 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Contrastive Divergence Training of Energy Based Models
Dec 17, 2020


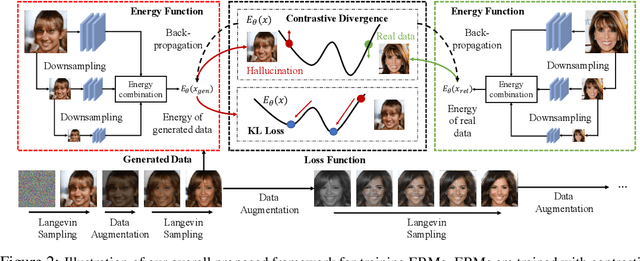

We propose several different techniques to improve contrastive divergence training of energy-based models (EBMs). We first show that a gradient term neglected in the popular contrastive divergence formulation is both tractable to estimate and is important to avoid training instabilities in previous models. We further highlight how data augmentation, multi-scale processing, and reservoir sampling can be used to improve model robustness and generation quality. Thirdly, we empirically evaluate stability of model architectures and show improved performance on a host of benchmarks and use cases, such as image generation, OOD detection, and compositional generation.
PLADE-Net: Towards Pixel-Level Accuracy for Self-Supervised Single-View Depth Estimation with Neural Positional Encoding and Distilled Matting Loss
Mar 12, 2021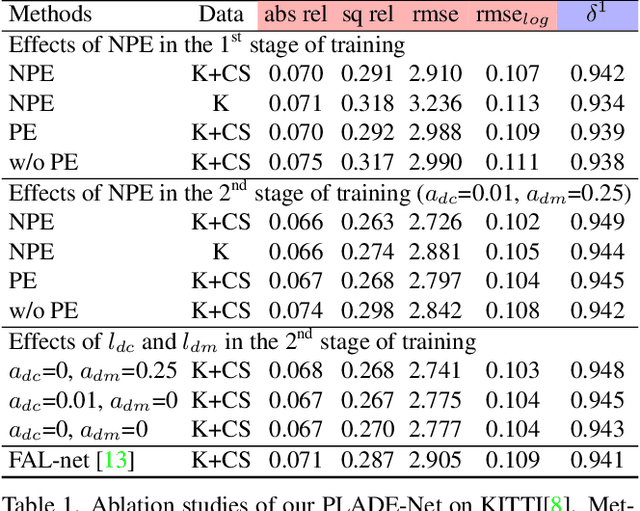

