 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-frame image super-resolution with fast upscaling technique
Oct 13, 2017
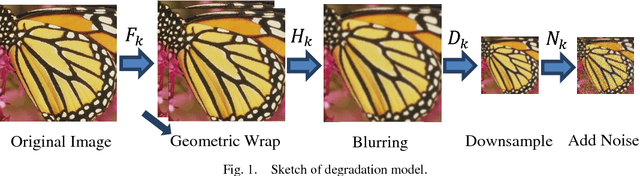



Multi-frame image super-resolution (MISR) aims to fuse information in low-resolution (LR) image sequence to compose a high-resolution (HR) one, which is applied extensively in many areas recently. Different with single image super-resolution (SISR), sub-pixel transitions between multiple frames introduce additional information, attaching more significance to fusion operator to alleviate the ill-posedness of MISR. For reconstruction-based approaches, the inevitable projection of reconstruction errors from LR space to HR space is commonly tackled by an interpolation operator, however crude interpolation may not fit the natural image and generate annoying blurring artifacts, especially after fusion operator. In this paper, we propose an end-to-end fast upscaling technique to replace the interpolation operator, design upscaling filters in LR space for periodic sub-locations respectively and shuffle the filter results to derive the final reconstruction errors in HR space. The proposed fast upscaling technique not only reduce the computational complexity of the upscaling operation by utilizing shuffling operation to avoid complex operation in HR space, but also realize superior performance with fewer blurring artifacts. Extensive experimental results demonstrate the effectiveness and efficiency of the proposed technique, whilst, combining the proposed technique with bilateral total variation (BTV) regu-larization, the MISR approach outperforms state-of-the-art methods.
CORE: Color Regression for Multiple Colors Fashion Garments
Oct 06, 2020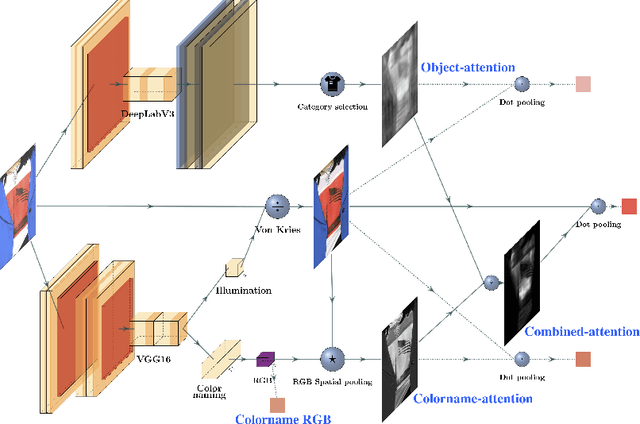

Among all fashion attributes, color is challenging to detect due to its subjective perception. Existing classification approaches can not go beyond the predefined list of discrete color names. In this paper, we argue that color detection is a regression problem. Thus, we propose a new architecture, based on attention modules and in two-stages. The first stage corrects the image illumination while detecting the main discrete color name. The second stage combines a colorname-attention (dependent of the detected color) with an object-attention (dependent of the clothing category) and finally weights a spatial pooling over the image pixels' RGB values. We further expand our work for multiple colors garments. We collect a dataset where each fashion item is labeled with a continuous color palette: we empirically show the benefits of our approach.
