 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
C2MSNet: A Novel approach for single image haze removal
Jan 25, 2018
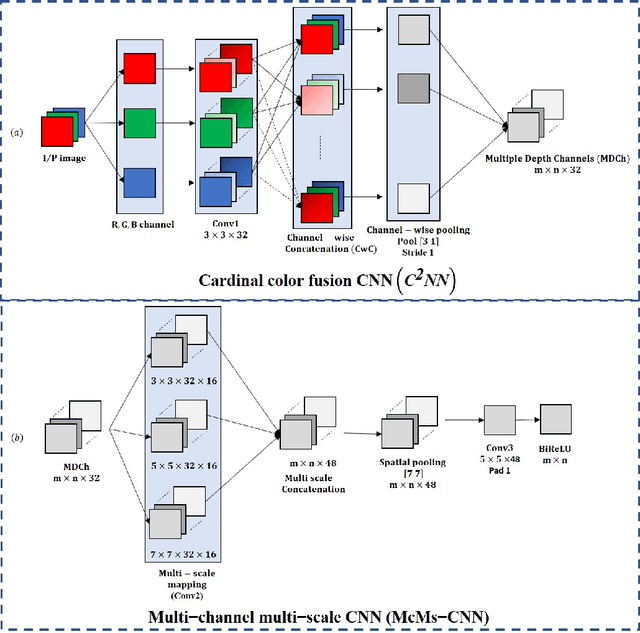
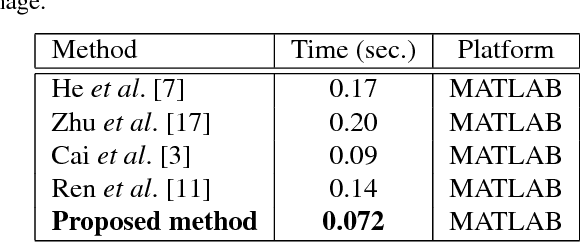
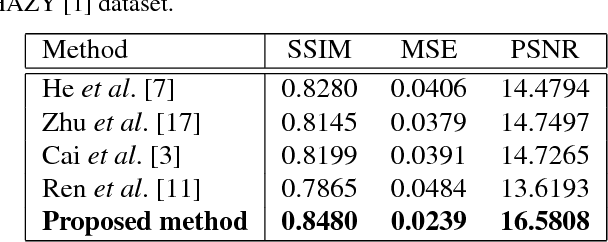
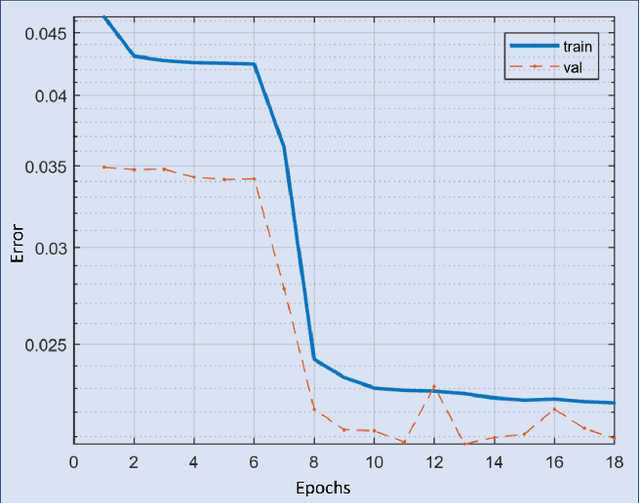
Degradation of image quality due to the presence of haze is a very common phenomenon. Existing DehazeNet [3], MSCNN [11] tackled the drawbacks of hand crafted haze relevant features. However, these methods have the problem of color distortion in gloomy (poor illumination) environment. In this paper, a cardinal (red, green and blue) color fusion network for single image haze removal is proposed. In first stage, network fusses color information present in hazy images and generates multi-channel depth maps. The second stage estimates the scene transmission map from generated dark channels using multi channel multi scale convolutional neural network (McMs-CNN) to recover the original scene. To train the proposed network, we have used two standard datasets namely: ImageNet [5] and D-HAZY [1]. Performance evaluation of the proposed approach has been carried out using structural similarity index (SSIM), mean square error (MSE) and peak signal to noise ratio (PSNR). Performance analysis shows that the proposed approach outperforms the existing state-of-the-art methods for single image dehazing.
