 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Fusion of Raman Chemical Imaging and Digital Histopathology using Machine Learning for Prostate Cancer Detection
Jan 18, 2021
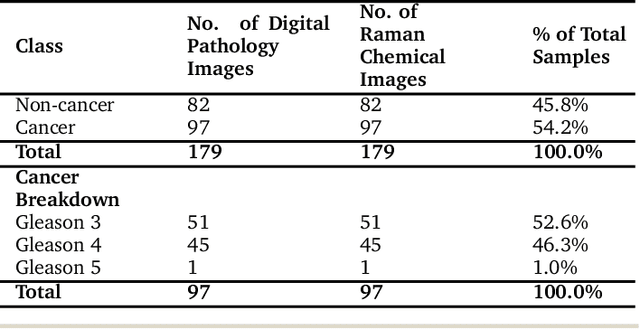
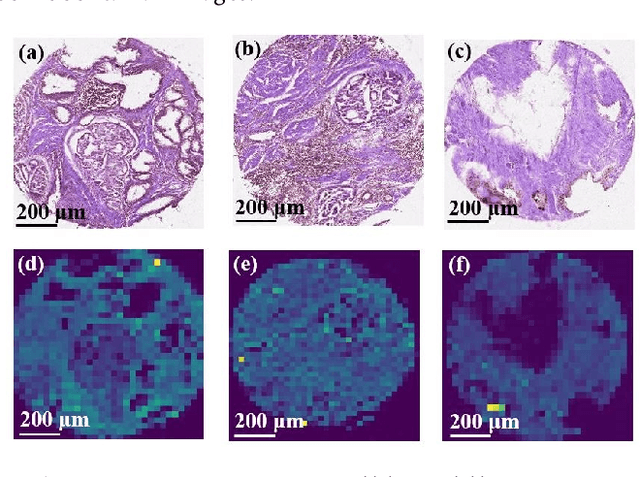

The diagnosis of prostate cancer is challenging due to the heterogeneity of its presentations, leading to the over diagnosis and treatment of non-clinically important disease. Accurate diagnosis can directly benefit a patient's quality of life and prognosis. Towards addressing this issue, we present a learning model for the automatic identification of prostate cancer. While many prostate cancer studies have adopted Raman spectroscopy approaches, none have utilised the combination of Raman Chemical Imaging (RCI) and other imaging modalities. This study uses multimodal images formed from stained Digital Histopathology (DP) and unstained RCI. The approach was developed and tested on a set of 178 clinical samples from 32 patients, containing a range of non-cancerous, Gleason grade 3 (G3) and grade 4 (G4) tissue microarray samples. For each histological sample, there is a pathologist labelled DP - RCI image pair. The hypothesis tested was whether multimodal image models can outperform single modality baseline models in terms of diagnostic accuracy. Binary non-cancer/cancer models and the more challenging G3/G4 differentiation were investigated. Regarding G3/G4 classification, the multimodal approach achieved a sensitivity of 73.8% and specificity of 88.1% while the baseline DP model showed a sensitivity and specificity of 54.1% and 84.7% respectively. The multimodal approach demonstrated a statistically significant 12.7% AUC advantage over the baseline with a value of 85.8% compared to 73.1%, also outperforming models based solely on RCI and median Raman spectra. Feature fusion of DP and RCI does not improve the more trivial task of tumour identification but does deliver an observed advantage in G3/G4 discrimination. Building on these promising findings, future work could include the acquisition of larger datasets for enhanced model generalization.