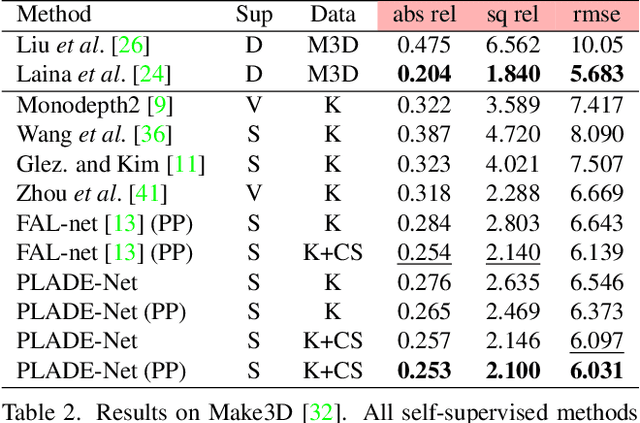

In this paper, we propose a self-supervised single-view pixel-level accurate depth estimation network, called PLADE-Net. The PLADE-Net is the first work that shows unprecedented accuracy levels, exceeding 95\% in terms of the $\delta^1$ metric on the challenging KITTI dataset. Our PLADE-Net is based on a new network architecture with neural positional encoding and a novel loss function that borrows from the closed-form solution of the matting Laplacian to learn pixel-level accurate depth estimation from stereo images. Neural positional encoding allows our PLADE-Net to obtain more consistent depth estimates by letting the network reason about location-specific image properties such as lens and projection distortions. Our novel distilled matting Laplacian loss allows our network to predict sharp depths at object boundaries and more consistent depths in highly homogeneous regions. Our proposed method outperforms all previous self-supervised single-view depth estimation methods by a large margin on the challenging KITTI dataset, with unprecedented levels of accuracy. Furthermore, our PLADE-Net, naively extended for stereo inputs, outperforms the most recent self-supervised stereo methods, even without any advanced blocks like 1D correlations, 3D convolutions, or spatial pyramid pooling. We present extensive ablation studies and experiments that support our method's effectiveness on the KITTI, CityScapes, and Make3D datasets.
A New Cervical Cytology Dataset for Nucleus Detection and Image Classification (Cervix93) and Methods for Cervical Nucleus Detection
Nov 23, 2018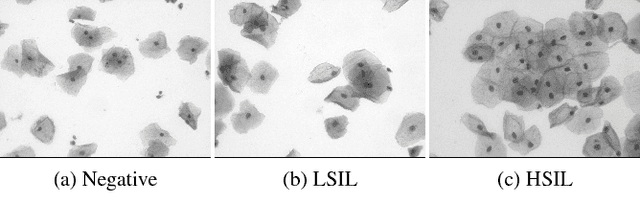
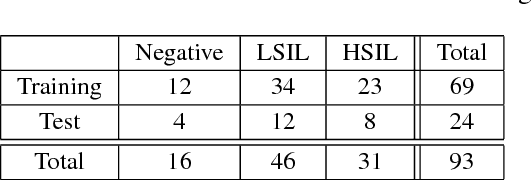
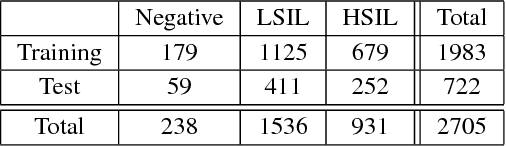

Analyzing Pap cytology slides is an important tasks in detecting and grading precancerous and cancerous cervical cancer stages. Processing cytology images usually involve segmenting nuclei and overlapping cells. We introduce a cervical cytology dataset that can be used to evaluate nucleus detection, as well as image classification methods in the cytology image processing area. This dataset contains 93 real image stacks with their grade labels and manually annotated nuclei within images. We also present two methods: a baseline method based on a previously proposed approach, and a deep learning method, and compare their results with other state-of-the-art methods. Both the baseline method and the deep learning method outperform other state-of-the-art methods by significant margins. Along with the dataset, we publicly make the evaluation code and the baseline method available to download for further benchmarking.
DARN: a Deep Adversial Residual Network for Intrinsic Image Decomposition
Mar 20, 2018
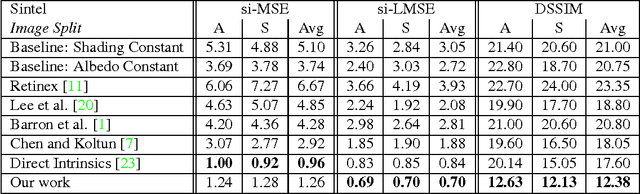
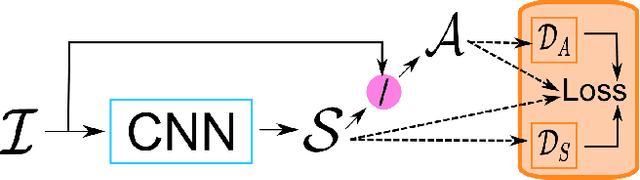

