 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Image Captioning via Policy Gradient optimization of SPIDEr
Mar 12, 2018
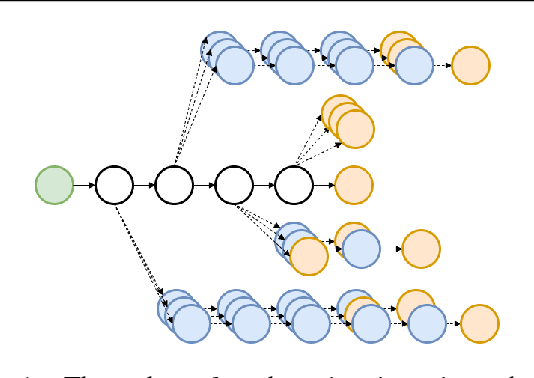
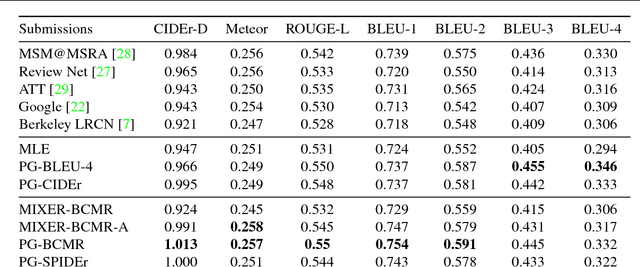
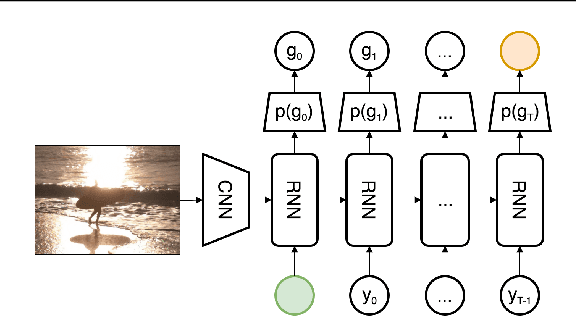

Current image captioning methods are usually trained via (penalized) maximum likelihood estimation. However, the log-likelihood score of a caption does not correlate well with human assessments of quality. Standard syntactic evaluation metrics, such as BLEU, METEOR and ROUGE, are also not well correlated. The newer SPICE and CIDEr metrics are better correlated, but have traditionally been hard to optimize for. In this paper, we show how to use a policy gradient (PG) method to directly optimize a linear combination of SPICE and CIDEr (a combination we call SPIDEr): the SPICE score ensures our captions are semantically faithful to the image, while CIDEr score ensures our captions are syntactically fluent. The PG method we propose improves on the prior MIXER approach, by using Monte Carlo rollouts instead of mixing MLE training with PG. We show empirically that our algorithm leads to easier optimization and improved results compared to MIXER. Finally, we show that using our PG method we can optimize any of the metrics, including the proposed SPIDEr metric which results in image captions that are strongly preferred by human raters compared to captions generated by the same model but trained to optimize MLE or the COCO metrics.
A Retinex-based Image Enhancement Scheme with Noise Aware Shadow-up Function
Nov 08, 2018This paper proposes a novel image contrast enhancement method based on both a noise aware shadow-up function and Retinex (retina and cortex) decomposition. Under low light conditions, images taken by digital cameras have low contrast in dark or bright regions. This is due to a limited dynamic range that imaging sensors have. For this reason, various contrast enhancement methods have been proposed. Our proposed method can enhance the contrast of images without not only over-enhancement but also noise amplification. In the proposed method, an image is decomposed into illumination layer and reflectance layer based on the retinex theory, and lightness information of the illumination layer is adjusted. A shadow-up function is used for preventing over-enhancement. The proposed mapping function, designed by using a noise aware histogram, allows not only to enhance contrast of dark region, but also to avoid amplifying noise, even under strong noise environments.
