 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Light Field Rendering with Deep Anti-Aliasing Neural Network
Apr 14, 2021
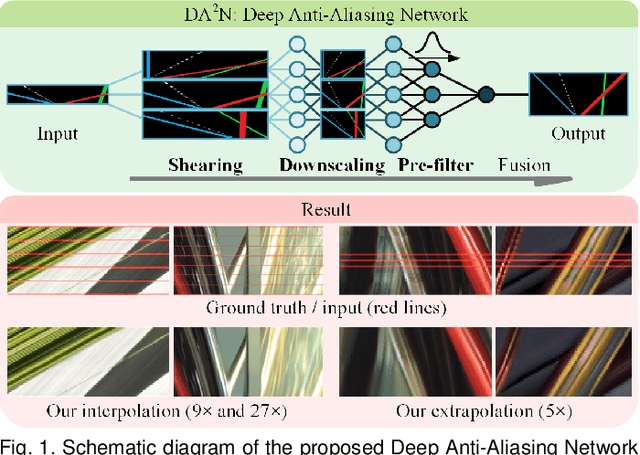

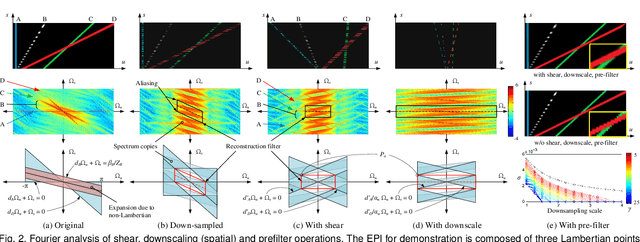
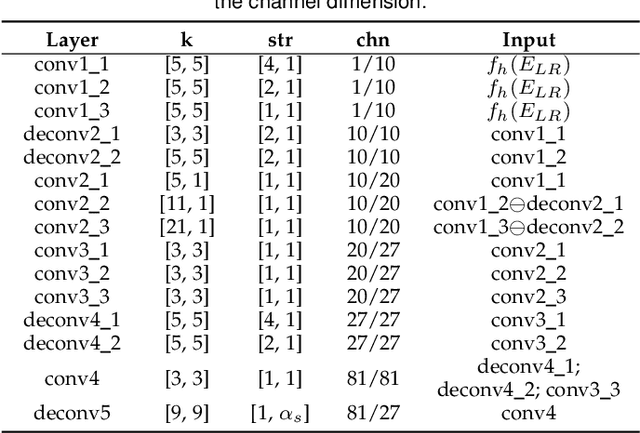
The light field (LF) reconstruction is mainly confronted with two challenges, large disparity and the non-Lambertian effect. Typical approaches either address the large disparity challenge using depth estimation followed by view synthesis or eschew explicit depth information to enable non-Lambertian rendering, but rarely solve both challenges in a unified framework. In this paper, we revisit the classic LF rendering framework to address both challenges by incorporating it with advanced deep learning techniques. First, we analytically show that the essential issue behind the large disparity and non-Lambertian challenges is the aliasing problem. Classic LF rendering approaches typically mitigate the aliasing with a reconstruction filter in the Fourier domain, which is, however, intractable to implement within a deep learning pipeline. Instead, we introduce an alternative framework to perform anti-aliasing reconstruction in the image domain and analytically show comparable efficacy on the aliasing issue. To explore the full potential, we then embed the anti-aliasing framework into a deep neural network through the design of an integrated architecture and trainable parameters. The network is trained through end-to-end optimization using a peculiar training set, including regular LFs and unstructured LFs. The proposed deep learning pipeline shows a substantial superiority in solving both the large disparity and the non-Lambertian challenges compared with other state-of-the-art approaches. In addition to the view interpolation for an LF, we also show that the proposed pipeline also benefits light field view extrapolation.