Fast Interactive Video Object Segmentation with Graph Neural Networks
Mar 05, 2021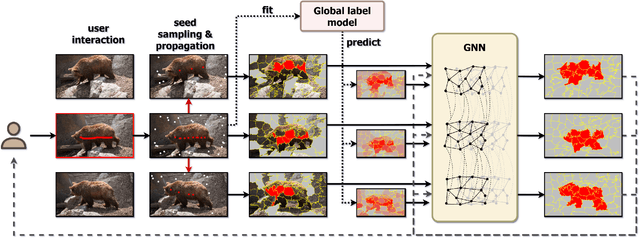


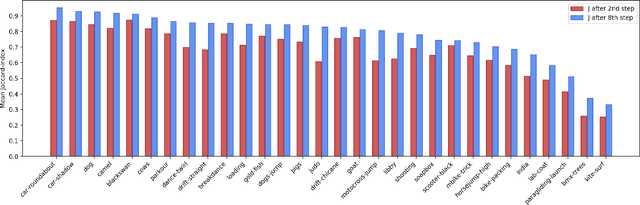
Pixelwise annotation of image sequences can be very tedious for humans. Interactive video object segmentation aims to utilize automatic methods to speed up the process and reduce the workload of the annotators. Most contemporary approaches rely on deep convolutional networks to collect and process information from human annotations throughout the video. However, such networks contain millions of parameters and need huge amounts of labeled training data to avoid overfitting. Beyond that, label propagation is usually executed as a series of frame-by-frame inference steps, which is difficult to be parallelized and is thus time consuming. In this paper we present a graph neural network based approach for tackling the problem of interactive video object segmentation. Our network operates on superpixel-graphs which allow us to reduce the dimensionality of the problem by several magnitudes. We show, that our network possessing only a few thousand parameters is able to achieve state-of-the-art performance, while inference remains fast and can be trained quickly with very little data.
A Simple Riemannian Manifold Network for Image Set Classification
May 27, 2018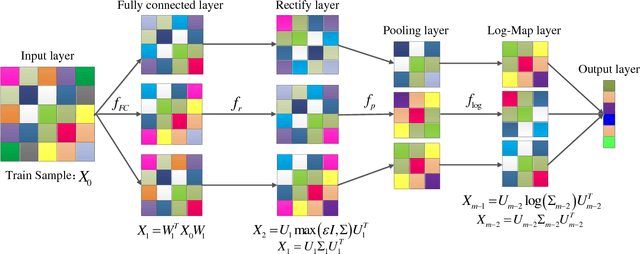
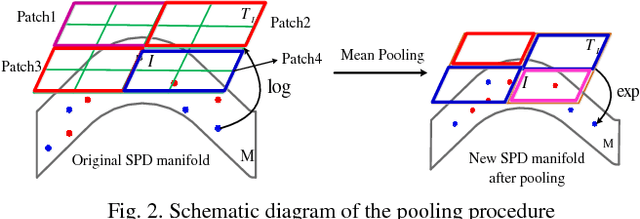
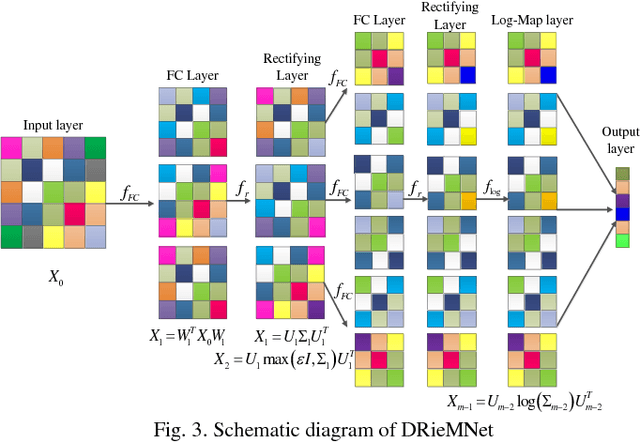
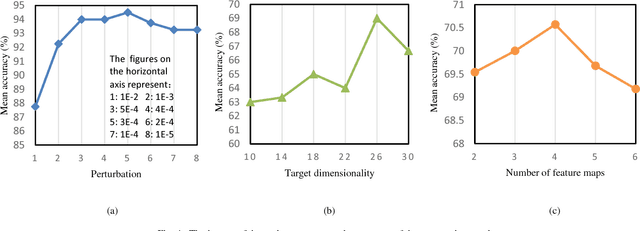
In the domain of image-set based classification, a considerable advance has been made by representing original image sets as covariance matrices which typical lie in a Riemannian manifold. Specifically, it is a Symmetric Positive Definite (SPD) manifold. Traditional manifold learning methods inevitably have the property of high computational complexity or weak performance of the feature representation. In order to overcome these limitations, we propose a very simple Riemannian manifold network for image set classification. Inspired by deep learning