 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Surface Geometry Model for LiDAR Depth Completion
Apr 17, 2021

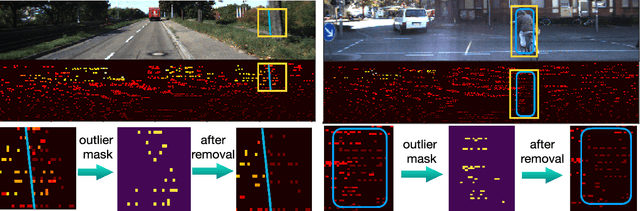
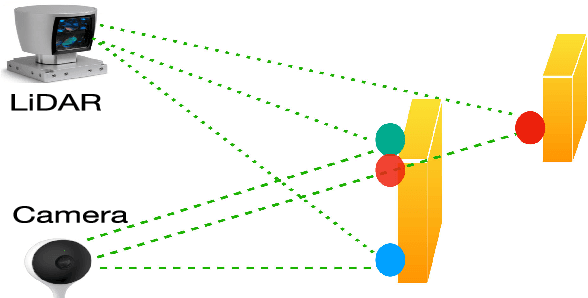
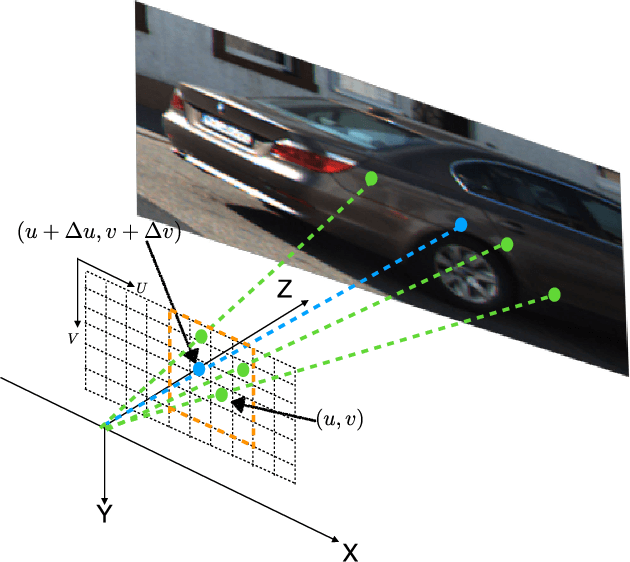
LiDAR depth completion is a task that predicts depth values for every pixel on the corresponding camera frame, although only sparse LiDAR points are available. Most of the existing state-of-the-art solutions are based on deep neural networks, which need a large amount of data and heavy computations for training the models. In this letter, a novel non-learning depth completion method is proposed by exploiting the local surface geometry that is enhanced by an outlier removal algorithm. The proposed surface geometry model is inspired by the observation that most pixels with unknown depth have a nearby LiDAR point. Therefore, it is assumed those pixels share the same surface with the nearest LiDAR point, and their respective depth can be estimated as the nearest LiDAR depth value plus a residual error. The residual error is calculated by using a derived equation with several physical parameters as input, including the known camera intrinsic parameters, estimated normal vector, and offset distance on the image plane. The proposed method is further enhanced by an outlier removal algorithm that is designed to remove incorrectly mapped LiDAR points from occluded regions. On KITTI dataset, the proposed solution achieves the best error performance among all existing non-learning methods and is comparable to the best self-supervised learning method and some supervised learning methods. Moreover, since outlier points from occluded regions is a commonly existing problem, the proposed outlier removal algorithm is a general preprocessing step that is applicable to many robotic systems with both camera and LiDAR sensors.
