 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fractional Local Neighborhood Intensity Pattern for Image Retrieval using Genetic Algorithm
Dec 30, 2017

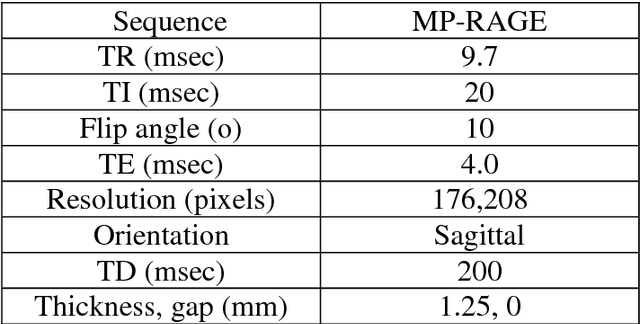
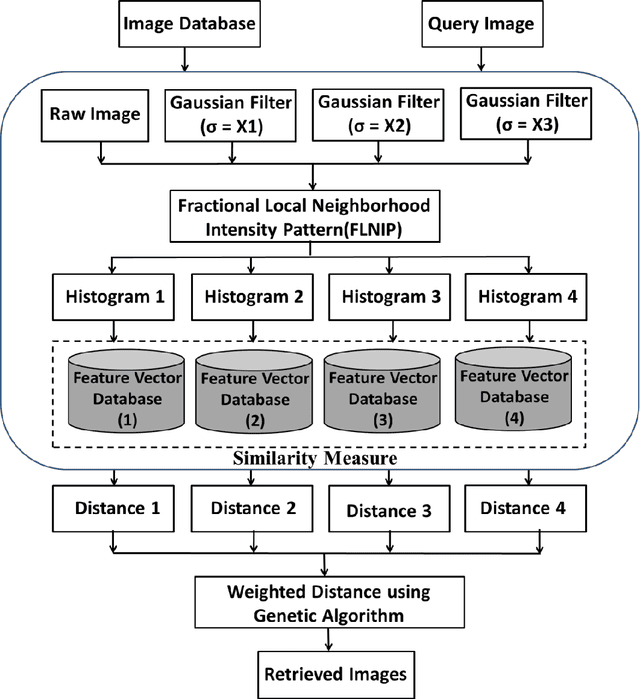
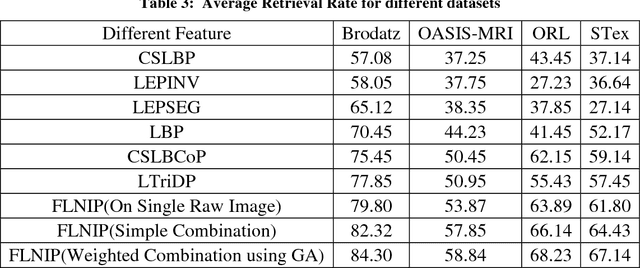
In this paper, a new texture descriptor named "Fractional Local Neighborhood Intensity Pattern" (FLNIP) has been proposed for content based image retrieval (CBIR). It is an extension of the Local Neighborhood Intensity Pattern (LNIP)[1]. FLNIP calculates the relative intensity difference between a particular pixel and the center pixel of a 3x3 window by considering the relationship with adjacent neighbors. In this work, the fractional change in the local neighborhood involving the adjacent neighbors has been calculated first with respect to one of the eight neighbors of the center pixel of a 3x3 window. Next, the fractional change has been calculated with respect to the center itself. The two values of fractional change are next compared to generate a binary bit pattern. Both sign and magnitude information are encoded in a single descriptor as it deals with the relative change in magnitude in the adjacent neighborhood i.e., the comparison of the fractional change. The descriptor is applied on four multi-resolution images- one being the raw image and the other three being filtered gaussian images obtained by applying gaussian filters of different standard deviations on the raw image to signify the importance of exploring texture information at different resolutions in an image. The four sets of distances obtained between the query and the target image are then combined with a genetic algorithm based approach to improve the retrieval performance by minimizing the distance between similar class images. The performance of the method has been tested for image retrieval on four popular databases. The precision and recall values observed on these databases have been compared with recent state-of-art local patterns. The proposed method has shown a significant improvement over many other existing methods.
