 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient
Jul 11, 2018
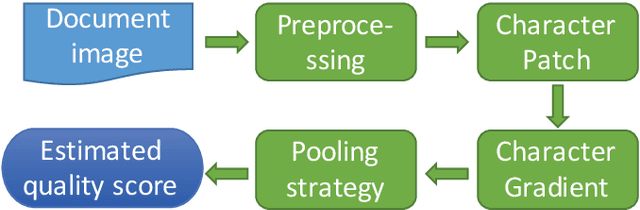


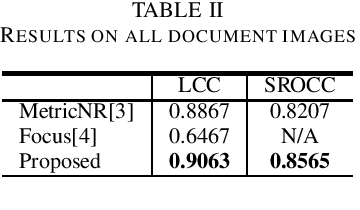
Document image quality assessment (DIQA) is an important and challenging problem in real applications. In order to predict the quality scores of document images, this paper proposes a novel no-reference DIQA method based on character gradient, where the OCR accuracy is used as a ground-truth quality metric. Character gradient is computed on character patches detected with the maximally stable extremal regions (MSER) based method. Character patches are essentially significant to character recognition and therefore suitable for use in estimating document image quality. Experiments on a benchmark dataset show that the proposed method outperforms the state-of-the-art methods in estimating the quality score of document images.
Evolving Learning Rate Optimizers for Deep Neural Networks
Mar 23, 2021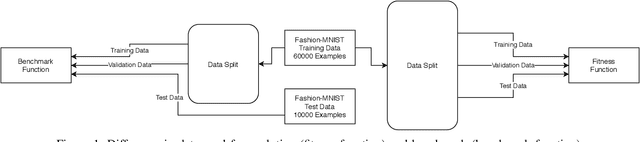

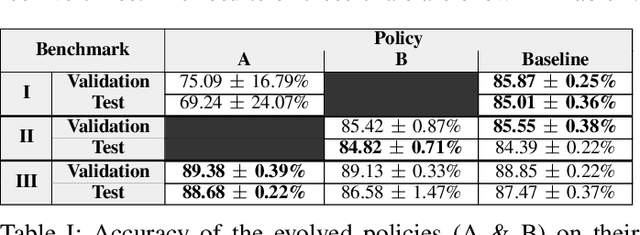
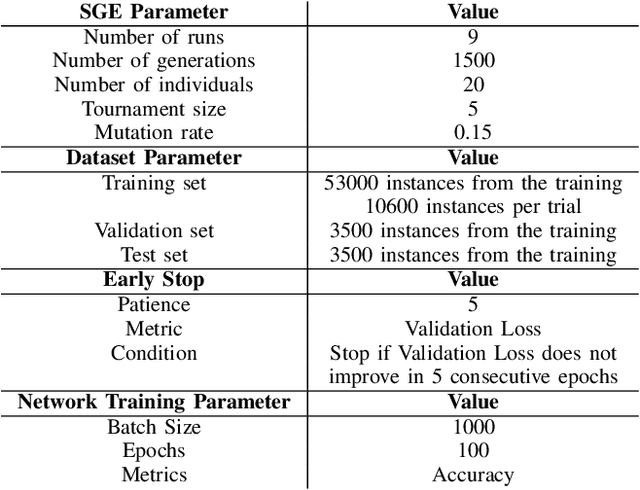
Artificial Neural Networks (ANNs) became popular due to their successful application difficult problems such image and speech recognition. However, when practitioners want to design an ANN they need to undergo laborious process of selecting a set of parameters and topology. Currently, there are several state-of-the art methods that allow for the automatic selection of some of these aspects. Learning Rate optimizers are a set of such techniques that search for good values of learning rates. Whilst these techniques are effective and have yielded good results over the years, they are general solution i.e. they do not consider the characteristics of a specific network. We propose a framework called AutoLR to automatically design Learning Rate Optimizers. Two versions of the system are detailed. The first one, Dynamic AutoLR, evolves static and dynamic learning rate optimizers based on the current epoch and the previous learning rate. The second version, Adaptive AutoLR, evolves adaptive optimizers that can fine tune the learning rate for each network eeight which makes them generally more effective. The results are competitive with the best state of the art methods, even outperforming them in some scenarios. Furthermore, the system evolved a classifier, ADES, that appears to be novel and innovative since, to the best of our knowledge, it has a structure that differs from state of the art methods.
