 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RAISR: Rapid and Accurate Image Super Resolution
Oct 04, 2016
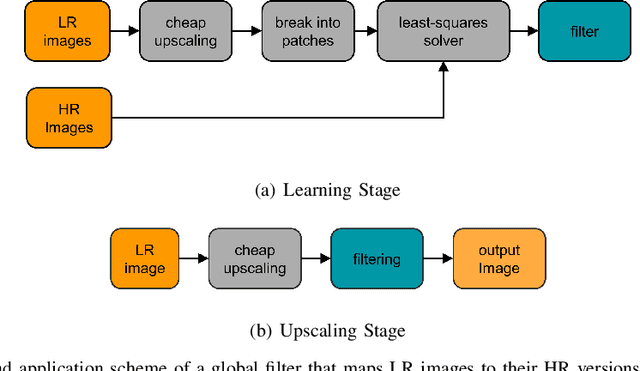
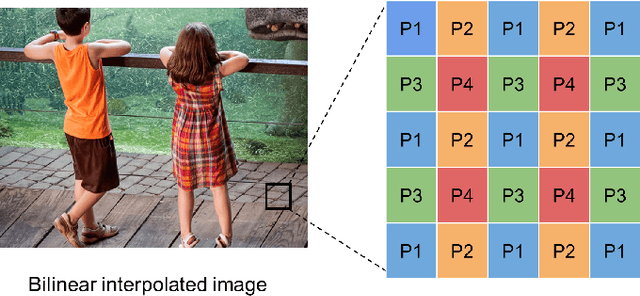
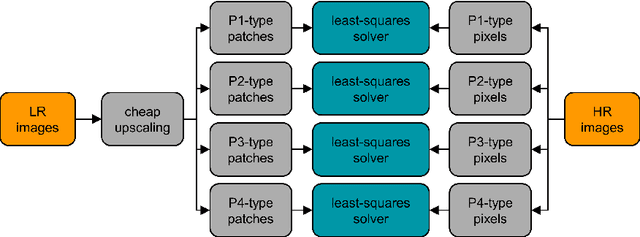
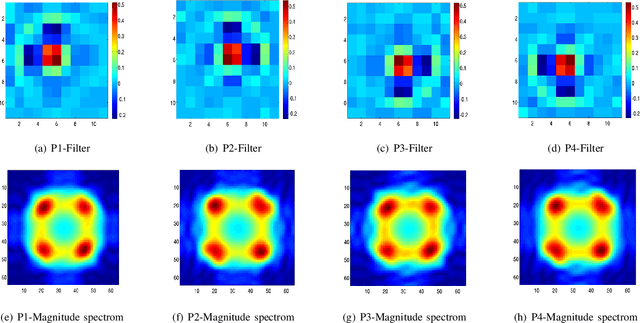
Given an image, we wish to produce an image of larger size with significantly more pixels and higher image quality. This is generally known as the Single Image Super-Resolution (SISR) problem. The idea is that with sufficient training data (corresponding pairs of low and high resolution images) we can learn set of filters (i.e. a mapping) that when applied to given image that is not in the training set, will produce a higher resolution version of it, where the learning is preferably low complexity. In our proposed approach, the run-time is more than one to two orders of magnitude faster than the best competing methods currently available, while producing results comparable or better than state-of-the-art. A closely related topic is image sharpening and contrast enhancement, i.e., improving the visual quality of a blurry image by amplifying the underlying details (a wide range of frequencies). Our approach additionally includes an extremely efficient way to produce an image that is significantly sharper than the input blurry one, without introducing artifacts such as halos and noise amplification. We illustrate how this effective sharpening algorithm, in addition to being of independent interest, can be used as a pre-processing step to induce the learning of more effective upscaling filters with built-in sharpening and contrast enhancement effect.