Neighborhood Watch: Representation Learning with Local-Margin Triplet Loss and Sampling Strategy for K-Nearest-Neighbor Image Classification
Oct 28, 2019
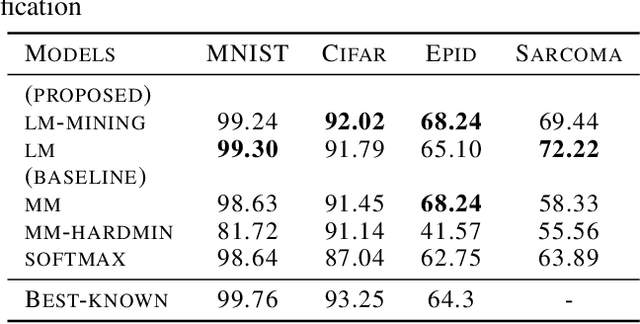
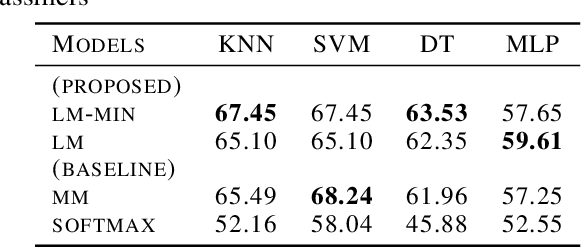
Deep representation learning using triplet network for classification suffers from a lack of theoretical foundation and difficulty in tuning both the network and classifiers for performance. To address the problem, local-margin triplet loss along with local positive and negative mining strategy is proposed with theory on how the strategy integrate nearest-neighbor hyper-parameter with triplet learning to increase subsequent classification performance. Results in experiments with 2 public datasets, MNIST and Cifar-10, and 2 small medical image datasets demonstrate that proposed strategy outperforms end-to-end softmax and typical triplet loss in settings without data augmentation while maintaining utility of transferable feature for related tasks. The method serves as a good performance baseline where end-to-end methods encounter difficulties such as small sample data with limited allowable data augmentation.
Are High-Frequency Components Beneficial for Training of Generative Adversarial Networks
Mar 20, 2021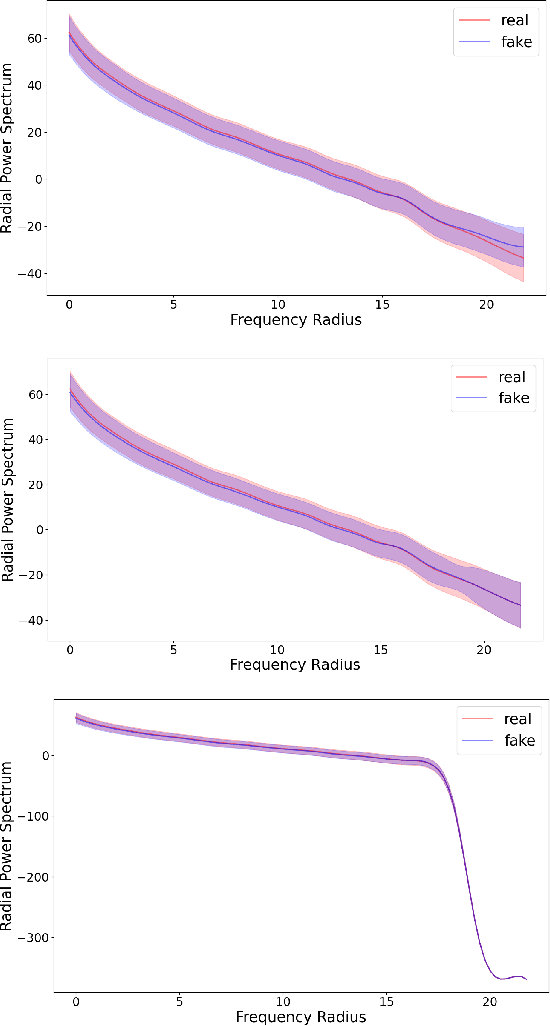
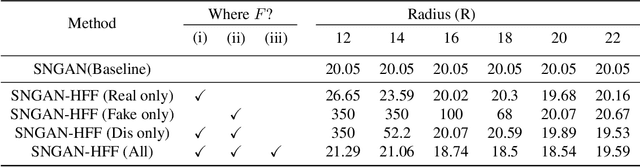
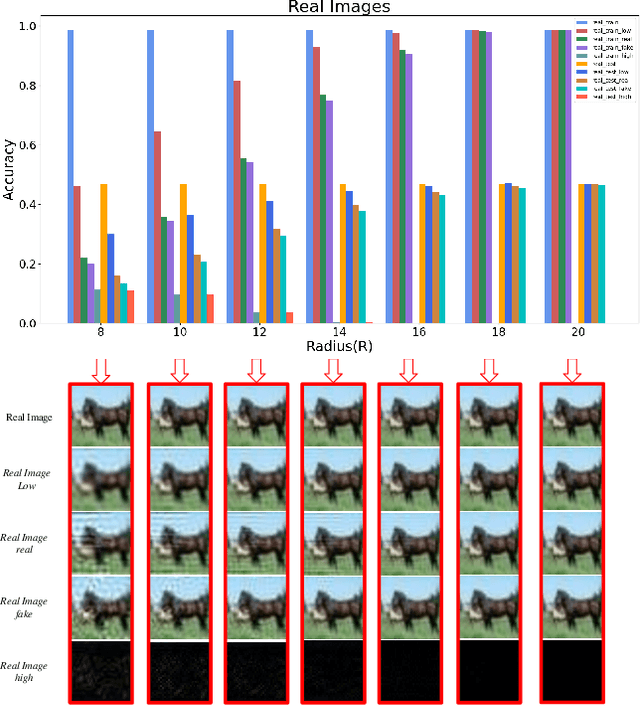
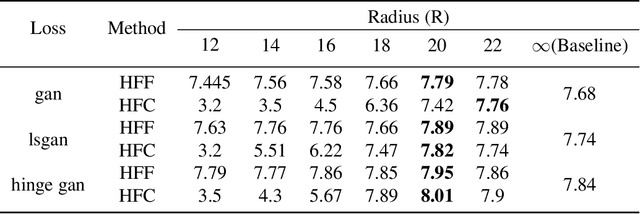
