 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilling Object Detectors via Decoupled Features
Mar 26, 2021
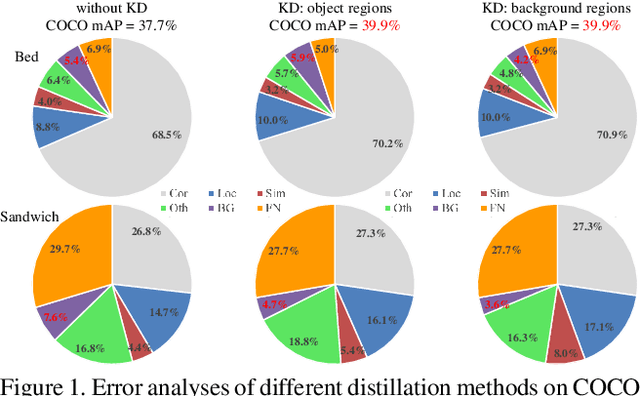
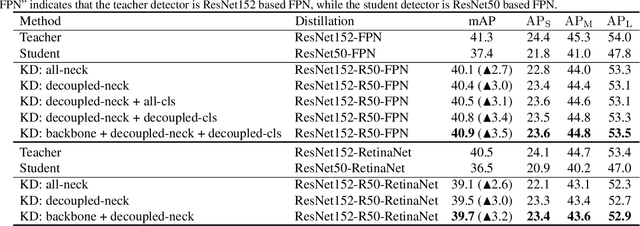

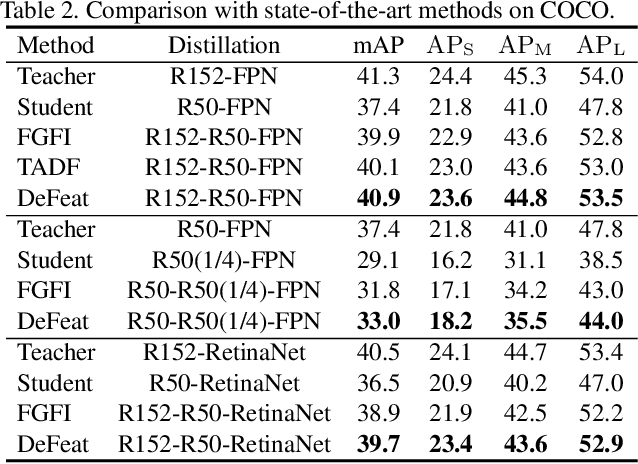
Knowledge distillation is a widely used paradigm for inheriting information from a complicated teacher network to a compact student network and maintaining the strong performance. Different from image classification, object detectors are much more sophisticated with multiple loss functions in which features that semantic information rely on are tangled. In this paper, we point out that the information of features derived from regions excluding objects are also essential for distilling the student detector, which is usually ignored in existing approaches. In addition, we elucidate that features from different regions should be assigned with different importance during distillation. To this end, we present a novel distillation algorithm via decoupled features (DeFeat) for learning a better student detector. Specifically, two levels of decoupled features will be processed for embedding useful information into the student, i.e., decoupled features from neck and decoupled proposals from classification head. Extensive experiments on various detectors with different backbones show that the proposed DeFeat is able to surpass the state-of-the-art distillation methods for object detection. For example, DeFeat improves ResNet50 based Faster R-CNN from 37.4% to 40.9% mAP, and improves ResNet50 based RetinaNet from 36.5% to 39.7% mAP on COCO benchmark. Our implementation is available at https://github.com/ggjy/DeFeat.pytorch.
