 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bidirectional Projection Network for Cross Dimension Scene Understanding
Mar 26, 2021
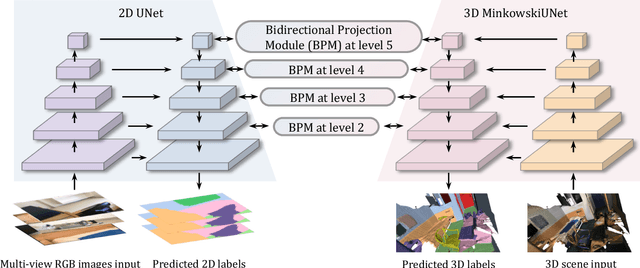
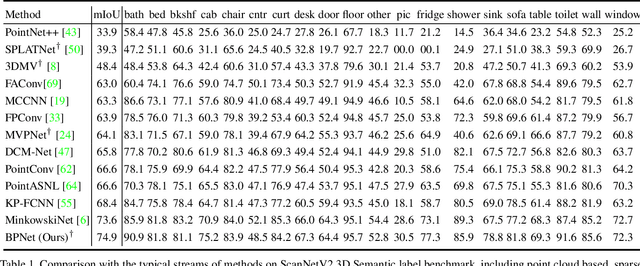
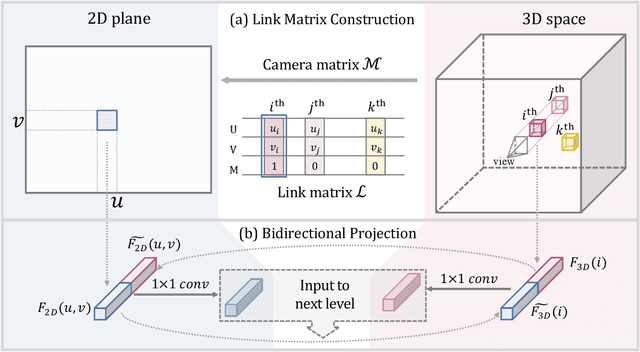
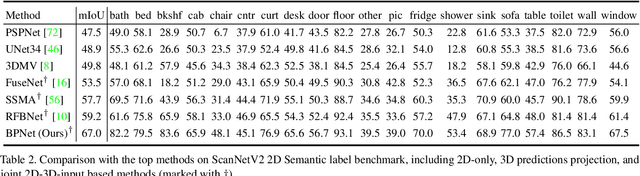
2D image representations are in regular grids and can be processed efficiently, whereas 3D point clouds are unordered and scattered in 3D space. The information inside these two visual domains is well complementary, e.g., 2D images have fine-grained texture while 3D point clouds contain plentiful geometry information. However, most current visual recognition systems process them individually. In this paper, we present a \emph{bidirectional projection network (BPNet)} for joint 2D and 3D reasoning in an end-to-end manner. It contains 2D and 3D sub-networks with symmetric architectures, that are connected by our proposed \emph{bidirectional projection module (BPM)}. Via the \emph{BPM}, complementary 2D and 3D information can interact with each other in multiple architectural levels, such that advantages in these two visual domains can be combined for better scene recognition. Extensive quantitative and qualitative experimental evaluations show that joint reasoning over 2D and 3D visual domains can benefit both 2D and 3D scene understanding simultaneously. Our \emph{BPNet} achieves top performance on the ScanNetV2 benchmark for both 2D and 3D semantic segmentation. Code is available at \url{https://github.com/wbhu/BPNet}.