Latent-Space Inpainting for Packet Loss Concealment in Collaborative Object Detection
Jan 30, 2021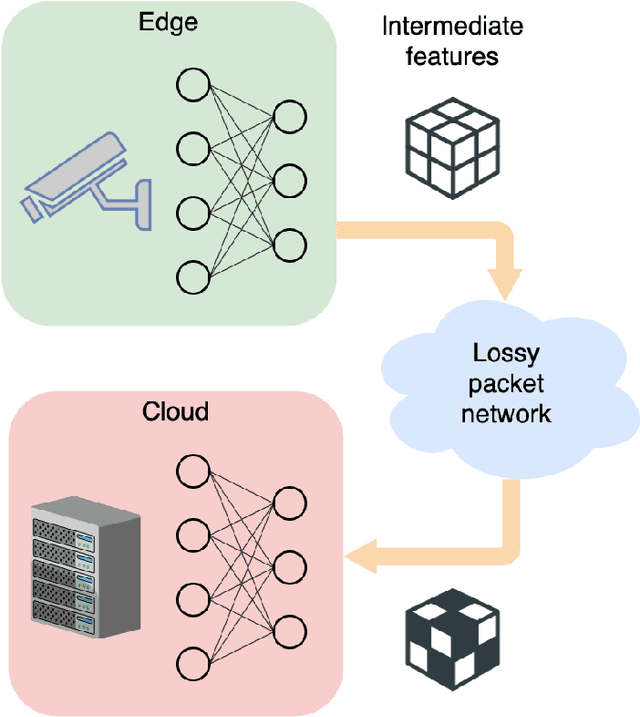
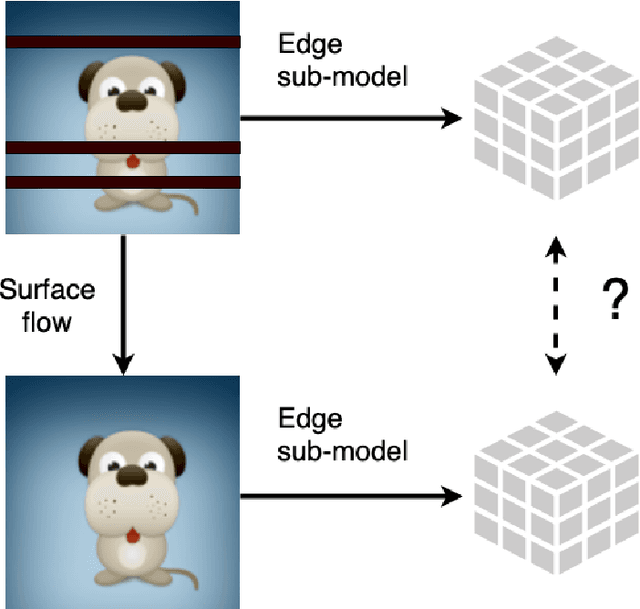
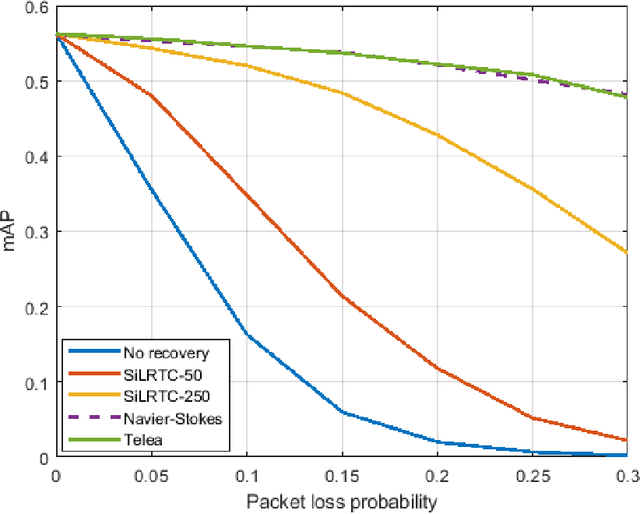

Edge devices, such as cameras and mobile units, are increasingly capable of performing sophisticated computation in addition to their traditional roles in sensing and communicating signals. The focus of this paper is on collaborative object detection, where deep features computed on the edge device from input images are transmitted to the cloud for further processing. We consider the impact of packet loss on the transmitted features and examine several ways for recovering the missing data. In particular, through theory and experiments, we show that methods for image inpainting based on partial differential equations work well for the recovery of missing features in the latent space. The obtained results represent the new state of the art for missing data recovery in collaborative object detection.