UPSET and ANGRI : Breaking High Performance Image Classifiers
Jul 04, 2017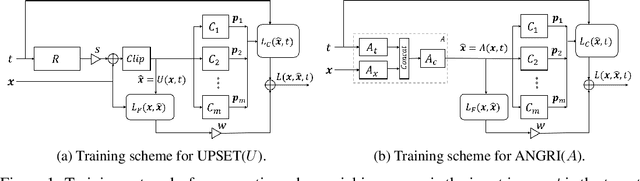
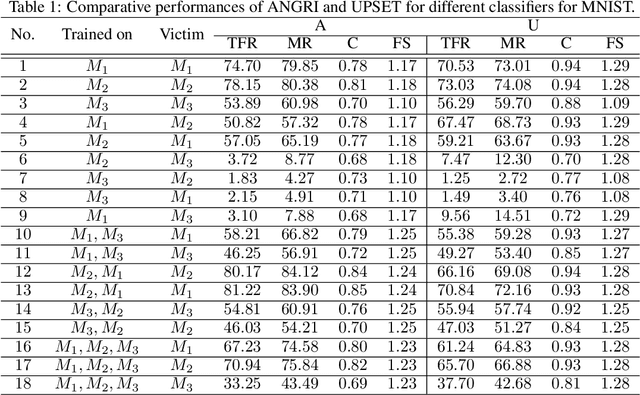

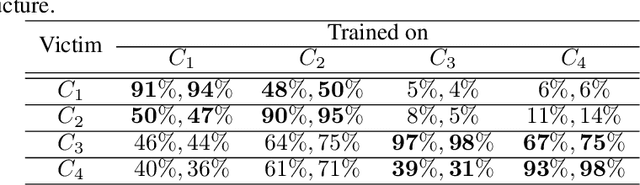
In this paper, targeted fooling of high performance image classifiers is achieved by developing two novel attack methods. The first method generates universal perturbations for target classes and the second generates image specific perturbations. Extensive experiments are conducted on MNIST and CIFAR10 datasets to provide insights about the proposed algorithms and show their effectiveness.
Joint Regression and Ranking for Image Enhancement
Apr 05, 2017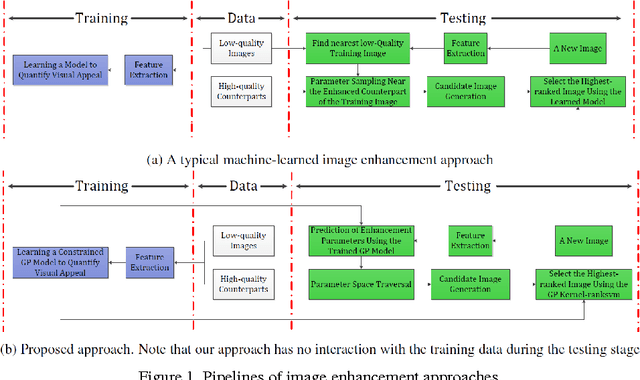
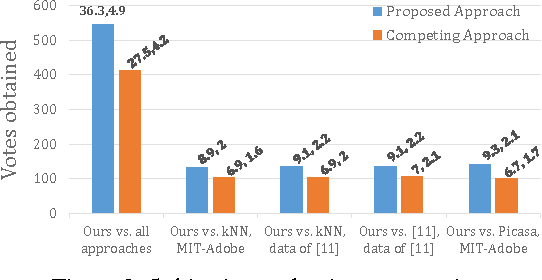
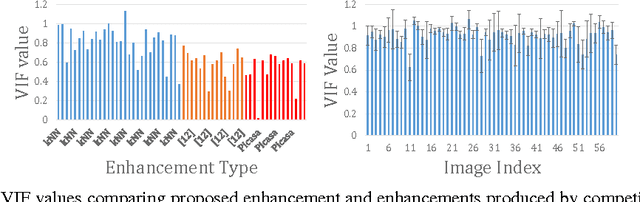

Research on automated image enhancement has gained momentum in recent years, partially due to the need for easy-to-use tools for enhancing pictures captured by ubiquitous cameras on mobile devices. Many of the existing leading methods employ machine-learning-based techniques, by which some enhancement parameters for a given image are found by relating the image to the training images with known enhancement parameters. While knowing the structure of the parameter space can facilitate search for the optimal solution, none of the existing methods has explicitly modeled and learned that structure. This paper presents an end-to-end, novel joint regression and ranking approach to model the interaction between desired enhancement parameters and images to be processed, employing a Gaussian process (GP). GP allows searching for ideal parameters using only the image features. The model naturally leads to a ranking technique for comparing images in the induced feature space. Comparative evaluation using the ground-truth based on the MIT-Adobe FiveK dataset plus subjective tests on an additional data-set were used to demonstrate the effectiveness of the proposed approach.