Incremental Multi-Target Domain Adaptation for Object Detection with Efficient Domain Transfer
Apr 13, 2021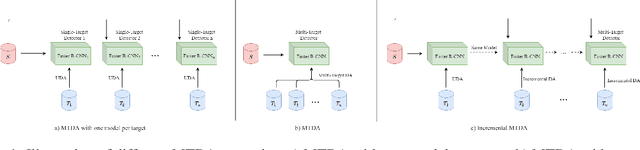
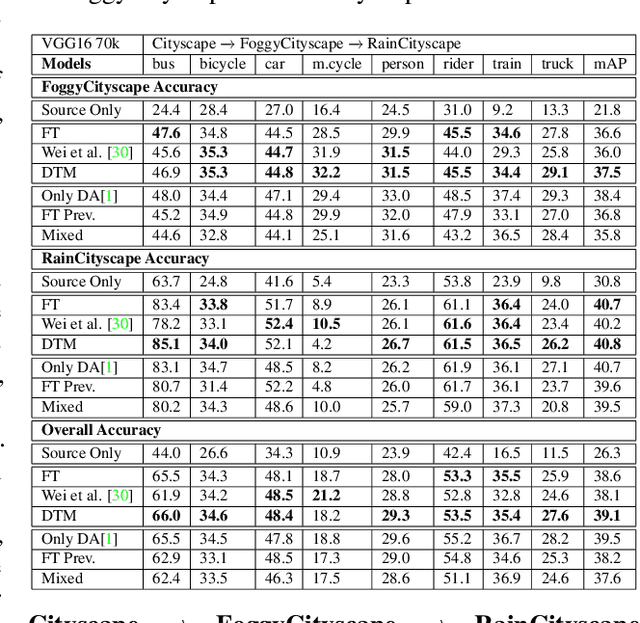
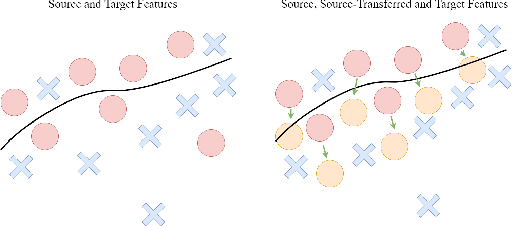
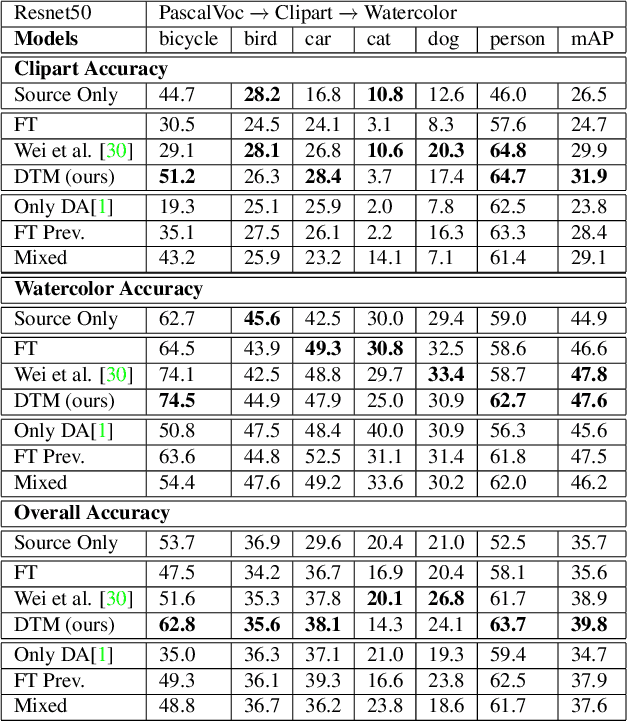
Techniques for multi-target domain adaptation (MTDA) seek to adapt a recognition model such that it can generalize well across multiple target domains. While several successful techniques have been proposed for unsupervised single-target domain adaptation (STDA) in object detection, adapting a model to multiple target domains using unlabeled image data remains a challenging and largely unexplored problem. Key challenges include the lack of bounding box annotations for target data, knowledge corruption, and the growing resource requirements needed to train accurate deep detection models. The later requirements are augmented by the need to retraining a model with previous-learned target data when adapting to each new target domain. Currently, the only MTDA technique in literature for object detection relies on distillation with a duplicated model to avoid knowledge corruption but does not leverage the source-target feature alignment after UDA. To address these challenges, we propose a new Incremental MTDA technique for object detection that can adapt a detector to multiple target domains, one at a time, without having to retain data of previously-learned target domains. Instead of distillation, our technique efficiently transfers source images to a joint target domains' space, on the fly, thereby preserving knowledge during incremental MTDA. Using adversarial training, our Domain Transfer Module (DTM) is optimized to trick the domain classifiers into classifying source images as though transferred into the target domain, thus allowing the DTM to generate samples close to a joint distribution of target domains. Our proposed technique is validated on different MTDA detection benchmarks, and results show it improving accuracy across multiple domains, despite the considerable reduction in complexity.
