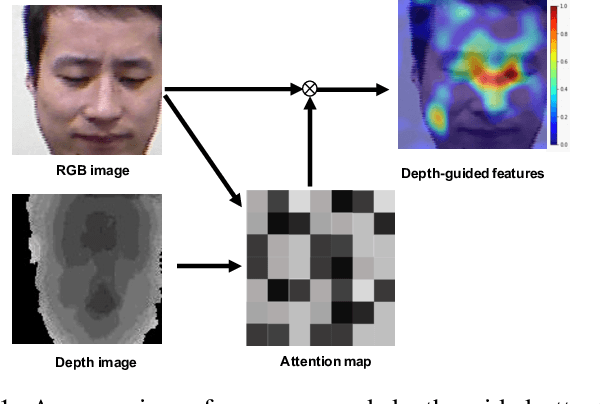
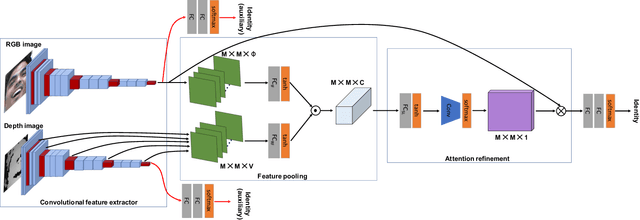
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN
Nov 05, 2020



We present an invert-and-edit framework to automatically transform facial weight of an input face image to look thinner or heavier by leveraging semantic facial attributes encoded in the latent space of Generative Adversarial Networks (GANs). Using a pre-trained StyleGAN as the underlying generator, we first employ an optimization-based embedding method to invert the input image into the StyleGAN latent space. Then, we identify the facial-weight attribute direction in the latent space via supervised learning and edit the inverted latent code by moving it positively or negatively along the extracted feature axis. Our framework is empirically shown to produce high-quality and realistic facial-weight transformations without requiring training GANs with a large amount of labeled face images from scratch. Ultimately, our framework can be utilized as part of an intervention to motivate individuals to make healthier food choices by visualizing the future impacts of their behavior on appearance.
Locally Masked Convolution for Autoregressive Models
Jun 27, 2020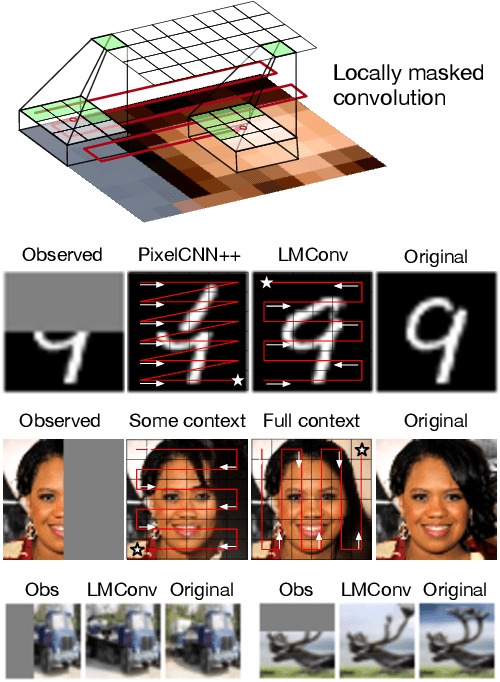
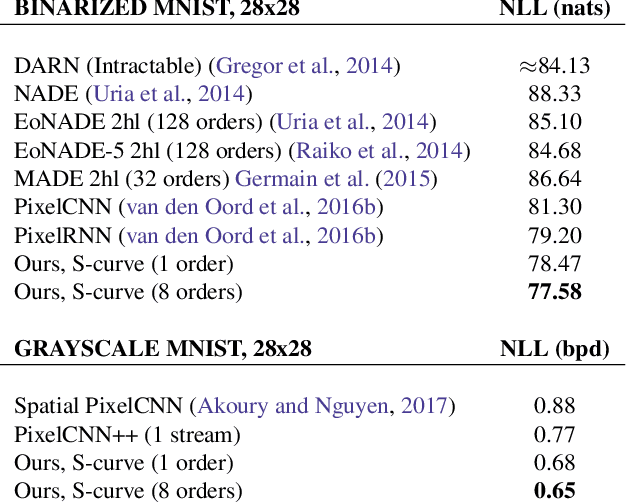
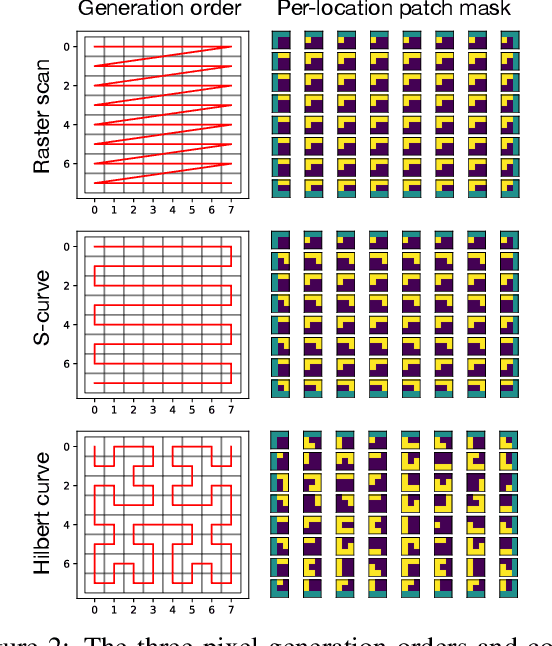

High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions. Our code is available at https://ajayjain.github.io/lmconv.