 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Network Quantization with Element-wise Gradient Scaling
Apr 02, 2021
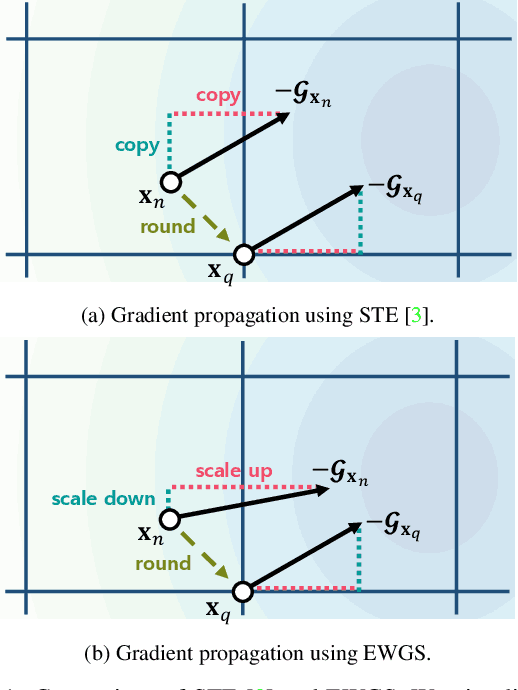
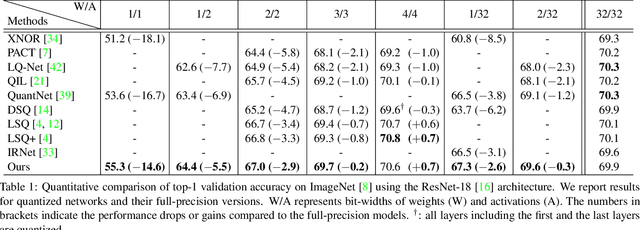
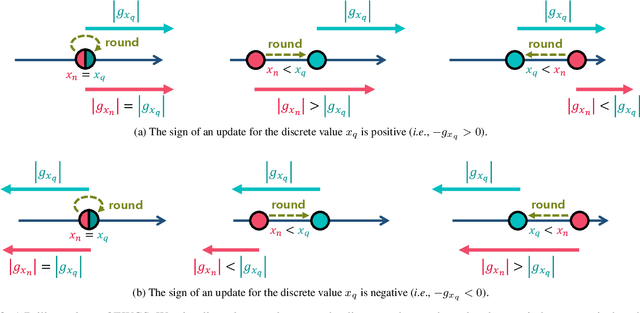
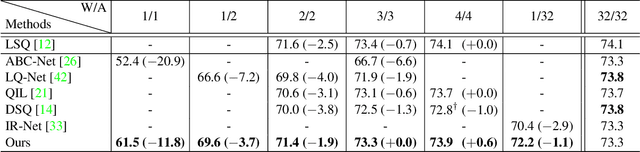
Network quantization aims at reducing bit-widths of weights and/or activations, particularly important for implementing deep neural networks with limited hardware resources. Most methods use the straight-through estimator (STE) to train quantized networks, which avoids a zero-gradient problem by replacing a derivative of a discretizer (i.e., a round function) with that of an identity function. Although quantized networks exploiting the STE have shown decent performance, the STE is sub-optimal in that it simply propagates the same gradient without considering discretization errors between inputs and outputs of the discretizer. In this paper, we propose an element-wise gradient scaling (EWGS), a simple yet effective alternative to the STE, training a quantized network better than the STE in terms of stability and accuracy. Given a gradient of the discretizer output, EWGS adaptively scales up or down each gradient element, and uses the scaled gradient as the one for the discretizer input to train quantized networks via backpropagation. The scaling is performed depending on both the sign of each gradient element and an error between the continuous input and discrete output of the discretizer. We adjust a scaling factor adaptively using Hessian information of a network. We show extensive experimental results on the image classification datasets, including CIFAR-10 and ImageNet, with diverse network architectures under a wide range of bit-width settings, demonstrating the effectiveness of our method.