* CVPR 2021 (Oral)
Benefiting Deep Latent Variable Models via Learning the Prior and Removing Latent Regularization
Jul 16, 2020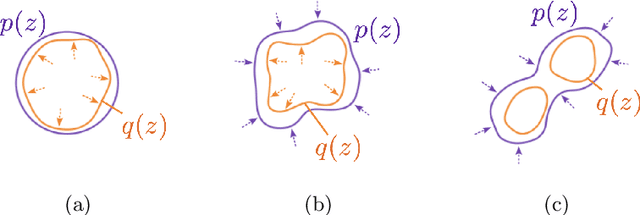
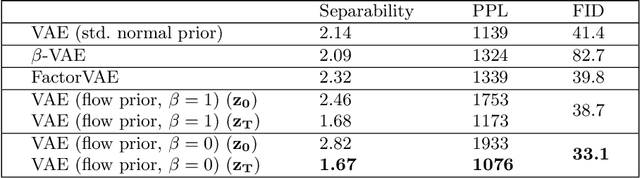
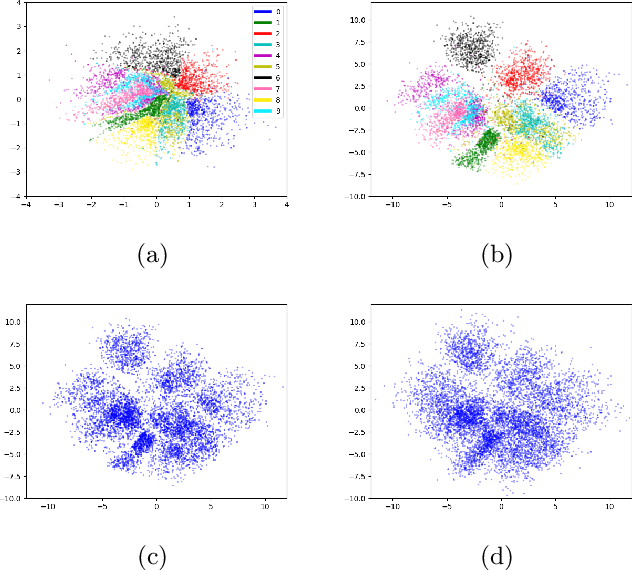

There exist many forms of deep latent variable models, such as the variational autoencoder and adversarial autoencoder. Regardless of the specific class of model, there exists an implicit consensus that the latent distribution should be regularized towards the prior, even in the case where the prior distribution is learned. Upon investigating the effect of latent regularization on image generation our results indicate that in the case where a sufficiently expressive prior is learned, latent regularization is not necessary and may in fact be harmful insofar as image quality is concerned. We additionally investigate the benefit of learned priors on two common problems in computer vision: latent variable disentanglement, and diversity in image-to-image translation.
Approximation of dilation-based spatial relations to add structural constraints in neural networks
Feb 22, 2021


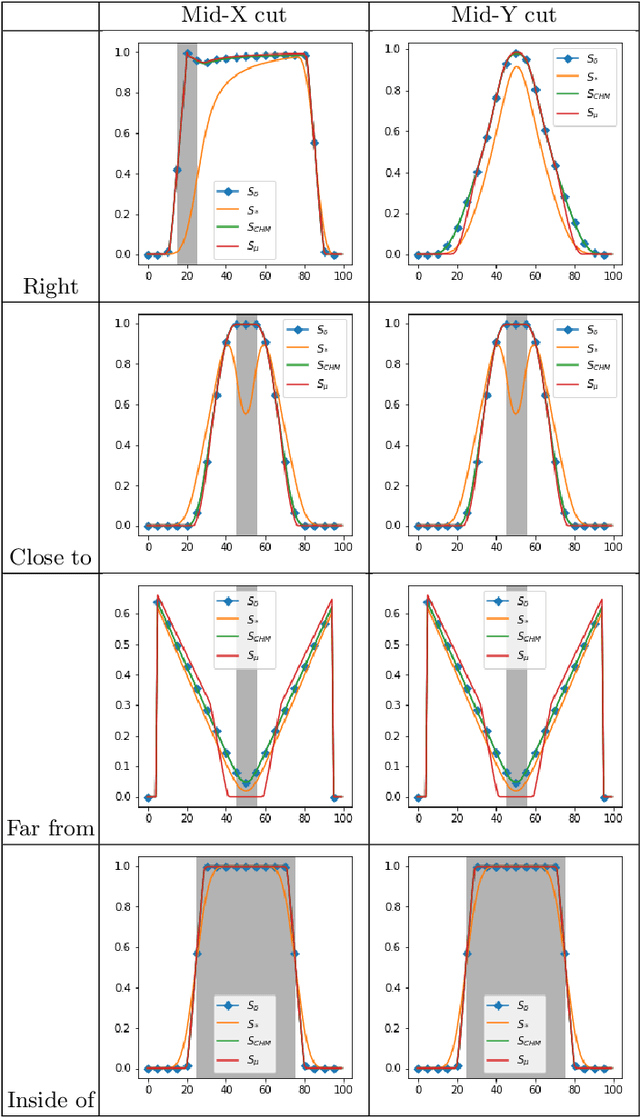
Spatial relations between objects in an image have proved useful for structural object recognition. Structural constraints can act as regularization in neural network training, improving generalization capability with small datasets. Several relations can be modeled as a morphological dilation of a reference object with a structuring element representing the semantics of the relation, from which the degree of satisfaction of the relation between another object and the reference object can be derived. However, dilation is not differentiable, requiring an approximation to be used in the context of gradient-descent training of a network. We propose to approximate dilations using convolutions based on a kernel equal to the structuring element. We show that the proposed approximation, even if slightly less accurate than previous approximations, is definitely faster to compute and therefore more suitable for computationally intensive neural network applications.
