 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Spectral Image Synthesis for Crop/Weed Segmentation in Precision Farming
Sep 12, 2020

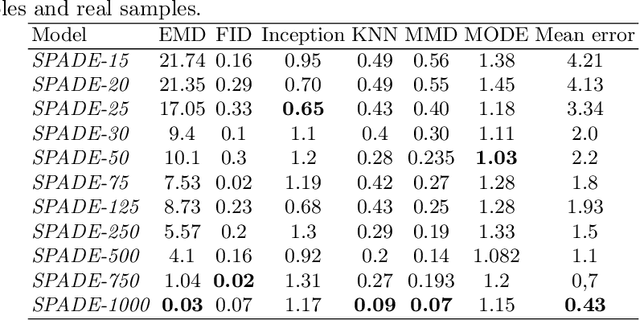
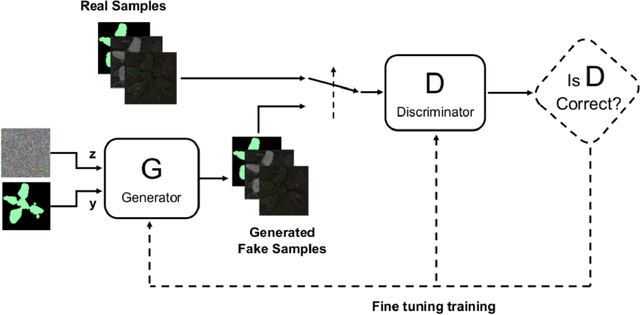
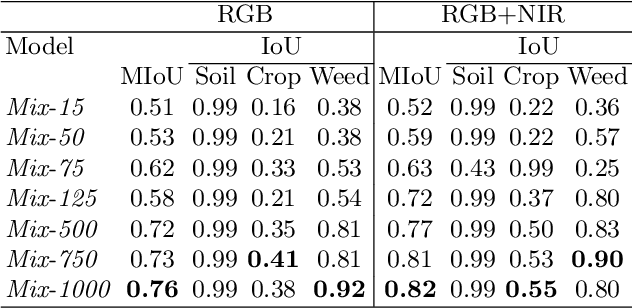
An effective perception system is a fundamental component for farming robots, as it enables them to properly perceive the surrounding environment and to carry out targeted operations. The most recent approaches make use of state-of-the-art machine learning techniques to learn an effective model for the target task. However, those methods need a large amount of labelled data for training. A recent approach to deal with this issue is data augmentation through Generative Adversarial Networks (GANs), where entire synthetic scenes are added to the training data, thus enlarging and diversifying their informative content. In this work, we propose an alternative solution with respect to the common data augmentation techniques, applying it to the fundamental problem of crop/weed segmentation in precision farming. Starting from real images, we create semi-artificial samples by replacing the most relevant object classes (i.e., crop and weeds) with their synthesized counterparts. To do that, we employ a conditional GAN (cGAN), where the generative model is trained by conditioning the shape of the generated object. Moreover, in addition to RGB data, we take into account also near-infrared (NIR) information, generating four channel multi-spectral synthetic images. Quantitative experiments, carried out on three publicly available datasets, show that (i) our model is capable of generating realistic multi-spectral images of plants and (ii) the usage of such synthetic images in the training process improves the segmentation performance of state-of-the-art semantic segmentation Convolutional Networks.