Efficient Neural Architecture Search on Low-Dimensional Data for OCT Image Segmentation
May 07, 2019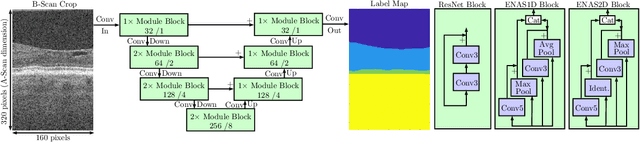
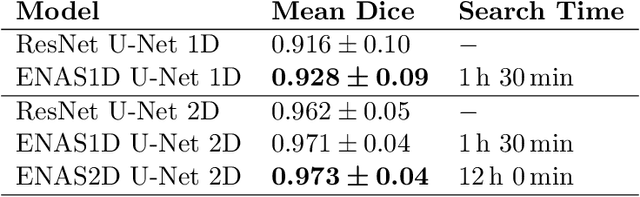
Typically, deep learning architectures are handcrafted for their respective learning problem. As an alternative, neural architecture search (NAS) has been proposed where the architecture's structure is learned in an additional optimization step. For the medical imaging domain, this approach is very promising as there are diverse problems and imaging modalities that require architecture design. However, NAS is very time-consuming and medical learning problems often involve high-dimensional data with high computational requirements. We propose an efficient approach for NAS in the context of medical, image-based deep learning problems by searching for architectures on low-dimensional data which are subsequently transferred to high-dimensional data. For OCT-based layer segmentation, we demonstrate that a search on 1D data reduces search time by 87.5% compared to a search on 2D data while the final 2D models achieve similar performance.
A Study of Human Gaze Behavior During Visual Crowd Counting
Sep 14, 2020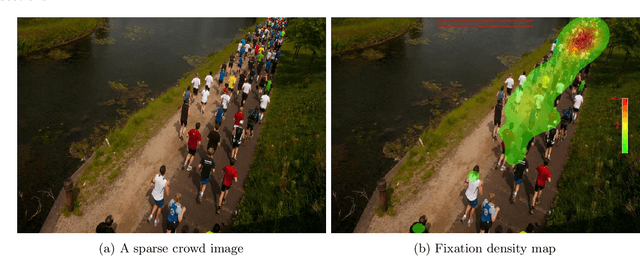
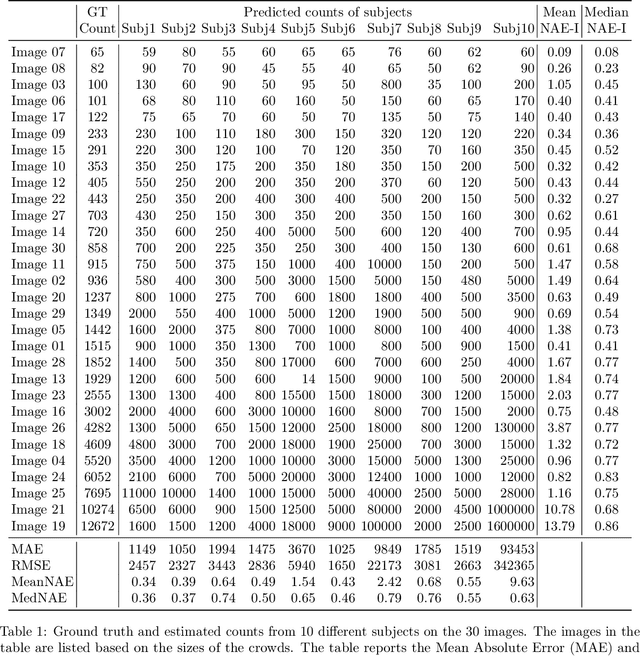

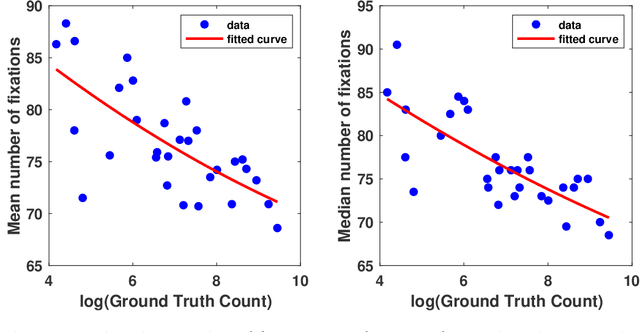
In this paper, we describe our study on how humans allocate their attention during visual crowd counting. Using an eye tracker, we collect gaze behavior of human participants who are tasked with counting the number of people in crowd images. Analyzing the collected gaze behavior of ten human participants on thirty crowd images, we observe some common approaches for visual counting. For an image of a small crowd, the approach is to enumerate over all people or groups of people in the crowd, and this explains the high level of similarity between the fixation density maps of different human participants. For an image of a large crowd, our participants tend to focus on one section of the image, count the number of people in that section, and then extrapolate to the other sections. In