 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do stable neural networks exist for classification problems? -- A new view on stability in AI
Jan 15, 2024
In deep learning (DL) the instability phenomenon is widespread and well documented, most commonly using the classical measure of stability, the Lipschitz constant. While a small Lipchitz constant is traditionally viewed as guarantying stability, it does not capture the instability phenomenon in DL for classification well. The reason is that a classification function -- which is the target function to be approximated -- is necessarily discontinuous, thus having an 'infinite' Lipchitz constant. As a result, the classical approach will deem every classification function unstable, yet basic classification functions a la 'is there a cat in the image?' will typically be locally very 'flat' -- and thus locally stable -- except at the decision boundary. The lack of an appropriate measure of stability hinders a rigorous theory for stability in DL, and consequently, there are no proper approximation theoretic results that can guarantee the existence of stable networks for classification functions. In this paper we introduce a novel stability measure $\mathscr{S}(f)$, for any classification function $f$, appropriate to study the stability of discontinuous functions and their approximations. We further prove two approximation theorems: First, for any $\epsilon > 0$ and any classification function $f$ on a \emph{compact set}, there is a neural network (NN) $\psi$, such that $\psi - f \neq 0$ only on a set of measure $< \epsilon$, moreover, $\mathscr{S}(\psi) \geq \mathscr{S}(f) - \epsilon$ (as accurate and stable as $f$ up to $\epsilon$). Second, for any classification function $f$ and $\epsilon > 0$, there exists a NN $\psi$ such that $\psi = f$ on the set of points that are at least $\epsilon$ away from the decision boundary.
Harnessing Machine Learning for Discerning AI-Generated Synthetic Images
Jan 14, 2024In the realm of digital media, the advent of AI-generated synthetic images has introduced significant challenges in distinguishing between real and fabricated visual content. These images, often indistinguishable from authentic ones, pose a threat to the credibility of digital media, with potential implications for disinformation and fraud. Our research addresses this challenge by employing machine learning techniques to discern between AI-generated and genuine images. Central to our approach is the CIFAKE dataset, a comprehensive collection of images labeled as "Real" and "Fake". We refine and adapt advanced deep learning architectures like ResNet, VGGNet, and DenseNet, utilizing transfer learning to enhance their precision in identifying synthetic images. We also compare these with a baseline model comprising a vanilla Support Vector Machine (SVM) and a custom Convolutional Neural Network (CNN). The experimental results were significant, demonstrating that our optimized deep learning models outperform traditional methods, with DenseNet achieving an accuracy of 97.74%. Our application study contributes by applying and optimizing these advanced models for synthetic image detection, conducting a comparative analysis using various metrics, and demonstrating their superior capability in identifying AI-generated images over traditional machine learning techniques. This research not only advances the field of digital media integrity but also sets a foundation for future explorations into the ethical and technical dimensions of AI-generated content in digital media.
GazeCLIP: Towards Enhancing Gaze Estimation via Text Guidance
Jan 07, 2024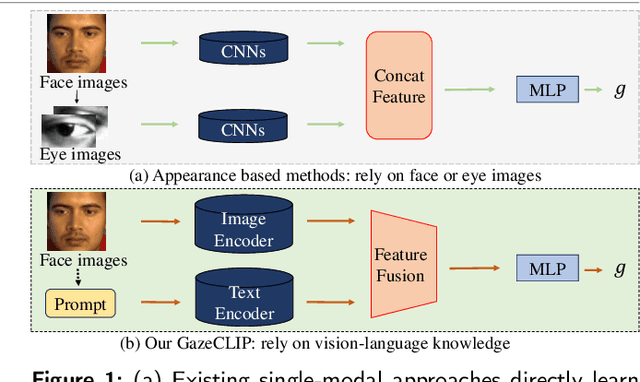

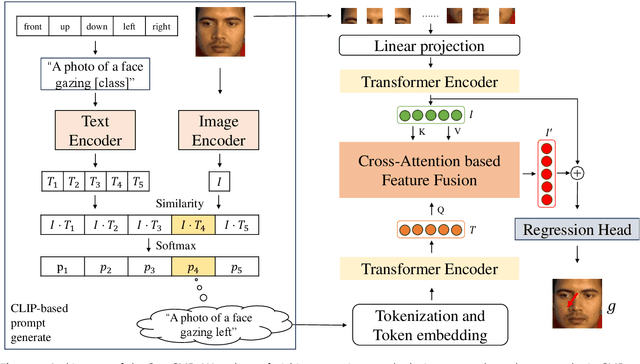
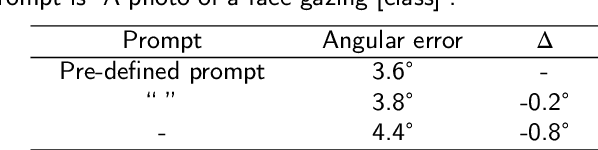
Over the past decade, visual gaze estimation has garnered growing attention within the research community, thanks to its wide-ranging application scenarios. While existing estimation approaches have achieved remarkable success in enhancing prediction accuracy, they primarily infer gaze directions from single-image signals and discard the huge potentials of the currently dominant text guidance. Notably, visual-language collaboration has been extensively explored across a range of visual tasks, such as image synthesis and manipulation, leveraging the remarkable transferability of large-scale Contrastive Language-Image Pre-training (CLIP) model. Nevertheless, existing gaze estimation