Detection and Localization of Facial Expression Manipulations
Mar 15, 2021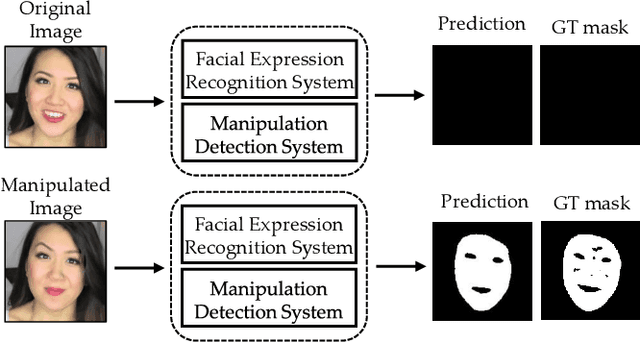
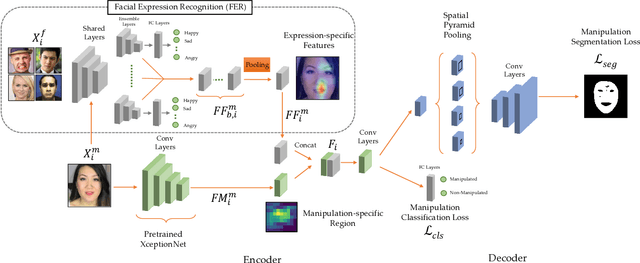

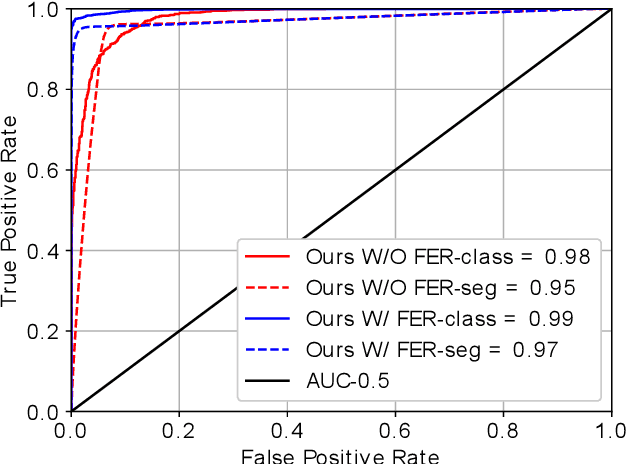
Concern regarding the wide-spread use of fraudulent images/videos in social media necessitates precise detection of such fraud. The importance of facial expressions in communication is widely known, and adversarial attacks often focus on manipulating the expression related features. Thus, it is important to develop methods that can detect manipulations in facial expressions, and localize the manipulated regions. To address this problem, we propose a framework that is able to detect manipulations in facial expression using a close combination of facial expression recognition and image manipulation methods. With the addition of feature maps extracted from the facial expression recognition framework, our manipulation detector is able to localize the manipulated region. We show that, on the Face2Face dataset, where there is abundant expression manipulation, our method achieves over 3% higher accuracy for both classification and localization of manipulations compared to state-of-the-art methods. In addition, results on the NeuralTextures dataset where the facial expressions corresponding to the mouth regions have been modified, show 2% higher accuracy in both classification and localization of manipulation. We demonstrate that the method performs at-par with the state-of-the-art methods in cases where the expression is not manipulated, but rather the identity is changed, thus ensuring generalizability of the approach.