What Does CNN Shift Invariance Look Like? A Visualization Study
Nov 09, 2020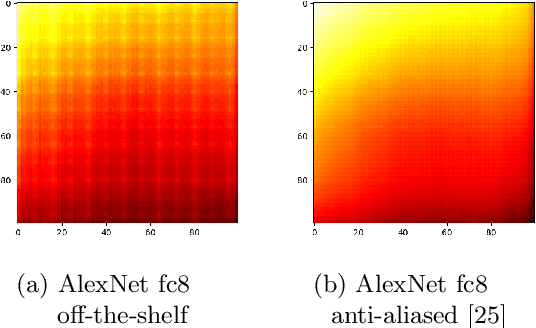
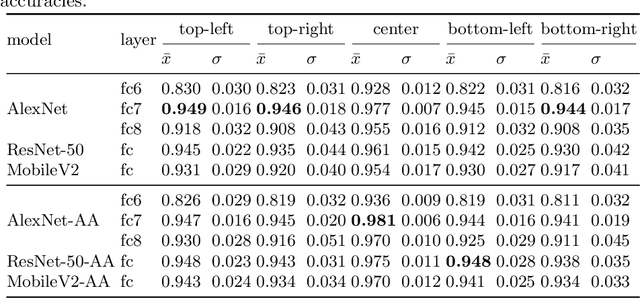
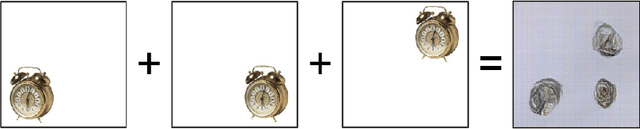
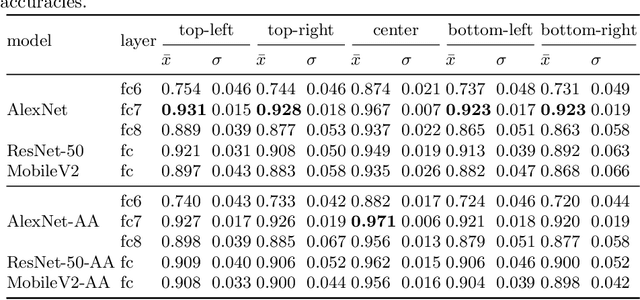
Feature extraction with convolutional neural networks (CNNs) is a popular method to represent images for machine learning tasks. These representations seek to capture global image content, and ideally should be independent of geometric transformations. We focus on measuring and visualizing the shift invariance of extracted features from popular off-the-shelf CNN models. We present the results of three experiments comparing representations of millions of images with exhaustively shifted objects, examining both local invariance (within a few pixels) and global invariance (across the image frame). We conclude that features extracted from popular networks are not globally invariant, and that biases and artifacts exist within this variance. Additionally, we determine that anti-aliased models significantly improve local invariance but do not impact global invariance. Finally, we provide a code repository for experiment reproduction, as well as a website to interact with our results at https://jakehlee.github.io/visualize-invariance.
