 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coarse-to-fine Seam Estimation for Image Stitching
May 24, 2018
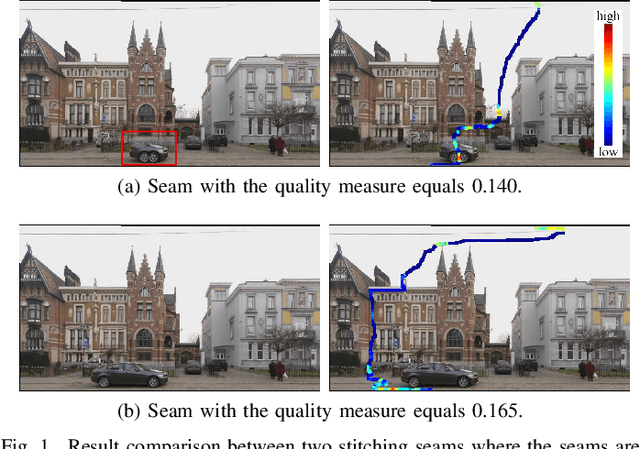
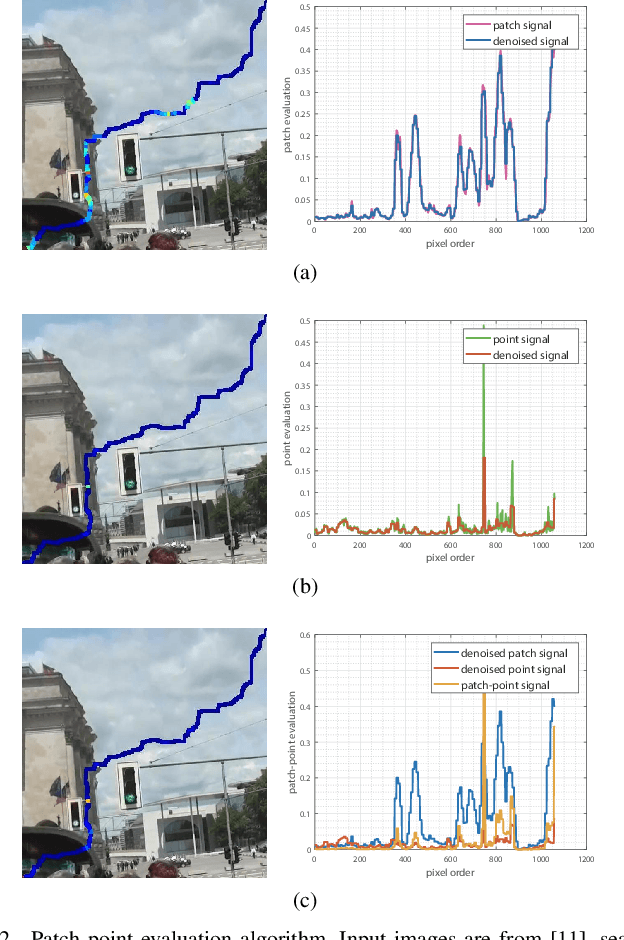


Seam-cutting and seam-driven techniques have been proven effective for handling imperfect image series in image stitching. Generally, seam-driven is to utilize seam-cutting to find a best seam from one or finite alignment hypotheses based on a predefined seam quality metric. However, the quality metrics in most methods are defined to measure the average performance of the pixels on the seam without considering the relevance and variance among them. This may cause that the seam with the minimal measure is not optimal (perception-inconsistent) in human perception. In this paper, we propose a novel coarse-to-fine seam estimation method which applies the evaluation in a different way. For pixels on the seam, we develop a patch-point evaluation algorithm concentrating more on the correlation and variation of them. The evaluations are then used to recalculate the difference map of the overlapping region and reestimate a stitching seam. This evaluation-reestimation procedure iterates until the current seam changes negligibly comparing with the previous seams. Experiments show that our proposed method can finally find a nearly perception-consistent seam after several iterations, which outperforms the conventional seam-cutting and other seam-driven methods.
