 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Single Image Rain Removal via a Deep Decomposition-Composition Network
Apr 08, 2018
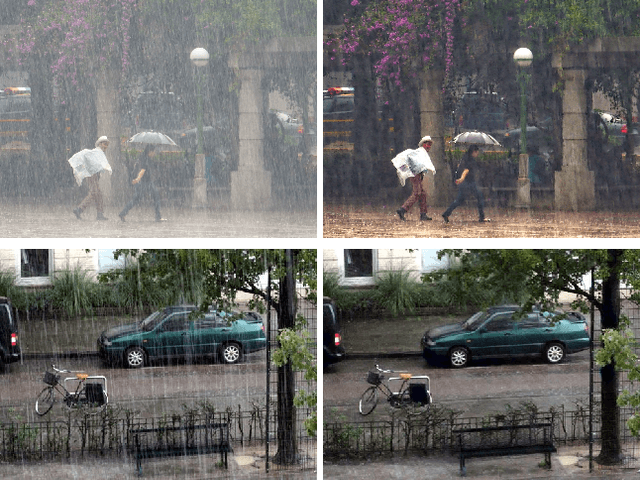
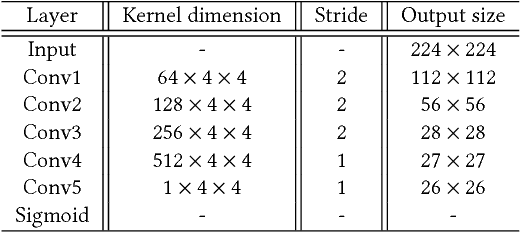
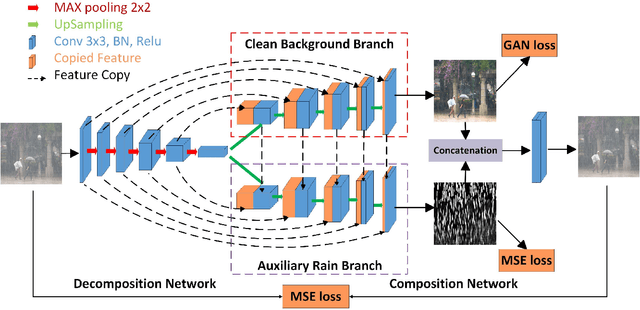
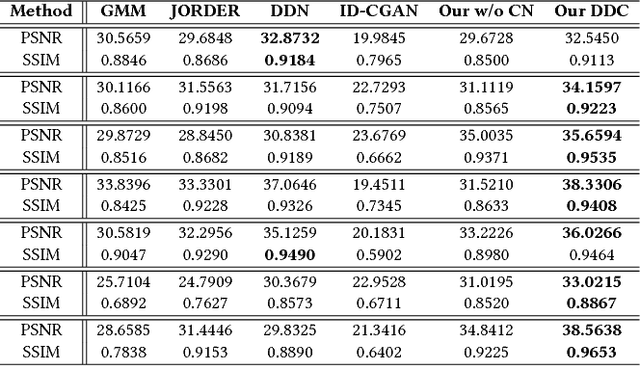
Rain effect in images typically is annoying for many multimedia and computer vision tasks. For removing rain effect from a single image, deep leaning techniques have been attracting considerable attentions. This paper designs a novel multi-task leaning architecture in an end-to-end manner to reduce the mapping range from input to output and boost the performance. Concretely, a decomposition net is built to split rain images into clean background and rain layers. Different from previous architectures, our model consists of, besides a component representing the desired clean image, an extra component for the rain layer. During the training phase, we further employ a composition structure to reproduce the input by the separated clean image and rain information for improving the quality of decomposition. Experimental results on both synthetic and real images are conducted to reveal the high-quality recovery by our design, and show its superiority over other state-of-the-art methods. Furthermore, our design is also applicable to other layer decomposition tasks like dust removal. More importantly, our method only requires about 50ms, significantly faster than the competitors, to process a testing image in VGA resolution on a GTX 1080 GPU, making it attractive for practical use.