We present a new deep supervised learning method for intrinsic decomposition of a single image into its albedo and shading components. Our contributions are based on a new fully convolutional neural network that estimates absolute albedo and shading jointly. Our solution relies on a single end-to-end deep sequence of residual blocks and a perceptually-motivated metric formed by two adversarially trained discriminators. As opposed to classical intrinsic image decomposition work, it is fully data-driven, hence does not require any physical priors like shading smoothness or albedo sparsity, nor does it rely on geometric information such as depth. Compared to recent deep learning techniques, we simplify the architecture, making it easier to build and train, and constrain it to generate a valid and reversible decomposition. We rediscuss and augment the set of quantitative metrics so as to account for the more challenging recovery of non scale-invariant quantities. We train and demonstrate our architecture on the publicly available MPI Sintel dataset and its intrinsic image decomposition, show attenuated overfitting issues and discuss generalizability to other data. Results show that our work outperforms the state of the art deep algorithms both on the qualitative and quantitative aspect.
OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association
Mar 03, 2021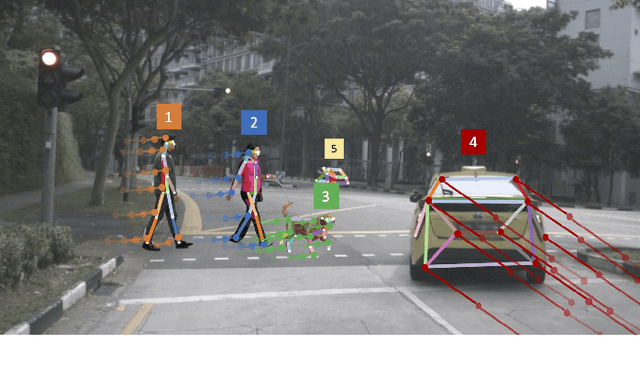


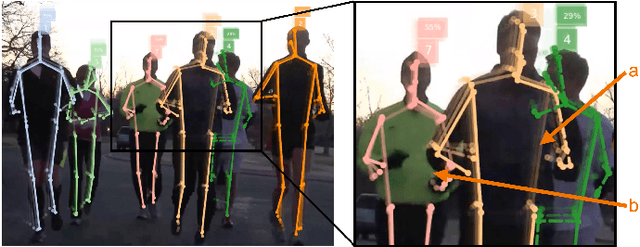
Many image-based perception tasks can be formulated as detecting, associating and tracking semantic keypoints, e.g., human body pose estimation and tracking. In this work, we present a general framework that jointly detects and forms spatio-temporal keypoint associations in a single stage, making this the first real-time pose detection and tracking algorithm. We present a generic neural network architecture that uses Composite Fields to detect and construct a spatio-temporal pose which is a single, connected graph whose nodes are the semantic keypoints (e.g., a person's body joints) in multiple frames. For the temporal associations, we introduce the Temporal Composite Association Field (TCAF) which requires an extended network architecture and training method beyond previous Composite Fields. Our experiments show competitive accuracy while being an order of magnitude faster on multiple publicly available datasets such as COCO, CrowdPose and the PoseTrack 2017 and 2018 datasets. We also show that our method generalizes to any class of semantic keypoints such as car and animal parts to provide a holistic perception framework that is well suited for urban mobility such as self-driving cars and delivery robots.
Dynamic Fusion Module Evolves Drivable Area and Road Anomaly Detection: A Benchmark and Algorithms
Mar 03, 2021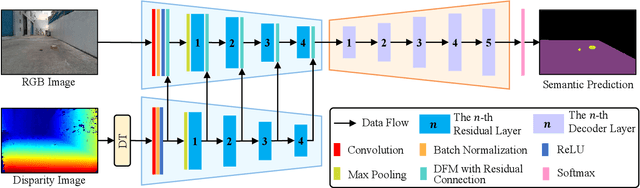