Group Equivariant Conditional Neural Processes
Feb 17, 2021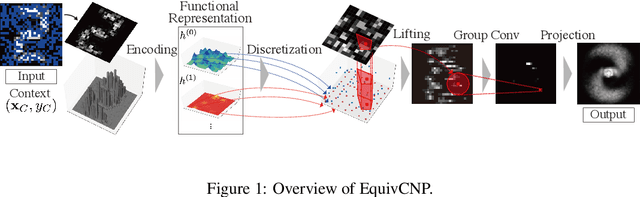
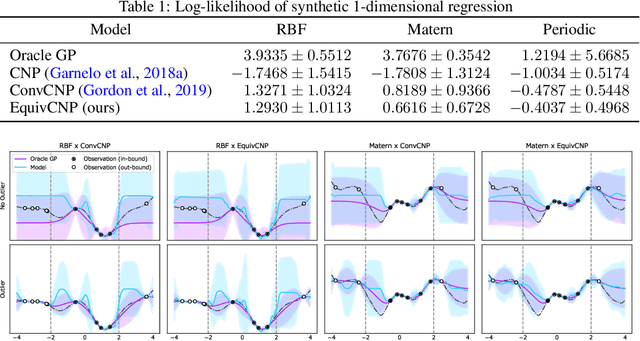

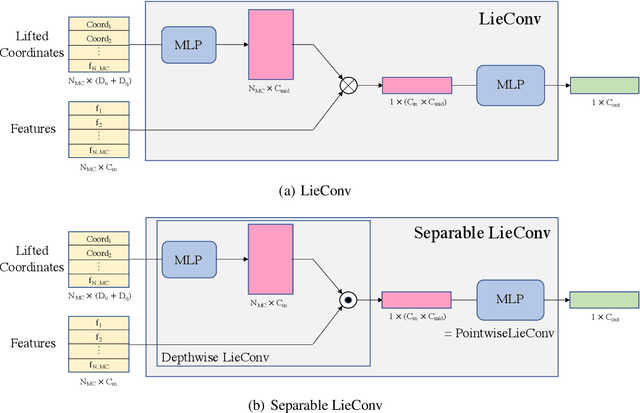
We present the group equivariant conditional neural process (EquivCNP), a meta-learning method with permutation invariance in a data set as in conventional conditional neural processes (CNPs), and it also has transformation equivariance in data space. Incorporating group equivariance, such as rotation and scaling equivariance, provides a way to consider the symmetry of real-world data. We give a decomposition theorem for permutation-invariant and group-equivariant maps, which leads us to construct EquivCNPs with an infinite-dimensional latent space to handle group symmetries. In this paper, we build architecture using Lie group convolutional layers for practical implementation. We show that EquivCNP with translation equivariance achieves comparable performance to conventional CNPs in a 1D regression task. Moreover, we demonstrate that incorporating an appropriate Lie group equivariance, EquivCNP is capable of zero-shot generalization for an image-completion task by selecting an appropriate Lie group equivariance.
Vision Transformers for Dense Prediction
Mar 24, 2021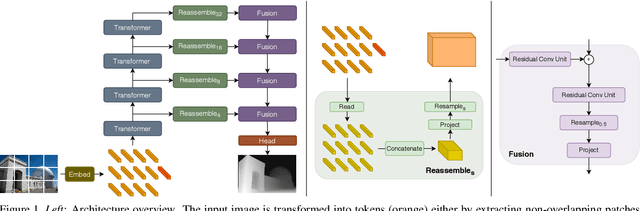
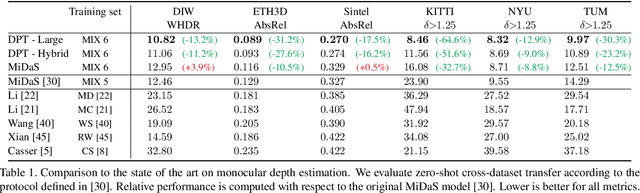
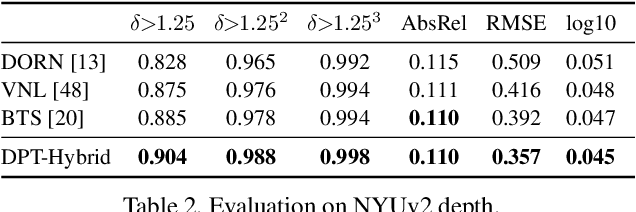

We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.