Photovoltaic module segmentation and thermal analysis tool from thermal images
Oct 14, 2020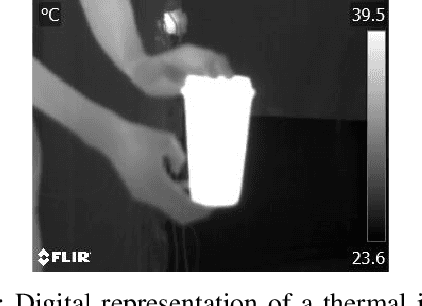
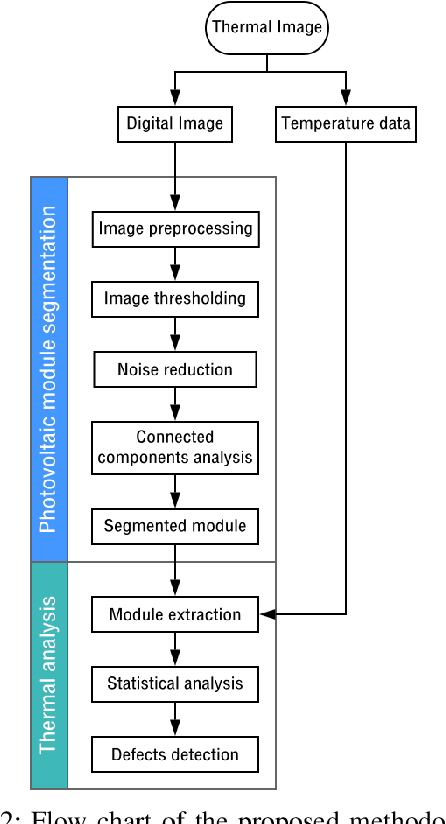
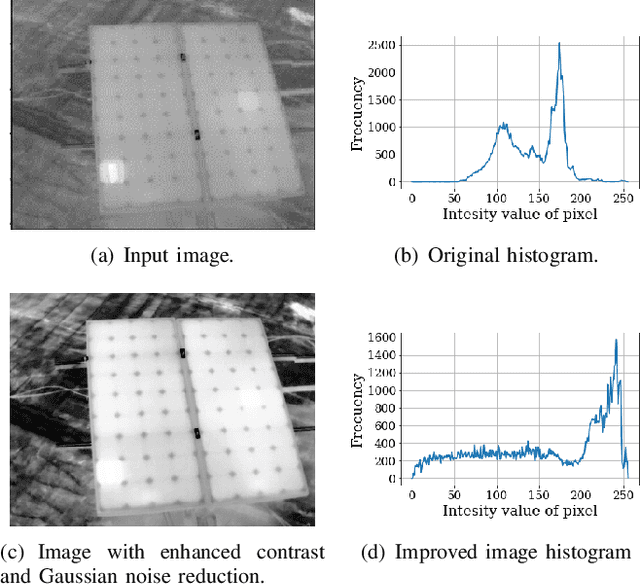

The growing interest in the use of clean energy has led to the construction of increasingly large photovoltaic systems. Consequently, monitoring the proper functioning of these systems has become a highly relevant issue.In this paper, automatic detection, and analysis of photovoltaic modules are proposed. To perform the analysis, a module identification step, based on a digital image processing algorithm, is first carried out. This algorithm consists of image enhancement (contrast enhancement, noise reduction, etc.), followed by segmentation of the photovoltaic module. Subsequently, a statistical analysis based on the temperature values of the segmented module is performed.Besides, a graphical user interface has been designed as a potential tool that provides relevant information of the photovoltaic modules.