* 14 pages, 12 figures. Accepted by IEEE TPAMI
Image Pre-processing on NumtaDB for Bengali Handwritten Digit Recognition
Aug 18, 2020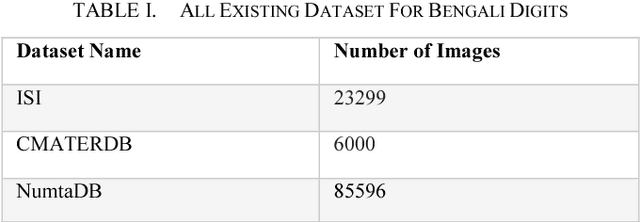
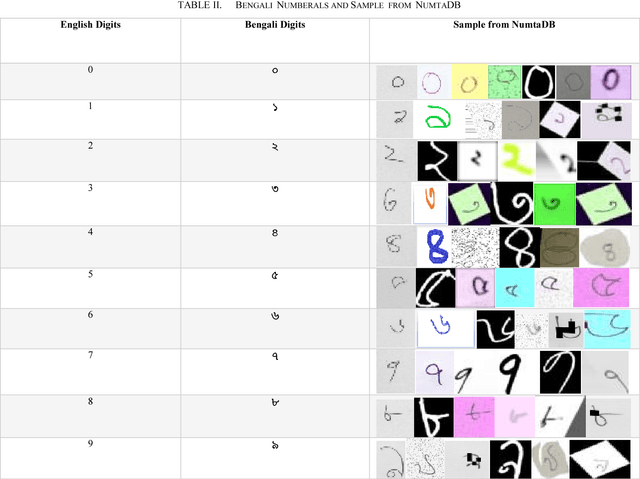
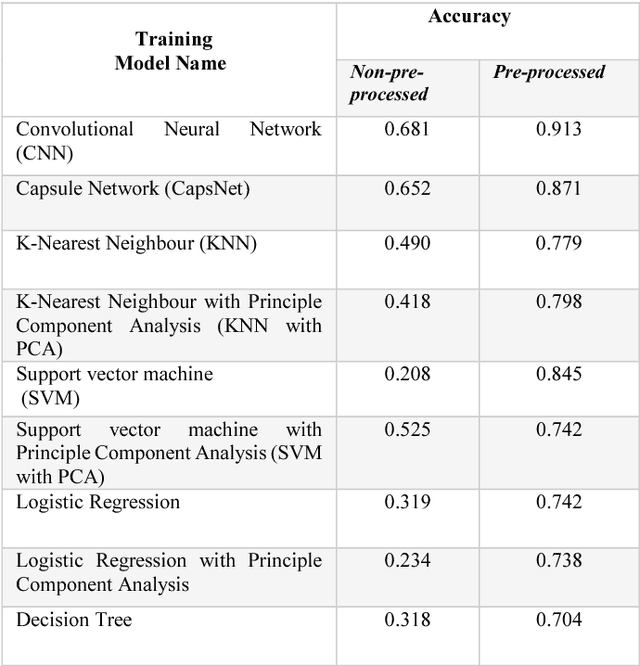
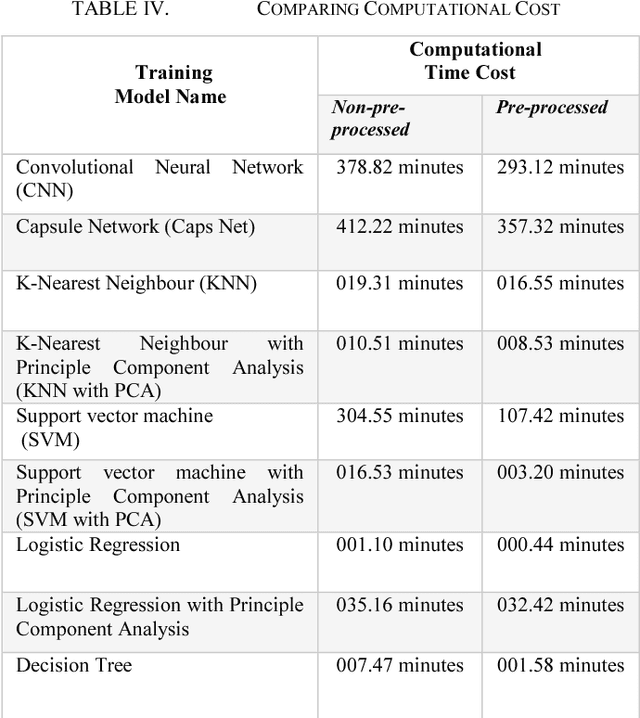
NumtaDB is by far the largest data-set collection for handwritten digits in Bengali. This is a diverse dataset containing more than 85000 images. But this diversity also makes this dataset very difficult to work with. The goal of this paper is to find the benchmark for pre-processed images which gives good accuracy on any machine learning models. The reason being, there are no available pre-processed data for Bengali digit recognition to work with like the English digits for MNIST.
