 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Semi-Automated Usability Evaluation Framework for Interactive Image Segmentation Systems
Sep 01, 2019
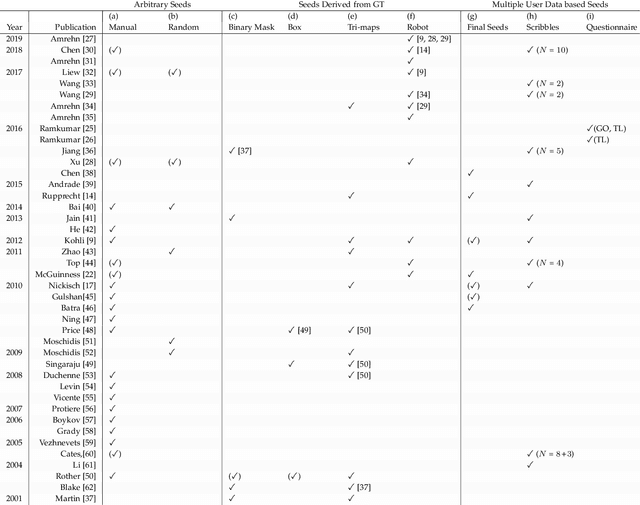
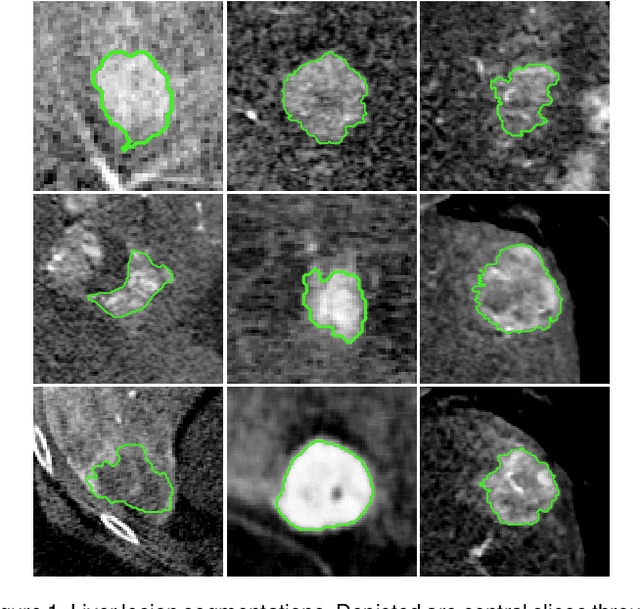
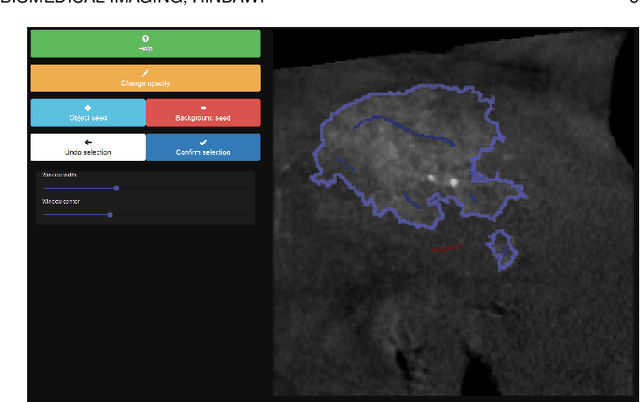
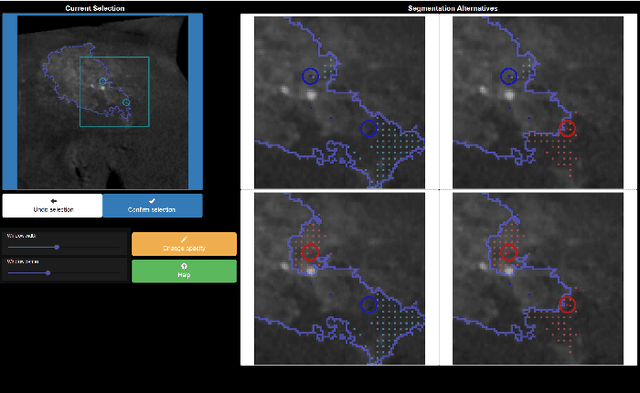
For complex segmentation tasks, the achievable accuracy of fully automated systems is inherently limited. Specifically, when a precise segmentation result is desired for a small amount of given data sets, semi-automatic methods exhibit a clear benefit for the user. The optimization of human computer interaction (HCI) is an essential part of interactive image segmentation. Nevertheless, publications introducing novel interactive segmentation systems (ISS) often lack an objective comparison of HCI aspects. It is demonstrated, that even when the underlying segmentation algorithm is the same throughout interactive prototypes, their user experience may vary substantially. As a result, users prefer simple interfaces as well as a considerable degree of freedom to control each iterative step of the segmentation. In this article, an objective method for the comparison of ISS is proposed, based on extensive user studies. A summative qualitative content analysis is conducted via abstraction of visual and verbal feedback given by the participants. A direct assessment of the segmentation system is executed by the users via the system usability scale (SUS) and AttrakDiff-2 questionnaires. Furthermore, an approximation of the findings regarding usability aspects in those studies is introduced, conducted solely from the system-measurable user actions during their usage of interactive segmentation prototypes. The prediction of all questionnaire results has an average relative error of 8.9%, which is close to the expected precision of the questionnaire results themselves. This automated evaluation scheme may significantly reduce the resources necessary to investigate each variation of a prototype's user interface (UI) features and segmentation methodologies.
