 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Visual Reasoning by Exploiting The Knowledge in Texts
Feb 09, 2021
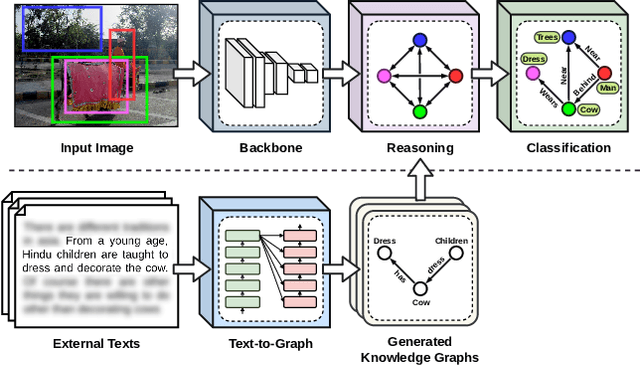

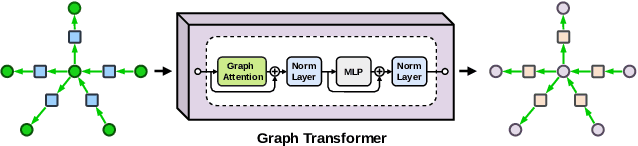
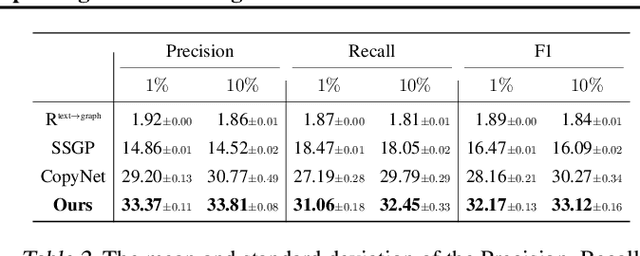
This paper presents a new framework for training image-based classifiers from a combination of texts and images with very few labels. We consider a classification framework with three modules: a backbone, a relational reasoning component, and a classification component. While the backbone can be trained from unlabeled images by self-supervised learning, we can fine-tune the relational reasoning and the classification components from external sources of knowledge instead of annotated images. By proposing a transformer-based model that creates structured knowledge from textual input, we enable the utilization of the knowledge in texts. We show that, compared to the supervised baselines with 1% of the annotated images, we can achieve ~8x more accurate results in scene graph classification, ~3x in object classification, and ~1.5x in predicate classification.
Terahertz Security Image Quality Assessment by No-reference Model Observers
Oct 03, 2017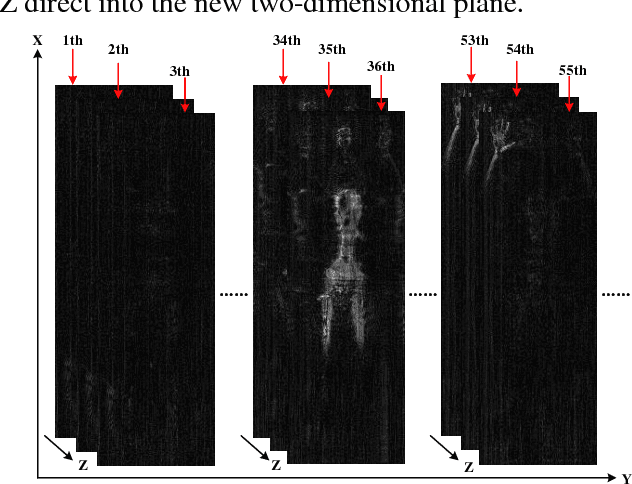

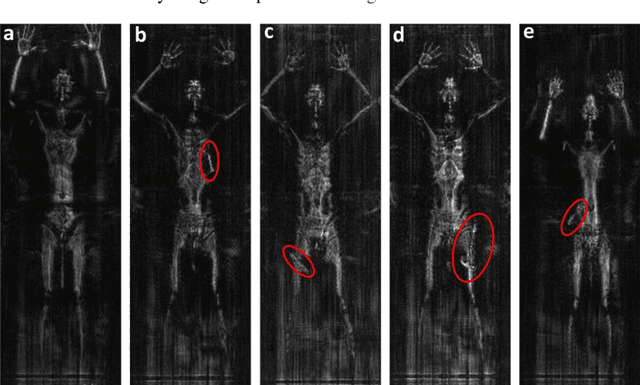
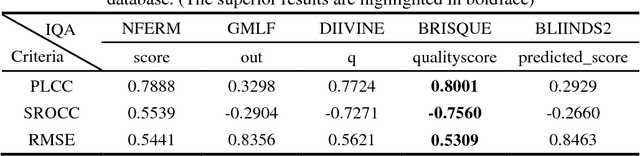
To provide the possibility of developing objective image quality assessment (IQA) algorithms for THz security images, we constructed the THz security image database (THSID) including a total of 181 THz security images with the resolution of 127*380. The main distortion types in THz security images were first analyzed for the design of subjective evaluation criteria to acquire the mean opinion scores. Subsequently, the