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 04, 2021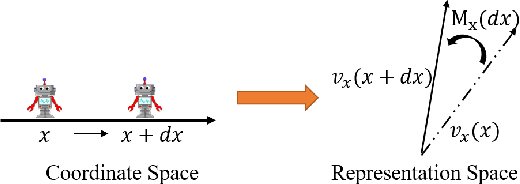
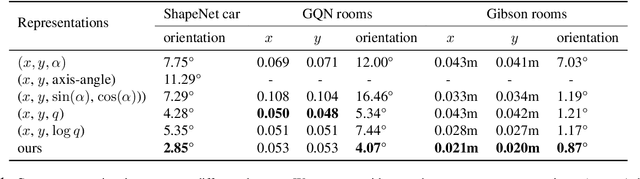
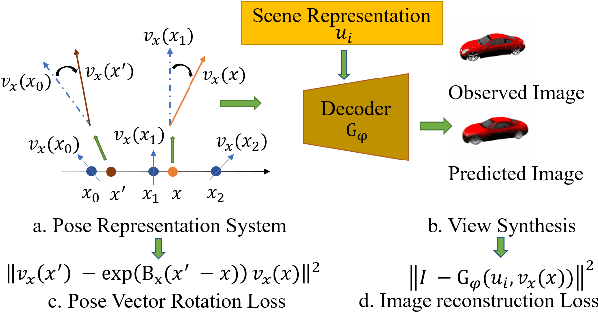
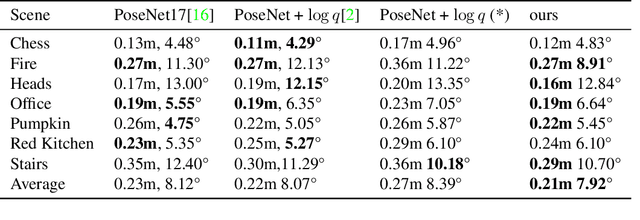
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.
Deep Recursive Embedding for High-Dimensional Data
Apr 12, 2021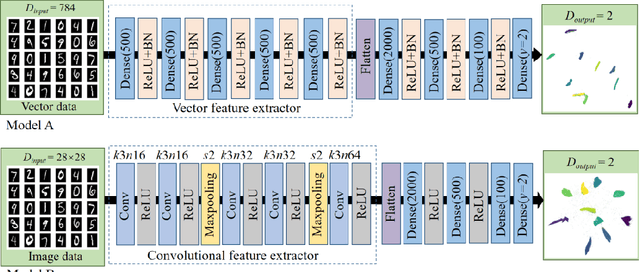
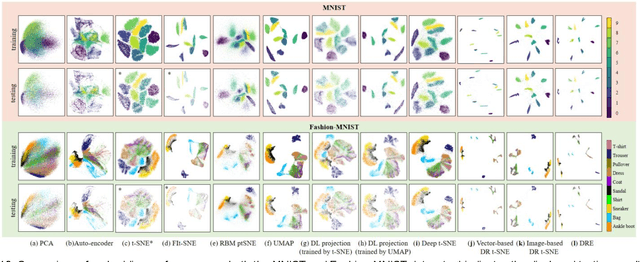
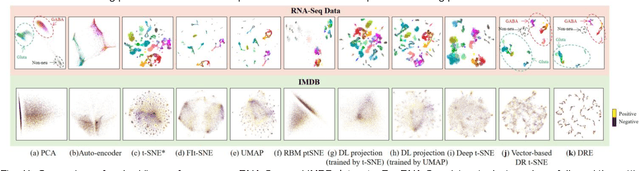
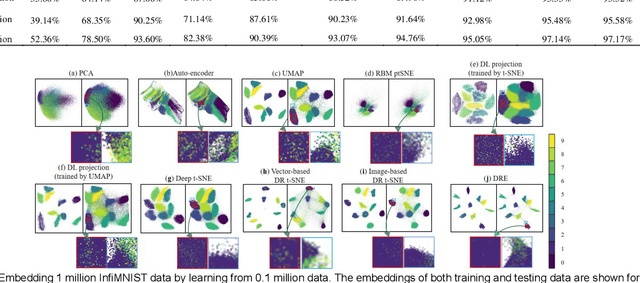
t-distributed stochastic neighbor embedding (t-SNE) is a well-established visualization method for complex high-dimensional data. However, the original t-SNE method is nonparametric, stochastic, and often cannot well prevserve the global structure of data as it emphasizes local neighborhood. With t-SNE as a reference, we propose to combine the deep neural network (DNN) with the mathematical-grounded embedding rules for high-dimensional data embedding. We first introduce a deep embedding network (DEN) framework, which can learn a parametric mapping from high-dimensional space to low-dimensional embedding. DEN has a flexible architecture that can accommodate different input data (vector, image, or tensor) and loss functions. To improve the embedding performance, a recursive training strategy is proposed to make use of the latent representations extracted by DEN. Finally, we propose a two-stage loss function combining the advantages of two popular embedding methods, namely, t-SNE and uniform manifold approximation and projection (UMAP), for optimal visualization effect. We name the proposed method Deep Recursive Embedding (DRE), which optimizes DEN with a recursive training strategy and two-stage losse. Our experiments demonstrated the excellent performance of the proposed DRE method on high-dimensional data embedding, across a variety of public databases. Remarkably, our comparative results suggested that our proposed DRE could lead to improved global structure preservation.