Automatic Ship Classification Utilizing Bag of Deep Features
Feb 23, 2021
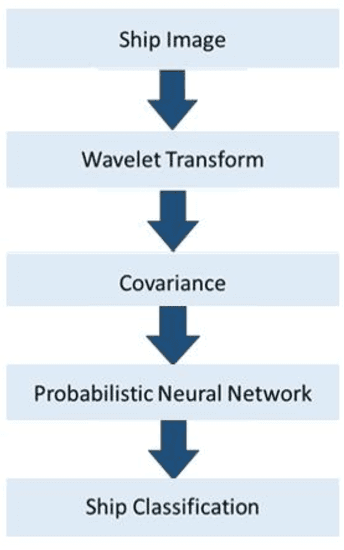
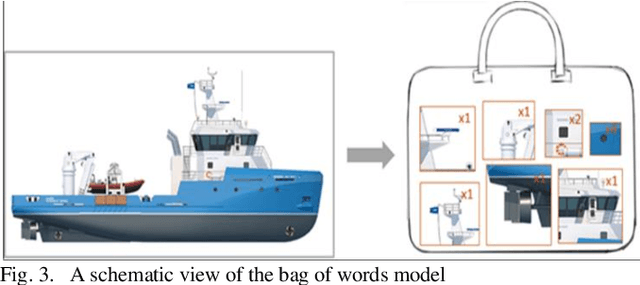
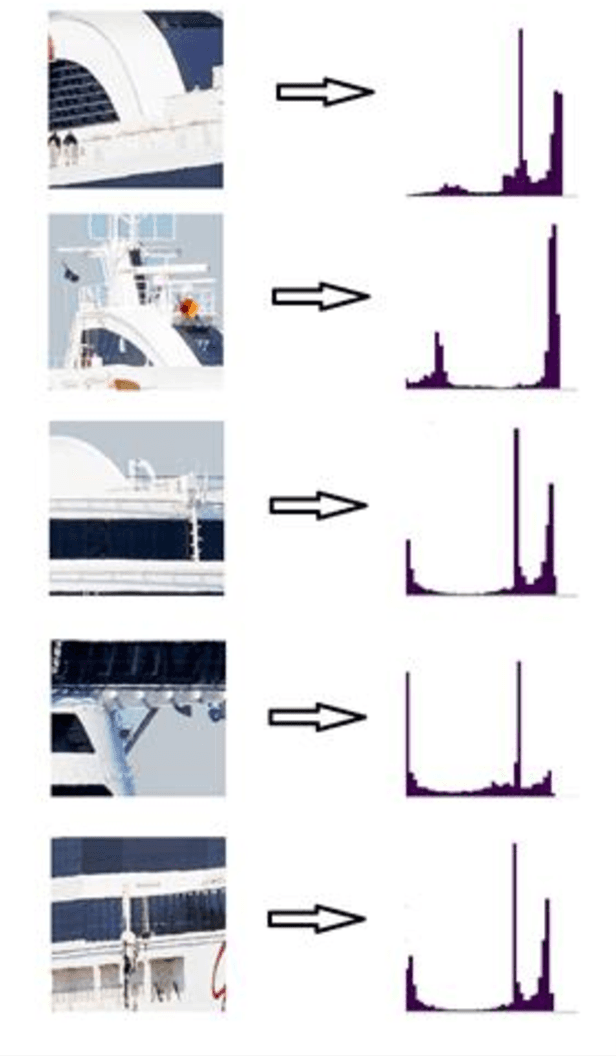
Detection and classification of ships based on their silhouette profiles in natural imagery is an important undertaking in computer science. This problem can be viewed from a variety of perspectives, including security, traffic control, and even militarism. Therefore, in each of the aforementioned applications, specific processing is required. In this paper, by applying the "bag of words" (BoW), a new method is presented that its words are the features that are obtained using pre-trained models of deep convolutional networks. , Three VGG models are utilized which provide superior accuracy in identifying objects. The regions of the image that are selected as the initial proposals are derived from a greedy algorithm on the key points generated by the Scale Invariant Feature Transform (SIFT) method. Using the deep features in the BOW method provides a good improvement in the recognition and classification of ships. Eventually, we obtained an accuracy of 91.8% in the classification of the ships which shows the improvement of about 5% compared to previous methods.