Kindling the Darkness: A Practical Low-light Image Enhancer
May 04, 2019
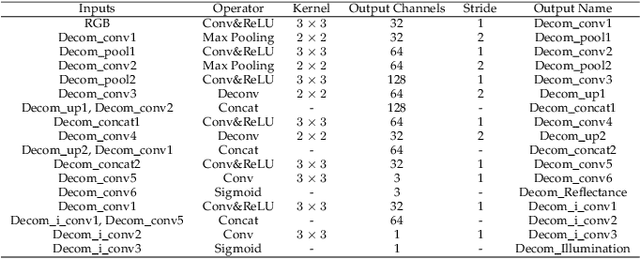
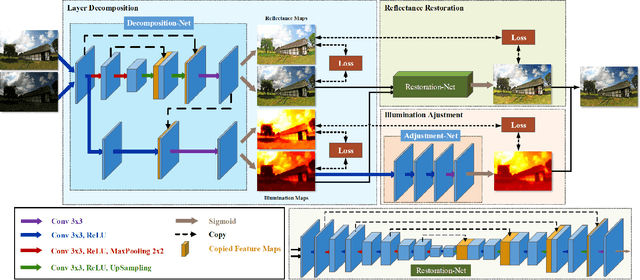
Images captured under low-light conditions often suffer from (partially) poor visibility. Besides unsatisfactory lightings, multiple types of degradations, such as noise and color distortion due to the limited quality of cameras, hide in the dark. In other words, solely turning up the brightness of dark regions will inevitably amplify hidden artifacts. This work builds a simple yet effective network for \textbf{Kin}dling the \textbf{D}arkness (denoted as KinD), which, inspired by Retinex theory, decomposes images into two components. One component (illumination) is responsible for light adjustment, while the other (reflectance) for degradation removal. In such a way, the original space is decoupled into two smaller subspaces, expecting to be better regularized/learned. It is worth to note that our network is trained with paired images shot under different exposure conditions, instead of using any ground-truth reflectance and illumination information. Extensive experiments are conducted to demonstrate the efficacy of our design and its superiority over state-of-the-art alternatives. Our KinD is robust against severe visual defects, and user-friendly to arbitrarily adjust light levels. In addition, our model spends less than 50ms to process an image in VGA resolution on a 2080Ti GPU. All the above merits make our KinD attractive for practical use.
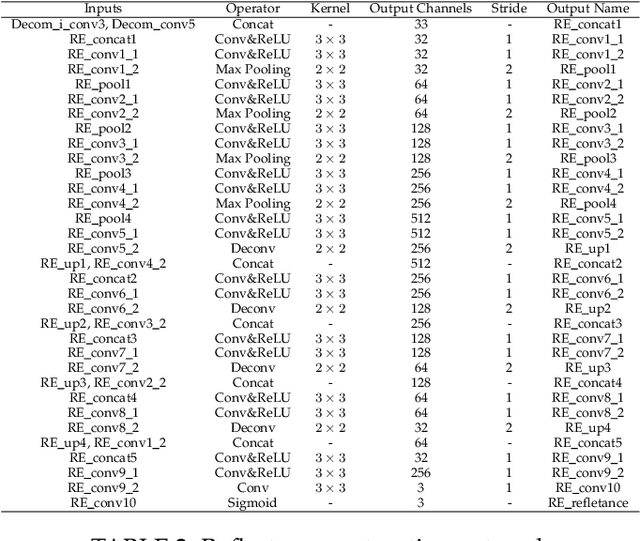
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021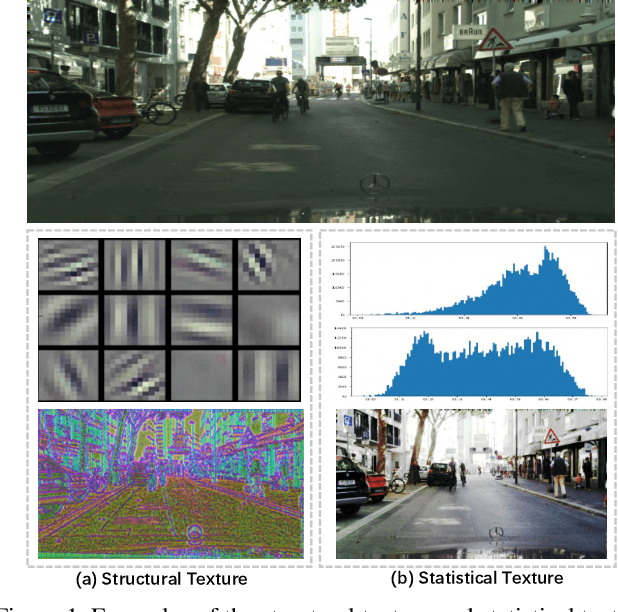
