 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MU-GAN: Facial Attribute Editing based on Multi-attention Mechanism
Sep 09, 2020

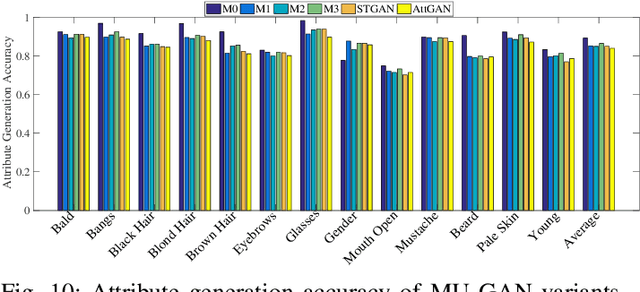
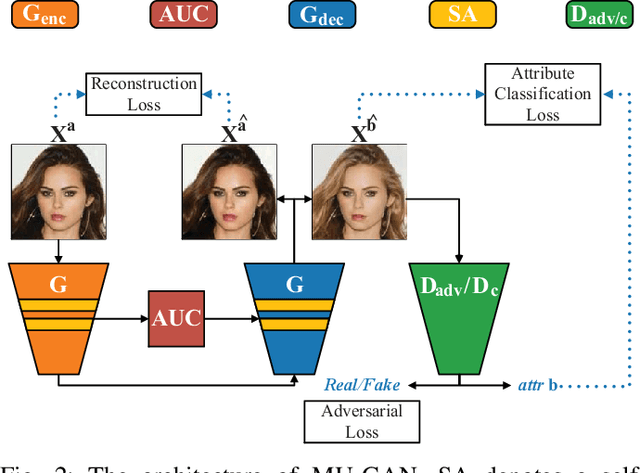
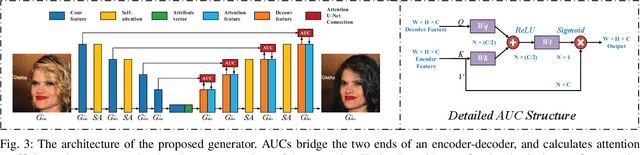
Facial attribute editing has mainly two objectives: 1) translating image from a source domain to a target one, and 2) only changing the facial regions related to a target attribute and preserving the attribute-excluding details. In this work, we propose a Multi-attention U-Net-based Generative Adversarial Network (MU-GAN). First, we replace a classic convolutional encoder-decoder with a symmetric U-Net-like structure in a generator, and then apply an additive attention mechanism to build attention-based U-Net connections for adaptively transferring encoder representations to complement a decoder with attribute-excluding detail and enhance attribute editing ability. Second, a self-attention mechanism is incorporated into convolutional layers for modeling long-range and multi-level dependencies across image regions. experimental results indicate that our method is capable of balancing attribute editing ability and details preservation ability, and can decouple the correlation among attributes. It outperforms the state-of-the-art methods in terms of attribute manipulation accuracy and image quality.
Sample-efficient Reinforcement Learning Representation Learning with Curiosity Contrastive Forward Dynamics Model
Mar 15, 2021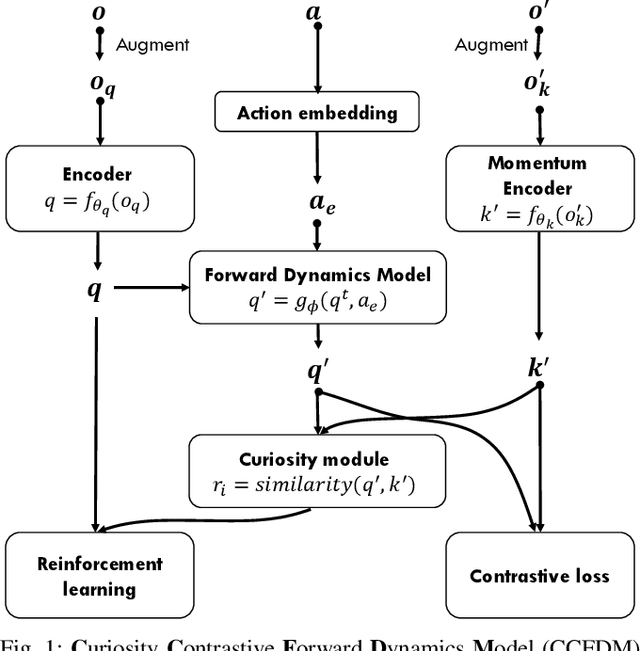
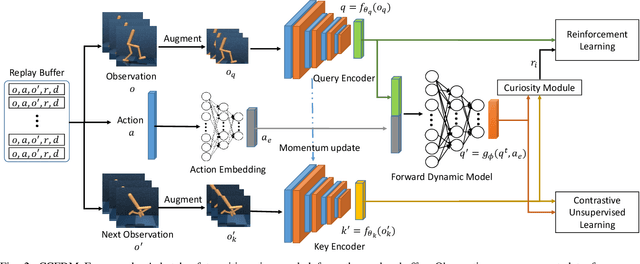
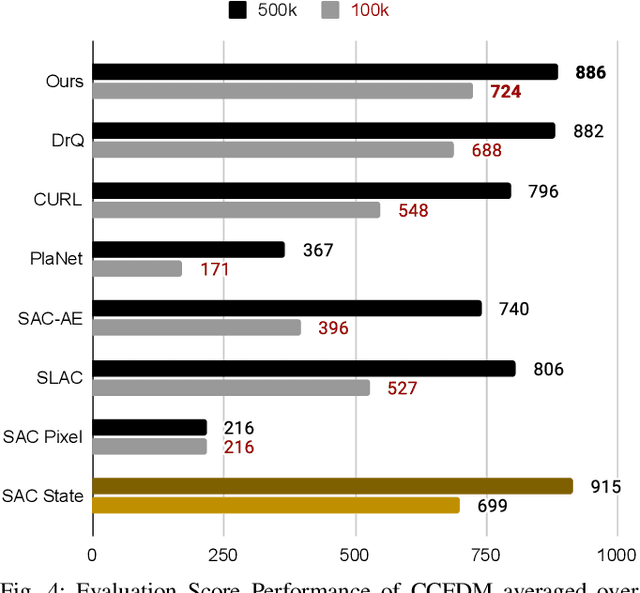
Developing an agent in reinforcement learning (RL) that is capable of performing complex control tasks directly from high-dimensional observation such as raw pixels is yet a challenge as efforts are made towards improving sample efficiency and generalization. This paper considers a learning framework for Curiosity Contrastive Forward Dynamics Model (CCFDM) in achieving a more sample-efficient RL based directly on raw pixels. CCFDM incorporates