3D Convolutional Neural Networks Image Registration Based on Efficient Supervised Learning from Artificial Deformations
Aug 27, 2019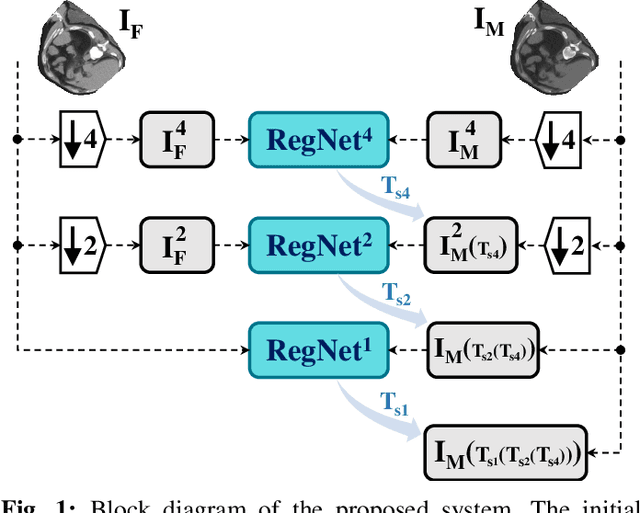
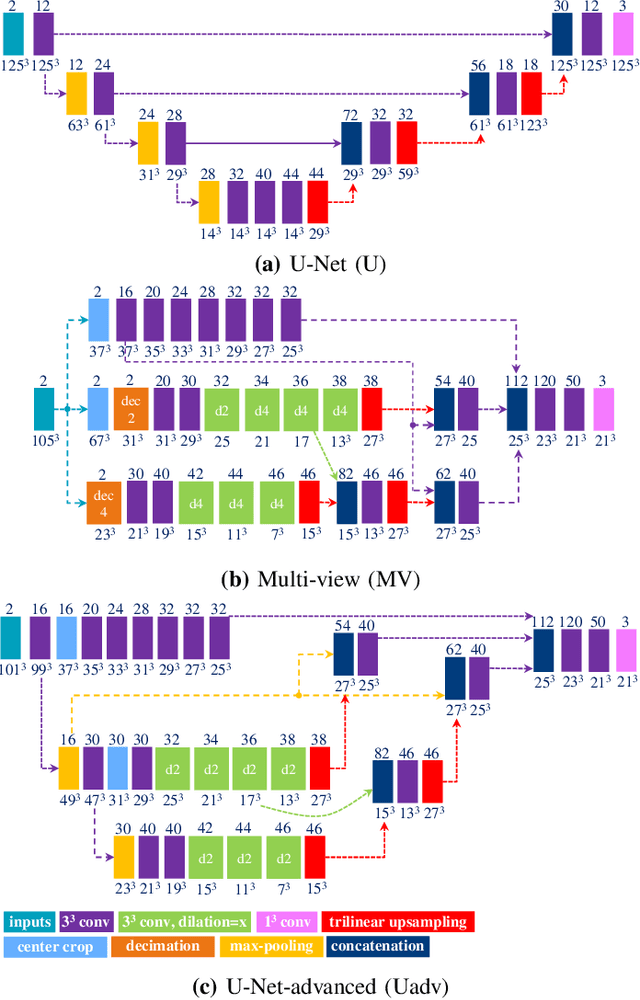
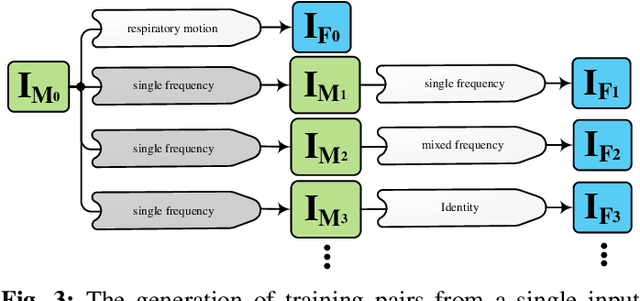
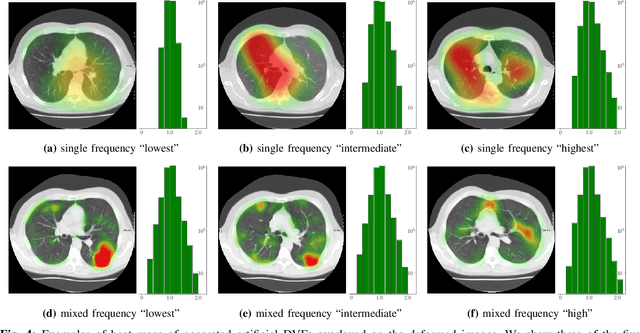
We propose a supervised nonrigid image registration method, trained using artificial displacement vector fields (DVF), for which we propose and compare three network architectures. The artificial DVFs allow training in a fully supervised and voxel-wise dense manner, but without the cost usually associated with the creation of densely labeled data. We propose a scheme to artificially generate DVFs, and for chest CT registration augment these with simulated respiratory motion. The proposed architectures are embedded in a multi-stage approach, to increase the capture range of the proposed networks in order to more accurately predict larger displacements. The proposed method, RegNet, is evaluated on multiple databases of chest CT scans and achieved a target registration error of 2.32 $\pm$ 5.33 mm and 1.86 $\pm$ 2.12 mm on SPREAD and DIR-Lab-4DCT studies, respectively. The average inference time of RegNet with two stages is about 2.2 s.