existing no-reference IQA algorithms, which were 5 opinion-aware approaches viz., NFERM, GMLF, DIIVINE, BRISQUE and BLIINDS2, and 8 opinion-unaware approaches viz., QAC, SISBLIM, NIQE, FISBLIM, CPBD, S3 and Fish_bb, were executed for the evaluation of the THz security image quality. The statistical results demonstrated the superiority of Fish_bb over the other testing IQA approaches for assessing the THz image quality with PLCC (SROCC) values of 0.8925 (-0.8706), and with RMSE value of 0.3993. The linear regression analysis and Bland-Altman plot further verified that the Fish__bb could substitute for the subjective IQA. Nonetheless, for the classification of THz security images, we tended to use S3 as a criterion for ranking THz security image grades because of the relatively low false positive rate in classifying bad THz image quality into acceptable category (24.69%). Interestingly, due to the specific property of THz image, the average pixel intensity gave the best performance than the above complicated IQA algorithms, with the PLCC, SROCC and RMSE of 0.9001, -0.8800 and 0.3857, respectively. This study will help the users such as researchers or security staffs to obtain the THz security images of good quality. Currently, our research group is attempting to make this research more comprehensive.
U-Net Based Architecture for an Improved Multiresolution Segmentation in Medical Images
Jul 17, 2020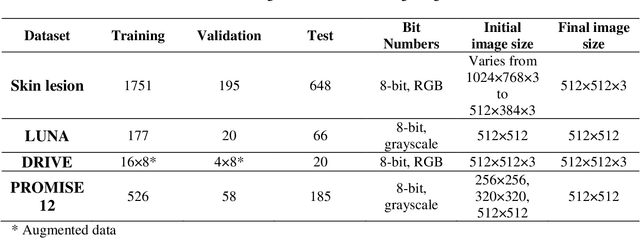
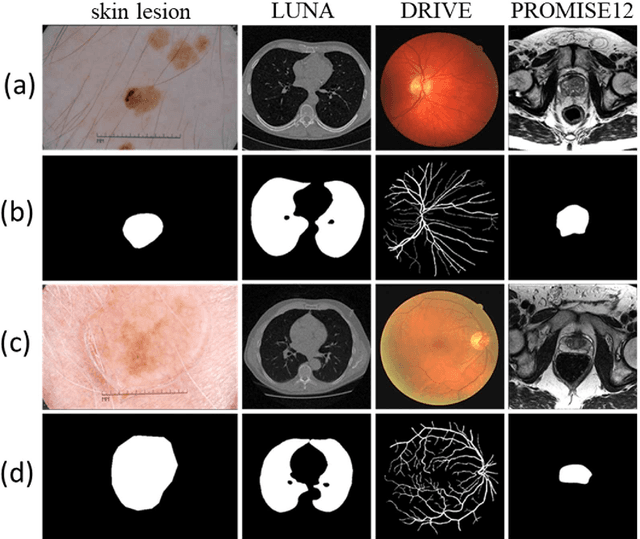
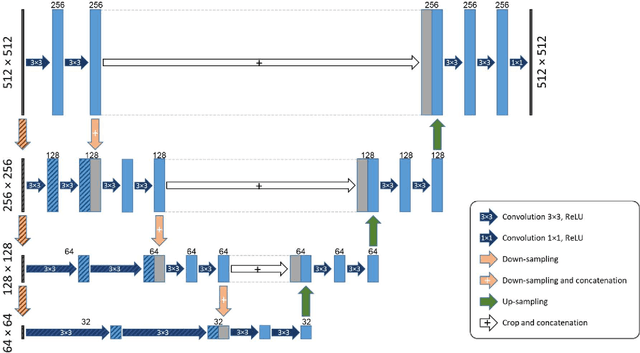
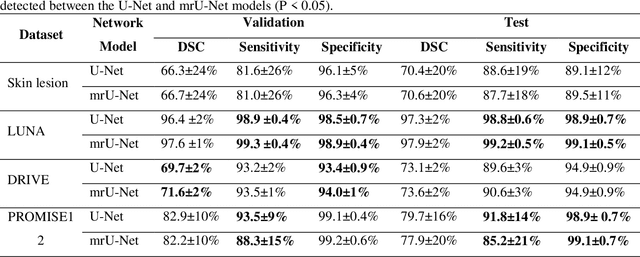