Counterfactual Generation and Fairness Evaluation Using Adversarially Learned Inference
Sep 17, 2020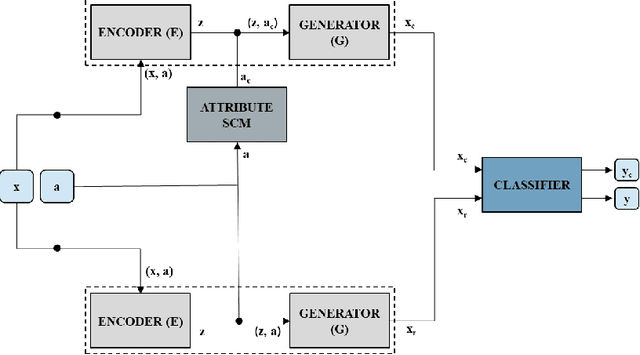

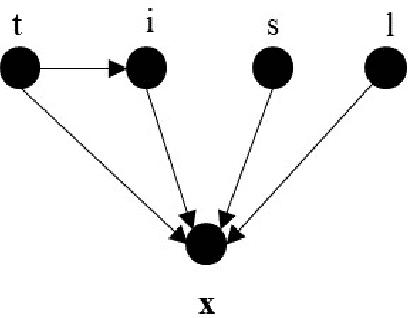
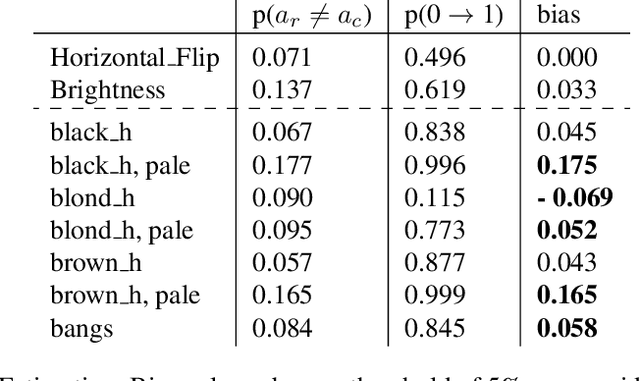
Recent studies have reported biases in machine learning image classifiers, especially against particular demographic groups. Counterfactual examples for an input---perturbations that change specific features but not others---have been shown to be useful for evaluating explainability and fairness of machine learning models. However, generating counterfactual examples for images is non-trivial due to the underlying causal structure governing the various features of an image. To be meaningful, generated perturbations need to satisfy constraints implied by the causal model. We present a method for generating counterfactuals by incorporating a known causal graph structure in a conditional variant of Adversarially Learned Inference (ALI). The proposed approach learns causal relationships between the specified attributes of an image and generates counterfactuals in accordance with these relationships. On Morpho-MNIST and CelebA datasets, the method generates counterfactuals that can change specified attributes and their causal descendants while keeping other attributes constant. As an application, we apply the generated counterfactuals from CelebA images to evaluate fairness biases in a classifier that predicts attractiveness of a face.