Image-based Automated Species Identification: Can Virtual Data Augmentation Overcome Problems of Insufficient Sampling?
Oct 18, 2020

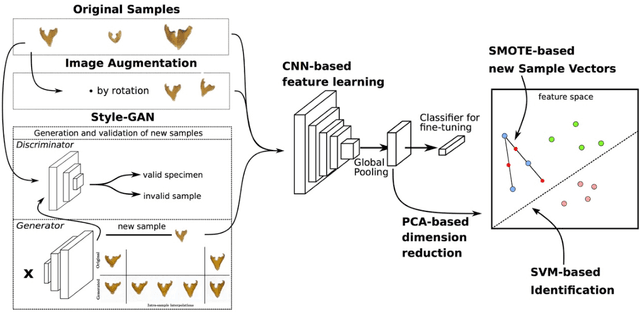

Automated species identification and delimitation is challenging, particularly in rare and thus often scarcely sampled species, which do not allow sufficient discrimination of infraspecific versus interspecific variation. Typical problems arising from either low or exaggerated interspecific morphological differentiation are best met by automated methods of machine learning that learn efficient and effective species identification from training samples. However, limited infraspecific sampling remains a key challenge also in machine learning. 1In this study, we assessed whether a two-level data augmentation approach may help to overcome the problem of scarce training data in automated visual species identification. The first level of visual data augmentation applies classic approaches of data augmentation and generation of faked images using a GAN approach. Descriptive feature vectors are derived from bottleneck features of a VGG-16 convolutional neural network (CNN) that are then stepwise reduced in dimensionality using Global Average Pooling and PCA to prevent overfitting. The second level of data augmentation employs synthetic additional sampling in feature space by an oversampling algorithm in vector space (SMOTE). Applied on two challenging datasets of scarab beetles (Coleoptera), our augmentation approach outperformed a non-augmented deep learning baseline approach as well as a traditional 2D morphometric approach (Procrustes analysis).
Segmentation of Lungs in Chest X-Ray Image Using Generative Adversarial Networks
Sep 12, 2020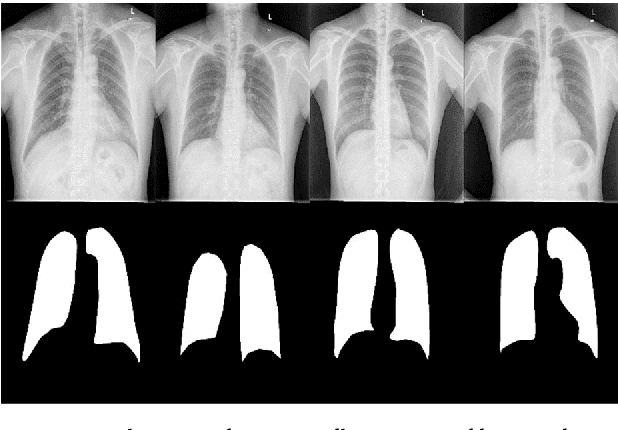

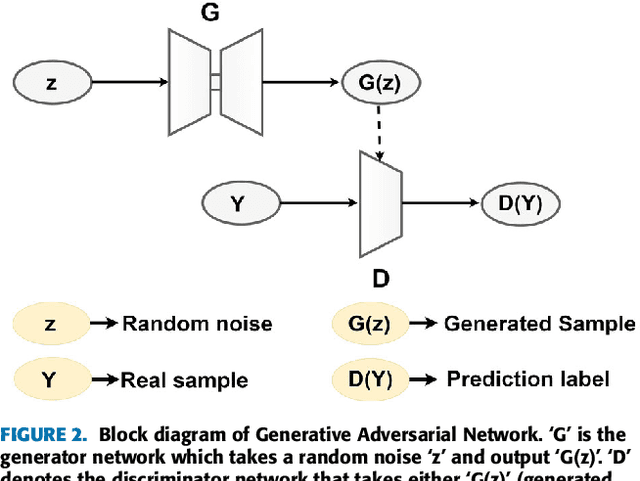