Morphological Operation Residual Blocks: Enhancing 3D Morphological Feature Representation in Convolutional Neural Networks for Semantic Segmentation of Medical Images
Mar 06, 2021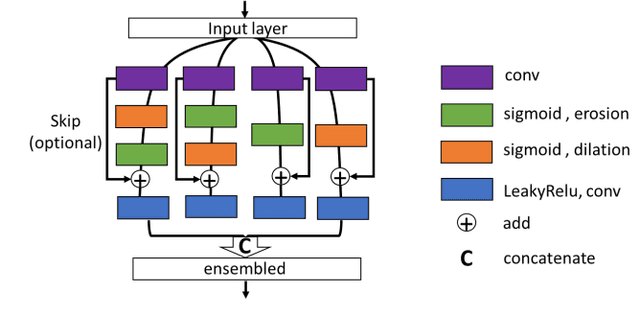
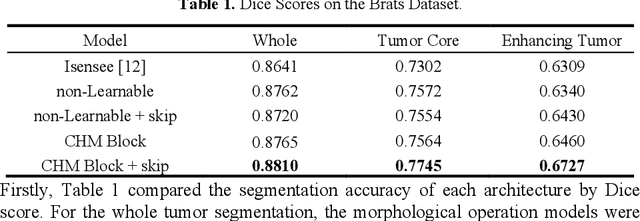
The shapes and morphology of the organs and tissues are important prior knowledge in medical imaging recognition and segmentation. The morphological operation is a well-known method for morphological feature extraction. As the morphological operation is performed well in hand-crafted image segmentation techniques, it is also promising to design an approach to approximate morphological operation in the convolutional networks. However, using the traditional convolutional neural network as a black-box is usually hard to specify the morphological operation action. Here, we introduced a 3D morphological operation residual block to extract morphological features in end-to-end deep learning models for semantic segmentation. This study proposed a novel network block architecture that embedded the morphological operation as an infinitely strong prior in the convolutional neural network. Several 3D deep learning models with the proposed morphological operation block were built and compared in different medical imaging segmentation tasks. Experimental results showed the proposed network achieved a relatively higher performance in the segmentation tasks comparing with the conventional approach. In conclusion, the novel network block could be easily embedded in traditional networks and efficiently reinforce the deep learning models for medical imaging segmentation.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021

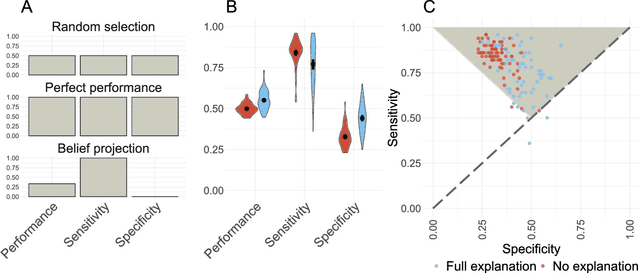
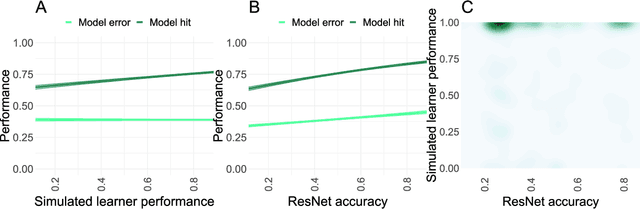
State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.