architectures, we design a fully connected layer to generate more novel, more powerful SPD matrices. However we exploit the rectifying layer to prevent the input SPD matrices from being singular. We also introduce a non-linear learning of the proposed network with an innovative objective function. Furthermore we devise a pooling layer to further reduce the redundancy of the input SPD matrices, and the log-map layer to project the SPD manifold to the Euclidean space. For learning the connection weights between the input layer and the fully connected layer, we use Two-directional two-dimensional Principal Component Analysis ((2D)2PCA) algorithm. The proposed Riemannian manifold network (RieMNet) avoids complex computing and can be built and trained extremely easy and efficient. We have also developed a deep version of RieMNet, named as DRieMNet. The proposed RieMNet and DRieMNet are evaluated on three tasks: video-based face recognition, set-based object categorization, and set-based cell identification. Extensive experimental results show the superiority of our method over the state-of-the-art.
Image-based Localization using Hourglass Networks
Aug 24, 2017
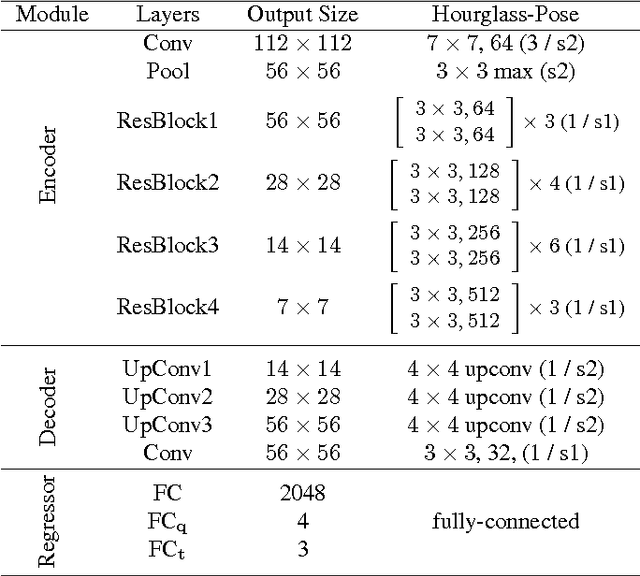


In this paper, we propose an encoder-decoder convolutional neural network (CNN) architecture for estimating camera pose (orientation and location) from a single RGB-image. The architecture has a hourglass shape consisting of a chain of convolution and up-convolution layers followed by a regression part. The up-convolution layers are introduced to preserve the fine-grained information of the input image. Following the common practice, we train our model in end-to-end manner utilizing transfer learning from large scale classification data. The experiments demonstrate the performance of the approach on data exhibiting different lighting conditions, reflections, and motion blur. The results indicate a clear improvement over the previous state-of-the-art even when compared to methods that utilize sequence of test frames instead of a single frame.