Robot Manipulator Control with Inverse Kinematics PD-Pseudoinverse Jacobian and Forward Kinematics Denavit Hartenberg
Mar 18, 2021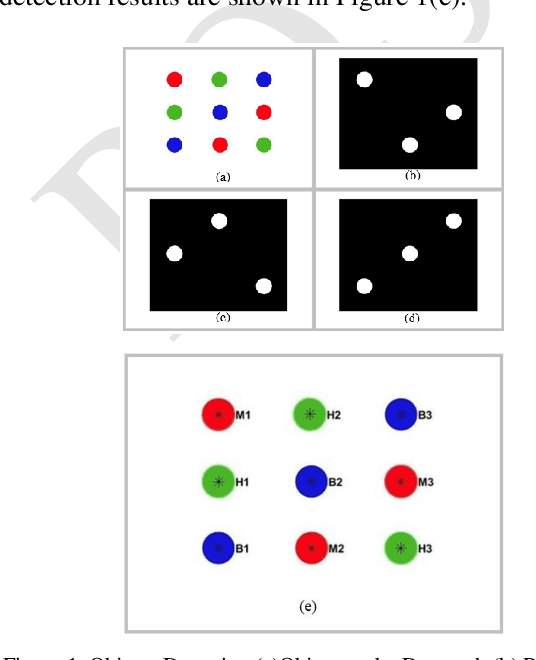
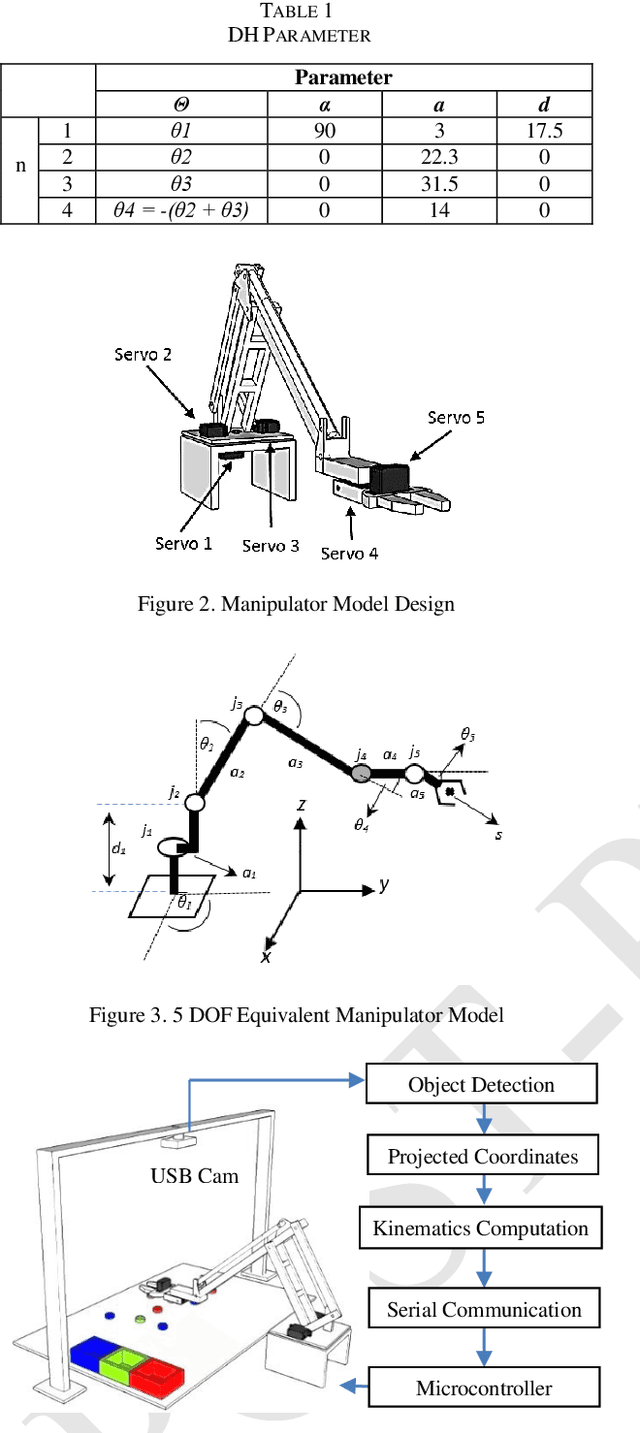
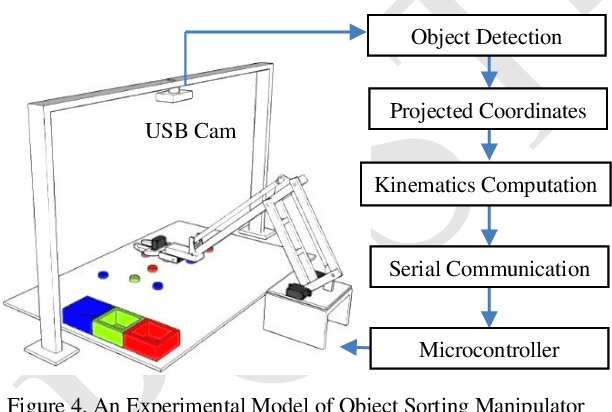
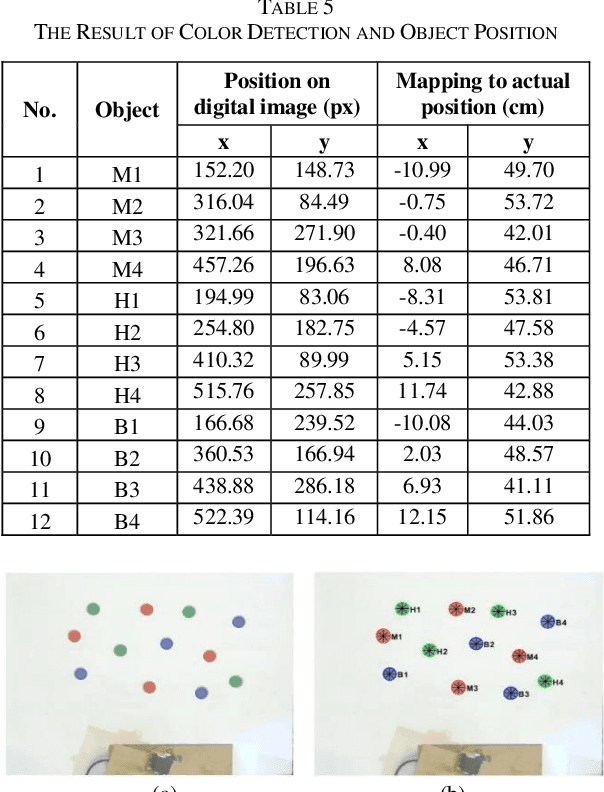
This paper presents the development of vision-based robotic arm manipulator control by applying Proportional Derivative-Pseudoinverse Jacobian (PD-PIJ) kinematics and Denavit Hartenberg forward kinematics. The task of sorting objects based on color is carried out to observe error propagation in the implementation of manipulator on real system. The objects image captured by the digital camera were processed based on HSV-color model and the centroid coordinate of each object detected were calculated. These coordinates are end effector position target to pick each object and were placed to the right position based on its color. Based on the end effector position target, PD-PIJ inverse kinematics method was used to determine the right angle of each joint of manipulator links. The angles found by PD-PIJ is the input of DH forward kinematics. The process was repeated until the square end effector reached the target. The experiment of model and implementation to actual manipulator were analyzed using Probability Density Function (PDF) and Weibull Probability Distribution. The result shows that the manipulator navigation system had a good performance. The real implementation of color sorting task on manipulator shows the probability of success rate cm is 94.46% for euclidian distance error less than 1.2 cm.