A Study of Human Gaze Behavior During Visual Crowd Counting
Sep 27, 2020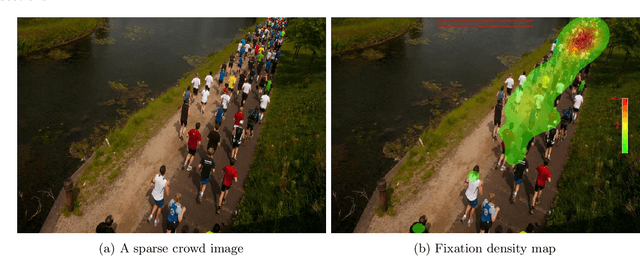
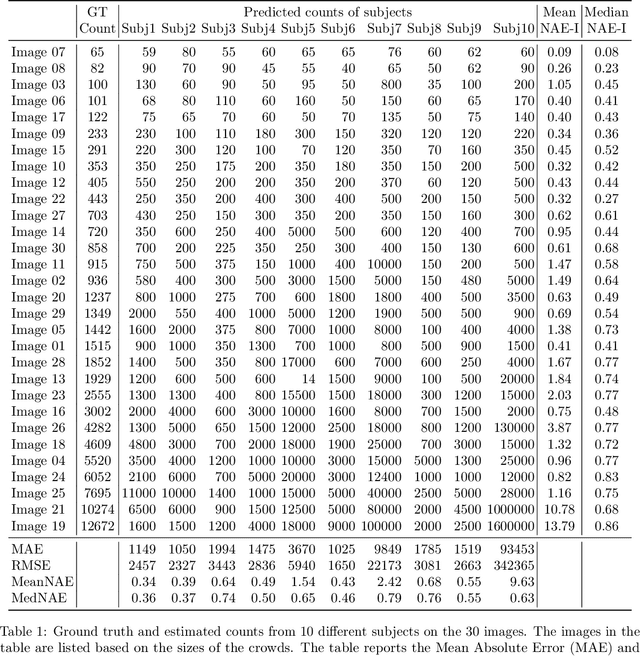

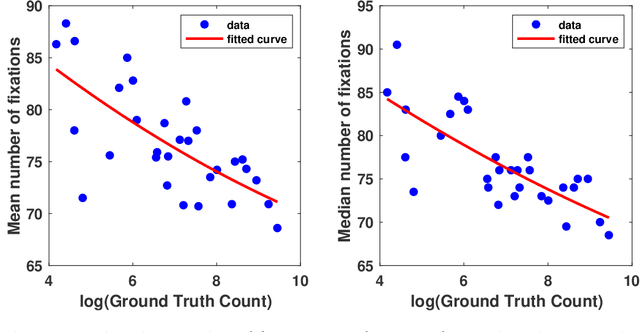
In this paper, we describe our study on how humans allocate their attention during visual crowd counting. Using an eye tracker, we collect gaze behavior of human participants who are tasked with counting the number of people in crowd images. Analyzing the collected gaze behavior of ten human participants on thirty crowd images, we observe some common approaches for visual counting. For an image of a small crowd, the approach is to enumerate over all people or groups of people in the crowd, and this explains the high level of similarity between the fixation density maps of different human participants. For an image of a large crowd, our participants tend to focus on one section of the image, count the number of people in that section, and then extrapolate to the other sections. In terms of count accuracy, our human participants are not as good at the counting task, compared to the performance of the current state-of-the-art computer algorithms. Interestingly, there is a tendency to under count the number of people in all crowd images. Gaze behavior data and images can be downloaded from https://www3.cs.stonybrook.edu/~minhhoai/projects/crowd_counting_gaze/.
Large-scale image analysis using docker sandboxing
Mar 07, 2017
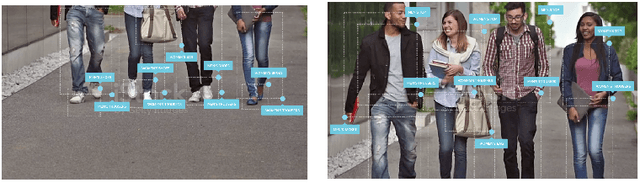


With the advent of specialized hardware such as Graphics Processing Units (GPUs), large scale image localization, classification and retrieval have seen increased prevalence. Designing scalable software architecture that co-evolves with such specialized hardware is a challenge in the commercial setting. In this paper, we describe one such architecture (\textit{Cortexica}) that leverages scalability of GPUs and sandboxing offered by docker containers. This allows for the flexibility of mixing different computer architectures as well as computational algorithms with the security of a trusted environment. We illustrate the utility of this framework in a commercial setting i.e., searching for multiple products in an image by combining image localisation and retrieval.
