 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
For Manifold Learning, Deep Neural Networks can be Locality Sensitive Hash Functions
Mar 11, 2021
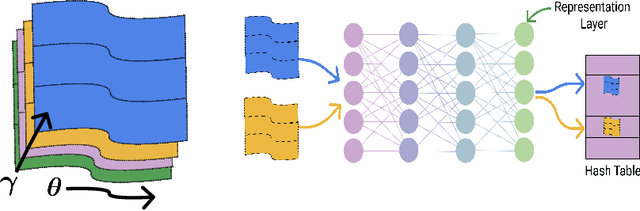
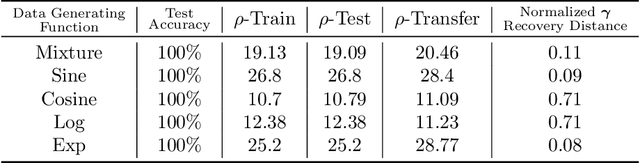

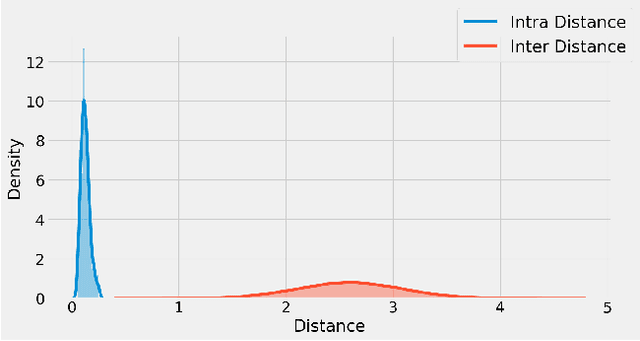
It is well established that training deep neural networks gives useful representations that capture essential features of the inputs. However, these representations are poorly understood in theory and practice. In the context of supervised learning an important question is whether these representations capture features informative for classification, while filtering out non-informative noisy ones. We explore a formalization of this question by considering a generative process where each class is associated with a high-dimensional manifold and different classes define different manifolds. Under this model, each input is produced using two latent vectors: (i) a "manifold identifier" $\gamma$ and; (ii)~a "transformation parameter" $\theta$ that shifts examples along the surface of a manifold. E.g., $\gamma$ might represent a canonical image of a dog, and $\theta$ might stand for variations in pose, background or lighting. We provide theoretical and empirical evidence that neural representations can be viewed as LSH-like functions that map each input to an embedding that is a function of solely the informative $\gamma$ and invariant to $\theta$, effectively recovering the manifold identifier $\gamma$. An important consequence of this behavior is one-shot learning to unseen classes.
A Dense-Depth Representation for VLAD descriptors in Content-Based Image Retrieval
Aug 15, 2018
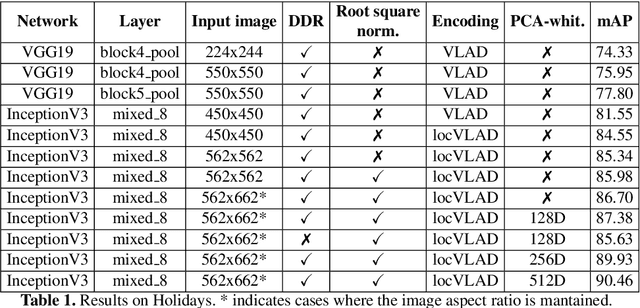
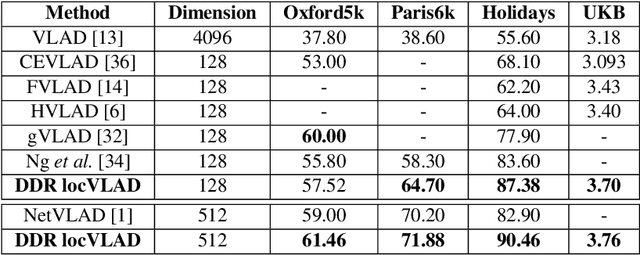
The recent advances brought by deep learning allowed to improve the performance in image retrieval tasks. Through the many convolutional layers, available in a Convolutional Neural Network (CNN), it is possible to obtain a hierarchy of features from the evaluated image. At every step, the patches extracted are smaller than the previous levels and more representative. Following this idea, this paper introduces a new detector applied on the feature maps extracted from pre-trained CNN. Specifically, this approach lets to increase the number of features in order to increase the performance of the aggregation algorithms like the most famous and used VLAD embedding. The proposed approach is tested on different public datasets: Holidays, Oxford5k, Paris6k and UKB.