a forward dynamics model (FDM) and performs contrastive learning to train its deep convolutional neural network-based image encoder (IE) to extract conducive spatial and temporal information for achieving a more sample efficiency for RL. In addition, during training, CCFDM provides intrinsic rewards, produced based on FDM prediction error, encourages the curiosity of the RL agent to improve exploration. The diverge and less-repetitive observations provide by both our exploration strategy and data augmentation available in contrastive learning improve not only the sample efficiency but also the generalization. Performance of existing model-free RL methods such as Soft Actor-Critic built on top of CCFDM outperforms prior state-of-the-art pixel-based RL methods on the DeepMind Control Suite benchmark.
Fast Interactive Video Object Segmentation with Graph Neural Networks
Mar 05, 2021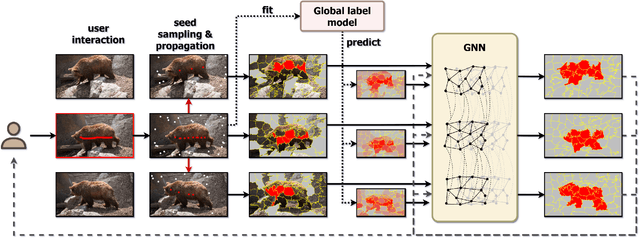


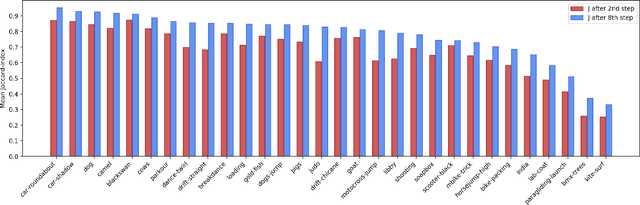
Pixelwise annotation of image sequences can be very tedious for humans. Interactive video object segmentation aims to utilize automatic methods to speed up the process and reduce the workload of the annotators. Most contemporary approaches rely on deep convolutional networks to collect and process information from human annotations throughout the video. However, such networks contain millions of parameters and need huge amounts of labeled training data to avoid overfitting. Beyond that, label propagation is usually executed as a series of frame-by-frame inference steps, which is difficult to be parallelized and is thus time consuming. In this paper we present a graph neural network based approach for tackling the problem of interactive video object segmentation. Our network operates on superpixel-graphs which allow us to reduce the dimensionality of the problem by several magnitudes. We show, that our network possessing only a few thousand parameters is able to achieve state-of-the-art performance, while inference remains fast and can be trained quickly with very little data.
