 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Implicit Integration of Superpixel Segmentation into Fully Convolutional Networks
Mar 05, 2021
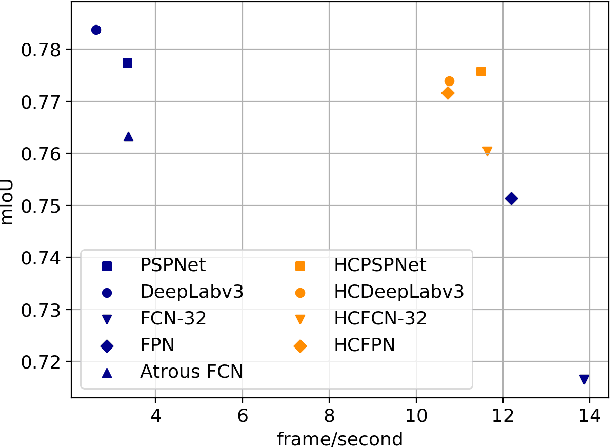
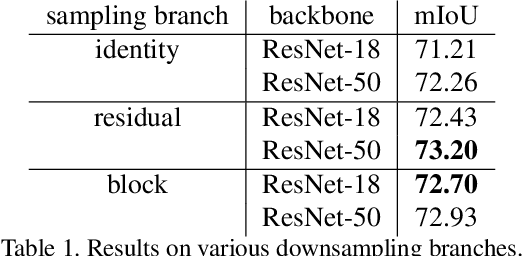

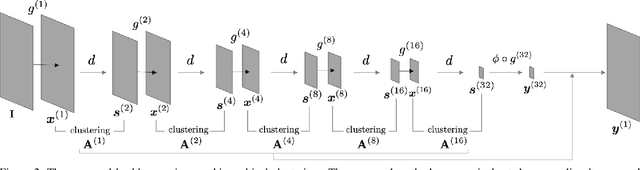
Superpixels are a useful representation to reduce the complexity of image data. However, to combine superpixels with convolutional neural networks (CNNs) in an end-to-end fashion, one requires extra models to generate superpixels and special operations such as graph convolution. In this paper, we propose a way to implicitly integrate a superpixel scheme into CNNs, which makes it easy to use superpixels with CNNs in an end-to-end fashion. Our proposed method hierarchically groups pixels at downsampling layers and generates superpixels. Our method can be plugged into many existing architectures without a change in their feed-forward path because our method does not use superpixels in the feed-forward path but use them to recover the lost resolution instead of bilinear upsampling. As a result, our method preserves detailed information such as object boundaries in the form of superpixels even when the model contains downsampling layers. We evaluate our method on several tasks such as semantic segmentation, superpixel segmentation, and monocular depth estimation, and confirm that it speeds up modern architectures and/or improves their prediction accuracy in these tasks.
Dataset Condensation with Differentiable Siamese Augmentation
Feb 16, 2021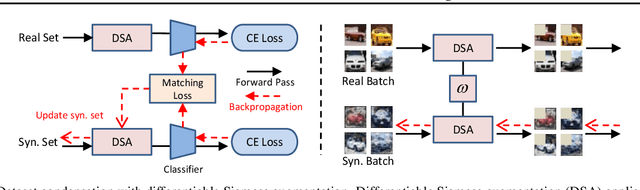
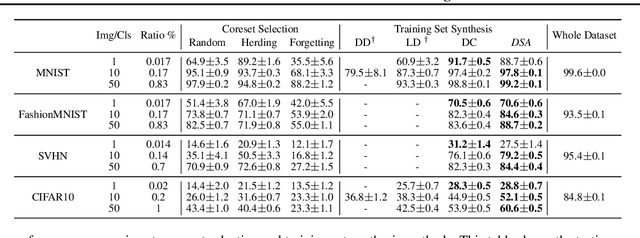