Robust Regression For Image Binarization Under Heavy Noises and Nonuniform Background
Jul 06, 2017
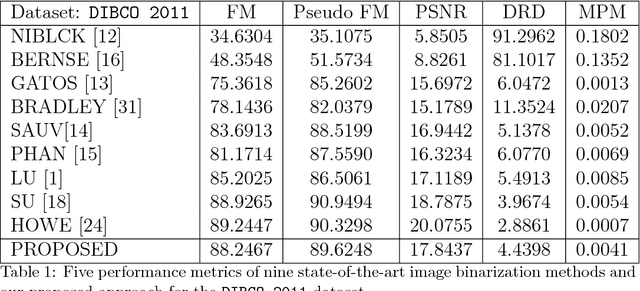
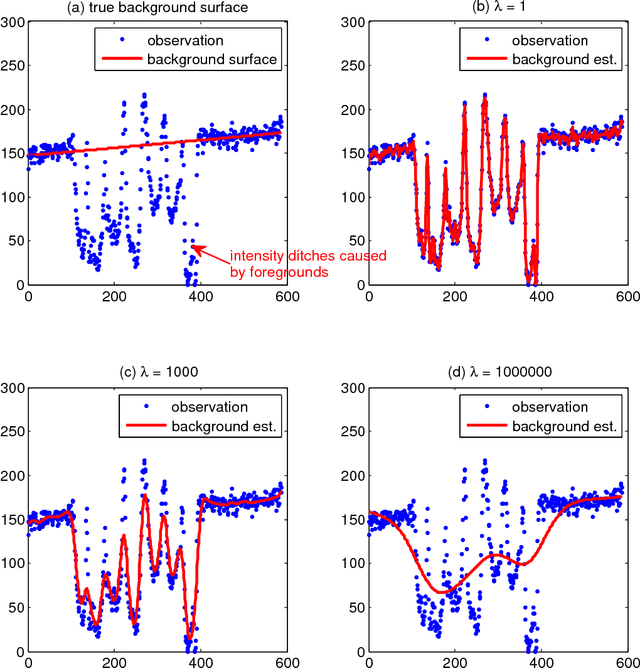
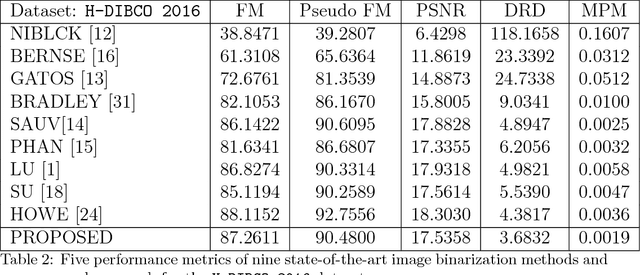
This paper presents a robust regression approach for image binarization under significant background variations and observation noises. The work is motivated by the need of identifying foreground regions in noisy microscopic image or degraded document images, where significant background variation and severe noise make an image binarization challenging. The proposed method first estimates the background of an input image, subtracts the estimated background from the input image, and apply a global thresholding to the subtracted outcome for achieving a binary image of foregrounds. A robust regression approach was proposed to estimate the background intensity surface with minimal effects of foreground intensities and noises, and a global threshold selector was proposed on the basis of a model selection criterion in a sparse regression. The proposed approach was validated using 26 test images and the corresponding ground truths, and the outcomes of the proposed work were compared with those from nine existing image binarization methods. The approach was also combined with three state-of-the-art morphological segmentation methods to show how the proposed approach can improve their image segmentation outcomes.