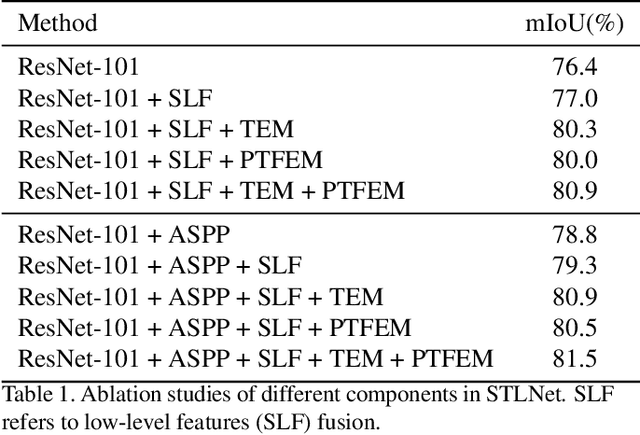
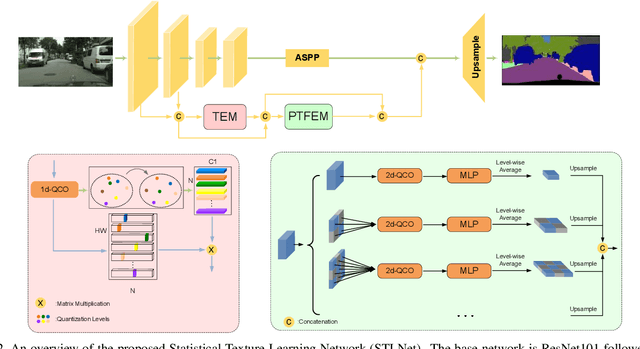

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
Lightweight Feature Fusion Network for Single Image Super-Resolution
Apr 13, 2019
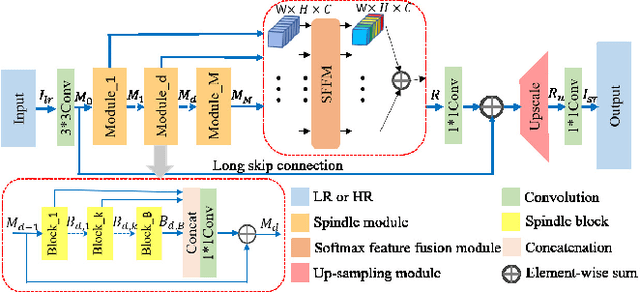
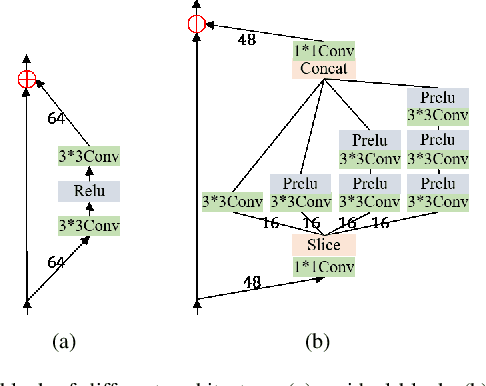
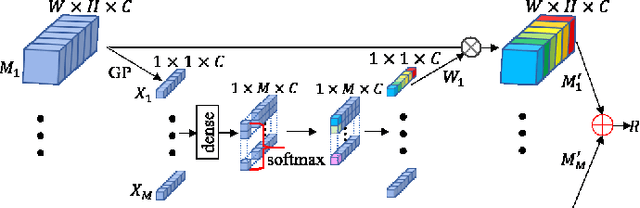
Single image super-resolution(SISR) has witnessed great progress as convolutional neural network(CNN) gets deeper and wider. However, enormous parameters hinder its application to real world problems. In this letter, We propose a lightweight feature fusion network (LFFN) that can fully explore multi-scale contextual information and greatly reduce network parameters while maximizing SISR results. LFFN is built on spindle blocks and a softmax feature fusion module (SFFM). Specifically, a spindle block is composed of a dimension extension unit, a feature exploration unit and a feature refinement unit. The dimension extension layer expands low dimension to high dimension and implicitly learns the feature maps which is suitable for the next unit. The feature exploration unit performs linear and nonlinear feature exploration aimed at different feature maps. The feature refinement layer is used to fuse and refine features. SFFM fuses the features from different modules in a self-adaptive learning manner with softmax function, making full use of hierarchical information with a small amount of parameter cost. Both qualitative and quantitative experiments on benchmark datasets show that LFFN achieves favorable performance against state-of-the-art methods with similar parameters.