Mixture separability loss in a deep convolutional network for image classification
Jun 16, 2019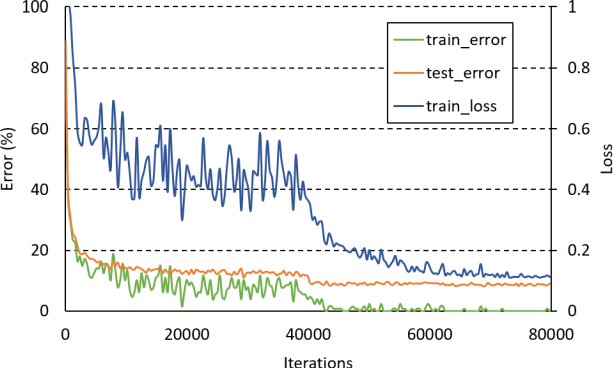
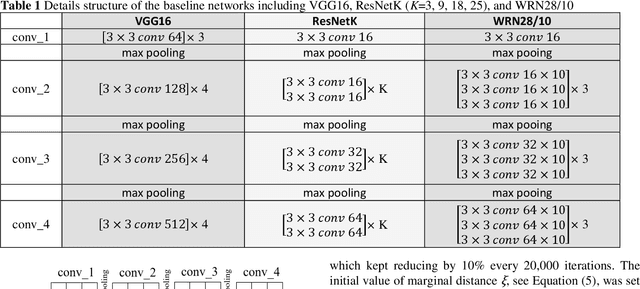
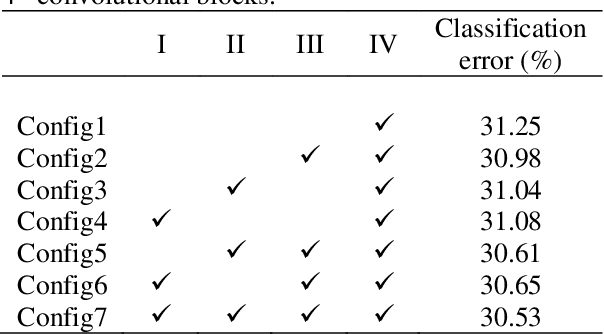
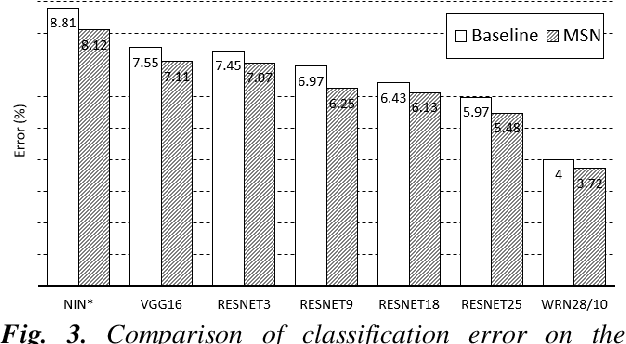
In machine learning, the cost function is crucial because it measures how good or bad a system is. In image classification, well-known networks only consider modifying the network structures and applying cross-entropy loss at the end of the network. However, using only cross-entropy loss causes a network to stop updating weights when all training images are correctly classified. This is the problem of the early saturation. This paper proposes a novel cost function, called mixture separability loss (MSL), which updates the weights of the network even when most of the training images are accurately predicted. MSL consists of between-class and within-class loss. Between-class loss maximizes the differences between inter-class images, whereas within-class loss minimizes the similarities between intra-class images. We designed the proposed loss function to attach to different convolutional layers in the network in order to utilize intermediate feature maps. Experiments show that a network with MSL deepens the learning process and obtains promising results with some public datasets, such as Street View House Number (SVHN), Canadian Institute for Advanced Research (CIFAR), and our self-collected Inha Computer Vision Lab (ICVL) gender dataset.