Adaptive Structure-constrained Robust Latent Low-Rank Coding for Image Recovery
Aug 21, 2019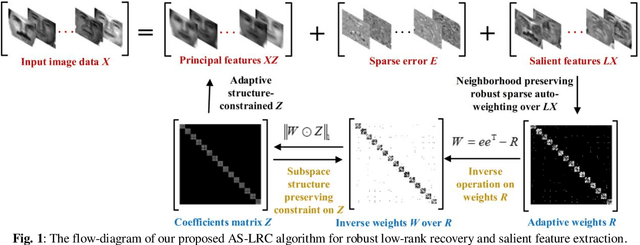

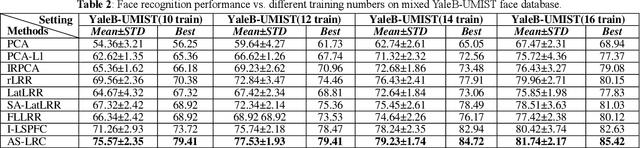
In this paper, we propose a robust representation learning model called Adaptive Structure-constrained Low-Rank Coding (AS-LRC) for the latent representation of data. To recover the underlying subspaces more accurately, AS-LRC seamlessly integrates an adaptive weighting based block-diagonal structure-constrained low-rank representation and the group sparse salient feature extraction into a unified framework. Specifically, AS-LRC performs the latent decomposition of given data into a low-rank reconstruction by a block-diagonal codes matrix, a group sparse locality-adaptive salient feature part and a sparse error part. To enforce the block-diagonal structures adaptive to different real datasets for the low-rank recovery, AS-LRC clearly computes an auto-weighting matrix based on the locality-adaptive features and multiplies by the low-rank coefficients for direct minimization at the same time. This encourages the codes to be block-diagonal and can avoid the tricky issue of choosing optimal neighborhood size or kernel width for the weight assignment, suffered in most local geometrical structures-preserving low-rank coding methods. In addition, our AS-LRC selects the L2,1-norm on the projection for extracting group sparse features rather than learning low-rank features by Nuclear-norm regularization, which can make learnt features robust to noise and outliers in samples, and can also make the feature coding process efficient. Extensive visualizations and numerical results demonstrate the effectiveness of our AS-LRC for image representation and recovery.
Learning and aggregating deep local descriptors for instance-level recognition
Jul 26, 2020
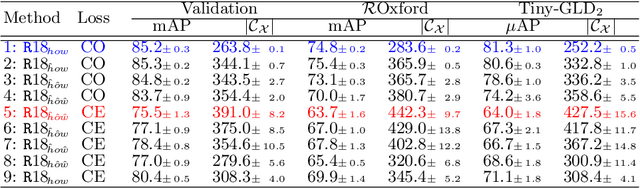
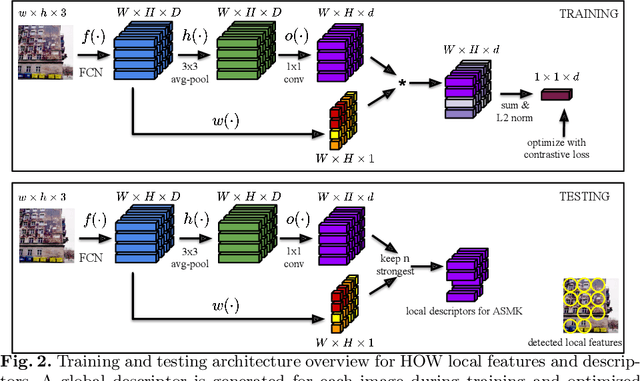
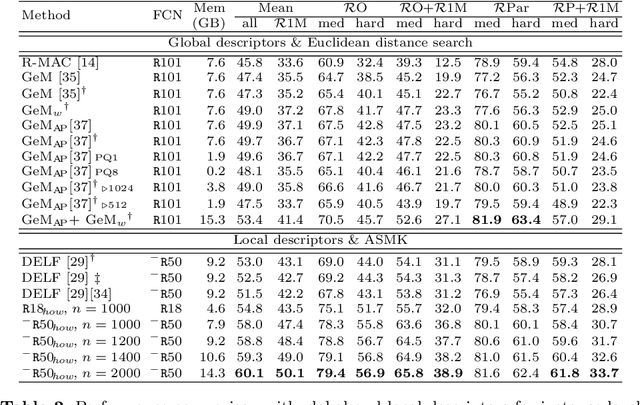
We propose an efficient method to learn deep local descriptors for instance-level recognition. The training only requires examples of positive and negative image pairs and is performed as metric learning of sum-pooled global image descriptors. At inference, the local descriptors are provided by the activations of internal components of the network. We demonstrate why such an approach learns local descriptors that work well for image similarity estimation with classical efficient match kernel methods. The experimental validation studies the trade-off between performance and memory requirements of the state-of-the-art image search approach based on match kernels. Compared to existing local descriptors, the proposed ones perform better in two instance-level recognition tasks and keep memory requirements lower. We experimentally show that global descriptors are not effective enough at large scale and that local descriptors are essential. We achieve state-of-the-art performance, in some cases even with a backbone network as small as ResNet18.