Beyond Fine-tuning: Classifying High Resolution Mammograms using Function-Preserving Transformations
Jan 20, 2021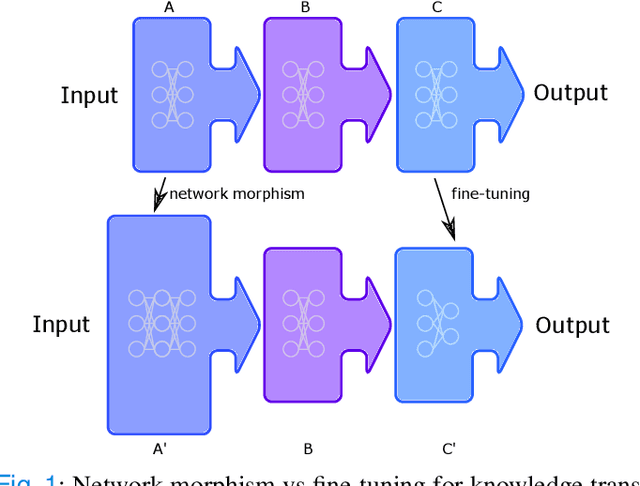
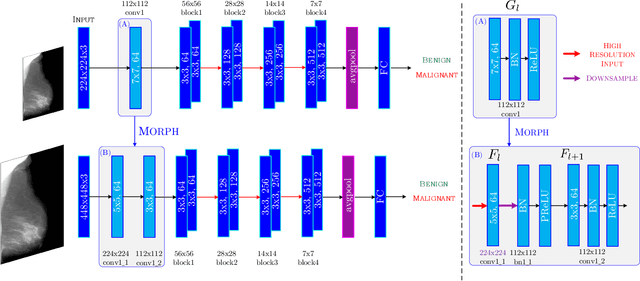
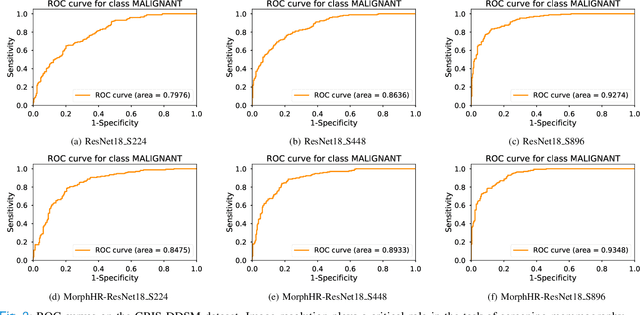
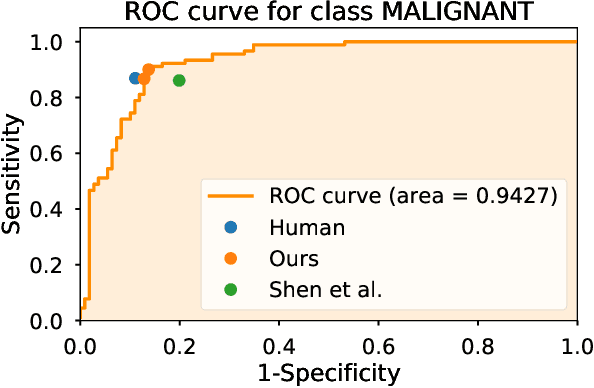
The task of classifying mammograms is very challenging because the lesion is usually small in the high resolution image. The current state-of-the-art approaches for medical image classification rely on using the de-facto method for ConvNets - fine-tuning. However, there are fundamental differences between natural images and medical images, which based on existing evidence from the literature, limits the overall performance gain when designed with algorithmic approaches. In this paper, we propose to go beyond fine-tuning by introducing a novel framework called MorphHR, in which we highlight a new transfer learning scheme. The idea behind the proposed framework is to integrate function-preserving transformations, for any continuous non-linear activation neurons, to internally regularise the network for improving mammograms classification. The proposed solution offers two major advantages over the existing techniques. Firstly and unlike fine-tuning, the proposed approach allows for modifying not only the last few layers but also several of the first ones on a deep ConvNet. By doing this, we can design the network front to be suitable for learning domain specific features. Secondly, the proposed scheme is scalable to hardware. Therefore, one can fit high resolution images on standard GPU memory. We show that by using high resolution images, one prevents losing relevant information. We demonstrate, through numerical and visual experiments, that the proposed approach yields to a significant improvement in the classification performance over state-of-the-art techniques, and is indeed on a par with radiology experts. Moreover and for generalisation purposes, we show the effectiveness of the proposed learning scheme on another large dataset, the ChestX-ray14, surpassing current state-of-the-art techniques.