terms of count accuracy, our human participants are not as good at the counting task, compared to the performance of the current state-of-the-art computer algorithms. Interestingly, there is a tendency to under count the number of people in all crowd images. Gaze behavior data and images can be downloaded from https://www3.cs.stonybrook.edu/~cvl/projects/crowd_counting_gaze/
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021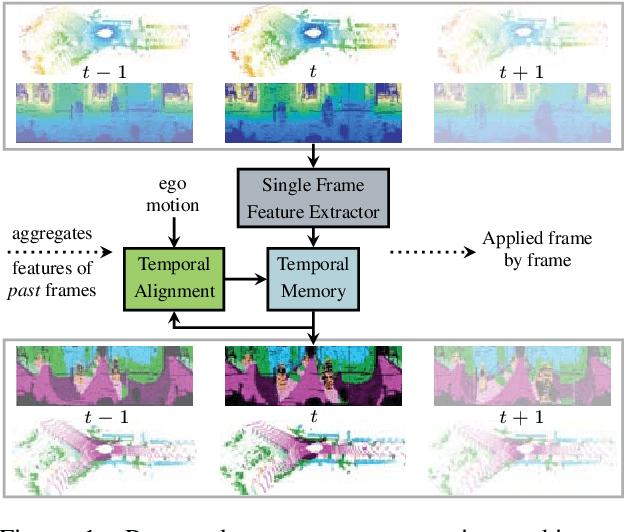
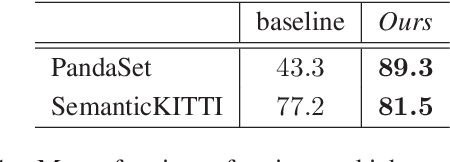
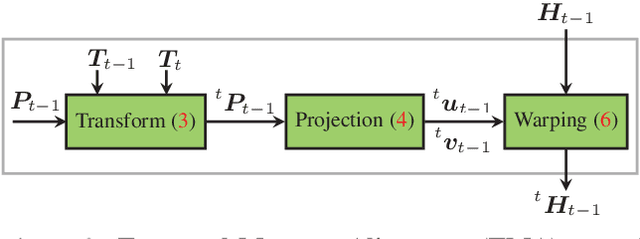
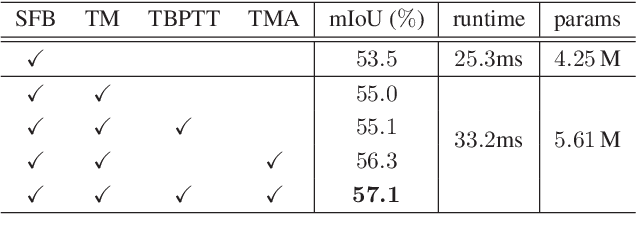
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
Computational efficient deep neural network with difference attention maps for facial action unit detection
Nov 27, 2020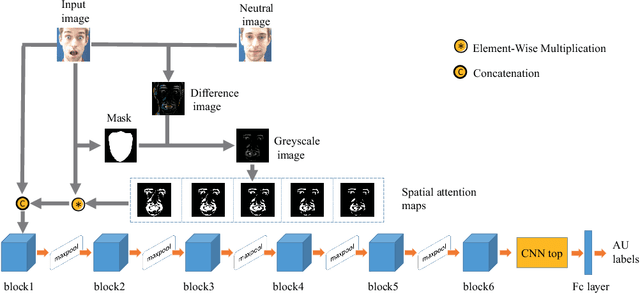


In this paper, we propose a computational efficient end-to-end training deep neural network (CEDNN) model and spatial attention maps based on difference images. Firstly, the difference image is generated by image processing. Then five binary images of difference images are obtained using different thresholds, which are used as spatial attention maps. We use group convolution to reduce model complexity. Skip connection and $\text{1}\times \text{1}$ convolution are used to ensure good performance even if the network model is not deep. As an input, spatial attention map can be selectively fed into the input of each block. The feature maps tend to focus on the parts that are related to the target task better. In addition, we only need to adjust the parameters of classifier to train different numbers of AU. It can be easily extended to varying datasets without increasing too much computation. A large number of experimental results show that the proposed CEDNN is obviously better than the traditional deep learning method on DISFA+ and CK+ datasets. After adding spatial attention maps, the result is better than the most advanced AU detection method. At the same time, the scale of the network is small, the running speed is fast, and the requirement for experimental equipment is low.