Monocular 3D Multi-Person Pose Estimation by Integrating Top-Down and Bottom-Up Networks
Apr 05, 2021
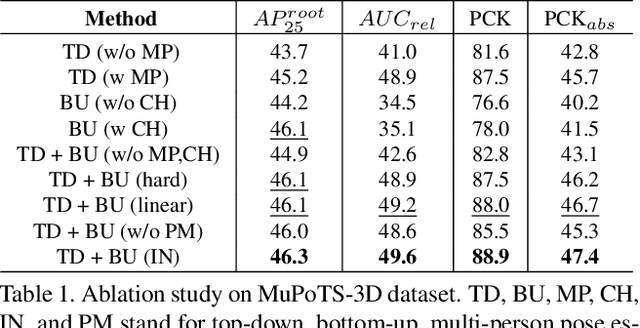
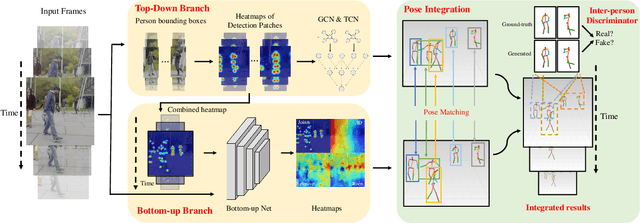
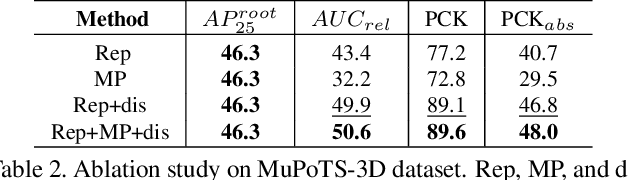
In monocular video 3D multi-person pose estimation, inter-person occlusion and close interactions can cause human detection to be erroneous and human-joints grouping to be unreliable. Existing top-down methods rely on human detection and thus suffer from these problems. Existing bottom-up methods do not use human detection, but they process all persons at once at the same scale, causing them to be sensitive to multiple-persons scale variations. To address these challenges, we propose the integration of top-down and bottom-up approaches to exploit their strengths. Our top-down network estimates human joints from all persons instead of one in an image patch, making it robust to possible erroneous bounding boxes. Our bottom-up network incorporates human-detection based normalized heatmaps, allowing the network to be more robust in handling scale variations. Finally, the estimated 3D poses from the top-down and bottom-up networks are fed into our integration network for final 3D poses. Besides the integration of top-down and bottom-up networks, unlike existing pose discriminators that are designed solely for single person, and consequently cannot assess natural inter-person interactions, we propose a two-person pose discriminator that enforces natural two-person interactions. Lastly, we also apply a semi-supervised method to overcome the 3D ground-truth data scarcity. Our quantitative and qualitative evaluations show the effectiveness of our method compared to the state-of-the-art baselines.