In many machine learning problems, large-scale datasets have become the de-facto standard to train state-of-the-art deep networks at the price of heavy computation load. In this paper, we focus on condensing large training sets into significantly smaller synthetic sets which can be used to train deep neural networks from scratch with minimum drop in performance. Inspired from the recent training set synthesis methods, we propose Differentiable Siamese Augmentation that enables effective use of data augmentation to synthesize more informative synthetic images and thus achieves better performance when training networks with augmentations. Experiments on multiple image classification benchmarks demonstrate that the proposed method obtains substantial gains over the state-of-the-art, 7% improvements on CIFAR10 and CIFAR100 datasets. We show with only less than 1% data that our method achieves 99.6%, 94.9%, 88.5%, 71.5% relative performance on MNIST, FashionMNIST, SVHN, CIFAR10 respectively.
CDLNet: Robust and Interpretable Denoising Through Deep Convolutional Dictionary Learning
Mar 05, 2021

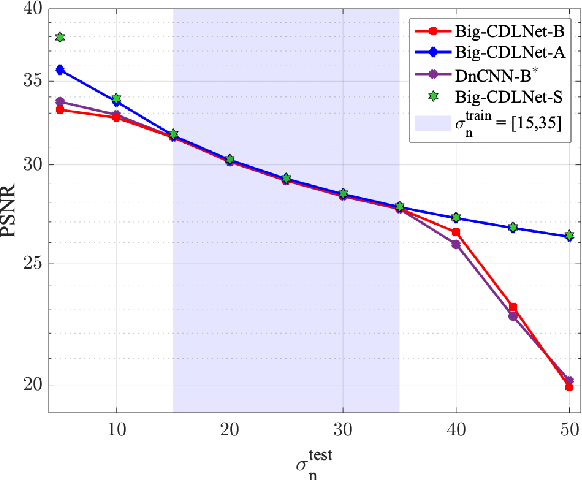

Deep learning based methods hold state-of-the-art results in image denoising, but remain difficult to interpret due to their construction from poorly understood building blocks such as batch-normalization, residual learning, and feature domain processing. Unrolled optimization networks propose an interpretable alternative to constructing deep neural networks by deriving their architecture from classical iterative optimization methods, without use of tricks from the standard deep learning tool-box. So far, such methods have demonstrated performance close to that of state-of-the-art models while using their interpretable construction to achieve a comparably low learned parameter count. In this work, we propose an unrolled convolutional dictionary learning network (CDLNet) and demonstrate its competitive denoising performance in both low and high parameter count regimes. Specifically, we show that the proposed model outperforms the state-of-the-art denoising models when scaled to similar parameter count. In addition, we leverage the model's interpretable construction to propose an augmentation of the network's thresholds that enables state-of-the-art blind denoising performance and near-perfect generalization on noise-levels unseen during training.
Image Denoising via Collaborative Dual-Domain Patch Filtering
May 01, 2018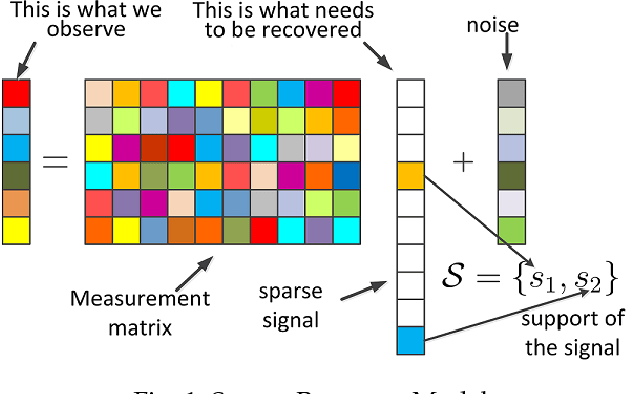
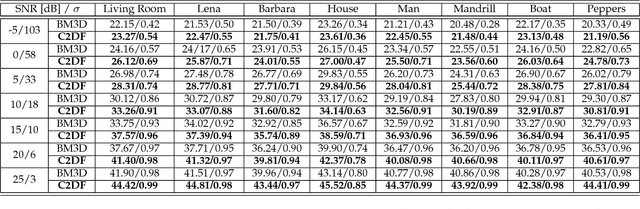