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021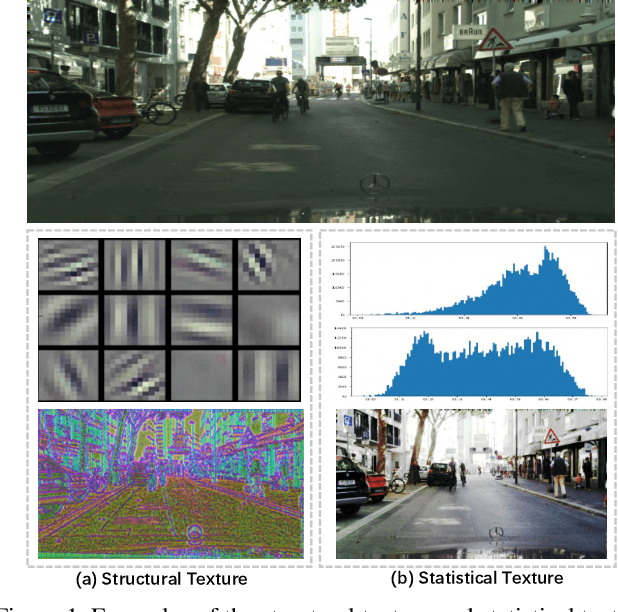
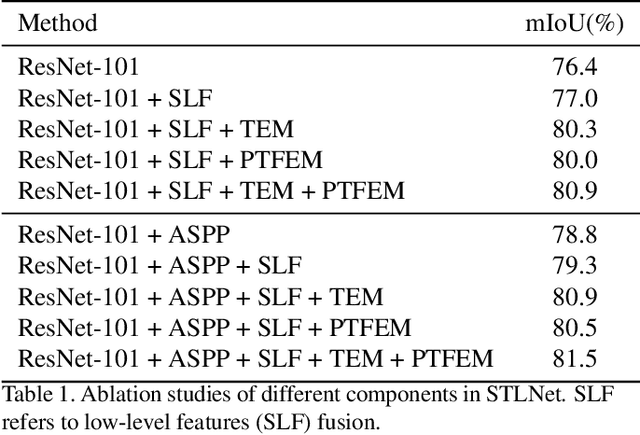
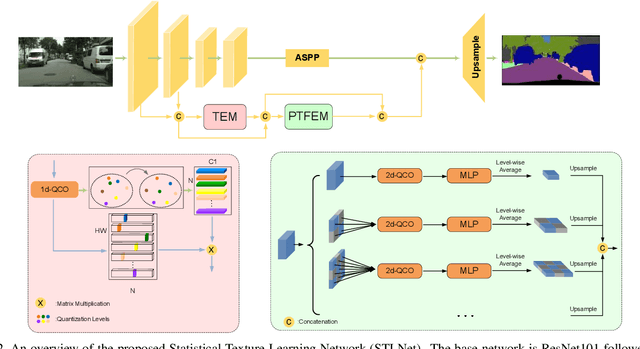

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
DeepN-JPEG: A Deep Neural Network Favorable JPEG-based Image Compression Framework
Mar 14, 2018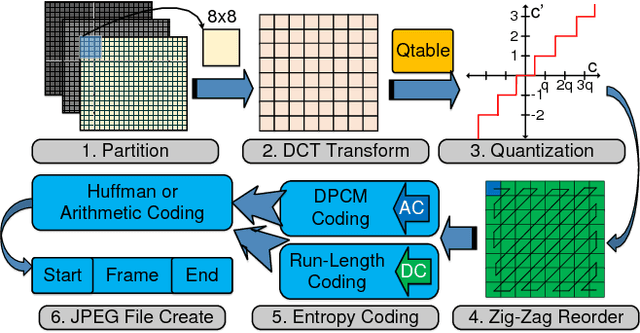
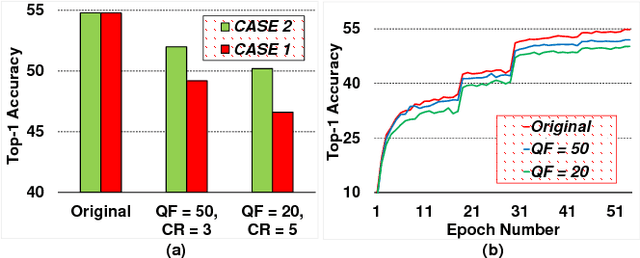
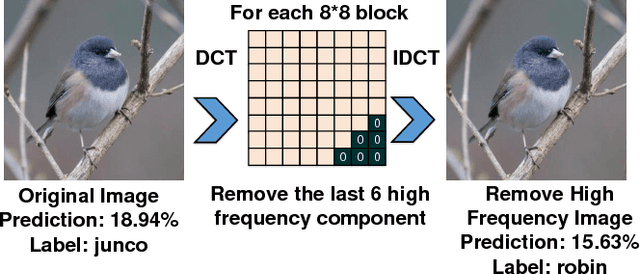
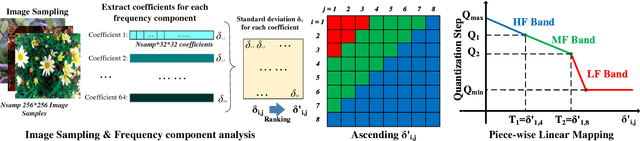
As one of most fascinating machine learning techniques, deep neural network (DNN) has demonstrated excellent performance in various intelligent tasks such as image classification. DNN achieves such performance, to a large extent, by performing expensive training over huge volumes of training data. To reduce the data storage and transfer overhead in smart resource-limited Internet-of-Thing (IoT) systems, effective data compression is a "must-have" feature before transferring real-time produced dataset for training or classification. While there have been many well-known image compression approaches (such as JPEG), we for the first time find that a human-visual based image compression approach such as JPEG compression is not an optimized solution for DNN systems, especially with high compression ratios. To this end, we develop an image compression framework tailored for DNN applications, named "DeepN-JPEG", to embrace the nature of deep cascaded information process mechanism of DNN architecture. Extensive experiments, based on "ImageNet" dataset with various state-of-the-art