Few-Shot Human Motion Transfer by Personalized Geometry and Texture Modeling
Mar 26, 2021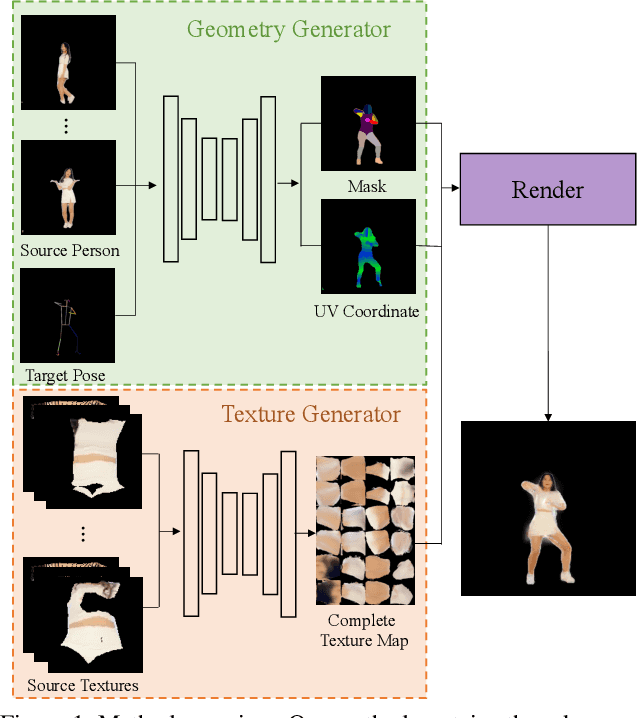

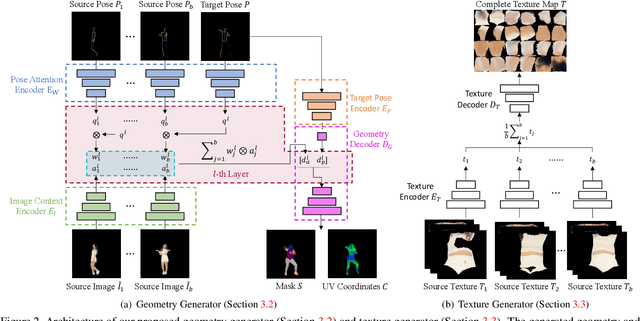
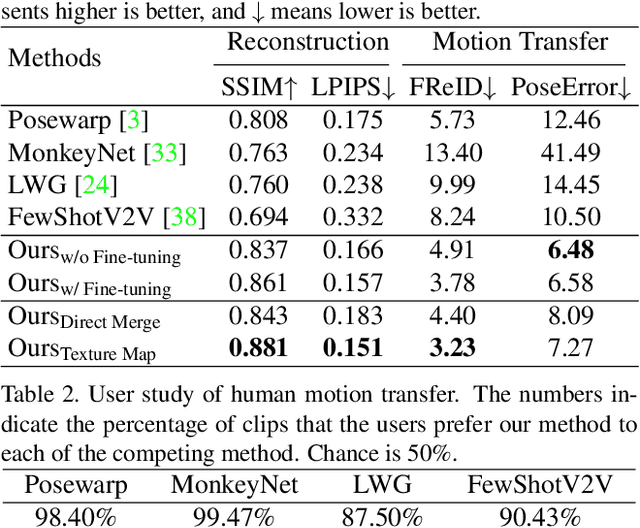
We present a new method for few-shot human motion transfer that achieves realistic human image generation with only a small number of appearance inputs. Despite recent advances in single person motion transfer, prior methods often require a large number of training images and take long training time. One promising direction is to perform few-shot human motion transfer, which only needs a few of source images for appearance transfer. However, it is particularly challenging to obtain satisfactory transfer results. In this paper, we address this issue by rendering a human texture map to a surface geometry (represented as a UV map), which is personalized to the source person. Our geometry generator combines the shape information from source images, and the pose information from 2D keypoints to synthesize the personalized UV map. A texture generator then generates the texture map conditioned on the texture of source images to fill out invisible parts. Furthermore, we may fine-tune the texture map on the manifold of the texture generator from a few source images at the test time, which improves the quality of the texture map without over-fitting or artifacts. Extensive experiments show the proposed method outperforms state-of-the-art methods both qualitatively and quantitatively. Our code is available at https://github.com/HuangZhiChao95/FewShotMotionTransfer.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Feb 25, 2021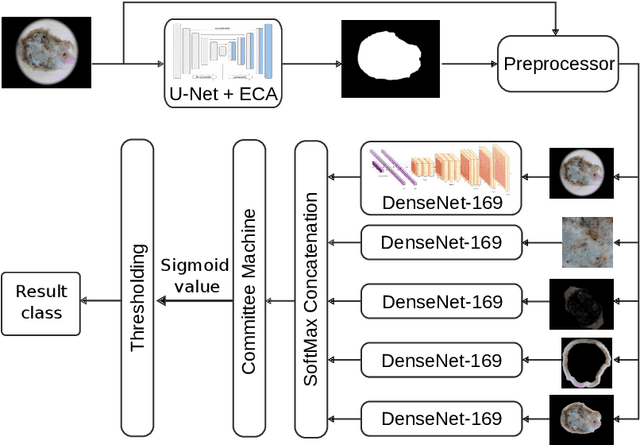