A Hybrid Quantum enabled RBM Advantage: Convolutional Autoencoders For Quantum Image Compression and Generative Learning
Jan 31, 2020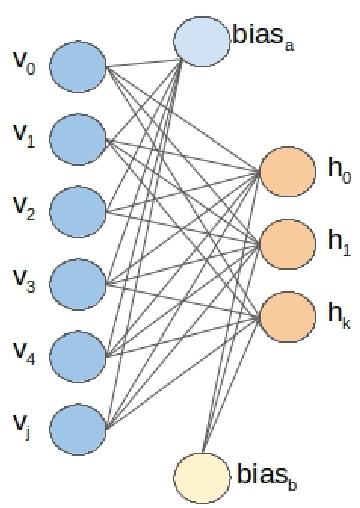

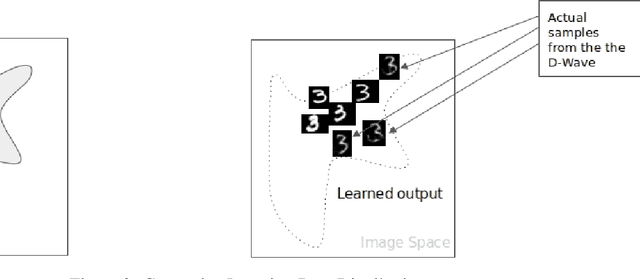

Understanding how the D-Wave quantum computer could be used for machine learning problems is of growing interest. Our work evaluates the feasibility of using the D-Wave as a sampler for machine learning. We describe a hybrid system that combines a classical deep neural network autoencoder with a quantum annealing Restricted Boltzmann Machine (RBM) using the D-Wave. We evaluate our hybrid autoencoder algorithm using two datasets, the MNIST dataset and MNIST Fashion dataset. We evaluate the quality of this method by using a downstream classification method where the training is based on quantum RBM-generated samples. Our method overcomes two key limitations in the current 2000-qubit D-Wave processor, namely the limited number of qubits available to accommodate typical problem sizes for fully connected quantum objective functions and samples that are binary pixel representations. As a consequence of these limitations we are able to show how we achieved nearly a 22-fold compression factor of grayscale 28 x 28 sized images to binary 6 x 6 sized images with a lossy recovery of the original 28 x 28 grayscale images. We further show how generating samples from the D-Wave after training the RBM, resulted in 28 x 28 images that were variations of the original input data distribution, as opposed to recreating the training samples. We formulated an MNIST classification problem using a deep convolutional neural network that used samples from a quantum RBM to train the MNIST classifier and compared the results with an MNIST classifier trained with the original MNIST training data set, as well as an MNIST classifier trained using classical RBM samples. Our hybrid autoencoder approach indicates advantage for RBM results relative to the use of a current RBM classical computer implementation for image-based machine learning and even more promising results for the next generation D-Wave quantum system.