Combining Pyramid Pooling and Attention Mechanism for Pelvic MR Image Semantic Segmentaion
Jun 28, 2018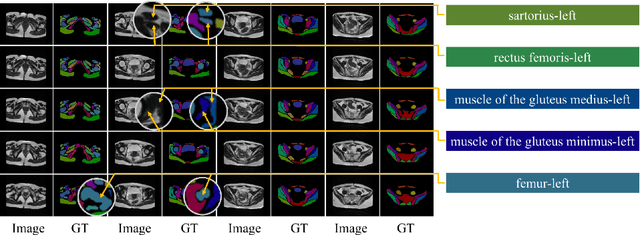
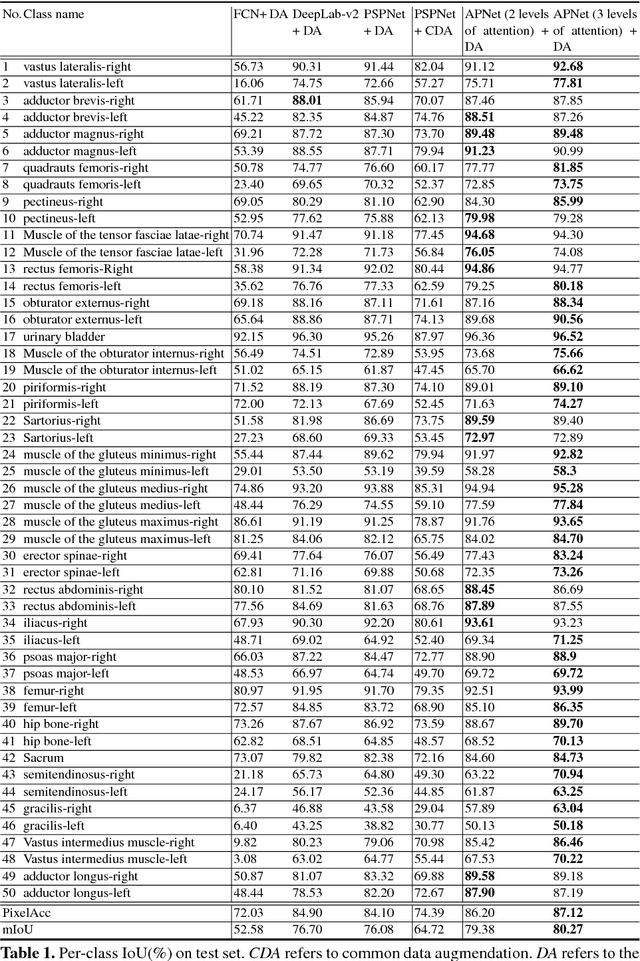

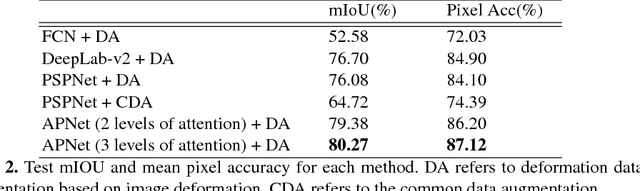
One of the time-consuming routine work for a radiologist is to discern anatomical structures from tomographic images. For assisting radiologists, this paper develops an automatic segmentation method for pelvic magnetic resonance (MR) images. The task has three major challenges 1) A pelvic organ can have various sizes and shapes depending on the axial image, which requires local contexts to segment correctly. 2) Different organs often have quite similar appearance in MR images, which requires global context to segment. 3) The number of available annotated images are very small to use the latest segmentation algorithms. To address the challenges, we propose a novel convolutional neural network called Attention-Pyramid network (APNet) that effectively exploits both local and global contexts, in addition to a data-augmentation technique that is particularly effective for MR images. In order to evaluate our method, we construct fine-grained (50 pelvic organs) MR image segmentation dataset, and experimentally confirm the superior performance of our techniques over the state-of-the-art image segmentation methods.