Purpose: Manual medical image segmentation is an exhausting and time-consuming task along with high inter-observer variability. In this study, our objective is to improve the multi-resolution image segmentation performance of U-Net architecture. Approach: We have proposed a fully convolutional neural network for image segmentation in a multi-resolution framework. We used U-Net as the base architecture and modified that to improve its image segmentation performance. In the proposed architecture (mrU-Net), the input image and its down-sampled versions were used as the network inputs. We added more convolution layers to extract features directly from the down-sampled images. We trained and tested the network on four different medical datasets, including skin lesion photos, lung computed tomography (CT) images (LUNA dataset), retina images (DRIVE dataset), and prostate magnetic resonance (MR) images (PROMISE12 dataset). We compared the performance of mrU-Net to U-Net under similar training and testing conditions. Results: Comparing the results to manual segmentation labels, mrU-Net achieved average Dice similarity coefficients of 70.6%, 97.9%, 73.6%, and 77.9% for the skin lesion, LUNA, DRIVE, and PROMISE12 segmentation, respectively. For the skin lesion, LUNA, and DRIVE datasets, mrU-Net outperformed U-Net with significantly higher accuracy and for the PROMISE12 dataset, both networks achieved similar accuracy. Furthermore, using mrU-Net led to a faster training rate on LUNA and DRIVE datasets when compared to U-Net. Conclusions: The striking feature of the proposed architecture is its higher capability in extracting image-derived features compared to U-Net. mrU-Net illustrated a faster training rate and slightly more accurate image segmentation compared to U-Net.
Computing Valid p-values for Image Segmentation by Selective Inference