approaches ignore the rich semantic cues conveyed by linguistic signals and priors in CLIP feature space, thereby yielding performance setbacks. In pursuit of making up this gap, we delve deeply into the text-eye collaboration protocol and introduce a novel gaze estimation framework in this paper, referred to as GazeCLIP. Specifically, we intricately design a linguistic description generator to produce text signals with coarse directional cues. Additionally, a CLIP-based backbone that excels in characterizing text-eye pairs for gaze estimation is presented. This is followed by the implementation of a fine-grained multi-modal fusion module aimed at modeling the interrelationships between heterogeneous inputs. Extensive experiments on three challenging datasets demonstrate the superiority of the proposed GazeCLIP which surpasses the previous approaches and achieves the state-of-the-art estimation accuracy.
Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation
Jan 12, 2024Assessing long-form responses generated by Vision-Language Models (VLMs) is challenging. It not only requires checking whether the VLM follows the given instruction but also verifying whether the text output is properly grounded on the given image. Inspired by the recent approach of evaluating LMs with LMs, in this work, we propose to evaluate VLMs with VLMs. For this purpose, we present a new feedback dataset called the Perception Collection, encompassing 15K customized score rubrics that users might care about during assessment. Using the Perception Collection, we train Prometheus-Vision, the first open-source VLM evaluator model that can understand the user-defined score criteria during evaluation. Prometheus-Vision shows the highest Pearson correlation with human evaluators and GPT-4V among open-source models, showing its effectiveness for transparent and accessible evaluation of VLMs. We open-source our code, dataset, and model at https://github.com/kaistAI/prometheus-vision
Progressive Frequency-Aware Network for Laparoscopic Image Desmoking
Dec 19, 2023Laparoscopic surgery offers minimally invasive procedures with better patient outcomes, but smoke presence challenges visibility and safety. Existing learning-based methods demand large datasets and high computational resources. We propose the Progressive Frequency-Aware Network (PFAN), a lightweight GAN framework for laparoscopic image desmoking, combining the strengths of CNN and Transformer for progressive information extraction in the frequency domain. PFAN features CNN-based Multi-scale Bottleneck-Inverting (MBI) Blocks for capturing local high-frequency information and Locally-Enhanced Axial Attention Transformers (LAT) for efficiently handling global low-frequency information. PFAN efficiently desmokes laparoscopic images even with limited training data. Our method outperforms state-of-the-art approaches in PSNR, SSIM, CIEDE2000, and visual quality on the Cholec80 dataset and retains only 629K parameters. Our code and models are made publicly available at: https://github.com/jlzcode/PFAN.
Advancing Image Retrieval with Few-Shot Learning and Relevance Feedback
Dec 18, 2023With such a massive growth in the number of images stored, efficient search in a database has become a crucial endeavor managed by image retrieval systems. Image Retrieval with Relevance Feedback (IRRF) involves iterative human interaction during the retrieval process, yielding more meaningful outcomes. This process can be generally cast as a binary classification problem with only {\it few} labeled samples derived from user feedback. The IRRF task frames a unique few-shot learning characteristics including binary classification of imbalanced and asymmetric classes, all in an open-set regime. In this paper, we study this task through the lens of few-shot learning methods. We propose a new scheme based on a hyper-network, that is tailored to the task and facilitates swift adjustment to user feedback. Our approach's efficacy is validated through comprehensive evaluations on multiple benchmarks and two supplementary tasks, supported by theoretical analysis. We demonstrate the advantage of our model over strong baselines on 4 different datasets in IRRF, addressing also retrieval of images with multiple objects. Furthermore, we show that our method can attain SoTA results in few-shot one-class classification and reach comparable results in binary classification task of few-shot open-set recognition.