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020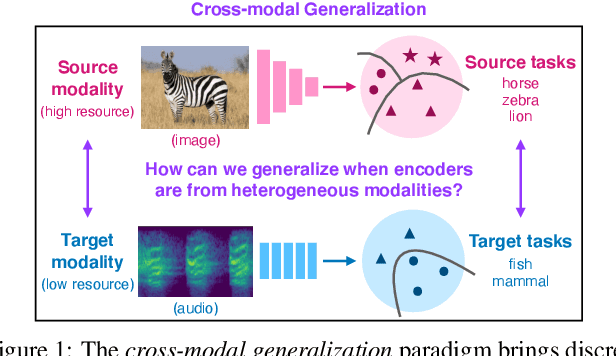
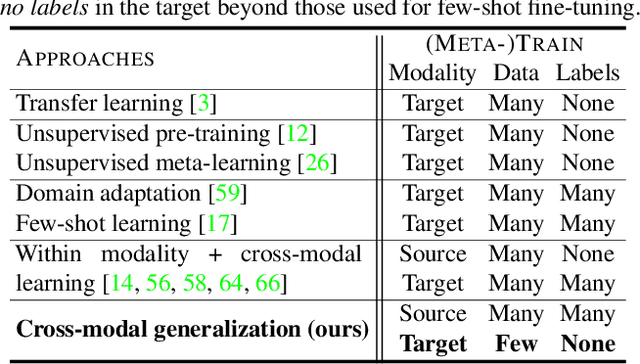
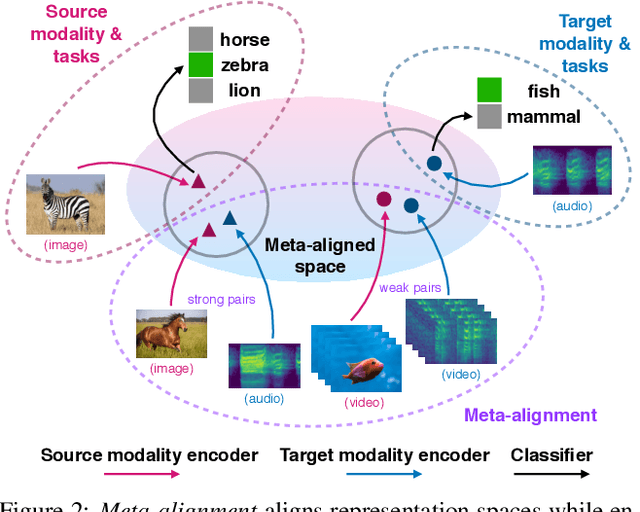
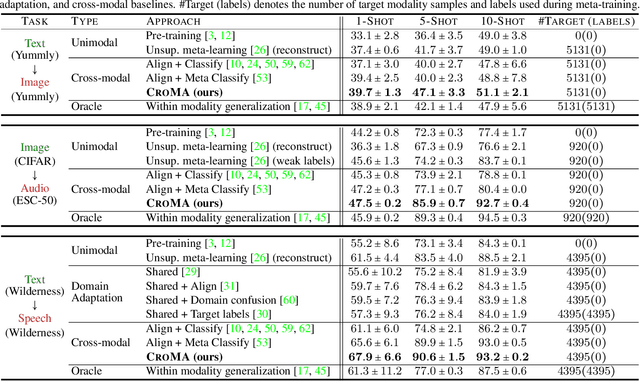
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
Effective Image Differencing with ConvNets for Real-time Transient Hunting
Oct 04, 2017

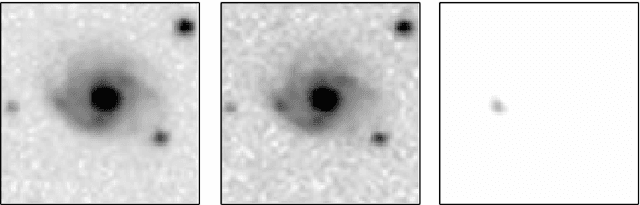
Large sky surveys are increasingly relying on image subtraction pipelines for real-time (and archival) transient detection. In this process one has to contend with varying PSF, small brightness variations in many sources, as well as artifacts resulting from saturated stars, and, in general, matching errors. Very often the differencing is done with a reference image that is deeper than individual images and the attendant difference in noise characteristics can also lead to artifacts. We present here a deep-learning approach to transient detection that encapsulates all the steps of a traditional image subtraction pipeline -- image registration, background subtraction, noise removal, psf matching, and subtraction -- into a single real-time convolutional network. Once trained the method works lighteningly fast, and given that it does multiple steps at one go, the advantages for multi-CCD, fast surveys like ZTF and LSST are obvious.