Deep Learning from Shallow Dives: Sonar Image Generation and Training for Underwater Object Detection
Oct 18, 2018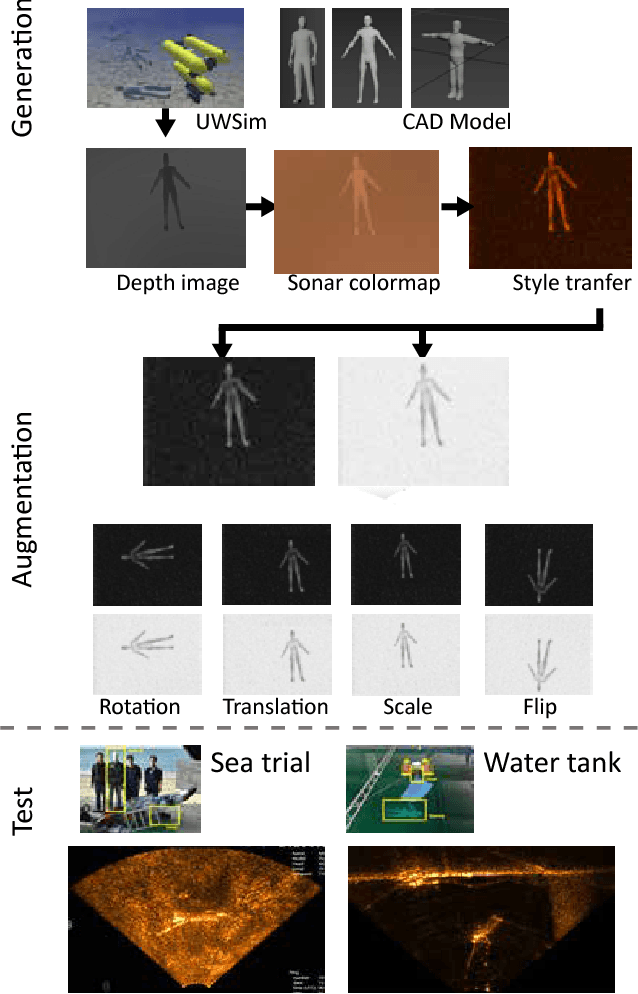

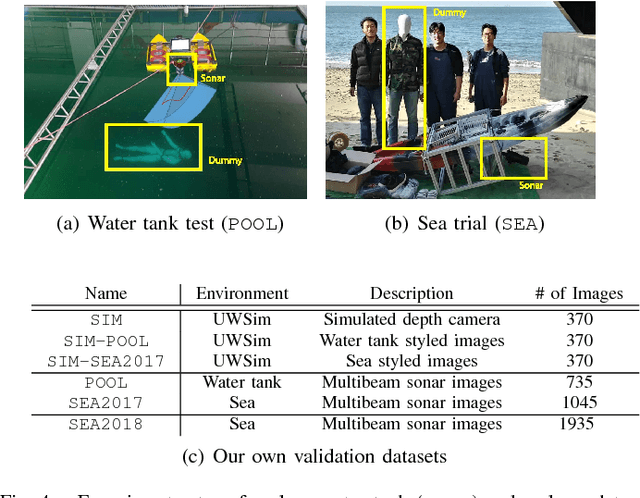
Among underwater perceptual sensors, imaging sonar has been highlighted for its perceptual robustness underwater. The major challenge of imaging sonar, however, arises from the difficulty in defining visual features despite limited resolution and high noise levels. Recent developments in deep learning provide a powerful solution for computer-vision researches using optical images. Unfortunately, deep learning-based approaches are not well established for imaging sonars, mainly due to the scant data in the training phase. Unlike the abundant publically available terrestrial images, obtaining underwater images is often costly, and securing enough underwater images for training is not straightforward. To tackle this issue, this paper presents a solution to this field's lack of data by introducing a novel end-to-end image-synthesizing method in the training image preparation phase. The proposed method present image synthesizing scheme to the images captured by an underwater simulator. Our synthetic images are based on the sonar imaging models and noisy characteristics to represent the real data obtained from the sea. We validate the proposed scheme by training using a simulator and by testing the simulated images with real underwater sonar images obtained from a water tank and the sea.
