 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Application of Deep Learning in Recognizing Bates Numbers and Confidentiality Stamping from Images
Feb 05, 2021


In eDiscovery, it is critical to ensure that each page produced in legal proceedings conforms with the requirements of court or government agency production requests. Errors in productions could have severe consequences in a case, putting a party in an adverse position. The volume of pages produced continues to increase, and tremendous time and effort has been taken to ensure quality control of document productions. This has historically been a manual and laborious process. This paper demonstrates a novel automated production quality control application which leverages deep learning-based image recognition technology to extract Bates Number and Confidentiality Stamping from legal case production images and validate their correctness. Effectiveness of the method is verified with an experiment using a real-world production data.
Learnable Companding Quantization for Accurate Low-bit Neural Networks
Mar 12, 2021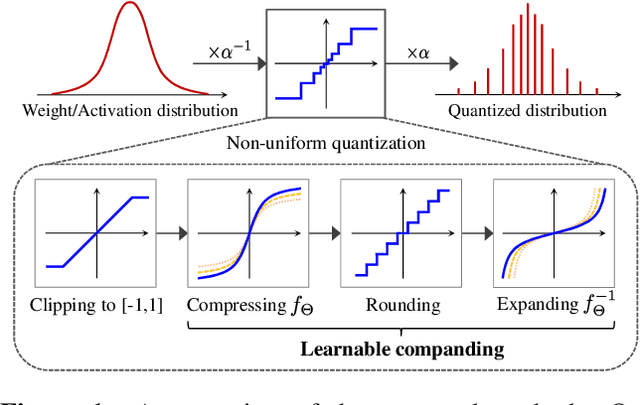
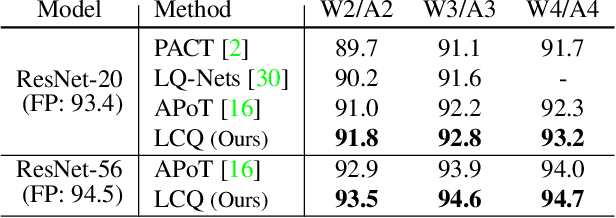
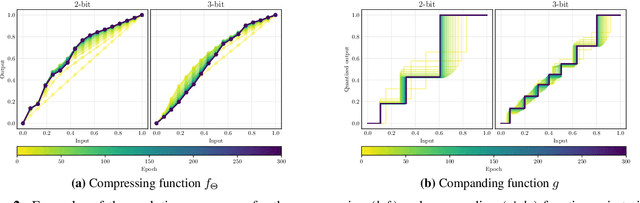
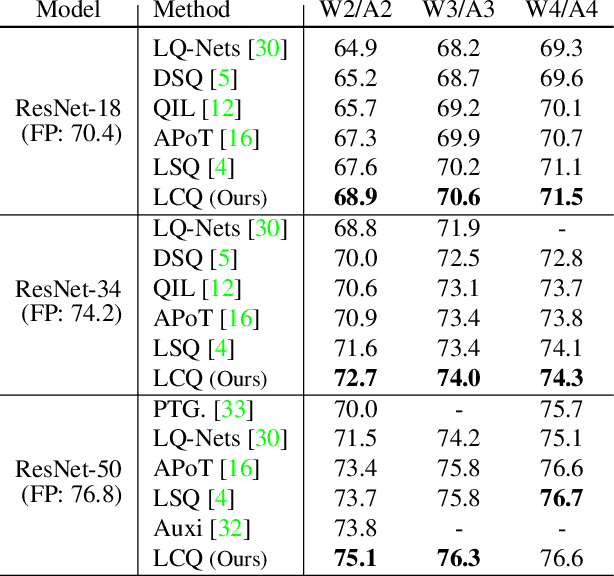
Quantizing deep neural networks is an effective method for reducing memory consumption and improving inference speed, and is thus useful for implementation in resource-constrained devices. However, it is still hard for extremely low-bit models to achieve accuracy comparable with that of full-precision models. To address this issue, we propose learnable companding quantization (LCQ) as a novel non-uniform quantization method for 2-, 3-, and 4-bit models. LCQ jointly optimizes model weights and learnable companding functions that can flexibly and non-uniformly control the quantization levels of weights and activations. We also present a new weight normalization technique that allows more stable training for quantization. Experimental results show that LCQ outperforms conventional state-of-the-art methods and narrows the gap between quantized and full-precision models for image classification and object detection tasks. Notably, the 2-bit ResNet-50 model on ImageNet achieves top-1 accuracy of 75.1% and reduces the gap to 1.7%, allowing LCQ to further exploit the potential of non-uniform quantization.