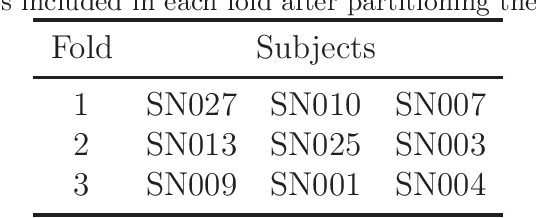
Wearable Sensors for Spatio-Temporal Grip Force Profiling
Jan 16, 2021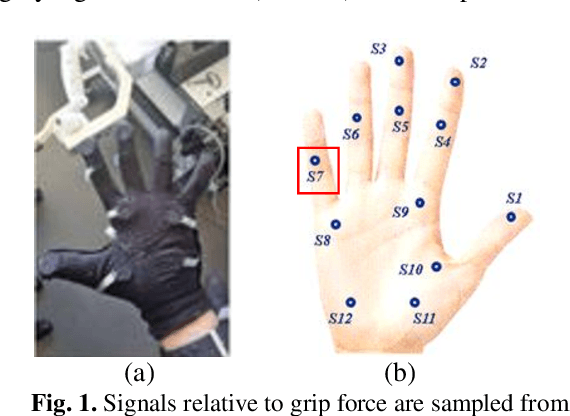
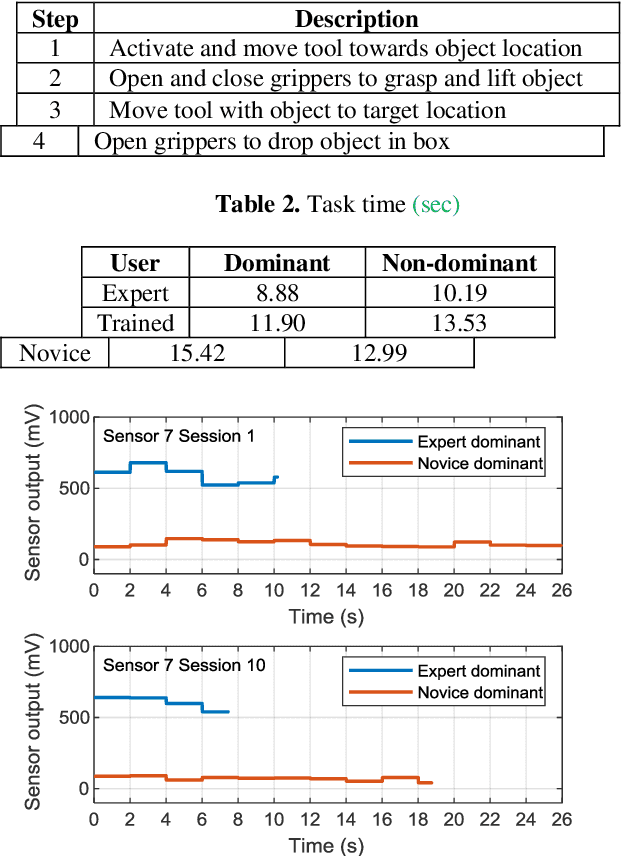
Wearable biosensor technology enables real-time, convenient, and continuous monitoring of users behavioral signals. Such include signals relative to body motion, body temperature, biological or biochemical markers, and individual grip forces, which are studied in this paper. A four step pick and drop image guided and robot assisted precision task has been designed for exploiting a wearable wireless sensor glove system. Individual spatio temporal grip forces are analyzed on the basis of thousands of individual sensor data, collected from different locations on the dominant and non-dominant hands of each of three users in ten successive task sessions. Statistical comparisons reveal specific differences between grip force profiles of the individual users as a function of task skill level (expertise) and time.