FakeMix Augmentation Improves Transparent Object Detection
Mar 24, 2021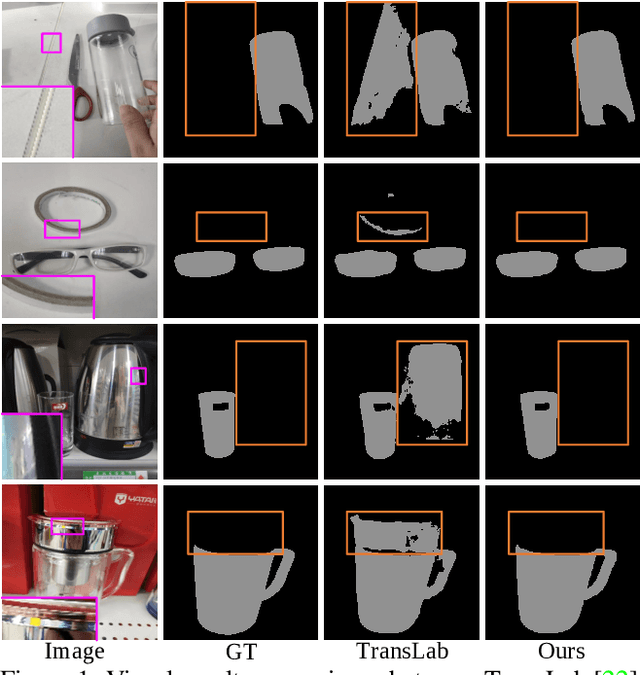

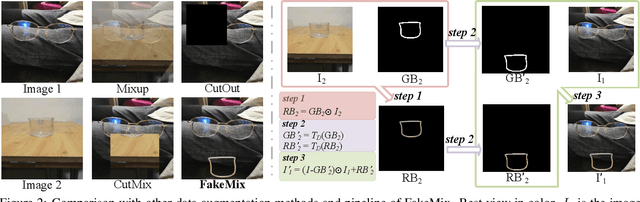
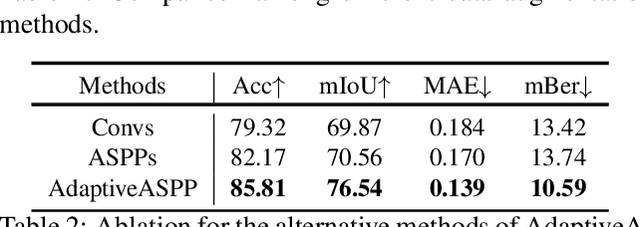
Detecting transparent objects in natural scenes is challenging due to the low contrast in texture, brightness and colors. Recent deep-learning-based works reveal that it is effective to leverage boundaries for transparent object detection (TOD). However, these methods usually encounter boundary-related imbalance problem, leading to limited generation capability. Detailly, a kind of boundaries in the background, which share the same characteristics with boundaries of transparent objects but have much smaller amounts, usually hurt the performance. To conquer the boundary-related imbalance problem, we propose a novel content-dependent data augmentation method termed FakeMix. Considering collecting these trouble-maker boundaries in the background is hard without corresponding annotations, we elaborately generate them by appending the boundaries of transparent objects from other samples into the current image during training, which adjusts the data space and improves the generalization of the models. Further, we present AdaptiveASPP, an enhanced version of ASPP, that can capture multi-scale and cross-modality features dynamically. Extensive experiments demonstrate that our methods clearly outperform the state-of-the-art methods. We also show that our approach can also transfer well on related tasks, in which the model meets similar troubles, such as mirror detection, glass detection, and camouflaged object detection. Code will be made publicly available.