Shape-constrained Symbolic Regression -- Improving Extrapolation with Prior Knowledge
Mar 29, 2021
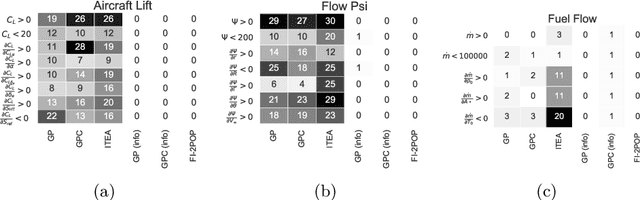
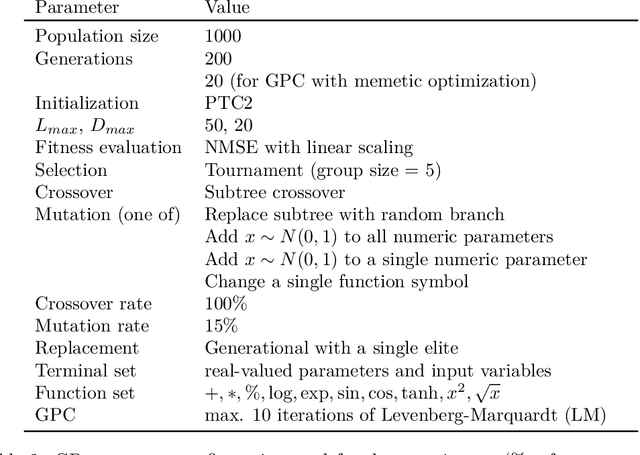
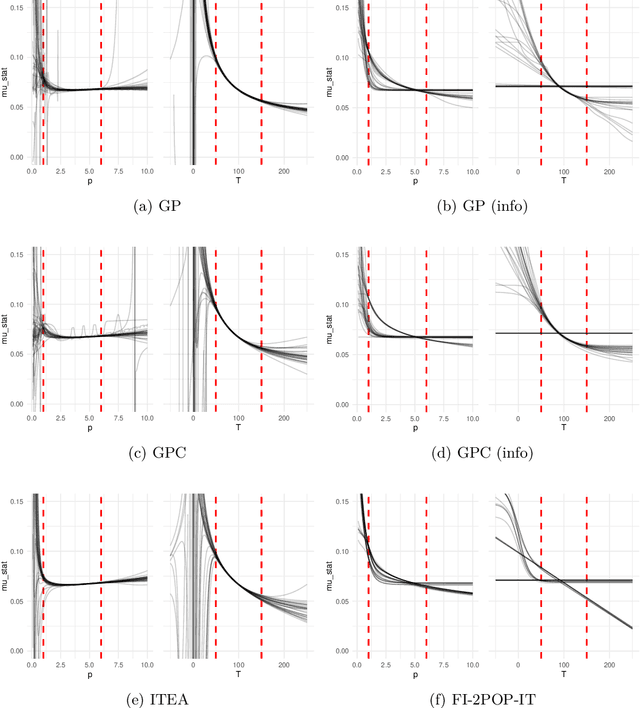
We investigate the addition of constraints on the function image and its derivatives for the incorporation of prior knowledge in symbolic regression. The approach is called shape-constrained symbolic regression and allows us to enforce e.g. monotonicity of the function over selected inputs. The aim is to find models which conform to expected behaviour and which have improved extrapolation capabilities. We demonstrate the feasibility of the idea and propose and compare two evolutionary algorithms for shape-constrained symbolic regression: i) an extension of tree-based genetic programming which discards infeasible solutions in the selection step, and ii) a two population evolutionary algorithm that separates the feasible from the infeasible solutions. In both algorithms we use interval arithmetic to approximate bounds for models and their partial derivatives. The algorithms are tested on a set of 19 synthetic and four real-world regression problems. Both algorithms are able to identify models which conform to shape constraints which is not the case for the unmodified symbolic regression algorithms. However, the predictive accuracy of models with constraints is worse on the training set and the test set. Shape-constrained polynomial regression produces the best results for the test set but also significantly larger models.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 18, 2019

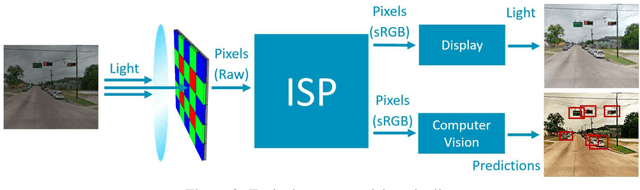