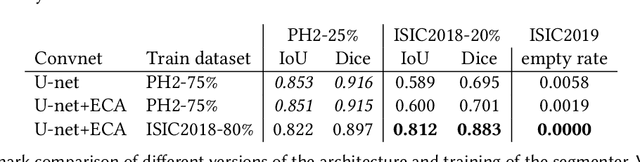
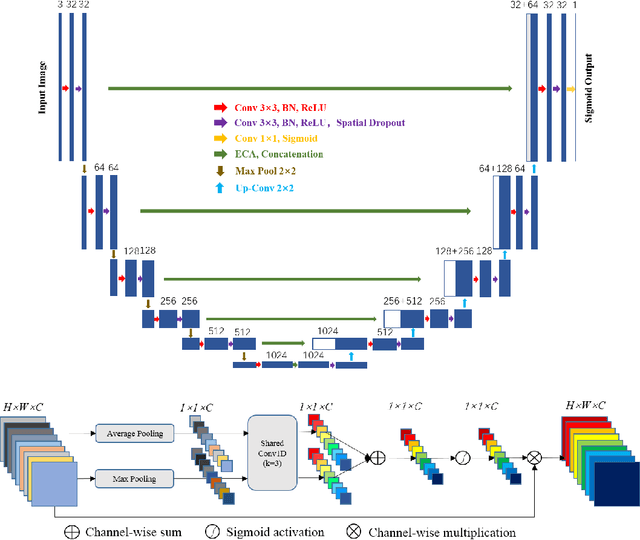
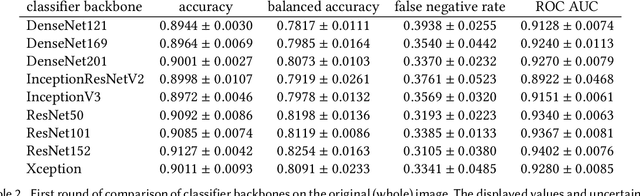
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.
Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Mar 26, 2021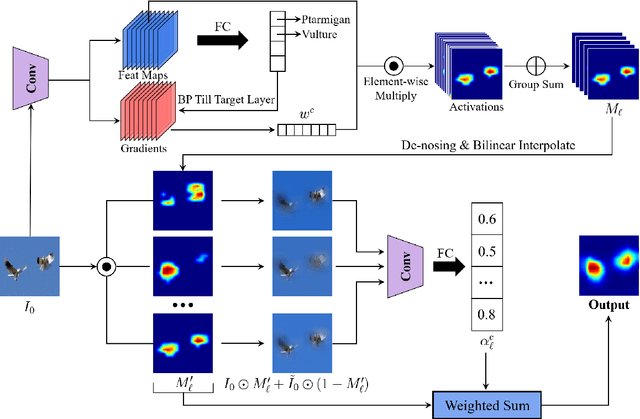

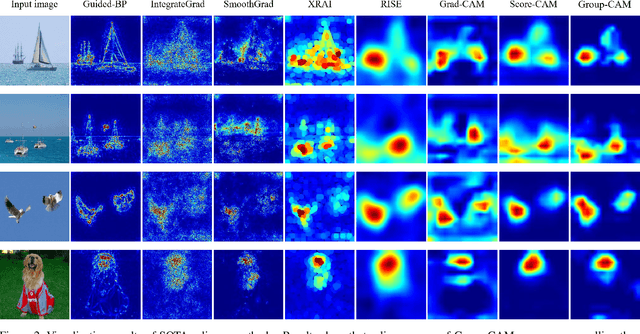
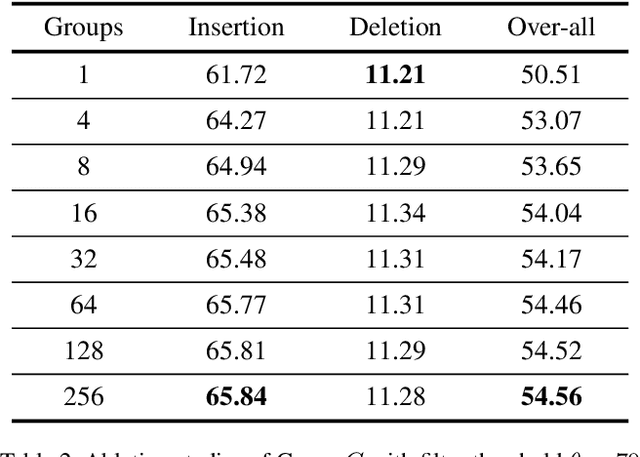
In this paper, we propose an efficient saliency map generation method, called Group score-weighted Class Activation Mapping (Group-CAM), which adopts the "split-transform-merge" strategy to generate saliency maps. Specifically, for an input image, the class activations are firstly split into groups. In each group, the sub-activations are summed and de-noised as an initial mask. After that, the initial masks are transformed with meaningful perturbations and then applied to preserve sub-pixels of the input (i.e., masked inputs), which are then fed into the network to calculate the confidence scores. Finally, the initial masks are weighted summed to form the final saliency map, where the weights are confidence scores produced by the masked inputs. Group-CAM is efficient yet effective, which only requires dozens of queries to the network while producing target-related saliency maps. As a result, Group-CAM can be served as an effective data