A Metaheuristic-Driven Approach to Fine-Tune Deep Boltzmann Machines
Jan 14, 2021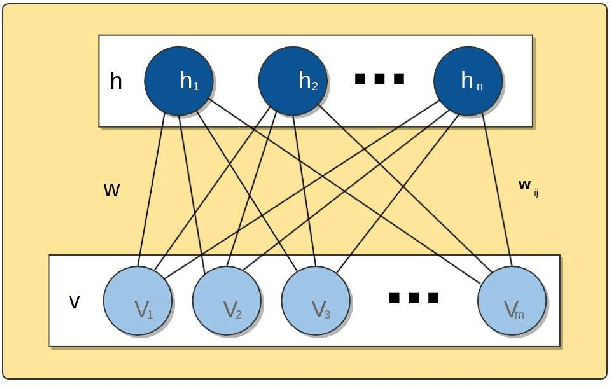
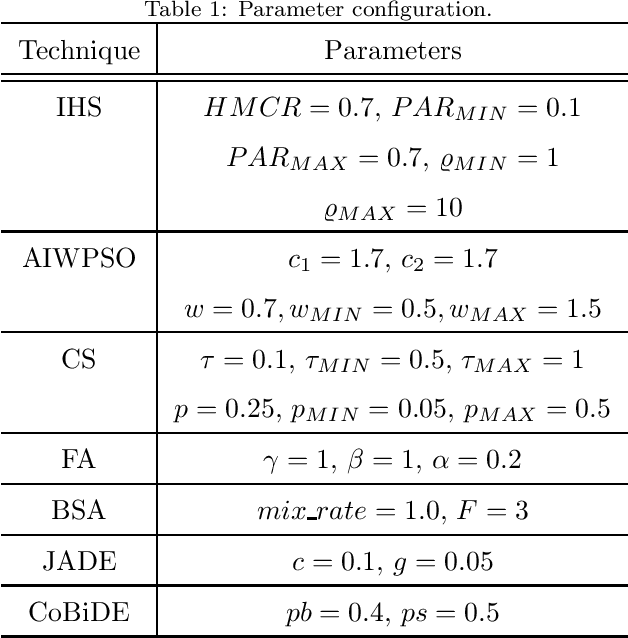
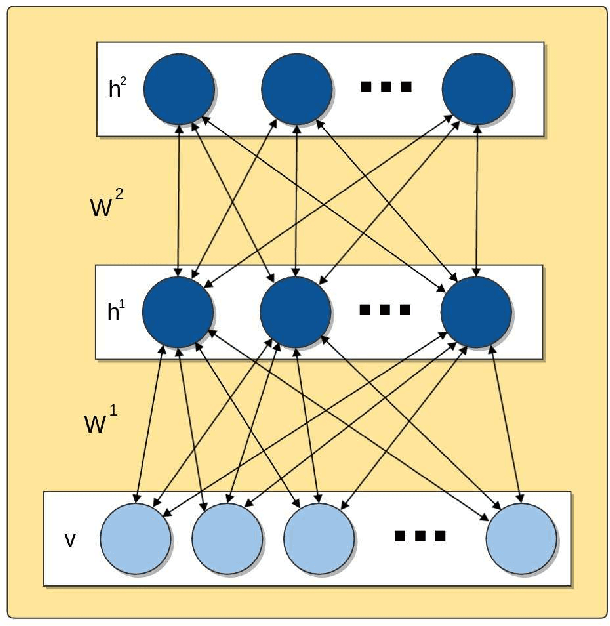
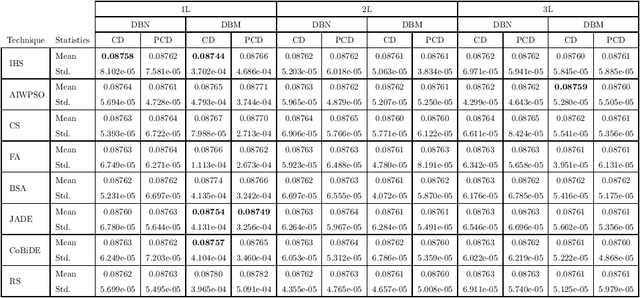
Deep learning techniques, such as Deep Boltzmann Machines (DBMs), have received considerable attention over the past years due to the outstanding results concerning a variable range of domains. One of the main shortcomings of these techniques involves the choice of their hyperparameters, since they have a significant impact on the final results. This work addresses the issue of fine-tuning hyperparameters of Deep Boltzmann Machines using metaheuristic optimization techniques with different backgrounds, such as swarm intelligence, memory- and evolutionary-based approaches. Experiments conducted in three public datasets for binary image reconstruction showed that metaheuristic techniques can obtain reasonable results.