Efficient Kernel based Matched Filter Approach for Segmentation of Retinal Blood Vessels
Dec 07, 2020
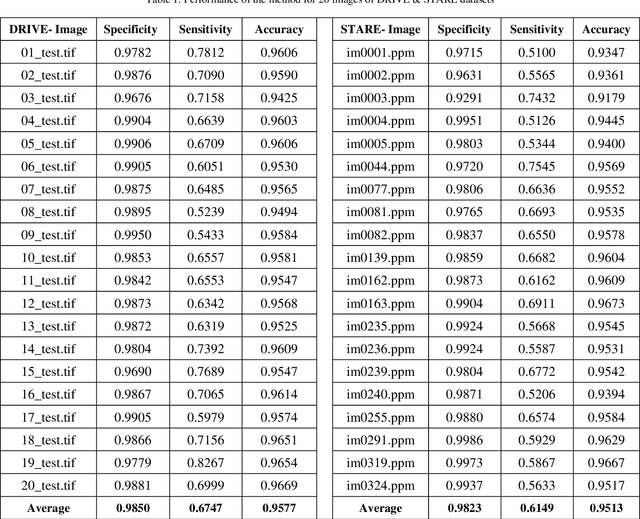
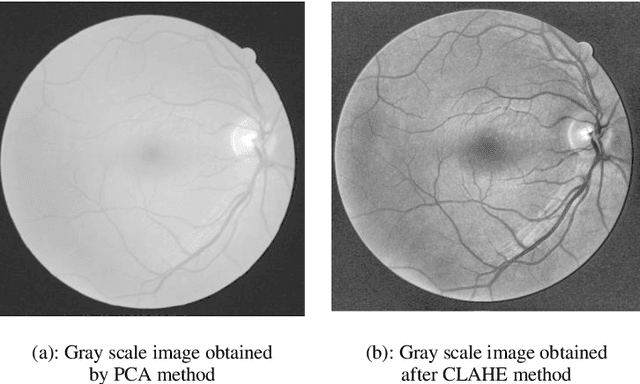
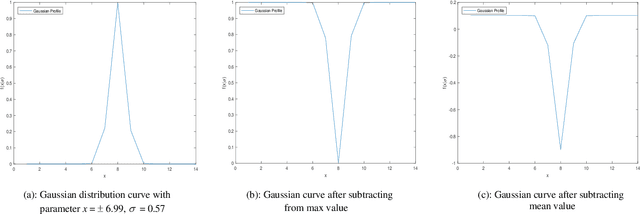
Retinal blood vessels structure contains information about diseases like obesity, diabetes, hypertension and glaucoma. This information is very useful in identification and treatment of these fatal diseases. To obtain this information, there is need to segment these retinal vessels. Many kernel based methods have been given for segmentation of retinal vessels but their kernels are not appropriate to vessel profile cause poor performance. To overcome this, a new and efficient kernel based matched filter approach has been proposed. The new matched filter is used to generate the matched filter response (MFR) image. We have applied Otsu thresholding method on obtained MFR image to extract the vessels. We have conducted extensive experiments to choose best value of parameters for the proposed matched filter kernel. The proposed approach has examined and validated on two online available DRIVE and STARE datasets. The proposed approach has specificity 98.50%, 98.23% and accuracy 95.77 %, 95.13% for DRIVE and STARE dataset respectively. Obtained results confirm that the proposed method has better performance than others. The reason behind increased performance is due to appropriate proposed kernel which matches retinal blood vessel profile more accurately.