augment trick for fine-tuning the networks. We comprehensively evaluate the performance of Group-CAM on common-used benchmarks, including deletion and insertion tests on ImageNet-1k, and pointing game tests on COCO2017. Extensive experimental results demonstrate that Group-CAM achieves better visual performance than the current state-of-the-art explanation approaches. The code is available at https://github.com/wofmanaf/Group-CAM.
Generative Models Improve Radiomics Reproducibility in Low Dose CTs: A Simulation Study
Apr 30, 2021
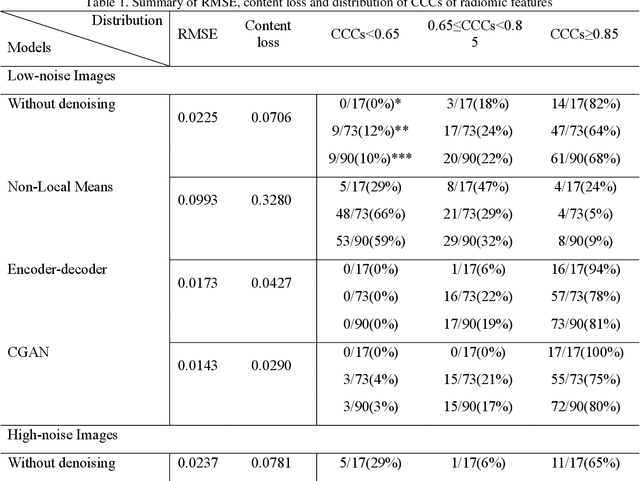
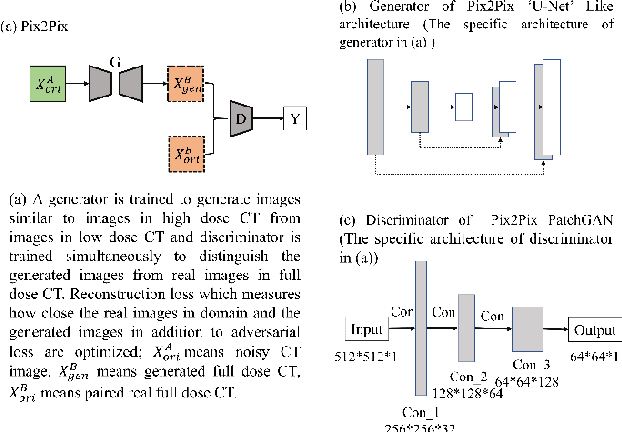
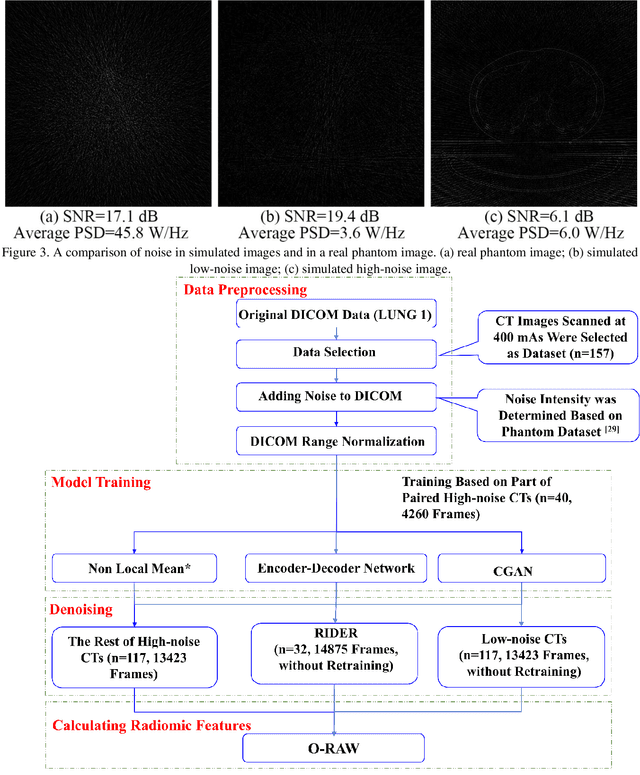
Radiomics is an active area of research in medical image analysis, the low reproducibility of radiomics has limited its applicability to clinical practice. This issue is especially prominent when radiomic features are calculated from noisy images, such as low dose computed tomography (CT) scans. In this article, we investigate the possibility of improving the reproducibility of radiomic features calculated on noisy CTs by using generative models for denoising.One traditional denoising method - non-local means - and two generative models - encoder-decoder networks (EDN) and conditional generative adversarial networks (CGANs) - were selected as the test models. We added noise to the sinograms of full dose CTs to mimic low dose CTs with two different levels of noise: low-noise CT and high-noise CT. Models were trained on high-noise CTs and