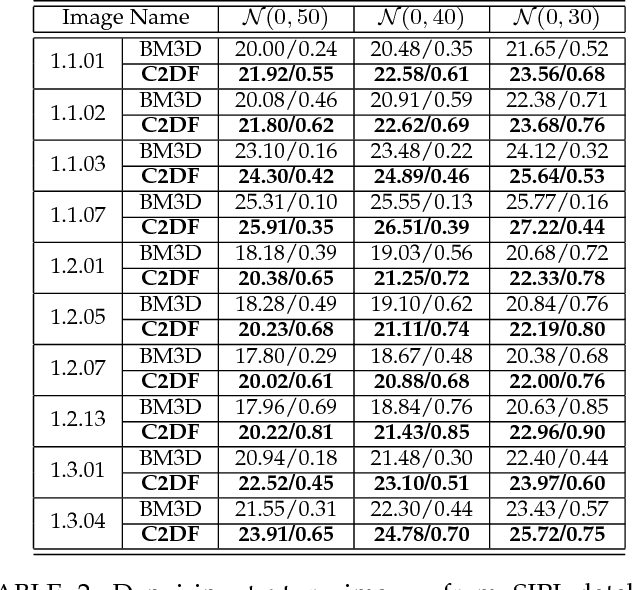
In this paper, we propose a novel image denoising algorithm exploiting features from both spatial as well as transformed domain. We implement intensity-invariance based improved grouping for collaborative support-agnostic sparse reconstruction. For collaboration firstly, we stack similar-structured patches via intensity-invariant correlation measure. The grouped patches collaborate to yield desirable sparse estimates for noise filtering. This is because similar patches share the same support in the transformed domain, such similar supports can be used as probabilities of active taps to refine the sparse estimates. This ultimately produces a very useful patch estimate thus increasing the quality of recovered image by discarding the noise-causing components. A region growing based spatially developed post-processor is then applied to further enhance the smooth regions by extracting the spatial domain features. We also extend our proposed method for denoising of color images. Comparison results with the state-of-the-art algorithms in terms of peak signal-to-noise ratio (PNSR) and structural similarity (SSIM) index from extensive experimentations via a broad range of scenarios demonstrate the superiority of our proposed algorithm.
A Study of Human Gaze Behavior During Visual Crowd Counting
Sep 27, 2020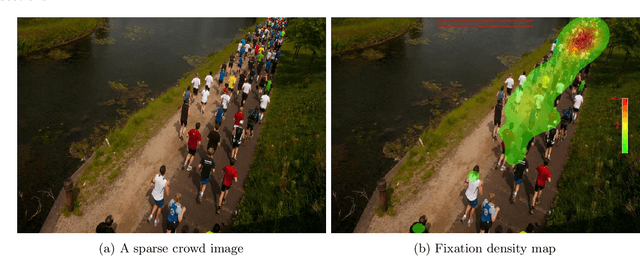
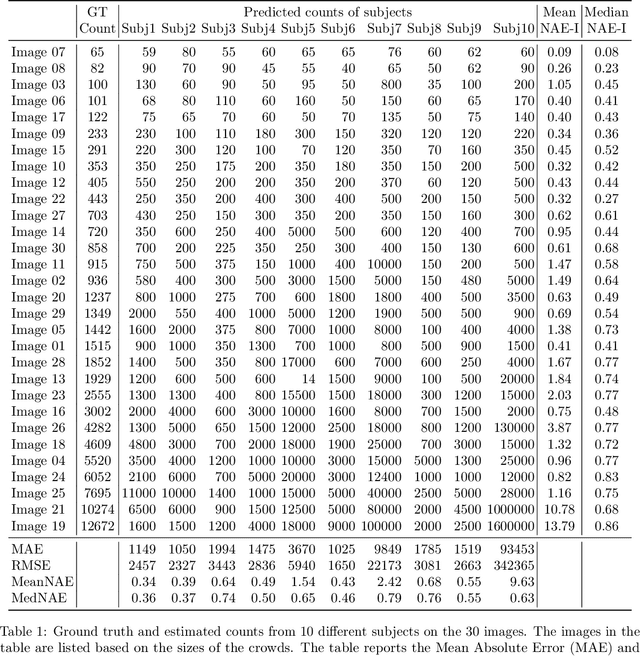