DNNs, show that "DeepN-JPEG" can achieve ~3.5x higher compression rate over the popular JPEG solution while maintaining the same accuracy level for image recognition, demonstrating its great potential of storage and power efficiency in DNN-based smart IoT system design.
LogoDet-3K: A Large-Scale Image Dataset for Logo Detection
Aug 12, 2020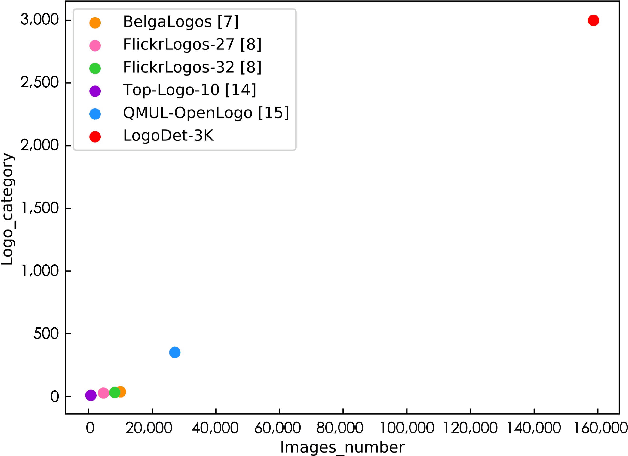
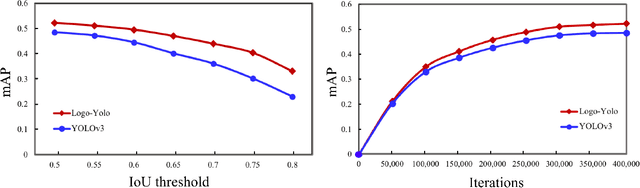


Logo detection has been gaining considerable attention because of its wide range of applications in the multimedia field, such as copyright infringement detection, brand visibility monitoring, and product brand management on social media. In this paper, we introduce LogoDet-3K, the largest logo detection dataset with full annotation, which has 3,000 logo categories, about 200,000 manually annotated logo objects and 158,652 images. LogoDet-3K creates a more challenging benchmark for logo detection, for its higher comprehensive coverage and wider variety in both logo categories and annotated objects compared with existing datasets. We describe the collection and annotation process of our dataset, analyze its scale and diversity in comparison to other datasets for logo detection. We further propose a strong baseline method Logo-Yolo, which incorporates Focal loss and CIoU loss into the state-of-the-art YOLOv3 framework for large-scale logo detection. Logo-Yolo can solve the problems of multi-scale objects, logo sample imbalance and inconsistent bounding-box regression. It obtains about 4% improvement on the average performance