Learnable Companding Quantization for Accurate Low-bit Neural Networks
Mar 12, 2021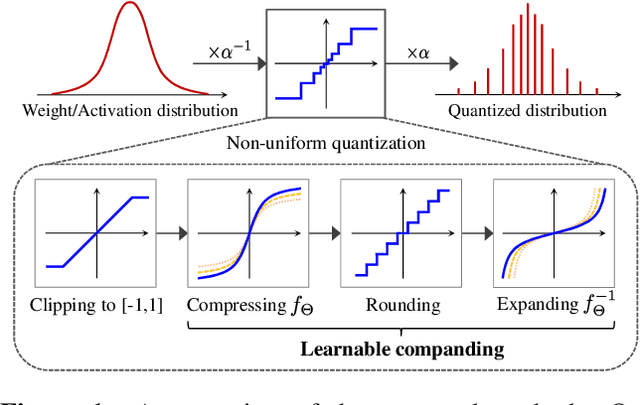
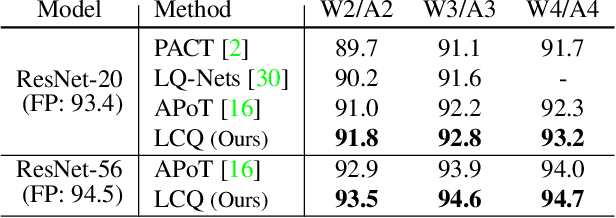
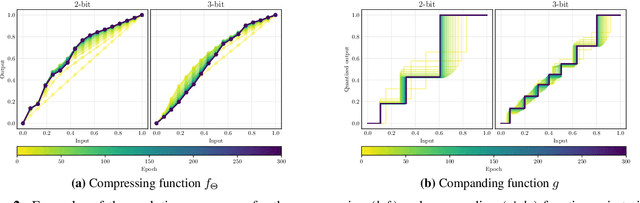
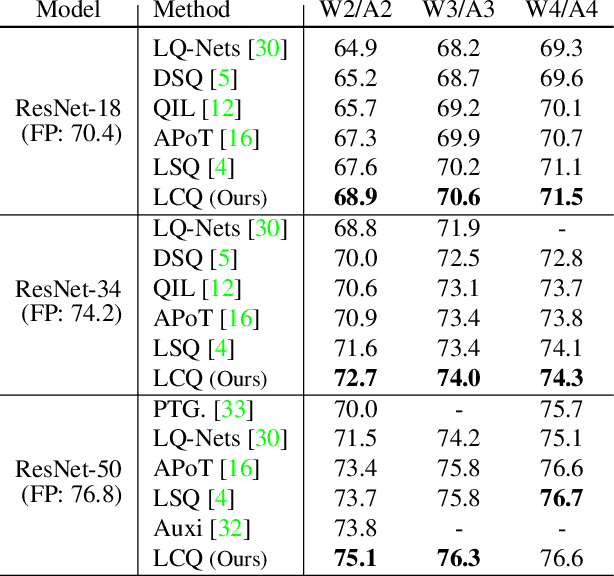
Quantizing deep neural networks is an effective method for reducing memory consumption and improving inference speed, and is thus useful for implementation in resource-constrained devices. However, it is still hard for extremely low-bit models to achieve accuracy comparable with that of full-precision models. To address this issue, we propose learnable companding quantization (LCQ) as a novel non-uniform quantization method for 2-, 3-, and 4-bit models. LCQ jointly optimizes model weights and learnable companding functions that can flexibly and non-uniformly control the quantization levels of weights and activations. We also present a new weight normalization technique that allows more stable training for quantization. Experimental results show that LCQ outperforms conventional state-of-the-art methods and narrows the gap between quantized and full-precision models for image classification and object detection tasks. Notably, the 2-bit ResNet-50 model on ImageNet achieves top-1 accuracy of 75.1% and reduces the gap to 1.7%, allowing LCQ to further exploit the potential of non-uniform quantization.
Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing
May 14, 2018

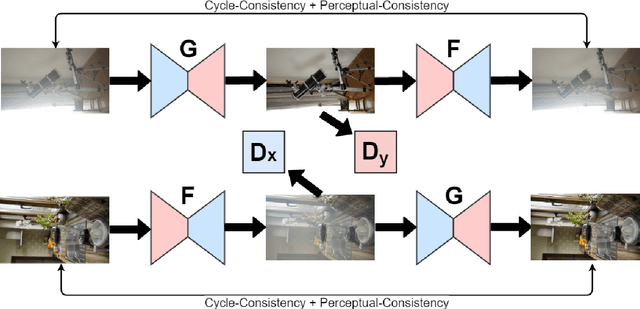
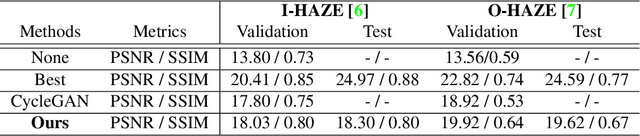
In this paper, we present an end-to-end network, called Cycle-Dehaze, for single image dehazing problem, which does not require pairs of hazy and corresponding ground truth images for training. That is, we train the network by feeding clean and hazy images in an unpaired manner. Moreover, the proposed approach does not rely on estimation of the atmospheric scattering model parameters. Our method enhances CycleGAN formulation by combining cycle-consistency and perceptual losses in order to improve the quality of textural information recovery and generate visually better haze-free images. Typically, deep learning models for dehazing take low resolution images as input and produce low resolution outputs. However, in the NTIRE 2018 challenge on single image dehazing, high resolution images were provided. Therefore, we apply bicubic downscaling. After obtaining low-resolution outputs from the network, we utilize the Laplacian pyramid to upscale the output images to the original resolution. We conduct experiments on NYU-Depth, I-HAZE, and O-HAZE datasets. Extensive experiments demonstrate that the proposed approach improves CycleGAN method both quantitatively and qualitatively.
Boundary-based Image Forgery Detection by Fast Shallow CNN
Feb 03, 2018
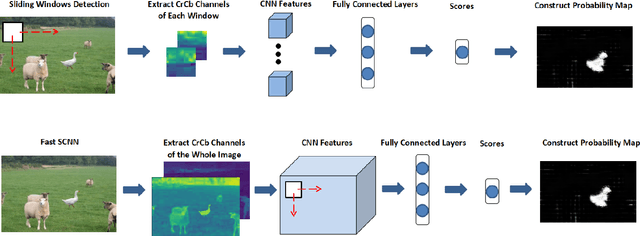


Image forgery detection is the task of detecting and localizing forged parts in tampered images. Previous works mostly focus on high resolution images using traces of resampling features, demosaicing features or sharpness of edges. However, a good detection method should also be applicable to low resolution images because compressed or resized images are common these days. To this end, we propose a Shallow Convolutional Neural Network(SCNN), capable of distinguishing the boundaries of forged regions from original edges in low resolution images. SCNN is designed to utilize the information of chroma and saturation. Based on SCNN, two approaches that are named Sliding Windows Detection (SWD) and Fast SCNN, respectively, are developed to detect and localize image forgery region. In this paper, we substantiate that Fast SCNN can detect drastic change of chroma and saturation. In image forgery detection experiments Our model is evaluated on the CASIA 2.0 dataset. The results show that Fast SCNN performs well on low resolution images and achieves significant improvements over the state-of-the-art.
Pyramidal RoR for Image Classification
Oct 01, 2017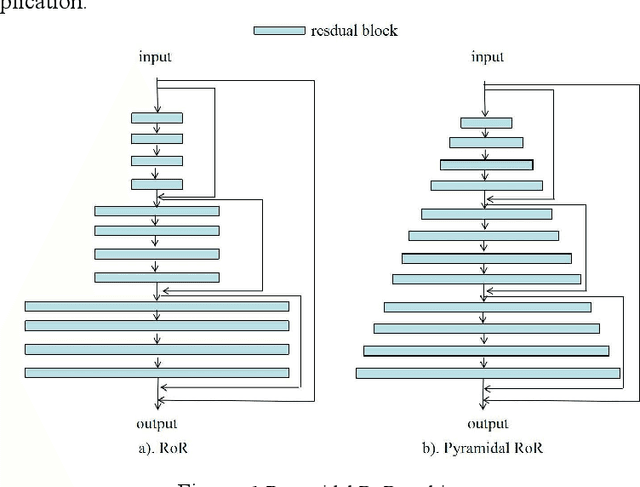

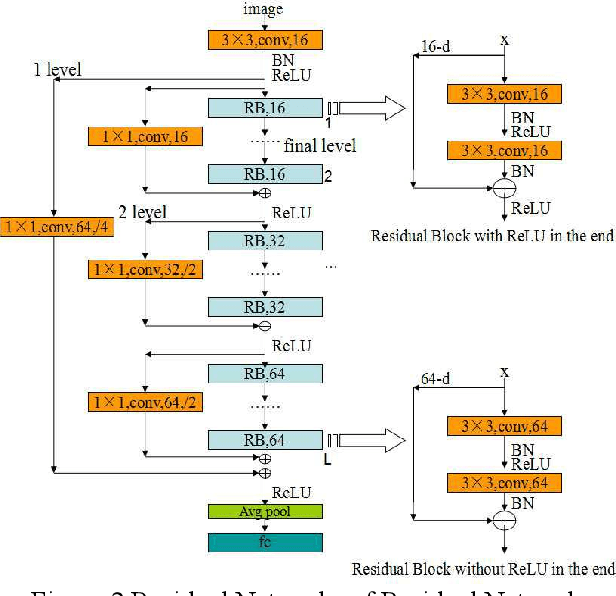