Joint detection of drivable areas and road anomalies is very important for mobile robots. Recently, many semantic segmentation approaches based on convolutional neural networks (CNNs) have been proposed for pixel-wise drivable area and road anomaly detection. In addition, some benchmark datasets, such as KITTI and Cityscapes, have been widely used. However, the existing benchmarks are mostly designed for self-driving cars. There lacks a benchmark for ground mobile robots, such as robotic wheelchairs. Therefore, in this paper, we first build a drivable area and road anomaly detection benchmark for ground mobile robots, evaluating the existing state-of-the-art single-modal and data-fusion semantic segmentation CNNs using six modalities of visual features. Furthermore, we propose a novel module, referred to as the dynamic fusion module (DFM), which can be easily deployed in existing data-fusion networks to fuse different types of visual features effectively and efficiently. The experimental results show that the transformed disparity image is the most informative visual feature and the proposed DFM-RTFNet outperforms the state-of-the-arts. Additionally, our DFM-RTFNet achieves competitive performance on the KITTI road benchmark. Our benchmark is publicly available at https://sites.google.com/view/gmrb.
Asymmetric Deep Semantic Quantization for Image Retrieval
Mar 29, 2019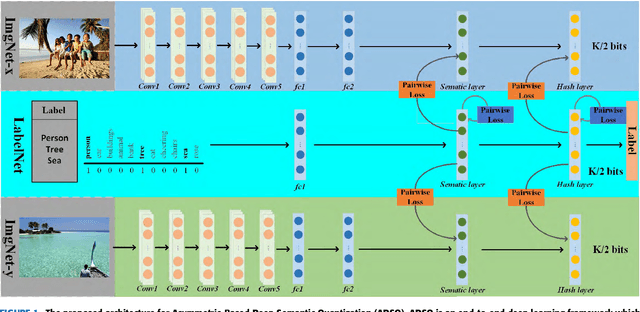
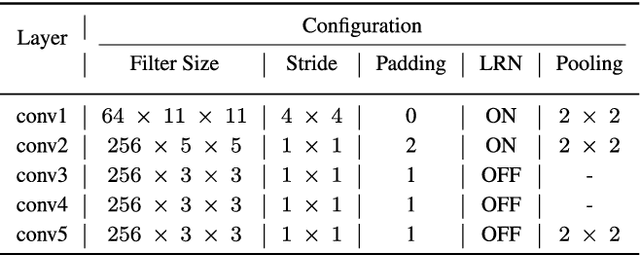

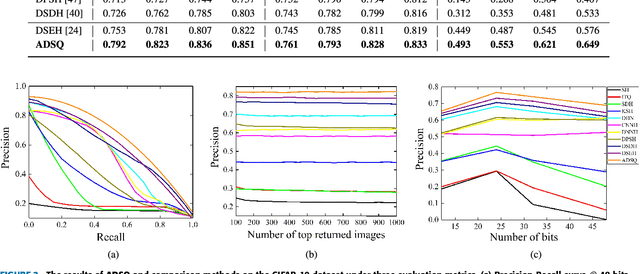
Due to its fast retrieval and storage efficiency capabilities, hashing has been widely used in nearest neighbor retrieval tasks. By using deep learning based techniques, hashing can outperform non-learning based hashing in many applications. However, there are some limitations to previous learning based hashing methods (e.g., the learned hash codes are not discriminative due to the hashing methods being unable to discover rich semantic information and the training strategy having difficulty optimizing the discrete binary codes). In this paper, we propose a novel learning based hashing method, named \textbf{\underline{A}}symmetric \textbf{\underline{D}}eep \textbf{\underline{S}}emantic \textbf{\underline{Q}}uantization (\textbf{ADSQ}). \textbf{ADSQ} is implemented using three stream frameworks, which consists of one \emph{LabelNet} and two \emph{ImgNets}. The \emph{LabelNet} leverages three fully-connected layers, which is used to capture rich semantic information between image pairs. For the two \emph{ImgNets}, they each adopt the same convolutional neural network structure, but with different weights (i.e., asymmetric convolutional neural networks). The two \emph{ImgNets} are used to generate discriminative compact hash codes. Specifically, the function of the \emph{LabelNet} is to capture rich semantic information that is used to guide the two \emph{ImgNets} in minimizing the gap between the real-continuous features and discrete binary codes. By doing this, \textbf{ADSQ} can make full use of the most critical semantic information to guide the feature learning process and consider the consistency of the common semantic space and Hamming space. Results from our experiments demonstrate that \textbf{ADSQ} can generate high discriminative compact hash codes and it outperforms current state-of-the-art methods on three benchmark datasets, CIFAR-10, NUS-WIDE, and ImageNet.
Event-based Synthetic Aperture Imaging
Mar 03, 2021
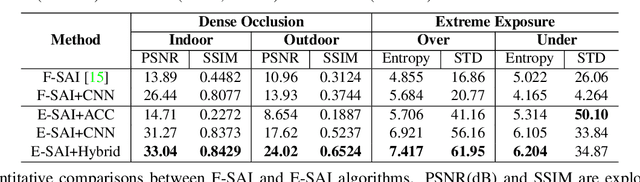