* 30 pages, 7 figures
iCurb: Imitation Learning-based Detection of Road Curbs using Aerial Images for Autonomous Driving
Mar 31, 2021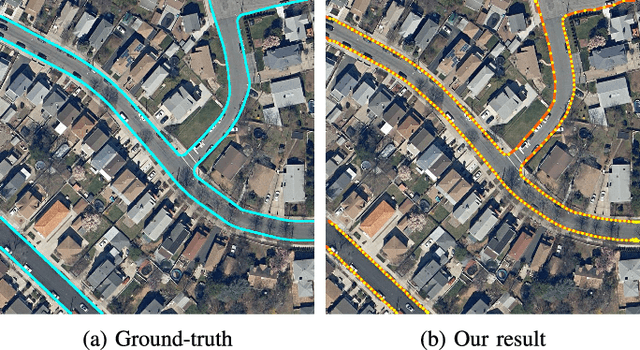
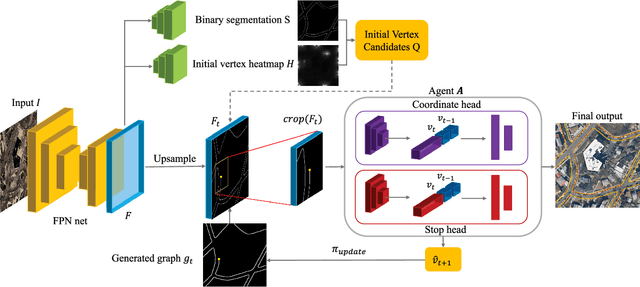
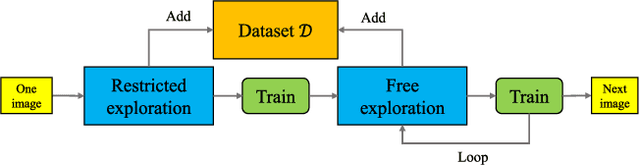
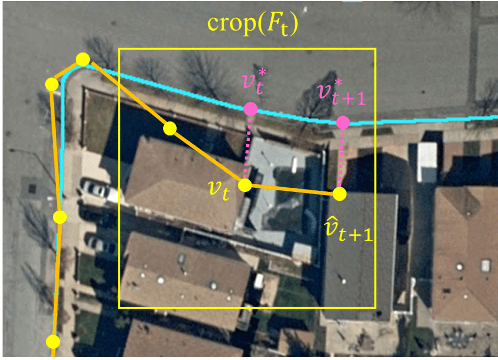
Detection of road curbs is an essential capability for autonomous driving. It can be used for autonomous vehicles to determine drivable areas on roads. Usually, road curbs are detected on-line using vehicle-mounted sensors, such as video cameras and 3-D Lidars. However, on-line detection using video cameras may suffer from challenging illumination conditions, and Lidar-based approaches may be difficult to detect far-away road curbs due to the sparsity issue of point clouds. In recent years, aerial images are becoming more and more worldwide available. We find that the visual appearances between road areas and off-road areas are usually different in aerial images, so we propose a novel solution to detect road curbs off-line using aerial images. The input to our method is an aerial image, and the output is directly a graph (i.e., vertices and edges) representing road curbs. To this end, we formulate the problem as an imitation learning problem, and design a novel network and an innovative training strategy to train an agent to iteratively find the road-curb graph. The experimental results on a public dataset confirm the effectiveness and superiority of our method. This work is accompanied with a demonstration video and a supplementary document at https://tonyxuqaq.github.io/iCurb/.