Colonoscopy Polyp Detection: Domain Adaptation From Medical Report Images to Real-time Videos
Dec 31, 2020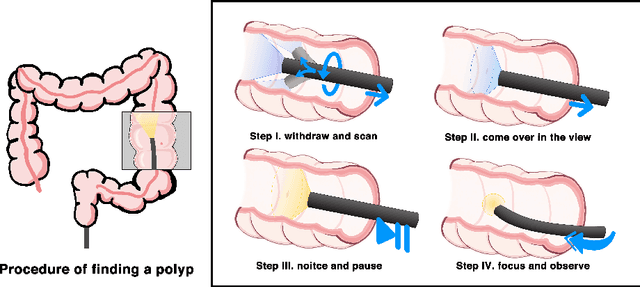
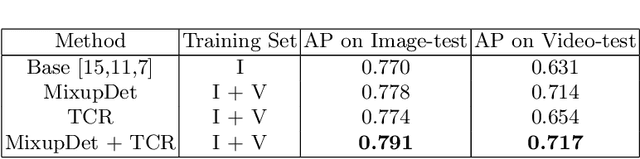
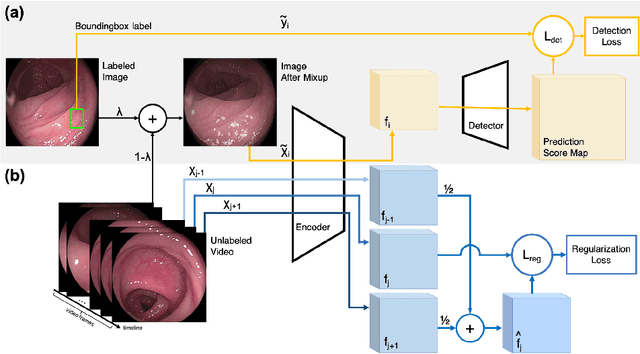
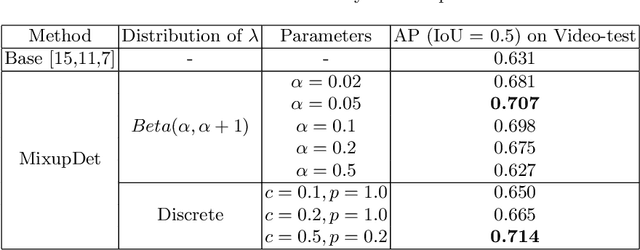
Automatic colorectal polyp detection in colonoscopy video is a fundamental task, which has received a lot of attention. Manually annotating polyp region in a large scale video dataset is time-consuming and expensive, which limits the development of deep learning techniques. A compromise is to train the target model by using labeled images and infer on colonoscopy videos. However, there are several issues between the image-based training and video-based inference, including domain differences, lack of positive samples, and temporal smoothness. To address these issues, we propose an Image-video-joint polyp detection network (Ivy-Net) to address the domain gap between colonoscopy images from historical medical reports and real-time videos. In our Ivy-Net, a modified mixup is utilized to generate training data by combining the positive images and negative video frames at the pixel level, which could learn the domain adaptive representations and augment the positive samples. Simultaneously, a temporal coherence regularization (TCR) is proposed to introduce the smooth constraint on feature-level in adjacent frames and improve polyp detection by unlabeled colonoscopy videos. For evaluation, a new large colonoscopy polyp dataset is collected, which contains 3056 images from historical medical reports of 889 positive patients and 7.5-hour videos of 69 patients (28 positive). The experiments on the collected dataset demonstrate that our Ivy-Net achieves the state-of-the-art result on colonoscopy video.
Adversarial Deformation Regularization for Training Image Registration Neural Networks