The Residual Networks of Residual Networks (RoR) exhibits excellent performance in the image classification task, but sharply increasing the number of feature map channels makes the characteristic information transmission incoherent, which losses a certain of information related to classification prediction, limiting the classification performance. In this paper, a Pyramidal RoR network model is proposed by analysing the performance characteristics of RoR and combining with the PyramidNet. Firstly, based on RoR, the Pyramidal RoR network model with channels gradually increasing is designed. Secondly, we analysed the effect of different residual block structures on performance, and chosen the residual block structure which best favoured the classification performance. Finally, we add an important principle to further optimize Pyramidal RoR networks, drop-path is used to avoid over-fitting and save training time. In this paper, image classification experiments were performed on CIFAR-10/100 and SVHN datasets, and we achieved the current lowest classification error rates were 2.96%, 16.40% and 1.59%, respectively. Experiments show that the Pyramidal RoR network optimization method can improve the network performance for different data sets and effectively suppress the gradient disappearance problem in DCNN training.
Thousand to One: Semantic Prior Modeling for Conceptual Coding
Mar 12, 2021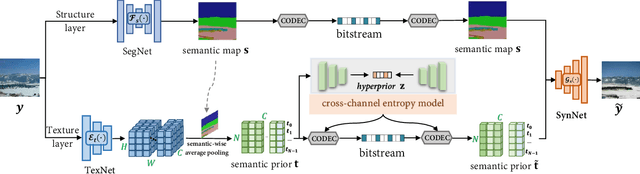
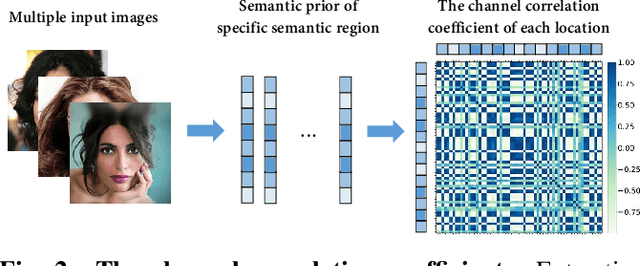

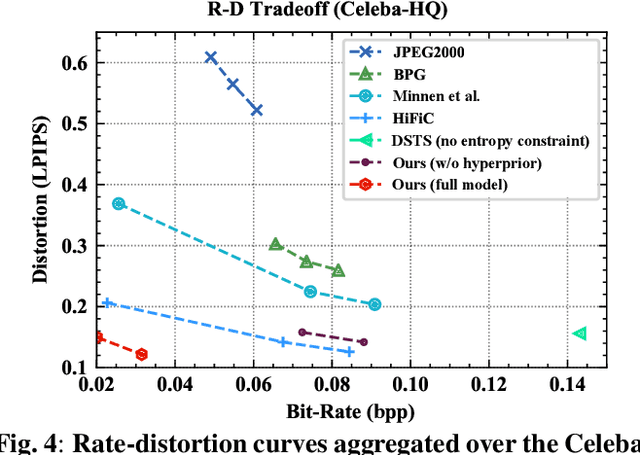
Conceptual coding has been an emerging research topic recently, which encodes natural images into disentangled conceptual representations for compression. However, the compression performance of the existing methods is still sub-optimal due to the lack of comprehensive consideration of rate constraint and reconstruction quality. To this end, we propose a novel end-to-end semantic prior modeling-based conceptual coding scheme towards extremely low bitrate image compression, which leverages semantic-wise deep representations as a unified prior for entropy estimation and texture synthesis. Specifically, we employ semantic segmentation maps as structural guidance for extracting deep semantic prior, which provides fine-grained texture distribution modeling for better detail construction and higher flexibility in subsequent high-level vision tasks. Moreover, a cross-channel entropy model is proposed to further exploit the inter-channel correlation of the spatially independent semantic prior, leading to more accurate entropy estimation for rate-constrained training. The proposed scheme achieves an ultra-high 1000x compression ratio, while still enjoying high visual reconstruction quality and versatility towards visual processing and analysis tasks.