Amortised MAP Inference for Image Super-resolution
Feb 21, 2017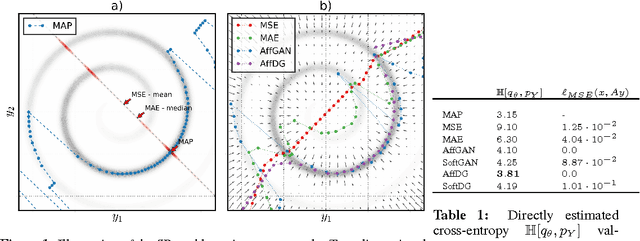
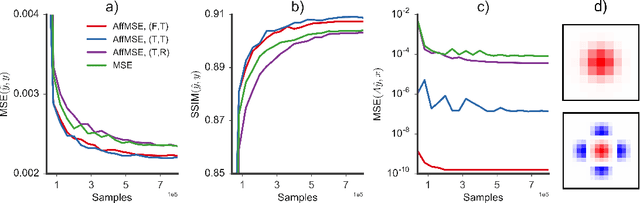


Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high-resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss. However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Furthermore, MAP inference is often performed via optimisation-based iterative algorithms which don't compare well with the efficiency of neural-network-based alternatives. Here we introduce new methods for amortised MAP inference whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
Reinforcement learning using Deep Q Networks and Q learning accurately localizes brain tumors on MRI with very small training sets
Oct 21, 2020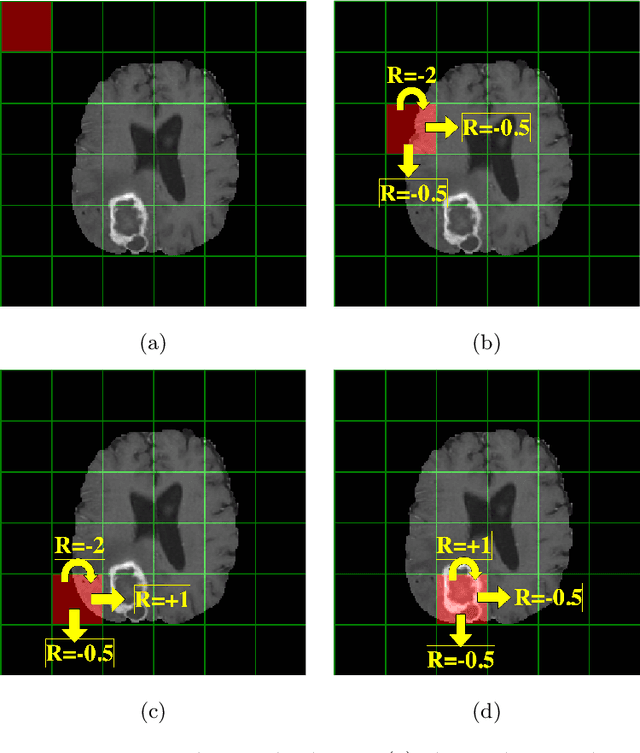
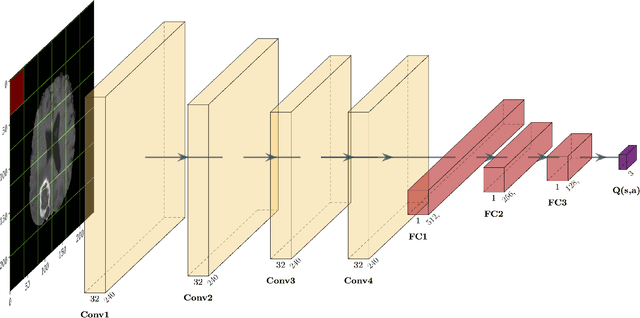
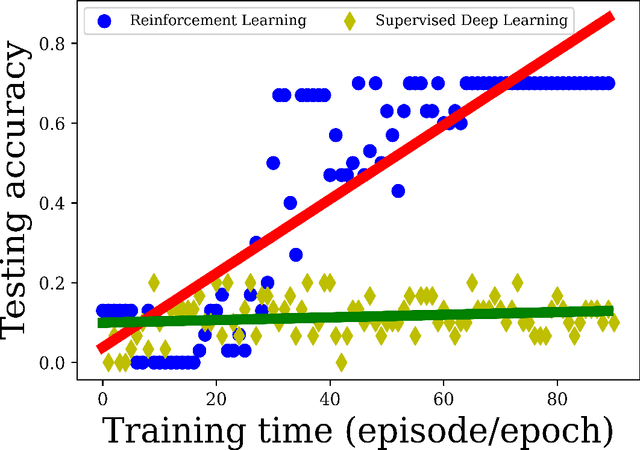
Purpose Supervised deep learning in radiology suffers from notorious inherent limitations: 1) It requires large, hand-annotated data sets, 2) It is non-generalizable, and 3) It lacks explainability and intuition. We have recently proposed Reinforcement Learning to address all threes. However, we applied it to images with radiologist eye tracking points, which limits the state-action space. Here we generalize the Deep-Q Learning to a gridworld-based environment, so that only the images and image masks are required. Materials and Methods We trained a Deep Q network on 30 two-dimensional image slices from the BraTS brain tumor database. Each image contained one lesion. We then tested the trained Deep Q network on a separate set of 30 testing set images. For comparison, we also trained and tested a keypoint detection supervised deep learning network for the same set of training / testing images. Results Whereas the supervised approach quickly overfit the training data, and