* 5 pages, 8 figures and 4 tables
An optical neural network using less than 1 photon per multiplication
Apr 27, 2021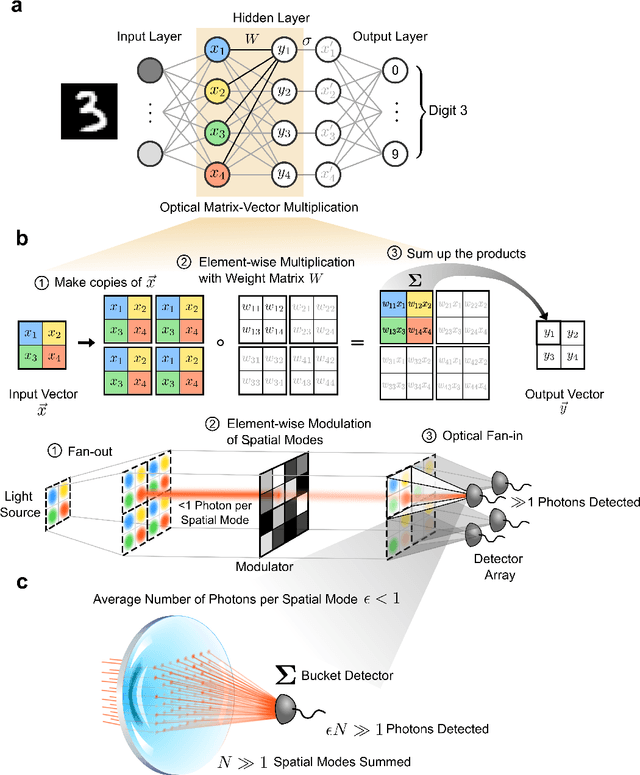
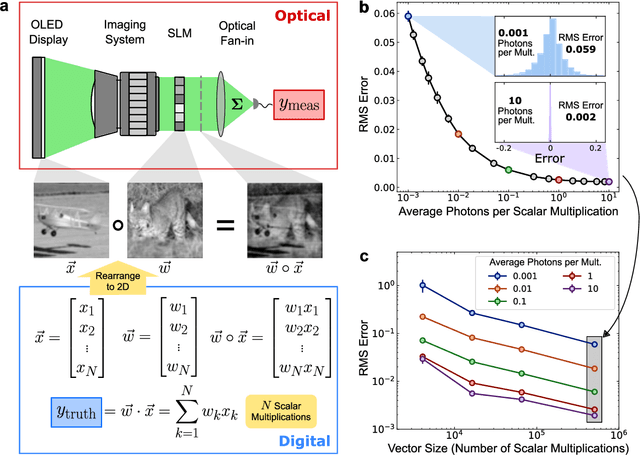
Deep learning has rapidly become a widespread tool in both scientific and commercial endeavors. Milestones of deep learning exceeding human performance have been achieved for a growing number of tasks over the past several years, across areas as diverse as game-playing, natural-language translation, and medical-image analysis. However, continued progress is increasingly hampered by the high energy costs associated with training and running deep neural networks on electronic processors. Optical neural networks have attracted attention as an alternative physical platform for deep learning, as it has been theoretically predicted that they can fundamentally achieve higher energy efficiency than neural networks deployed on conventional digital computers. Here, we experimentally demonstrate an optical neural network achieving 99% accuracy on handwritten-digit classification using ~3.2 detected photons per weight multiplication and ~90% accuracy using ~0.64 photons (~$2.4 \times 10^{-19}$ J of optical energy) per weight multiplication. This performance was achieved using a custom free-space optical processor that executes matrix-vector multiplications in a massively parallel fashion, with up to ~0.5 million scalar (weight) multiplications performed at the same time. Using commercially available optical components and standard neural-network training methods, we demonstrated that optical neural networks can operate near the standard quantum limit with extremely low optical powers and still achieve high accuracy. Our results provide a proof-of-principle for low-optical-power operation, and with careful system design including the surrounding electronics used for data storage and control, open up a path to realizing optical processors that require only $10^{-16}$ J total energy per scalar multiplication -- which is orders of magnitude more efficient than current digital processors.
Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing
May 14, 2018

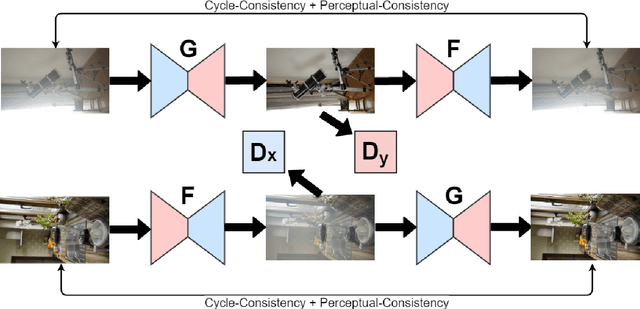
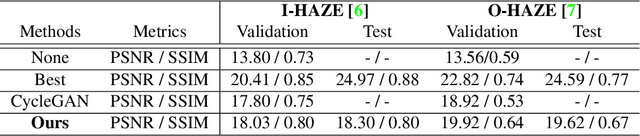
In this paper, we present an end-to-end network, called Cycle-Dehaze, for single image dehazing problem, which does not require pairs of hazy and corresponding ground truth images for training. That is, we train the network by feeding clean and hazy images in an unpaired manner. Moreover, the proposed approach does not rely on estimation of the atmospheric scattering model parameters. Our method enhances CycleGAN formulation by combining cycle-consistency and perceptual losses in order to improve the quality of textural information recovery and generate visually better haze-free images. Typically, deep learning models for dehazing take low resolution images as input and produce low resolution outputs. However, in the NTIRE 2018 challenge on single image dehazing, high resolution images were provided. Therefore, we apply bicubic downscaling. After obtaining low-resolution outputs from the network, we utilize the Laplacian pyramid to upscale the output images to the original resolution. We conduct experiments on NYU-Depth, I-HAZE, and O-HAZE datasets. Extensive experiments demonstrate that the proposed approach improves CycleGAN method both quantitatively and qualitatively.
Boundary-based Image Forgery Detection by Fast Shallow CNN
Feb 03, 2018
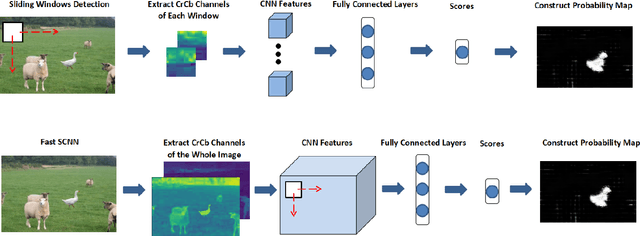


Image forgery detection is the task of detecting and localizing forged parts in tampered images. Previous works mostly focus on high resolution images using traces of resampling features, demosaicing features or sharpness of edges. However, a good detection method should also be applicable to low resolution images because compressed or resized images are common these days. To this end, we propose a Shallow Convolutional Neural Network(SCNN), capable of distinguishing the boundaries of forged regions from original edges in low resolution images. SCNN is designed to utilize the information of chroma and saturation. Based on SCNN, two approaches that are named Sliding Windows Detection (SWD) and Fast SCNN, respectively, are developed to detect and localize image forgery region. In this paper, we substantiate that Fast SCNN can detect drastic change of chroma and saturation. In image forgery detection experiments Our model is evaluated on the CASIA 2.0 dataset. The results show that Fast SCNN performs well on low resolution images and achieves significant improvements over the state-of-the-art.