Deep Depth Completion of a Single RGB-D Image
May 02, 2018

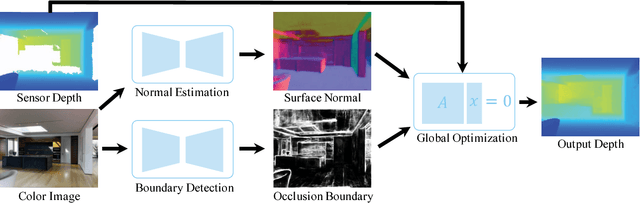
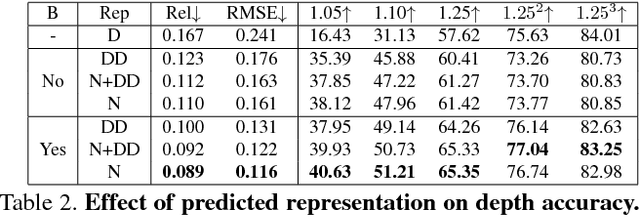
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions, optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.
Do Not Mask What You Do Not Need to Mask: a Parser-Free Virtual Try-On
Jul 03, 2020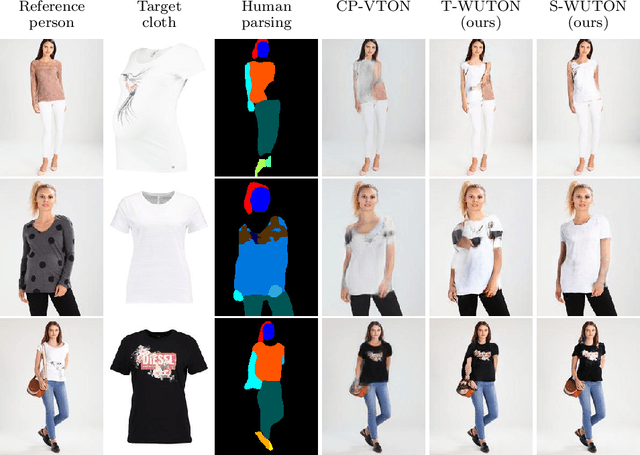
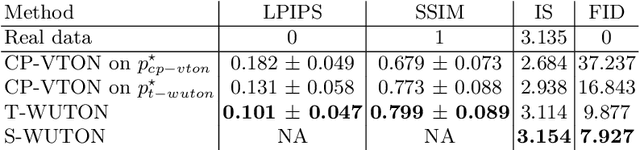
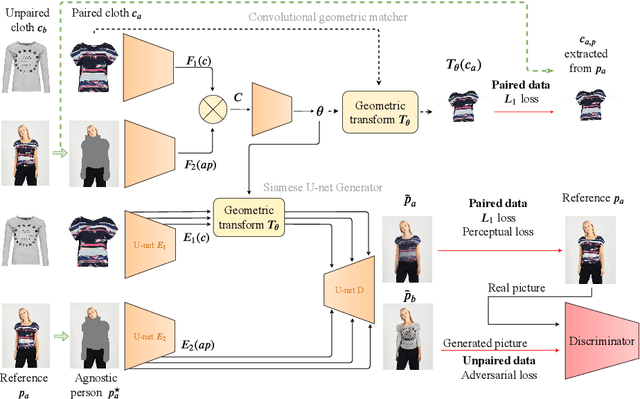

The 2D virtual try-on task has recently attracted a great interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires fitting an in-shop cloth image on the image of a person, which is highly challenging because it involves cloth warping, image compositing, and synthesizing. Casting virtual try-on into a supervised task faces a difficulty: available datasets are composed of pairs of pictures (cloth, person wearing the cloth). Thus, we have no access to ground-truth when the cloth on the person changes. State-of-the-art models solve this by masking the cloth information on the person with both a human parser and a pose estimator. Then, image synthesis modules are trained to reconstruct the person image from the masked person image and the cloth image. This procedure has several caveats: firstly, human parsers are prone to errors; secondly, it is a costly pre-processing step, which also has to be applied at inference time; finally, it makes the task harder than it is since the mask covers information that should be kept such as hands or accessories. In this paper, we propose a novel student-teacher paradigm where the teacher is trained in the standard way (reconstruction) before guiding the student to focus on the initial task (changing the cloth). The student additionally learns from an adversarial loss, which pushes it to follow the distribution of the real images. Consequently, the student exploits information that is masked to the teacher. A student trained without the adversarial loss would not use this information. Also, getting rid of both human parser and pose estimator at inference time allows obtaining a real-time virtual try-on.