predicably performed poorly on the testing set (11\% accuracy), the Deep-Q learning approach showed progressive improved generalizability to the testing set over training time, reaching 70\% accuracy. Conclusion We have shown a proof-of-principle application of reinforcement learning to radiological images, here using 2D contrast-enhanced MRI brain images with the goal of localizing brain tumors. This represents a generalization of recent work to a gridworld setting, naturally suitable for analyzing medical images.
Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing
May 14, 2018

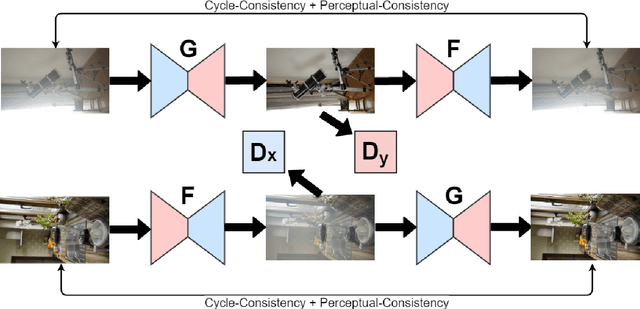
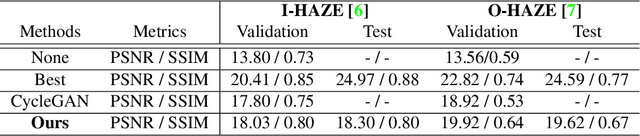
In this paper, we present an end-to-end network, called Cycle-Dehaze, for single image dehazing problem, which does not require pairs of hazy and corresponding ground truth images for training. That is, we train the network by feeding clean and hazy images in an unpaired manner. Moreover, the proposed approach does not rely on estimation of the atmospheric scattering model parameters. Our method enhances CycleGAN formulation by combining cycle-consistency and perceptual losses in order to improve the quality of textural information recovery and generate visually better haze-free images. Typically, deep learning models for dehazing take low resolution images as input and produce low resolution outputs. However, in the NTIRE 2018 challenge on single image dehazing, high resolution images were provided. Therefore, we apply bicubic downscaling. After obtaining low-resolution outputs from the network, we utilize the Laplacian pyramid to upscale the output images to the original resolution. We conduct experiments on NYU-Depth, I-HAZE, and O-HAZE datasets. Extensive experiments demonstrate that the proposed approach improves CycleGAN method both quantitatively and qualitatively.
Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
Jan 31, 2021
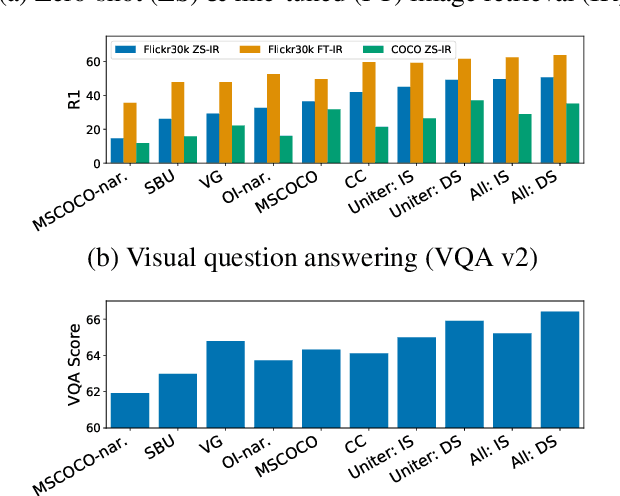
Recently multimodal transformer models have gained popularity because their performance on language and vision tasks suggest they learn rich visual-linguistic representations. Focusing on zero-shot image retrieval tasks, we study three important factors which can impact the quality of learned representations: pretraining data, the attention mechanism, and loss functions. By pretraining models on six datasets, we observe that dataset noise and language similarity to our downstream task are important indicators of model performance. Through architectural analysis, we learn that models with a multimodal attention mechanism can outperform deeper models with modality specific attention mechanisms. Finally, we show that successful contrastive losses used in the self-supervised learning literature do not yield similar performance gains when used in multimodal transformers
Gaussian kernel smoothing
Jul 19, 2020
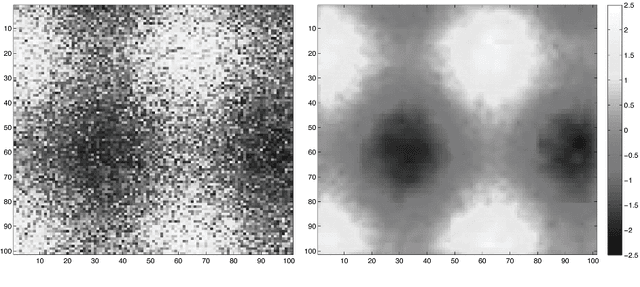
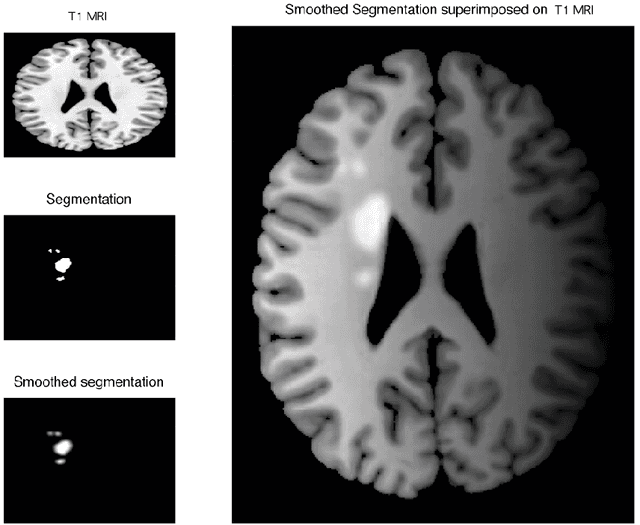
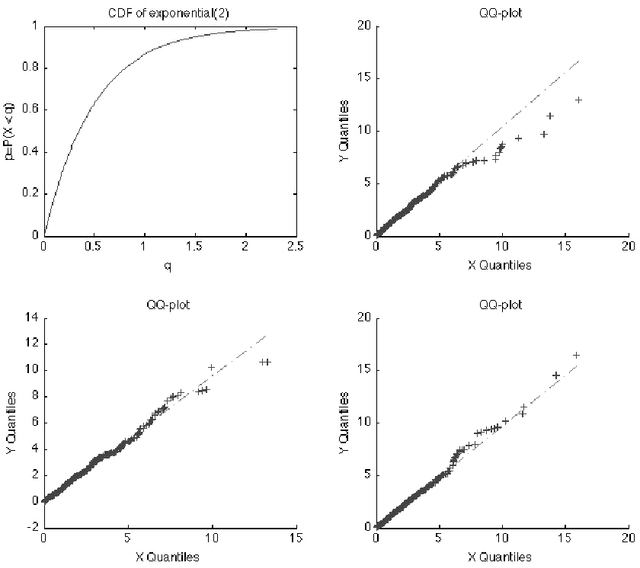
Image acquisition and segmentation are likely to introduce noise. Further image processing such as image registration and parameterization can introduce additional noise. It is thus imperative to reduce noise measurements and boost signal. In order to increase the signal-to-noise ratio (SNR) and smoothness of data required for the subsequent random field theory based statistical inference, some type of smoothing is necessary. Among many image smoothing methods, Gaussian kernel smoothing has emerged as a