Robust, fast and accurate: a 3-step method for automatic histological image registration
Mar 29, 2019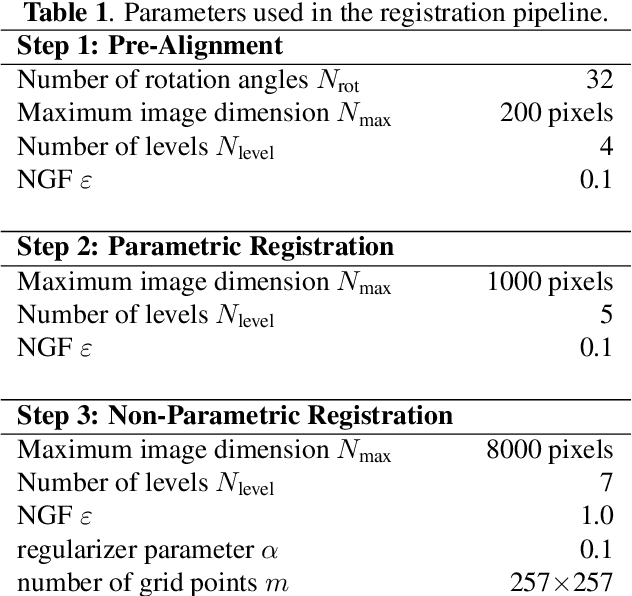
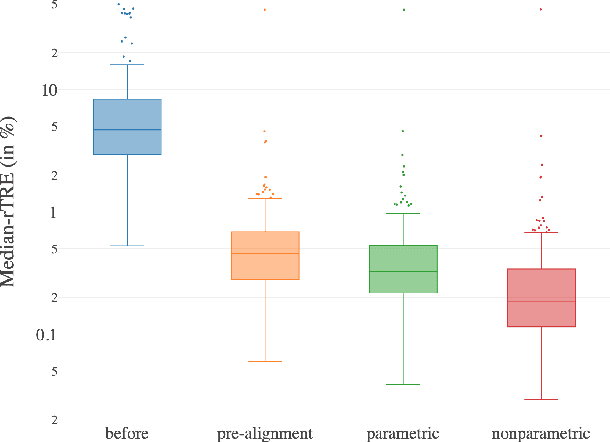
We present a 3-step registration pipeline for differently stained histological serial sections that consists of 1) a robust pre-alignment, 2) a parametric registration computed on coarse resolution images, and 3) an accurate nonlinear registration. In all three steps the NGF distance measure is minimized with respect to an increasingly flexible transformation. We apply the method in the ANHIR image registration challenge and evaluate its performance on the training data. The presented method is robust (error reduction in 99.6% of the cases), fast (runtime 4 seconds) and accurate (median relative target registration error 0.19%).
Classifying neuromorphic data using a deep learning framework for image classification
Jul 02, 2018
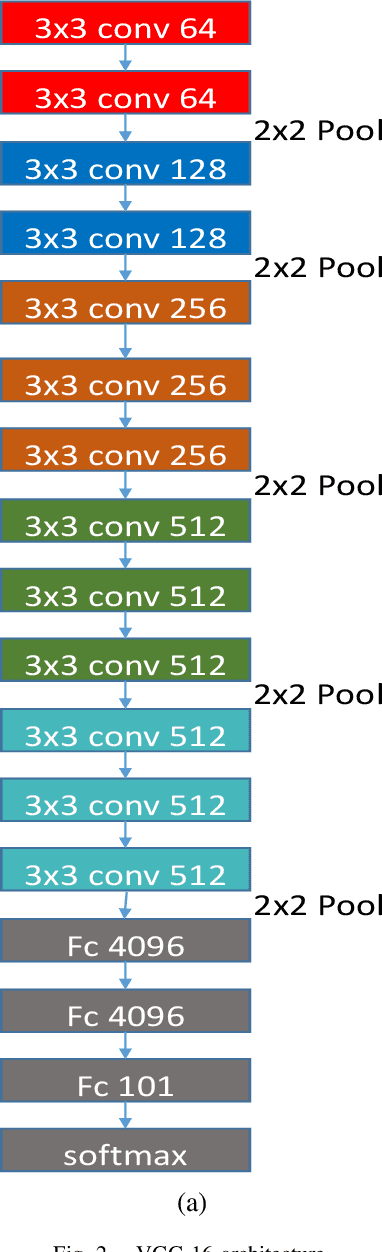
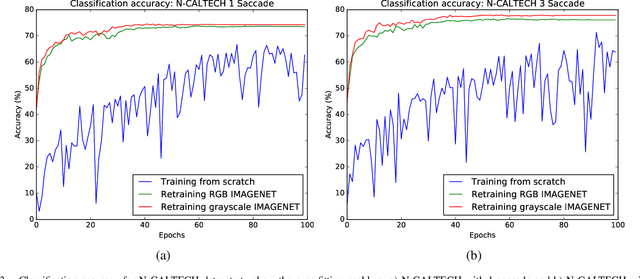
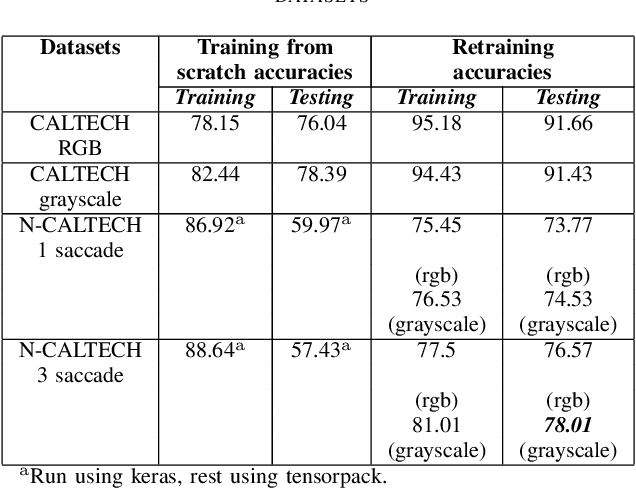
In the field of artificial intelligence, neuromorphic computing has been around for several decades. Deep learning has however made much recent progress such that it consistently outperforms neuromorphic learning algorithms in classification tasks in terms of accuracy. Specifically in the field of image classification, neuromorphic computing has been traditionally using either the temporal or rate code for encoding static images in datasets into spike trains. It is only till recently, that neuromorphic vision sensors are widely used by the neuromorphic research community, and provides an alternative to such encoding methods. Since then, several neuromorphic datasets as obtained