Advancements in Generative Adversarial Networks (GANs) have the ability to generate realistic images that are visually indistinguishable from real images. However, recent studies of the image spectrum have demonstrated that generated and real images share significant differences at high frequency. Furthermore, the high-frequency components invisible to human eyes affect the decision of CNNs and are related to the robustness of it. Similarly, whether the discriminator will be sensitive to the high-frequency differences, thus reducing the fitting ability of the generator to the low-frequency components is an open problem. In this paper, we demonstrate that the discriminator in GANs is sensitive to such high-frequency differences that can not be distinguished by humans and the high-frequency components of images are not conducive to the training of GANs. Based on these, we propose two preprocessing methods eliminating high-frequency differences in GANs training: High-Frequency Confusion (HFC) and High-Frequency Filter (HFF). The proposed methods are general and can be easily applied to most existing GANs frameworks with a fraction of the cost. The advanced performance of the proposed method is verified on multiple loss functions, network architectures, and datasets.
Gaussian kernel smoothing
Jul 19, 2020
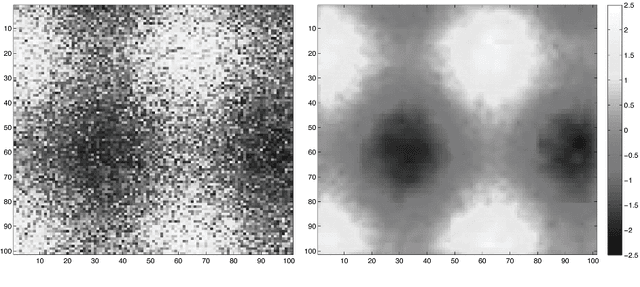
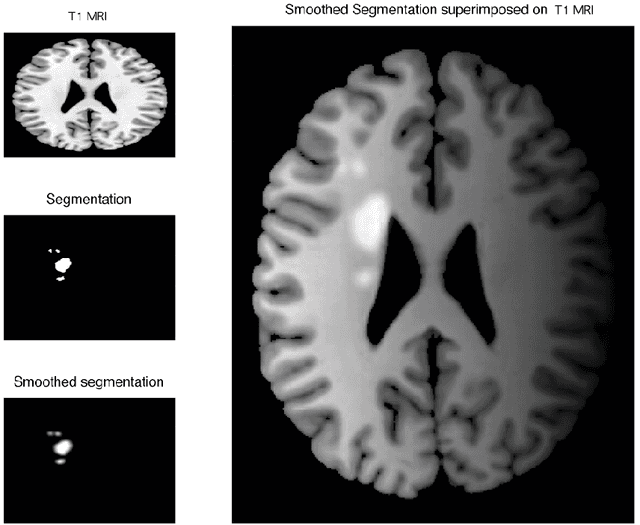
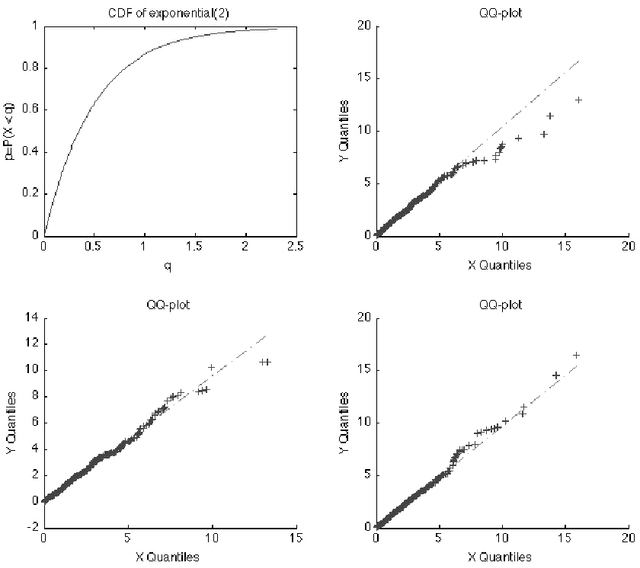
Image acquisition and segmentation are likely to introduce noise. Further image processing such as image registration and parameterization can introduce additional noise. It is thus imperative to reduce noise measurements and boost signal. In order to increase the signal-to-noise ratio (SNR) and smoothness of data required for the