Spatial-Channel Transformer Network for Trajectory Prediction on the Traffic Scenes
Feb 05, 2021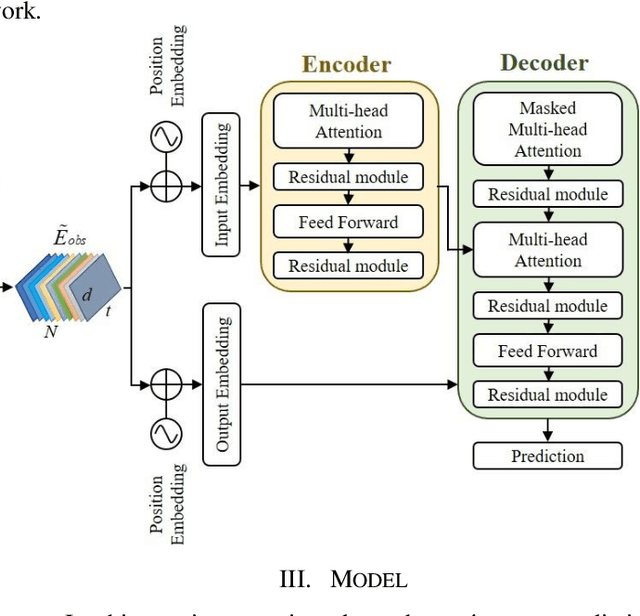
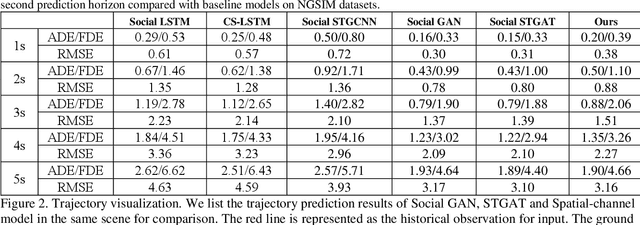
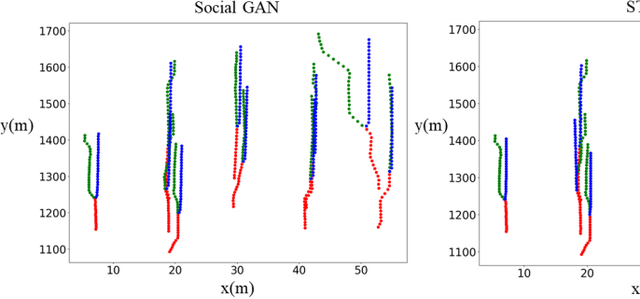
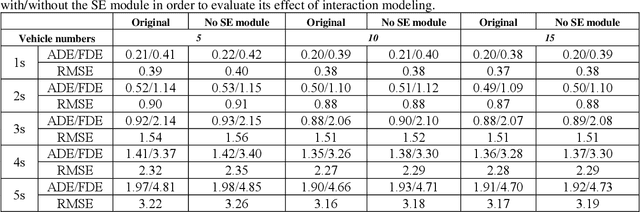
Predicting motion of surrounding agents is critical to real-world applications of tactical path planning for autonomous driving. Due to the complex temporal dependencies and social interactions of agents, on-line trajectory prediction is a challenging task. With the development of attention mechanism in recent years, transformer model has been applied in natural language sequence processing first and then image processing. In this paper, we present a Spatial-Channel Transformer Network for trajectory prediction with attention functions. Instead of RNN models, we employ transformer model to capture the spatial-temporal features of agents. A channel-wise module is inserted to measure the social interaction between agents. We find that the Spatial-Channel Transformer Network achieves promising results on real-world trajectory prediction datasets on the traffic scenes.