Pyramidal RoR for Image Classification
Oct 01, 2017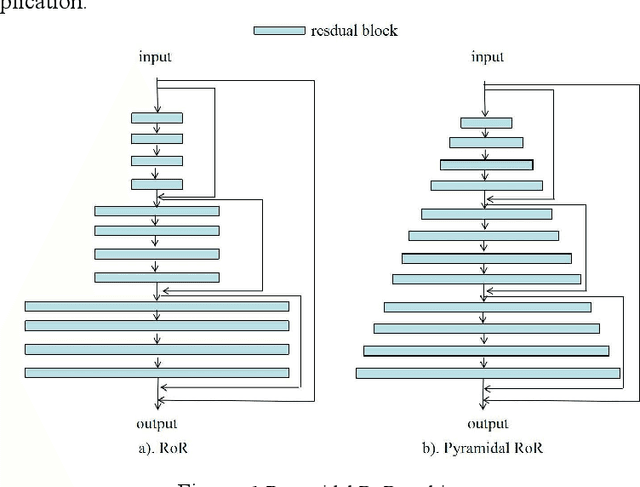

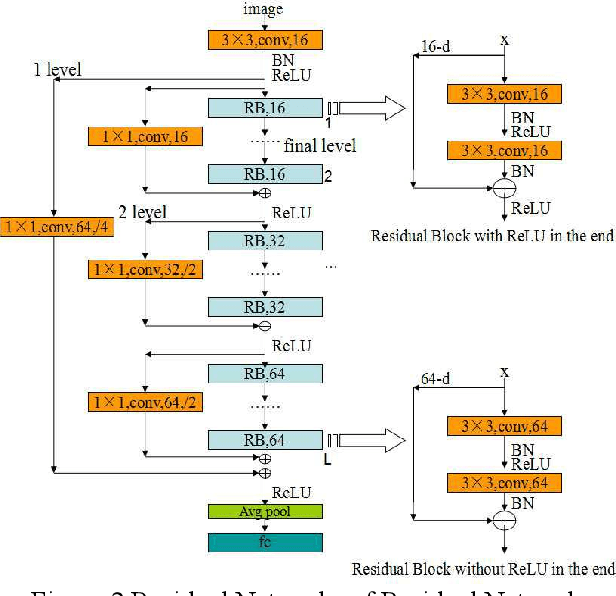

The Residual Networks of Residual Networks (RoR) exhibits excellent performance in the image classification task, but sharply increasing the number of feature map channels makes the characteristic information transmission incoherent, which losses a certain of information related to classification prediction, limiting the classification performance. In this paper, a Pyramidal RoR network model is proposed by analysing the performance characteristics of RoR and combining with the PyramidNet. Firstly, based on RoR, the Pyramidal RoR network model with channels gradually increasing is designed. Secondly, we analysed the effect of different residual block structures on performance, and chosen the residual block structure which best favoured the classification performance. Finally, we add an important principle to further optimize Pyramidal RoR networks, drop-path is used to avoid over-fitting and save training time. In this paper, image classification experiments were performed on CIFAR-10/100 and SVHN datasets, and we achieved the current lowest classification error rates were 2.96%, 16.40% and 1.59%, respectively. Experiments show that the Pyramidal RoR network optimization method can improve the network performance for different data sets and effectively suppress the gradient disappearance problem in DCNN training.