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021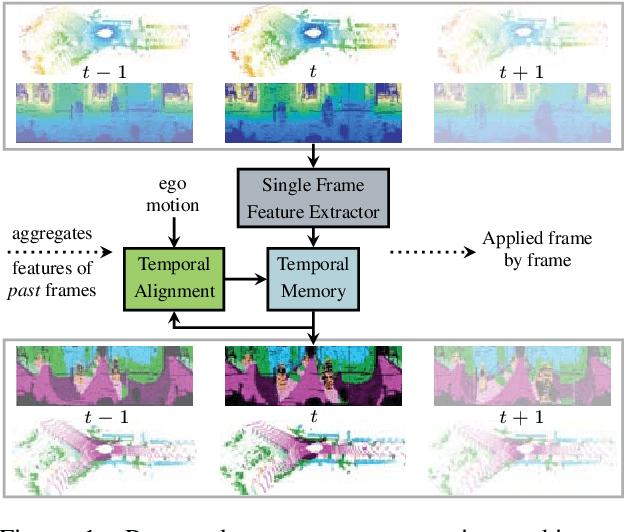
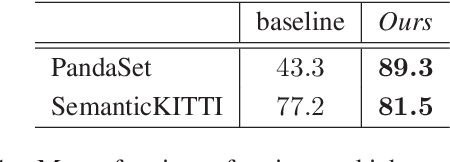
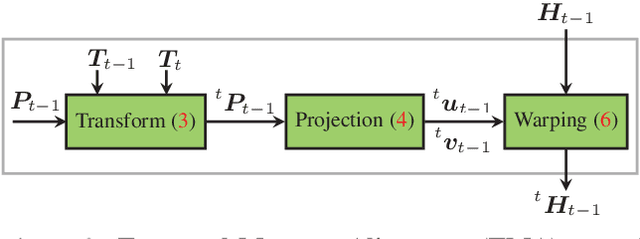
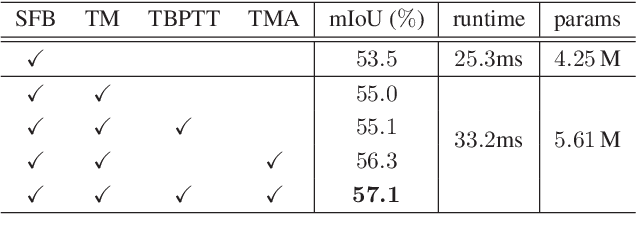
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
CORE: Color Regression for Multiple Colors Fashion Garments
Oct 06, 2020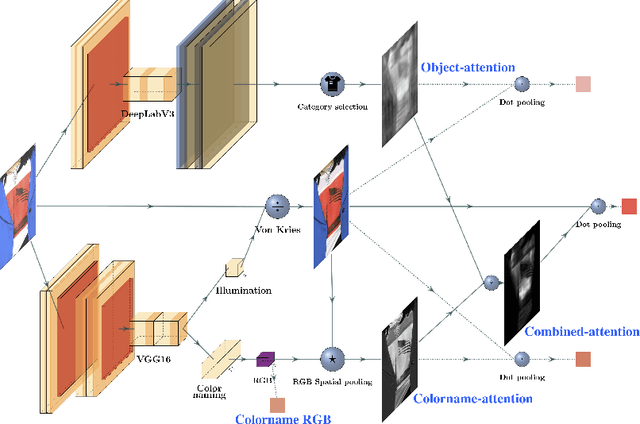

Among all fashion attributes, color is challenging to detect due to its subjective perception. Existing classification approaches can not go beyond the predefined list of discrete color names. In this paper, we argue that color detection is a regression problem. Thus, we propose a new architecture, based on attention modules and in two-stages. The first stage corrects the image illumination while detecting the main discrete color name. The second stage combines a colorname-attention (dependent of the detected color) with an object-attention (dependent of the clothing category) and finally weights a spatial pooling over the image pixels' RGB values. We further expand our work for multiple colors garments. We collect a dataset where each fashion item is labeled with a continuous color palette: we empirically show the benefits of our approach.