Thousand to One: Semantic Prior Modeling for Conceptual Coding
Mar 12, 2021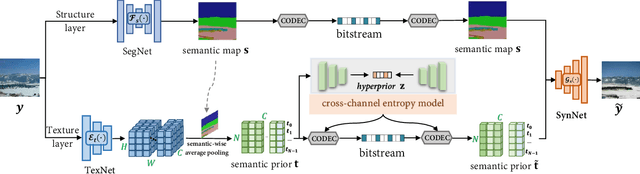
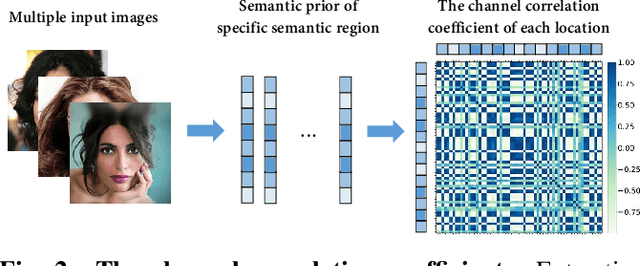

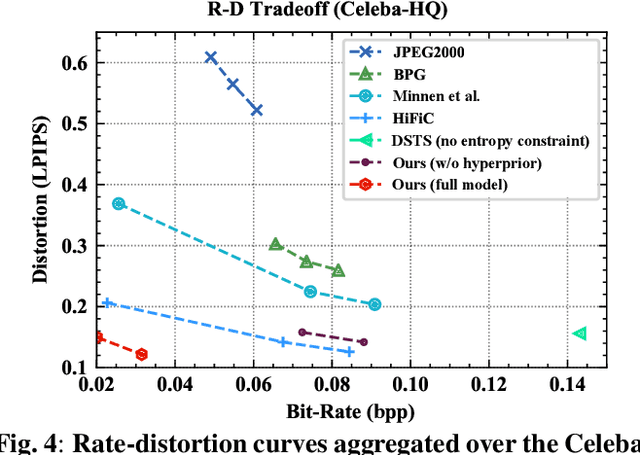
Conceptual coding has been an emerging research topic recently, which encodes natural images into disentangled conceptual representations for compression. However, the compression performance of the existing methods is still sub-optimal due to the lack of comprehensive consideration of rate constraint and reconstruction quality. To this end, we propose a novel end-to-end semantic prior modeling-based conceptual coding scheme towards extremely low bitrate image compression, which leverages semantic-wise deep representations as a unified prior for entropy estimation and texture synthesis. Specifically, we employ semantic segmentation maps as structural guidance for extracting deep semantic prior, which provides fine-grained texture distribution modeling for better detail construction and higher flexibility in subsequent high-level vision tasks. Moreover, a cross-channel entropy model is proposed to further exploit the inter-channel correlation of the spatially independent semantic prior, leading to more accurate entropy estimation for rate-constrained training. The proposed scheme achieves an ultra-high 1000x compression ratio, while still enjoying high visual reconstruction quality and versatility towards visual processing and analysis tasks.
On-device Scalable Image-based Localization
Feb 10, 2018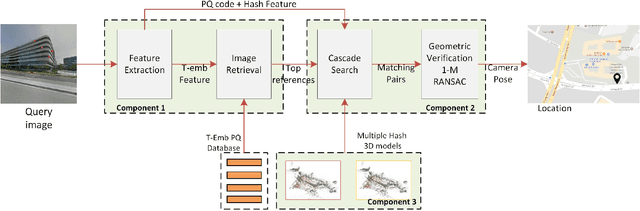

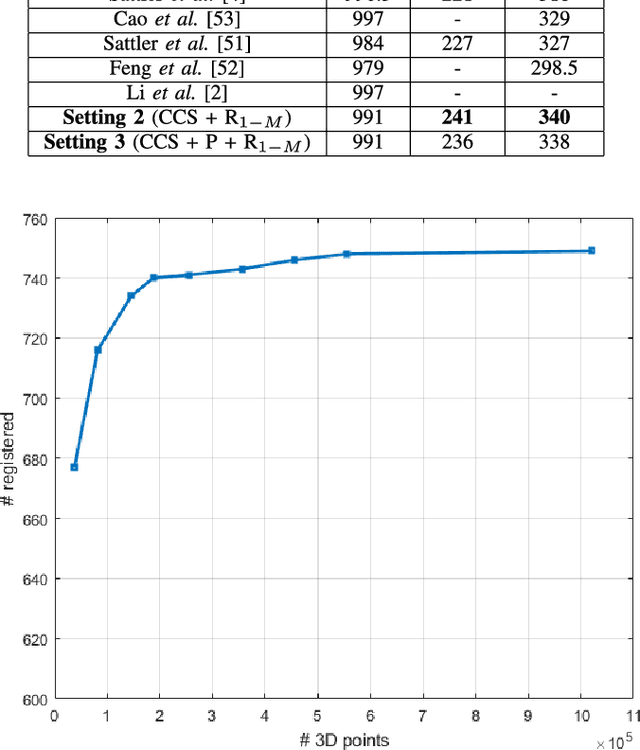

We present the scalable design of an entire on-device system for large-scale urban localization. The proposed design integrates compact image retrieval and 2D-3D correspondence search to estimate the camera pose in a city region of extensive coverage. Our design is GPS agnostic and does not require the network connection. The system explores the use of an abundant dataset: Google Street View (GSV). In order to overcome the resource constraints of mobile devices, we carefully optimize the system design at every stage: we use state-of-the-art image retrieval to quickly locate candidate regions and limit candidate 3D points; we propose a new hashing-based approach for fast computation of 2D-3D correspondences and new one-many RANSAC for accurate pose estimation. The experiments are conducted on benchmark datasets for 2D-3D correspondence search and on a database of over 227K Google Street View (GSV) images for the overall system. Results show that our 2D-3D correspondence search achieves state-of-the-art performance on some benchmark datasets and our system can accurately and quickly localize mobile images; the median error is less than 4 meters and the processing time is averagely less than 10s on a typical mobile device.