Jun 03, 2019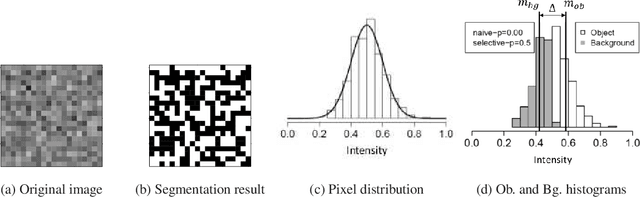
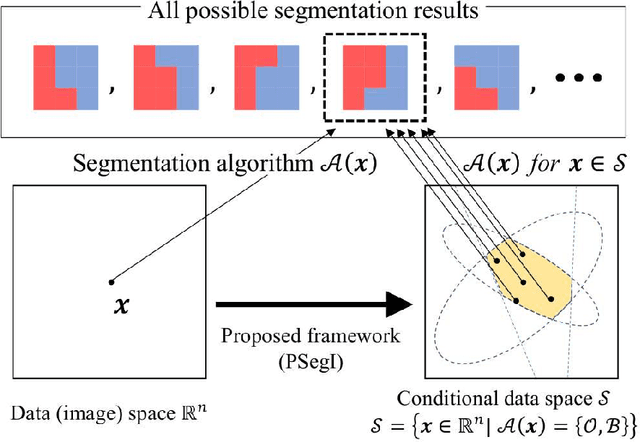
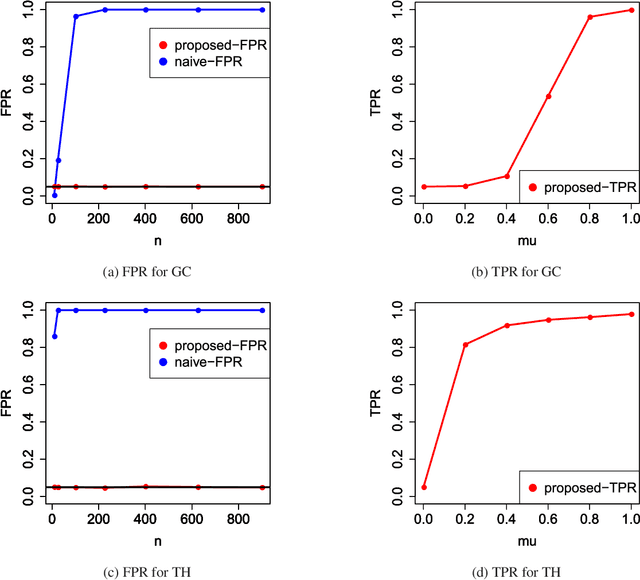
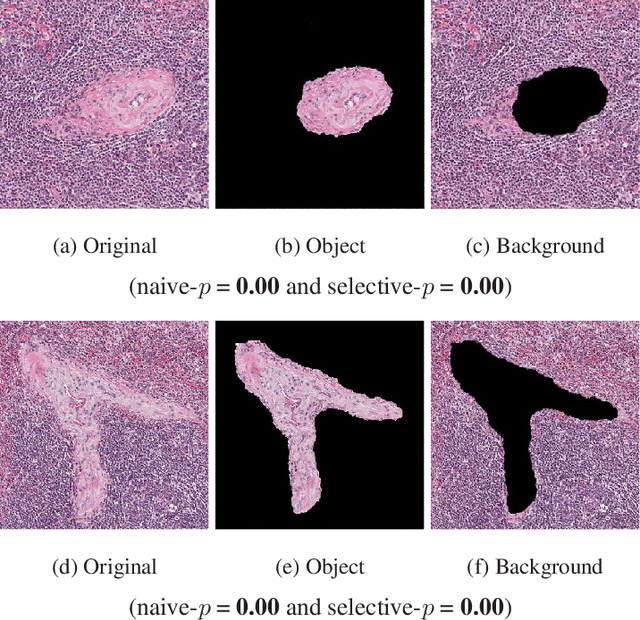
Image segmentation is one of the most fundamental tasks of computer vision. In many practical applications, it is essential to properly evaluate the reliability of individual segmentation results. In this study, we propose a novel framework to provide the statistical significance of segmentation results in the form of p-values. Specifically, we consider a statistical hypothesis test for determining the difference between the object and the background regions. This problem is challenging because the difference can be deceptively large (called segmentation bias) due to the adaptation of the segmentation algorithm to the data. To overcome this difficulty, we introduce a statistical approach called selective inference, and develop a framework to compute valid p-values in which the segmentation bias is properly accounted for. Although the proposed framework is potentially applicable to various segmentation algorithms, we focus in this paper on graph cut-based and threshold-based segmentation algorithms, and develop two specific methods to compute valid p-values for the segmentation results obtained by these algorithms. We prove the theoretical validity of these two methods and demonstrate their practicality by applying them to segmentation problems for medical images.
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Jan 25, 2021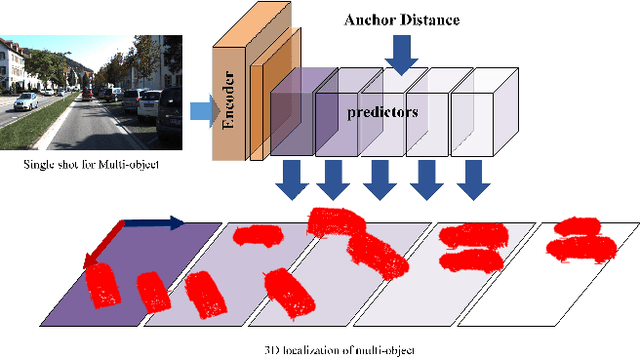
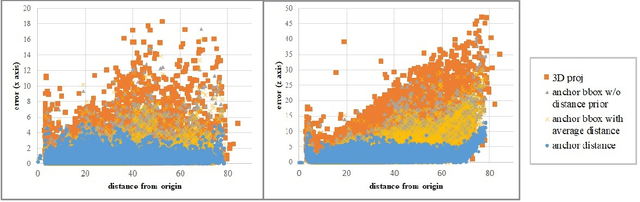
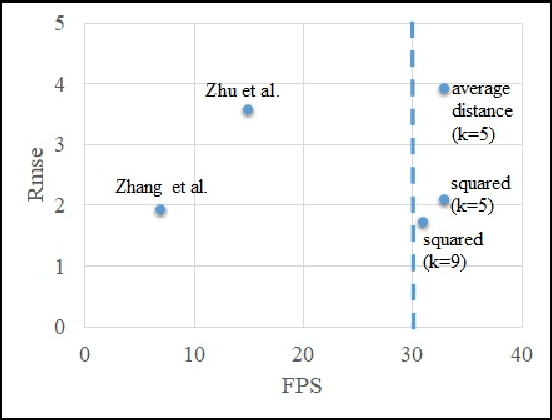
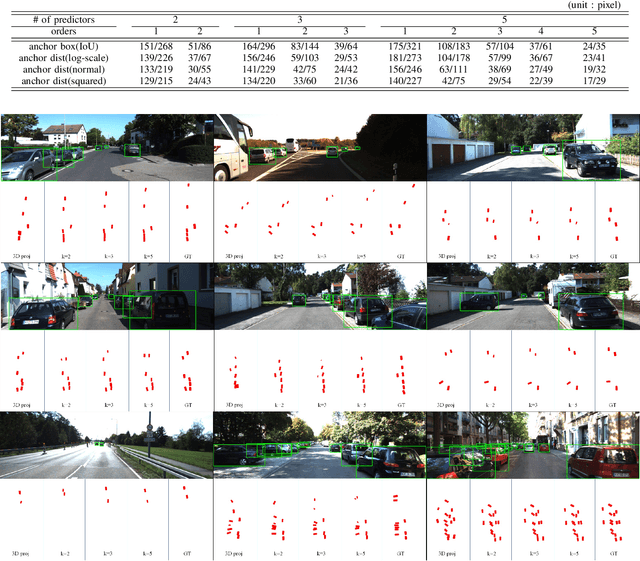
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.