Large-scale image analysis using docker sandboxing
Mar 07, 2017


With the advent of specialized hardware such as Graphics Processing Units (GPUs), large scale image localization, classification and retrieval have seen increased prevalence. Designing scalable software architecture that co-evolves with such specialized hardware is a challenge in the commercial setting. In this paper, we describe one such architecture (\textit{Cortexica}) that leverages scalability of GPUs and sandboxing offered by docker containers. This allows for the flexibility of mixing different computer architectures as well as computational algorithms with the security of a trusted environment. We illustrate the utility of this framework in a commercial setting i.e., searching for multiple products in an image by combining image localisation and retrieval.
The Case for High-Accuracy Classification: Think Small, Think Many!
Mar 18, 2021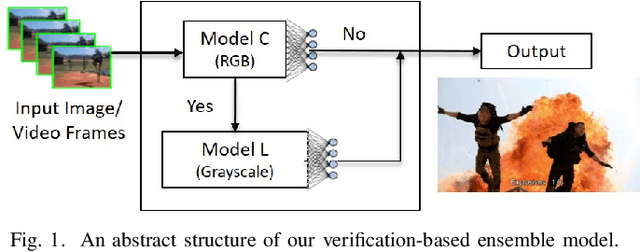

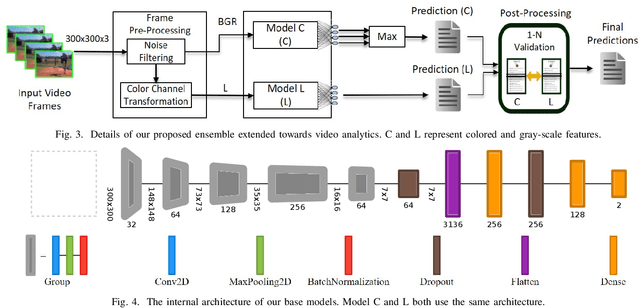
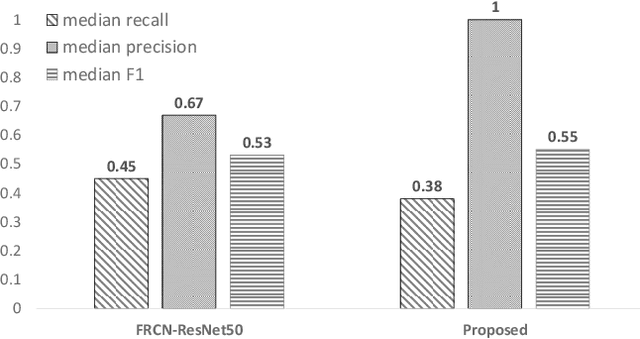
To facilitate implementation of high-accuracy deep neural networks especially on resource-constrained devices, maintaining low computation requirements is crucial. Using very deep models for classification purposes not only decreases the neural network training speed and increases the inference time, but also need more data for higher prediction accuracy and to mitigate false positives. In this paper, we propose an efficient and lightweight deep classification ensemble structure based on a combination of simple color features, which is particularly designed for "high-accuracy" image classifications with low false positives. We designed, implemented, and evaluated our approach for explosion detection use-case applied to images and videos. Our evaluation results based on a large test test show considerable improvements on the prediction accuracy compared to the popular ResNet-50 model, while benefiting from 7.64x faster inference and lower computation cost. While we applied our approach to explosion detection, our approach is general and can be applied to other similar classification use cases as well. Given the insight gained from our experiments, we hence propose a "think small, think many" philosophy in classification scenarios: that transforming a single, large, monolithic deep model into a verification-based step model ensemble of multiple small, simple, lightweight models with narrowed-down color spaces can possibly lead to predictions with higher accuracy.