Stereo image de-fencing using smartphones
Dec 05, 2016
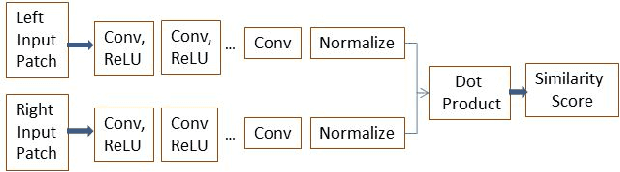
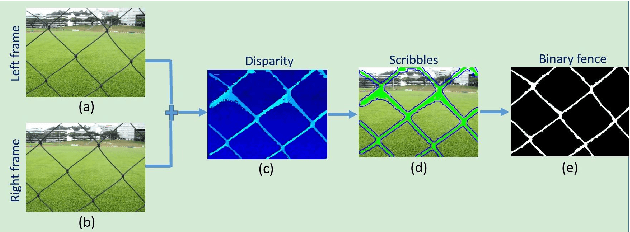

Conventional approaches to image de-fencing have limited themselves to using only image data in adjacent frames of the captured video of an approximately static scene. In this work, we present a method to harness disparity using a stereo pair of fenced images in order to detect fence pixels. Tourists and amateur photographers commonly carry smartphones/phablets which can be used to capture a short video sequence of the fenced scene. We model the formation of the occluded frames in the captured video. Furthermore, we propose an optimization framework to estimate the de-fenced image using the total variation prior to regularize the ill-posed problem.
Fingerprint Presentation Attack Detection utilizing Time-Series, Color Fingerprint Captures
Apr 08, 2021
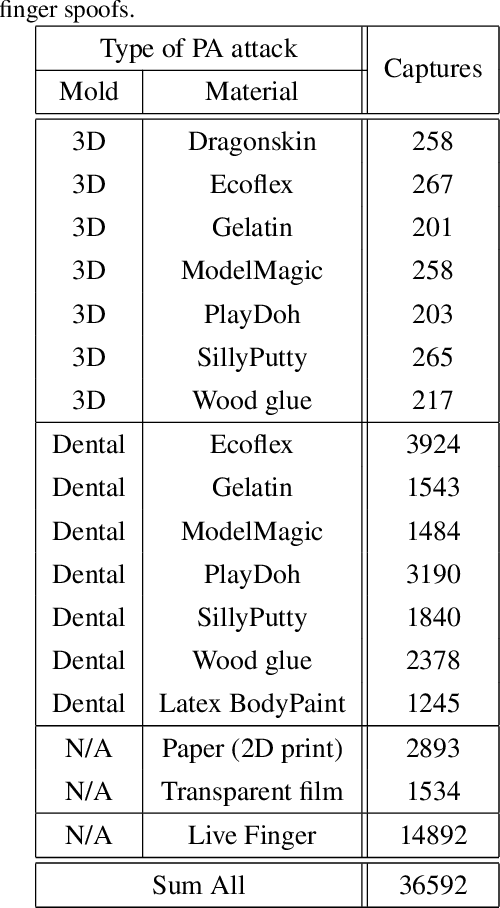

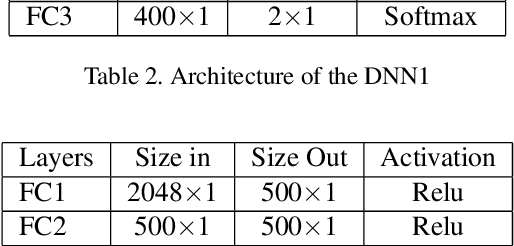
Fingerprint capture systems can be fooled by widely accessible methods to spoof the system using fake fingers, known as presentation attacks. As biometric recognition systems become more extensively relied upon at international borders and in consumer electronics, presentation attacks are becoming an increasingly serious issue. A robust solution is needed that can handle the increased variability and complexity of spoofing techniques. This paper demonstrates the viability of utilizing a sensor with time-series and color-sensing capabilities to improve the robustness of a traditional fingerprint sensor and introduces a comprehensive fingerprint dataset with over 36,000 image sequences and a state-of-the-art set of spoofing techniques. The specific sensor used in this research captures a traditional gray-scale static capture and a time-series color capture simultaneously. Two different methods for Presentation Attack Detection (PAD) are used to assess the benefit of a color dynamic capture. The first algorithm utilizes Static-Temporal Feature Engineering on the fingerprint capture to generate a classification decision. The second generates its classification decision using features extracted by way of the Inception V3 CNN trained on ImageNet. Classification performance is evaluated using features extracted exclusively from the static capture, exclusively from the dynamic capture, and on a fusion of the two feature sets. With both PAD approaches we find that the fusion of the dynamic and static feature-set is shown to improve performance to a level not individually achievable.