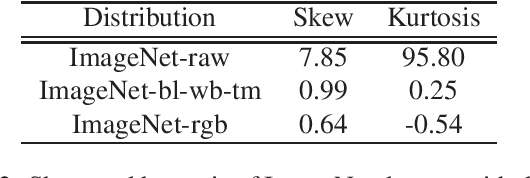
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
Automated Multi-Channel Segmentation for the 4D Myocardial Velocity Mapping Cardiac MR
Dec 16, 2020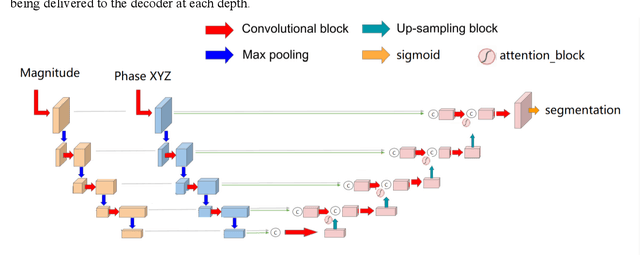
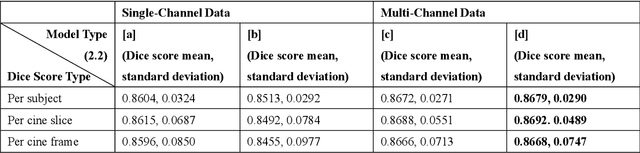

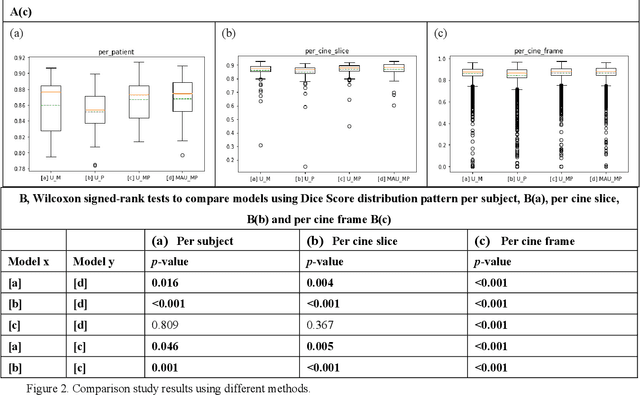
Four-dimensional (4D) left ventricular myocardial velocity mapping (MVM) is a cardiac magnetic resonance (CMR) technique that allows assessment of cardiac motion in three orthogonal directions. Accurate and reproducible delineation of the myocardium is crucial for accurate analysis of peak systolic and diastolic myocardial velocities. In addition to the conventionally available magnitude CMR data, 4D MVM also acquires three velocity-encoded phase datasets which are used to generate velocity maps. These can be used to facilitate and improve myocardial delineation. Based on the success of deep learning in medical image processing, we propose a novel automated framework that improves the standard U-Net based methods on these CMR multi-channel data (magnitude and phase) by cross-channel fusion with attention module and shape information based post-processing to achieve accurate delineation of both epicardium and endocardium contours. To evaluate the results, we employ the widely used Dice scores and the quantification of myocardial longitudinal peak velocities. Our proposed network trained with multi-channel data shows enhanced performance compared to standard U-Net based networks trained with single-channel data. Based on the results, our method provides compelling evidence for the design and application for the multi-channel image analysis of the 4D MVM CMR data.