Stochastic Image Deformation in Frequency Domain and Parameter Estimation using Moment Evolutions
Dec 13, 2018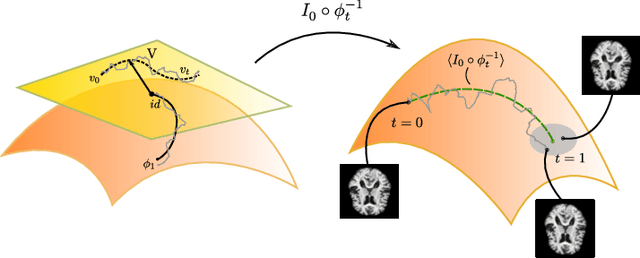
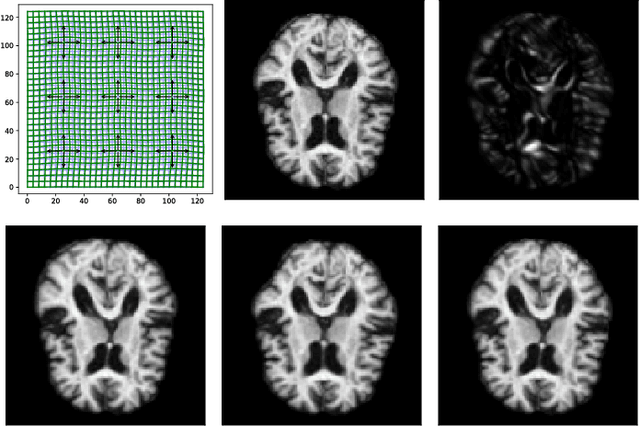
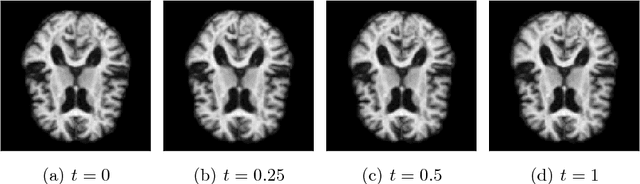
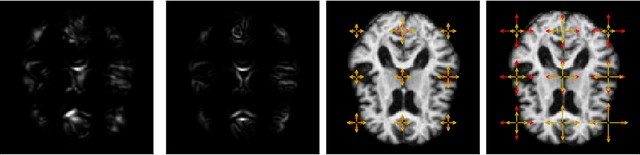
Modelling deformation of anatomical objects observed in medical images can help describe disease progression patterns and variations in anatomy across populations. We apply a stochastic generalisation of the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework to model differences in the evolution of anatomical objects detected in populations of image data. The computational challenges that are prevalent even in the deterministic LDDMM setting are handled by extending the FLASH LDDMM representation to the stochastic setting keeping a finite discretisation of the infinite dimensional space of image deformations. In this computationally efficient setting, we perform estimation to infer parameters for noise correlations and local variability in datasets of images. Fundamental for the optimisation procedure is using the finite dimensional Fourier representation to derive approximations of the evolution of moments for the stochastic warps. Particularly, the first moment allows us to infer deformation mean trajectories. The second moment encodes variation around the mean, and thus provides information on the noise correlation. We show on simulated datasets of 2D MR brain images that the estimation algorithm can successfully recover parameters of the stochastic model.
Amortised MAP Inference for Image Super-resolution
Feb 21, 2017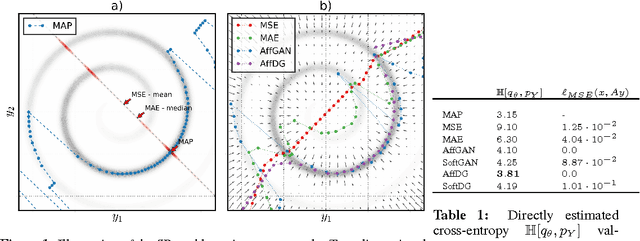
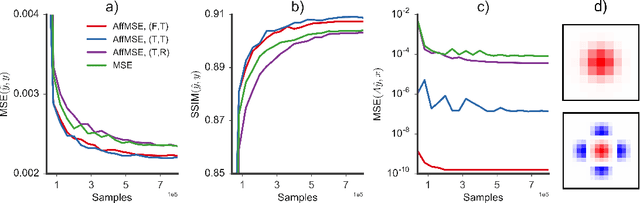


Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high-resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss. However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Furthermore, MAP inference is often performed via optimisation-based iterative algorithms which don't compare well with the efficiency of neural-network-based alternatives. Here we introduce new methods for amortised MAP inference whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