used to denoise low-noise CTs without re-training. We also test the performance of our model in real data, using dataset of same-day repeat low dose CTs to assess the reproducibility of radiomic features in denoised images. The EDN and the CGAN improved the concordance correlation coefficients (CCC) of radiomic features for low-noise images from 0.87 to 0.92 and for high-noise images from 0.68 to 0.92 respectively. Moreover, the EDN and the CGAN improved the test-retest reliability of radiomic features (mean CCC increased from 0.89 to 0.94) based on real low dose CTs. The results show that denoising using EDN and CGANs can improve the reproducibility of radiomic features calculated on noisy CTs. Moreover, images with different noise levels can be denoised to improve the reproducibility using these models without re-training, as long as the noise intensity is equal or lower than that in high-noise CTs. To the authors' knowledge, this is the first effort to improve the reproducibility of radiomic features calculated on low dose CT scans.
Robust Regression For Image Binarization Under Heavy Noises and Nonuniform Background
Jul 06, 2017
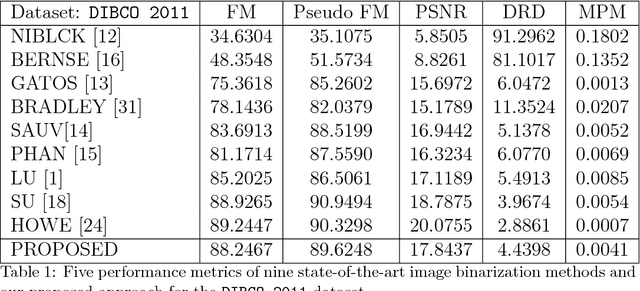
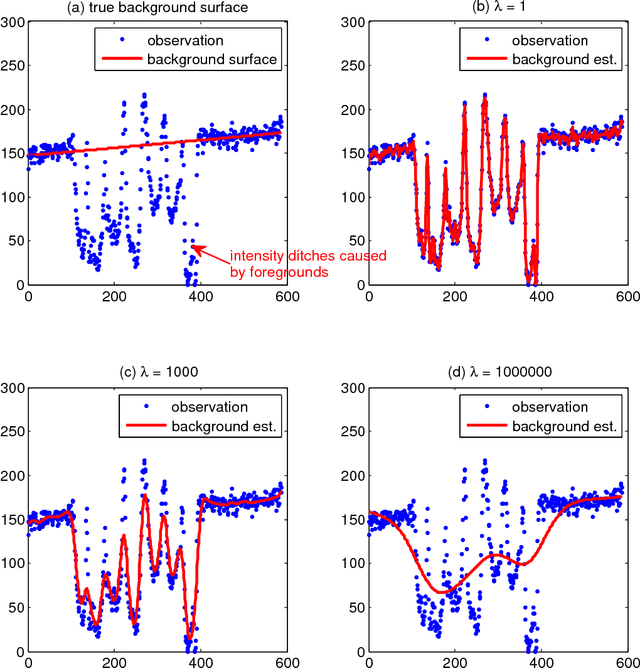
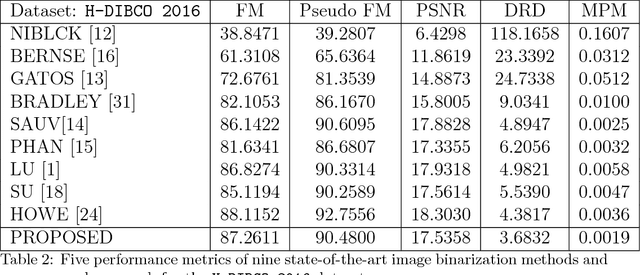
This paper presents a robust regression approach for image binarization under significant background variations and observation noises. The work is motivated by the need of identifying foreground regions in noisy microscopic image or