The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
Nov 02, 2018


We present Open Images V4, a dataset of 9.2M images with unified annotations for image classification, object detection and visual relationship detection. The images have a Creative Commons Attribution license that allows to share and adapt the material, and they have been collected from Flickr without a predefined list of class names or tags, leading to natural class statistics and avoiding an initial design bias. Open Images V4 offers large scale across several dimensions: 30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes, and 375k visual relationship annotations involving 57 classes. For object detection in particular, we provide 15x more bounding boxes than the next largest datasets (15.4M boxes on 1.9M images). The images often show complex scenes with several objects (8 annotated objects per image on average). We annotated visual relationships between them, which support visual relationship detection, an emerging task that requires structured reasoning. We provide in-depth comprehensive statistics about the dataset, we validate the quality of the annotations, and we study how the performance of many modern models evolves with increasing amounts of training data. We hope that the scale, quality, and variety of Open Images V4 will foster further research and innovation even beyond the areas of image classification, object detection, and visual relationship detection.
SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis
Apr 12, 2018
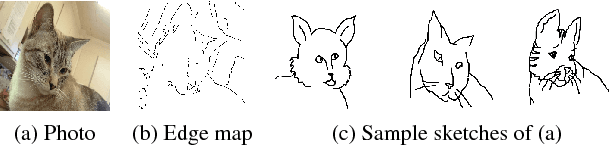


Synthesizing realistic images from human drawn sketches is a challenging problem in computer graphics and vision. Existing approaches either need exact edge maps, or rely on retrieval of existing photographs. In this work, we propose a novel Generative Adversarial Network (GAN) approach that synthesizes plausible images from 50 categories including motorcycles, horses and couches. We demonstrate a data augmentation technique for sketches which is fully automatic, and we show that the augmented data is helpful to our task. We introduce a new network building block suitable for both the generator and discriminator which improves the information flow by injecting the input image at multiple scales. Compared to state-of-the-art image translation methods, our approach generates more realistic images and achieves significantly higher Inception Scores.