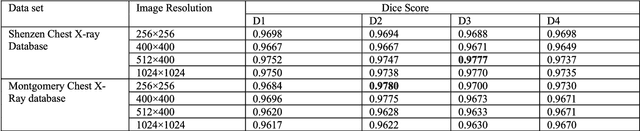
Chest X-ray (CXR) is a low-cost medical imaging technique. It is a common procedure for the identification of many respiratory diseases compared to MRI, CT, and PET scans. This paper presents the use of generative adversarial networks (GAN) to perform the task of lung segmentation on a given CXR. GANs are popular to generate realistic data by learning the mapping from one domain to another. In our work, the generator of the GAN is trained to generate a segmented mask of a given input CXR. The discriminator distinguishes between a ground truth and the generated mask, and updates the generator through the adversarial loss measure. The objective is to generate masks for the input CXR, which are as realistic as possible compared to the ground truth masks. The model is trained and evaluated using four different discriminators referred to as D1, D2, D3, and D4, respectively. Experimental results on three different CXR datasets reveal that the proposed model is able to achieve a dice-score of 0.9740, and IOU score of 0.943, which are better than other reported state-of-the art results.
* Volume 8, August 2020, Pages 153535 - 153545
Volumetric Propagation Network: Stereo-LiDAR Fusion for Long-Range Depth Estimation
Mar 24, 2021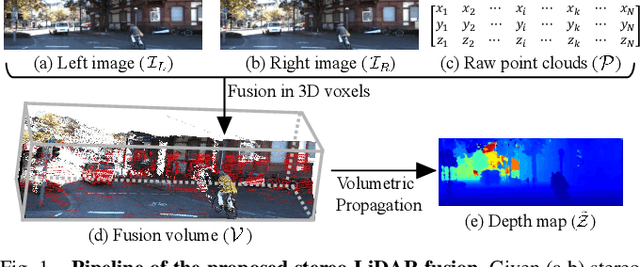
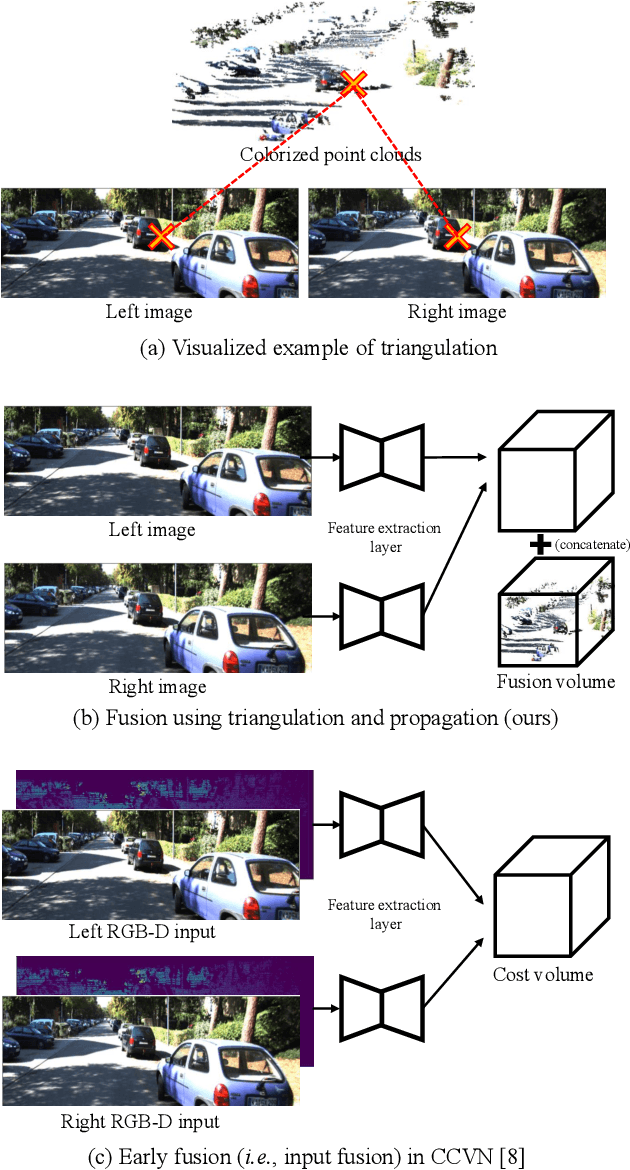
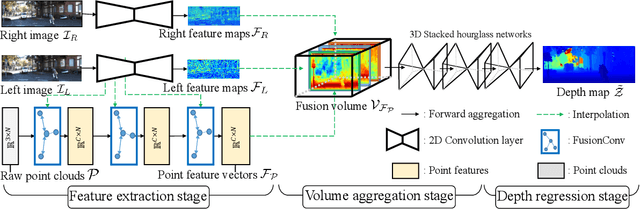
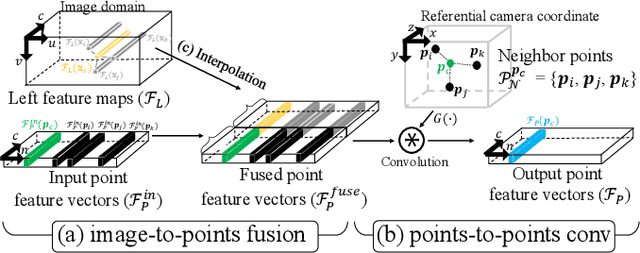
Stereo-LiDAR fusion is a promising task in that we can utilize two different types of 3D perceptions for practical usage -- dense 3D information (stereo cameras) and highly-accurate sparse point clouds (LiDAR). However, due to their different modalities and structures, the method of aligning sensor data is the key for successful sensor fusion. To this end, we propose a