degraded document images, where significant background variation and severe noise make an image binarization challenging. The proposed method first estimates the background of an input image, subtracts the estimated background from the input image, and apply a global thresholding to the subtracted outcome for achieving a binary image of foregrounds. A robust regression approach was proposed to estimate the background intensity surface with minimal effects of foreground intensities and noises, and a global threshold selector was proposed on the basis of a model selection criterion in a sparse regression. The proposed approach was validated using 26 test images and the corresponding ground truths, and the outcomes of the proposed work were compared with those from nine existing image binarization methods. The approach was also combined with three state-of-the-art morphological segmentation methods to show how the proposed approach can improve their image segmentation outcomes.
You Only Look One-level Feature
Mar 17, 2021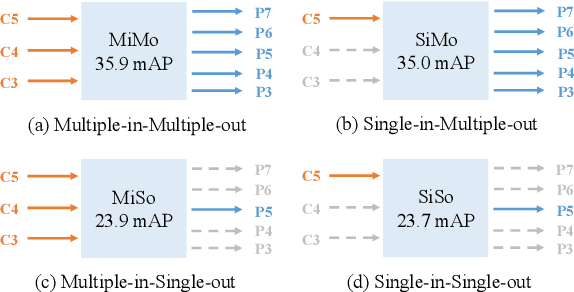
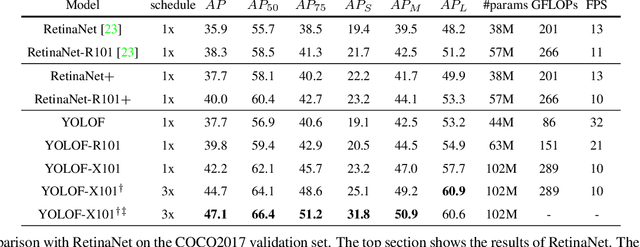

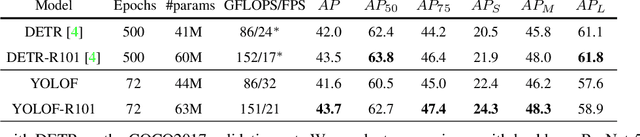
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being $2.5\times$ faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with $7\times$ less training epochs. With an image size of $608\times608$, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is $13\%$ faster than YOLOv4. Code is available at \url{https://github.com/megvii-model/YOLOF}.