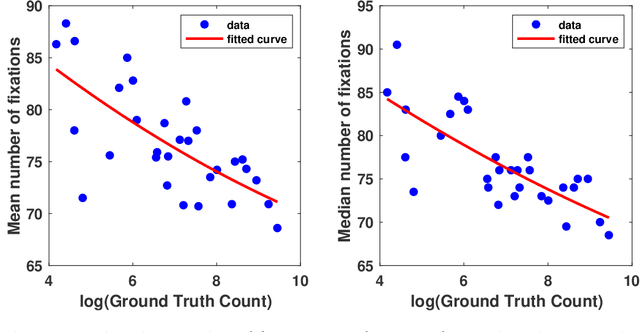
In this paper, we describe our study on how humans allocate their attention during visual crowd counting. Using an eye tracker, we collect gaze behavior of human participants who are tasked with counting the number of people in crowd images. Analyzing the collected gaze behavior of ten human participants on thirty crowd images, we observe some common approaches for visual counting. For an image of a small crowd, the approach is to enumerate over all people or groups of people in the crowd, and this explains the high level of similarity between the fixation density maps of different human participants. For an image of a large crowd, our participants tend to focus on one section of the image, count the number of people in that section, and then extrapolate to the other sections. In terms of count accuracy, our human participants are not as good at the counting task, compared to the performance of the current state-of-the-art computer algorithms. Interestingly, there is a tendency to under count the number of people in all crowd images. Gaze behavior data and images can be downloaded from https://www3.cs.stonybrook.edu/~minhhoai/projects/crowd_counting_gaze/.
Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
Dec 09, 2020
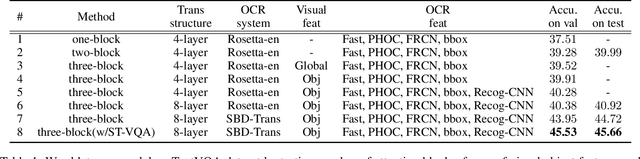
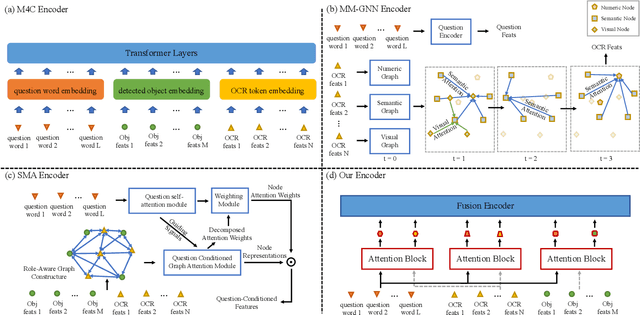

Texts appearing in daily scenes that can be recognized by OCR (Optical Character Recognition) tools contain significant information, such as street name, product brand and prices. Two tasks -- text-based visual question answering and text-based image captioning, with a text extension from existing vision-language applications, are catching on rapidly. To address these problems, many sophisticated multi-modality encoding frameworks (such as heterogeneous graph structure) are being used. In this paper, we argue that a simple attention mechanism can do the same or even better job without any bells and whistles. Under this mechanism, we simply split OCR token features into separate visual- and linguistic-attention branches, and send them to a popular Transformer decoder to generate answers or captions. Surprisingly, we find this simple baseline model is rather strong -- it consistently outperforms state-of-the-art (SOTA) models on two popular benchmarks, TextVQA and all three tasks of ST-VQA, although these SOTA models use far more complex encoding mechanisms. Transferring it to text-based image captioning, we also surpass the TextCaps Challenge 2020 winner. We wish this work to set the new baseline for this two OCR text related applications and to inspire new thinking of multi-modality encoder design. Code is available at https://github.com/ZephyrZhuQi/ssbaseline
Counterfactual Generation and Fairness Evaluation Using Adversarially Learned Inference
Sep 17, 2020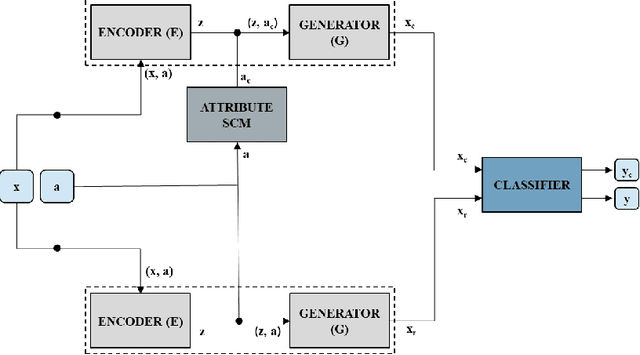