Fully Automated Left Atrium Segmentation from Anatomical Cine Long-axis MRI Sequences using Deep Convolutional Neural Network with Unscented Kalman Filter
Sep 28, 2020
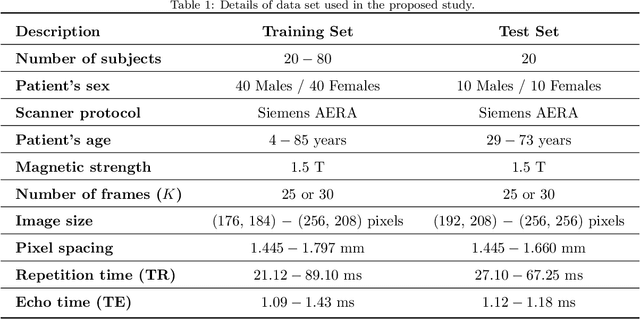
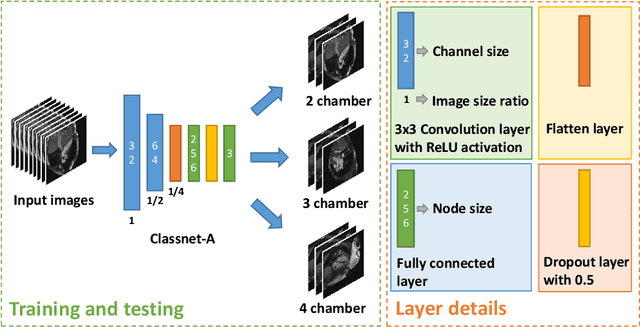
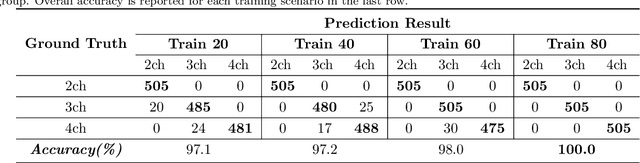
This study proposes a fully automated approach for the left atrial segmentation from routine cine long-axis cardiac magnetic resonance image sequences using deep convolutional neural networks and Bayesian filtering. The proposed approach consists of a classification network that automatically detects the type of long-axis sequence and three different convolutional neural network models followed by unscented Kalman filtering (UKF) that delineates the left atrium. Instead of training and predicting all long-axis sequence types together, the proposed approach first identifies the image sequence type as to 2, 3 and 4 chamber views, and then performs prediction based on neural nets trained for that particular sequence type. The datasets were acquired retrospectively and ground truth manual segmentation was provided by an expert radiologist. In addition to neural net based classification and segmentation, another neural net is trained and utilized to select image sequences for further processing using UKF to impose temporal consistency over cardiac cycle. A cyclic dynamic model with time-varying angular frequency is introduced in UKF to characterize the variations in cardiac motion during image scanning. The proposed approach was trained and evaluated separately with varying amount of training data with images acquired from 20, 40, 60 and 80 patients. Evaluations over 1515 images with equal number of images from each chamber group acquired from an additional 20 patients demonstrated that the proposed model outperformed state-of-the-art and yielded a mean Dice coefficient value of 94.1%, 93.7% and 90.1% for 2, 3 and 4-chamber sequences, respectively, when trained with datasets from 80 patients.
Data Augmentation for Meta-Learning