Deep learning with self-supervision and uncertainty regularization to count fish in underwater images
Apr 30, 2021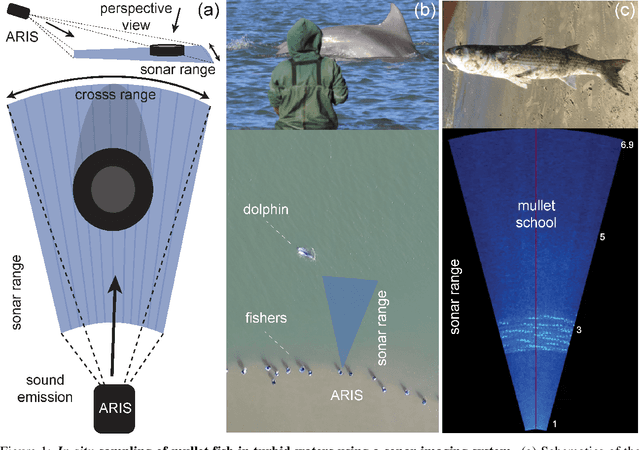
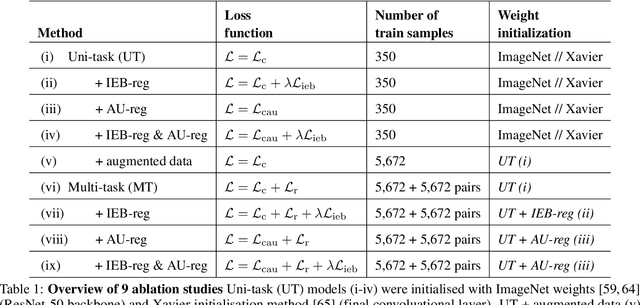
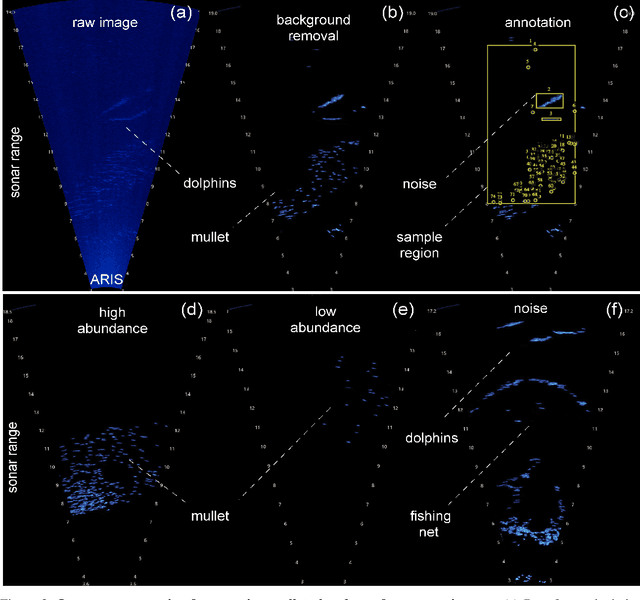
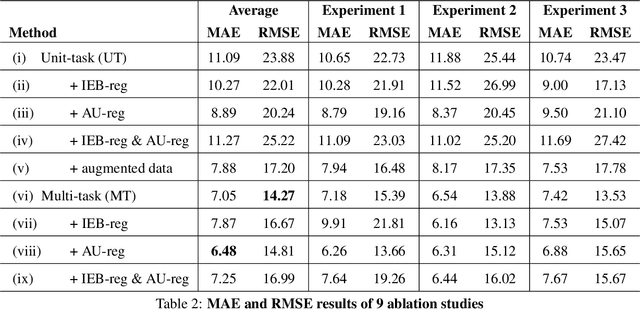
Effective conservation actions require effective population monitoring. However, accurately counting animals in the wild to inform conservation decision-making is difficult. Monitoring populations through image sampling has made data collection cheaper, wide-reaching and less intrusive but created a need to process and analyse this data efficiently. Counting animals from such data is challenging, particularly when densely packed in noisy images. Attempting this manually is slow and expensive, while traditional computer vision methods are limited in their generalisability. Deep learning is the state-of-the-art method for many computer vision tasks, but it has yet to be properly explored to count animals. To this end, we employ deep learning, with a density-based regression approach, to count fish in low-resolution sonar images. We introduce a large dataset of sonar videos, deployed to record wild mullet schools (Mugil liza), with a subset of 500 labelled images. We utilise abundant unlabelled data in a self-supervised task to improve the supervised counting task. For the first time in this context, by introducing uncertainty quantification, we improve model training and provide an accompanying measure of prediction uncertainty for more informed biological decision-making. Finally, we demonstrate the generalisability of our proposed counting framework through testing it on a recent benchmark dataset of high-resolution annotated underwater images from varying habitats (DeepFish). From experiments on both contrasting datasets, we demonstrate our network outperforms the few other deep learning models implemented for solving this task. By providing an open-source framework along with training data, our study puts forth an efficient deep learning template for crowd counting aquatic animals thereby contributing effective methods to assess natural populations from the ever-increasing visual data.