Exploiting Adam-like Optimization Algorithms to Improve the Performance of Convolutional Neural Networks
Mar 26, 2021
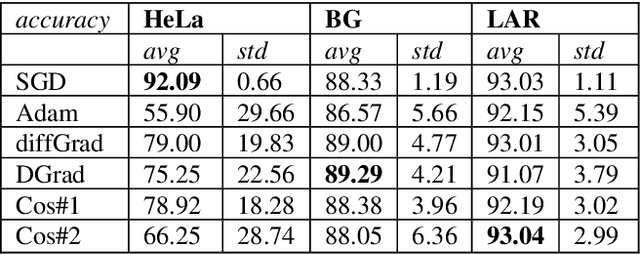
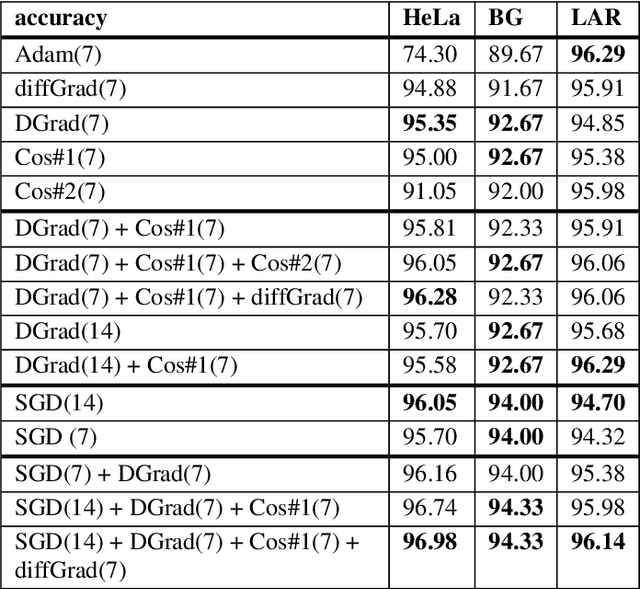
Stochastic gradient descent (SGD) is the main approach for training deep networks: it moves towards the optimum of the cost function by iteratively updating the parameters of a model in the direction of the gradient of the loss evaluated on a minibatch. Several variants of SGD have been proposed to make adaptive step sizes for each parameter (adaptive gradient) and take into account the previous updates (momentum). Among several alternative of SGD the most popular are AdaGrad, AdaDelta, RMSProp and Adam which scale coordinates of the gradient by square roots of some form of averaging of the squared coordinates in the past gradients and automatically adjust the learning rate on a parameter basis. In this work, we compare Adam based variants based on the difference between the present and the past gradients, the step size is adjusted for each parameter. We run several tests benchmarking proposed methods using medical image data. The experiments are performed using ResNet50 architecture neural network. Moreover, we have tested ensemble of networks and the fusion with ResNet50 trained with stochastic gradient descent. To combine the set of ResNet50 the simple sum rule has been applied. Proposed ensemble obtains very high performance, it obtains accuracy comparable or better than actual state of the art. To improve reproducibility and research efficiency the MATLAB source code used for this research is available at GitHub: https://github.com/LorisNanni.
On Generating Transferable Targeted Perturbations
Mar 26, 2021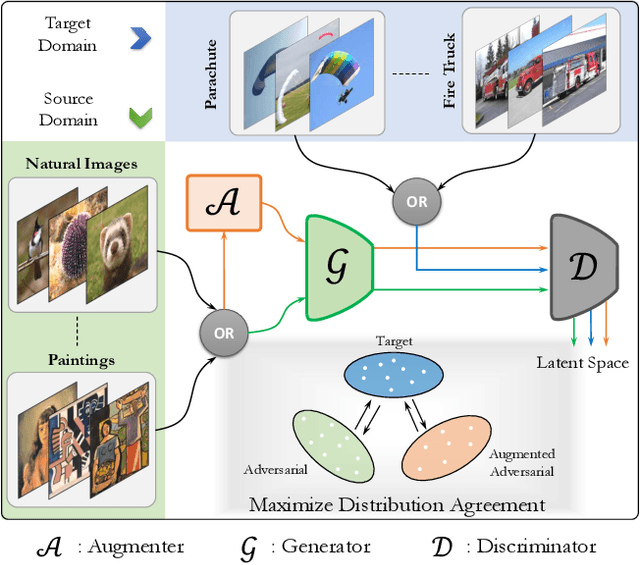
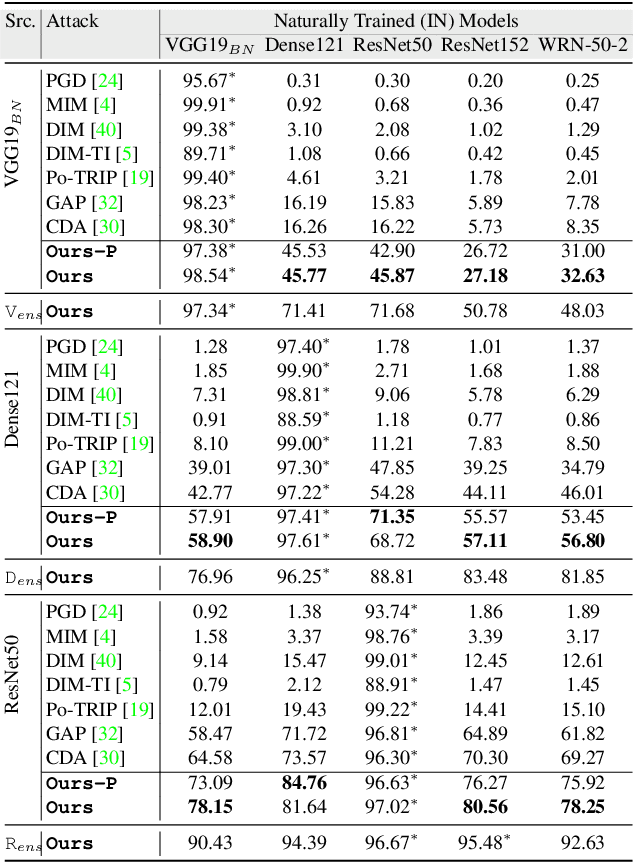

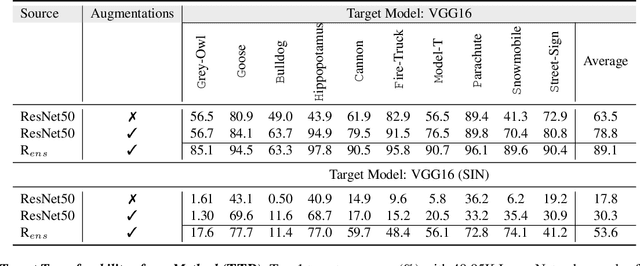