by applying such sensors on image datasets (e.g. the neuromorphic CALTECH 101) have been introduced. These data are encoded in spike trains and hence seem ideal for benchmarking of neuromorphic learning algorithms. Specifically, we train a deep learning framework used for image classification on the CALTECH 101 and a collapsed version of the neuromorphic CALTECH 101 datasets. We obtained an accuracy of 91.66% and 78.01% for the CALTECH 101 and neuromorphic CALTECH 101 datasets respectively. For CALTECH 101, our accuracy is close to the best reported accuracy, while for neuromorphic CALTECH 101, it outperforms the last best reported accuracy by over 10%. This raises the question of the suitability of such datasets as benchmarks for neuromorphic learning algorithms.
Serial-parallel Multi-Scale Feature Fusion for Anatomy-Oriented Hand Joint Detection
Feb 19, 2021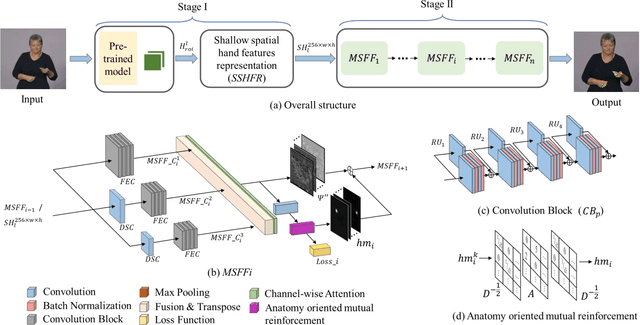

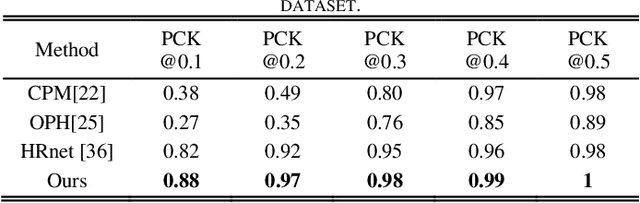
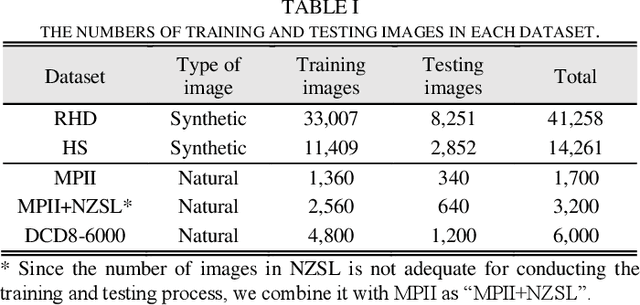
Accurate hand joints detection from images is a fundamental topic which is essential for many applications in computer vision and human computer interaction. This paper presents a two stage network for hand joints detection from single unmarked image by using serial-parallel multi-scale feature fusion. In stage I, the hand regions are located by a pre-trained network, and the features of each detected hand region are extracted by a shallow spatial hand features representation module. The extracted hand features are then fed into stage II, which consists of serially connected feature extraction modules with similar structures, called "multi-scale feature fusion" (MSFF). A MSFF contains parallel multi-scale feature extraction