geometry-aware stereo-LiDAR fusion network for long-range depth estimation, called volumetric propagation network. The key idea of our network is to exploit sparse and accurate point clouds as a cue for guiding correspondences of stereo images in a unified 3D volume space. Unlike existing fusion strategies, we directly embed point clouds into the volume, which enables us to propagate valid information into nearby voxels in the volume, and to reduce the uncertainty of correspondences. Thus, it allows us to fuse two different input modalities seamlessly and regress a long-range depth map. Our fusion is further enhanced by a newly proposed feature extraction layer for point clouds guided by images: FusionConv. FusionConv extracts point cloud features that consider both semantic (2D image domain) and geometric (3D domain) relations and aid fusion at the volume. Our network achieves state-of-the-art performance on the KITTI and the Virtual-KITTI datasets among recent stereo-LiDAR fusion methods.
Single-Image Depth Perception in the Wild
Jan 06, 2017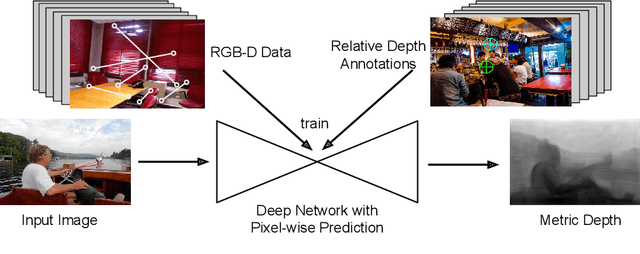
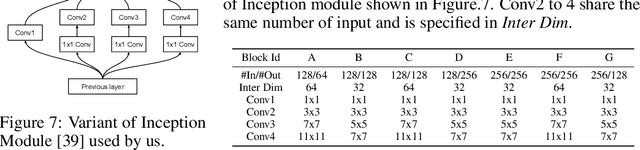

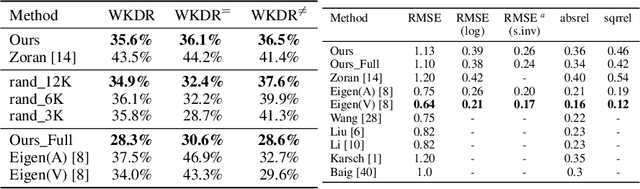
This paper studies single-image depth perception in the wild, i.e., recovering depth from a single image taken in unconstrained settings. We introduce a new dataset "Depth in the Wild" consisting of images in the wild annotated with relative depth between pairs of random points. We also propose a new algorithm that learns to estimate metric depth using annotations of relative depth. Compared to the state of the art, our algorithm is simpler and performs better. Experiments show that our algorithm, combined with existing RGB-D data and our new relative depth annotations, significantly improves single-image depth perception in the wild.