compared with YOLOv3, and greater improvements compared with reported several deep detection models on LogoDet-3K. The evaluations on other three existing datasets further verify the effectiveness of our method, and demonstrate better generalization ability of LogoDet-3K on logo detection and retrieval tasks. The LogoDet-3K dataset is used to promote large-scale logo-related research and it can be found at https://github.com/Wangjing1551/LogoDet-3K-Dataset.
Generic 3D Convolutional Fusion for image restoration
Jul 26, 2016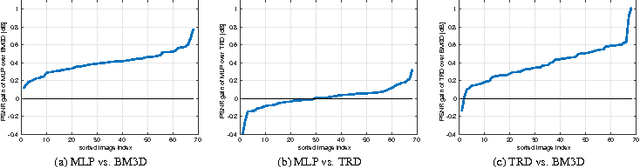
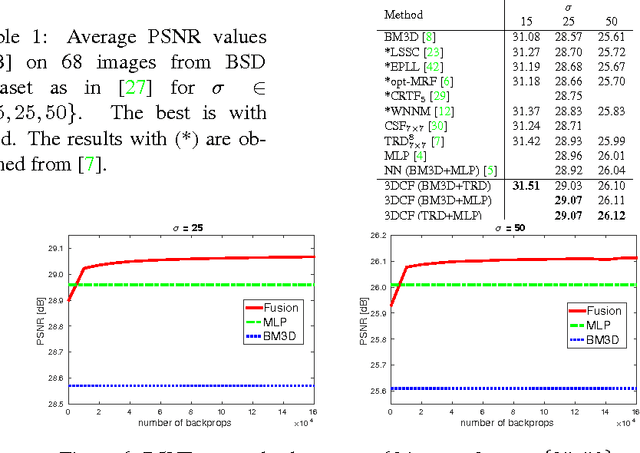

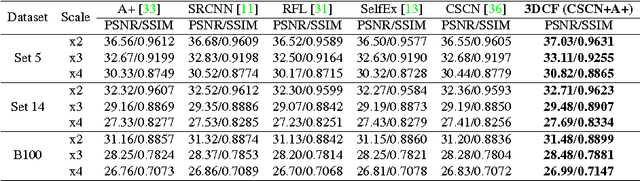
Also recently, exciting strides forward have been made in the area of image restoration, particularly for image denoising and single image super-resolution. Deep learning techniques contributed to this significantly. The top methods differ in their formulations and assumptions, so even if their average performance may be similar, some work better on certain image types and image regions than others. This complementarity motivated us to propose a novel 3D convolutional fusion (3DCF) method. Unlike other methods adapted to different tasks, our method uses the exact same convolutional network architecture to address both image denois- ing and single image super-resolution. As a result, our 3DCF method achieves substantial improvements (0.1dB-0.4dB PSNR) over the state-of-the-art methods that it fuses, and this on standard benchmarks for both tasks. At the same time, the method still is computationally efficient.