Uncertainty-Based Biological Age Estimation of Brain MRI Scans
Mar 15, 2021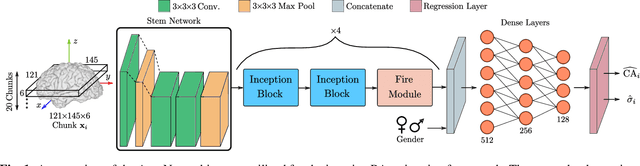
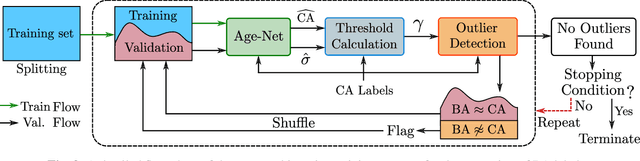
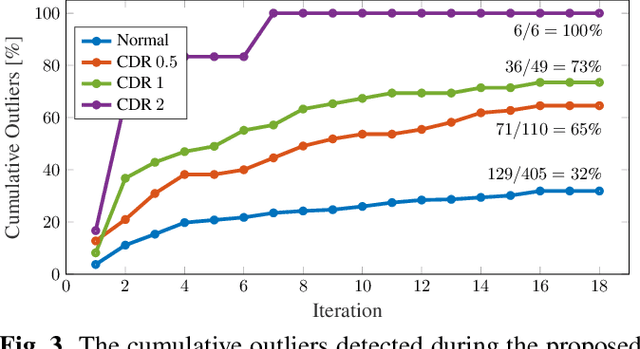
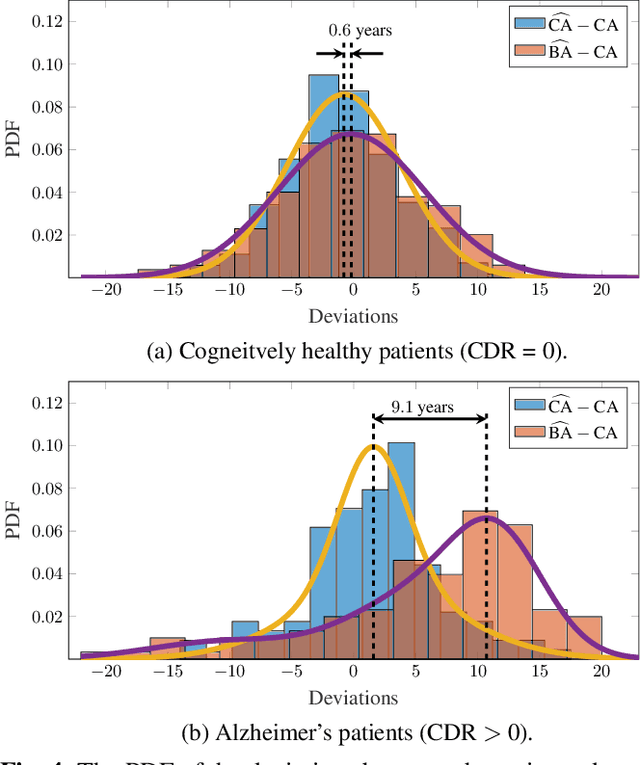
Age is an essential factor in modern diagnostic procedures. However, assessment of the true biological age (BA) remains a daunting task due to the lack of reference ground-truth labels. Current BA estimation approaches are either restricted to skeletal images or rely on non-imaging modalities that yield a whole-body BA assessment. However, various organ systems may exhibit different aging characteristics due to lifestyle and genetic factors. In this initial study, we propose a new framework for organ-specific BA estimation utilizing 3D magnetic resonance image (MRI) scans. As a first step, this framework predicts the chronological age (CA) together with the corresponding patient-dependent aleatoric uncertainty. An iterative training algorithm is then utilized to segregate atypical aging patients from the given population based on the predicted uncertainty scores. In this manner, we hypothesize that training a new model on the remaining population should approximate the true BA behavior. We apply the proposed methodology on a brain MRI dataset containing healthy individuals as well as Alzheimer's patients. We demonstrate the correlation between the predicted BAs and the expected cognitive deterioration in Alzheimer's patients.
How to distribute data across tasks for meta-learning?