Compressing Visual-linguistic Model via Knowledge Distillation
Apr 05, 2021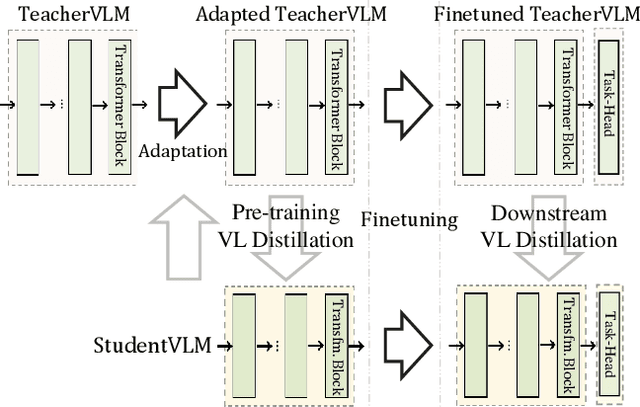
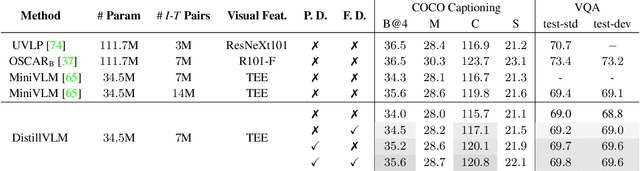
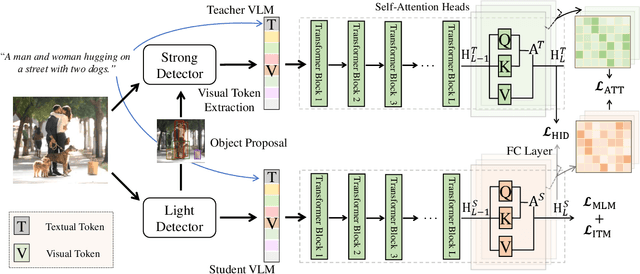
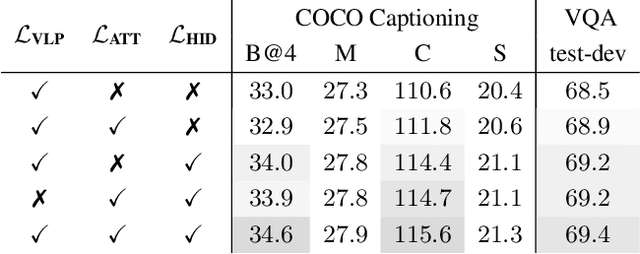
Despite exciting progress in pre-training for visual-linguistic (VL) representations, very few aspire to a small VL model. In this paper, we study knowledge distillation (KD) to effectively compress a transformer-based large VL model into a small VL model. The major challenge arises from the inconsistent regional visual tokens extracted from different detectors of Teacher and Student, resulting in the misalignment of hidden representations and attention distributions. To address the problem, we retrain and adapt the Teacher by using the same region proposals from Student's detector while the features are from Teacher's own object detector. With aligned network inputs, the adapted Teacher is capable of transferring the knowledge through the intermediate representations. Specifically, we use the mean square error loss to mimic the attention distribution inside the transformer block and present a token-wise noise contrastive loss to align the hidden state by contrasting with negative representations stored in a sample queue. To this end, we show that our proposed distillation significantly improves the performance of small VL models on image captioning and visual question answering tasks. It reaches 120.8 in CIDEr score on COCO captioning, an improvement of 5.1 over its non-distilled counterpart; and an accuracy of 69.8 on VQA 2.0, a 0.8 gain from the baseline. Our extensive experiments and ablations confirm the effectiveness of VL distillation in both pre-training and fine-tuning stages.