Tracking Pedestrian Heads in Dense Crowd
Mar 24, 2021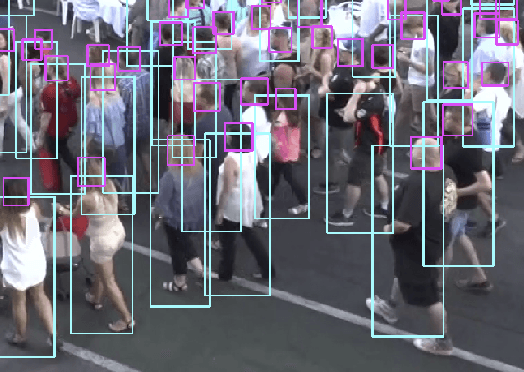
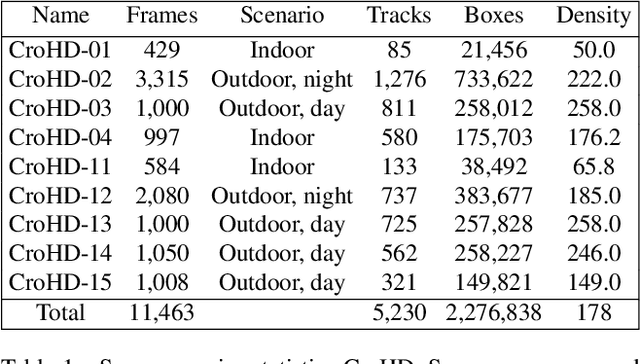

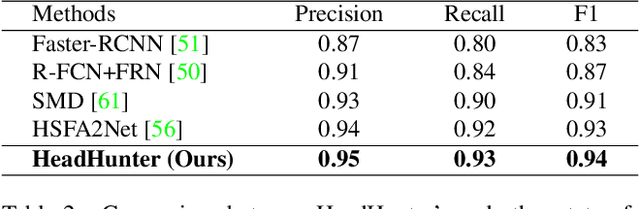
Tracking humans in crowded video sequences is an important constituent of visual scene understanding. Increasing crowd density challenges visibility of humans, limiting the scalability of existing pedestrian trackers to higher crowd densities. For that reason, we propose to revitalize head tracking with Crowd of Heads Dataset (CroHD), consisting of 9 sequences of 11,463 frames with over 2,276,838 heads and 5,230 tracks annotated in diverse scenes. For evaluation, we proposed a new metric, IDEucl, to measure an algorithm's efficacy in preserving a unique identity for the longest stretch in image coordinate space, thus building a correspondence between pedestrian crowd motion and the performance of a tracking algorithm. Moreover, we also propose a new head detector, HeadHunter, which is designed for small head detection in crowded scenes. We extend HeadHunter with a Particle Filter and a color histogram based re-identification module for head tracking. To establish this as a strong baseline, we compare our tracker with existing state-of-the-art pedestrian trackers on CroHD and demonstrate superiority, especially in identity preserving tracking metrics. With a light-weight head detector and a tracker which is efficient at identity preservation, we believe our contributions will serve useful in advancement of pedestrian tracking in dense crowds.