Cortical-inspired image reconstruction via sub-Riemannian geometry and hypoelliptic diffusion
Jan 11, 2018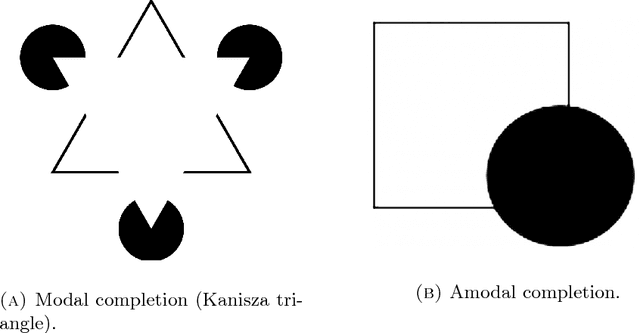
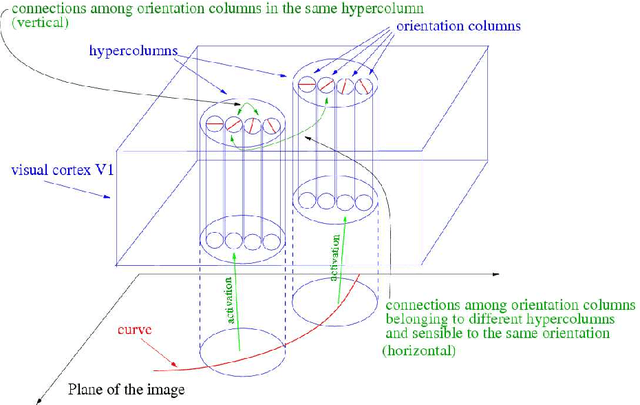
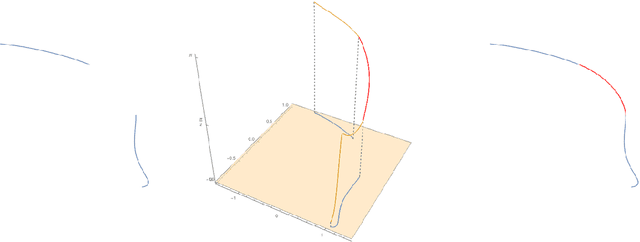
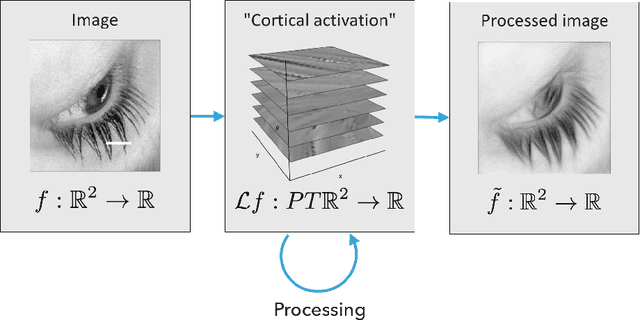
In this paper we review several algorithms for image inpainting based on the hypoelliptic diffusion naturally associated with a mathematical model of the primary visual cortex. In particular, we present one algorithm that does not exploit the information of where the image is corrupted, and others that do it. While the first algorithm is able to reconstruct only images that our visual system is still capable of recognize, we show that those of the second type completely transcend such limitation providing reconstructions at the state-of-the-art in image inpainting. This can be interpreted as a validation of the fact that our visual cortex actually encodes the first type of algorithm.