branches, which generate initial hand joint heatmaps. The initial heatmaps are then mutually reinforced by the anatomic relationship between hand joints. The experimental results on five hand joints datasets show that the proposed network overperforms the state-of-the-art methods.
Anomaly Detection with Deep Perceptual Autoencoders
Jun 23, 2020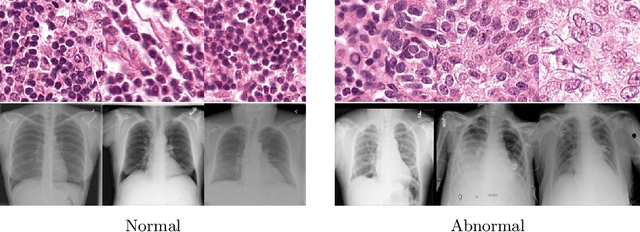
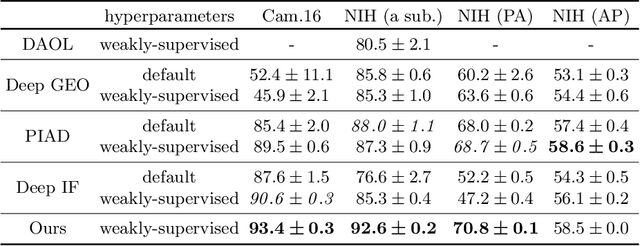
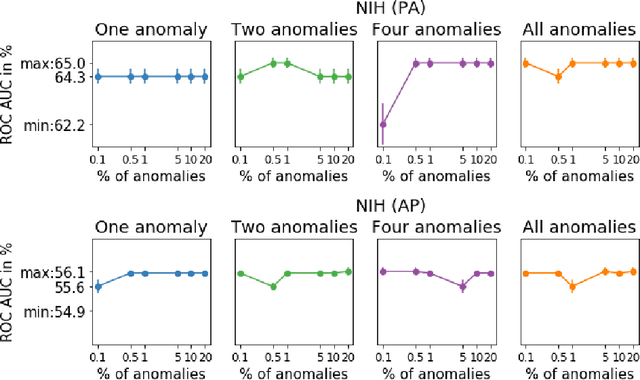

Anomaly detection is the problem of recognizing abnormal inputs based on the seen examples of normal data. Despite recent advances of deep learning in recognizing image anomalies, these methods still prove incapable of handling complex medical images, such as barely visible abnormalities in chest X-rays and metastases in lymph nodes. To address this problem, we introduce a new powerful method of image anomaly detection. It relies on the classical autoencoder approach with a re-designed training pipeline to handle high-resolution, complex images and a robust way of computing an image abnormality score. We revisit the very problem statement of fully unsupervised anomaly detection, where no abnormal examples at all are provided during the model setup. We propose to relax this unrealistic assumption by using a very small number of anomalies of confined variability merely to initiate the search of hyperparameters of the model. We evaluate our solution on natural image datasets with a known benchmark, as well as on two medical datasets containing radiology and digital pathology images. The proposed approach suggests a new strong baseline for image anomaly detection and outperforms state-of-the-art approaches in complex medical image analysis tasks.