Deep Depth Completion of a Single RGB-D Image
May 02, 2018

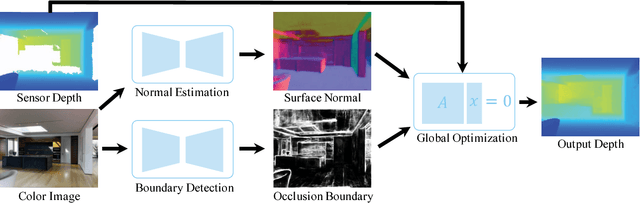
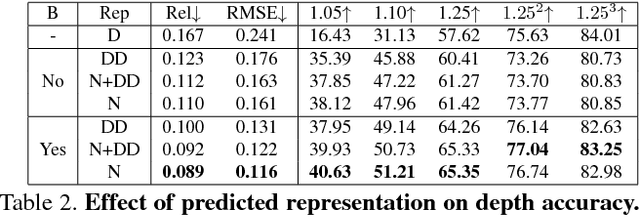
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions, optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.
Blind Inverse Gamma Correction with Maximized Differential Entropy
Jul 05, 2020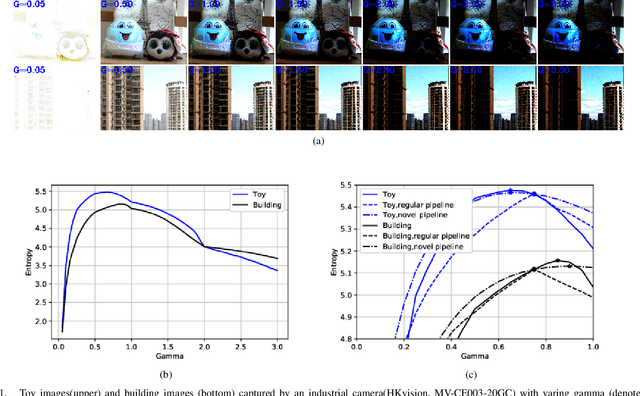
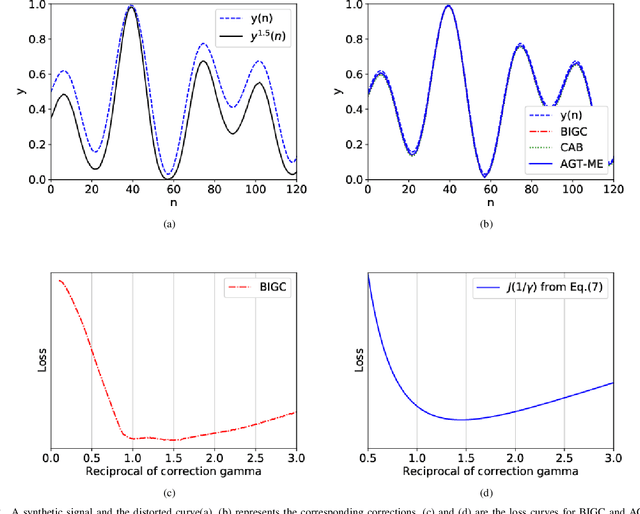

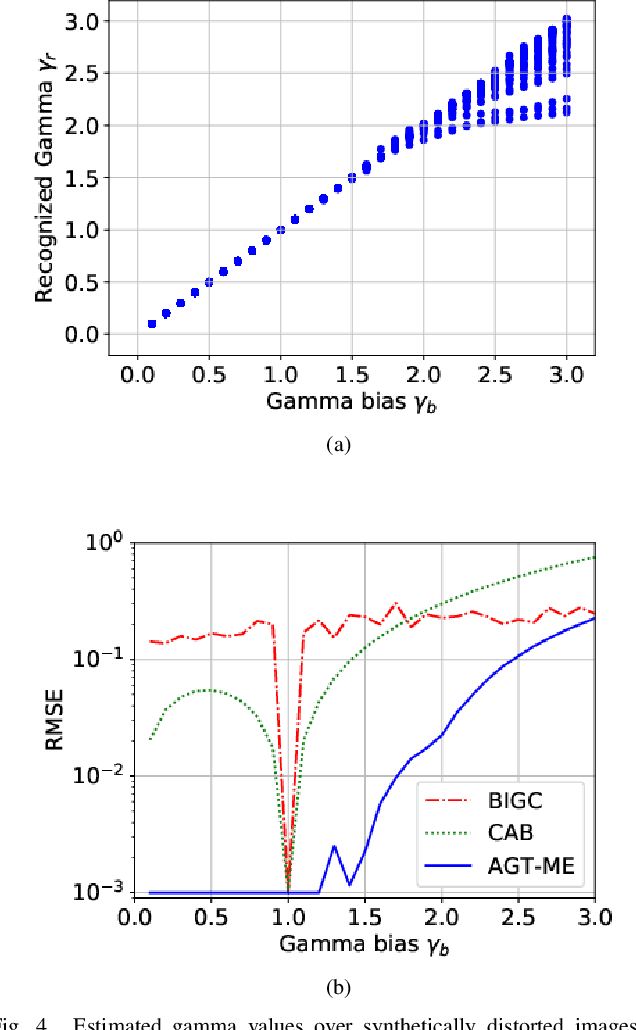
Unwanted nonlinear gamma distortion frequently occurs in a great diversity of images during the procedures of image acquisition, processing, and/or display. And the gamma distortion often varies with capture setup change and luminance variation. Blind inverse gamma correction, which automatically determines a proper restoration gamma value from a given image, is of paramount importance to attenuate the distortion. For blind inverse gamma correction, an adaptive gamma transformation method (AGT-ME) is proposed directly from a maximized differential entropy model. And the corresponding optimization has a mathematical concise closed-form solution, resulting in efficient implementation and accurate gamma restoration of AGT-ME. Considering the human eye has a non-linear perception sensitivity, a modified version AGT-ME-VISUAL is also proposed to achieve better visual performance. Tested on variable datasets, AGT-ME could obtain an accurate estimation of a large range of gamma distortion (0.1 to 3.0), outperforming the state-of-the-art methods. Besides, the proposed AGT-ME and AGT-ME-VISUAL were applied to three typical applications, including automatic gamma adjustment, natural/medical image contrast enhancement, and fringe projection profilometry image restoration. Furthermore, the AGT-ME/ AGT-ME-VISUAL is general and can be seamlessly extended to the masked image, multi-channel (color or spectrum) image, or multi-frame video, and free of the arbitrary tuning parameter. Besides, the corresponding Python code (https://github.com/yongleex/AGT-ME) is also provided for interested users.