Tablext: A Combined Neural Network And Heuristic Based Table Extractor
Apr 22, 2021
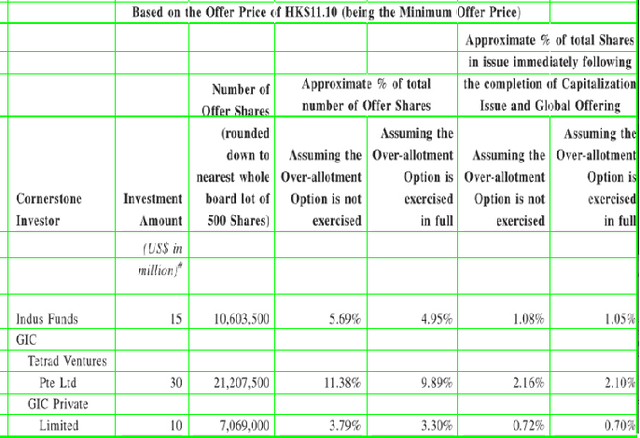
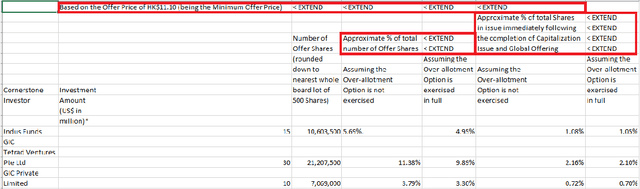
A significant portion of the data available today is found within tables. Therefore, it is necessary to use automated table extraction to obtain thorough results when data-mining. Today's popular state-of-the-art methods for table extraction struggle to adequately extract tables with machine-readable text and structural data. To make matters worse, many tables do not have machine-readable data, such as tables saved as images, making most extraction methods completely ineffective. In order to address these issues, a novel, general format table extractor tool, Tablext, is proposed. This tool uses a combination of computer vision techniques and machine learning methods to efficiently and effectively identify and extract data from tables. Tablext begins by using a custom Convolutional Neural Network (CNN) to identify and separate all potential tables. The identification process is optimized by combining the custom CNN with the YOLO object detection network. Then, the high-level structure of each table is identified with computer vision methods. This high-level, structural meta-data is used by another CNN to identify exact cell locations. As a final step, Optical Characters Recognition (OCR) is performed on every individual cell to extract their content without needing machine-readable text. This multi-stage algorithm allows for the neural networks to focus on completing complex tasks, while letting image processing methods efficiently complete the simpler ones. This leads to the proposed approach to be general-purpose enough to handle a large batch of tables regardless of their internal encodings or their layout complexity. Additionally, it becomes accurate enough to outperform competing state-of-the-art table extractors on the ICDAR 2013 table dataset.
Real-time Deep Pose Estimation with Geodesic Loss for Image-to-Template Rigid Registration
Aug 18, 2018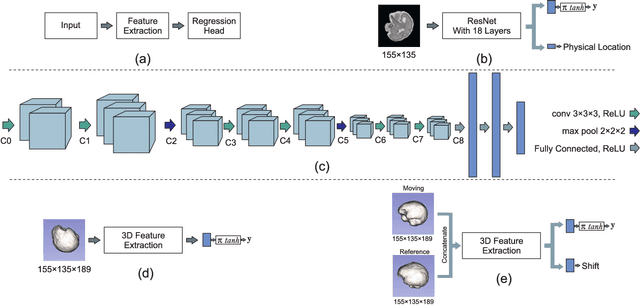