DAC: Deep Autoencoder-based Clustering, a General Deep Learning Framework of Representation Learning
Feb 15, 2021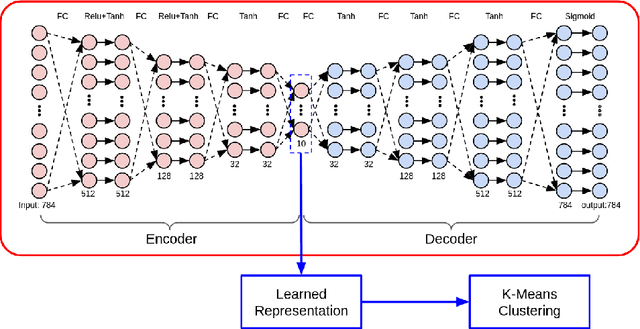



Clustering performs an essential role in many real world applications, such as market research, pattern recognition, data analysis, and image processing. However, due to the high dimensionality of the input feature values, the data being fed to clustering algorithms usually contains noise and thus could lead to in-accurate clustering results. While traditional dimension reduction and feature selection algorithms could be used to address this problem, the simple heuristic rules used in those algorithms are based on some particular assumptions. When those assumptions does not hold, these algorithms then might not work. In this paper, we propose DAC, Deep Autoencoder-based Clustering, a generalized data-driven framework to learn clustering representations using deep neuron networks. Experiment results show that our approach could effectively boost performance of the K-Means clustering algorithm on a variety types of datasets.
Application of Facial Recognition using Convolutional Neural Networks for Entry Access Control
Nov 23, 2020
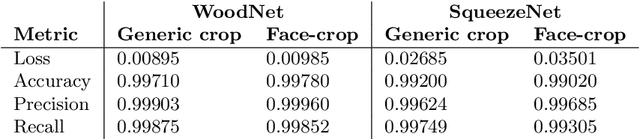
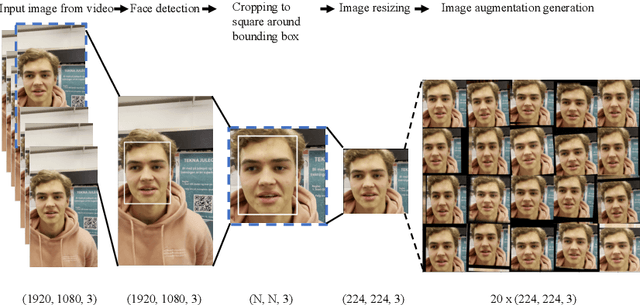
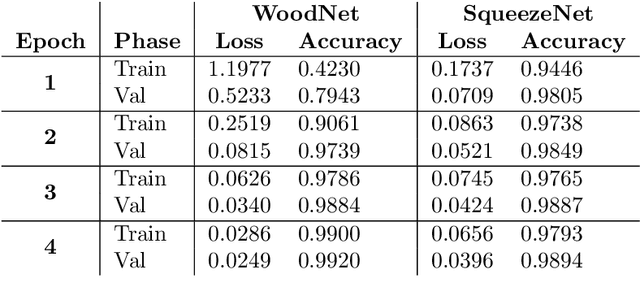
The purpose of this paper is to design a solution to the problem of facial recognition by use of convolutional neural networks, with the intention of applying the solution in a camera-based home-entry access control system. More specifically, the paper focuses on solving the supervised classification problem of taking images of people as input and classifying the person in the image as one of the authors or not. Two approaches are proposed: (1) building and training a neural network called WoodNet from scratch and (2) leveraging transfer learning by utilizing a network pre-trained on the ImageNet database and adapting it to this project's data and classes. In order to train the models to recognize the authors, a dataset containing more than 150 000 images has been created, balanced over the authors and others. Image extraction from videos and image augmentation techniques were instrumental for dataset creation. The results are two models classifying the individuals in the dataset with high accuracy, achieving over 99% accuracy on held-out test data. The pre-trained model fitted significantly faster than WoodNet, and seems to generalize better. However, these results come with a few caveats. Because of the way the dataset was compiled, as well as the high accuracy, one has reason to believe the models over-fitted to the data to some degree. An added consequence of the data compilation method is that the test dataset may not be sufficiently different from the training data, limiting its ability to validate generalization of the models. However, utilizing the models in a web-cam based system, classifying faces in real-time, shows promising results and indicates that the models generalized fairly well for at least some of the classes (see the accompanying video).