CO2: Consistent Contrast for Unsupervised Visual Representation Learning
Oct 05, 2020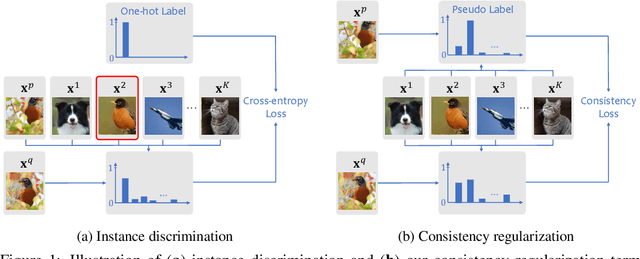
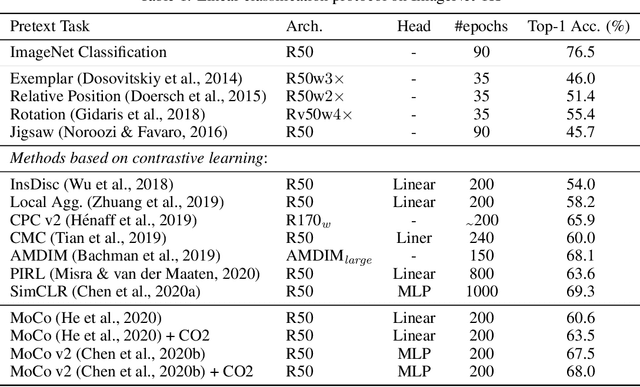
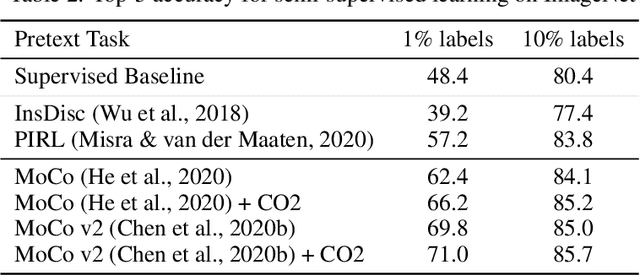
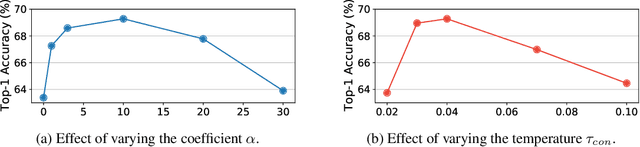
Contrastive learning has been adopted as a core method for unsupervised visual representation learning. Without human annotation, the common practice is to perform an instance discrimination task: Given a query image crop, this task labels crops from the same image as positives, and crops from other randomly sampled images as negatives. An important limitation of this label assignment strategy is that it can not reflect the heterogeneous similarity between the query crop and each crop from other images, taking them as equally negative, while some of them may even belong to the same semantic class as the query. To address this issue, inspired by consistency regularization in semi-supervised learning on unlabeled data, we propose Consistent Contrast (CO2), which introduces a consistency regularization term into the current contrastive learning framework. Regarding the similarity of the query crop to each crop from other images as "unlabeled", the consistency term takes the corresponding similarity of a positive crop as a pseudo label, and encourages consistency between these two similarities. Empirically, CO2 improves Momentum Contrast (MoCo) by 2.9% top-1 accuracy on ImageNet linear protocol, 3.8% and 1.1% top-5 accuracy on 1% and 10% labeled semi-supervised settings. It also transfers to image classification, object detection, and semantic segmentation on PASCAL VOC. This shows that CO2 learns better visual representations for these downstream tasks.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021

State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.
The Use of Video Captioning for Fostering Physical Activity
Apr 07, 2021
Video Captioning is considered to be one of the most challenging problems in the field of computer vision. Video Captioning involves the combination of different deep learning models to perform object detection, action detection, and localization by processing a sequence of image frames. It is crucial to consider the sequence of actions in a video in order to generate a meaningful description of the overall action event. A reliable, accurate, and real-time video captioning method can be used in many applications. However, this paper focuses on one application: video captioning for fostering and facilitating physical activities. In broad terms, the work can be considered to be assistive technology. Lack of physical activity appears to be increasingly widespread in many nations due to many factors, the most important being the convenience that technology has provided in workplaces. The adopted sedentary lifestyle is becoming a significant public health issue. Therefore, it is essential to incorporate more physical movements into our daily lives. Tracking one's daily physical activities would offer a base for comparison with activities performed in subsequent days. With the above in mind, this paper proposes a video captioning framework that aims to describe the activities in a video and estimate a person's daily physical activity level. This framework could potentially help people trace their daily movements to reduce an inactive lifestyle's health risks. The work presented in this paper is still in its infancy. The initial steps of the application are outlined in this paper. Based on our preliminary research, this project has great merit.