* 8 pages, 3 figures, ICB-2019
Instance Similarity Deep Hashing for Multi-Label Image Retrieval
Mar 19, 2018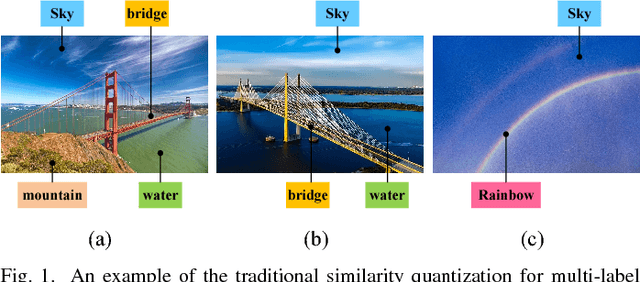

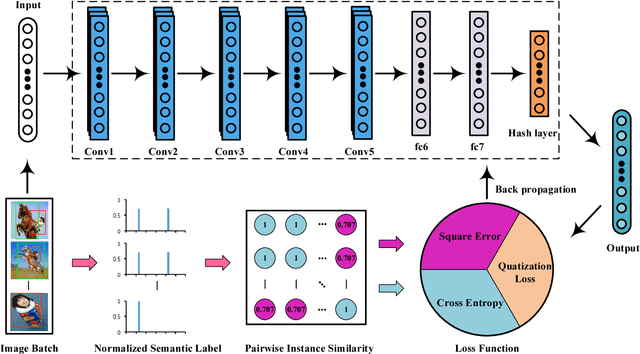

Hash coding has been widely used in the approximate nearest neighbor search for large-scale image retrieval. Recently, many deep hashing methods have been proposed and shown largely improved performance over traditional feature-learning-based methods. Most of these methods examine the pairwise similarity on the semantic-level labels, where the pairwise similarity is generally defined in a hard-assignment way. That is, the pairwise similarity is '1' if they share no less than one class label and '0' if they do not share any. However, such similarity definition cannot reflect the similarity ranking for pairwise images that hold multiple labels. In this paper, a new deep hashing method is proposed for multi-label image retrieval by re-defining the pairwise similarity into an instance similarity, where the instance similarity is quantified into a percentage based on the normalized semantic labels. Based on the instance similarity, a weighted cross-entropy loss and a minimum mean square error loss are tailored for loss-function construction, and are efficiently used for simultaneous feature learning and hash coding. Experiments on three popular datasets demonstrate that, the proposed method outperforms the competing methods and achieves the state-of-the-art performance in multi-label image retrieval.
LaPred: Lane-Aware Prediction of Multi-Modal Future Trajectories of Dynamic Agents
Apr 01, 2021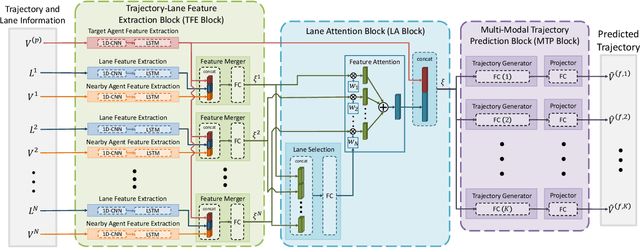
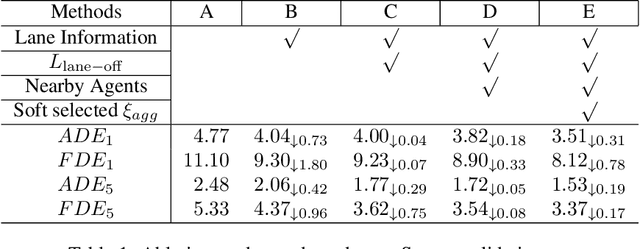
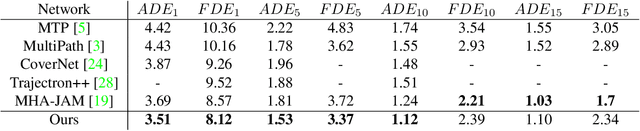
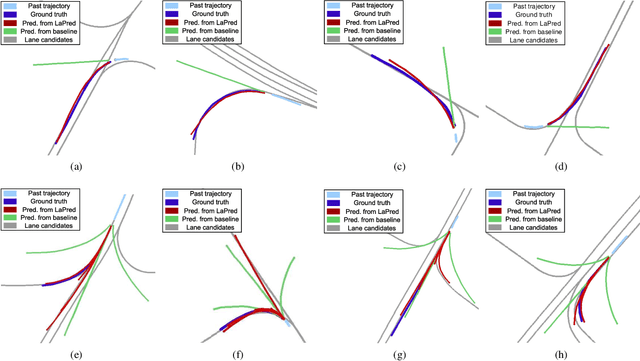