A Locally Adapting Technique for Boundary Detection using Image Segmentation
Jul 27, 2017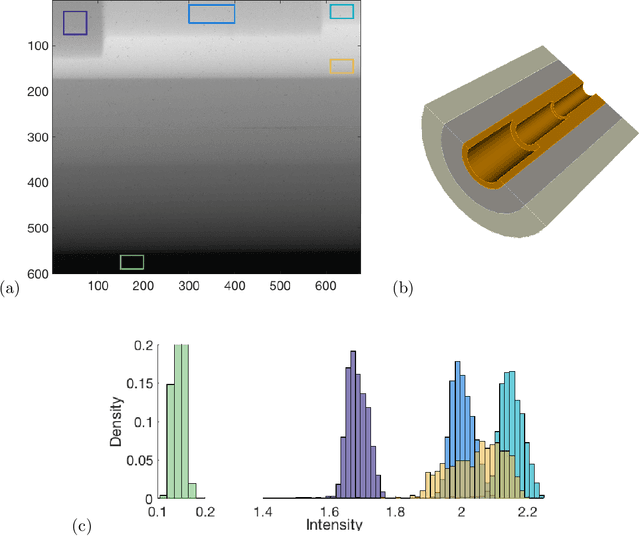
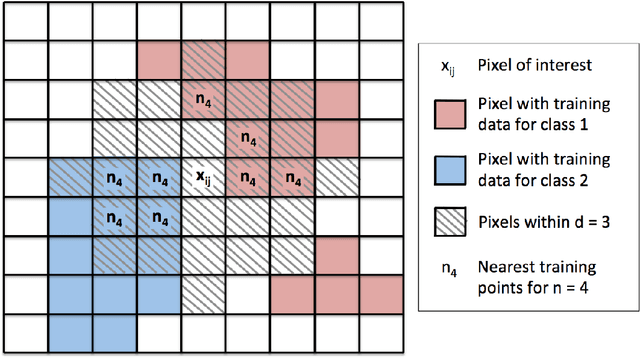
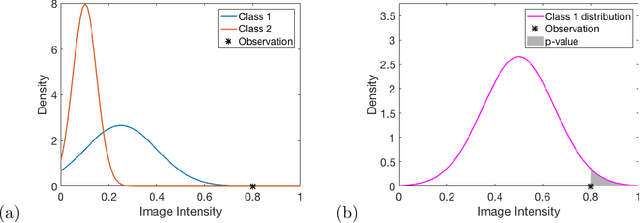
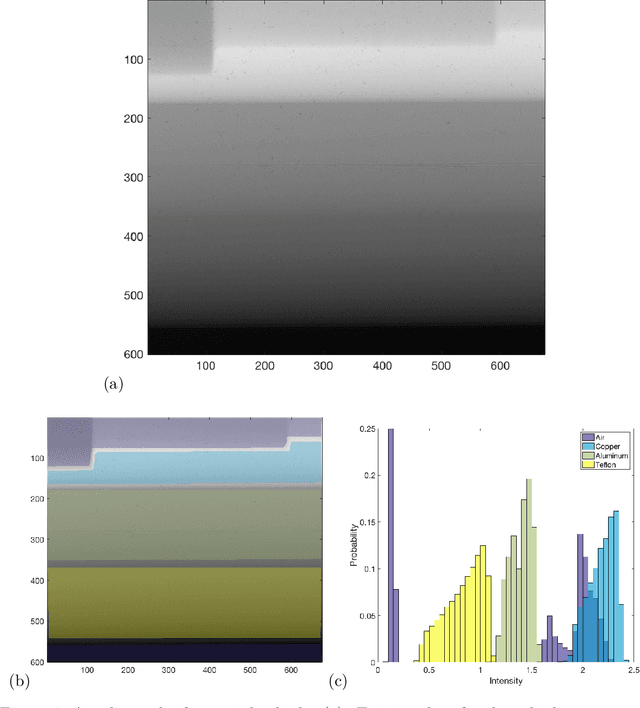
Rapid growth in the field of quantitative digital image analysis is paving the way for researchers to make precise measurements about objects in an image. To compute quantities from the image such as the density of compressed materials or the velocity of a shockwave, we must determine object boundaries. Images containing regions that each have a spatial trend in intensity are of particular interest. We present a supervised image segmentation method that incorporates spatial information to locate boundaries between regions with overlapping intensity histograms. The segmentation of a pixel is determined by comparing its intensity to distributions from local, nearby pixel intensities. Because of the statistical nature of the algorithm, we use maximum likelihood estimation theory to quantify uncertainty about each boundary. We demonstrate the success of this algorithm on a radiograph of a multicomponent cylinder and on an optical image of a laser-induced shockwave, and we provide final boundary locations with associated bands of uncertainty.