May 27, 2018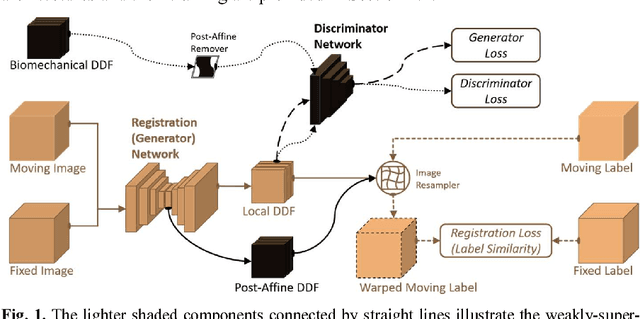
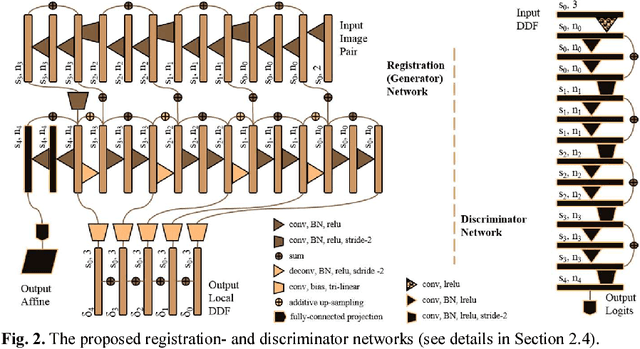
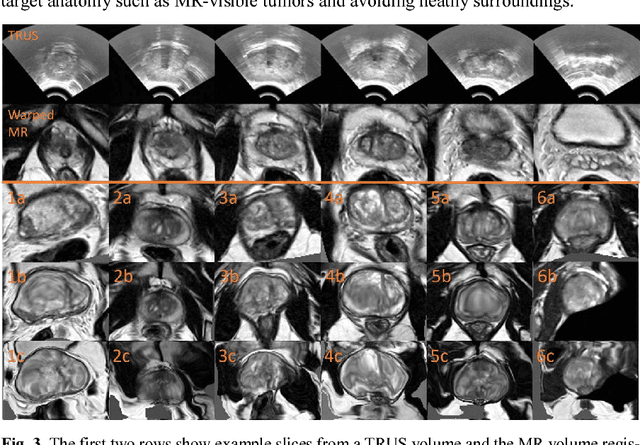
We describe an adversarial learning approach to constrain convolutional neural network training for image registration, replacing heuristic smoothness measures of displacement fields often used in these tasks. Using minimally-invasive prostate cancer intervention as an example application, we demonstrate the feasibility of utilizing biomechanical simulations to regularize a weakly-supervised anatomical-label-driven registration network for aligning pre-procedural magnetic resonance (MR) and 3D intra-procedural transrectal ultrasound (TRUS) images. A discriminator network is optimized to distinguish the registration-predicted displacement fields from the motion data simulated by finite element analysis. During training, the registration network simultaneously aims to maximize similarity between anatomical labels that drives image alignment and to minimize an adversarial generator loss that measures divergence between the predicted- and simulated deformation. The end-to-end trained network enables efficient and fully-automated registration that only requires an MR and TRUS image pair as input, without anatomical labels or simulated data during inference. 108 pairs of labelled MR and TRUS images from 76 prostate cancer patients and 71,500 nonlinear finite-element simulations from 143 different patients were used for this study. We show that, with only gland segmentation as training labels, the proposed method can help predict physically plausible deformation without any other smoothness penalty. Based on cross-validation experiments using 834 pairs of independent validation landmarks, the proposed adversarial-regularized registration achieved a target registration error of 6.3 mm that is significantly lower than those from several other regularization methods.