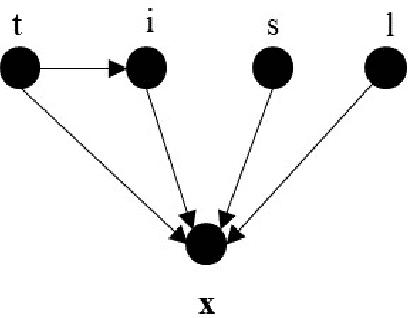
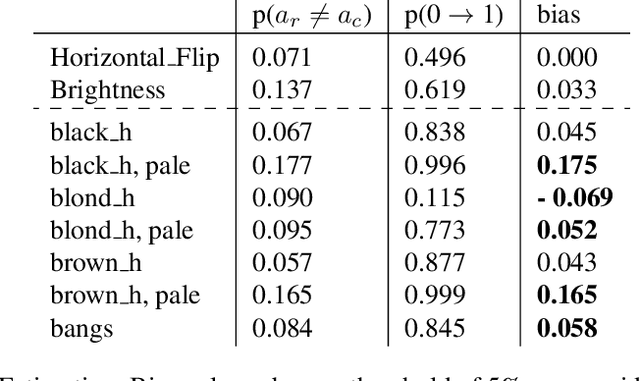
Recent studies have reported biases in machine learning image classifiers, especially against particular demographic groups. Counterfactual examples for an input---perturbations that change specific features but not others---have been shown to be useful for evaluating explainability and fairness of machine learning models. However, generating counterfactual examples for images is non-trivial due to the underlying causal structure governing the various features of an image. To be meaningful, generated perturbations need to satisfy constraints implied by the causal model. We present a method for generating counterfactuals by incorporating a known causal graph structure in a conditional variant of Adversarially Learned Inference (ALI). The proposed approach learns causal relationships between the specified attributes of an image and generates counterfactuals in accordance with these relationships. On Morpho-MNIST and CelebA datasets, the method generates counterfactuals that can change specified attributes and their causal descendants while keeping other attributes constant. As an application, we apply the generated counterfactuals from CelebA images to evaluate fairness biases in a classifier that predicts attractiveness of a face.
DeepBlindness: Fast Blindness Map Estimation and Blindness Type Classification for Outdoor Scene from Single Color Image
Nov 02, 2019
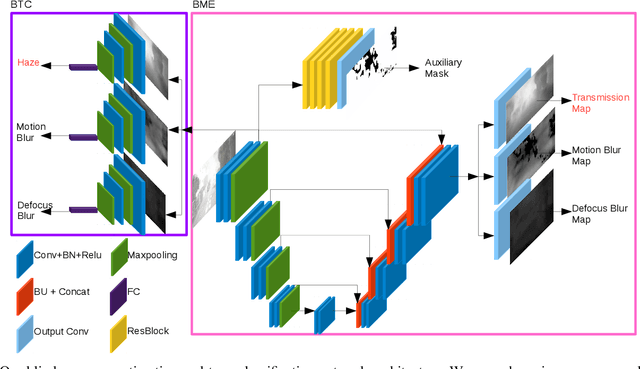