Autonomous robotic re-alignment for face-to-face underwater human-robot interaction
Jan 09, 2024The use of autonomous underwater vehicles (AUVs) to accomplish traditionally challenging and dangerous tasks has proliferated thanks to advances in sensing, navigation, manipulation, and on-board computing technologies. Utilizing AUVs in underwater human-robot interaction (UHRI) has witnessed comparatively smaller levels of growth due to limitations in bi-directional communication and significant technical hurdles to bridge the gap between analogies with terrestrial interaction strategies and those that are possible in the underwater domain. A necessary component to support UHRI is establishing a system for safe robotic-diver approach to establish face-to-face communication that considers non-standard human body pose. In this work, we introduce a stereo vision system for enhancing UHRI that utilizes three-dimensional reconstruction from stereo image pairs and machine learning for localizing human joint estimates. We then establish a convention for a coordinate system that encodes the direction the human is facing with respect to the camera coordinate frame. This allows automatic setpoint computation that preserves human body scale and can be used as input to an image-based visual servo control scheme. We show that our setpoint computations tend to agree both quantitatively and qualitatively with experimental setpoint baselines. The methodology introduced shows promise for enhancing UHRI by improving robotic perception of human orientation underwater.
Structure-focused Neurodegeneration Convolutional Neural Network for Modeling and Classification of Alzheimer's Disease
Jan 10, 2024Alzheimer's disease (AD), the predominant form of dementia, poses a growing global challenge and underscores the urgency of accurate and early diagnosis. The clinical technique radiologists adopt for distinguishing between mild cognitive impairment (MCI) and AD using Machine Resonance Imaging (MRI) encounter hurdles because they are not consistent and reliable. Machine learning has been shown to offer promise for early AD diagnosis. However, existing models focused on focal fine-grain features without considerations to focal structural features that give off information on neurodegeneration of the brain cerebral cortex. Therefore, this paper proposes a machine learning (ML) framework that integrates Gamma correction, an image enhancement technique, and includes a structure-focused neurodegeneration convolutional neural network (CNN) architecture called SNeurodCNN for discriminating between AD and MCI. The ML framework leverages the mid-sagittal and para-sagittal brain image viewpoints of the structure-focused Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through experiments, our proposed machine learning framework shows exceptional performance. The parasagittal viewpoint set achieves 97.8% accuracy, with 97.0% specificity and 98.5% sensitivity. The midsagittal viewpoint is shown to present deeper insights into the structural brain changes given the increase in accuracy, specificity, and sensitivity, which are 98.1% 97.2%, and 99.0%, respectively. Using GradCAM technique, we show that our proposed model is capable of capturing the structural dynamics of MCI and AD which exist about the frontal lobe, occipital lobe, cerebellum, and parietal lobe. Therefore, our model itself as a potential brain structural change Digi-Biomarker for early diagnosis of AD.