subsequent random field theory based statistical inference, some type of smoothing is necessary. Among many image smoothing methods, Gaussian kernel smoothing has emerged as a de facto smoothing technique among brain imaging researchers due to its simplicity in numerical implementation. Gaussian kernel smoothing also increases statistical sensitivity and statistical power as well as Gausianness. Gaussian kernel smoothing can be viewed as weighted averaging of voxel values. Then from the central limit theorem, the weighted average should be more Gaussian.
Predicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Aug 13, 2020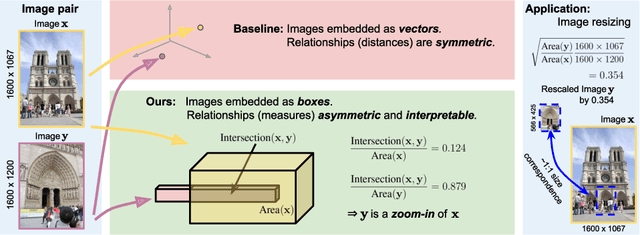
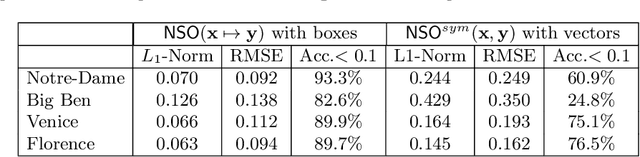

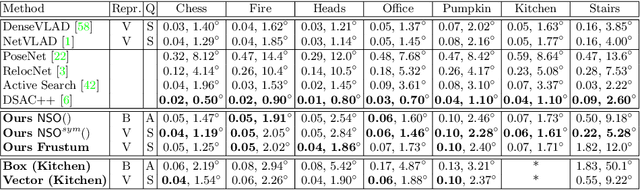
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.
Stereo image de-fencing using smartphones
Dec 05, 2016
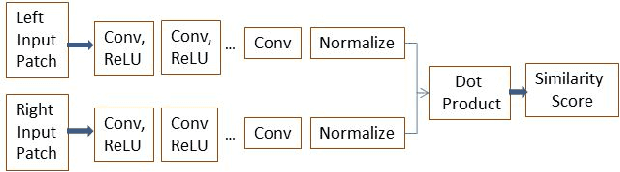
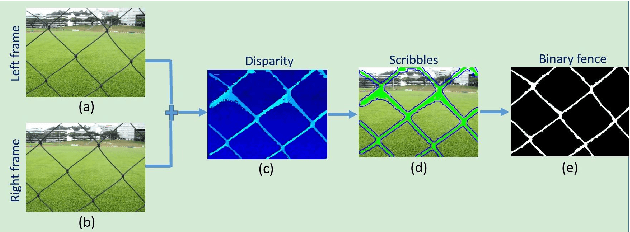

Conventional approaches to image de-fencing have limited themselves to using only image data in adjacent frames of the captured video of an approximately static scene. In this work, we present a method to harness disparity using a stereo pair of fenced images in order to detect fence pixels. Tourists and amateur photographers commonly carry smartphones/phablets which can be used to capture a short video sequence of the fenced scene. We model the formation of the occluded frames in the captured video. Furthermore, we propose an optimization framework to estimate the de-fenced image using the total variation prior to regularize the ill-posed problem.