Unsupervised Multi-Domain Image Translation with Domain-Specific Encoders/Decoders
Dec 06, 2017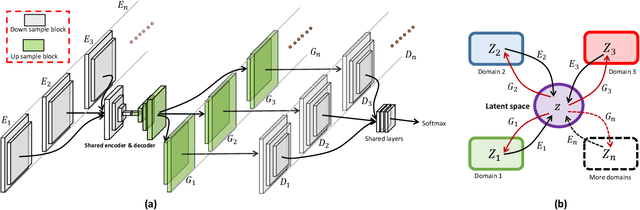


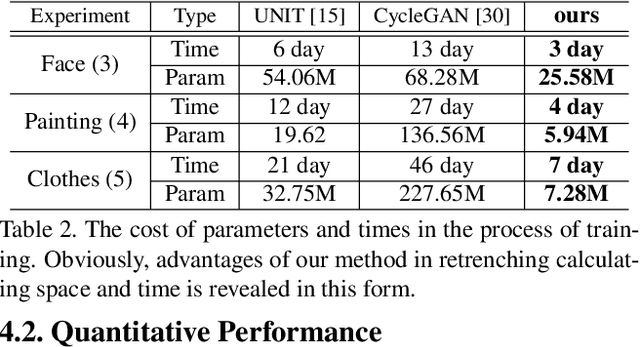
Unsupervised Image-to-Image Translation achieves spectacularly advanced developments nowadays. However, recent approaches mainly focus on one model with two domains, which may face heavy burdens with large cost of $O(n^2)$ training time and model parameters, under such a requirement that $n$ domains are freely transferred to each other in a general setting. To address this problem, we propose a novel and unified framework named Domain-Bank, which consists of a global shared auto-encoder and $n$ domain-specific encoders/decoders, assuming that a universal shared-latent sapce can be projected. Thus, we yield $O(n)$ complexity in model parameters along with a huge reduction of the time budgets. Besides the high efficiency, we show the comparable (or even better) image translation results over state-of-the-arts on various challenging unsupervised image translation tasks, including face image translation, fashion-clothes translation and painting style translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on digit benchmark datasets. Further, thanks to the explicit representation of the domain-specific decoders as well as the universal shared-latent space, it also enables us to conduct incremental learning to add a new domain encoder/decoder. Linear combination of different domains' representations is also obtained by fusing the corresponding decoders.