Towards Dense People Detection with Deep Learning and Depth images
Jul 14, 2020
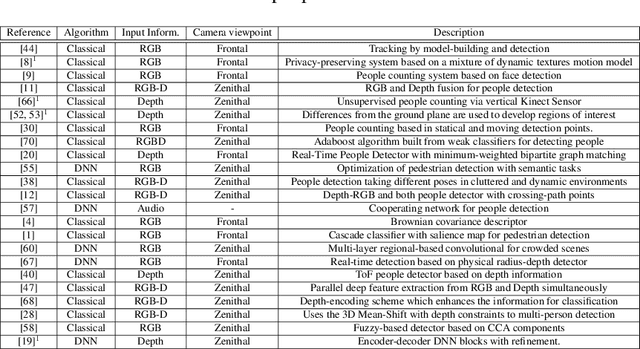
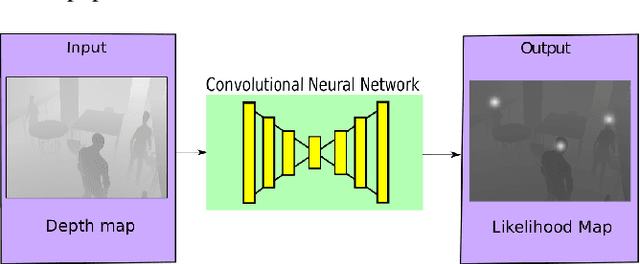
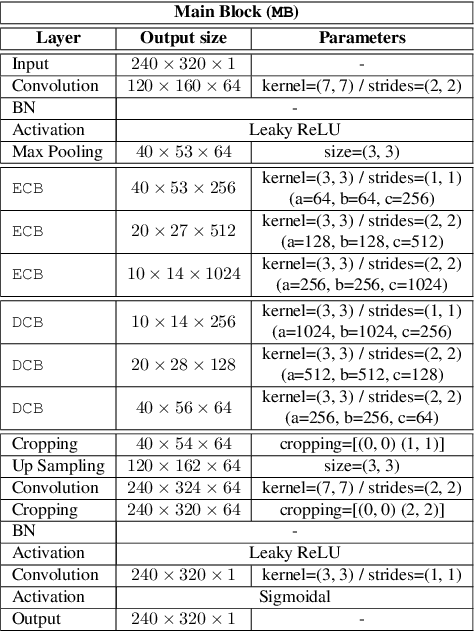
This paper proposes a DNN-based system that detects multiple people from a single depth image. Our neural network processes a depth image and outputs a likelihood map in image coordinates, where each detection corresponds to a Gaussian-shaped local distribution, centered at the person's head. The likelihood map encodes both the number of detected people and their 2D image positions, and can be used to recover the 3D position of each person using the depth image and the camera calibration parameters. Our architecture is compact, using separated convolutions to increase performance, and runs in real-time with low budget GPUs. We use simulated data for initially training the network, followed by fine tuning with a relatively small amount of real data. We show this strategy to be effective, producing networks that generalize to work with scenes different from those used during training. We thoroughly compare our method against the existing state-of-the-art, including both classical and DNN-based solutions. Our method outperforms existing methods and can accurately detect people in scenes with significant occlusions.