Hierarchical Variational Auto-Encoding for Unsupervised Domain Generalization
Feb 22, 2021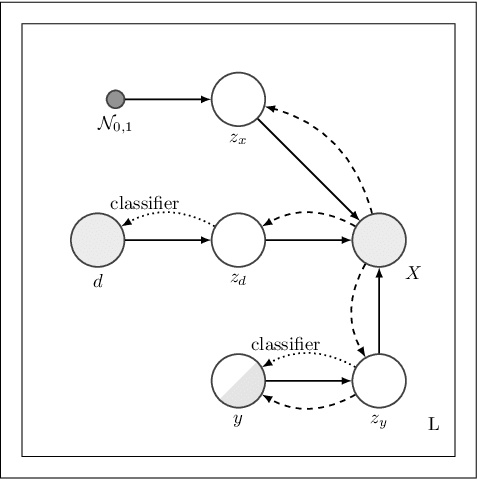

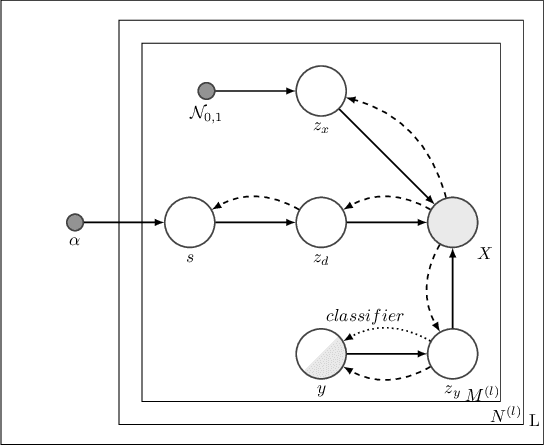

We address the task of domain generalization, where the goal is to train a predictive model based on a number of domains such that it is able to generalize to a new, previously unseen domain. We choose a generative approach within the framework of variational autoencoders and propose an unsupervised algorithm that is able to generalize to new domains without supervision. We show that our method is able to learn representations that disentangle domain-specific information from class-label specific information even in complex settings where an unobserved substructure is present in domains. Our interpretable method outperforms previously proposed generative algorithms for domain generalization and achieves competitive performance compared to state-of-the-art approaches, which are based on complex image-processing steps, on the standard domain generalization benchmark dataset PACS. Additionally, we proposed weak domain supervision which can further increase the performance of our algorithm in the PACS dataset.
Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering
Oct 18, 2020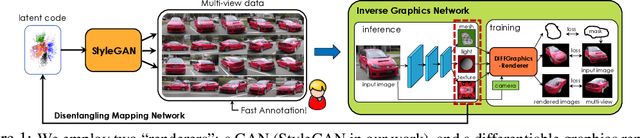



Differentiable rendering has paved the way to training neural networks to perform "inverse graphics" tasks such as predicting 3D geometry from monocular photographs. To train high performing models, most of the current approaches rely on multi-view imagery which are not readily available in practice. Recent Generative Adversarial Networks (GANs) that synthesize images, in contrast, seem to acquire 3D knowledge implicitly during training: object viewpoints can be manipulated by simply manipulating the latent codes. However, these latent codes often lack further physical interpretation and thus GANs cannot easily be inverted to perform explicit 3D reasoning. In this paper, we aim to extract and disentangle 3D knowledge learned by generative models by utilizing differentiable renderers. Key to our approach is to exploit GANs as a multi-view data generator to train an inverse graphics network using an off-the-shelf differentiable renderer, and the trained inverse graphics network as a teacher to disentangle the GAN's latent code into interpretable 3D properties. The entire architecture is trained iteratively using cycle consistency losses. We show that our approach significantly outperforms state-of-the-art inverse graphics networks trained on existing datasets, both quantitatively and via user studies. We further showcase the disentangled GAN as a controllable 3D "neural renderer", complementing traditional graphics renderers.