In this paper, we address the problem of predicting the future motion of a dynamic agent (called a target agent) given its current and past states as well as the information on its environment. It is paramount to develop a prediction model that can exploit the contextual information in both static and dynamic environments surrounding the target agent and generate diverse trajectory samples that are meaningful in a traffic context. We propose a novel prediction model, referred to as the lane-aware prediction (LaPred) network, which uses the instance-level lane entities extracted from a semantic map to predict the multi-modal future trajectories. For each lane candidate found in the neighborhood of the target agent, LaPred extracts the joint features relating the lane and the trajectories of the neighboring agents. Then, the features for all lane candidates are fused with the attention weights learned through a self-supervised learning task that identifies the lane candidate likely to be followed by the target agent. Using the instance-level lane information, LaPred can produce the trajectories compliant with the surroundings better than 2D raster image-based methods and generate the diverse future trajectories given multiple lane candidates. The experiments conducted on the public nuScenes dataset and Argoverse dataset demonstrate that the proposed LaPred method significantly outperforms the existing prediction models, achieving state-of-the-art performance in the benchmarks.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021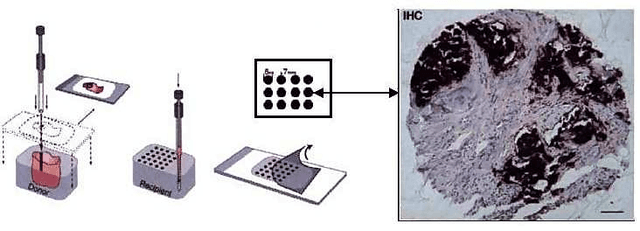
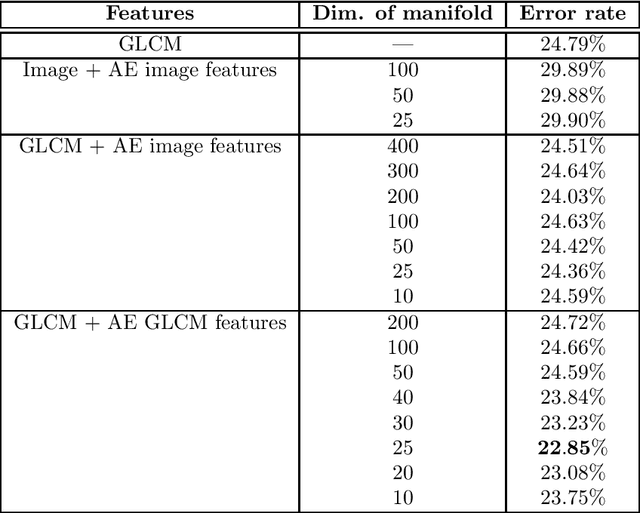
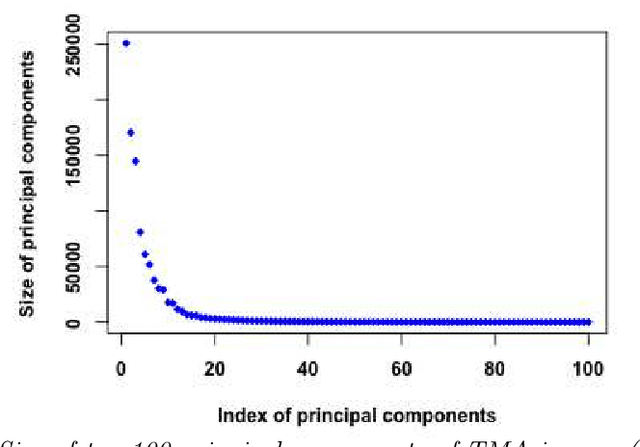
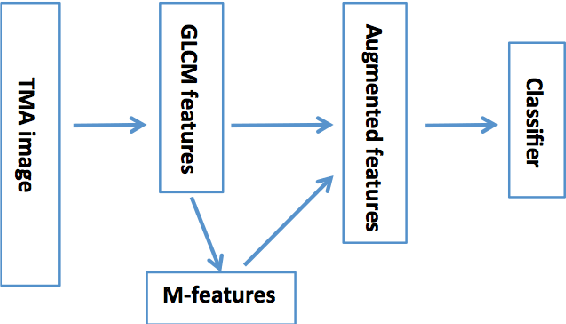
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