Mar 15, 2021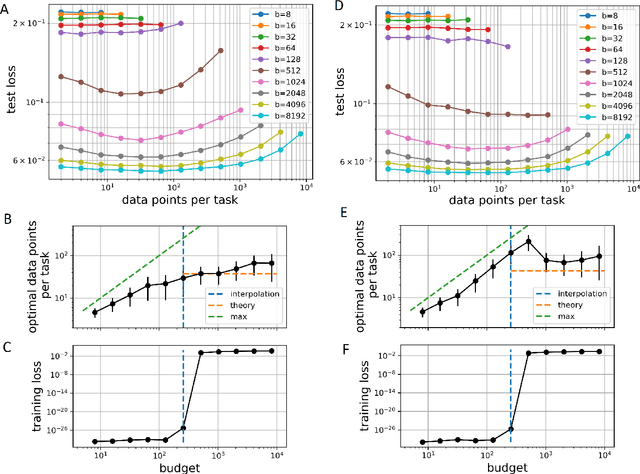
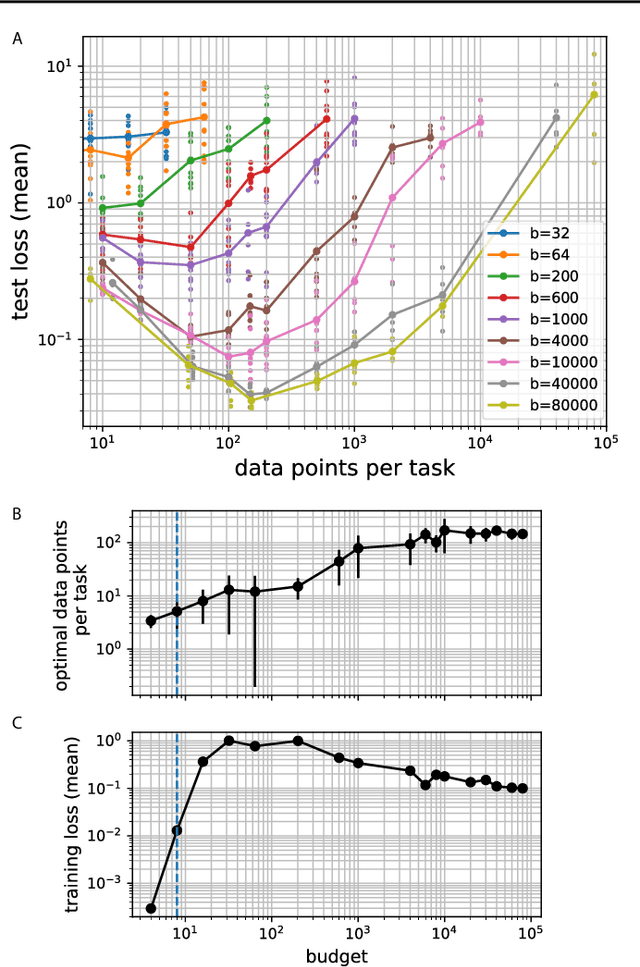
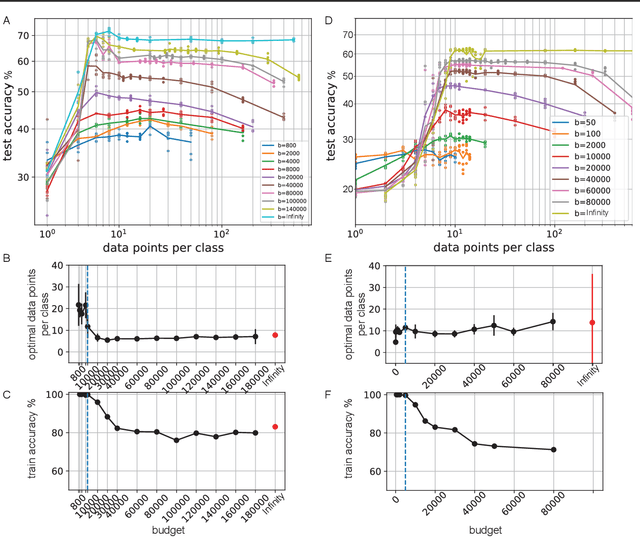

Meta-learning models transfer the knowledge acquired from previous tasks to quickly learn new ones. They are tested on benchmarks with a fixed number of data points per training task. This number is usually arbitrary and it is unknown how it affects the performance. Since labelling of data is expensive, finding the optimal allocation of labels across training tasks may reduce costs: given a fixed budget of labels, should we use a small number of highly labelled tasks, or many tasks with few labels each? We show that: 1) The optimal number of data points per task depends on the budget, but it converges to a unique constant value for large budgets; 2) Convergence occurs around the interpolation threshold of the model. We prove our results mathematically on mixed linear regression, and we show empirically that the same results hold for nonlinear regression and few-shot image classification on CIFAR-FS and mini-ImageNet. Our results suggest a simple and efficient procedure for data collection: the optimal allocation of data can be computed at low cost, by using relatively small data, and collection of additional data can be optimized by the knowledge of the optimal allocation.