Oct 14, 2020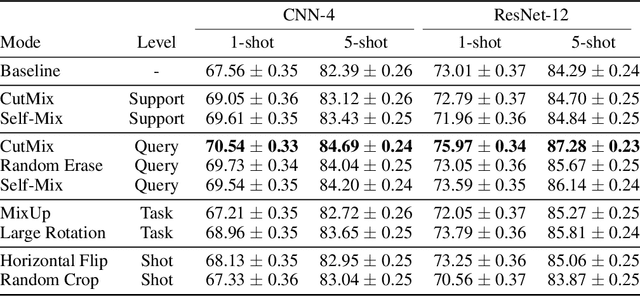
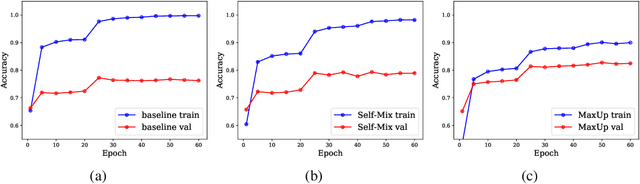
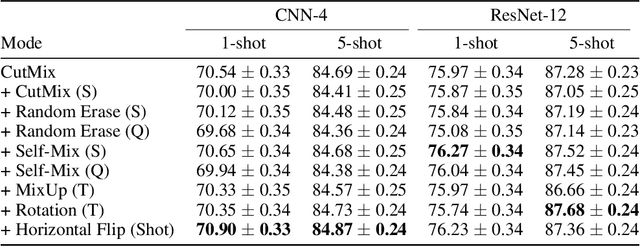
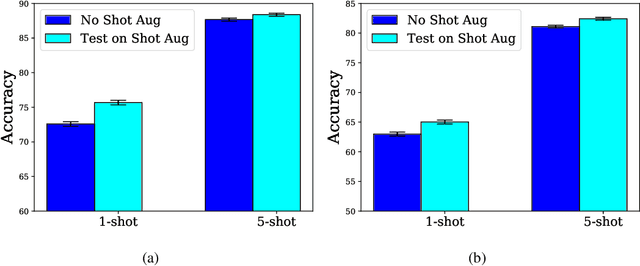
Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, sophisticated data augmentation schemes are used to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample not only images, but classes as well. We investigate how data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
Dictionary learning based image enhancement for rarity detection
Sep 13, 2016
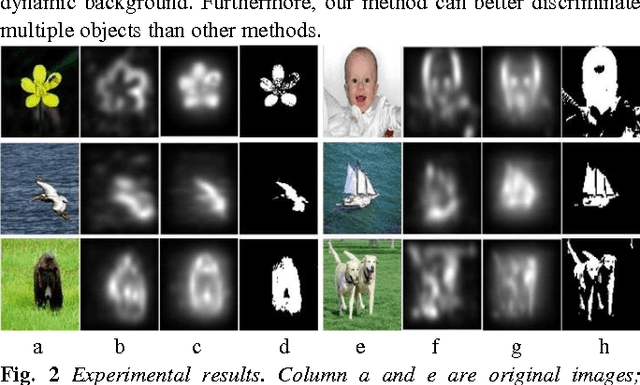
Image enhancement is an important image processing technique that processes images suitably for a specific application e.g. image editing. The conventional solutions of image enhancement are grouped into two categories which are spatial domain processing method and transform domain processing method such as contrast manipulation, histogram equalization, homomorphic filtering. This paper proposes a new image enhance method based on dictionary learning. Particularly, the proposed method adjusts the image by manipulating the rarity of dictionary atoms. Firstly, learn the dictionary through sparse coding algorithms on divided sub-image blocks. Secondly, compute the rarity of dictionary atoms on statistics of the corresponding sparse coefficients. Thirdly, adjust the rarity according to specific application and form a new dictionary. Finally, reconstruct the image using the updated dictionary and sparse coefficients. Compared with the traditional techniques, the proposed method enhances image based on the image content not on distribution of pixel grey value or frequency. The advantages of the proposed method lie in that it is in better correspondence with the response of the human visual system and more suitable for salient objects extraction. The experimental results demonstrate the effectiveness of the proposed image enhance method.
MUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
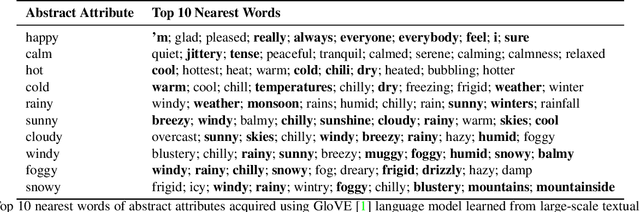

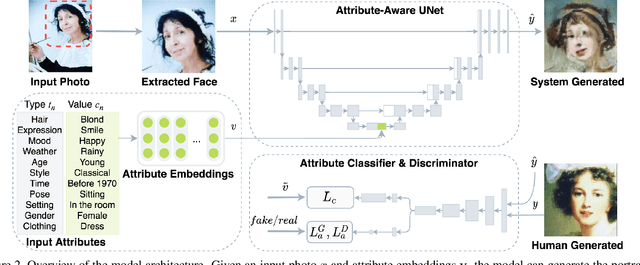
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.