While the untargeted black-box transferability of adversarial perturbations has been extensively studied before, changing an unseen model's decisions to a specific `targeted' class remains a challenging feat. In this paper, we propose a new generative approach for highly transferable targeted perturbations (\ours). We note that the existing methods are less suitable for this task due to their reliance on class-boundary information that changes from one model to another, thus reducing transferability. In contrast, our approach matches the perturbed image `distribution' with that of the target class, leading to high targeted transferability rates. To this end, we propose a new objective function that not only aligns the global distributions of source and target images, but also matches the local neighbourhood structure between the two domains. Based on the proposed objective, we train a generator function that can adaptively synthesize perturbations specific to a given input. Our generative approach is independent of the source or target domain labels, while consistently performs well against state-of-the-art methods on a wide range of attack settings. As an example, we achieve $32.63\%$ target transferability from (an adversarially weak) VGG19$_{BN}$ to (a strong) WideResNet on ImageNet val. set, which is 4$\times$ higher than the previous best generative attack and 16$\times$ better than instance-specific iterative attack. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/TTP}}.
MMDF: Mobile Microscopy Deep Framework
Jul 27, 2020

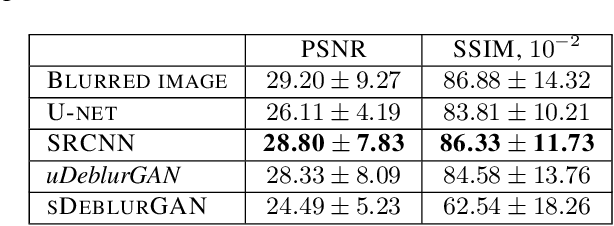
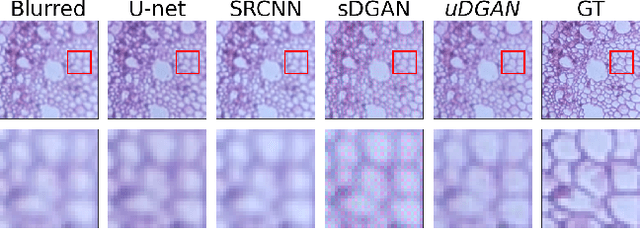
In the last decade, a huge step was done in the field of mobile microscopes development as well as in the field of mobile microscopy application to real-life disease diagnostics and a lot of other important areas (air/water quality pollution, education, agriculture). In current study we applied image processing techniques from Deep Learning (in-focus/out-of-focus classification, image deblurring and denoising, multi-focus image fusion) to the data obtained from the mobile microscope. Overview of significant works for every task is presented, the most suitable approaches were highlighted. Chosen approaches were implemented as well as their performance were compared with classical computer vision techniques.