RAISR: Rapid and Accurate Image Super Resolution
Oct 04, 2016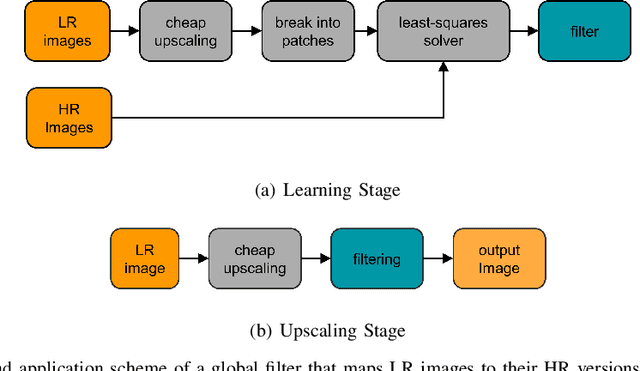
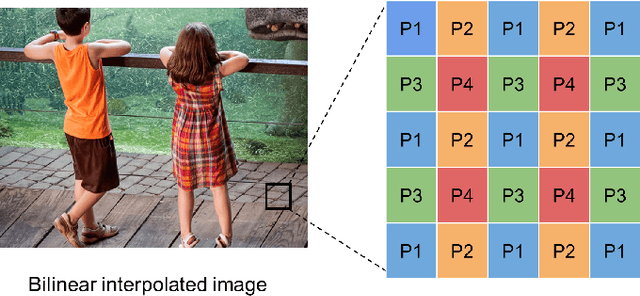
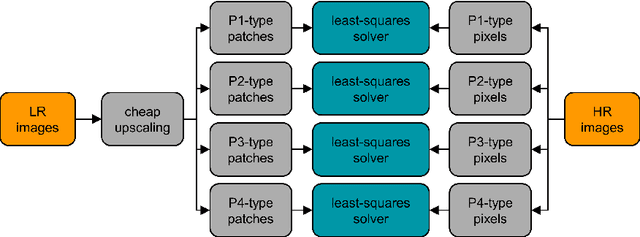
Given an image, we wish to produce an image of larger size with significantly more pixels and higher image quality. This is generally known as the Single Image Super-Resolution (SISR) problem. The idea is that with sufficient training data (corresponding pairs of low and high resolution images) we can learn set of filters (i.e. a mapping) that when applied to given image that is not in the training set, will produce a higher resolution version of it, where the learning is preferably low complexity. In our proposed approach, the run-time is more than one to two orders of magnitude faster than the best competing methods currently available, while producing results comparable or better than state-of-the-art. A closely related topic is image sharpening and contrast enhancement, i.e., improving the visual quality of a blurry image by amplifying the underlying details (a wide range of frequencies). Our approach additionally includes an extremely efficient way to produce an image that is significantly sharper than the input blurry one, without introducing artifacts such as halos and noise amplification. We illustrate how this effective sharpening algorithm, in addition to being of independent interest, can be used as a pre-processing step to induce the learning of more effective upscaling filters with built-in sharpening and contrast enhancement effect.