de facto smoothing technique among brain imaging researchers due to its simplicity in numerical implementation. Gaussian kernel smoothing also increases statistical sensitivity and statistical power as well as Gausianness. Gaussian kernel smoothing can be viewed as weighted averaging of voxel values. Then from the central limit theorem, the weighted average should be more Gaussian.
A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement
Nov 02, 2017
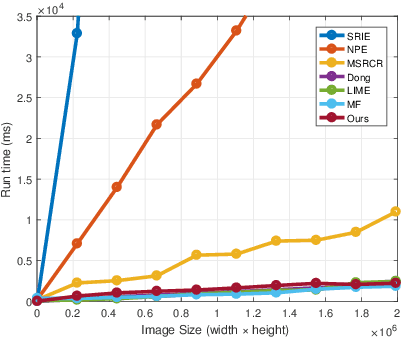

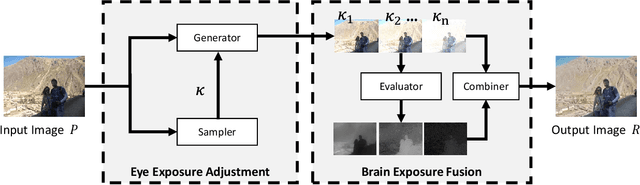
Low-light images are not conducive to human observation and computer vision algorithms due to their low visibility. Although many image enhancement techniques have been proposed to solve this problem, existing methods inevitably introduce contrast under- and over-enhancement. Inspired by human visual system, we design a multi-exposure fusion framework for low-light image enhancement. Based on the framework, we propose a dual-exposure fusion algorithm to provide an accurate contrast and lightness enhancement. Specifically, we first design the weight matrix for image fusion using illumination estimation techniques. Then we introduce our camera response model to synthesize multi-exposure images. Next, we find the best exposure ratio so that the synthetic image is well-exposed in the regions where the original image is under-exposed. Finally, the enhanced result is obtained by fusing the input image and the synthetic image according to the weight matrix. Experiments show that our method can obtain results with less contrast and lightness distortion compared to that of several state-of-the-art methods.