SCRIB: Set-classifier with Class-specific Risk Bounds for Blackbox Models
Mar 05, 2021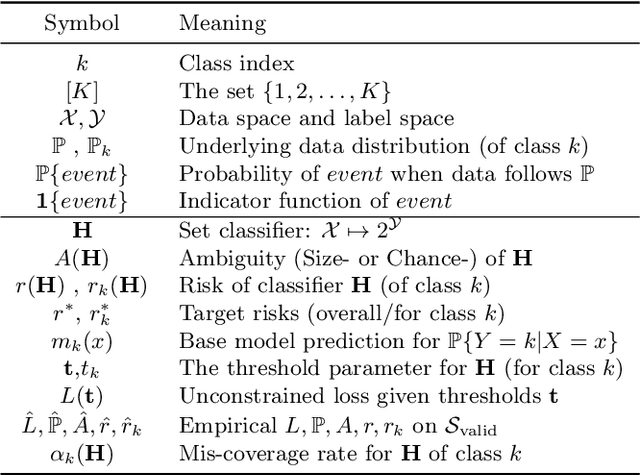
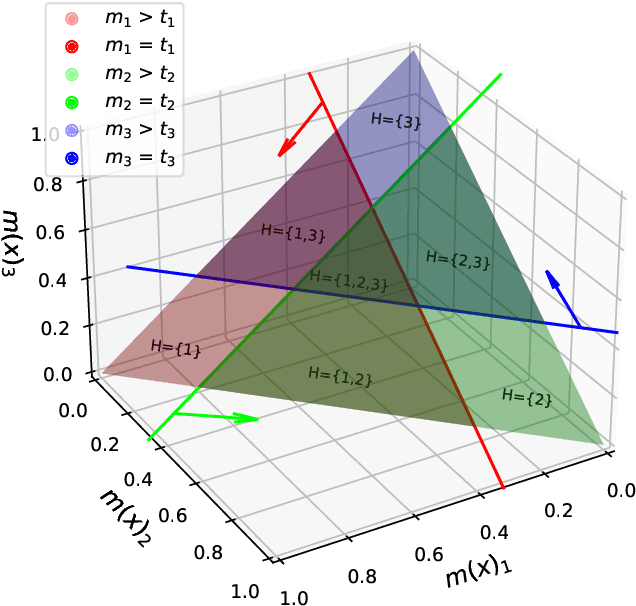
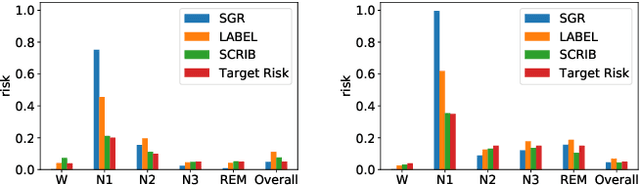
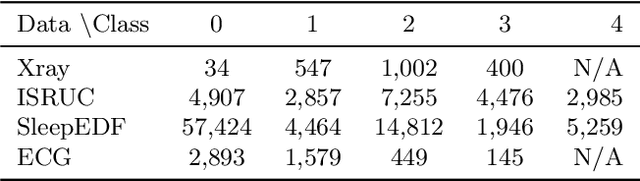
Despite deep learning (DL) success in classification problems, DL classifiers do not provide a sound mechanism to decide when to refrain from predicting. Recent works tried to control the overall prediction risk with classification with rejection options. However, existing works overlook the different significance of different classes. We introduce Set-classifier with Class-specific RIsk Bounds (SCRIB) to tackle this problem, assigning multiple labels to each example. Given the output of a black-box model on the validation set, SCRIB constructs a set-classifier that controls the class-specific prediction risks with a theoretical guarantee. The key idea is to reject when the set classifier returns more than one label. We validated SCRIB on several medical applications, including sleep staging on electroencephalogram (EEG) data, X-ray COVID image classification, and atrial fibrillation detection based on electrocardiogram (ECG) data. SCRIB obtained desirable class-specific risks, which are 35\%-88\% closer to the target risks than baseline methods.