Metrics for Exposing the Biases of Content-Style Disentanglement
Aug 27, 2020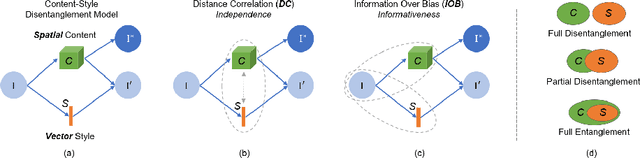
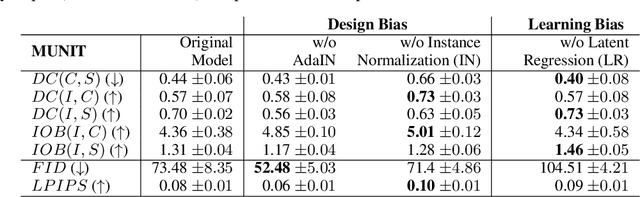
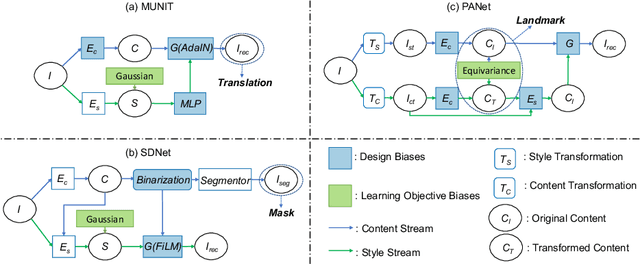
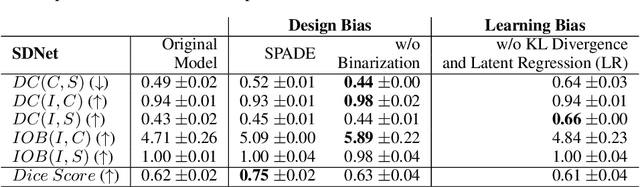
Recent state-of-the-art semi- and un-supervised solutions for challenging computer vision tasks have used the idea of encoding image content into a spatial tensor and image appearance or "style" into a vector. These decomposed representations take advantage of equivariant properties of network design and improve performance in equivariant tasks, such as image-to-image translation. Most of these methods use the term "disentangled" for their representations and employ model design, learning objectives, and data biases to achieve good model performance. While considerable effort has been made to measure disentanglement in vector representations, currently, metrics that can characterize the degree of disentanglement between the representations and task performance are lacking. In this paper, we propose metrics to measure how (un)correlated, biased, and informative the content and style representations are. In particular, we first identify key design choices and learning constraints on three popular models that employ content-style disentanglement and derive ablated versions. Then, we use our metrics to ascertain the role of each bias. Our experiments reveal a "sweet-spot" between disentanglement, task performance and latent space interpretability. The proposed metrics enable the design of better models and the selection of models that achieve the desired performance and disentanglement. Our metrics library is available at https://github.com/TsaftarisCollaboratory/CSDisentanglement_Metrics_Library.