Realism in Action: Anomaly-Aware Diagnosis of Brain Tumors from Medical Images Using YOLOv8 and DeiT
Jan 10, 2024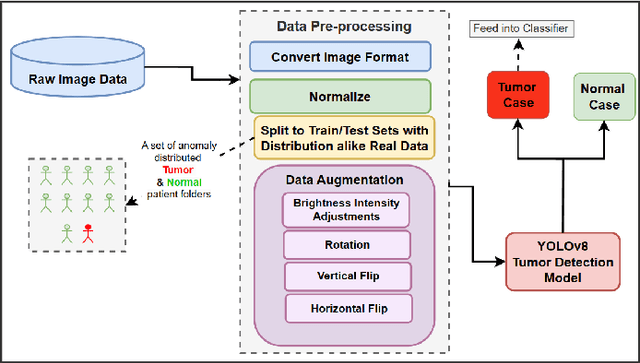
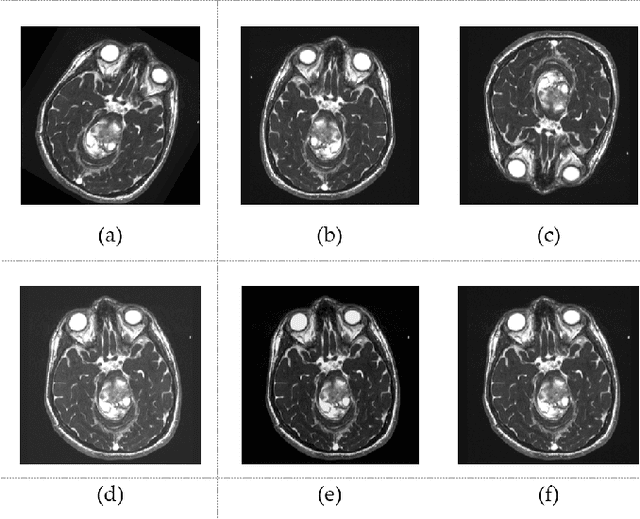
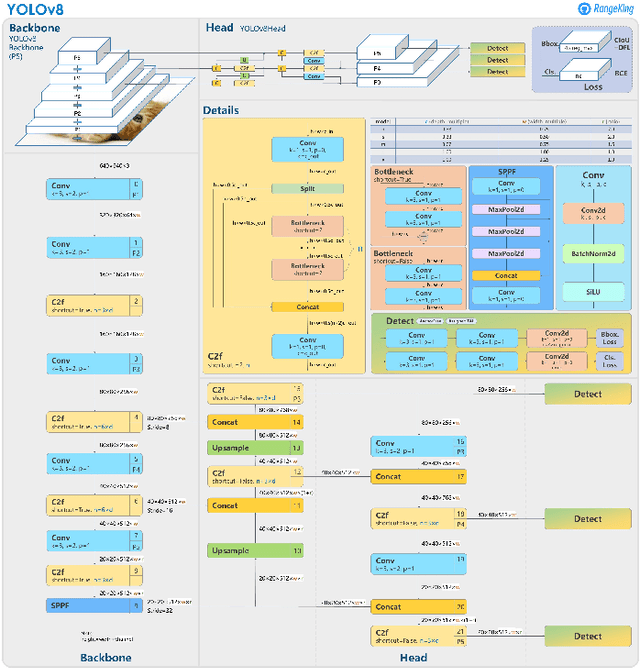
In the field of medical sciences, reliable detection and classification of brain tumors from images remains a formidable challenge due to the rarity of tumors within the population of patients. Therefore, the ability to detect tumors in anomaly scenarios is paramount for ensuring timely interventions and improved patient outcomes. This study addresses the issue by leveraging deep learning (DL) techniques to detect and classify brain tumors in challenging situations. The curated data set from the National Brain Mapping Lab (NBML) comprises 81 patients, including 30 Tumor cases and 51 Normal cases. The detection and classification pipelines are separated into two consecutive tasks. The detection phase involved comprehensive data analysis and pre-processing to modify the number of image samples and the number of patients of each class to anomaly distribution (9 Normal per 1 Tumor) to comply with real world scenarios. Next, in addition to common evaluation metrics for the testing, we employed a novel performance evaluation method called Patient to Patient (PTP), focusing on the realistic evaluation of the model. In the detection phase, we fine-tuned a YOLOv8n detection model to detect the tumor region. Subsequent testing and evaluation yielded competitive performance both in Common Evaluation Metrics and PTP metrics. Furthermore, using the Data Efficient Image Transformer (DeiT) module, we distilled a Vision Transformer (ViT) model from a fine-tuned ResNet152 as a teacher in the classification phase. This approach demonstrates promising strides in reliable tumor detection and classification, offering potential advancements in tumor diagnosis for real-world medical imaging scenarios.
SPDGAN: A Generative Adversarial Network based on SPD Manifold Learning for Automatic Image Colorization
Dec 21, 2023This paper addresses the automatic colorization problem, which converts a gray-scale image to a colorized one. Recent deep-learning approaches can colorize automatically grayscale images. However, when it comes to different scenes which contain distinct color styles, it is difficult to accurately capture the color characteristics. In this work, we propose a fully automatic colorization approach based on Symmetric Positive Definite (SPD) Manifold Learning with a generative adversarial network (SPDGAN) that improves the quality of the colorization results. Our SPDGAN model establishes an adversarial game between two discriminators and a generator. The latter is based on ResNet architecture with few alterations. Its goal is to generate fake colorized images without losing color information across layers through residual connections. Then, we employ two discriminators from different domains. The first one is devoted to the image pixel domain, while the second one is to the Riemann manifold domain which helps to avoid color misalignment. Extensive experiments are conducted on the Places365 and COCO-stuff databases to test the effect of each component of our SPDGAN. In addition, quantitative and qualitative comparisons with state-of-the-art methods demonstrate the effectiveness of our model by achieving more realistic colorized images with less artifacts visually, and good results of PSNR, SSIM, and FID values.