An automated approach to mitigate transcription errors in braille texts for the Portuguese language
Mar 05, 2021
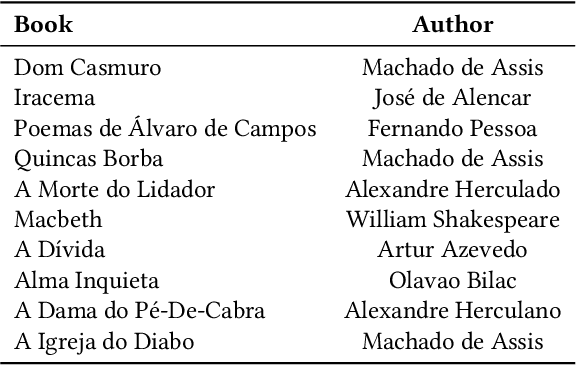

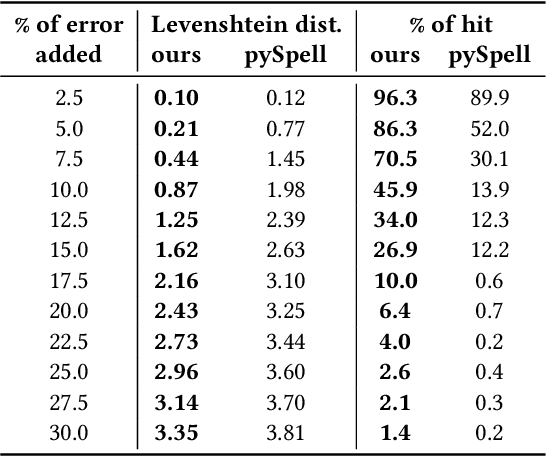
The quota system in Brazil made it possible to include blind students in higher education. Teachers' lack of knowledge about the braille system can represent a barrier between them and students who use it for writing and reading. Computer-vision-based transcription solutions represent mechanisms for reducing understanding restrictions on this system. However, such tools face nuisances inherent to image processing systems, e.g., illumination, noise, and scale, harming the result. This paper presents an automated approach to mitigate transcription errors in braille texts for the Portuguese language. We propose a selection function, combined with dictionaries, that provides the best correspondence of words based on their braille representation. We validated our proposal on a dataset of synthetic images by submitting them to different noise levels and testing the proposal's robustness. Experimental results confirm the effectiveness of the solution compared to a standard approach. As a contribution of this paper, we expect to provide a method to support robust and adaptable solutions to real use conditions.
Combining Morphological and Histogram based Text Line Segmentation in the OCR Context
Mar 16, 2021



Text line segmentation is one of the pre-stages of modern optical character recognition systems. The algorithmic approach proposed by this paper has been designed for this exact purpose. Its main characteristic is the combination of two different techniques, morphological image operations and horizontal histogram projections. The method was developed to be applied on a historic data collection that commonly features quality issues, such as degraded paper, blurred text, or curved text lines. For that reason, the segmenter in question could be of particular interest for cultural institutions, such as libraries, archives, museums, ..., that want access to robust line bounding boxes for a given historic document. Because of the promising segmentation results that are joined by low computational cost, the algorithm was incorporated into the OCR pipeline of the National Library of Luxembourg, in the context of the initiative of reprocessing their historic newspaper collection. The general contribution of this paper is to outline the approach and to evaluate the gains in terms of accuracy and speed, comparing it to the segmentation algorithm bundled with the used open source OCR software.