Shape-constrained Symbolic Regression -- Improving Extrapolation with Prior Knowledge
Mar 29, 2021
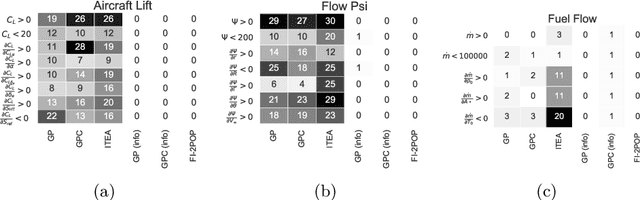
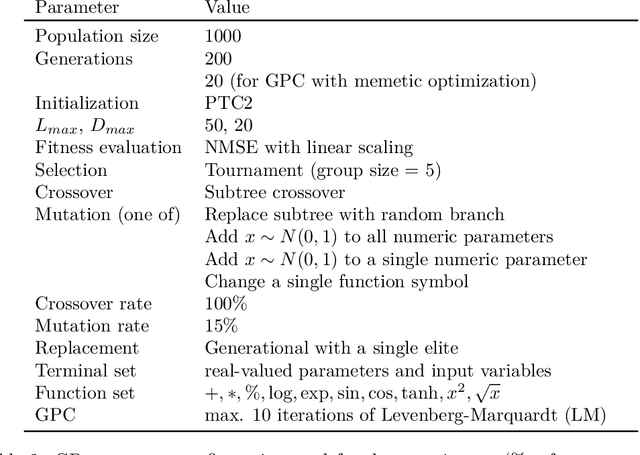
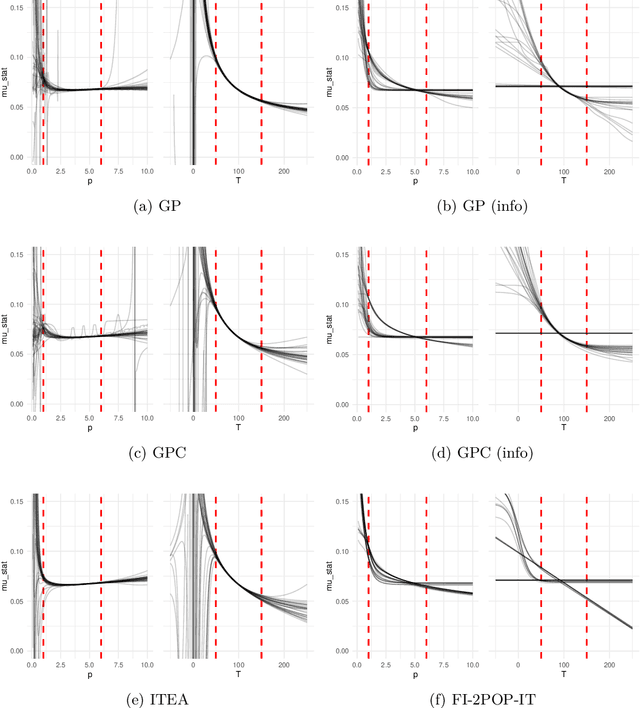
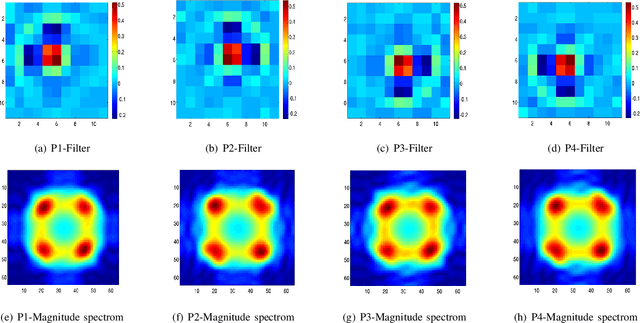
We investigate the addition of constraints on the function image and its derivatives for the incorporation of prior knowledge in symbolic regression. The approach is called shape-constrained symbolic regression and allows us to enforce e.g. monotonicity of the function over selected inputs. The aim is to find models which conform to expected behaviour and which have improved extrapolation capabilities. We demonstrate the feasibility of the idea and propose and compare two evolutionary algorithms for shape-constrained symbolic regression: i) an extension of tree-based genetic programming which discards infeasible solutions in the selection step, and ii) a two population evolutionary algorithm that separates the feasible from the infeasible solutions. In both algorithms we use interval arithmetic to approximate bounds for models and their partial derivatives. The algorithms are tested on a set of 19 synthetic and four real-world regression problems. Both algorithms are able to identify models which conform to shape constraints which is not the case for the unmodified symbolic regression algorithms. However, the predictive accuracy of models with constraints is worse on the training set and the test set. Shape-constrained polynomial regression produces the best results for the test set but also significantly larger models.