What Does CNN Shift Invariance Look Like? A Visualization Study
Nov 09, 2020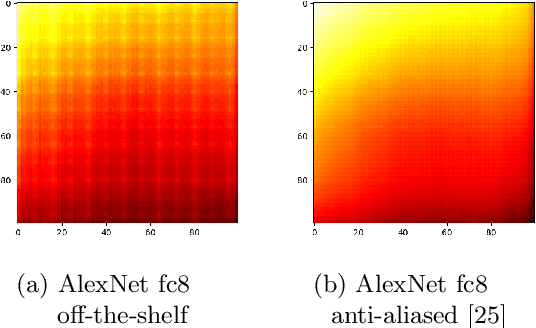
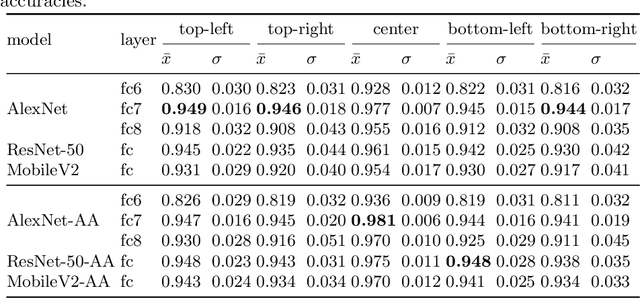
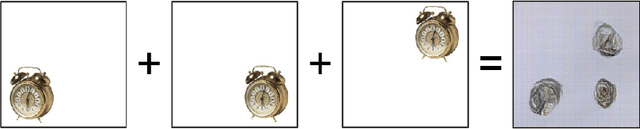
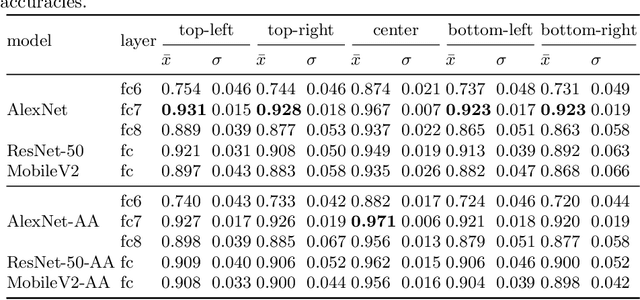
Feature extraction with convolutional neural networks (CNNs) is a popular method to represent images for machine learning tasks. These representations seek to capture global image content, and ideally should be independent of geometric transformations. We focus on measuring and visualizing the shift invariance of extracted features from popular off-the-shelf CNN models. We present the results of three experiments comparing representations of millions of images with exhaustively shifted objects, examining both local invariance (within a few pixels) and global invariance (across the image frame). We conclude that features extracted from popular networks are not globally invariant, and that biases and artifacts exist within this variance. Additionally, we determine that anti-aliased models significantly improve local invariance but do not impact global invariance. Finally, we provide a code repository for experiment reproduction, as well as a website to interact with our results at https://jakehlee.github.io/visualize-invariance.
Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network
Feb 11, 2021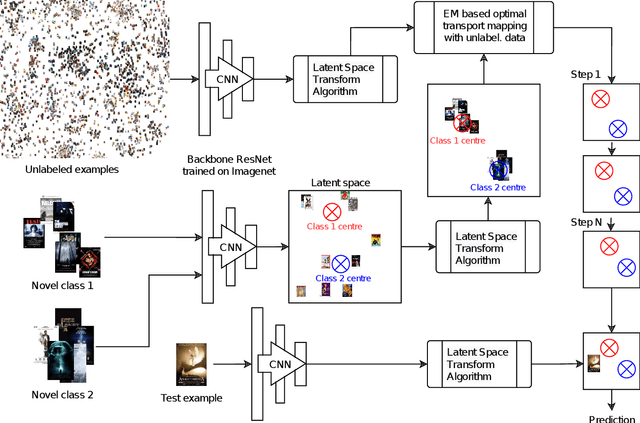
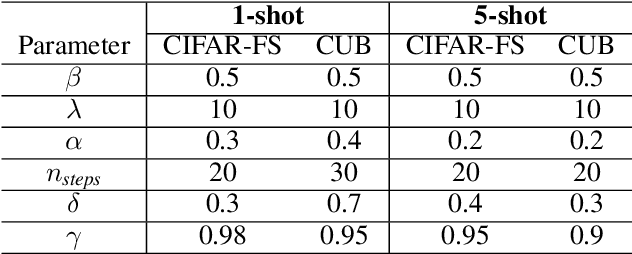
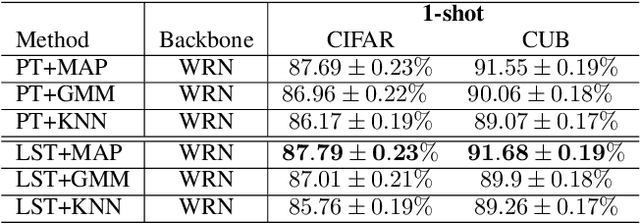
MetaDL Challenge 2020 focused on image classification tasks in few-shot settings. This paper describes second best submission in the competition. Our meta learning approach modifies the distribution of classes in a latent space produced by a backbone network for each class in order to better follow the Gaussian distribution. After this operation which we call Latent Space Transform algorithm, centers of classes are further aligned in an iterative fashion of the Expectation Maximisation algorithm to utilize information in unlabeled data that are often provided on top of few labelled instances. For this task, we utilize optimal transport mapping using the Sinkhorn algorithm. Our experiments show that this approach outperforms previous works as well as other variants of the algorithm, using K-Nearest Neighbour algorithm, Gaussian Mixture Models, etc.
VideoMix: Rethinking Data Augmentation for Video Classification
Dec 07, 2020
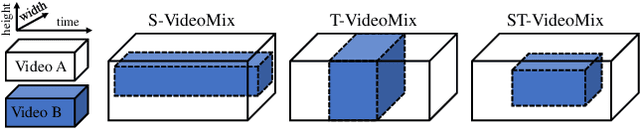
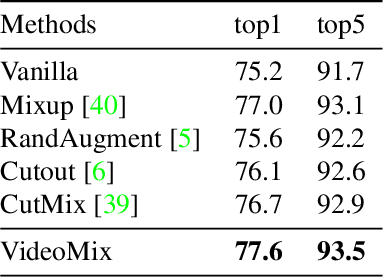
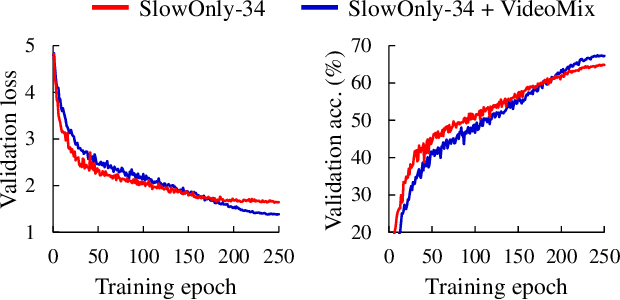
State-of-the-art video action classifiers often suffer from overfitting. They tend to be biased towards specific objects and scene cues, rather than the foreground action content, leading to sub-optimal generalization performances. Recent data augmentation strategies have been reported to address the overfitting problems in static image classifiers. Despite the effectiveness on the static image classifiers, data augmentation has rarely been studied for videos. For the first time in the field, we systematically analyze the efficacy of various data augmentation strategies on the video classification task. We then propose a powerful augmentation strategy VideoMix. VideoMix creates a new training video by inserting a video cuboid into another video. The ground truth labels are mixed proportionally to the number of voxels from each video. We show that VideoMix lets a model learn beyond the object and scene biases and extract more robust cues for action recognition. VideoMix consistently outperforms other augmentation baselines on Kinetics and the challenging Something-Something-V2 benchmarks. It also improves the weakly-supervised action localization performance on THUMOS'14. VideoMix pretrained models exhibit improved accuracies on the video detection task (AVA).