You Only Look One-level Feature
Mar 17, 2021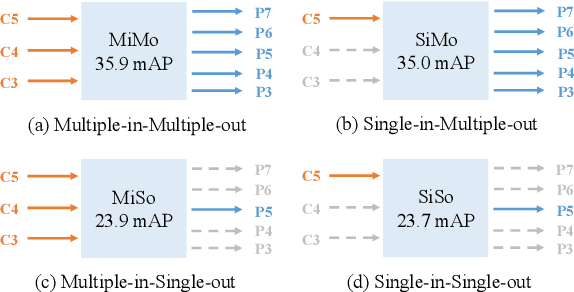
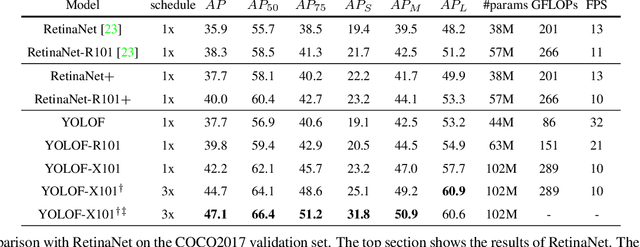

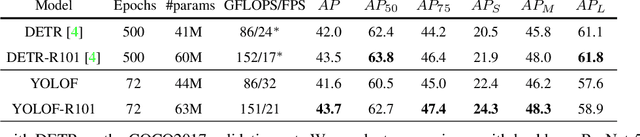
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being $2.5\times$ faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with $7\times$ less training epochs. With an image size of $608\times608$, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is $13\%$ faster than YOLOv4. Code is available at \url{https://github.com/megvii-model/YOLOF}.
Entanglement Entropy of Target Functions for Image Classification and Convolutional Neural Network
Oct 16, 2017
The success of deep convolutional neural network (CNN) in computer vision especially image classification problems requests a new information theory for function of image, instead of image itself. In this article, after establishing a deep mathematical connection between image classification problem and quantum spin model, we propose to use entanglement entropy, a generalization of classical Boltzmann-Shannon entropy, as a powerful tool to characterize the information needed for representation of general function of image. We prove that there is a sub-volume-law bound for entanglement entropy of target functions of reasonable image classification problems. Therefore target functions of image classification only occupy a small subspace of the whole Hilbert space. As a result, a neural network with polynomial number of parameters is efficient for representation of such target functions of image. The concept of entanglement entropy can also be useful to characterize the expressive power of different neural networks. For example, we show that to maintain the same expressive power, number of channels $D$ in a convolutional neural network should scale with the number of convolution layers $n_c$ as $D\sim D_0^{\frac{1}{n_c}}$. Therefore, deeper CNN with large $n_c$ is more efficient than shallow ones.
Whole-Slide Image Focus Quality: Automatic Assessment and Impact on AI Cancer Detection