Generic 3D Convolutional Fusion for image restoration
Jul 26, 2016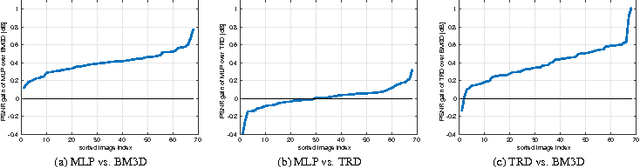
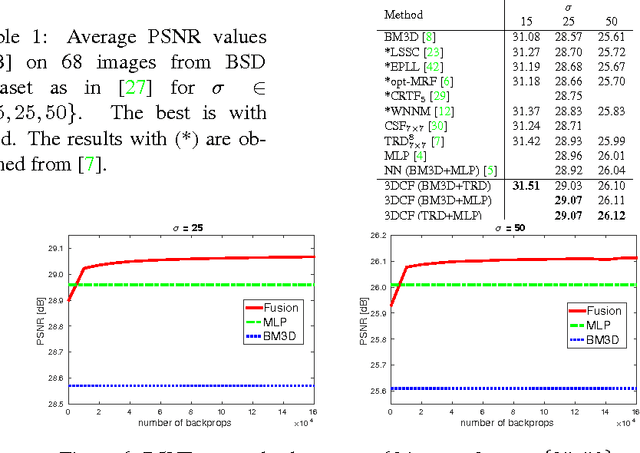

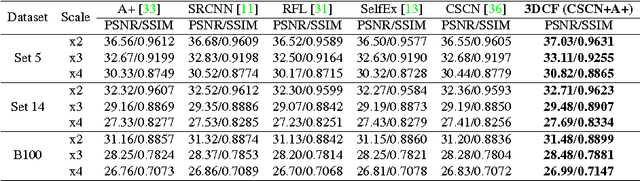
Also recently, exciting strides forward have been made in the area of image restoration, particularly for image denoising and single image super-resolution. Deep learning techniques contributed to this significantly. The top methods differ in their formulations and assumptions, so even if their average performance may be similar, some work better on certain image types and image regions than others. This complementarity motivated us to propose a novel 3D convolutional fusion (3DCF) method. Unlike other methods adapted to different tasks, our method uses the exact same convolutional network architecture to address both image denois- ing and single image super-resolution. As a result, our 3DCF method achieves substantial improvements (0.1dB-0.4dB PSNR) over the state-of-the-art methods that it fuses, and this on standard benchmarks for both tasks. At the same time, the method still is computationally efficient.
Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network
Feb 11, 2021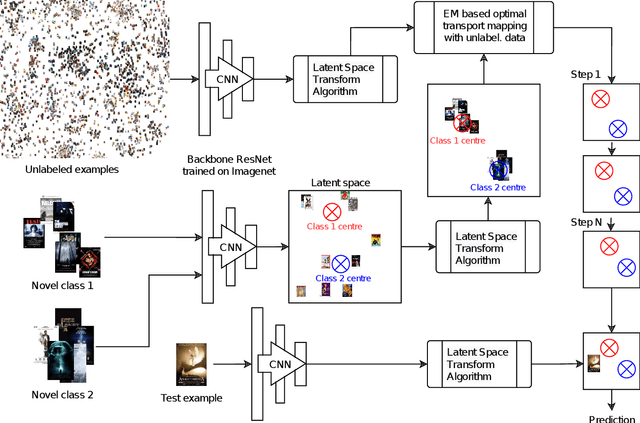
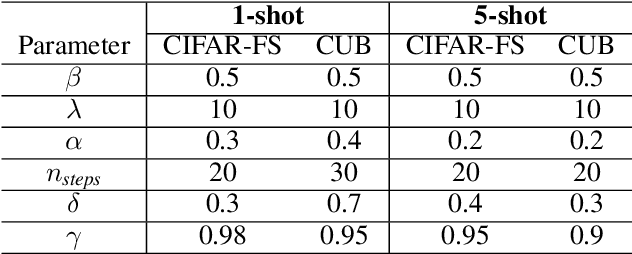
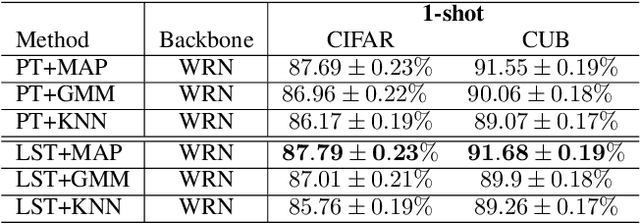
MetaDL Challenge 2020 focused on image classification tasks in few-shot settings. This paper describes second best submission in the competition. Our meta learning approach modifies the distribution of classes in a latent space produced by a backbone network for each class in order to better follow the Gaussian distribution. After this operation which we call Latent Space Transform algorithm, centers of classes are further aligned in an iterative fashion of the Expectation Maximisation algorithm to utilize information in unlabeled data that are often provided on top of few labelled instances. For this task, we utilize optimal transport mapping using the Sinkhorn algorithm. Our experiments show that this approach outperforms previous works as well as other variants of the algorithm, using K-Nearest Neighbour algorithm, Gaussian Mixture Models, etc.