Residual Dense Network for Image Super-Resolution
Mar 27, 2018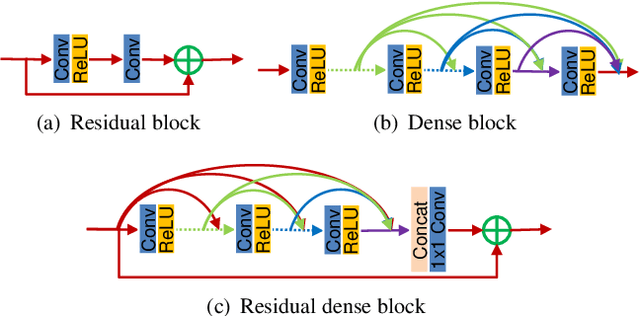

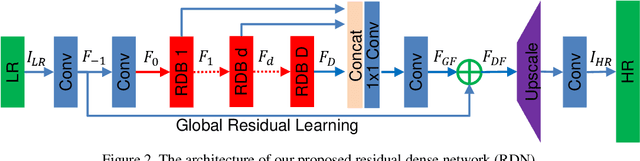
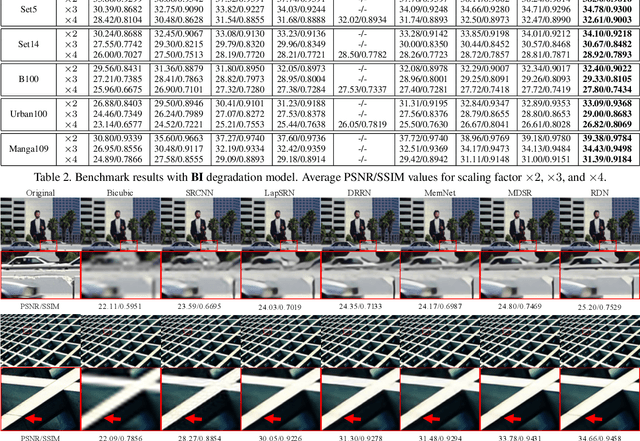
A very deep convolutional neural network (CNN) has recently achieved great success for image super-resolution (SR) and offered hierarchical features as well. However, most deep CNN based SR models do not make full use of the hierarchical features from the original low-resolution (LR) images, thereby achieving relatively-low performance. In this paper, we propose a novel residual dense network (RDN) to address this problem in image SR. We fully exploit the hierarchical features from all the convolutional layers. Specifically, we propose residual dense block (RDB) to extract abundant local features via dense connected convolutional layers. RDB further allows direct connections from the state of preceding RDB to all the layers of current RDB, leading to a contiguous memory (CM) mechanism. Local feature fusion in RDB is then used to adaptively learn more effective features from preceding and current local features and stabilizes the training of wider network. After fully obtaining dense local features, we use global feature fusion to jointly and adaptively learn global hierarchical features in a holistic way. Extensive experiments on benchmark datasets with different degradation models show that our RDN achieves favorable performance against state-of-the-art methods.
Fingerprint Presentation Attack Detection utilizing Time-Series, Color Fingerprint Captures
Apr 08, 2021
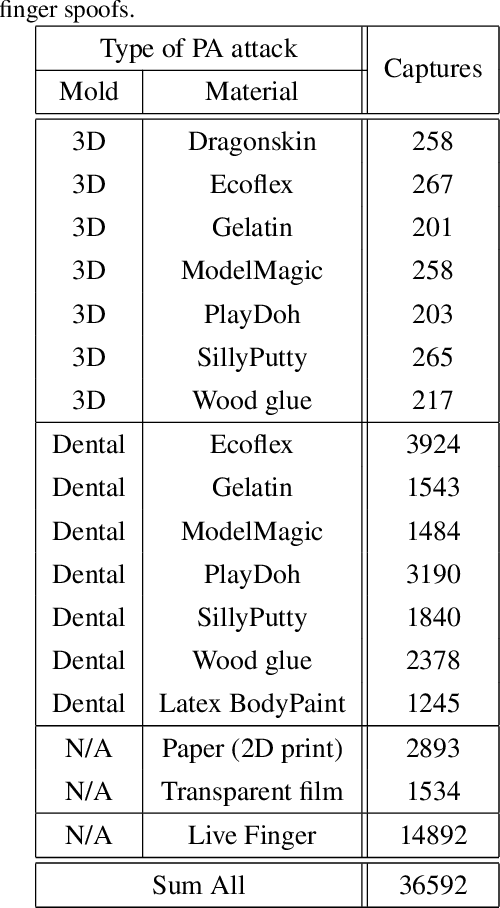

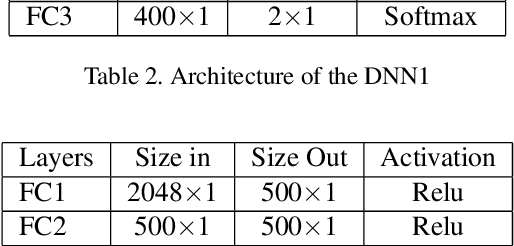
Fingerprint capture systems can be fooled by widely accessible methods to spoof the system using fake fingers, known as presentation attacks. As biometric recognition systems become more extensively relied upon at international borders and in consumer electronics, presentation attacks are becoming an increasingly serious issue. A robust solution is needed that can handle the increased variability and complexity of spoofing techniques. This paper demonstrates the viability of utilizing a sensor with time-series and color-sensing capabilities to improve the robustness of a traditional fingerprint sensor and introduces a comprehensive fingerprint dataset with over 36,000 image sequences and a state-of-the-art set of spoofing techniques. The specific sensor used in this research captures a traditional gray-scale static capture and a time-series color capture simultaneously. Two different methods for Presentation Attack Detection (PAD) are used to assess the benefit of a color dynamic capture. The first algorithm utilizes Static-Temporal Feature Engineering on the fingerprint capture to generate a classification decision. The second generates its classification decision using features extracted by way of the Inception V3 CNN trained on ImageNet. Classification performance is evaluated using features extracted exclusively from the static capture, exclusively from the dynamic capture, and on a fusion of the two feature sets. With both PAD approaches we find that the fusion of the dynamic and static feature-set is shown to improve performance to a level not individually achievable.