Outdoor vision robotic systems and autonomous cars suffer from many image-quality issues, particularly haze, defocus blur, and motion blur, which we will define generically as "blindness issues". These blindness issues may seriously affect the performance of robotic systems and could lead to unsafe decisions being made. However, existing solutions either focus on one type of blindness only or lack the ability to estimate the degree of blindness accurately. Besides, heavy computation is needed so that these solutions cannot run in real-time on practical systems. In this paper, we provide a method which could simultaneously detect the type of blindness and provide a blindness map indicating to what degree the vision is limited on a pixel-by-pixel basis. Both the blindness type and the estimate of per-pixel blindness are essential for tasks like deblur, dehaze, or the fail-safe functioning of robotic systems. We demonstrate the effectiveness of our approach on the KITTI and CUHK datasets where experiments show that our method outperforms other state-of-the-art approaches, achieving speeds of about 130 frames per second (fps).
Diverse Plausible Shape Completions from Ambiguous Depth Images
Nov 18, 2020
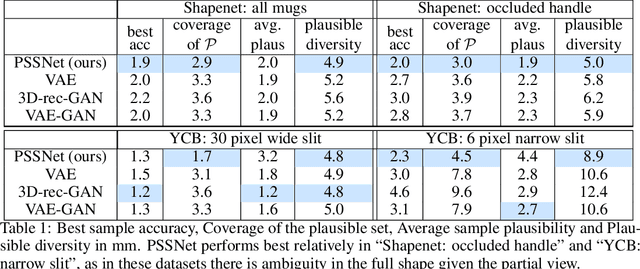
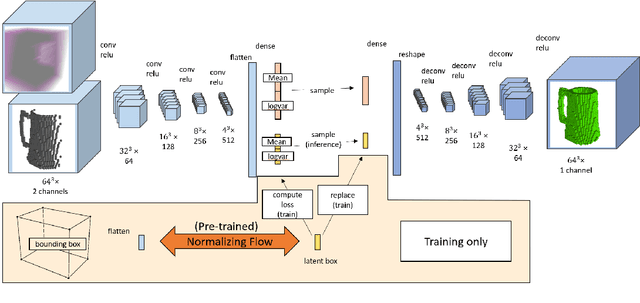
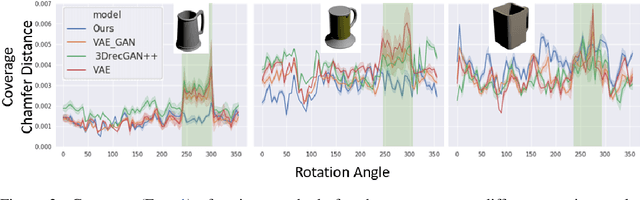
We propose PSSNet, a network architecture for generating diverse plausible 3D reconstructions from a single 2.5D depth image. Existing methods tend to produce only small variations on a single shape, even when multiple shapes are consistent with an observation. To obtain diversity we alter a Variational Auto Encoder by providing a learned shape bounding box feature as side information during training. Since these features are known during training, we are able to add a supervised loss to the encoder and noiseless values to the decoder. To evaluate, we sample a set of completions from a network, construct a set of plausible shape matches for each test observation, and compare using our plausible diversity metric defined over sets of shapes. We perform experiments using Shapenet mugs and partially-occluded YCB objects and find that our method performs comparably in datasets with little ambiguity, and outperforms existing methods when many shapes plausibly fit an observed depth image. We demonstrate one use for PSSNet on a physical robot when grasping objects in occlusion and clutter.
Chaining Identity Mapping Modules for Image Denoising
Dec 08, 2017

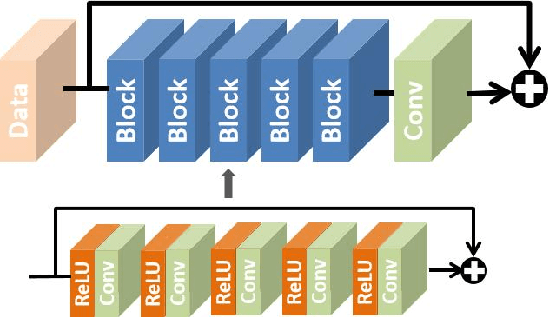

We propose to learn a fully-convolutional network model that consists of a Chain of Identity Mapping Modules (CIMM) for image denoising. The CIMM structure possesses two distinctive features that are important for the noise removal task. Firstly, each residual unit employs identity mappings as the skip connections and receives pre-activated input in order to preserve the gradient magnitude propagated in both the forward and backward directions. Secondly, by utilizing dilated kernels for the convolution layers in the residual branch, in other words within an identity mapping module, each neuron in the last convolution layer can observe the full receptive field of the first layer. After being trained on the BSD400 dataset, the proposed network produces remarkably higher numerical accuracy and better visual image quality than the state-of-the-art when being evaluated on conventional benchmark images and the BSD68 dataset.