LodoNet: A Deep Neural Network with 2D Keypoint Matchingfor 3D LiDAR Odometry Estimation
Sep 01, 2020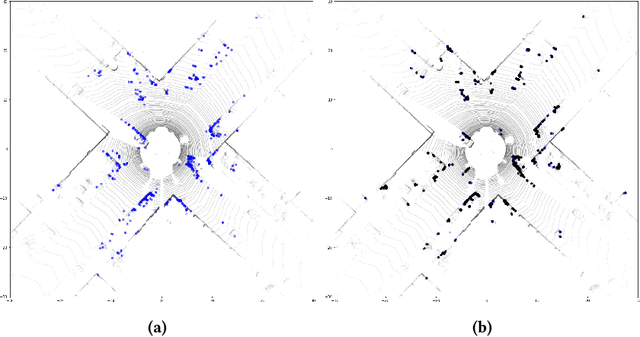
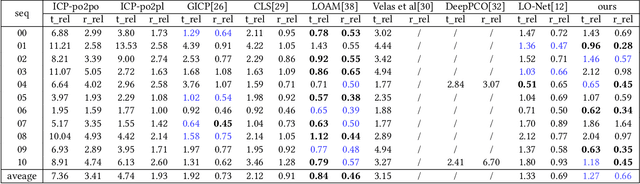
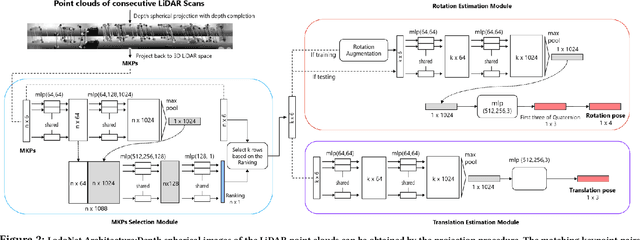
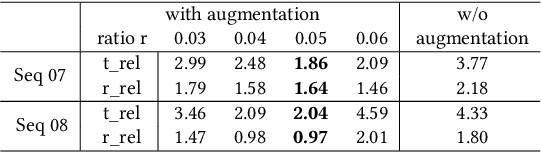
Deep learning based LiDAR odometry (LO) estimation attracts increasing research interests in the field of autonomous driving and robotics. Existing works feed consecutive LiDAR frames into neural networks as point clouds and match pairs in the learned feature space. In contrast, motivated by the success of image based feature extractors, we propose to transfer the LiDAR frames to image space and reformulate the problem as image feature extraction. With the help of scale-invariant feature transform (SIFT) for feature extraction, we are able to generate matched keypoint pairs (MKPs) that can be precisely returned to the 3D space. A convolutional neural network pipeline is designed for LiDAR odometry estimation by extracted MKPs. The proposed scheme, namely LodoNet, is then evaluated in the KITTI odometry estimation benchmark, achieving on par with or even better results than the state-of-the-art.