An Objective Evaluation Metric for image fusion based on Del Operator
May 25, 2019
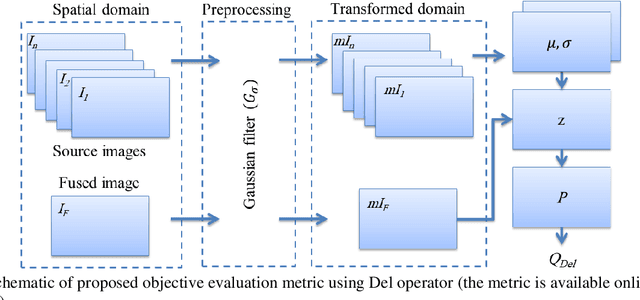
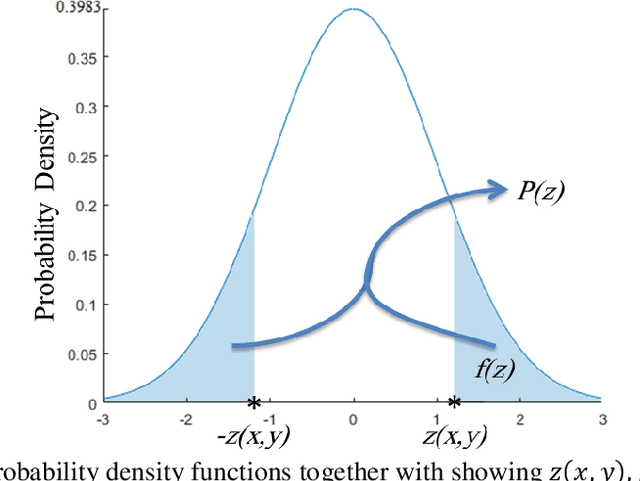
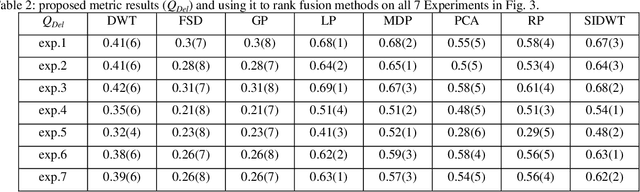
In this paper, a novel objective evaluation metric for image fusion is presented. Remarkable and attractive points of the proposed metric are that it has no parameter, the result is probability in the range of [0, 1] and it is free from illumination dependence. This metric is easy to implement and the result is computed in four steps: (1) Smoothing the images using Gaussian filter. (2) Transforming images to a vector field using Del operator. (3) Computing the normal distribution function ({\mu},{\sigma}) for each corresponding pixel, and converting to the standard normal distribution function. (4) Computing the probability of being well-behaved fusion method as the result. To judge the quality of the proposed metric, it is compared to thirteen well-known non-reference objective evaluation metrics, where eight fusion methods are employed on seven experiments of multimodal medical images. The experimental results and statistical comparisons show that in contrast to the previously objective evaluation metrics the proposed one performs better in terms of both agreeing with human visual perception and evaluating fusion methods that are not performed at the same level.