Patch-Based Image Similarity for Intraoperative 2D/3D Pelvis Registration During Periacetabular Osteotomy
Sep 23, 2019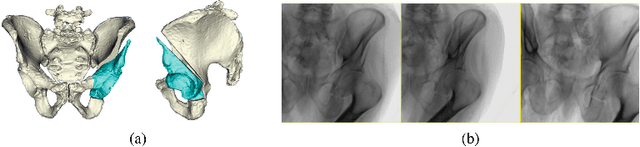
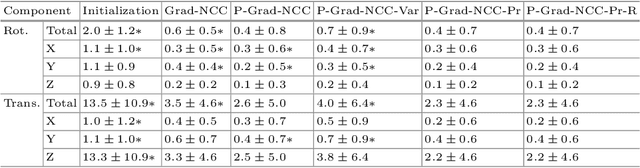
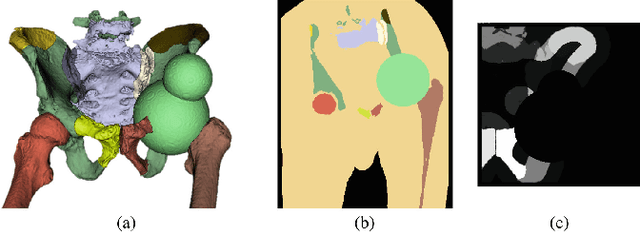
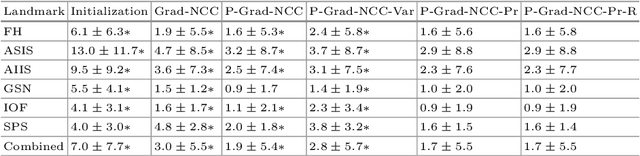
Periacetabular osteotomy is a challenging surgical procedure for treating developmental hip dysplasia, providing greater coverage of the femoral head via relocation of a patient's acetabulum. Since fluoroscopic imaging is frequently used in the surgical workflow, computer-assisted X-Ray navigation of osteotomes and the relocated acetabular fragment should be feasible. We use intensity-based 2D/3D registration to estimate the pelvis pose with respect to fluoroscopic images, recover relative poses of multiple views, and triangulate landmarks which may be used for navigation. Existing similarity metrics are unable to consistently account for the inherent mismatch between the preoperative intact pelvis, and the intraoperative reality of a fractured pelvis. To mitigate the effect of this mismatch, we continuously estimate the relevance of each pixel to solving the registration and use these values as weightings in a patch-based similarity metric. Limiting computation to randomly selected subsets of patches results in faster runtimes than existing patch-based methods. A simulation study was conducted with random fragment shapes, relocations, and fluoroscopic views, and the proposed method achieved a 1.7 mm mean triangulation error over all landmarks, compared to mean errors of 3 mm and 2.8 mm for the non-patched and image-intensity-variance-weighted patch similarity metrics, respectively.