* 8 pages, 3 figures, ICB-2019
Single MR Image Super-Resolution via Channel Splitting and Serial Fusion Network
Jan 19, 2019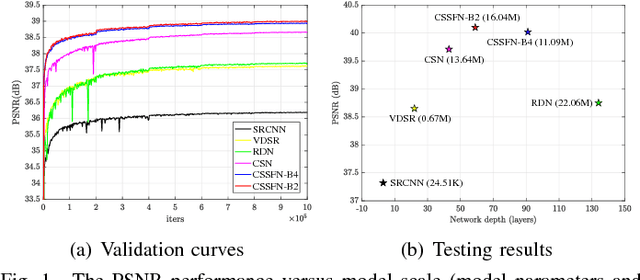
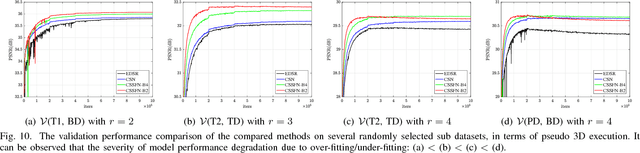
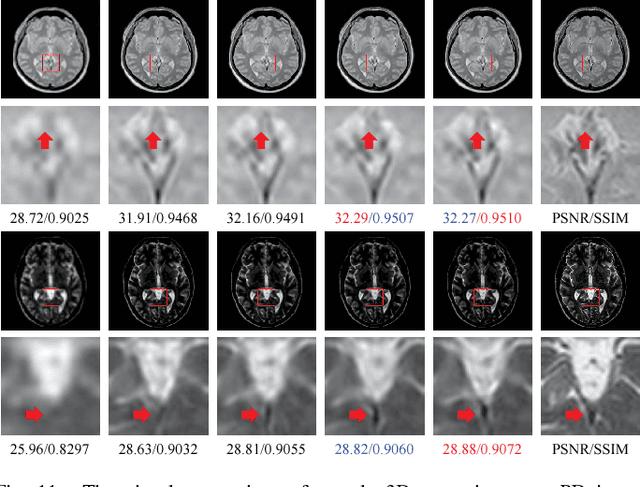
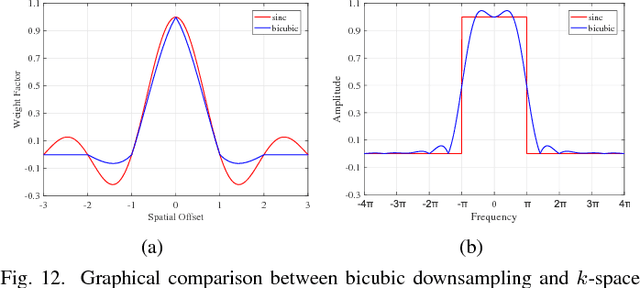
Spatial resolution is a critical imaging parameter in magnetic resonance imaging (MRI). Acquiring high resolution MRI data usually takes long scanning time and would subject to motion artifacts due to hardware, physical, and physiological limitations. Single image super-resolution (SISR), especially that based on deep learning techniques, is an effective and promising alternative technique to improve the current spatial resolution of magnetic resonance (MR) images. However, the deeper network is more difficult to be effectively trained because the information is gradually weakened as the network deepens. This problem becomes more serious for medical images due to the degradation of training examples. In this paper, we present a novel channel splitting and serial fusion network (CSSFN) for single MR image super-resolution. Specifically, the proposed CSSFN network splits the hierarchical features into a series of subfeatures, which are then integrated together in a serial manner. Thus, the network becomes deeper and can deal with the subfeatures on different channels discriminatively. Besides, a dense global feature fusion (DGFF) is adopted to integrate the intermediate features, which further promotes the information flow in the network. Extensive experiments on several typical MR images show the superiority of our CSSFN model over other advanced SISR methods.