Learning a Generative Motion Model from Image Sequences based on a Latent Motion Matrix
Nov 03, 2020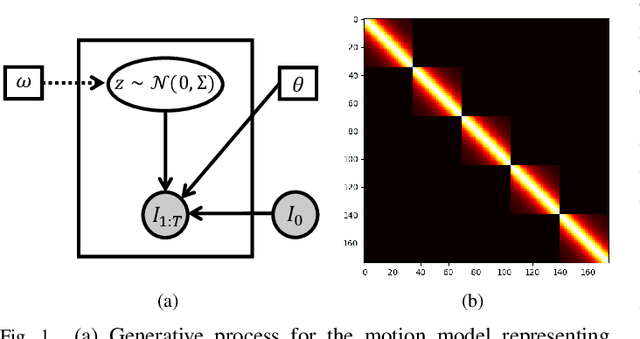
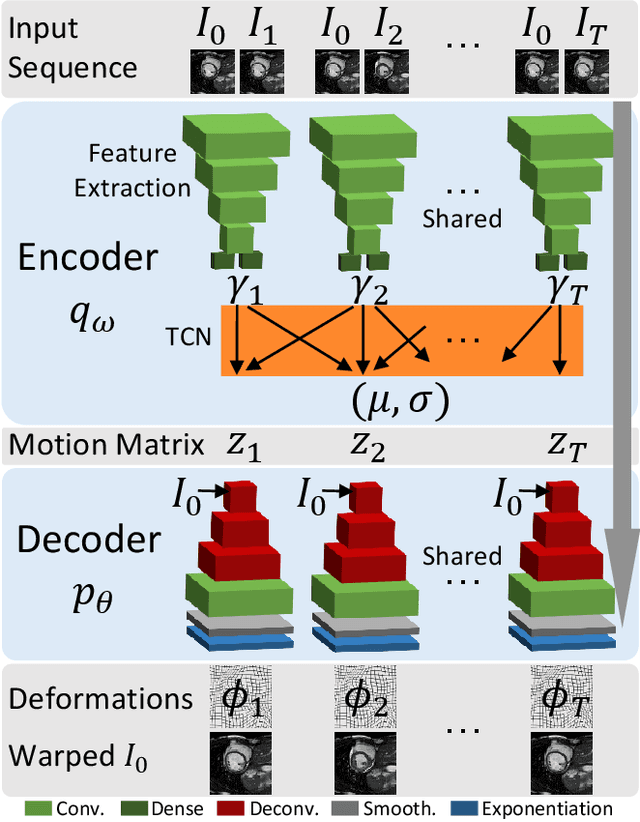
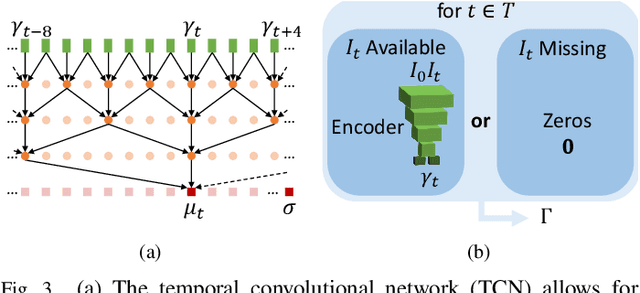
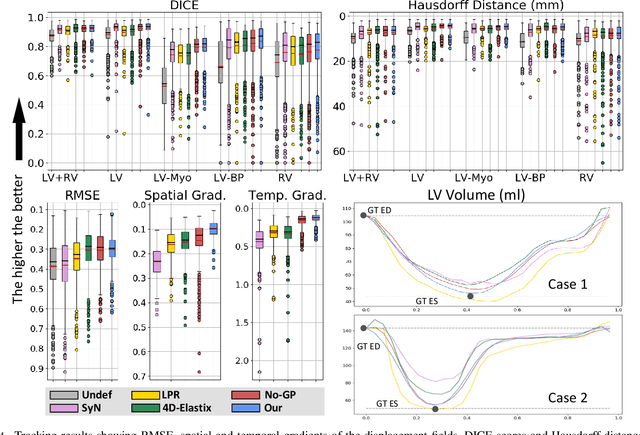
We propose to learn a probabilistic motion model from a sequence of images for spatio-temporal registration. Our model encodes motion in a low-dimensional probabilistic space - the motion matrix - which enables various motion analysis tasks such as simulation and interpolation of realistic motion patterns allowing for faster data acquisition and data augmentation. More precisely, the motion matrix allows to transport the recovered motion from one subject to another simulating for example a pathological motion in a healthy subject without the need for inter-subject registration. The method is based on a conditional latent variable model that is trained using amortized variational inference. This unsupervised generative model follows a novel multivariate Gaussian process prior and is applied within a temporal convolutional network which leads to a diffeomorphic motion model. Temporal consistency and generalizability is further improved by applying a temporal dropout training scheme. Applied to cardiac cine-MRI sequences, we show improved registration accuracy and spatio-temporally smoother deformations compared to three state-of-the-art registration algorithms. Besides, we demonstrate the model's applicability for motion analysis, simulation and super-resolution by an improved motion reconstruction from sequences with missing frames compared to linear and cubic interpolation.