* Presented at MICCAI CLIP Workshop 2018
AAformer: Auto-Aligned Transformer for Person Re-Identification
Apr 02, 2021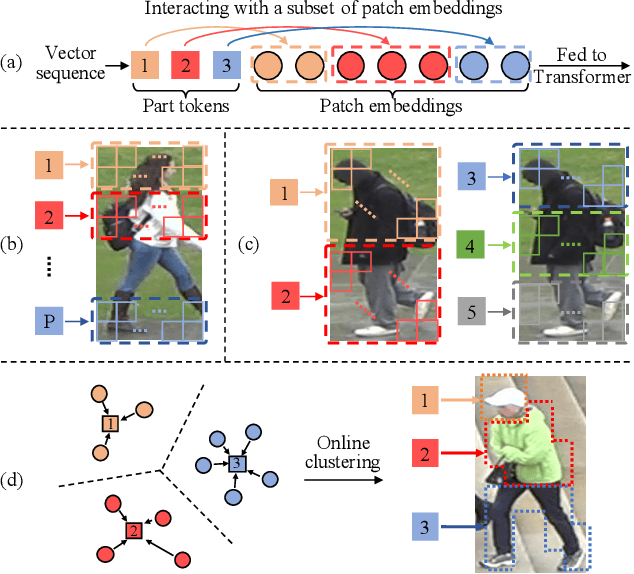
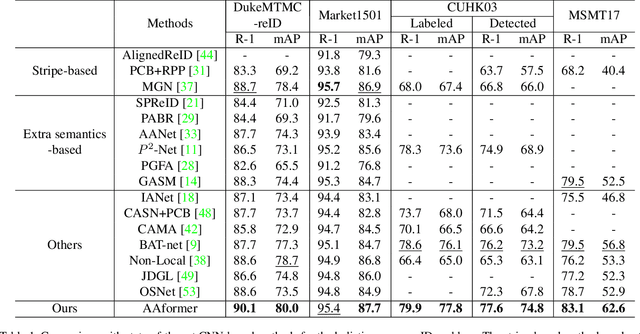
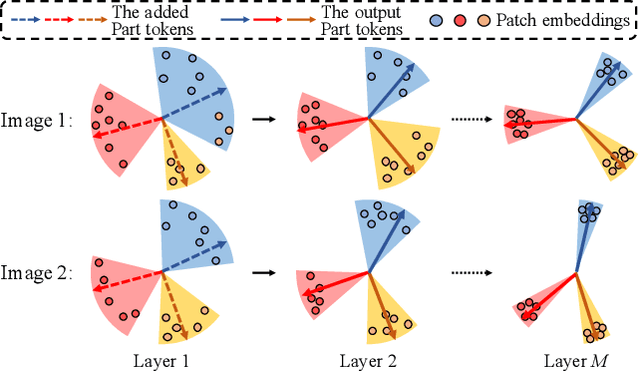
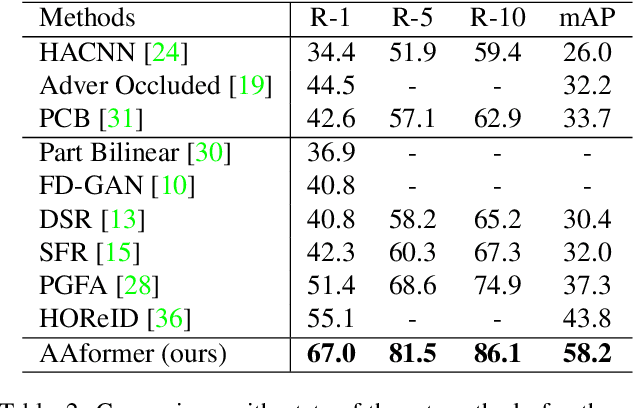
Transformer is showing its superiority over convolutional architectures in many vision tasks like image classification and object detection. However, the lacking of an explicit alignment mechanism limits its capability in person re-identification (re-ID), in which there are inevitable misalignment issues caused by pose/viewpoints variations, etc. On the other hand, the alignment paradigm of convolutional neural networks does not perform well in Transformer in our experiments. To address this problem, we develop a novel alignment framework for Transformer through adding the learnable vectors of "part tokens" to learn the part representations and integrating the part alignment into the self-attention. A part token only interacts with a subset of patch embeddings and learns to represent this subset. Based on the framework, we design an online Auto-Aligned Transformer (AAformer) to adaptively assign the patch embeddings of the same semantics to the identical part token in the running time. The part tokens can be regarded as the part prototypes, and a fast variant of Sinkhorn-Knopp algorithm is employed to cluster the patch embeddings to part tokens online. AAformer can be viewed as a new principled formulation for simultaneously learning both part alignment and part representations. Extensive experiments validate the effectiveness of part tokens and the superiority of AAformer over various state-of-the-art CNN-based methods. Our codes will be released.