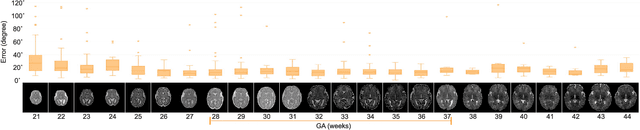
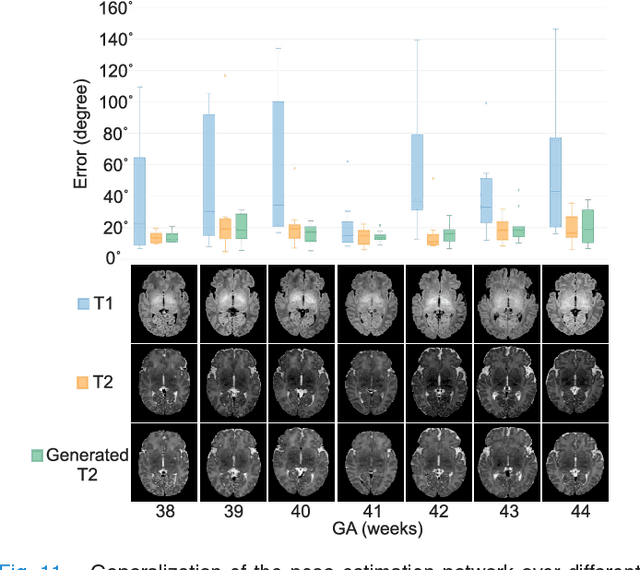
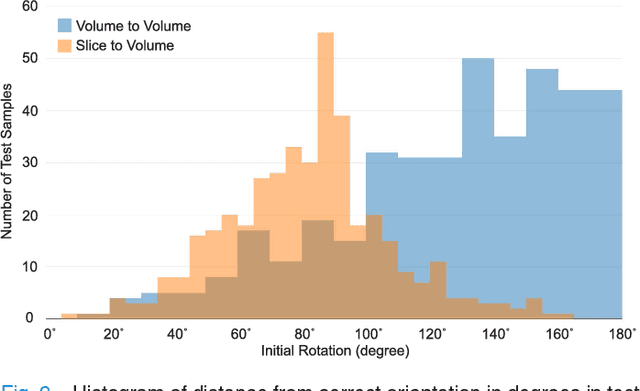
With an aim to increase the capture range and accelerate the performance of state-of-the-art inter-subject and subject-to-template 3D registration, we propose deep learning-based methods that are trained to find the 3D position of arbitrarily oriented subjects or anatomy based on slices or volumes of medical images. For this, we propose regression CNNs that learn to predict the angle-axis representation of 3D rotations and translations using image features. We use and compare mean square error and geodesic loss to train regression CNNs for 3D pose estimation used in two different scenarios: slice-to-volume registration and volume-to-volume registration. Our results show that in such registration applications that are amendable to learning, the proposed deep learning methods with geodesic loss minimization can achieve accurate results with a wide capture range in real-time (<100ms). We also tested the generalization capability of the trained CNNs on an expanded age range and on images of newborn subjects with similar and different MR image contrasts. We trained our models on T2-weighted fetal brain MRI scans and used them to predict the 3D pose of newborn brains based on T1-weighted MRI scans. We showed that the trained models generalized well for the new domain when we performed image contrast transfer through a conditional generative adversarial network. This indicates that the domain of application of the trained deep regression CNNs can be further expanded to image modalities and contrasts other than those used in training. A combination of our proposed methods with accelerated optimization-based registration algorithms can dramatically enhance the performance of automatic imaging devices and image processing methods of the future.
Vision Transformers for Dense Prediction
Mar 24, 2021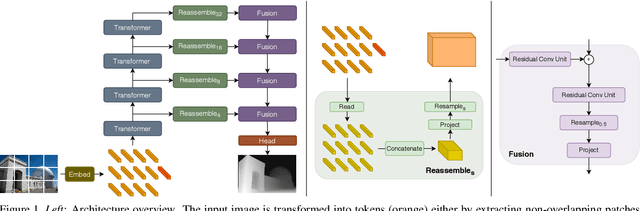
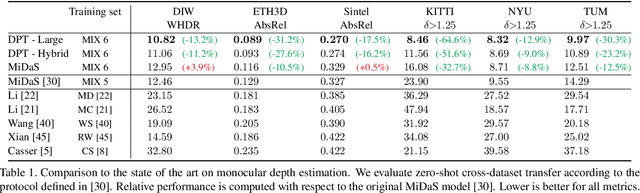
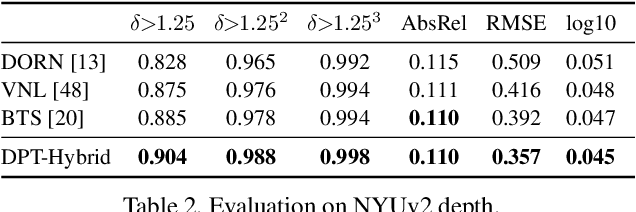

We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.