LaPred: Lane-Aware Prediction of Multi-Modal Future Trajectories of Dynamic Agents
Apr 01, 2021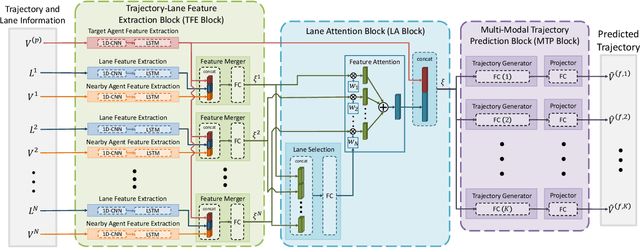
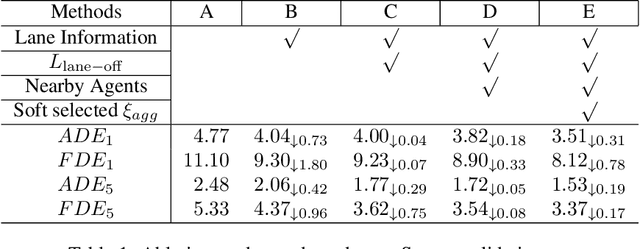
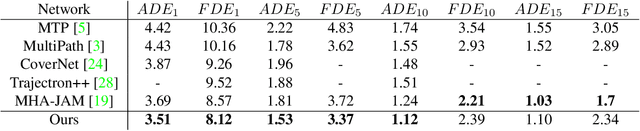
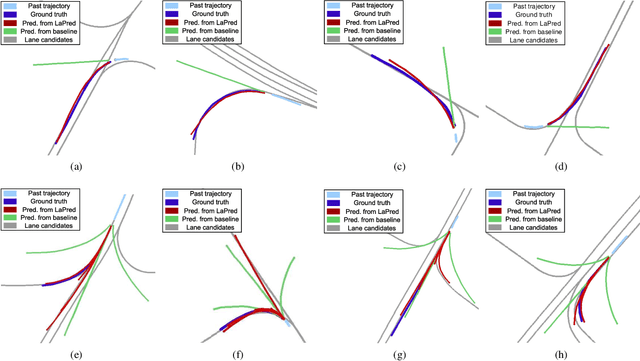
In this paper, we address the problem of predicting the future motion of a dynamic agent (called a target agent) given its current and past states as well as the information on its environment. It is paramount to develop a prediction model that can exploit the contextual information in both static and dynamic environments surrounding the target agent and generate diverse trajectory samples that are meaningful in a traffic context. We propose a novel prediction model, referred to as the lane-aware prediction (LaPred) network, which uses the instance-level lane entities extracted from a semantic map to predict the multi-modal future trajectories. For each lane candidate found in the neighborhood of the target agent, LaPred extracts the joint features relating the lane and the trajectories of the neighboring agents. Then, the features for all lane candidates are fused with the attention weights learned through a self-supervised learning task that identifies the lane candidate likely to be followed by the target agent. Using the instance-level lane information, LaPred can produce the trajectories compliant with the surroundings better than 2D raster image-based methods and generate the diverse future trajectories given multiple lane candidates. The experiments conducted on the public nuScenes dataset and Argoverse dataset demonstrate that the proposed LaPred method significantly outperforms the existing prediction models, achieving state-of-the-art performance in the benchmarks.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021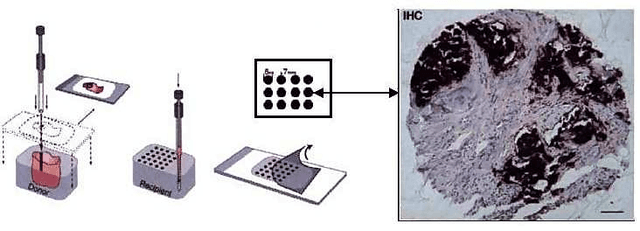