Dual Attention-in-Attention Model for Joint Rain Streak and Raindrop Removal
Mar 12, 2021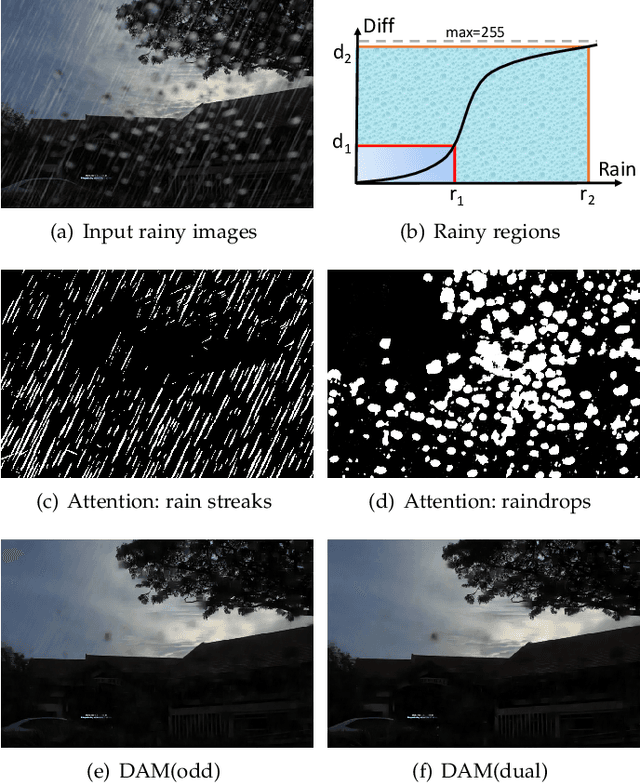
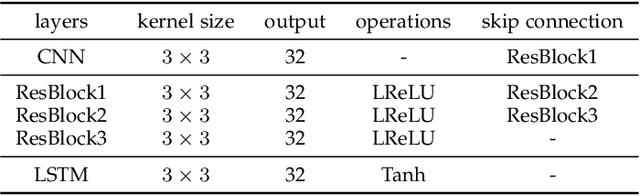
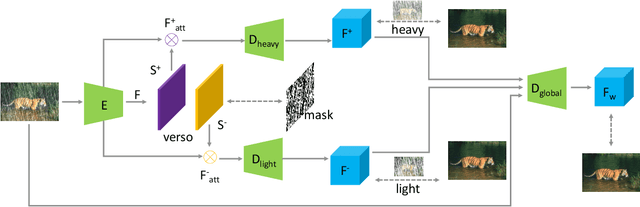
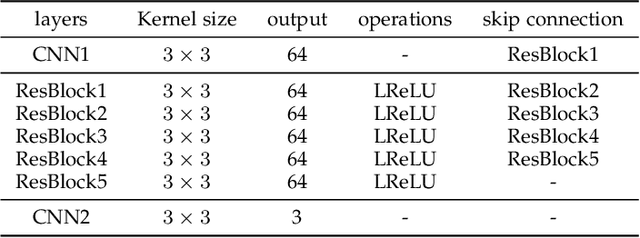
Rain streaks and rain drops are two natural phenomena, which degrade image capture in different ways. Currently, most existing deep deraining networks take them as two distinct problems and individually address one, and thus cannot deal adequately with both simultaneously. To address this, we propose a Dual Attention-in-Attention Model (DAiAM) which includes two DAMs for removing both rain streaks and raindrops. Inside the DAM, there are two attentive maps - each of which attends to the heavy and light rainy regions, respectively, to guide the deraining process differently for applicable regions. In addition, to further refine the result, a Differential-driven Dual Attention-in-Attention Model (D-DAiAM) is proposed with a "heavy-to-light" scheme to remove rain via addressing the unsatisfying deraining regions. Extensive experiments on one public raindrop dataset, one public rain streak and our synthesized joint rain streak and raindrop (JRSRD) dataset have demonstrated that the proposed method not only is capable of removing rain streaks and raindrops simultaneously, but also achieves the state-of-the-art performance on both tasks.