Deep Convolutional Neural Networks for Breast Cancer Histology Image Analysis
Apr 03, 2018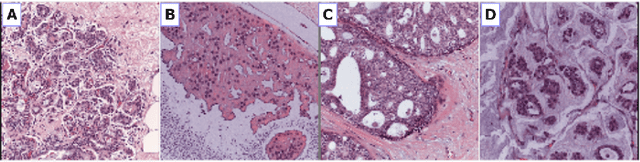
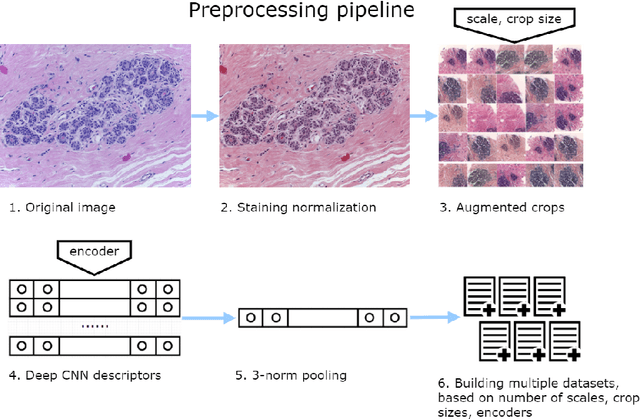
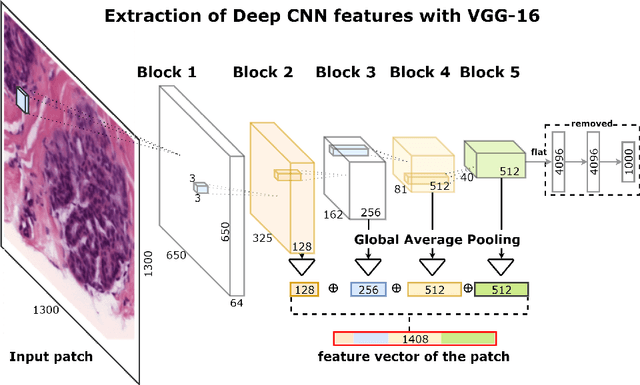
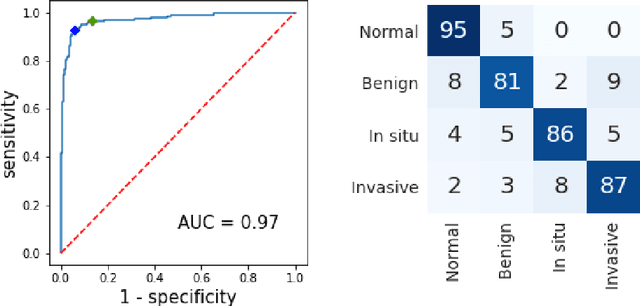
Breast cancer is one of the main causes of cancer death worldwide. Early diagnostics significantly increases the chances of correct treatment and survival, but this process is tedious and often leads to a disagreement between pathologists. Computer-aided diagnosis systems showed potential for improving the diagnostic accuracy. In this work, we develop the computational approach based on deep convolution neural networks for breast cancer histology image classification. Hematoxylin and eosin stained breast histology microscopy image dataset is provided as a part of the ICIAR 2018 Grand Challenge on Breast Cancer Histology Images. Our approach utilizes several deep neural network architectures and gradient boosted trees classifier. For 4-class classification task, we report 87.2% accuracy. For 2-class classification task to detect carcinomas we report 93.8% accuracy, AUC 97.3%, and sensitivity/specificity 96.5/88.0% at the high-sensitivity operating point. To our knowledge, this approach outperforms other common methods in automated histopathological image classification. The source code for our approach is made publicly available at https://github.com/alexander-rakhlin/ICIAR2018