Deep Active Shape Model for Face Alignment and Pose Estimation
Feb 27, 2021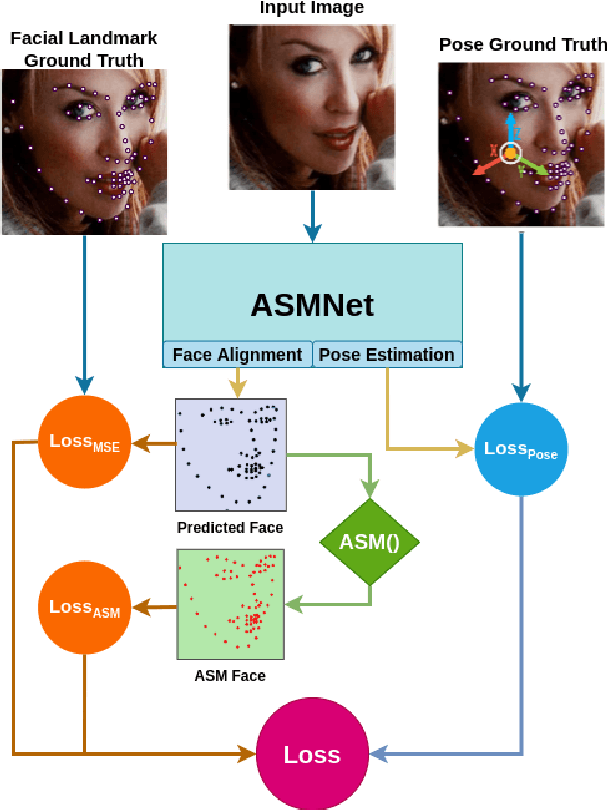
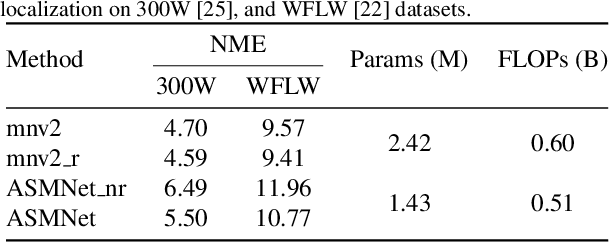
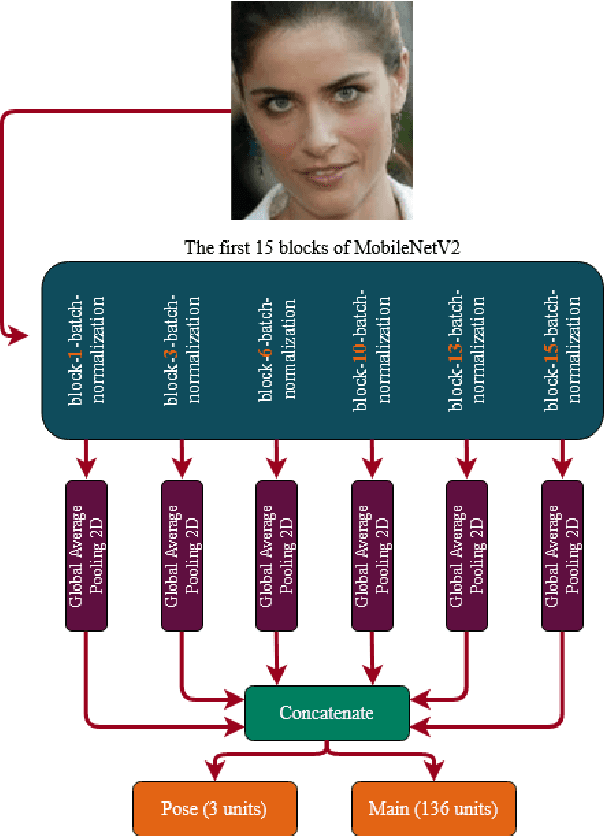
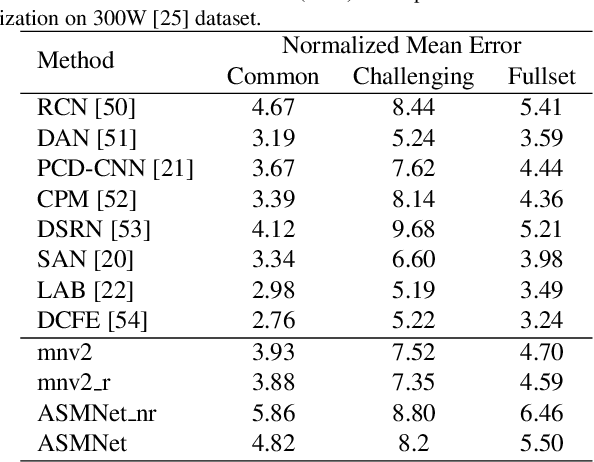
Active Shape Model (ASM) is a statistical model of object shapes that represents a target structure. ASM can guide machine learning algorithms to fit a set of points representing an object (e.g., face) onto an image. This paper presents a lightweight Convolutional Neural Network (CNN) architecture with a loss function regularized by ASM for face alignment and estimating head pose in the wild. The ASM-based regularization term in the loss function would guide the network to learn faster, generalize better, and hence handle challenging examples even with light-weight network architecture. We define multi-tasks in our loss function that are responsible for detecting facial landmark points, as well as estimating face pose. Learning multiple correlated tasks simultaneously builds synergy and improves the performance of individual tasks. Experimental results on challenging datasets show that our proposed ASM regularized loss function achieves competitive performance for facial landmark points detection and pose estimation using a very light-weight CNN architecture.