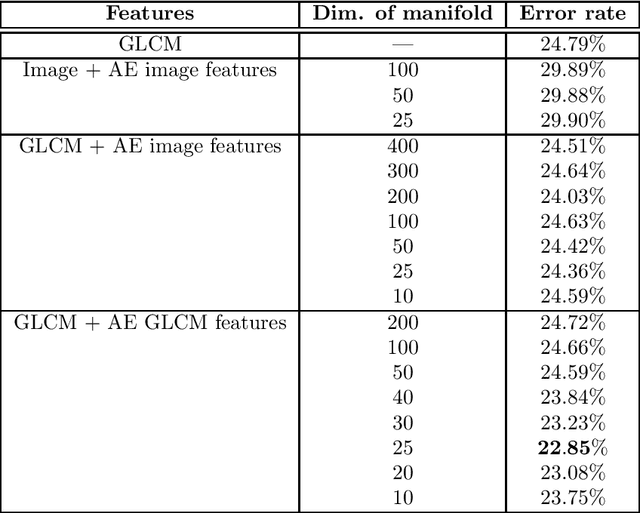
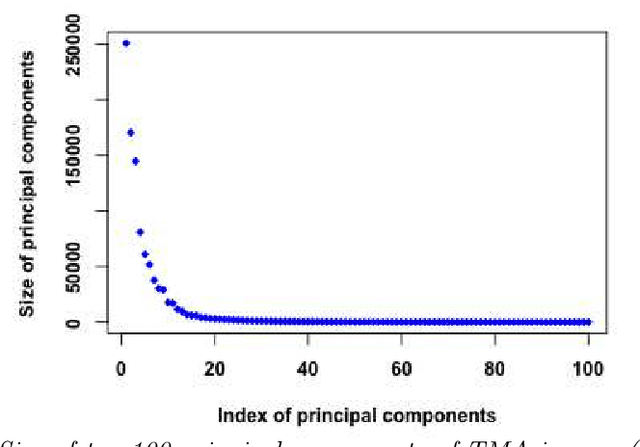
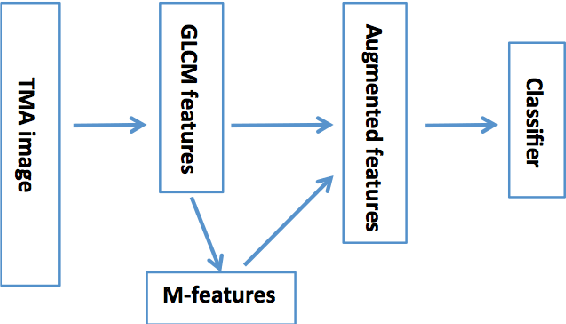
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
Adversarial Image Translation: Unrestricted Adversarial Examples in Face Recognition Systems
May 09, 2019

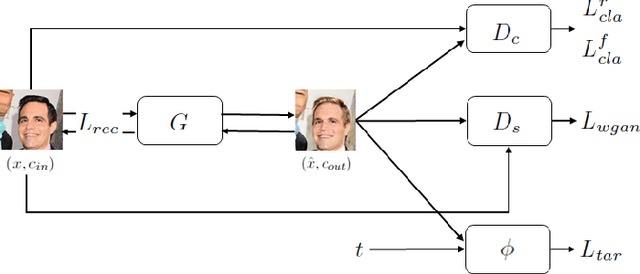

Thanks to recent advances in Deep Neural Networks (DNNs), face recognition systems have achieved high accuracy in classification of a large number of face images. However, recent works demonstrate that DNNs could be vulnerable to adversarial examples and raise concerns about robustness of face recognition systems. In particular adversarial examples that are not restricted to small perturbations could be more serious risks since conventional certified defenses might be ineffective against them. To shed light on the vulnerability of the face recognition systems to this type of adversarial examples, we propose a flexible and efficient method to generate unrestricted adversarial examples using image translation techniques. Our method enables us to translate a source into any desired facial appearance with large perturbations so that target face recognition systems could be deceived. We demonstrate through our experiments that our method achieves about $90\%$ and $30\%$ attack success rates under a white- and black-box setting, respectively. We also illustrate that our generated images are perceptually realistic and maintain personal identity while the perturbations are large enough to defeat certified defenses.