Jan 15, 2019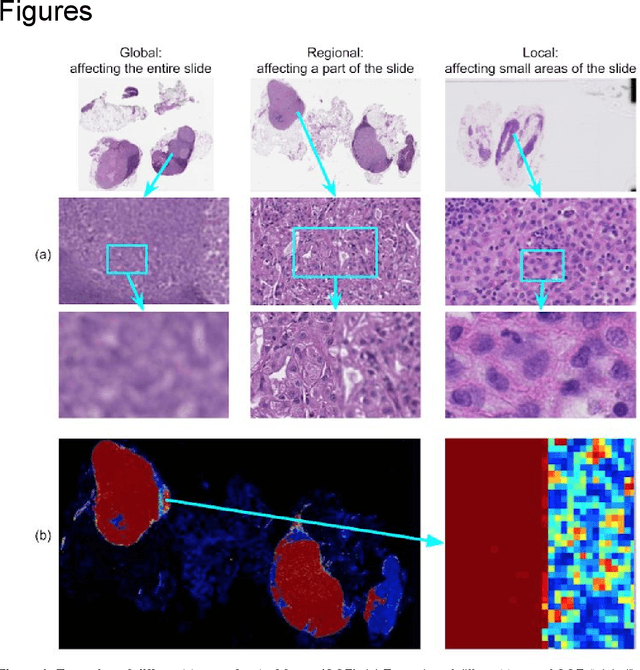
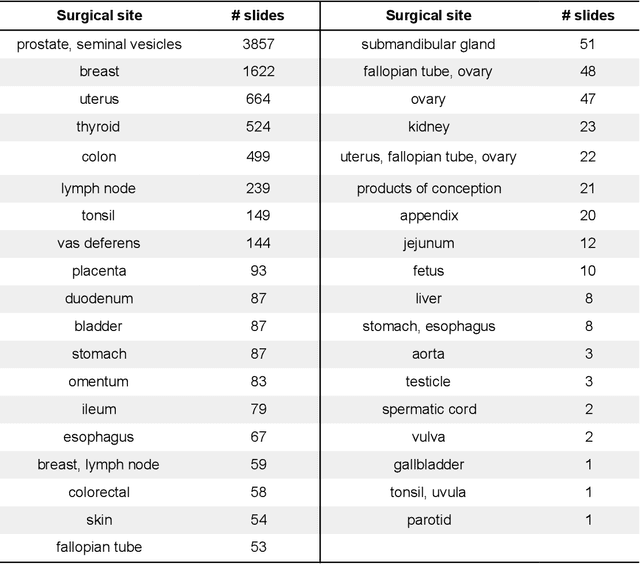
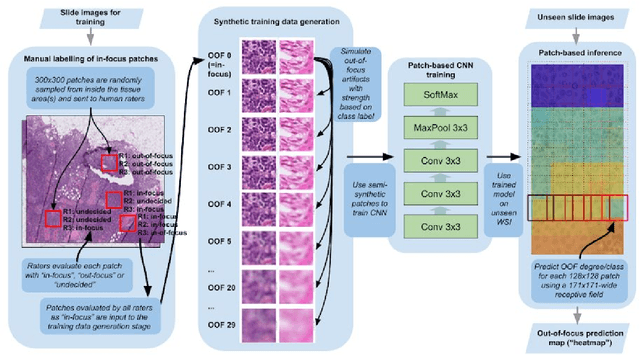
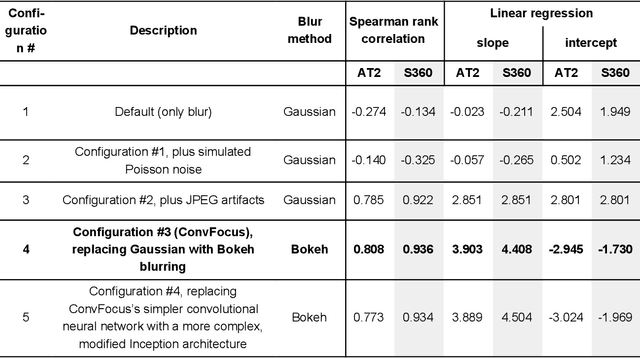
Digital pathology enables remote access or consults and powerful image analysis algorithms. However, the slide digitization process can create artifacts such as out-of-focus (OOF). OOF is often only detected upon careful review, potentially causing rescanning and workflow delays. Although scan-time operator screening for whole-slide OOF is feasible, manual screening for OOF affecting only parts of a slide is impractical. We developed a convolutional neural network (ConvFocus) to exhaustively localize and quantify the severity of OOF regions on digitized slides. ConvFocus was developed using our refined semi-synthetic OOF data generation process, and evaluated using real whole-slide images spanning 3 different tissue types and 3 different stain types that were digitized by two different scanners. ConvFocus's predictions were compared with pathologist-annotated focus quality grades across 514 distinct regions representing 37,700 35x35{\mu}m image patches, and 21 digitized "z-stack" whole-slide images that contain known OOF patterns. When compared to pathologist-graded focus quality, ConvFocus achieved Spearman rank coefficients of 0.81 and 0.94 on two scanners, and reproduced the expected OOF patterns from z-stack scanning. We also evaluated the impact of OOF on the accuracy of a state-of-the-art metastatic breast cancer detector and saw a consistent decrease in performance with increasing OOF. Comprehensive whole-slide OOF categorization could enable rescans prior to pathologist review, potentially reducing the impact of digitization focus issues on the clinical workflow. We show that the algorithm trained on our semi-synthetic OOF data generalizes well to real OOF regions across tissue types, stains, and scanners. Finally, quantitative OOF maps can flag regions that might otherwise be misclassified by image analysis algorithms, preventing OOF-induced errors.