Improving the generalization of network based relative pose regression: dimension reduction as a regularizer
Oct 24, 2020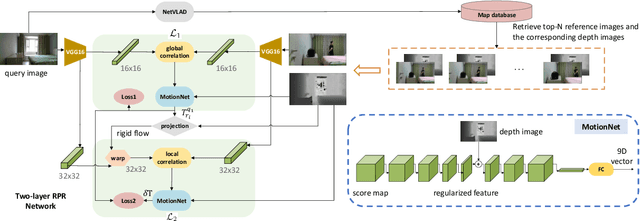
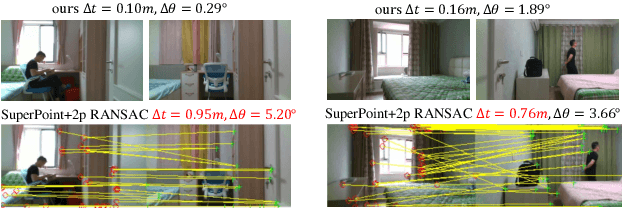
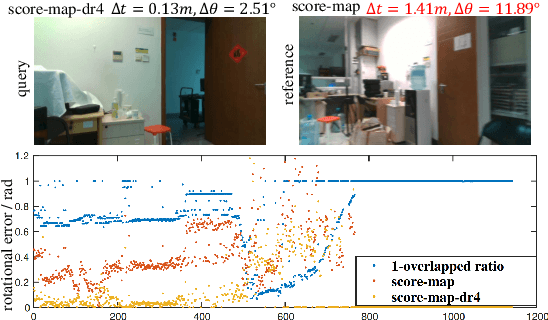
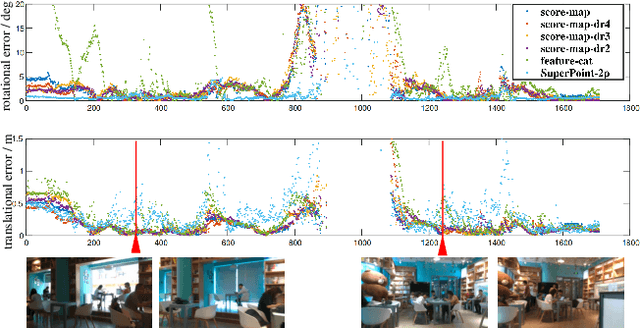
Visual localization occupies an important position in many areas such as Augmented Reality, robotics and 3D reconstruction. The state-of-the-art visual localization methods perform pose estimation using geometry based solver within the RANSAC framework. However, these methods require accurate pixel-level matching at high image resolution, which is hard to satisfy under significant changes from appearance, dynamics or perspective of view. End-to-end learning based regression networks provide a solution to circumvent the requirement for precise pixel-level correspondences, but demonstrate poor performance towards cross-scene generalization. In this paper, we explicitly add a learnable matching layer within the network to isolate the pose regression solver from the absolute image feature values, and apply dimension regularization on both the correlation feature channel and the image scale to further improve performance towards generalization and large viewpoint change. We implement this dimension regularization strategy within a two-layer pyramid based framework to regress the localization results from coarse to fine. In addition, the depth information is fused for absolute translational scale recovery. Through experiments on real world RGBD datasets we validate the effectiveness of our design in terms of improving both generalization performance and robustness towards viewpoint change, and also show the potential of regression based visual localization networks towards challenging occasions that are difficult for geometry based visual localization methods.