An Efficient Approximate kNN Graph Method for Diffusion on Image Retrieval
Apr 18, 2019
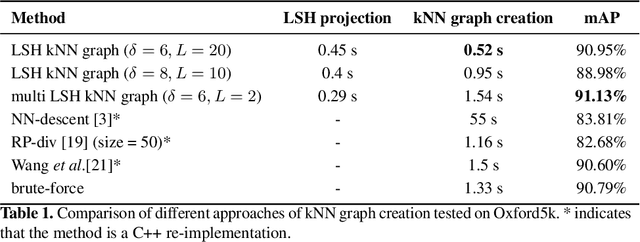
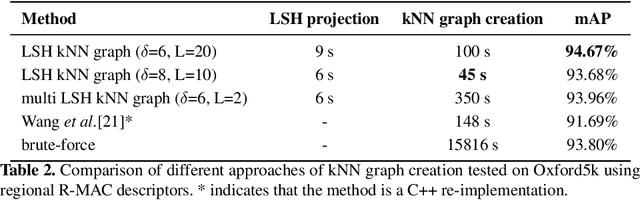

The application of the diffusion in many computer vision and artificial intelligence projects has been shown to give excellent improvements in performance. One of the main bottlenecks of this technique is the quadratic growth of the kNN graph size due to the high-quantity of new connections between nodes in the graph, resulting in long computation times. Several strategies have been proposed to address this, but none are effective and efficient. Our novel technique, based on LSH projections, obtains the same performance as the exact kNN graph after diffusion, but in less time (approximately 18 times faster on a dataset of a hundred thousand images). The proposed method was validated and compared with other state-of-the-art on several public image datasets, including Oxford5k, Paris6k, and Oxford105k.
Legacy Photo Editing with Learned Noise Prior
Nov 24, 2020
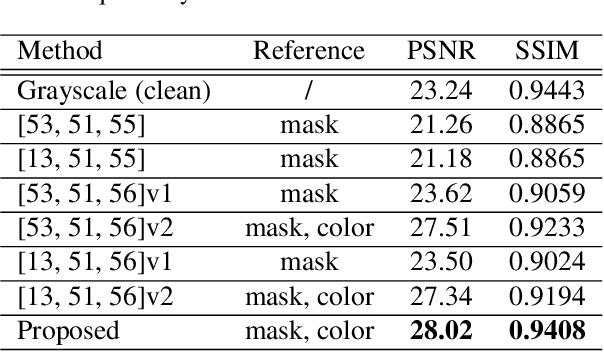

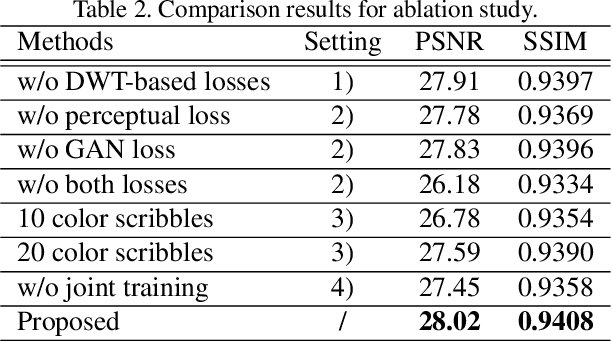
There are quite a number of photographs captured under undesirable conditions in the last century. Thus, they are often noisy, regionally incomplete, and grayscale formatted. Conventional approaches mainly focus on one point so that those restoration results are not perceptually sharp or clean enough. To solve these problems, we propose a noise prior learner NEGAN to simulate the noise distribution of real legacy photos using unpaired images. It mainly focuses on matching high-frequency parts of noisy images through discrete wavelet transform (DWT) since they include most of noise statistics. We also create a large legacy photo dataset for learning noise prior. Using learned noise prior, we can easily build valid training pairs by degrading clean images. Then, we propose an IEGAN framework performing image editing including joint denoising, inpainting and colorization based on the estimated noise prior. We evaluate the proposed system and compare it with state-of-the-art image enhancement methods. The experimental results demonstrate that it achieves the best perceptual quality. https://github.com/zhaoyuzhi/Legacy-Photo-Editing-with-Learned-Noise-Prior for the codes and the proposed LP dataset.