A Dense-Depth Representation for VLAD descriptors in Content-Based Image Retrieval
Aug 15, 2018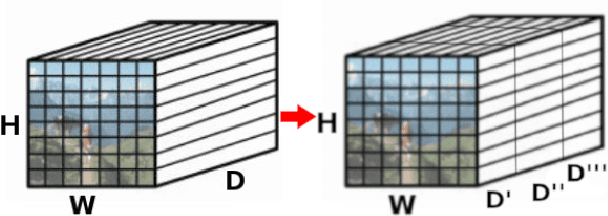
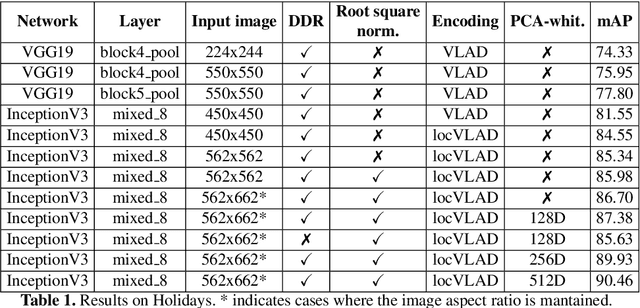
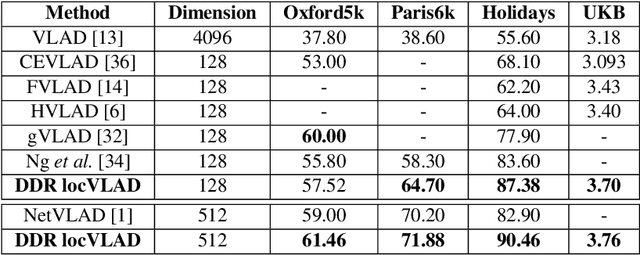
The recent advances brought by deep learning allowed to improve the performance in image retrieval tasks. Through the many convolutional layers, available in a Convolutional Neural Network (CNN), it is possible to obtain a hierarchy of features from the evaluated image. At every step, the patches extracted are smaller than the previous levels and more representative. Following this idea, this paper introduces a new detector applied on the feature maps extracted from pre-trained CNN. Specifically, this approach lets to increase the number of features in order to increase the performance of the aggregation algorithms like the most famous and used VLAD embedding. The proposed approach is tested on different public datasets: Holidays, Oxford5k, Paris6k and UKB.
Weakly-supervised multi-class object localization using only object counts as labels
Feb 23, 2021

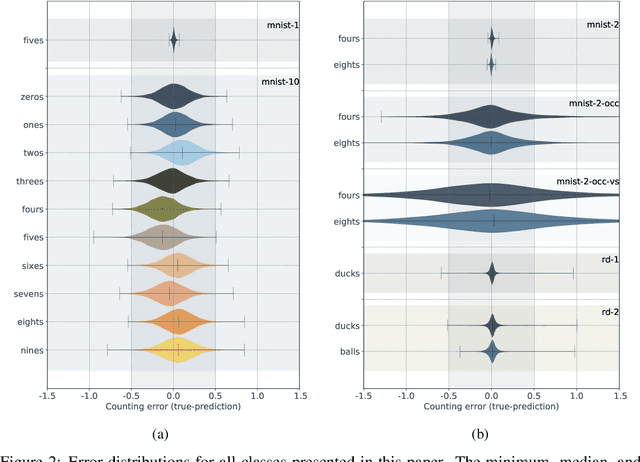

We demonstrate the use of an extensive deep neural network to localize instances of objects in images. The EDNN is naturally able to accurately perform multi-class counting using only ground truth count values as labels. Without providing any conceptual information, object annotations, or pixel segmentation information, the neural network is able to formulate its own conceptual representation of the items in the image. Using images labelled with only the counts of the objects present,the structure of the extensive deep neural network can be exploited to perform localization of the objects within the visual field. We demonstrate that a trained EDNN can be used to count objects in images much larger than those on which it was trained. In order to demonstrate our technique, we introduce seven new data sets: five progressively harder MNIST digit-counting data sets, and two datasets of 3d-rendered rubber ducks in various situations. On most of these datasets, the EDNN achieves greater than 99% test set accuracy in counting objects.