Searching for Alignment in Face Recognition
Feb 10, 2021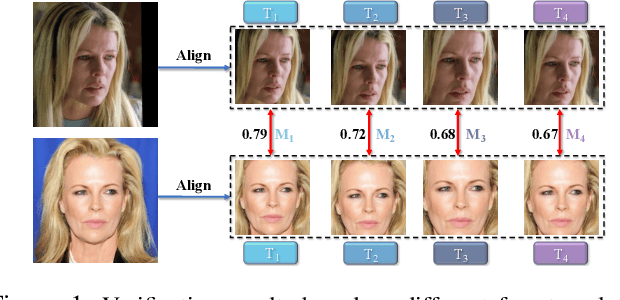
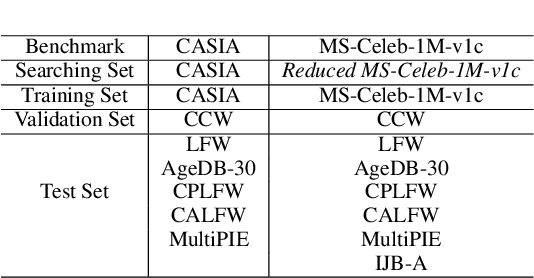
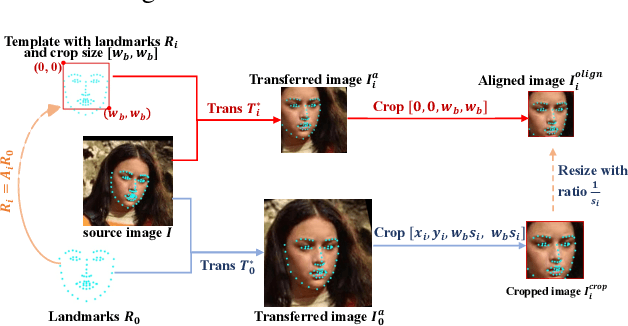
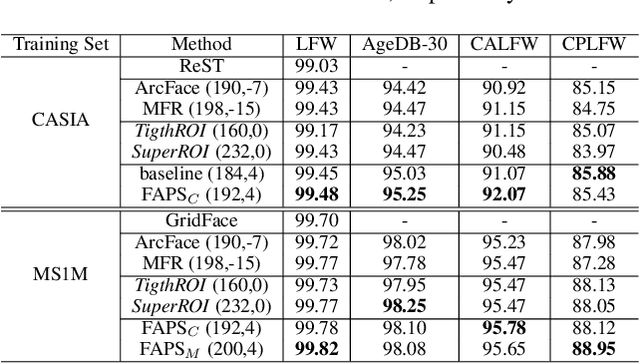
A standard pipeline of current face recognition frameworks consists of four individual steps: locating a face with a rough bounding box and several fiducial landmarks, aligning the face image using a pre-defined template, extracting representations and comparing. Among them, face detection, landmark detection and representation learning have long been studied and a lot of works have been proposed. As an essential step with a significant impact on recognition performance, the alignment step has attracted little attention. In this paper, we first explore and highlight the effects of different alignment templates on face recognition. Then, for the first time, we try to search for the optimal template automatically. We construct a well-defined searching space by decomposing the template searching into the crop size and vertical shift, and propose an efficient method Face Alignment Policy Search (FAPS). Besides, a well-designed benchmark is proposed to evaluate the searched policy. Experiments on our proposed benchmark validate the effectiveness of our method to improve face recognition performance.